論文閱讀筆記:Swin Transformer
- 前言
- 網路結構
- 網路細節
- Patch Merging
- W-MSA
- SW-MSA
- Efficient batch computation for shifted configuration
- Relative Position Bias
前言
論文原文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
原始碼地址:https://github.com/microsoft/Swin-Transformer
本篇論文作者試圖擴展Transformer的適用性,使其讓NLP可以和CNNs在視覺中一樣,作為計算機視覺的通用backbone,但是將Transformer在語言領域的高性能轉移到視覺領域的重大挑戰主要體現在兩種模式的兩個差異上:
1.規模:與word tokens不同,視覺元素在規模上可能有很大差異,這是一個在目標檢測等任務中受到關注的問題,在現有的基于Transformer的模型中,token都是固定比例的,這一屬性不適合視覺應用,
2.計算量:與文本段落中的單詞相比,影像中的像素解析度要高得多,存在許多視覺任務,例如需要在像素級進行密集預測的語意分割,而這對于高解析度影像上的Transformer來說是很困難的,因為自注意力的計算復雜性是影像大小的二次方,
為了克服這些問題,作者提出了一種通用的backbone,稱為Swin Transformer,它可以構造分層特征映射,并且計算復雜度與影像大小成線性關系,如圖所示:
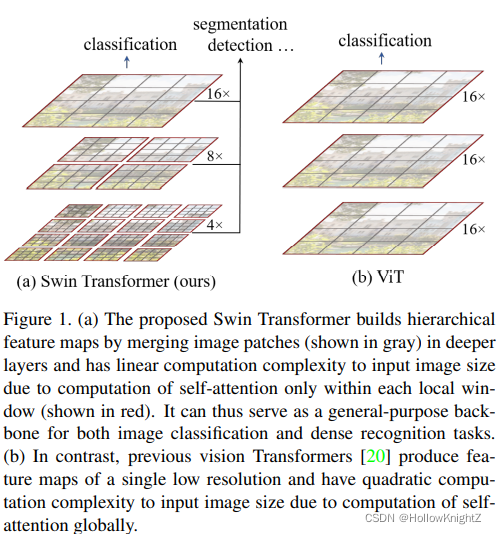
可以看出Swin Transformer更貼近于傳統的具有多尺寸特征圖的CNNs backbone,對影像分別下采樣4倍,8倍以及16倍,而Vision Transformer(ViT)一直下采樣16倍,多尺寸的特征圖有利于不同尺寸大小目標的分割和檢測任務(解決了差異1帶來的問題),
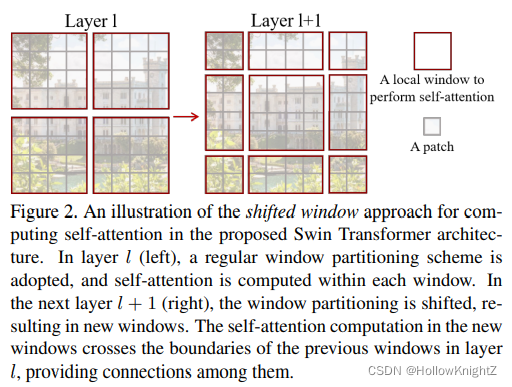
