一、Pulsar 介紹
Apache Pulsar 是 Apache 軟體基金會的頂級專案,是下一代云原生分布式訊息流平臺,集訊息、存盤、輕量化函式式計算為一體,采用計算與存盤分離架構設計,支持多租戶、持久化存盤、多機房跨區域資料復制,具有強一致性、高吞吐、低延時及高可擴展性等流資料存盤特性,
Pulsar 的關鍵特性如下:
- 是下一代云原生分布式訊息流平臺,
- Pulsar 的單個實體原生支持多個集群,可跨機房在集群間無縫地完成訊息復制,
- 極低的發布延遲和端到端延遲,
- 可無縫擴展到超過一百萬個 topic,
- 簡單的客戶端 API,支持 Java、Go、Python 和 C++,
- 主題的多種訂閱模式(獨占、共享和故障轉移),
- 通過 Apache BookKeeper 提供的持久化訊息存盤機制保證訊息傳遞 ,
- 由輕量級的 serverless 計算框架 Pulsar Functions 實作流原生的資料處理,
- 基于 Pulsar Functions 的 serverless connector 框架 Pulsar IO 使得資料更易移入、移出 Apache Pulsar,
- 分層式存盤可在資料陳舊時,將資料從熱存盤卸載到冷/長期存盤(如S3、GCS)中,
二、什么是云原生
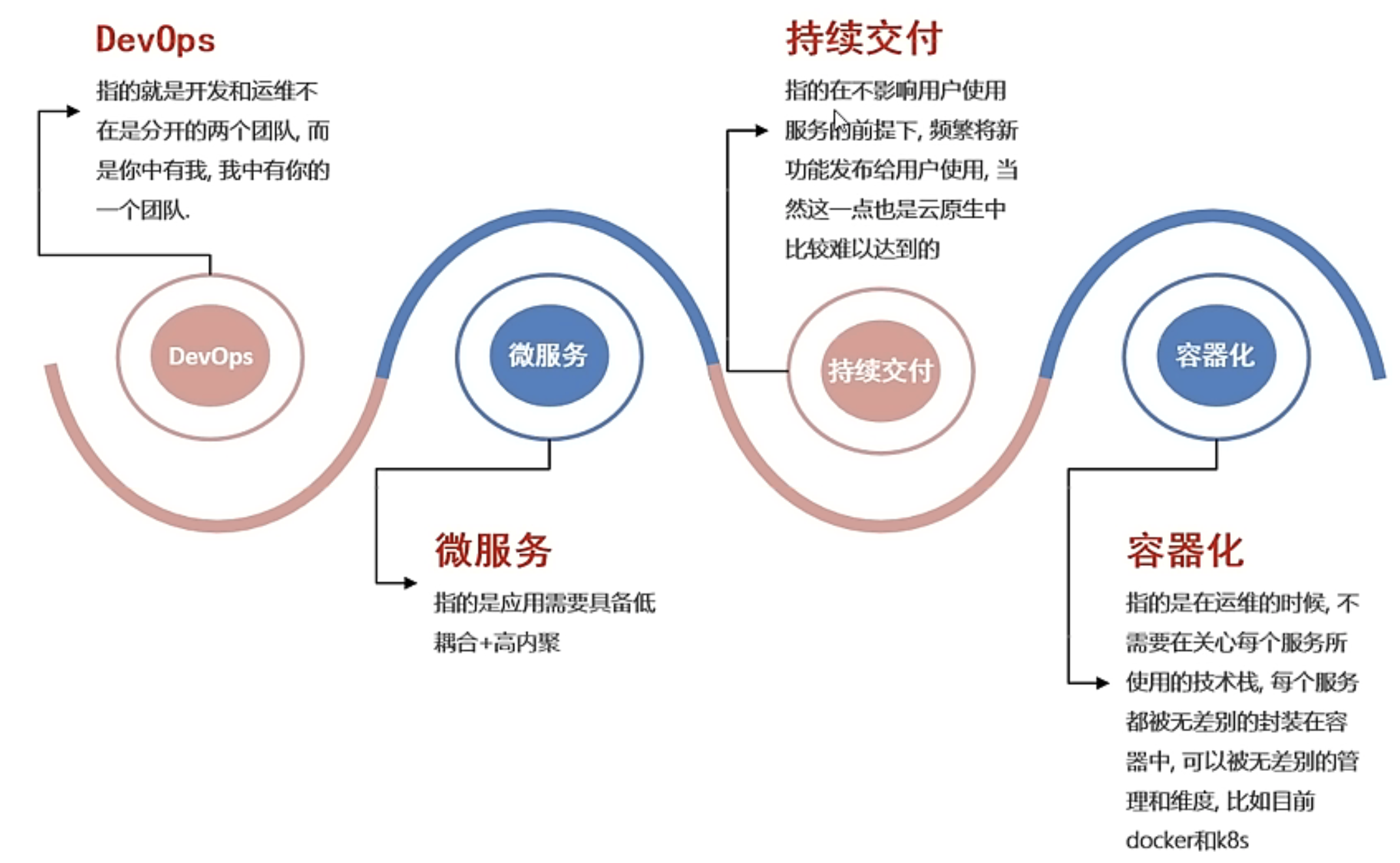
既然說 Pulsar 是下一代云原生分布式訊息流平臺,那我們得知道什么是云原生吧,
云原生的概念是 2013 年 Matt Stine 提出的,到目前為止,云原生的概念發生了多次變更,目前最新對云原生的定義為:DevOps + 持續交付 + 微服務 + 容器,
而符合云原生架構的應用程式是:采用開源堆疊(k8s + docker)進行容器化,基于微服務架構提高靈活性和可維護性,借助敏捷方法、DevOps 支持持續迭代和運維自動化,利用云平臺設施實作彈性伸縮、動態調度、優化資源利用率,
三、核心概念
3.1 Messages(訊息)
| Component | Description |
|---|---|
| Value / data payload | 訊息攜帶的資料,所有 Pulsar 的訊息攜帶原始 bytes,但是訊息資料也需要遵循資料 schemas, |
| Key | 訊息可以被 Key 打標簽,這可以對 topic 壓縮之類的事情起作用, |
| Properties | 可選的,用戶定義屬性的 key/value map, |
| Producer name | 生產訊息的 producer 的名稱(producer 被自動賦予默認名稱,但你也可以自己指定,) |
| Sequence ID | 在 topic 中,每個 Pulsar 訊息屬于一個有序的序列,訊息的 sequence ID 是它在序列中的次序, |
| Publish time | 訊息發布的時間戳 |
| Event time | 可選的時間戳,應用可以附在訊息上,代表某個事件發生的時間,例如,訊息被處理時,如果沒有明確的設定,那么 event time 為0, |
| TypedMessageBuilder | 它用于構造訊息,您可以使用TypedMessageBuilder設定訊息屬性,比如訊息鍵、訊息值,設定TypedMessageBuilder時,將鍵設定為字串,如果您將鍵設定為其他型別,例如,AVRO物件,則鍵將作為位元組發送,并且很難從消費者處取回AVRO物件, |
訊息的默認大小為 5 MB,可以通過以下方式配置訊息的最大大小,
- broker.conf
# The max size of a message (in bytes). maxMessageSize=5242880 - bookkeeper.conf
# The max size of the netty frame (in bytes). Any messages received larger than this value are rejected. The default value is 5 MB. nettyMaxFrameSizeBytes=5253120
3.2 Producers(生產者)
生產者是關聯到 topic 的程式,它發布訊息到 Pulsar 的 broker 上,
3.2.1 Send modes(發送模式)
producer 可以以同步或者異步的方式發布訊息到 broker,
| Mode | Description |
|---|---|
| 異步發送 | 發送訊息后,producer等待broker的確認,如果沒有收到確認,producer會認為發送失敗, |
