在資料分析和建模的程序中,有相當多的時間要用在資料準備上:加載、清理、轉換以及重塑,這些作業會占到分析師時間的80%或更多,幸運的是pandas和內置的Python標準庫提供了高效、靈活的工具可以幫助我們輕松的做這些事情,
本文重點介紹通過pandas進行資料的清洗,資料處理中的清洗作業主要包括對需要分析的資料集中的缺失值(空值)、重復值、例外值的處理,對于資料清洗一般也是分兩個步驟,第一步就是要很方便快速的找到需要處理的資料,如何快速找到資料中的缺失值(空值)、重復資料或例外的資料,第二步是對找到的資料根據自己的實際使用需求進行處理,如洗掉還是替換成其他的資料,
一、處理缺失值
在許多資料分析作業程序中,由于對資料質量問題,缺失資料是經常發生的,對于數值資料,pandas使用浮點值NaN(Not a Number)表示缺失資料,在pandas中,還采用了R語言中慣用的缺失值表示法NA,它表示不可用not available,在統計應用中,NA資料可能是不存在的資料或雖然存在但是看不到,進行資料清洗對缺失資料進行分析,以判斷資料采集的問題或缺失資料導致的偏差,
1、判斷缺失值(空值)
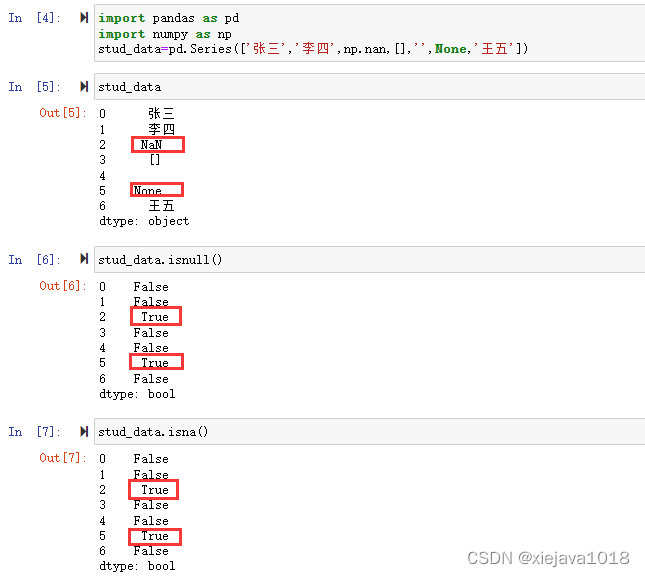
在pandas中通過isna()或isnull()方法判斷空值,二者等價,用于判斷一個series或dataframe各元素值是否為空的bool結果,需注意對空值的界定:即None或numpy.nan才算空值,而空字串、空串列等則不屬于空值;類似地,notna()和notnull()則用于判斷是否非空,
看下實體:
import pandas as pd
import numpy as np
stud_data=pd.Series(['張三','李四',np.nan,[],'',None,'王五'])
stud_data
通過stud_data.isnull()和stud_data.isna()分別來判斷空值
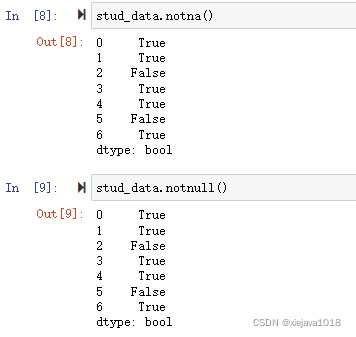