Swin Transformer的另一個創新點為將連續的self-attention layers劃分成多個視窗,每個視窗單獨進行muti-head self-attetion(后文中均簡稱為MSA)計算,文中稱為windows muti-head self-attetion(后文中均簡稱為W-MSA)計算,在W-MSA后會通過shift window的方式將視窗滑動,使得不同window之間可以資訊互動,文中成為shifted windows muti-head self-attetion(后文中均簡稱為SW-MSA)計算,如下圖,通過W-MSA和SW-MSA,成功的降低了計算量并且也保證了各個window之間的資訊互動,保證了全域視野(解決了差異2帶來的問題),
那么上述的兩種方法具體是如何實作的呢?下文會通過介紹Swin Transformer的網路結構來詳細講解,
網路結構
詳細的網路結構引數如下表:
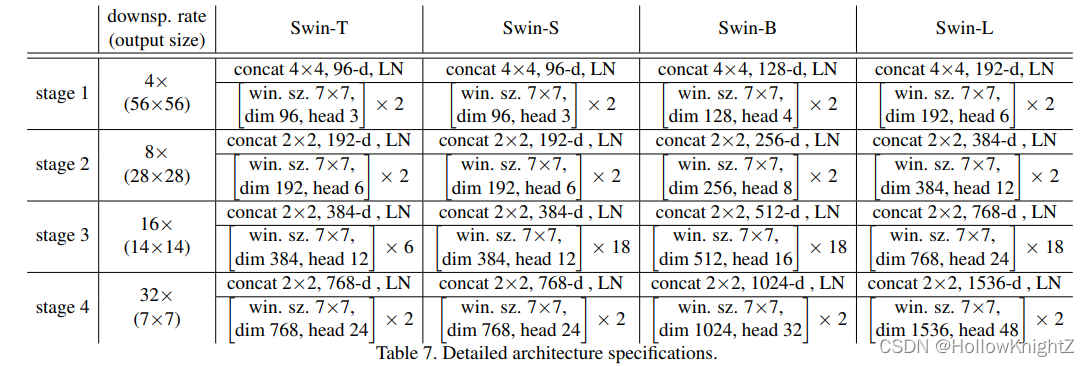
上表表示有Swin-T、 Swin-S、 Swin-B、 Swin-L四種尺寸的網路結構,C代表stage1之后的輸出通道:

論文中給出的是Swin Transformer的Swin-T的網路結構,如圖(a),其中的Swin Transformer Block如圖(b),即將VIT attention Encoding Block中的MSA換成了W-MSA和SW-MSA:
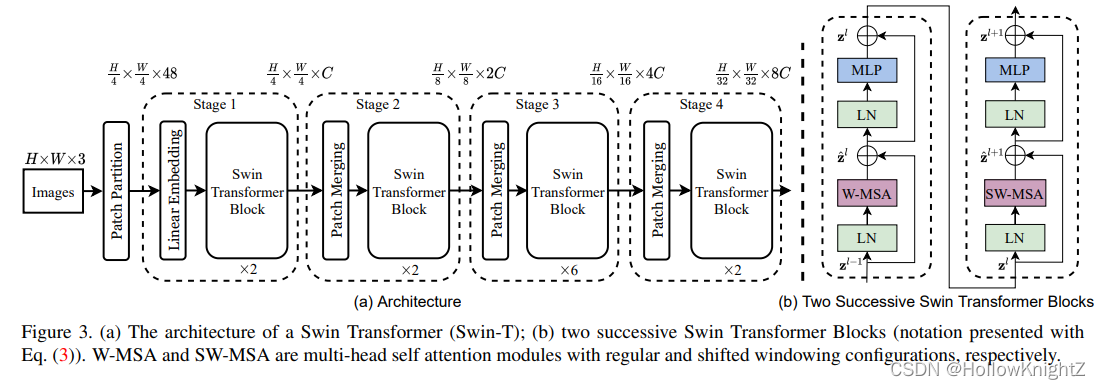
首先將
H
×
W
×
3
H×W×3
H×W×3 的圖片輸入到Patch Partition中進行分塊,每個Patch的大小為
4
×
4
×
3
=
48
4×4×3=48
4×4×3=48,通過Patch Partition后 shape 從
H
×
W
×
3
H×W×3
H×W×3 變為
H
4
×
W
4
×
48
\frac{H}{4} ×\frac{W}{4}×48
4H?×4W?×48 ,然后在通過Linear Embeding層對每個像素的channel資料做線性變換,變為
H
4
×
W
4
×
C
\frac{H}{4} ×\frac{W}{4}×C