| 同步發送 | producer 將會把訊息放入阻塞佇列,然后馬上回傳,客戶端類別庫將會在背后把訊息發送給 broker,如果佇列滿了,根據傳給 producer 的引數,producer 可能阻塞或者直接回傳失敗, |
3.2.2 Access mode(訪問模式)
你可以為生產者提供不同型別的主題訪問模式,
| Access mode | Description |
|---|---|
| Shared(共享) | 多個生產者可以發布一個主題,這是默認設定, |
| Exclusive(獨占) | 一個主題只能由一個生產者發布,如果已經有生產者連接,其他生產者試圖發布該主題立即得到錯誤,如果“老”生產者與 broker 發生網路磁區,“老”生產者將被驅逐,“新”生產者將被選為下一個唯一的生產者, |
| WaitForExclusive(獨占等待) | 如果已經有一個生產者連接,生產者的創建是未決的(而不是超時),直到生產者獲得獨占訪問,成功成為排他性的生產者被視為領導者,因此,如果您想為您的應用程式實作 leader 選舉方案,您可以使用這種訪問模式, |
3.2.3 Compression(壓縮)
你可以壓縮生產者在傳輸期間發布的訊息,Pulsar 目前支持以下型別的壓縮:
- LZ4
- ZLIB
- ZSTD
- SNAPPY
3.2.4 Batching(批處理)
如果批處理開啟,producer 將會累積一批訊息,然后通過一次請求發送出去,批處理的大小取決于最大的訊息數量及最大的發布延遲,
3.2.5 Chunking(分塊)
- 批處理和分塊不能同時啟用,要啟用分塊,必須提前禁用批處理,
- Chunking 只支持持久化的主題,
- Chunking 僅支持 exclusive 和 failover 訂閱模式,
3.2.5.1 處理一個 producer 和一個訂閱 consumer 的分塊訊息
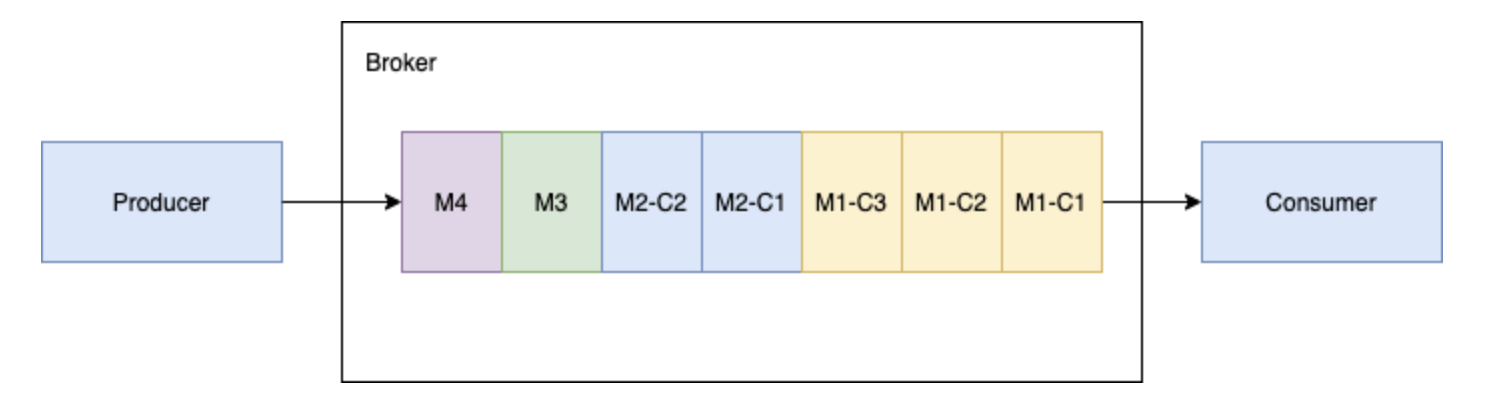
如下圖所示,當生產者向主題發送一批大的分塊訊息和普通的非分塊訊息時, 假設生產者發送的訊息為 M1,M1 有三個分塊 M1-C1,M1-C2 和 M1-C3, 這個 broker 在其管理的 ledger 里面保存所有的三個塊訊息,然后以相同的順序分發給消費者(獨占/災備模式), 消費者將在記憶體快取所有的塊訊息,直到收到所有的訊息塊,將這些訊息合并成為原始的訊息 M1,發送給處理行程,
3.2.5.2 處理多個 producer 和一個訂閱 consumer 的分塊訊息
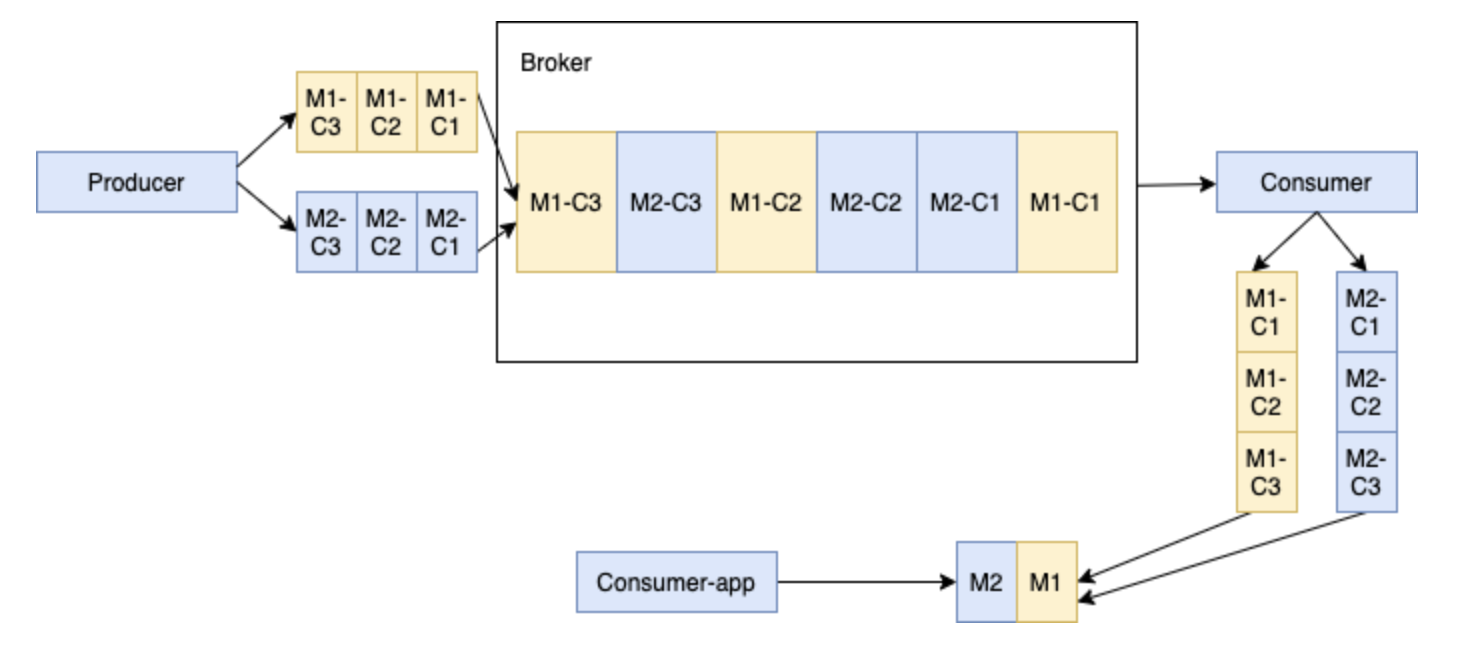
當多個生產者發布塊訊息到單個主題,這個 Broker 在同一個 Ledger 里面保存來自不同生產者的所有塊訊息, 如下所示,生產者1發布的訊息 M1,M1 由 M1-C1, M1-C2 和 M1-C3 三個塊組成, 生產者2發布的訊息 M2,M2 由 M2-C1, M2-C2 和 M2-C3 三個塊組成, 這些特定訊息的所有分塊是順序排列的,但是其在 ledger 里面可能不是連續的, 這種方式會給消費者帶來一定的記憶體負擔,因為消費者會為每個大訊息在記憶體開辟一塊緩沖區,以便將所有的塊訊息合并為原始的大訊息,
3.3 Consumers(消費者)
消費者通過訂閱關聯到主題,然后接收訊息的程式,
3.3.1 Receive modes(接收模式)
訊息可以通過同步或者異步的方式從 broker 接收,
| Mode | Description |
|---|---|
| 同步接收 | 同步接收將會阻塞,直到訊息可用, |
| 異步接收 | 異步接收立即回傳 future 值,例如 java 中的 CompletableFuture,一旦新訊息可用,它即刻完成, |
3.3.2 Listeners(監聽)
客戶端類別庫提供了它們對于 consumer 的監聽實作,舉一個 Java 客戶端的例子,它提供了 MessageListener 介面,在這個介面中,一旦接受到新的訊息,received 方法將被呼叫,
3.3.3 Acknowledgement(確認)
消費者成功處理了訊息,需要發送確認給 broker,以讓 broker 丟掉這條訊息(否則它將存盤著此訊息),
訊息的確認可以一個接一個,也可以累積一起,累積確認時,消費者只需要確認最后一條它收到的訊息,所有之前(包含此條)的訊息,都不會被重新發給那個消費者,
累積訊息確認不能用于 shared 訂閱模式,因為 shared 訂閱為同一個訂閱引入了多個消費者,
3.4 Topics(主題)
