引言
本著“凡我不能創造的,我就不能理解”的思想,本系列文章會基于純Python以及NumPy從零創建自己的深度學習框架,該框架類似PyTorch能實作自動求導,
要深入理解深度學習,從零開始創建的經驗非常重要,從自己可以理解的角度出發,盡量不使用外部完備的框架前提下,實作我們想要的模型,本系列文章的宗旨就是通過這樣的程序,讓大家切實掌握深度學習底層實作,而不是僅做一個調包俠,
本系列文章首發于微信公眾號:JavaNLP
我們已經了解了線性回歸和邏輯回歸,本文來學習深度學習中神經網路的基礎構建——神經元,以及常見的激活函式,
神經元
神經網路和邏輯回歸很像,但神經網路更強大,而神經網路是由很多個神經元(Neuron)組成的,一個神經元將實數集作為輸入,然后應用某種運算,產生一個實數輸出,
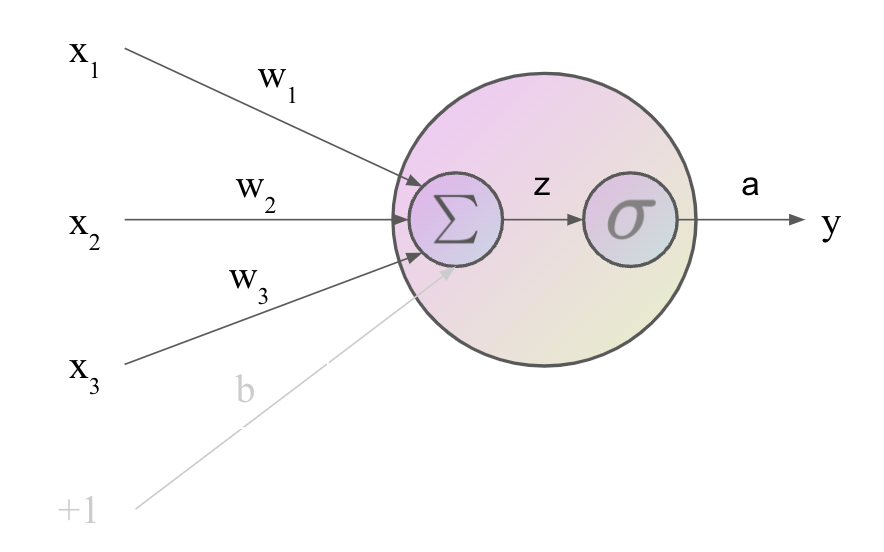
在神經元內部,如上圖所示,神經元首先計算輸入的加權和
∑
i
w
i
x
i
\sum_i w_i x_i
∑i?wi?xi?,然后加上偏置項
b
b
b,給定輸入
x
1
,
?
?
,
x
n
x_1,\cdots,x_n
x1?,?,xn?,每個輸入對應一個權重,得到加權和
z
z
z:
z
=
b
+
∑
i
w
i
x
i
(1)
z = b + \sum_i w_i x_i \tag 1
z=b+i∑?wi?xi?(1)
通常使用向量的形式描述更加方便,這樣
z
z
z由向量
w
w
w和標量
b
b
b,以及輸入向量
x
x
x來描述:
z
=
w
?
x
+
b
(2)
z =w \cdot x +b \tag 2
z=w?x+b(2)
注意這里得到的
z
z
z只是一個實數(標量),
最后,我們不是直接使用
z
z
z作為輸出,神經元內部應用一個非線性函式
f
f
f到
z
z
z?上:
y
=
a
=
f
(
z
)
y = a = f(z)
y=a=f(z)
這里的非線性函式稱為激活函式,該函式的輸出值稱為激活值
a
a
a,我們已經見過的一種激活函式是Sigmoid函式:
y
=
σ
(
z
)
=
1
1
+
e
?
z
(3)
y = \sigma(z) = \frac{1}{1 + e^{-z}} \tag 3
y=σ(z)=1+e?z1?(3)
這里神經元的輸出
y
y
y和激活值
a
a
a相同,但在神經網路中,我們通常用
y
y
y?表示整個網路最終的輸出,把
(
2
)
(2)
(2)代入
(
3
)
(3)
(3),得到神經元的輸出:
y
=
σ
(
w
?
x
+
b
)
=
1
1
+
exp
?
