摘要
本文以MNIST手寫數字識別任務為例,使用FPGA搭建了一個LSTM網路加速器,并選取MNIST資料集中的10張圖片,通過vivado軟體進行仿真驗證,實驗結果表明,本文設計的基于FPGA的LSTM網路加速器可以完成圖片分類任務,其準確率為80%(20張圖片,4張分類錯誤),本文主要分為四部分,第一章為LSTM硬體加速器的原理介紹,第二章為軟體部分的程式設計思路,第三章為FPGA硬體部分的設計思路,本文所設計的LSTM硬體加速器的完整的工程檔案已上傳,并在文末對工程檔案進行了簡單的介紹,
目錄
- 摘要
- 一、基于FPGA的LSTM加速器設計原理
- 1. 長短期神經網路(Long Short Term Memory,LSTM)原理
- 2. 對LSTM網路模型中權值矩陣的剪枝(Top-k剪枝)
- 3. 對LSTM網路模型中權值的量化
- 3.1 對數量化原理
- 3.2 線性量化原理
- 4. 非線性激活函式近似法
- 二、Pytorch框架下的LSTM實作手寫數字圖片分類任務(MNIST資料集)
- 1. 分類器模型的搭建
- 2. 對分類器的剪枝壓縮(Top-k剪枝)
- 3. 非線性激活函式近似法的程式設計
- 4. 對數量化的程式設計
- 5. 線性量化的程式設計
- 6. 壓縮后模型的資料匯入FPGA的程式介紹
- 三、Xilinx FPGA上的LSTM硬體加速器設計
- 四、工程檔案介紹
- 參考資料
一、基于FPGA的LSTM加速器設計原理
基于FPGA的LSTM加速器設計流程如下所示:
-
- 在Pytorch框架下搭建LSTM網路模型,并用GPU進行模型訓練;
-
- 對訓練好的LSTM網路模型進行剪枝壓縮,并通過重訓練恢復精度;
-
- 使用分段線性函式替代非線性激活函式,并通過重訓練恢復精度;
-
- 對模型的權值進行量化,并匯入到FPGA的ROM資源中;
-
- 在FPGA上搭建LSTM硬體加速器;
-
- 對搭建的硬體加速器進行驗證評估;
本章主要對各流程中的原理部分進行介紹,本章盡可能的解釋了FPGA實作LSTM硬體加速器所需的原理知識,詳細的介紹可以參考文末給出的參考資料,
1. 長短期神經網路(Long Short Term Memory,LSTM)原理
傳統回圈神經網路(Recuurent Nerual Network,RNN)通過將上一時間步的輸出
h
t
h_{t}
ht?作為輸入的一部分,和當前輸入
x
t
x_{t}
xt?一起作為輸入資訊輸入到網路中,從而能夠捕獲序列信號的特性,然而,傳統RNN存在梯度消失和梯度下降的問題,
而LSTM通過引入記憶細胞機制緩解了傳統回圈神經網路(Recuurent Nerual Network,RNN)梯度消失和梯度爆炸的問題,
LSTM的運算式如下所示:
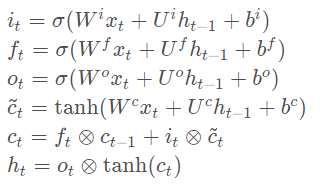
其中
i
t
i_{t}
it?為輸入門,取值范圍為(0~1),表示更新記憶細胞的程度,
f
t
f_{t}
ft?為遺忘門,取值范圍為(0~1),表示上一時間步的記憶細胞
c
t
?