類似地,notna()和notnull()則用于判斷是否非空
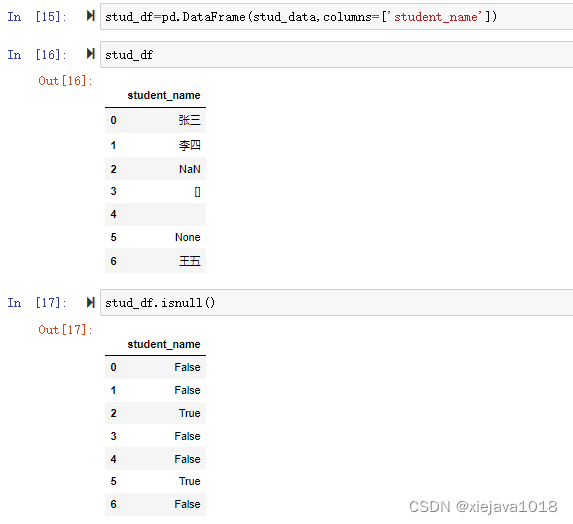
同樣的對于DataFrame中的缺失資料判斷也是一樣的,
構建DataFrame
stud_df=pd.DataFrame(stud_data,columns=['student_name'])
stud_df
對于缺失值的處理有兩種常用的方式,一是用按一定的策略對空值進行填充,二是對于缺失值干脆進行洗掉,
2、填充缺失值(空值)
pandas中用戶填充缺失值的方法是fillna(),可以按一定的策略對空值進行填充,如常數填充、向前/向后填充等,也可通過inplace引數確定是否本地更改,
1.常量填充
stud_df[['student_name']].fillna('某某')

可以看到判斷為缺失值的地方都填充了"某某",因為空字串和空串列都不是缺失值,所以沒有填充,
2.向前和向后填充NA
通過fillna(mathod=‘ffill’),mathod=‘ffill’ 向前填充和 mathod=‘bfill’ 向后填充,也就是說用前面的值來填充NA或用后面的值來填充NA
我們來增加一列性別列gender來看一下,
stud_gender_data=pd.Series([1,0,np.nan,'女',1,None,'男'])
stud_df['gender']=stud_gender_data
stud_df
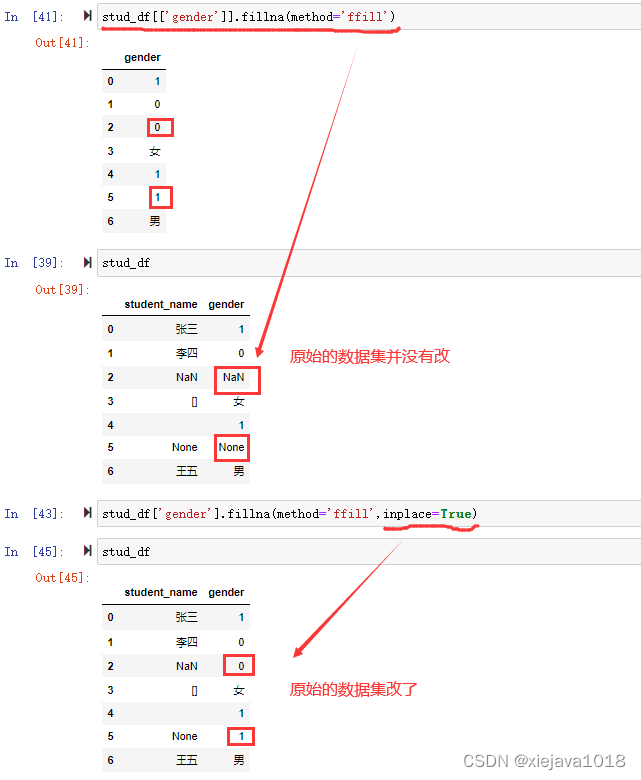
stud_df[['gender']].fillna(method='ffill')
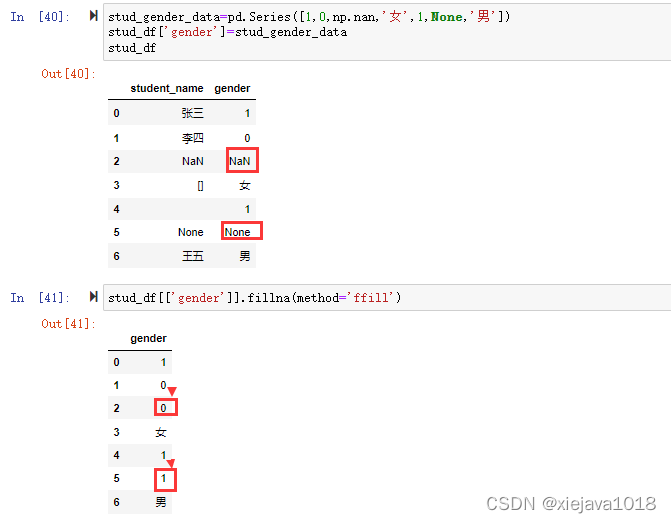
可以看到通過method=‘ffill’,將NaN和None前面的值填充端到了NaN和None,
用fillna()進行填充會回傳一個填充好的資料集的副本,并沒有對原始資料進行操作,如果要修改原始資料可以通過inplace引數確定是否本地更改,