(
?
(
w
?
x
+
b
)
)
(4)
y = \sigma(w\cdot x + b) = \frac{1}{1 + \exp(-(w\cdot x + b))} \tag 4
y=σ(w?x+b)=1+exp(?(w?x+b))1?(4)
除了Sigmoid之外,還有很多其他比較常見的激活函式,
常見激活函式
激活函式(activation function)通過計算加權和并加上偏置來確定神經元是否應該被激活,大多數激活函式都是非線性的,所有
ReLU
最常用的激活函式是修正線性單元(Rectified linear unit,ReLU),提供了一種非常簡單的非線性變換,給定元素
x
x
x,ReLU函式被定義為該元素與
0
0
0的最大值:
ReLU
(
x
)
=
max
?
(
0
,
x
)
(5)
\text{ReLU}(x) = \max(0, x) \tag 5
ReLU(x)=max(0,x)(5)
ReLU函式通過將相應的激活值設為
0
0
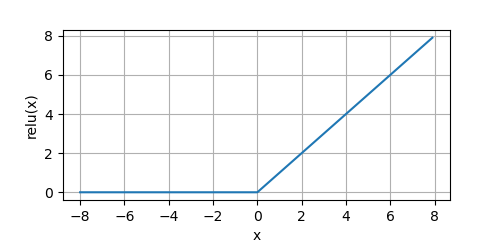
0,僅保留正元素并丟棄所有負元素,我們可以畫出函式的圖形感受一下:
from metagrad.functions import *
from metagrad.utils import plot
if __name__ == '__main__':
x = Tensor.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = relu(x)
plot(x.numpy(), y.numpy(), 'x', 'relu(x)', random_fname=True, figsize=(5, 2.5))
當輸入為負時,ReLU函式的導數為 0 0 0,當輸入為正時,ReLU函式的導數為 1 1 1,當輸入為 0 0 0時,我們讓其導數也為 0 0 0,
y.backward(Tensor.ones_like(x))
plot(x.numpy(), x.grad.numpy(), 'x', 'grad of relu', figsize=(5, 2.5))
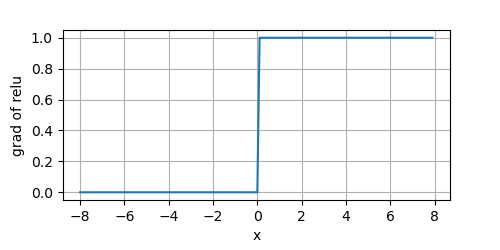
由于ReLU的簡單性,沒有包含 e x e^x ex,導致它的計算效率極高,同時它的梯度要么為 0 0 0,要么為 1 1 1,這使得優化變現得更好,減輕了困擾神經網路的梯度訊息問題,
ReLU導數的函式圖形如上圖所示,我們可以看到,在 x < 0 x < 0 x<0的一側,梯度值永遠是 0 0 0,因此,在反向傳播的程序中,可能有些神經元的權重不會被更新(因為導數為 0 0 0),這可能會導致永不激活的死節點(神經元),這個問題可以被ReLU的變種:Leaky ReLU解決,
Leaky ReLU
Leaky ReLU是ReLU的改進版本,主要用于解決上面跳到的死節點問題,通過給所有負值賦予一個小的正斜率來解決
Leaky ReLu
(
x
)
=
m
a
x
(
a
x
,
x
)
(6)