1
c_{t-1}
ct?1?的剔除程度,
c
~
t
\tilde{c}_{t}
c~t?表示待更新入記憶細胞的資訊,
o
t
o_{t}
ot?為輸出門,決定記憶細胞與輸出資訊的關系,LSTM通過門控單元,能及時的剔除記憶細胞中的無用資訊,并及時準確地更新資訊,從而能緩解傳統RNN的梯度消失和梯度爆炸的問題,但也因此引入了大量的引數,導致其難以直接運行在存盤、計算資源受限的平臺,例如FPGA,
2. 對LSTM網路模型中權值矩陣的剪枝(Top-k剪枝)
由于神經網路具有很強的魯棒性,即使被大幅度的壓縮,也能保證其準確率,
E
L
S
T
M
[
1
]
ELSTM^{[1]}
ELSTM[1]中提出了一種top-
k
k
k剪枝方案,該剪枝方案將權值矩陣的每個相鄰的c個權值分為一組,每組只保留前k個絕對值最大的非零權值,其余權值均設為0,
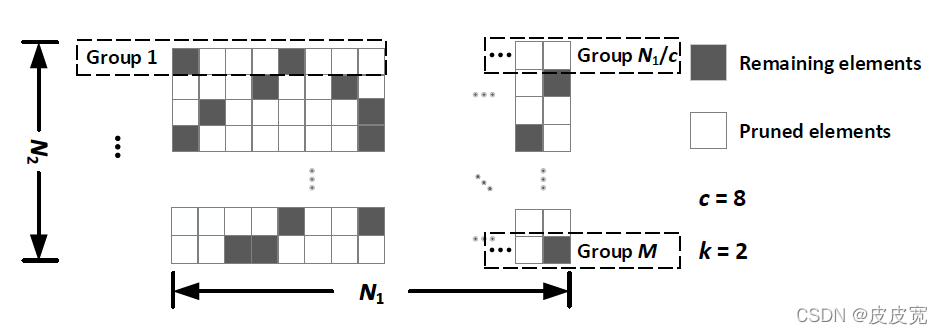
c=8,k=2的top-
k
k
k剪枝示意圖如上所示,存盤top-
k
k
k剪枝方案壓縮后的權值矩陣時,只需要3bits(
l
o
g
2
c
=
3
log_{2}c = 3
log2?c=3)即可表示該非零權值的位置資訊,
3. 對LSTM網路模型中權值的量化
除了通過剪枝壓縮模型外,還可以通過量化來壓縮模型,由于GPU訓練的模型為32位浮點數,而FPGA處理資料大多是定點數,因此需要對模型進行量化,常用的量化方式用兩種,一種是線性量化,一種是對數量化,
3.1 對數量化原理
對數量化的運算式如下所示:
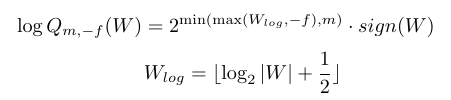
其中m,f分別代表量化后的整數位位數和小數位位數,這種量化方式量化后的數為2的冪次方,如0011就表示
2
?
3
2^{-3}
2?3,而與2的冪次方的乘法運算,可以用移位運算替代,如
a
?
2
?
b
=
a
>
>
>
b
a * 2^{-b} = a >>> b
a?2?b=a>>>b,
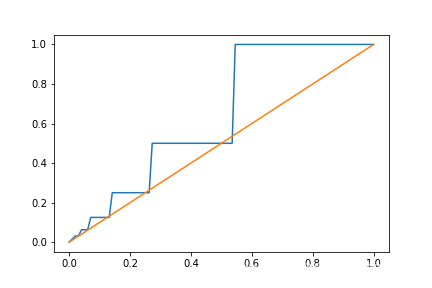
如圖所示,藍色線表示函式
y
=
l
o
g
Q
m
,
?
f
(
x
)
y = log Q_{m,-f}(x)
y=logQm,?f?(x),橘色線條表示函式
y
=
x
y=x
y=x,由圖可知,對數量化對數值較大的數,量化產生的誤差較大,因此,只被用于量化LSTM網路的權值矩陣引數,
3.2 線性量化原理
線性量化的運算式如下所示:
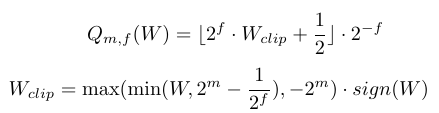
其中m,f分別代表量化后的整數位位數和小數位位數,
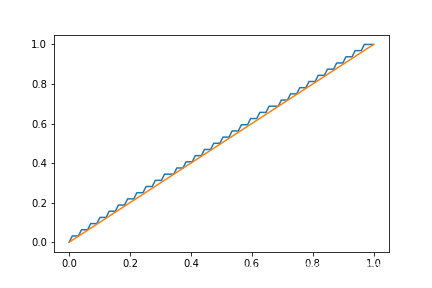
如圖所示,藍色線表示函式 y = Q m , f ( x ) y = Q_{m, f}(x) y=Qm,f?(x),橘色線條表示函式 y = x y=x y=x,線性量化的誤差較穩定,因此輸入、輸出、中間運算結果均采用線性量化,
4. 非線性激活函式近似法
LSTM中的
σ
\sigma
σ和
tanh
?