4H?×4W?×C,接著通過4個Stage進行下采樣,除了Stage1是Linear Embedding加一對Swin Transformer Block,其他三個Stage都是一個patch merging加若干對Swin Transformer Block,Patch Partition加Stage1的Linear Embedding,這個程序類似于VIT中的Linear Projection of Flattened Patches操作,即patch embedding程序(可查看博文【論文閱讀筆記:Vision Transformer】和博文【Vision Transformer(Pytorch版)代碼閱讀注釋】了解),一對Swin Transformer Block如圖(b)中的包含W-MSA的Block和SW-MSA Block,所以Stage中的Block都是2的倍數,
網路細節
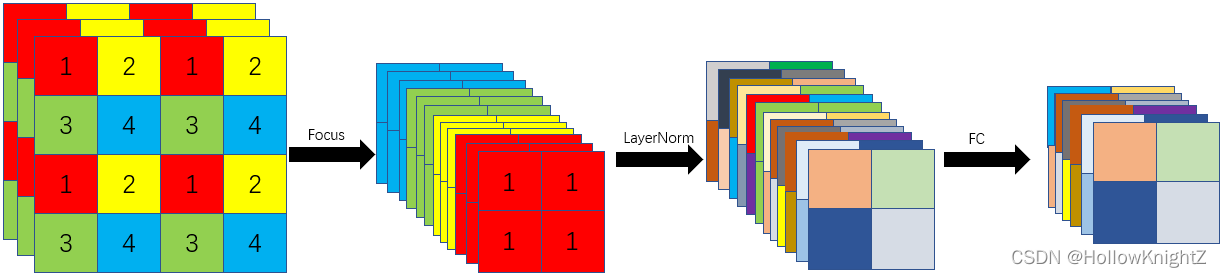
Patch Merging
Patch Merging類似于YoloV5中的Focus模塊(Focus模塊的介紹可查看博文【從YOLOv5原始碼yolo.py詳細介紹Yolov5的網路結構】),只不過在Patch Merging模塊在Focus模塊之后再進行LayerNorm和通道上的全連接,使得
H
=
H
0
2
,
W
=
W
0
2
,
C
=
C
0
×
2
H=\frac{H_0}{2} ,W=\frac{W_0}{2},C=C_0×2
H=2H0??,W=2W0??,C=C0?×2,如下圖:
W-MSA
引入W-MSA的目的是為了減少計算量,但同時也會使得window之間無法進行資訊互動,
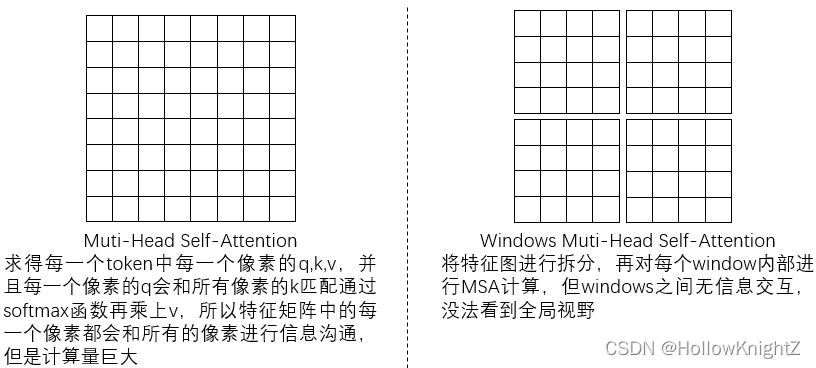
論文中提到一個
h
×
w
×
C
h×w×C
h×w×C 的 特征圖,MSA 的計算量為公式(1),拆分成 window 寬高均為 M 以后的 W-MSA計算量為公式(2):
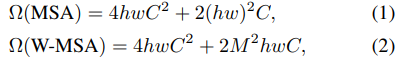
這兩個計算量公式是根據Muti-Head Self-Attention公式得來的(Attention公式介紹可查看博文【論文閱讀筆記:Attention Is All You Need】):

兩個矩陣相乘(
A
a
×
b
×
B
b
×
c
=
C
a
×
c
A^{a×b}×B^{b×c}=C^{a×c}
Aa×b×Bb×c=Ca×c)的計算量為:
F
L
O
P
s
=
a
×
b
×
c
+
a
×
(
b
?