\text{Leaky ReLu}(x) = max(ax, x) \tag 6
Leaky ReLu(x)=max(ax,x)(6)
通常這里的
a
=
0.01
a=0.01
a=0.01,為了看出效果,在畫圖時讓
a
=
0.1
a=0.1
a=0.1,我們看一下它的圖形:
y = leaky_relu(x)
plot(x.numpy(), y.numpy(), 'x', 'leaky relu(x)', random_fname=True, figsize=(5, 2.5))
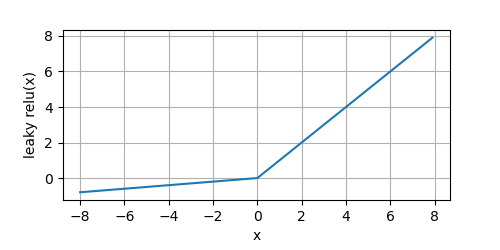
Leaky ReLU的優點與ReLU相同,同時對于負輸入,其導數也變成了一個非零值(即 a a a),
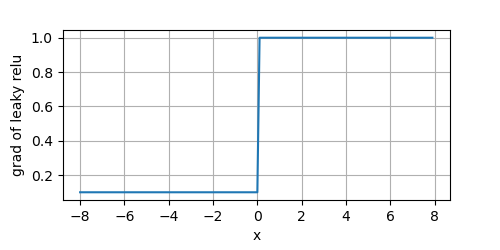
從上圖可以看到,對于 x < 0 x < 0 x<0的一側,它們也有非零的導數,不至于出現死節點,但是由于 a a a通常很小,導致在在此側的模型引數學習緩慢,
除了Leaky ReLU外,類似地還有兩種變體,分別是Parametric ReLU和Randomized Leaky ReLU,
Parametric ReLU稱為引數化的ReLU,即令Leaky ReLU中的 a a a變成了一個可學習的引數,
而Randomized Leaky ReLU讓 a a a取自一個連續均勻概率分布,
Exponential Linear Unit
ELU(Exponential Linear Unit)也是ReLU的一種變體,類似Leaky ReLU修改在
x
<
0
x < 0
x<0側的斜率,但在負區域不是一條直線,而是一條對數曲線,
ELU
(
x
)
=
max
?
(
0
,
x
)
+
min
?
(
0
,
α
?
(
exp
?
(
x
)
?
1
)
)
(7)
\text{ELU}(x) = \max(0,x) + \min(0, \alpha *(\exp(x)-1)) \tag 7
ELU(x)=max(0,x)+min(0,α?(exp(x)?1))(7)
通常
α
=
1
\alpha=1
α=1,我們畫出ELU的影像:
y = elu(x)
plot(x.numpy(), y.numpy(), 'x', 'elu(x)', random_fname=True, figsize=(5, 2.5))
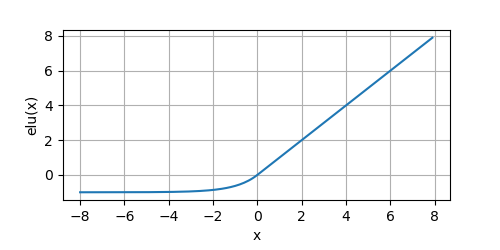
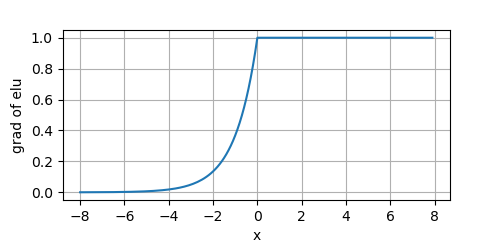
ELU在負值部分緩慢變得平滑,直到輸出等于 ? α -\alpha ?α,且 α α α是一個可調整的引數,它控制著ELU負值部分在何時飽和,但是引入了 e x e^x ex,其導數的影像為:
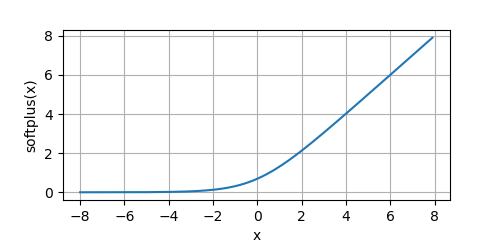
SoftPlus
SoftPlus函式與ReLU函式接近,但比較平滑,也是單邊抑制的,
SoftPlus
(
x
)
=
1
β
?
log
?
(
1
+
exp
?