\tanh
tanh函式,均為帶有
e
x
e^{x}
ex的指數運算函式,FPGA難以直接實作這種復雜函式,常用的解決方案是用分段線性函式替代這兩個非線性激活函式,如下所示:
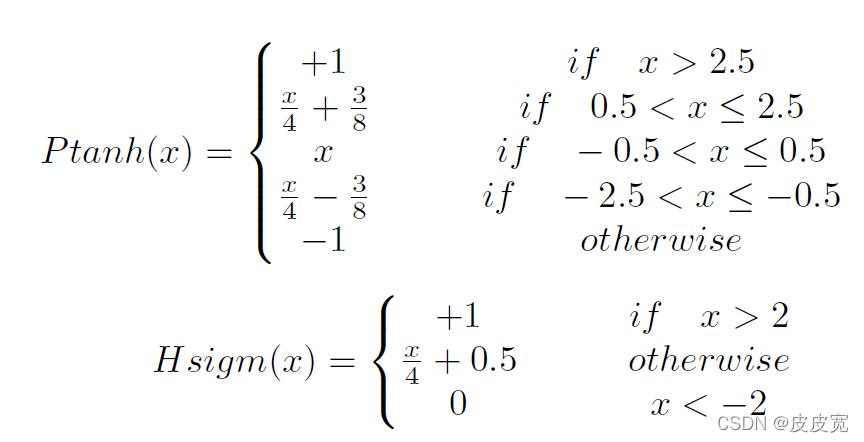
為了便于FPGA的實作,本文采用Ptanh函式替代
t
a
n
h
tanh
tanh,用
H
s
i
g
m
Hsigm
Hsigm替代
σ
\sigma
σ,
二、Pytorch框架下的LSTM實作手寫數字圖片分類任務(MNIST資料集)
本章主要對軟體部分的設計進行介紹,并對關鍵代碼進行解釋,完整代碼參考工程檔案,
1. 分類器模型的搭建
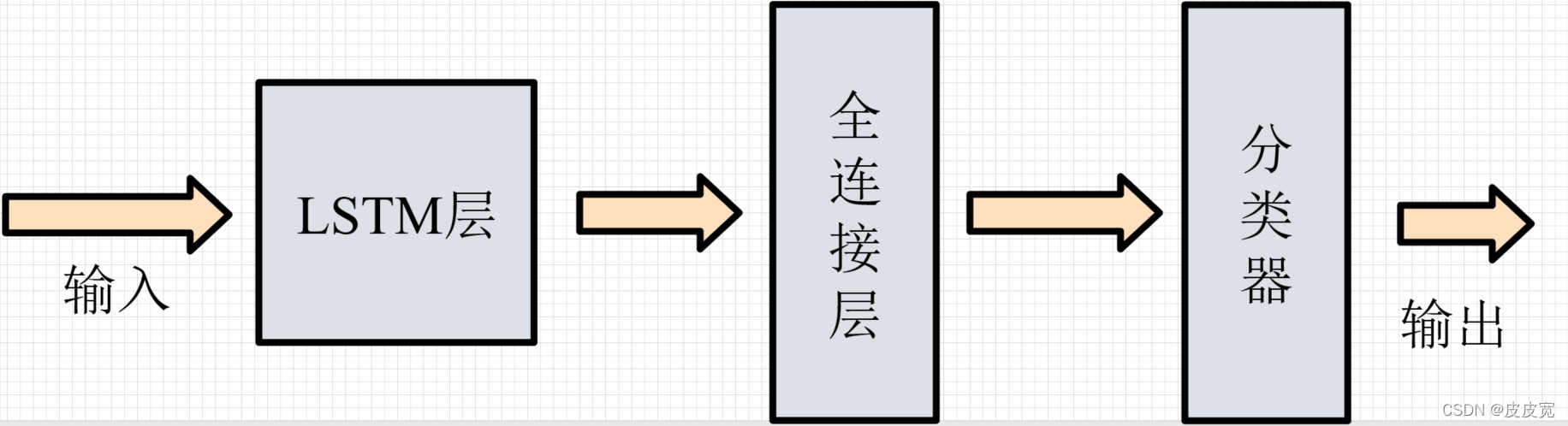
本文搭建的LSTM網路模型包含一個輸入維度為28,隱藏層維度28的單層單向的LSTM層,一個輸入維度28,輸出維度10的全連接層(Fully Connect,FC),以及一個4bit輸出的分類器(輸出最大值的位置資訊,0~9),
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.rnn = LSTM(28, 28, num_layers=1,
bias=True, return_sequences=True, grad_clip=None)
self.fc = nn.Linear(28, 10)
def forward(self, x):
zeros = Variable(torch.zeros(x.size()[0], 28, device=torch.device("cuda")))
initial_states = [(zeros, zeros)]
x = x.squeeze(1)
hidden, _ = self.rnn(x, initial_states) #LSTM層
x = self.fc(hidden[:, -1, :]) #全連接層
return x
net = Net()
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) #分類器
由于官方未提供(也可能是我沒找到)LSTM對數量化的API,因此本文選用的LSTM為自定義的程式檔案(詳見工程檔案),
2. 對分類器的剪枝壓縮(Top-k剪枝)
訓練好的網路模型難以直接運行在資源受限的平臺,因此需要剪枝壓縮,top- k k k剪枝壓縮代碼如下所式:
def topk(para, k):
c = torch.zeros(para.size()[0], para.size()[1],dtype = torch.int)
l = int(para.size()[1]/7)
parameter = torch.abs(para)
_, b = torch.topk(parameter[:,:7], k, 1, largest = True)
for i in range(1,l):
_, b1 = torch.topk(parameter[:,i*7:(i+1)*7], k, 1, largest = True)
b1 = b1 + i * 7
b = torch.cat((b,b1),dim=1)
for j in range(c.size()[0]):
c[j, b[j, :]] = 1
return c
由于資訊維度為28,因此本文選取每7個權值為一組,每組保留k個權值,本文選取的k為4,通過函式topk生成掩膜矩陣,再根據pytorch提供的API進行剪枝訓練,
c1 = topk(net.rnn.cell0.weight_ix, 4) #根據W^{i}生成掩膜矩陣
class FooBarPruningMethod1(prune.BasePruningMethod): #呼叫剪枝的API,更改掩膜矩陣
"""Prune every other entry in a tensor