1
)
×
c
≈
2
×
a
×
b
×
c
FLOPs = a×b×c + a×(b-1)×c≈2×a×b×c
FLOPs=a×b×c+a×(b?1)×c≈2×a×b×c
其中包含
a
×
b
×
c
a×b×c
a×b×c 次乘法和
a
×
(
b
?
1
)
×
c
a×(b-1)×c
a×(b?1)×c 次加法,
MSA計算步驟如下:
1.由于
h
×
w
×
C
h×w×C
h×w×C 的 特征圖相當于有
h
×
w
h×w
h×w 個
C
C
C 維的token向量,將其表示為矩陣:
A
h
w
×
C
A^{hw×C}
Ahw×C
2.Token 矩陣通過乘上 W q C × d k , W k C × d k , W v C × d v W_q^{C×d_k},W_k^{C×d_k},W_v^{C×d_v} WqC×dk??,WkC×dk??,WvC×dv?? 獲得對應的 Q h w × d k , K h w × d k , V h w × d v Q^{hw×d_k},K^{hw×d_k},V^{hw×d_v} Qhw×dk?,Khw×dk?,Vhw×dv?,即:
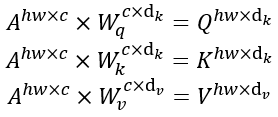
依據論文Attention的原始碼,假設 d k = d v = C h e a d d_k=d_v= \frac{C}{head} dk?=dv?=headC?,因此 3 對矩陣相乘計算量為 6 h w C 2 h e a d \frac{6hwC^2}{head} head6hwC2?,
3.接著計算 Q h w × C h e a d × ( K T ) C h e a d × h w Q^{hw× \frac{C}{head}}×(K^T)^{ \frac{C}{head}×hw} Qhw×headC?×(KT)headC?×hw,得到 h w × h w hw× hw hw×hw 大小的矩陣,計算量為 2 ( h w ) 2 C h e a d \frac{2(hw)^2C}{head} head2(hw)2C?,
4.除以
d
k
\sqrt{d_k}
dk?
?再計算softmax,論文中提出忽略這部分的計算量:

矩陣大小依然為
h
w
×
h
w
hw× hw
hw×hw ,
5.將得到的 h w × h w hw×hw hw×hw 的矩陣再乘上 V h w × C h e a d V^{hw× \frac{C}{head}} Vhw×headC?,得到 h w × C h e a d hw× \frac{C}{head} hw×headC? 大小的矩陣,計算量為 2 ( h w ) 2 C h e a d \frac{2(hw)^2C}{head} head2(hw)2C?,
6.最后再乘上融合矩陣 W O C h e a d ? C W_O^{ \frac{C}{head}*C} WOheadC??C?將特征矩陣還原成 h w × C hw×C hw×C 大小的矩陣,計算量為 2 h w C 2 h e a d \frac{2hwC^2}{head} head2hwC2?,
總計算量為 8 h w C 2 h e a d + 4 ( h w ) 2 C h e a d \frac{8hwC^2}{head}+\frac{4(hw)^2C}{head} head8hwC2?+head4(hw)2C?,因為 muti-head self-attention 中 head ≥ 2,所以總計算量 ≤ 4 h w C 2 + 2 ( h w ) 2 C 4hwC^2+2(hw)^2C 4hwC2+2(hw)2C,這里取最大值進行比較,
W-MSA計算步驟如下:
1.將
h
×
w
×
C
h×w×C
h×w×C 的 特征圖劃分到
h
M
×
w
M
\frac{h}{M}×\frac{w}{M}
Mh?×Mw? 個寬高均為 M 的 windows 中,
2.將每個寬高為 M 的 windows 進行WSA計算,每個 windows 的計算量為 4 ( M C ) 2 + 2 ( M ) 4 C 4(MC)^2+2(M)^4C 4(MC)2+2(M)4C,
3. h M × w M \frac{h}{M}×\frac{w}{M} Mh?×Mw? 個 windows 的總計算量為 h M × w M × ( 4 ( M C ) 2 + 2 ( M ) 4 C ) = 4 h w C 2 + 2 M 2 h w C \frac{h}{M}×\frac{w}{M}×(4(MC)^2+2(M)^4C) =4hwC^2+2M^2hwC Mh?×Mw?×(4(MC)2+2(M)4C)=4hwC2+2M2hwC.