(
β
?
x
)
)
(8)
\text{SoftPlus}(x) = \frac{1}{\beta} * \log(1 + \exp(\beta * x)) \tag 8
SoftPlus(x)=β1??log(1+exp(β?x))(8)
其中
β
\beta
β默認為
1
1
1,隨著
β
β
β的增加,該函式越來越像ReLU,
我們看一下默認情況下的函式影像:
y = softplus(x, beta=10)
plot(x.numpy(), y.numpy(), 'x', 'softplus(x)', random_fname=True, figsize=(5, 2.5))
當 β = 10 \beta=10 β=10時,我們看一下函式影像:
y = softplus(x, beta=10)
plot(x.numpy(), y.numpy(), 'x', r'softplus(x) with $\beta$ = 10', random_fname=True, figsize=(5, 2.5))
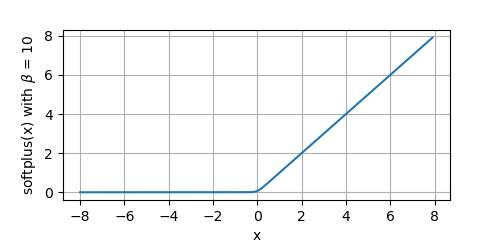
其導數為:
d
d
x
Swish
(
x
)
=
d
d
x
(
1
β
log
?
(
1
+
exp
?
(
β
x
)
)
)
=
1
β
exp
?
(
β
x
)
β
1
+
exp
?
(
β
x
)
=
1
1
+
exp
?
(
?
β
x
)
=
σ
(
β
x
)
\begin{aligned} \frac{d}{dx}\text{Swish}(x) &= \frac{d}{dx} \left(\frac{1}{\beta} \log(1 + \exp(\beta x)) \right) \\ &= \frac{1}{\beta} \frac{\exp(\beta x) \beta}{1 + \exp(\beta x)}\\ &= \frac{1}{1 + \exp(-\beta x)} \\ &= \sigma(\beta x) \end{aligned}
dxd?Swish(x)?=dxd?(β1?log(1+exp(βx)))=β1?1+exp(βx)exp(βx)β?=1+exp(?βx)1?=σ(βx)?
當
β
=
1
\beta=1
β=1,其導數就是
σ
(
x
)
\sigma(x)
σ(x),我們來看下其導數影像:
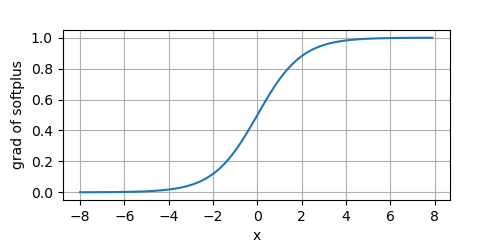
Swish
Swish在更深層次的模型上顯示出比ReLU更好的性能,Swish的輸入從負無窮到正無窮,函式定義為
Swish
=
x
?
σ
(
x
)
=
x
1
+
exp
?
(
?
x
)
(9)
\text{Swish} = x * \sigma(x) = \frac{x}{1 + \exp(-x)} \tag 9
Swish=x?σ(x)=1+exp(?x)x?(9)
相當于是對輸入
x
x
x進行了門控(通過
σ
\sigma
σ函式),我們看一下它的影像:
y = swish(x)
plot(x.numpy(), y.numpy(), 'x', 'swish(x)', random_fname=True, figsize=(5, 2.5))
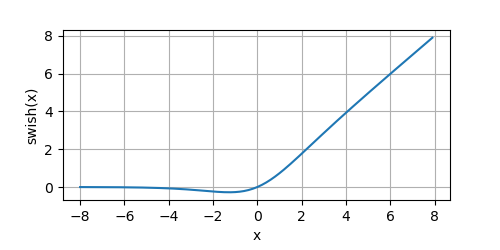
它的曲線都是光滑的,且處處可導,當 x x x增大時,函式值趨于無窮大;當 x x x減小時,函式值趨于常數,
Swish函式的導數為下面的公式:
d
d
x
Swish
(
x
)
=
d
d
x
x
σ
(
x
)
=
σ
(
x
)
+
σ
(
x
)
′
x
=
σ
(
x
)
+
σ
(
x
)
(
1
?