"""
PRUNING_TYPE = 'unstructured'
def compute_mask(self, t, default_mask):
mask = c1
return mask
FooBarPruningMethod1.apply(net.rnn.cell0, 'weight_ix') #對權值矩陣W^{i}進行剪枝
權值矩陣 W i W^{i} Wi的剪枝程式設計如上所示,以此類推,對LSTM其他權值矩陣,及FC層的權值矩陣進行剪枝,
3. 非線性激活函式近似法的程式設計
Ptanh和Hsigm函式如下所示,本文將剪枝后的網路中的非線性激活函式用這兩個分段線性函式進行替代,并通過重訓練恢復模型精度,
def Ptanh(inn):
we1 = inn < -2.5
we2 = (inn >= -2.5) & (inn < -0.5)
we3 = (inn >= -0.5) & (inn < 0.5)
we4 = (inn >= 0.5) & (inn < 2.5)
we5 = inn >= 2.5
out1 = -1
out2 = 0.25 * inn - 0.375
out3 = inn
out4 = 0.25 * inn + 0.375
out5 = 1
out = out1 * we1 + out2 * we2 + out3 * we3 + out4 * we4 + out5 * we5
return out
def Hsigm(inn)
out = torch.clip(0.25 * inn + 0.5, 0, 1, out=None)
return out
4. 對數量化的程式設計
def log2_Q(a):
a = a.to('cpu')
b = a.detach().numpy()
e = np.sign(b)
b = np.clip(np.round(np.log2(np.fabs(b))+0.4),-7,0) #得到最接近原始a的2的冪次方,不改變a的其他屬性,因此只使用data屬性
b = np.power(2,b) * e
a.data = torch.from_numpy(b).data
return a
對數量化的函式如上所示,權值被量化為4bits數,詳見[1],然而量化后的權值矩陣不能再訓練,因此本文先量化的候選記憶細胞的權值矩陣( W c W^{c} Wc、 U c U^{c} Uc),之后對其他剩余的權值進行重新訓練;再量化輸出門和遺忘門的權值矩陣( W o W^{o} Wo、 U o U^{o} Uo、 W f W^{f} Wf、 U f U^{f} Uf),并對其他剩余的權值進行訓練,最后再量化輸入門的權值矩陣( W i W^{i} Wi、 U i U^{i} Ui),
5. 線性量化的程式設計
def Q(a): #輸入訓練引數,輸出量化后的訓練引數
a = a.to('cpu')
b = a.detach().numpy() #由于a是訓練引數,requires_grad為True,因此不能直接用numpy函式操作,需轉換
b = np.clip(b,-0.875,0.875) #0.875是1 - (1/2)^3
b = np.round(b * 8 + 0.5) / 8
a.data = torch.from_numpy(b).data #得到最接近原始a的定點數
return a
權值被量化為4bits數,詳見[1],本文對FC層的權值矩陣進行線性量化,將其量化為4bits數,
6. 壓縮后模型的資料匯入FPGA的程式介紹
由于FPGA中存盤和運算為二進制補碼形式,因此需要將權值轉換為補碼形式,轉換程式如下所示:
def p_d2b(n, m, f): #將一個10進制正數轉換為一個2進制數,保留m位整數,f位小數,首位符號位
b = []
x = 2
n = n * np.power(2, f)