由于W-MSA只和 h w hw hw 的一次方成線性關系,而MSA會包含 h w hw hw 的二次關系,因此W-MSA大大的降低了計算量,
SW-MSA
前文介紹W-MSA在劃分視窗時會帶來windows間資訊無法互動的問題,所以作者提到使用 shifted window 的方法來增加資訊互動,論文的描述如下:

即先從左上角開始使用常規的W-MSA進行視窗劃分,每個視窗大小為
M
×
M
M×M
M×M,接著以
s
t
r
i
d
e
=
(
?
M
2
?
,
?
M
2
?
)
stride = (\lfloor \frac{M}{2} \rfloor,\lfloor \frac{M}{2} \rfloor)
stride=(?2M??,?2M??) 滑動視窗,
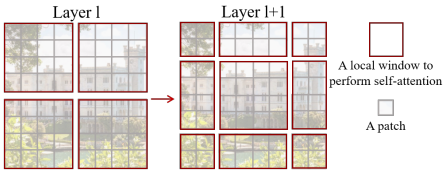
以上圖為例,左邊為
L
a
y
e
r
Layer
Layer
l
l
l 層 feature map 大小為
8
×
8
8×8
8×8,window 大小為
4
×
4
4×4
4×4,共
2
×
2
2×2
2×2 個windows,每個window以
s
t
r
i
d
e
=
(
?
M
2
?
,
?
M
2
?
)
=
(
2
,
2
)
stride = (\lfloor \frac{M}{2} \rfloor,\lfloor \frac{M}{2} \rfloor)=(2,2)
stride=(?2M??,?2M??)=(2,2) 滑動,得到右邊
L
a
y
e
r
Layer
Layer
l
+
1
l+1
l+1 層的 feature map,其程序可以用下圖表示:
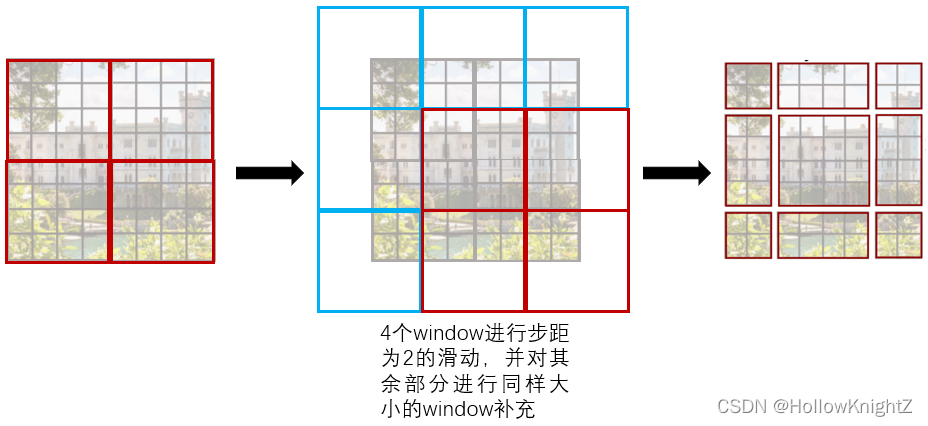
Efficient batch computation for shifted configuration
SW-MSA 將原本資訊不互動的
?
h
M
?
×
?
w
M
?
\lceil \frac{h}{M} \rceil×\lceil \frac{w}{M} \rceil
?Mh??×?Mw?? 個 windows 做了資訊互動并變成了
(
?
h
M
?
+
1
)
×
(
?
w
M
?