3、洗掉缺失值(空值)
如果想洗掉缺失值,那么使用 dropna() 函式與引數 axis 可以實作,在默認情況下,按照 axis=0 來按行處理,這意味著如果某一行中存在 NaN 值將會洗掉整行資料,如果在dropna()中傳入how='all'將只會洗掉全為NA或NaN的行,示例如下:

二、處理重復值
重復資料也是在實際資料處理程序中碰到比較多的,處理重復資料就是在資料集中找出重復資料然后將其洗掉保留一個唯一不重復的資料,
1、檢測重復值
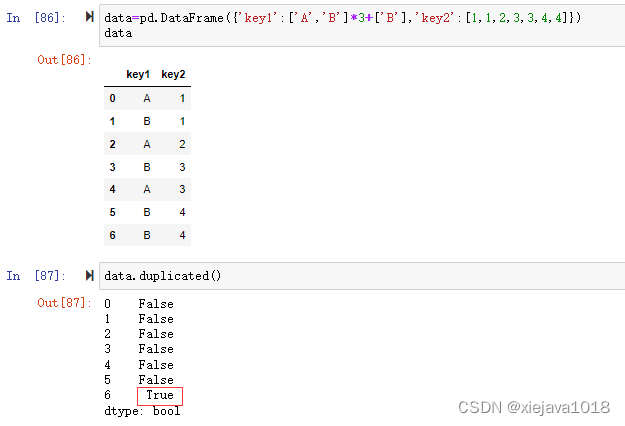
pandas通過duplicated()方法檢測各行是否重復,回傳一個行索引的bool結果,可通過keep引數設定保留第一行、最后一行、無保留,例如keep=first意味著在存在重復的多行時,首行被認為是合法的而可以保留,
構造一個DataFrame來看一個實體:
data=pd.DataFrame({'key1':['A','B']*3+['B'],'key2':[1,1,2,3,3,4,4]})
data
data.duplicated()
2、洗掉重復值
pandas通過drop_duplicates()方法按行檢測并洗掉重復的記錄,也可通過keep引數設定保留項,由于該方法默認是按行進行檢測,如果存在某個需要需要按列洗掉,則可以先轉置再執行該方法,
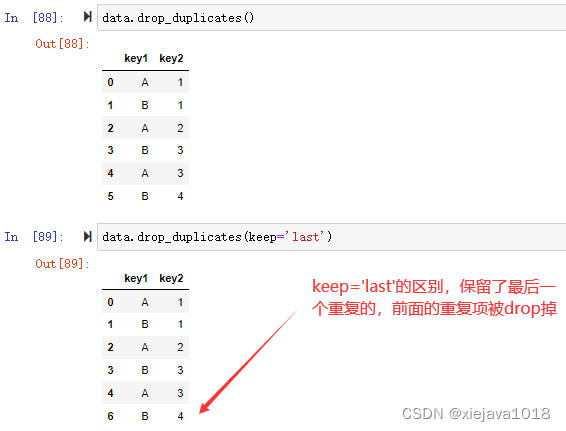
data.drop_duplicates()
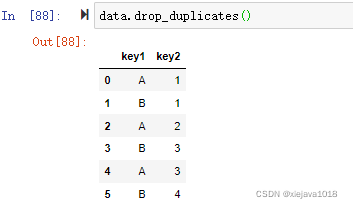
可以看到第7行也就是index為6的重復行被洗掉了,
當帶了keep='last'引數時,保留最后一個重復項,前面的重復項將被丟棄,可以看到保留的是索引為6的,索引為5的重復項被丟棄了,
三、處理例外值
1、判斷例外值
判斷例外值的標準依賴具體分析資料,如大于或小于某個基線范圍的值,
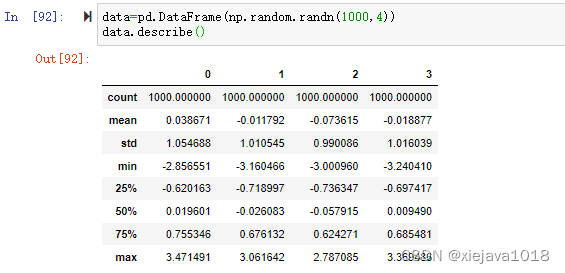