n = int(n)
while True:
s = n // x
y = n % x
b = b + [y]
if s == 0:
break
n = s
b.reverse()
if(len(b) > (m+f)):
for i in range(m+f):
b[i] = 1
b = b[:m+f]
elif(len(b) < (m+f)):
for i in range(m+f-len(b)):
b.insert(0,0)
b.insert(0,0)
a = [str(i) for i in b ]
return a
def n_d2b(n, m, f): #求一個10進制負數轉換為一個2進制補碼形式,保留m位整數,f位小數,首位符號位
n = -1 * n
b = p_d2b(n, m, f)
b[0] = '1'
flag = 1
for i in range(len(b)-1,0,-1):
if b[i]== '1' and flag == 1:
b[i] = '1'
flag = 0
elif b[i] == '0' and flag == 1:
b[i] = '0'
flag = 1
elif b[i] == '0':
b[i] = '1'
else:
b[i] = '0'
a = [str(i) for i in b ]
return a
def d2b(n, m, f): #求一個數n的補碼,保留m位整數,n位小數,首位符號位
if n < 0:
c = n_d2b(n, m, f)
else:
c = p_d2b(n, m, f)
return c
對數量化后的數的存盤與線性量化不同,如0.125( 2 ? 3 2^{-3} 2?3),應該存盤為0011,表示右移3位即可完成乘法操作,對數量化后的資料的二進制生成函式如下所示:
def logd2b(n, f):
if n > 0:
n = np.log2(n)
n = np.floor(-1 * n + 0.5)
if n >= np.power(2,f):
n = np.power(2,f)
a = p_d2b(n,f,0)
else:
n = -1 * n
n = np.log2(n)
n = np.floor(-1 * n + 0.5)
if n >= np.power(2, f):
n = np.power(2, f)
a = p_d2b(n, f, 0)
a[0] = '1'
return a
通過以上方式生成FPGA的ROM可加載的coe檔案,將GPU訓練出的網路模型引數匯入到FPGA中,
def output_file_log(weight,name):
name = 'coe/'+name
f1 = open(str(name)+"_data.coe","a")
f2 = open(str(name)+"_index.coe","a")
data =';\nmemory_initialization_radix = 2;\nmemory_initialization_vector='
f1.writelines(data)
f2.writelines(data)
para = weight.numpy()
for i in range(para.shape[0]):
f1.writelines('\n')
f2.writelines('\n')
for j in range(para.shape[1]):
if para[i,j]!=0:
data = logd2b(para[i,j], 3)
index = p_d2b(j%7,3,0)[1:] #topk剪枝后的非零權值需要3bit表示其在分組中的位置資訊
f1.writelines(data)
f2.writelines(index)
f1.writelines(';')
f1.close()
f2.writelines(';')
f2.close()