+
1
)
(\lceil \frac{h}{M} \rceil+1)×(\lceil \frac{w}{M} \rceil+1)
(?Mh??+1)×(?Mw??+1) 個,如果對每個 windows 都做 MSA 計算,那么計算量又會比 W-MSA 多,而且 每個 window 的大小也不一樣, 無法并行計算,為了解決這個問題,論文提出了一種相鄰非重疊視窗之間的連接方式j,如下圖:
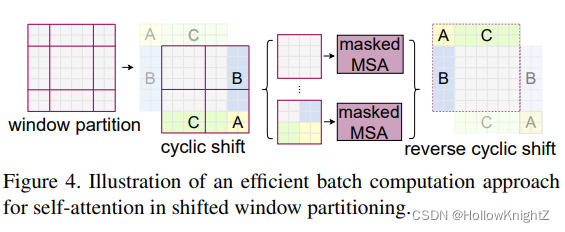
該程序如果不理解可以看下圖:
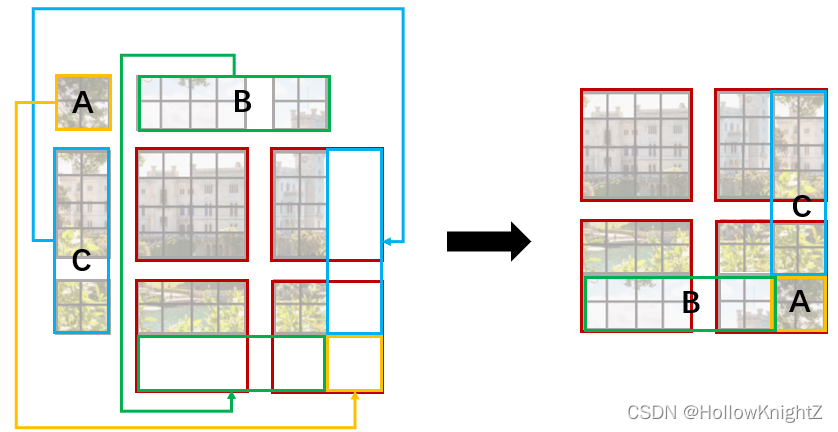
其將A、B、C三個框中的 window 移動到四個
4
×
4
4×4
4×4 紅色框的對應位置,使其湊成四個
4
×
4
4×4
4×4 的window,由于有幾個 window 是由不相鄰的子視窗組成,需要通過Masked MSA 掩膜計算來限制每個 window 中的不同子視窗的 MSA,
至于 window 是如何移動以及掩膜計算如何實作,會通過后續的代碼閱讀博文來介紹,
Relative Position Bias
論文使用了相對位置偏置,公式如下:
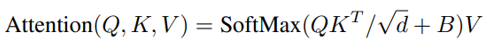
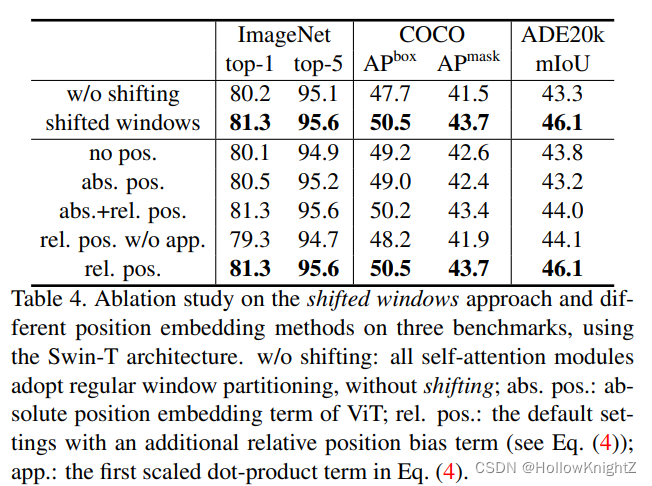
論文中只是提到使用改偏置的效果,并沒有產出細節,后續也會通過代碼閱讀博文來介紹,
使用了相對位置偏置
(
r
e
l
.
p
o
s
.
)
(rel.pos.)
(rel.pos.)以后帶來了明顯的提升,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423345.html
標籤:AI