和其它的發布訂閱系統一樣,Pulsar 中的 topic 是帶有名稱的通道,用來從 producer 到 consumer 傳輸訊息,Topic 的名稱是符合良好結構的 URL,
{persistent|non-persistent}://tenant/namespace/topic
| Topic name component | Description |
|---|---|
| persistent / non-persistent | 定義了 topic 型別,Pulsar 支持兩種不同 topic:持久和非持久(默認是持久型別,如果你沒有指明型別,topic 將會是持久型別),持久 topic 的所有訊息都會保存在硬碟上(這意味著多塊硬碟,除非是單機模式的 broker),反之,非持久 topic 的資料不會存盤到硬碟上, |
| tenant | 實體中 topic 的租戶,tenant 是 Pulsar 多租戶的基本要素,可以被跨集群的傳播, |
| namespace | topic 的管理單元,相關 topic 組的管理機制,大多數的 topic 配置在 namespace 層面生效,每個 tenant 可以有多個 namespace, |
| topic | 主題名稱的最后組成部分,topic 的名稱很自由,沒有什么特殊的含義, |
3.4.1 Partitioned topics(磁區主題)
普通主題僅由單個 broker 提供服務,這限制了主題的最大吞吐量,磁區主題是由多個 broker 處理的一種特殊型別的主題,因此允許更高的吞吐量,
磁區的主題實際上實作為 N 個內部主題,其中 N 是磁區的數量,當將訊息發布到磁區主題時,每個訊息都被路由到幾個 broker 中的一個,磁區在 broker 間的分布由 Pulsar 自動處理,
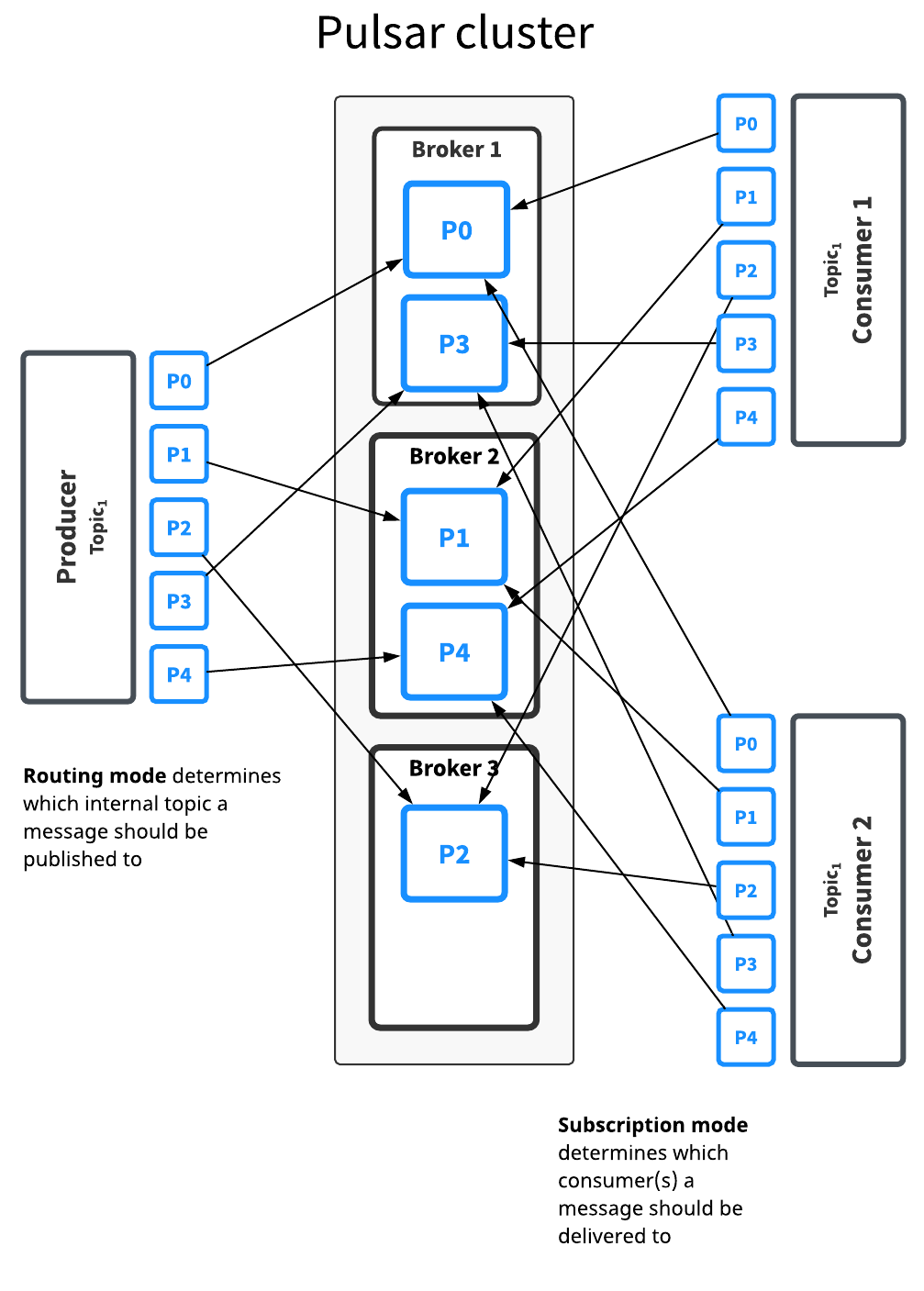
如上圖,Topic1 主題有 5 個磁區(P0 到 P4),劃分在 3 個 broker 上,因為磁區比 broker 多,前兩個 broker 分別處理兩個磁區,而第三個 broker 只處理一個磁區(同樣,Pulsar 自動處理磁區的分布),
此主題的訊息將廣播給兩個消費者,路由模式決定將每個訊息發布到哪個磁區,而訂閱模式決定將哪些訊息發送到哪個消費者,
在大多數情況下,可以分別決定路由和訂閱模式,通常,吞吐量問題應該指導磁區/路由決策,而訂閱決策應該根據應用程式語意進行指導,
就訂閱模式的作業方式而言,磁區主題和普通主題之間沒有區別,因為磁區僅決定訊息由生產者發布和由消費者處理和確認之間發生了什么,
磁區主題需要通過管理 API 顯式創建,磁區的數量可以在創建主題時指定,
3.4.1.1 Routing modes(路由模式)
當發布訊息到磁區 topic,你必須要指定路由模式,路由模式決定了每條訊息被發布到的磁區(其實是內部主題),
下面是三種默認可用的路由模式:
| Mode | Description |
|---|---|
| RoundRobinPartition | message 無 key 則輪詢,有 key 則 hash(key) 指定磁區,(默認模式) |
| SinglePartition | message 無 key,producer 將會隨機選擇一個磁區,把所有的訊息發往該磁區,如果 message 指定了 key,磁區的 producer 會把 key 做 hash,然后分配訊息到指定的磁區, |
| CustomPartition | 使用自定義訊息路由實作,可以決定特定的訊息進入指定的磁區, |
3.4.1.2 Ordering guarantee(順序保證)
訊息的順序與路由模式和訊息的 key 有關:
| Ordering guarantee | Description | Routing Mode and Key |
|---|---|---|
| Per-key-partition(按 key 磁區) | 具有相同 key 的所有訊息將被按順序放置在同一個磁區中, | 使用 SinglePartition 或 RoundRobinPartition 模式,Key 由每個訊息提供, |
| Per-producer(按 producer) | 來自同一生產者的所有訊息將是有序的, | 使用 SinglePartition 模式,并且沒有為每個訊息提供 Key, |
3.4.1.3 Hashing scheme(哈希方案)
HashingScheme 是一個 enum,表示在選擇要為特定訊息使用的磁區時可用的標準哈希函式集,