σ
(
x
)
)
x
\begin{aligned} \frac{d}{dx}\text{Swish}(x) &= \frac{d}{dx} x \sigma(x) \\ &= \sigma(x) + \sigma(x)^\prime x \\ &= \sigma(x) + \sigma(x)(1 - \sigma(x)) x \end{aligned}
dxd?Swish(x)?=dxd?xσ(x)=σ(x)+σ(x)′x=σ(x)+σ(x)(1?σ(x))x?
其導數的影像為:
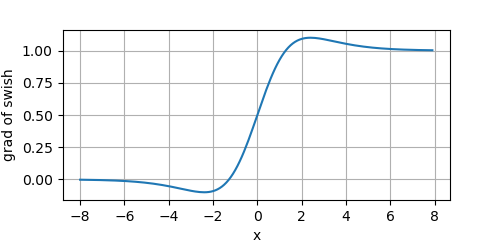
Swish的特性:
-
無上邊界:不像sigmoid和tanh函式,Swish沒有上邊界的,因為它避免了在接近零的梯度中緩慢的訓練時間——像sigmoid或tanh這樣的函式是有界的,因此需要小心地初始化網路,以保持在這些函式的界限內,
-
曲線的平滑性:平滑性在泛化和優化中起著重要的作用,與ReLU不同,Swish是一個平滑的函式,這使得它對初始化權值和學習率不那么敏感,
-
有下邊界:這有助于增強正則化效果( x x x左側慢慢接近于 0 0 0,一定程度過濾掉一部分資訊,起到正則化的效果),
Sigmoid
Sigmoid函式將輸入壓縮為區間
(
0
,
1
)
(0,1)
(0,1)上的輸出,因此,Sigmoid函式通常稱為擠壓函式(squashing function):
sigmoid
(
x
)
=
1
1
+
exp
?
(
?
x
)
(10)
\text{sigmoid}(x) = \frac{1}{1 + \exp(-x)} \tag {10}
sigmoid(x)=1+exp(?x)1?(10)
當我們想要將輸出看成二分類的概率時,sigmoid此時最常用,然而,sigmoid在隱藏層中較少使用,它通常被更簡單、更容易訓練的ReLU所取代,
下面我們畫出sigmoid函式,
y = sigmoid(x)
plot(x.numpy(), y.numpy(), 'x', 'sigmoid(x)', random_fname=True, figsize=(5, 2.5))
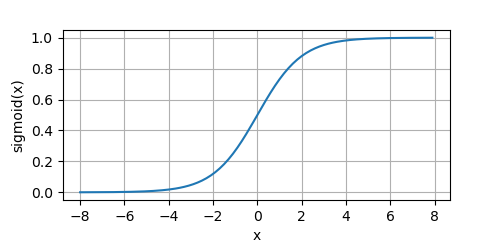
其導數計算如下:
d
d
x
sigmoid
(
x
)
=
d
d
x
1
1
+
e
?
x
=
0
×
(
1
+
e
?
x
)
?
1
×
(
1
+
e
?
x
)
′
(
1
+
e
?
x
)
2
=
?
(
?
e
?
x
)
(
1
+
e
?
x
)
2
=
1
+
e
?
x
?
1
(
1
+
e
?
x
)
2
=
1
1
+
e
?
x
?
1
(
1
+
e
?
x
)
2
=
1
1
+
e
?
x
(
1
?
1
1
+
e
?
x
)
=
σ
(
x
)
(
1
?
σ
(
x
)
)
\begin{aligned} \frac{d}{dx}\text{sigmoid}(x) &= \frac{d}{dx} \frac{1}{1 + e^{-x}} \\ &= \frac{0 \times (1+e^{-x}) - 1\times (1+e^{-x})^\prime}{(1 + e^{-x})^2} \\ &= \frac{- (-e^{-x})}{(1+e^{-x})^2} \\ &= \frac{1 + e^{-x} - 1}{(1+e^{-x})^2} \\ &= \frac{1}{1 + e^{-x}} - \frac{1}{(1 + e^{-x})^2} \\ &= \frac{1}{1 + e^{-x}} \left( 1 - \frac{1}{1 + e^{-x}} \right) \\ &= \sigma(x)(1 - \sigma(x)) \end{aligned}
dxd?sigmoid(x)?=dxd?1+e?x1?=(1+e?x)20×(1+e?x)?1×(1+e?x)′?=(1+e?x)2?(?e?x)?=(1+e?x)21+e?x?1?=1+e?x1??(1+e?x)21?=1+e?x1?(1?1+e?x1?)=σ(x)(1?σ(x))?