def output_file_Q(weight,name):
name = 'coe/' + name
f1 = open(name + "_data.coe", "a")
f2 = open(name + "_index.coe", "a")
data = ';\nmemory_initialization_radix = 2;\nmemory_initialization_vector='
f1.writelines(data)
f2.writelines(data)
para = weight.numpy()
for i in range(para.shape[0]):
f1.writelines('\n')
f2.writelines('\n')
for j in range(para.shape[1]):
if para[i, j] != 0:
data = d2b(para[i, j], 2,13)
index = p_d2b(j % 7, 3, 0)[1:]#topk剪枝后的非零權值需要3bit表示其在分組中的位置資訊
f1.writelines(data)
f2.writelines(index)
f1.writelines(';')
f1.close()
f2.writelines(';')
f2.close()
三、Xilinx FPGA上的LSTM硬體加速器設計
LSTM整體框架如圖所示:
其中LSTM層的結構如下所示:
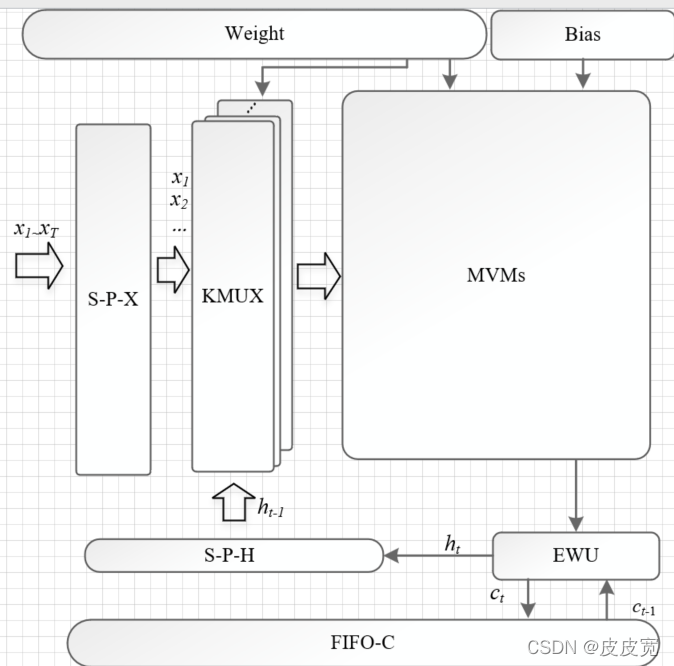
輸入資料經過S-P-X轉換為多維向量,和非零權值的位置資訊一起送入KMUX單元進行篩選,篩選后的非零權值和輸入資訊在MVMs模塊中完成矩陣乘加運算,并在EWU模塊中完成激活,點乘等運算,計算出的記憶細胞的值存盤在FIFO-C中,輸出資訊
h
t
h_{t}
ht?則存盤在S-P-H中,以作為下一個時間步的輸入,全連接層和LSTM的架構大體相似,
輸入‘4’的圖片,仿真結果如圖所示,結果正確,
硬體部分沒有太多要說的,需要注意的有如下幾點:
-
- 位寬問題:如果整數位位寬設定太少,會出現溢位,小數位位寬較少,則會截斷一些資訊,從而導致誤差,因此中間結果的位寬,需要根據實際情況進行調整;
-
- 補碼的移位運算:本文將LSTM的權值矩陣量化為2的冪次方,從而可以用移位運算來替代乘法運算,可有一個問題,比如負數補碼的移位,直接使用有符號的移位運算,出來是錯的,比如一個1符號位,3整數位的數1111(-1),右移4位后是1111(-1,帶符號的右移,補充符號位),而這并不是我們想要的結果,我們想要的是-1右移4位是-0.0625,截斷后位0,而不是依然-1,而原碼的移位則運算正確,因此,本文LSTM的乘法運算(用移位運算替代),先將輸入轉換為原碼形式(C2t模塊),進行移位操作后,再轉換為補碼形式(t2c模塊),
-
- 其余的比較復雜的就是時序了,需要慢慢的捋,完整工程檔案已上傳,沒有積分的可以評論區留郵箱發,
四、工程檔案介紹
完整工程檔案:基于FPGA的LSTM加速器設計(MNIST資料集為例)
- python (軟體代碼)
-
- 1-MNIST-LSTM.py (初始網路模型)
-
- 2-MNIST-LSTM.py (top-k剪枝)
-
- 3-MNIST-LSTM-topk-linear.py (分段線性函式替代非線性函式)
-
- 4.5.6.7.8.9.10.11的py檔案為量化程式
-
- 12-output-weight.py (權值匯出函式)
-
- 13-out-img.py(圖片資料匯出程式)
- FPGA (硬體代碼)
-
- 其中MNIST為頂層模塊,Test_MNIST為仿真驗證程式
參考資料
- ELSTM(topk剪枝)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423349.html
標籤:AI