有兩種型別的標準哈希函式可用:JavaStringHash 和 Murmur3_32Hash,生產者的默認哈希函式是 JavaStringHash,請注意,當生產者可以來自不同的多語言客戶端時,JavaStringHash 是沒有用的,在這個用例下,建議使用 Murmur3_32Hash,
3.4.2 persistent/Non-persistent topics(持久/非持久主題)
默認情況下, Pulsar 會保存所有沒確認的訊息到 BookKeeper 中,持久 Topic 的訊息在 Broker 重啟或者 Consumer 出現問題時保存下來,
除了持久 Topic , Pulsar 也支持非持久 Topic ,這些 Topic 的訊息只存在于記憶體中,不會存盤到磁盤,
因為 Broker 不會對訊息進行持久化存盤,當 Producer 將訊息發送到 Broker 時, Broker 可以立即將 ack 回傳給 Producer ,所以非持久 Topic 的訊息傳遞會比持久 Topic 的訊息傳遞更快一些,相對的,當 Broker 因為一些原因宕機、重啟后,非持久 Topic 的訊息都會消失,訂閱者將無法收到這些訊息,
3.4.3 Dead letter topic(死信主題)
死信主題允許你在用戶無法成功消費某些訊息時使用新訊息,在這種機制中,無法使用的訊息存盤在單獨的主題中,稱為死信主題,你可以決定如何處理死信主題中的訊息,
下面的例子展示了如何在 Java 客戶端中使用默認的死信主題:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.build())
.subscribe();
默認的死信主題格式:
<topicname>-<subscriptionname>-DLQ
如果你想指定死信主題的名稱,請使用下面的 Java 客戶端示例:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.deadLetterTopic("your-topic-name")
.build())
.subscribe();
死信主題依賴于訊息的重新投遞,由于確認超時或否認確認,訊息將被重新發送,如果要對訊息使用否定確認,請確保在確認超時之前對其進行否定確認,
目前,在共享和 Key_Shared 訂閱模式下啟用了死信主題,
3.4.4 Retry letter topic(重試主題)
對于許多在線業務系統,由于業務邏輯處理中出現例外,訊息會被重復消費,若要配置重新消費失敗訊息的延遲時間,你可以配置生產者將訊息發送到業務主題和重試主題,并在消費者上啟用自動重試,當在消費者上啟用自動重試時,如果訊息沒有被消費,則訊息將存盤在重試主題中,因此消費者在指定的延遲時間后將自動接收來自重試主題的失敗訊息,
默認情況下,不啟用自動重試功能,你可以將 enableRetry 設定為 true,以啟用消費者的自動重試,
下面來看個如何使用從重試主題來消費訊息的示例:
Consumer<byte[]> consumer = pulsarClient.newConsumer(Schema.BYTES)
.topic(topic)
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.enableRetry(true)
.receiverQueueSize(100)
.deadLetterPolicy(DeadLetterPolicy.builder()
.maxRedeliverCount(maxRedeliveryCount)
.retryLetterTopic("persistent://my-property/my-ns/my-subscription-custom-Retry")
.build())
.subscriptionInitialPosition(SubscriptionInitialPosition.Earliest)
.subscribe();
3.5 Subscriptions(訂閱模式)
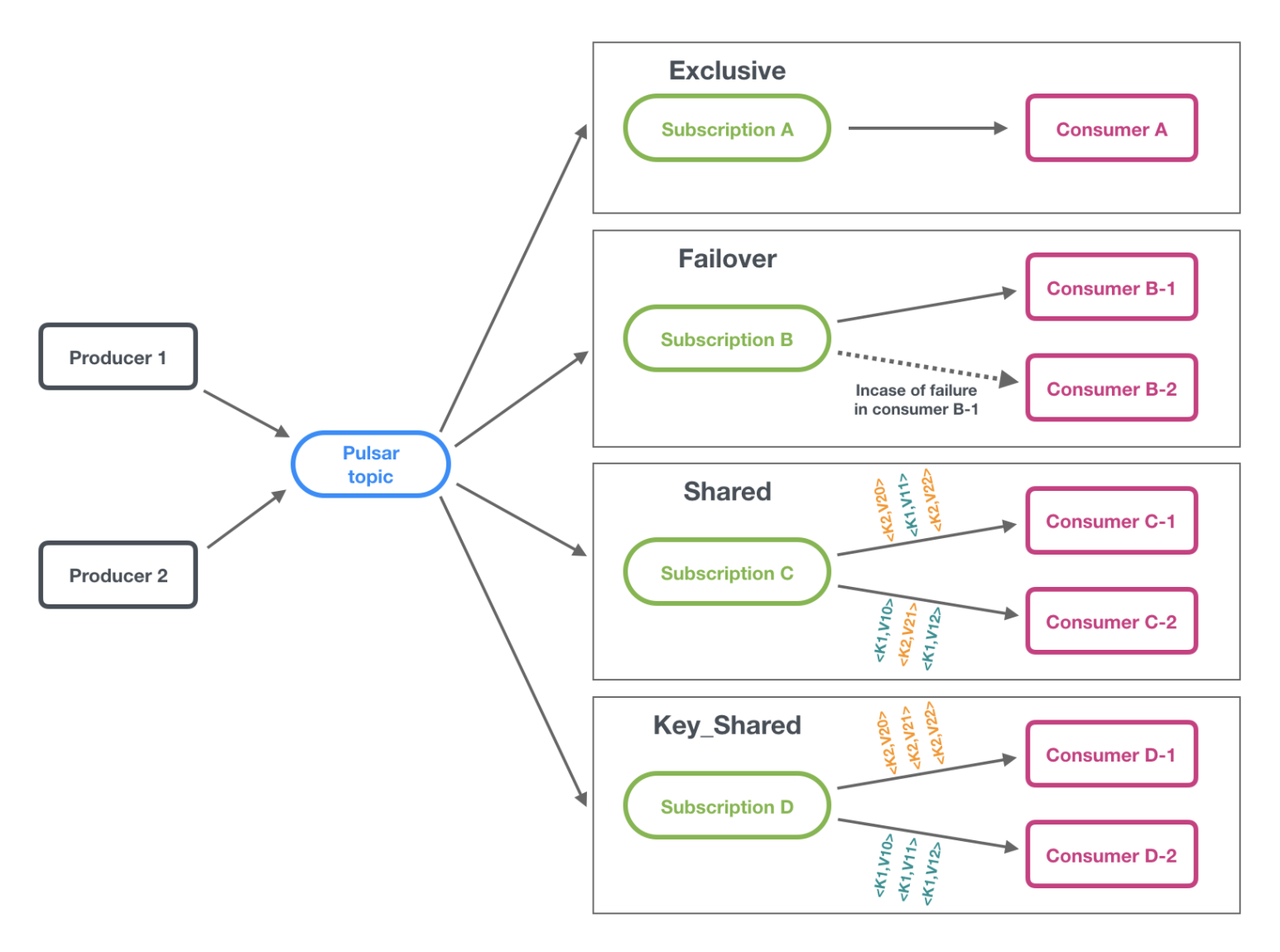
Pulsar 支持 exclusive(獨占)、failover(災備)、 shared(共享)和 key_shared(key 共享) 四種訊息訂閱模式,這四種模式的示意圖如下:
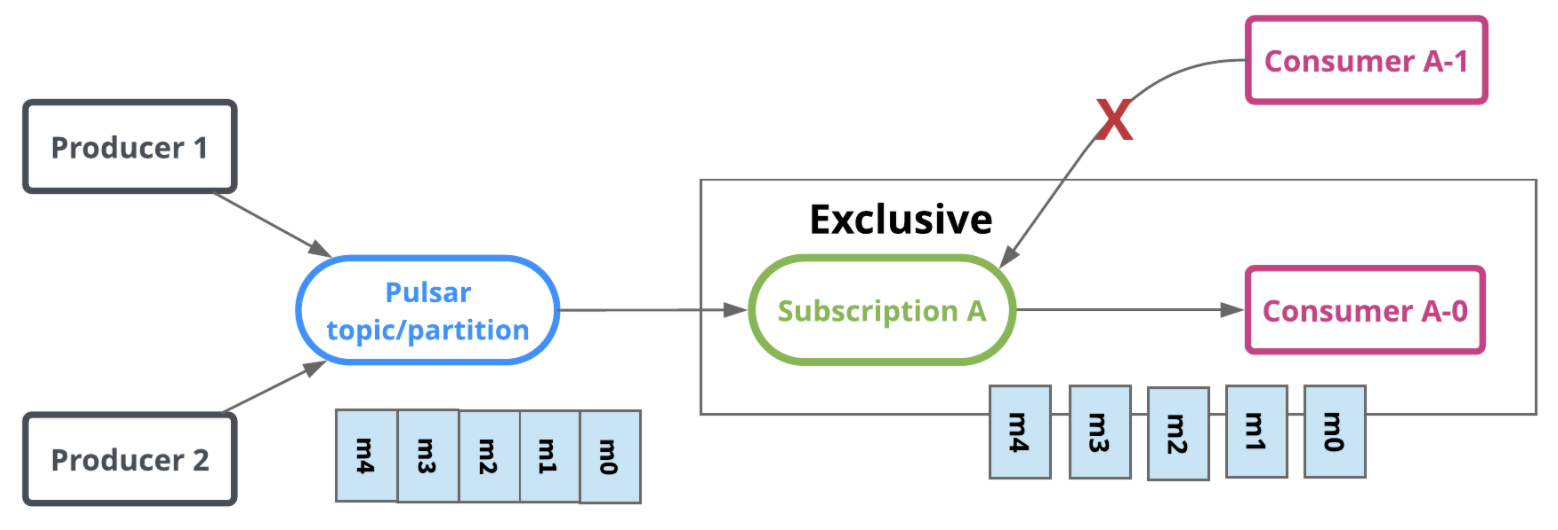
3.5.1 Exclusive(獨占模式)
獨占模式是 Pulsar 默認的訊息訂閱模式,在這種模式下,只能有一個 consumer 消費訊息,如果有多于一個 consumer 消費此 topic 則會出錯,消費示意圖如下:
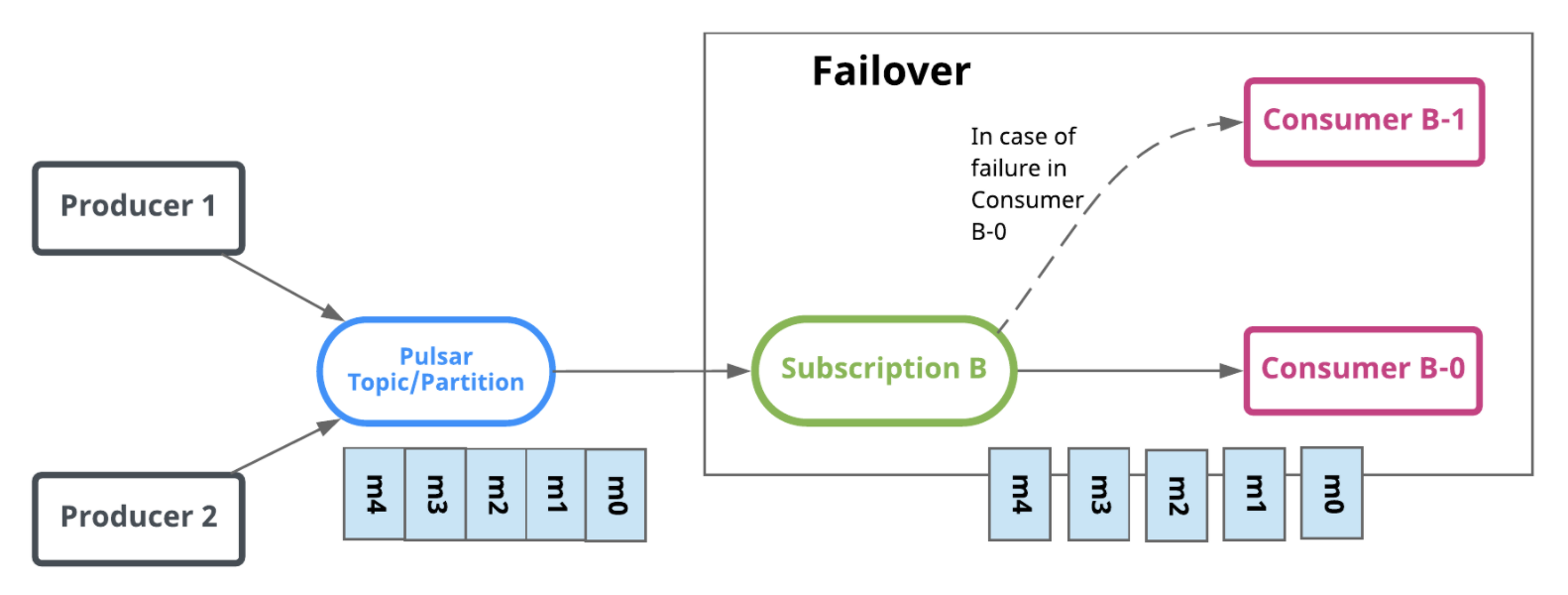
3.5.2 Failover(災備模式)
災備模式下,一個 topic 也是只有單個 consumer 消費一個訂閱關系的訊息,與獨占模式不同之處在于,災備模式下,每個消費者會被排序,當前面的消費者無法連接上 broker 后,訊息會由下一個消費者消費,消費示意圖如下:
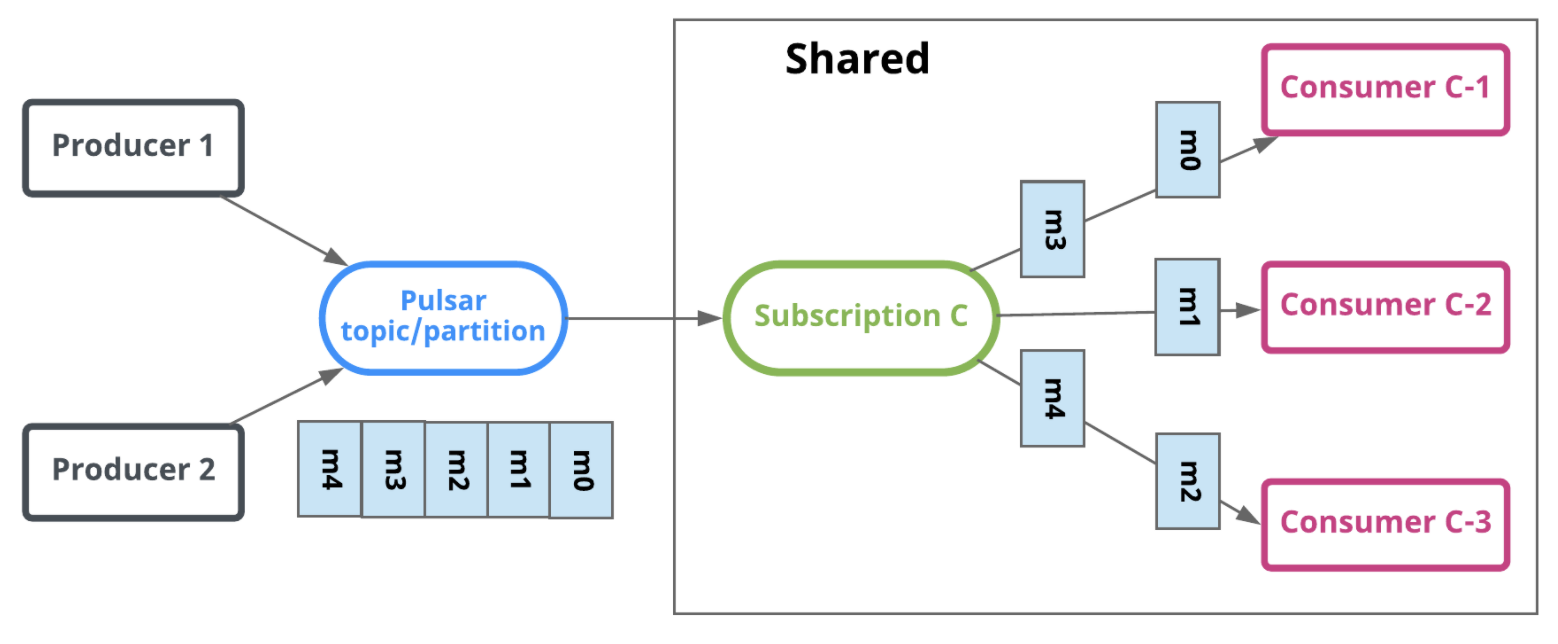
3.5.3 Shared(共享模式)
共享模式下,訊息可被多個 consumer 同時消費,無法保證訊息的順序,并且無法使用 one by one 和 cumulative 的 ack 模式,訊息通過 roundrobin 的方式投遞到每一個消費者,消費示意圖如下:
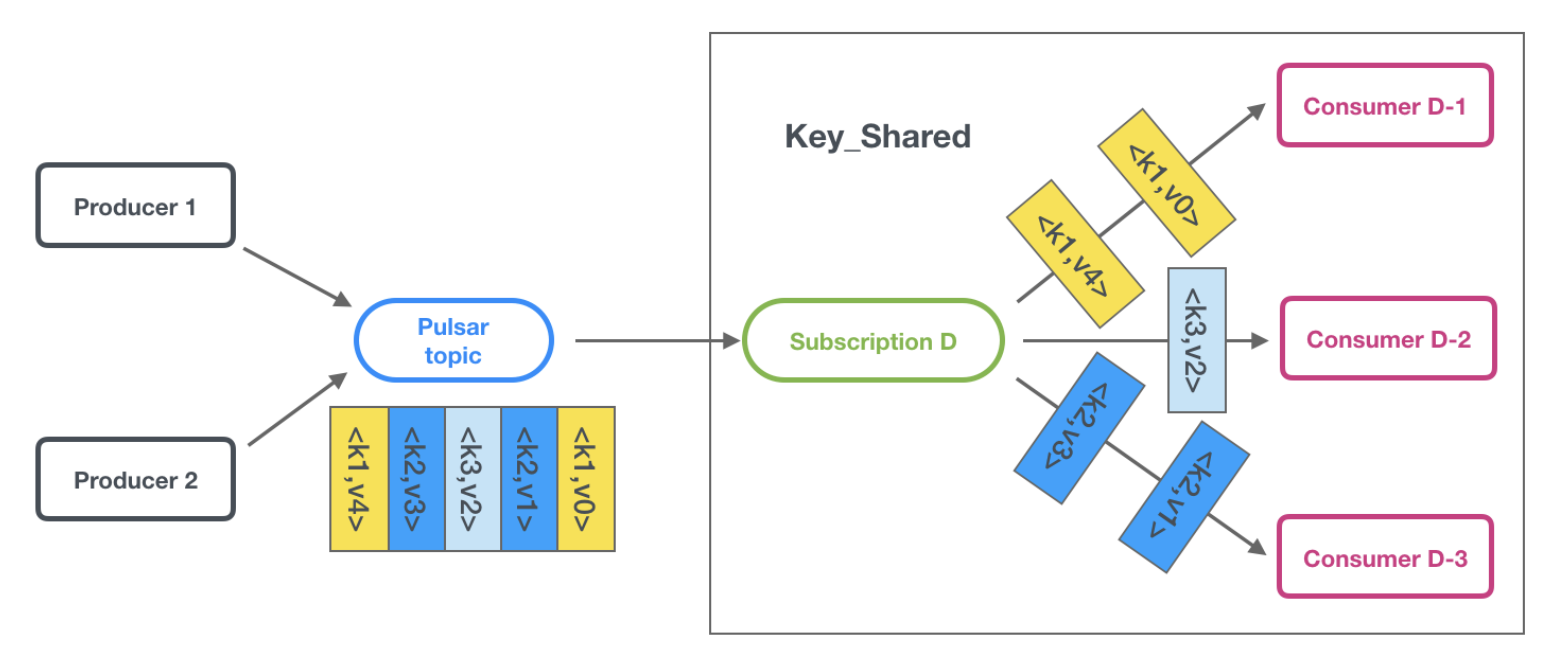
3.5.4 Key_Shared(Key 共享模式)
Key_Shared 模式是 Shared 模式的一種,不同的是它按 key 對訊息做投遞,相同的 key 的訊息會被投遞到同一個 consumer 上,消費示意圖如下:
3.6 Message retention and expiry(訊息保留和過期)
默認策略:
- 立即洗掉所有已經被消費者確認過的的訊息;
- 以 backlog 的形式,持久保存所有未被確認的訊息;
兩個特性:
- 訊息保留讓你可以保存 consumer 確認過的訊息;
- 訊息過期讓你可以給未被確認的訊息設定存活時長(TTL);
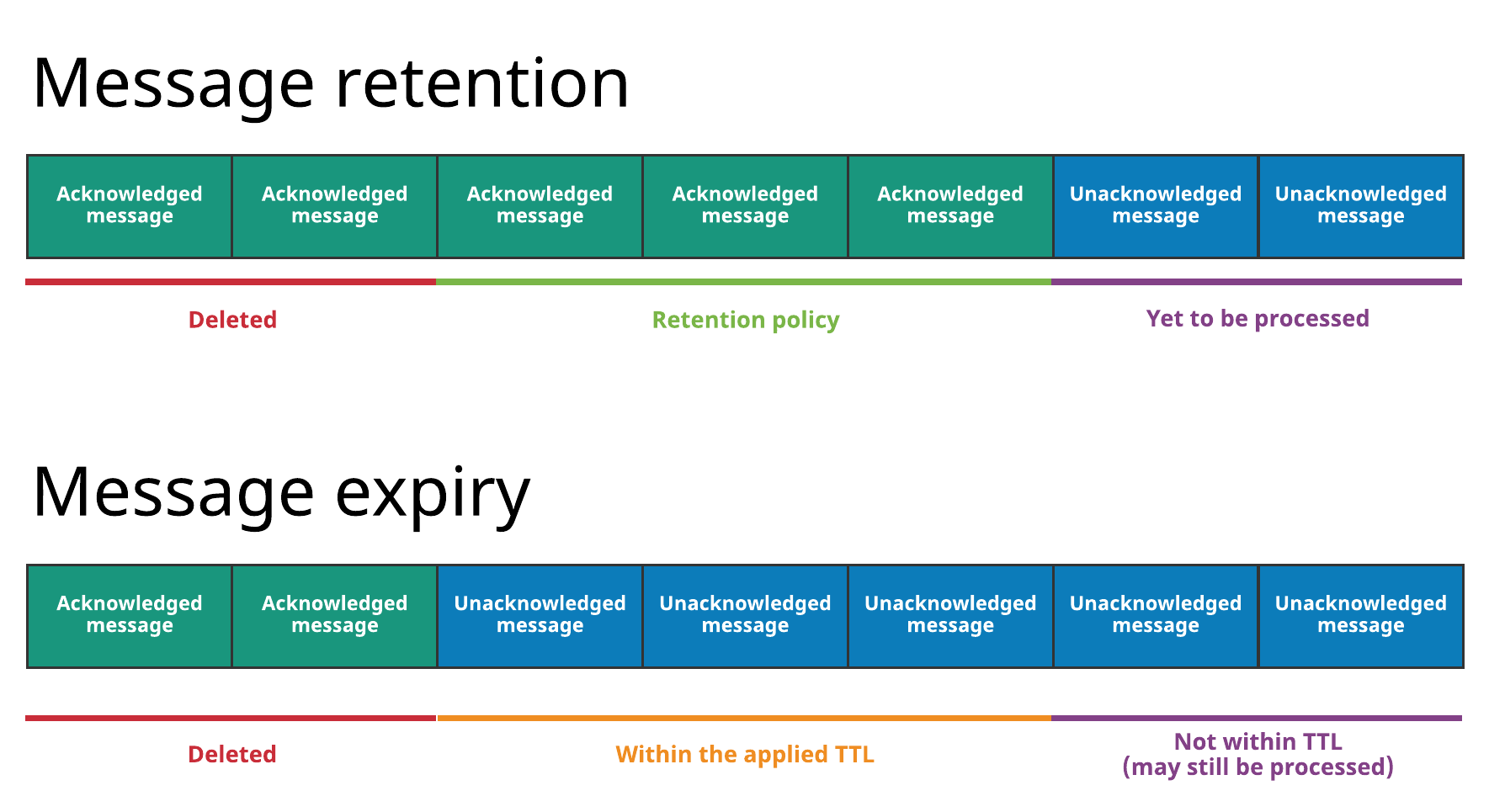
注:所有訊息保留和過期在 namespace 層面管理,
3.7 Message deduplication(訊息去重)
實作訊息去重的一種方式是確保訊息僅生成一次,即生產者冪等,這種方式的缺點是把訊息去重的作業交由應用去做,
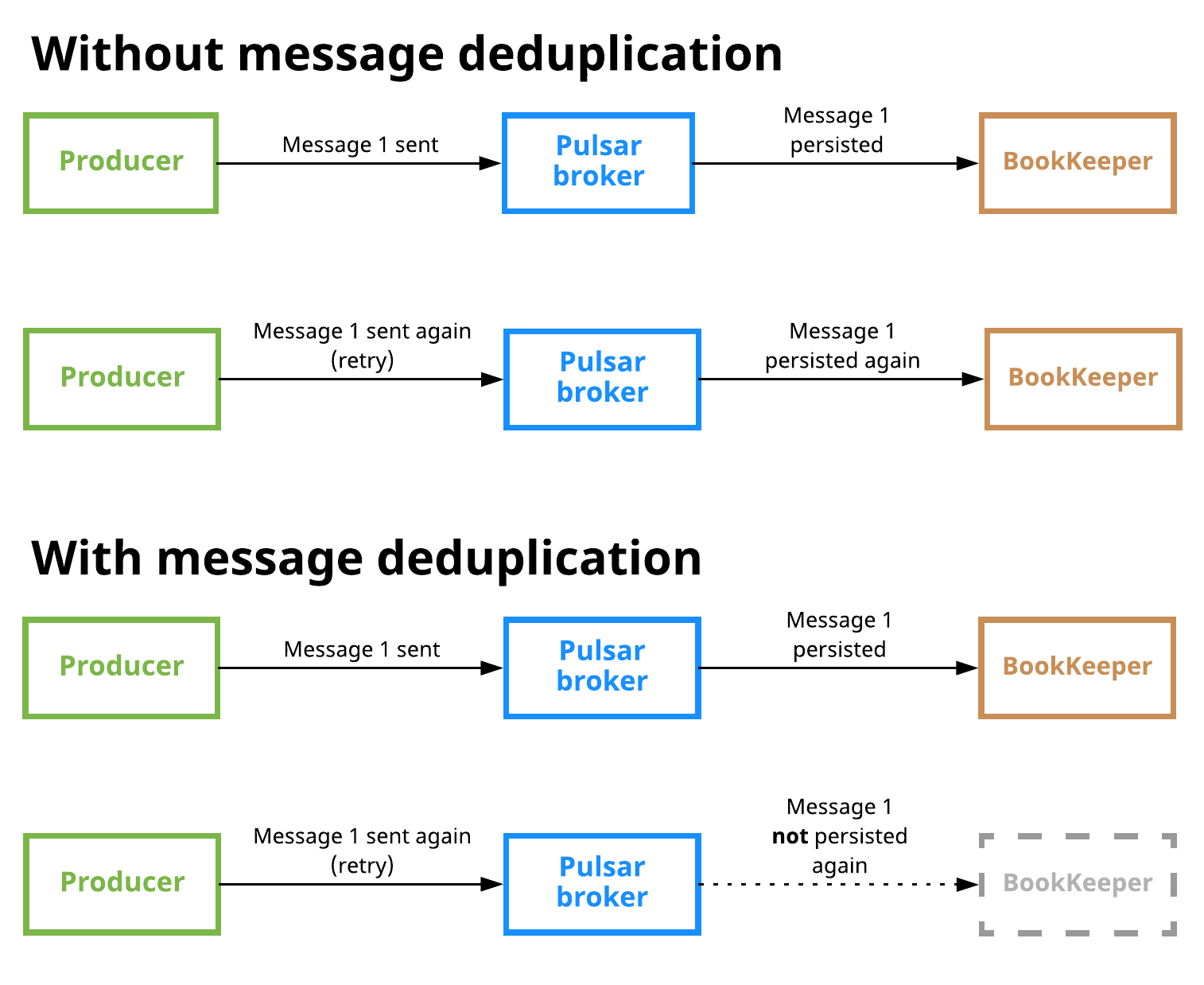
在 Pulsar 中, Broker 支持配置開啟訊息去重,用戶不需要為了訊息去重去調整 Producer 的代碼,啟用訊息去重后,即使一條訊息被多次發送到 Topic 上,這條訊息也只會被持久化到磁盤一次,
如下圖,未開啟訊息去重時, Producer 發送訊息 1 到 Topic 后, Broker 會把訊息 1 持久化到 BookKeeper ,當 Producer 又發送訊息 1 時, Broker 會把訊息 1 再一次持久化到 BookKeeper ,開啟訊息去重后,當 Producer 再次發送訊息 1 時, Broker 不會把訊息 1 再一次持久化到磁盤,
3.7.1 去重原理
Producer 對每一個發送的訊息,都會采用遞增的方式生成一個唯一的 sequenceID,這個訊息會放在 message 的元資料中傳遞給 Broker ,同時, Broker 也會維護一個 PendingMessage 佇列,當 Broker 回傳發送成功 ack 后, Producer 會將 PendingMessage 佇列中的對應的 Sequence ID 洗掉,表示 Producer 任務這個訊息生產成功,Broker 會記錄針對每個 Producer 接收到的最大 Sequence ID 和已經處理完的最大 Sequence ID,
當 Broker 開啟訊息去重后, Broker 會對每個訊息請求進行是否去重的判斷,收到的最新的 Sequence ID 是否大于 Broker 端記錄的兩個維度的最大 Sequence ID,如果大于則不重復,如果小于或等于則訊息重復,訊息重復時, Broker 端會直接回傳 ack,不會繼續走后續的存盤處理流程,
3.8 Delayed message delivery(訊息延遲傳遞)
延時訊息功能允許 Consumer 能夠在訊息發送到 Topic 后過一段時間才能消費到這條訊息,在這種機制中,訊息在發布到 Broker 后,會被存盤在 BookKeeper 中,當到訊息特定的延遲時間時,訊息就會傳遞給 Consumer ,
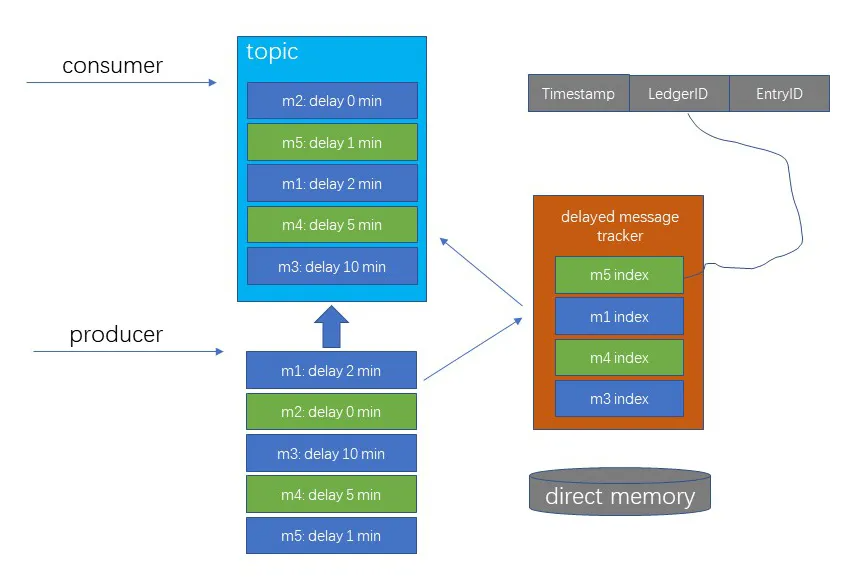
下圖為訊息延遲傳遞的機制,Broker 在存盤延遲訊息的時候不會進行特殊的處理,當 Consumer 消費訊息的時候,如果這條訊息設定了延遲時間,則會把這條訊息加入 DelayedDeliveryTracker 中,當到了指定的發送時間時,DelayedDeliveryTracker 才會把這條訊息推送給消費者,