其導數的影像為:
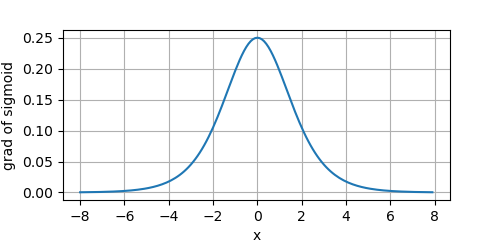
在深層網路中,Sigmoid存在三個問題:
- 飽和的神經元會讓梯度消失,即在較大的正數或負數作為輸入的時候,梯度就會變成零,使得神經元基本不能更新,
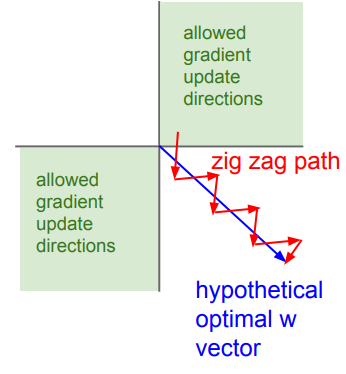
- 其輸出不是以 0 0 0為中心的,而是 0.5 0.5 0.5,我們知道 d L d w = d L d z x \frac{dL}{dw} = \frac{dL}{dz}x dwdL?=dzdL?x,在深層網路中,由于上一層使用的是Sigmoid激活函式,導致該層的輸入都是正數,即該層 w w w的梯度取決于 d L d z \frac{dL}{dz} dzdL?,要么都是正的,要么都是負的,出現了zig zag問題,如下圖所示,假設最佳更新路線是藍線所示,由于zig zag問題,使其優化變成緩慢,
- 指數計算耗時
Tanh
tanh是sigmoid函式的變種,它的函式值變成范圍從
?
1
-1
?1到
+
1
+1
+1,即變成了以
0
0
0為中心的,
tanh
?
(
x
)
=
e
x
?
e
?
x
e
x
+
e
?
x
(11)
\tanh(x) = \frac{e^x - e^{-x}}{e^x + e^{-x}} \tag{11}
tanh(x)=ex+e?xex?e?x?(11)
我們來畫出該函式的影像:
y = tanh(x)
plot(x.numpy(), y.numpy(), 'x', 'tanh(x)', random_fname=True, figsize=(5, 2.5))
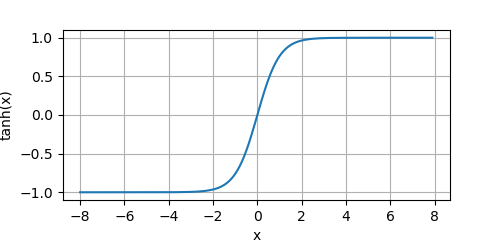
tanh函式具有平滑可微性,和將離群值映射到均值的良好性質,
為什么說tanh函式是sigmoid函式的變種呢?我們來推導一下:
tanh
?
(
x
)
=
e
x
?
e
?
x
e
x
+
e
?
x
=
e
x
+
e
?
x
?
e
?
x
?
e
?
x
e
x
+
e
?
x
=
1
+
?
2
e
?
x
e
x
+
e
?
x
=
1
?
2
e
2
x
+
1
=
1
?
2
σ
(
?
2
x
)
=
1
?
2
(
1
?
σ
(
2
x
)
)
=
1
?
2
+
2
σ
(
2
x
)
=
2
σ
(
2
x
)
?