我們來看一個含有正態分布的DataFrame資料集
data=pd.DataFrame(np.random.randn(1000,4))
data.describe()
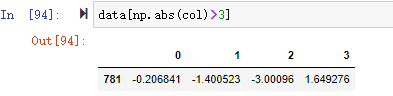
假設我們認為某列中絕對值大小超過3的是例外值,那么判斷例外值就是要找出某列中大小超過3的值,
data[np.abs(col)>3]
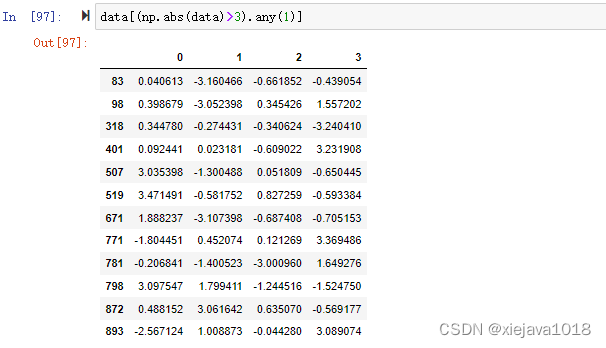
要選出全部含有絕對值大小超過3的行,可以在布爾型DataFrame中使用any()方法,
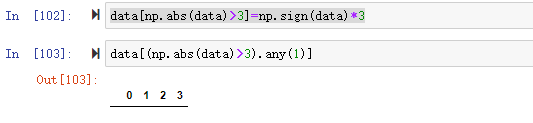
data[(np.abs(data)>3).any(1)]
2、替換例外值
對于例外值,可以直接替換,
如:
data[np.abs(data)>3]=np.sign(data)*3
這樣就可以將例外值替換為絕對值不大于3的
3、洗掉例外值
洗掉例外值,可以用pandas的drop()方法,接受引數在特定軸線執行洗掉一潭訓多條記錄,可通過axis引數設定是按行洗掉還是按列洗掉
如洗掉第3列,列索引為2的列中絕對值>3的行
col=data[2]
data.drop(data[np.abs(col)>3].index,inplace=True)
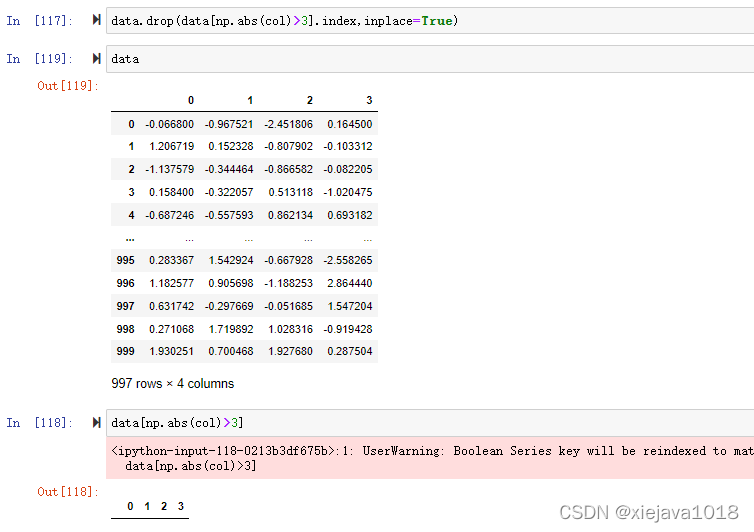
可以看到本來有1000行的,洗掉了3行,再用data[np.abs(col)>3]驗證,已經找不到資料了,
至此,本文通過實體介紹了pandas進行資料清洗包括缺失值、重復值及例外值的處理,資料清洗是資料分析前面的準備作業,資料質量的好壞將直接影響資料分析的結果,
作者博客:http://xiejava.ishareread.com/
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423346.html
標籤:AI