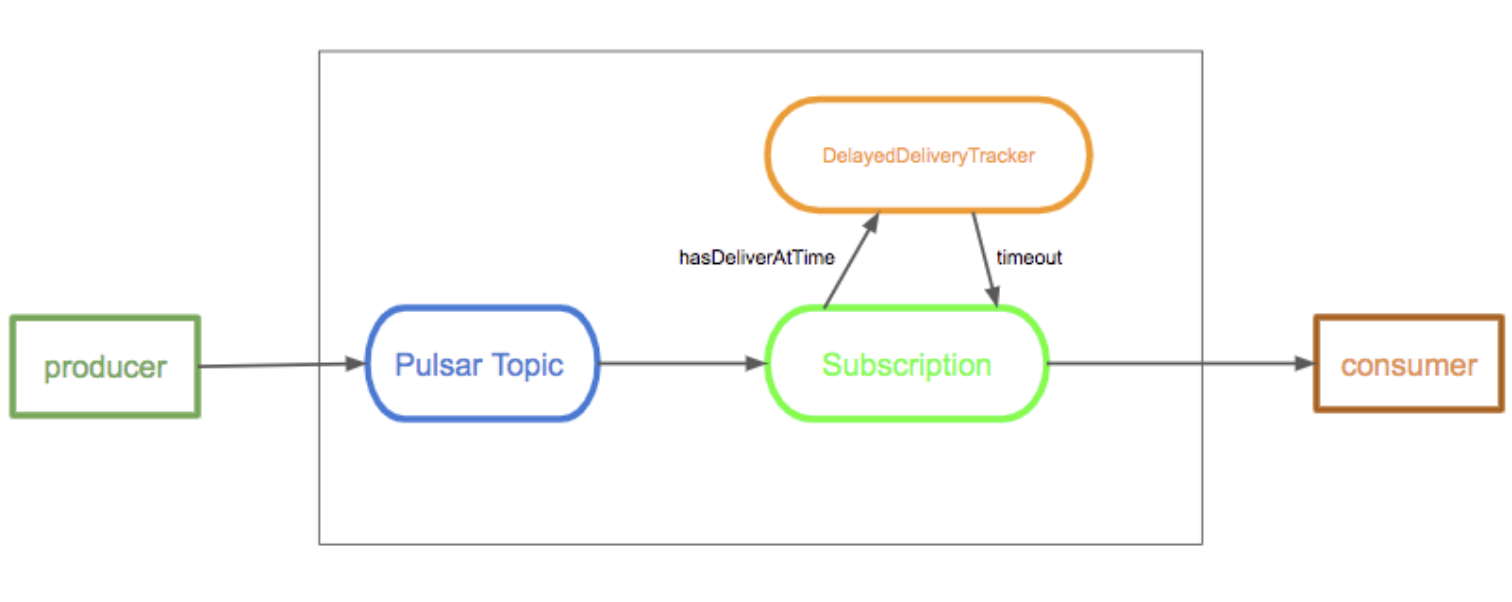
注:延遲訊息傳遞僅在共享訂閱模式下有效,在獨占和故障轉移訂閱模式下,將立即分派延遲的訊息,
3.8.1 示例
- Broker
# Whether to enable the delayed delivery for messages. # If disabled, messages are immediately delivered and there is no tracking overhead. delayedDeliveryEnabled=true # Control the ticking time for the retry of delayed message delivery, # affecting the accuracy of the delivery time compared to the scheduled time. # Default is 1 second. delayedDeliveryTickTimeMillis=1000 - Producer
// message to be delivered at the configured delay interval producer.newMessage().deliverAfter(3L, TimeUnit.Minute).value("Hello Pulsar!").send();
3.8.2 訊息延遲傳遞原理
在 Pulsar 中,可以通過兩種方式實作延遲投遞,分別為 deliverAfter 和 deliverAt,
deliverAfter 可以指定具體的延遲時間戳,deliverAt 可以指定訊息在多長時間后消費,兩種方式本質時一樣的,deliverAt 方式下,客戶端會計算出具體的延遲時間戳發送給 Broker ,
DelayedDeliveryTracker 會記錄所有需要延遲投遞的訊息的 index ,index 由 Timestamp、 Ledger ID、 Entry ID 三部分組成,其中 Ledger ID 和 Entry ID 用于定位該訊息,Timestamp 除了記錄需要投遞的時間,還用于延遲優先級佇列排序,DelayedDeliveryTracker 會根據延遲時間對訊息進行排序,延遲時間最短的放在前面,當 Consumer 在消費時,如果有到期的訊息需要消費,則根據 DelayedDeliveryTracker index 的 Ledger ID、 Entry ID 找到對應的訊息進行消費,如下圖, Producer 依次投遞 m1、m2、m3、m4、m5 這五條訊息,m2 沒有設定延遲時間,所以會被 Consumer 直接消費,m1、m3、m4、m5 在 DelayedDeliveryTracker 會根據延遲時間進行排序,并在到達延遲時間時,依次被 Consumer 進行消費,
3.9 多租戶模式
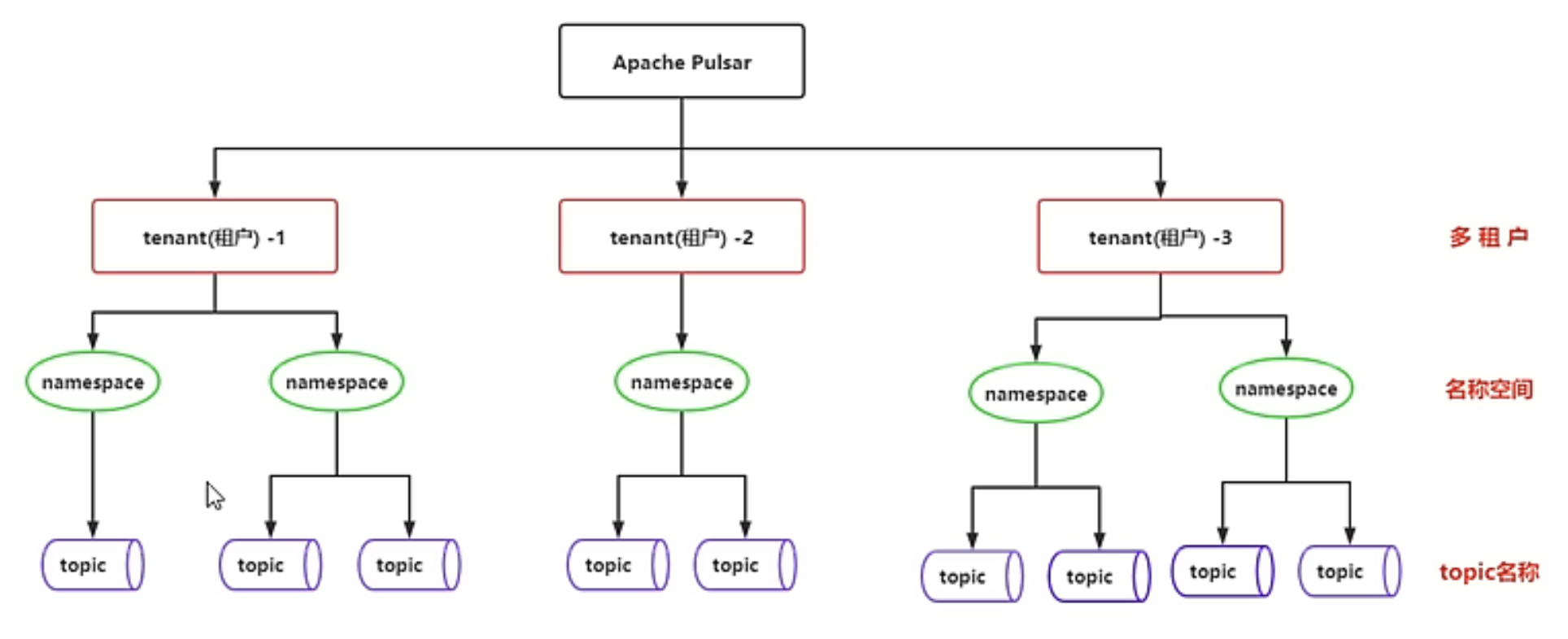
Pulsar 的云原生架構天然支持多租戶,每個租戶下還支持多 Namespace(命名空間),非常適合做共享大集群,方便維護,此外,Pulsar 天然支持租戶之間資源的邏輯隔離,只要用戶的運營管控后臺和監控足夠強大,便可以做到動態隔離大流量租戶,防止互相干擾,還能實作大集群資源的充分利用,
- Tenant(租戶)和 Namespace(命名空間)是 Pulsar 支持多租戶的兩個核心概念,
- 在租戶級別,Pulsar 為特定的租戶預留合適的存盤空間、應用授權和認證機制,
- 在命名空間級別,Pulsar 有一系列的配置策略(Policy),包括存盤配額、流控、訊息過期策略和命名空間之間的隔離策略,
Pulsar 的多租戶性質主要體現在 Topic 的 URL 中,結構如下:
persistent://tenant/namespace/topic
租戶、命名空間、topic 更直觀的關系可以看下圖:
3.10 統一訊息模型
- Pulsar 做了佇列模型與流模型的統一,在 Topic 級別只需保存一份資料,同一份資料可多次消費,以流式、佇列等方式計算不同的訂閱模型,大大的提升了靈活度,
- 同時 Pulsar 通過事務采用 Exactly-Once(剛好一次)的語意,在進行訊息傳輸程序中,可以確保資料不丟不重,
3.11 Segmented Streams(分片流)
- Pulsar 將無界的資料看作是分片的流,分片分散存盤在分層存盤(tiered storage)、BookKeeper 集群和 Broker 節點上,而對外提供一個統一的、無界資料的視圖,