1
\begin{aligned} \tanh(x) &= \frac{e^x - e^{-x}}{e^x + e^{-x}} \\ &= \frac{e^x + e^{-x} - e^{-x} - e^{-x} }{e^x + e^{-x}} \\ &= 1 + \frac{-2e^{-x}}{e^x + e^{-x}} \\ &= 1 - \frac{2}{e^{2x}+ 1}\\ &= 1 - 2\sigma(-2x) \\ &= 1 - 2(1 - \sigma(2x)) \\ &= 1 - 2 + 2\sigma(2x) \\ &= 2\sigma(2x) - 1 \end{aligned}
tanh(x)?=ex+e?xex?e?x?=ex+e?xex+e?x?e?x?e?x?=1+ex+e?x?2e?x?=1?e2x+12?=1?2σ(?2x)=1?2(1?σ(2x))=1?2+2σ(2x)=2σ(2x)?1?
因此,我們可以看到tanh只是sigmoid函式的縮放版本,
tanh函式的導數是:
d
d
x
tanh
?
(
x
)
=
d
d
x
e
x
?
e
?
x
e
x
+
e
?
x
=
(
e
x
?
e
?
x
)
′
(
e
x
+
e
?
x
)
?
(
e
x
?
e
?
x
)
(
e
x
+
e
?
x
)
′
(
e
x
+
e
?
x
)
2
=
(
e
x
+
e
?
x
)
2
?
(
e
x
?
e
?
x
)
2
(
e
x
+
e
?
x
)
2
=
1
?
(
e
x
?
e
?
x
e
x
+
e
?
x
)
2
=
1
?
tanh
?
2
(
x
)
\begin{aligned} \frac{d}{dx}\tanh(x) &= \frac{d}{dx} \frac{e^x - e^{-x}}{e^x + e^{-x}} \\ &= \frac{(e^x - e^{-x})^\prime(e^x + e^{-x}) -(e^x - e^{-x})(e^x + e^{-x})^\prime}{(e^x + e^{-x})^2} \\ &= \frac{(e^x + e^{-x})^2 - (e^x - e^{-x})^2}{(e^x + e^{-x})^2} \\ &= 1 - \left ( \frac{e^x - e^{-x}}{e^x + e^{-x}} \right)^2 \\ &= 1 - \tanh^2(x) \end{aligned}
dxd?tanh(x)?=dxd?ex+e?xex?e?x?=(ex+e?x)2(ex?e?x)′(ex+e?x)?(ex?e?x)(ex+e?x)′?=(ex+e?x)2(ex+e?x)2?(ex?e?x)2?=1?(ex+e?xex?e?x?)2=1?tanh2(x)?
其中
d
d
x
e
x
=
e
x
\frac{d}{dx} e^x = e^x
dxd?ex=ex;
d
d
x
e
?
x
=
?
e
?
x
\frac{d}{dx}e^{-x} = - e^{-x}
dxd?e?x=?e?x
其導數影像如下所示:
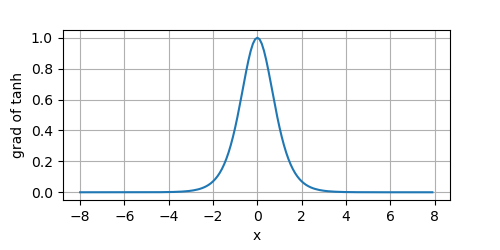
可以看到,當輸入接近于 0 0 0時,tanh函式的導數接近于最大值 1 1 1,而輸入在任一方向上越遠離 0 0 0點,導數越接近 0 0 0,
Tanh的缺點類似Sigmoid,不過它是以 0 0 0為中心的,避免了zig zag問題,
如何選擇激活函式
我們看了這么多激活函式,到底要如何選擇呢?
在深層網路中,首先要嘗試ReLU,它具有速度快的優點,如果效果欠佳;
那么嘗試Leaky ReLU;
或者tanh這種以零為中心的;
另外,在RNN中常用sigmoid或tanh,作為門控或概率值,
完整代碼
完整代碼筆者上傳到了程式員最大交友網站上去了,地址: 👉 https://github.com/nlp-greyfoss/metagrad
References
- DIVE INTO DEEP LEARNING
- Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423348.html
標籤:AI