- 不需要用戶顯式遷移資料,對用戶無感知,減少存盤成本并保持近似無限的存盤,
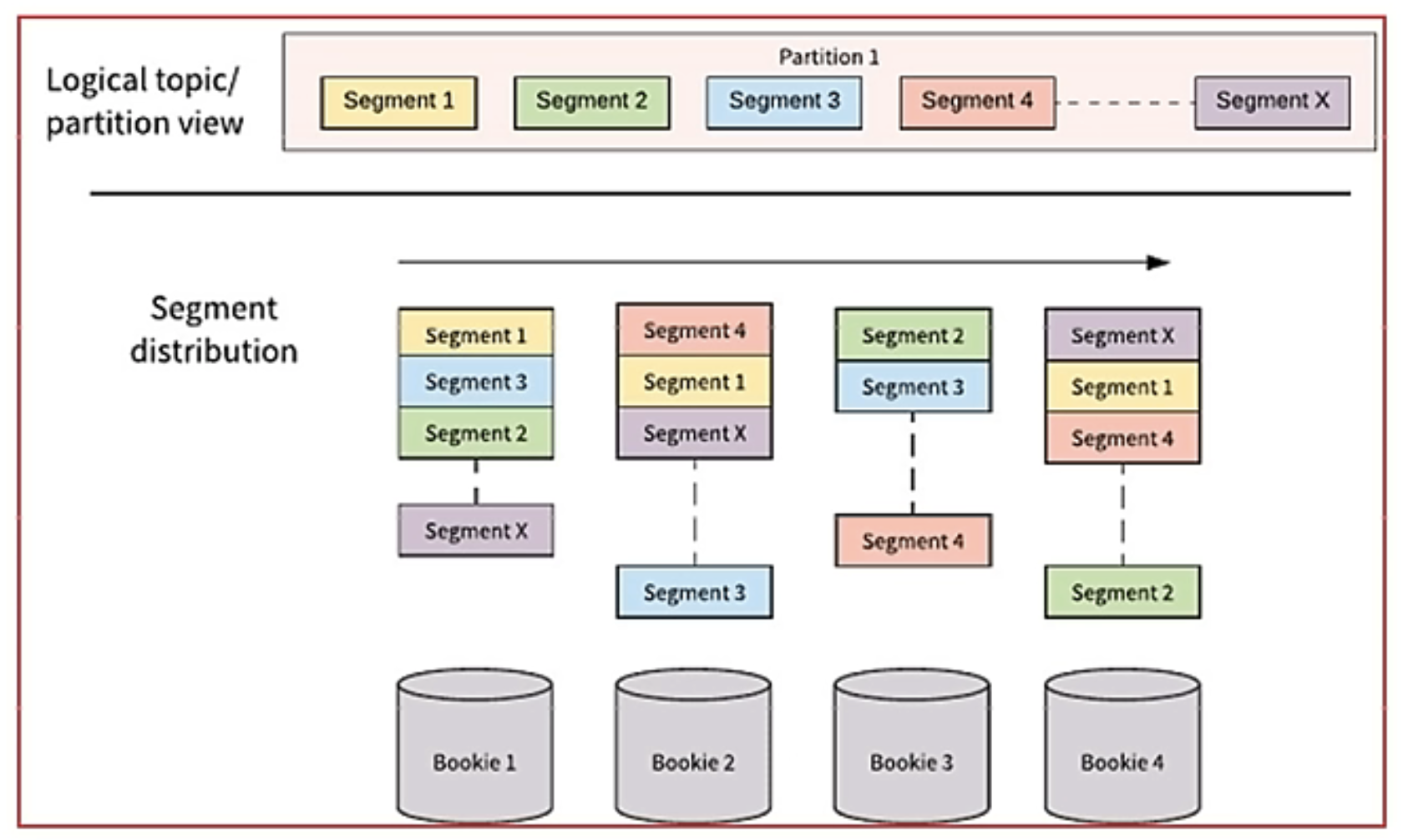
3.12 Geo Replication(跨地域復制)
- Pulsar 中的跨地域復制是將 Pulsar 中持久化的訊息在多個集群間備份,
- 在 Pulsar 2.4.0 中新增了復制訂閱模式(Replicated-subscriptions),在某個集群失效情況下,該功能可以在其他集群恢復消費者的消費狀態, 從而達到熱備模式下訊息服務的高可用,
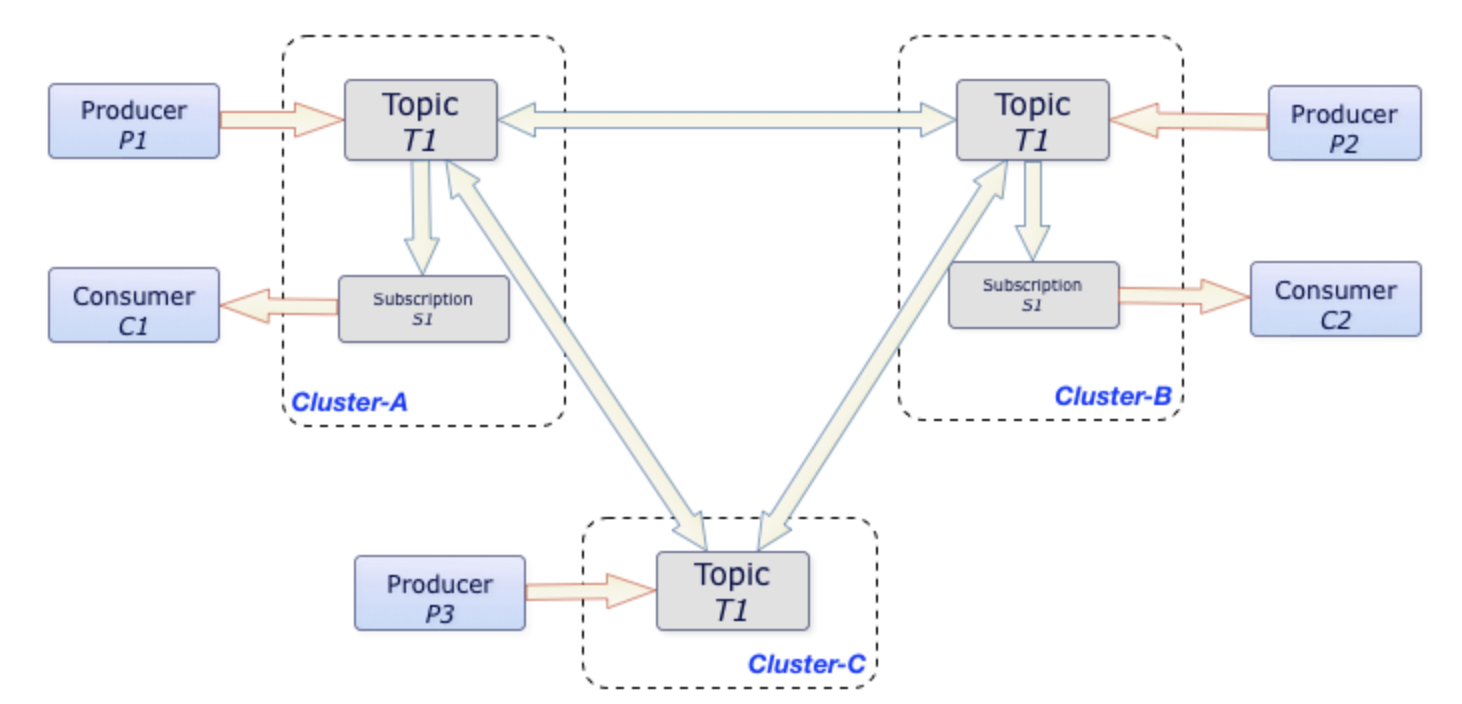
在這個圖中,每當 P1、P2 和 P3 生產者分別將訊息發布到 Cluster-A、Cluster-B 和 Cluster-C 上的 T1 主題時,這些訊息就會立即跨集群復制,一旦訊息被復制,C1 和 C2 消費者就可以從他們各自的集群中消費這些訊息,
沒有跨地域復制,C1 和 C2 消費者就不能使用 P3 生產者發布的訊息,
四、云原生架構
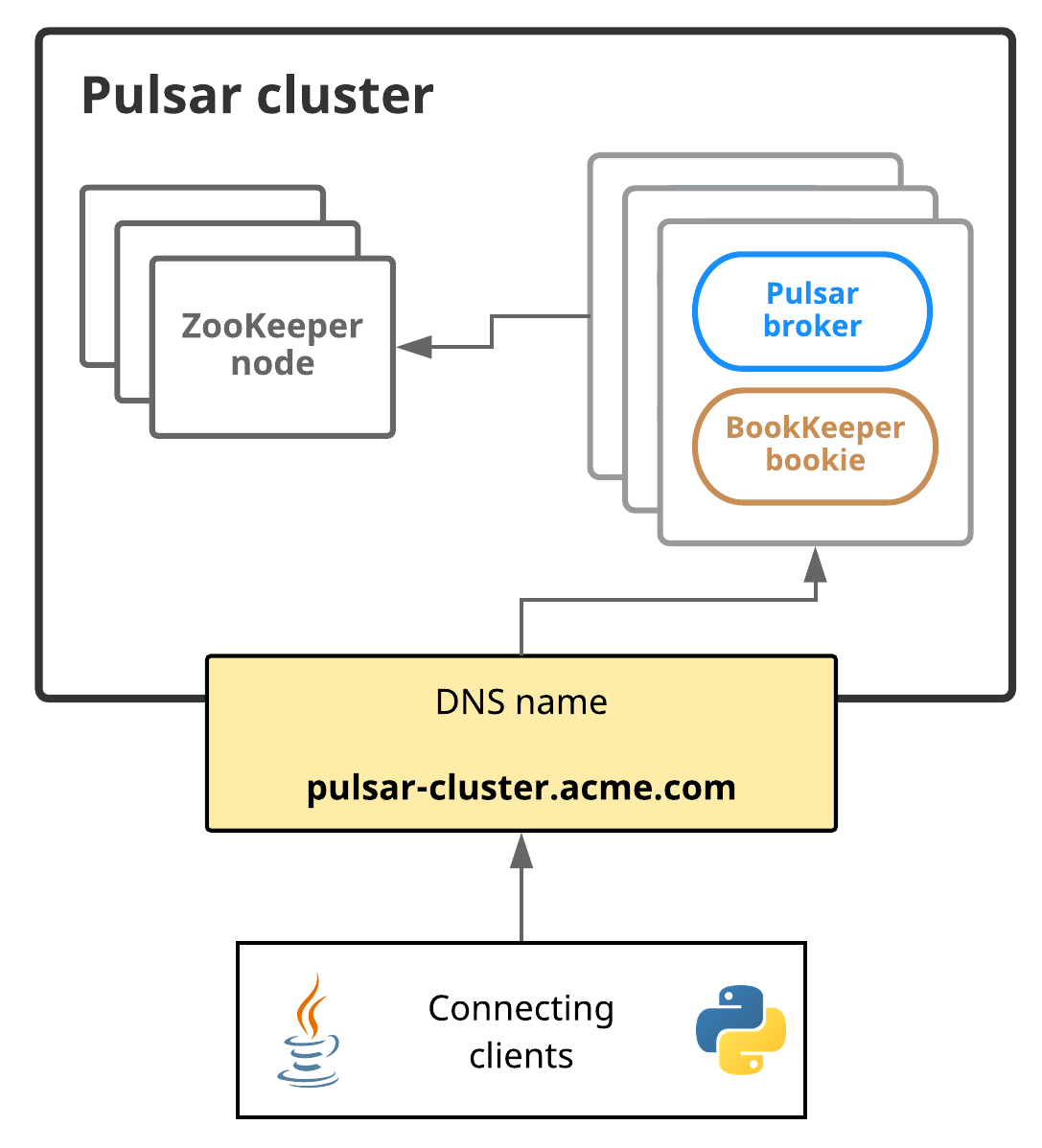
4.1 Pulsar 集群架構
單個 Pulsar 集群由以下三部分組成:
- 一個或者多個 broker 負責處理和負載均衡 producer 發出的訊息,并將這些訊息分派給 consumer;Broker 與 Pulsar 配置存盤互動來處理相應的任務,并將訊息存盤在 BookKeeper 實體中(又稱 bookies);Broker 依賴 ZooKeeper 集群處理特定的任務,等等,
- 包含一個或多個 bookie 的 BookKeeper 集群負責訊息的持久化存盤,
- 一個 ZooKeeper 集群,用來處理多個 Pulsar 集群之間的協調任務,
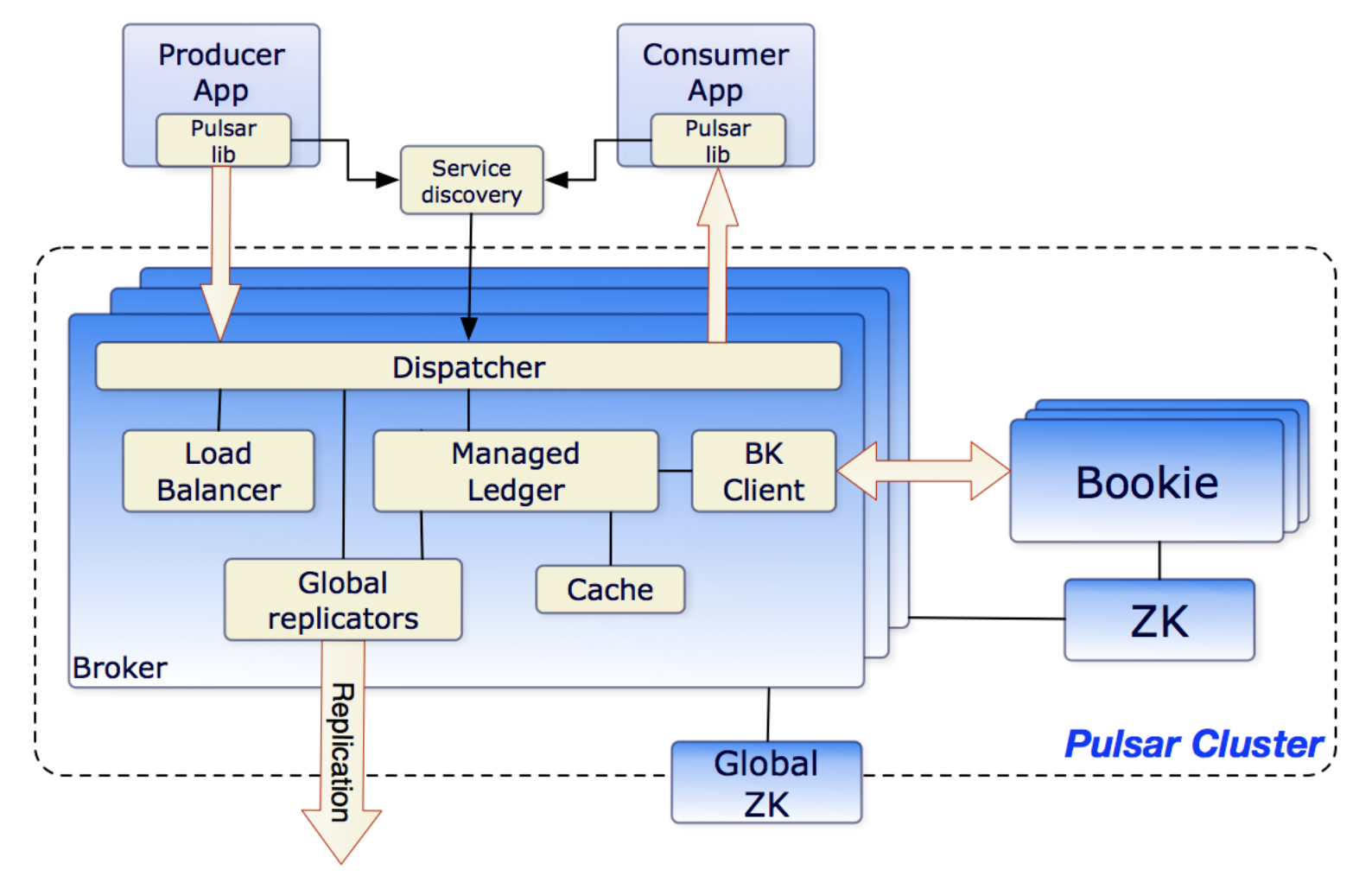
Pulsar 分理出 Broker 與 Bookie 兩層架構,Broker 為無狀態服務,用于發布和消費訊息,而 BookKeeper 專注于存盤,Pulsar 存盤是分片的,這種架構可以避免擴容時受限制,實作資料的獨立擴展和快速恢復,
4.2 Brokers
Pulsar 的 broker 是一個無狀態組件,主要負責運行另外的兩個組件:
- 一個 HTTP 服務器(Service discovery),它暴露了 REST 系統管理介面以及在生產者和消費者之間進行 Topic 查找的 API,
- 一個調度分發器(Dispatcher),它是異步的 TCP 服務器,通過自定義二進制協議應用于所有相關的資料傳輸,
出于性能考慮,訊息通常從 Managed Ledger 快取中分派出去,除非積壓超過快取大小,如果積壓的訊息對于快取來說太大了,則 Broker 將開始從 BookKeeper 那里讀取 Entries(Entry 同樣是 BookKeeper 中的概念,相當于一條記錄),
最后,為了支持全域 Topic 異地復制,Broker 會控制 Replicators 追蹤本地發布的條目,并把這些條目用Java客戶端重新發布到其他區域,
4.3 ZooKeeper 元資料存盤
Pulsar 使用 Apache ZooKeeper 進行元資料存盤、集群配置和協調,
- 配置存盤 Quorum 存盤了租戶、命名空間和其他需要全域一致的配置項,
- 每個集群有自己獨立的本地 ZooKeeper 保存集群內部配置和協調資訊,例如 broker 負責哪幾個主題及所有權歸屬元資料、broker 負載報告,BookKeeper ledger 元資料(這個是 BookKeeper 本身所依賴的)等等,
4.4 BookKeeper 持久化存盤
Apache Pulsar 為應用程式提供有保證的資訊傳遞,如果訊息成功到達 broker,就認為其預期到達了目的地,
為了提供這種保證,未確認送達的訊息需要持久化存盤直到它們被確認送達,這種訊息傳遞模式通常稱為持久訊息傳遞,在 Pulsar 內部,所有訊息都被保存并同步 N 份,例如,2 個服務器保存四份,每個服務器上面都有鏡像的 RAID 存盤,
Pulsar 用 Apache BookKeeper 作為持久化存盤,BookKeeper 是一個分布式的預寫日志(WAL)系統,有如下幾個特性特別適合 Pulsar 的應用場景:
- 使 Pulsar 能夠利用獨立的日志,稱為 ledgers,可以隨著時間的推移為 topic 創建多個 ledgers,
- 它為處理順序訊息提供了非常有效的存盤,
- 保證了多系統掛掉時 ledgers 的讀取一致性,
- 提供不同的 Bookies 之間均勻的 IO 分布的特性,
- 它在容量和吞吐量方面都具有水平伸縮性,能夠通過增加 bookies 立即增加容量到集群中,并提升吞吐量,
- Bookies 被設計成可以承載數千的并發讀寫的 ledgers, 使用多個磁盤設備,一個用于日志,另一個用于一般存盤,這樣 Bookies 可以將讀操作的影響和對于寫操作的延遲分隔開,
4.4.1 brokers 與 bookies 互動
下圖展示了 brokers 和 bookies 是如何互動的:
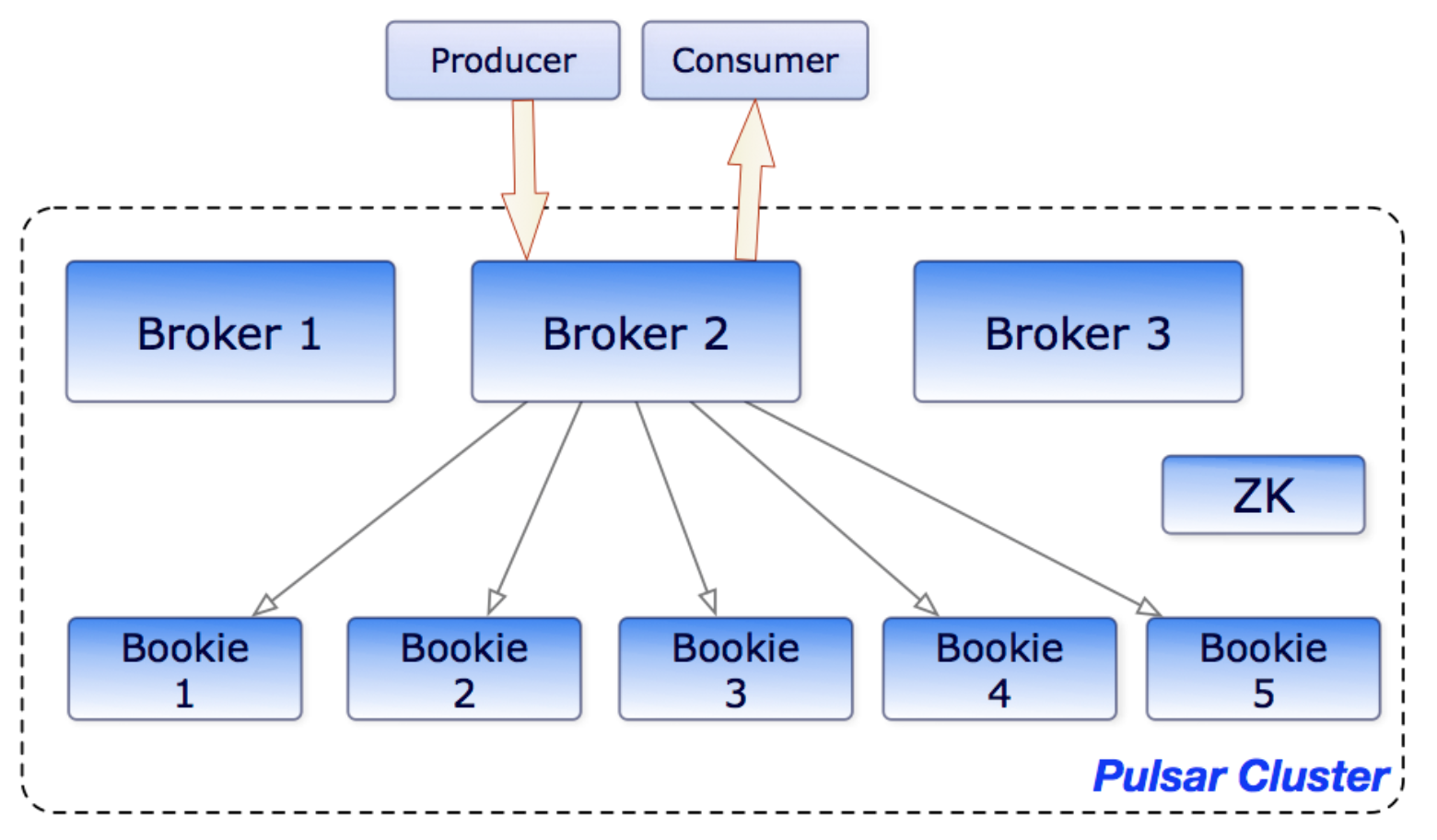
相比 Kafka、RocketMQ 等 MQ,Pulsar 基于 BookKeeper 的存盤、計算分離架構,使得 Pulsar 的訊息存盤可以獨立于 Broker 而擴展,
4.4.2 Ledgers
Ledger 是一個只追加的資料結構,并且只有一個寫入器,這個寫入器負責多個 BookKeeper 存盤節點(就是 Bookies)的寫入, Ledger 的條目會被復制到多個 bookies, Ledgers 本身有著非常簡單的語意:
- Pulsar Broker 可以創建 ledger,添加內容到 ledger 和關閉 ledger,
- 當一個 ledger 被關閉后,除非明確的要寫資料或者是因為寫入器掛掉導致 ledger 關閉,這個 ledger 只會以只讀模式打開,
- 最后,當 ledger 中的條目不再有用的時候,整個 legder 可以被洗掉(ledger 分布是跨 Bookies 的),
4.5 Pulsar 代理
Pulsar 客戶端和 Pulsar 集群互動的一種方式就是直連 Pulsar brokers , 然而,在某些情況下,這種直連既不可行也不可取,因為客戶端并不知道 broker 的地址, 例如在云環境或者 Kubernetes 以及其他類似的系統上面運行 Pulsar,直連 brokers 就基本上不可能了,
Pulsar proxy 為這個問題提供了一個解決方案,為所有的 broker 提供了一個網關,如果選擇運行了Pulsar Proxy,所有的客戶都會通過這個代理而不是直接與 brokers 通信,
4.6 Service discovery(服務發現)
連接到 Pulsar brokers 的客戶端需要能夠使用單個 URL 與整個 Pulsar 實體通信,
你可以使用自己的服務發現系統,如果你使用自己的系統,只有一個要求:當客戶端端點執行 HTTP 請求,比如 http://pulsar.us-west.example.com:8080,客戶端需要被重定向到一些活躍在集群所需的 broker,無論通過 DNS、HTTP 或 IP 重定向或其他手段,
五、Pulsar 相關組件
5.1 層級存盤
- Infinite Stream:以流的方式永久保存原始資料
- 磁區的容量不再受限制
- 充分利用云存盤或現有的廉價存盤(例如 HDFS)
- 資料統一表征:客戶端無需關心資料究竟存盤在哪里
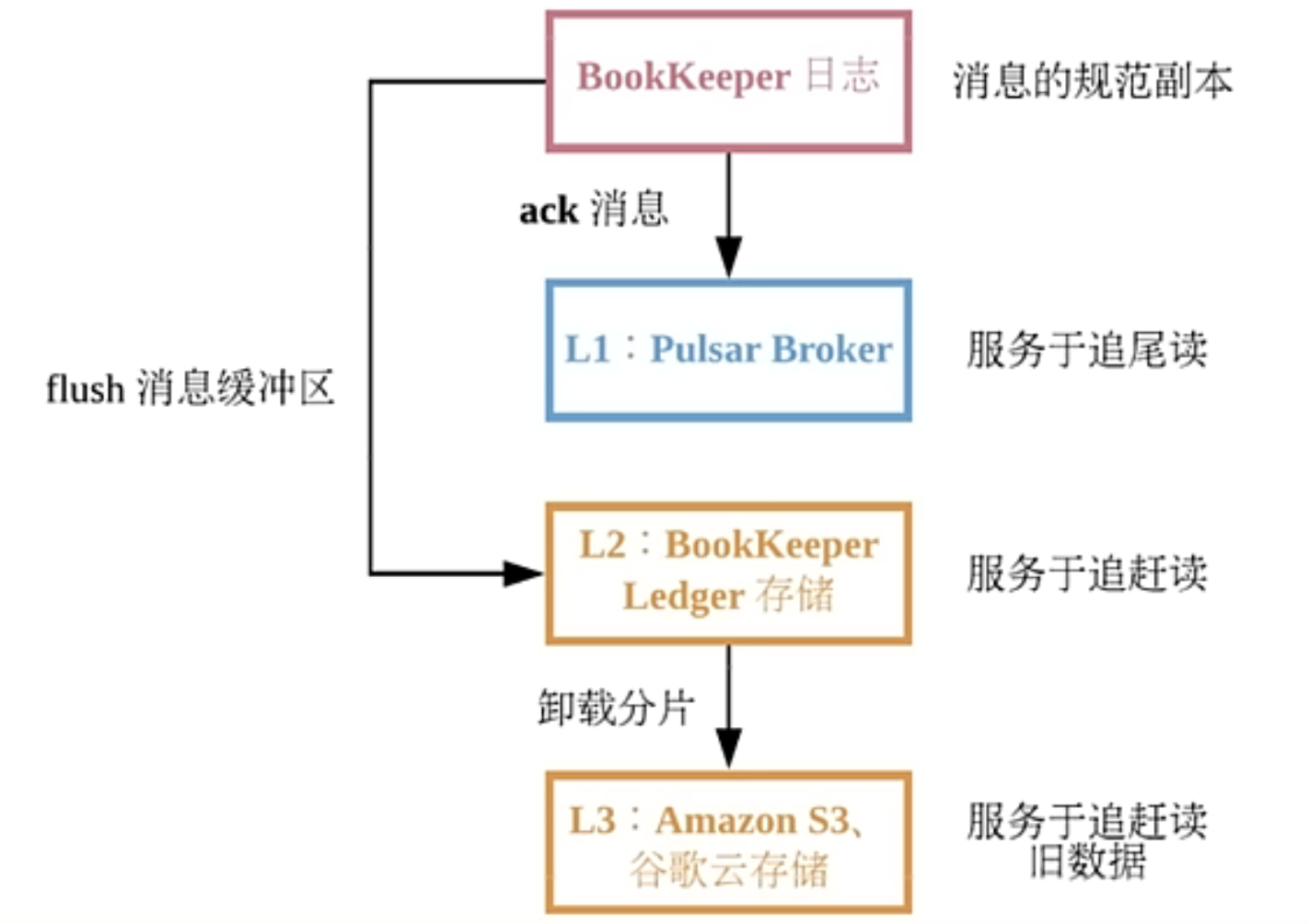
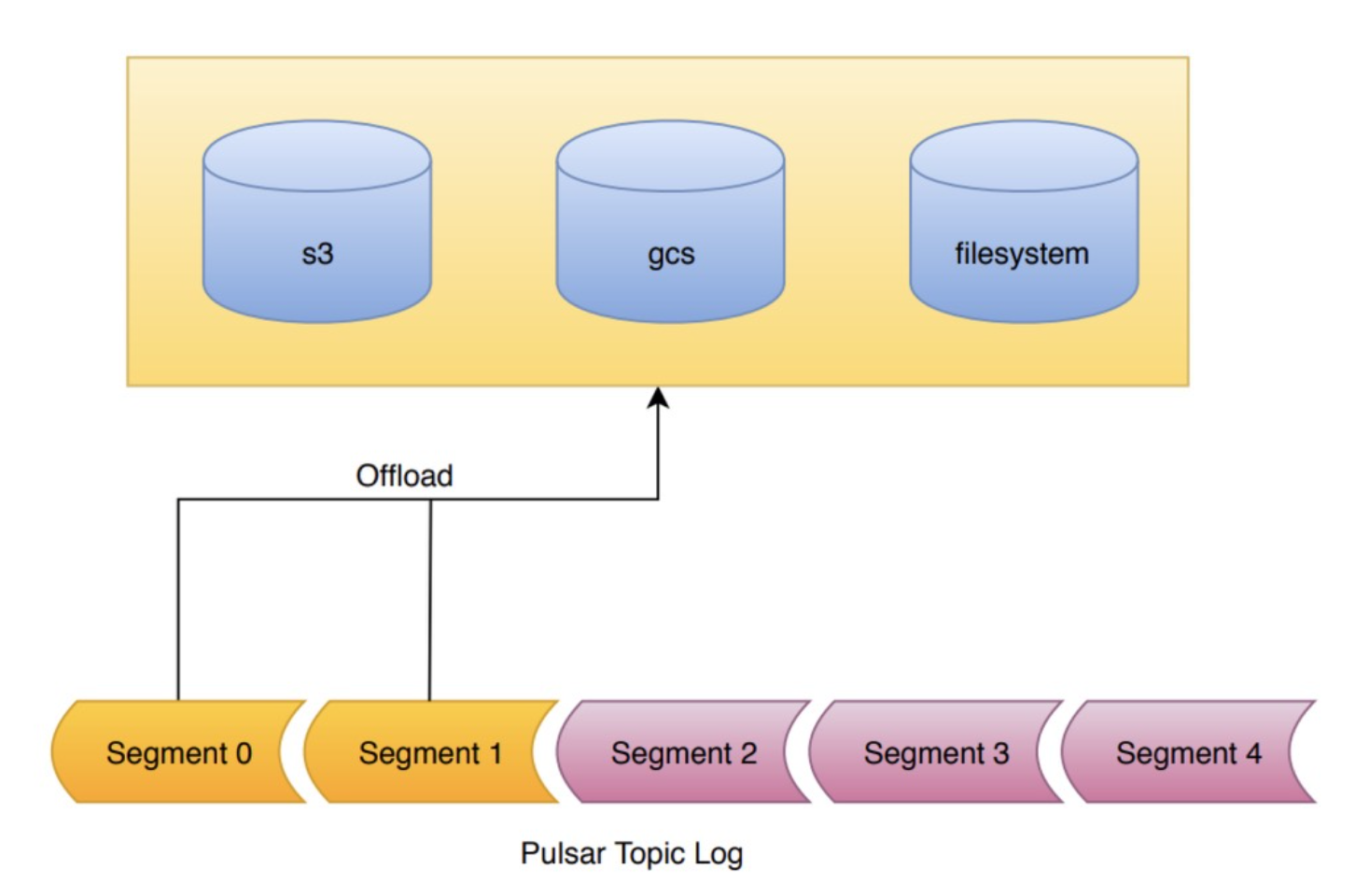
分層存盤的卸載機制就充分利用了這種面向分片式架構(segment oriented architecture), 當需要開始卸載資料時,訊息日志中的分片就依次被同步至分層存盤中, 直到訊息日志中所有的分片(除了當前分片之外)都已被寫入分層存盤后,
默認情況下寫入到 BookKeeper 的資料會復制三個物理機副本, 然而,一旦分片被封存在 BookKeeper 中后,該分片就不可更改并且可以復制到歸檔存盤中去, 長期存盤可以達到節省存盤費用的目的,通過使用 Reed-Solomon error correction 機制,還可減少物理備份數量,
5.2 Pulsar IO(Connector)連接器
- Pulsar IO 分為輸入(Input)和輸出(Output)兩個模塊,輸入代表資料從哪里來,通過 Source 實作資料輸入,輸出代表資料要往哪里去,通過 Sink 實作資料輸出,
- Pulsar 提出了 IO (也稱為 Pulsar Connector),用于解決 Pulsar 與周邊系統的集成問題,幫助用戶高效完成作業,
- 目前 Pulsar IO 支持非常多的連接集成操作:例如 HDFS、Spark、Flink、Flume、ES、HBase等,

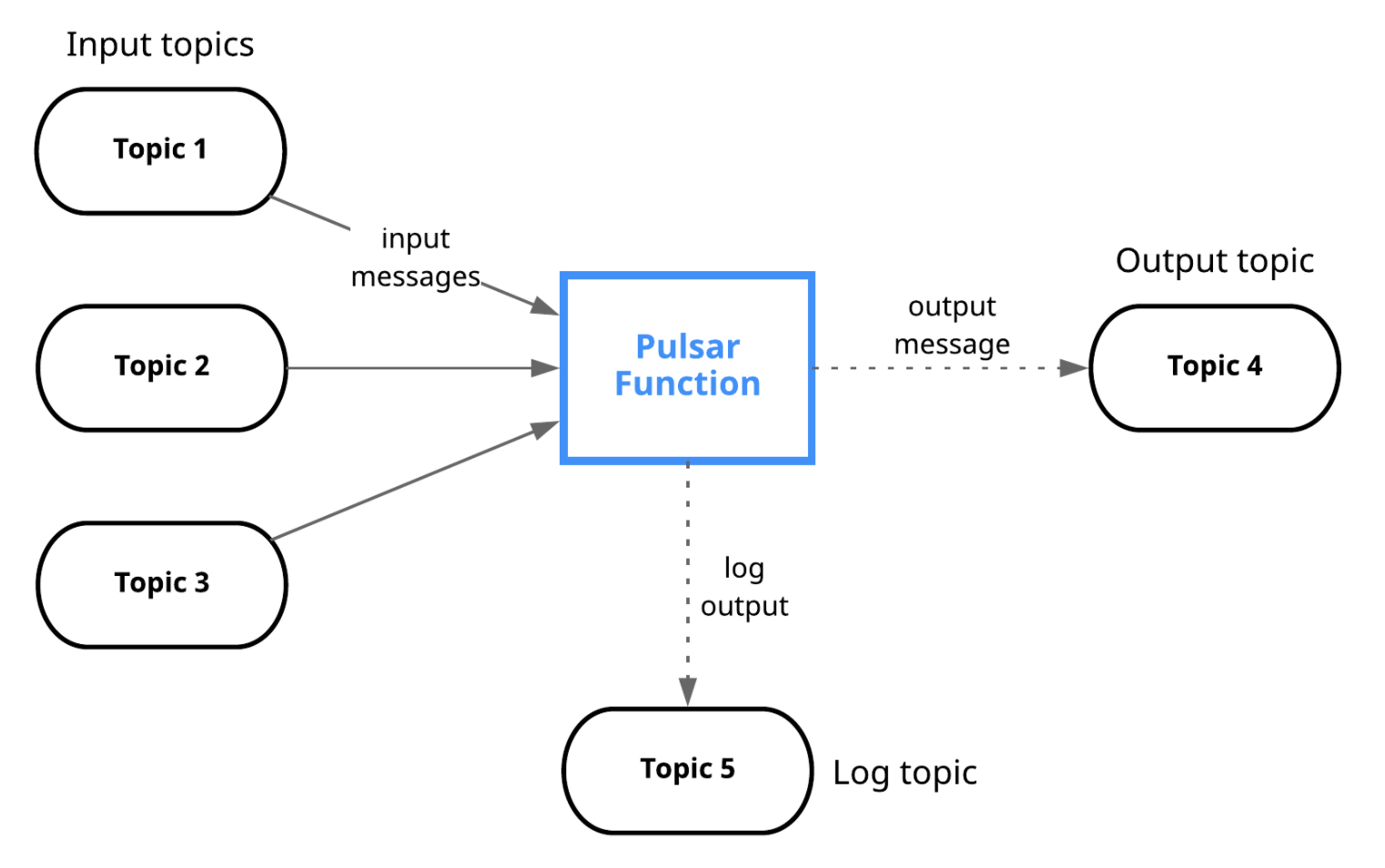
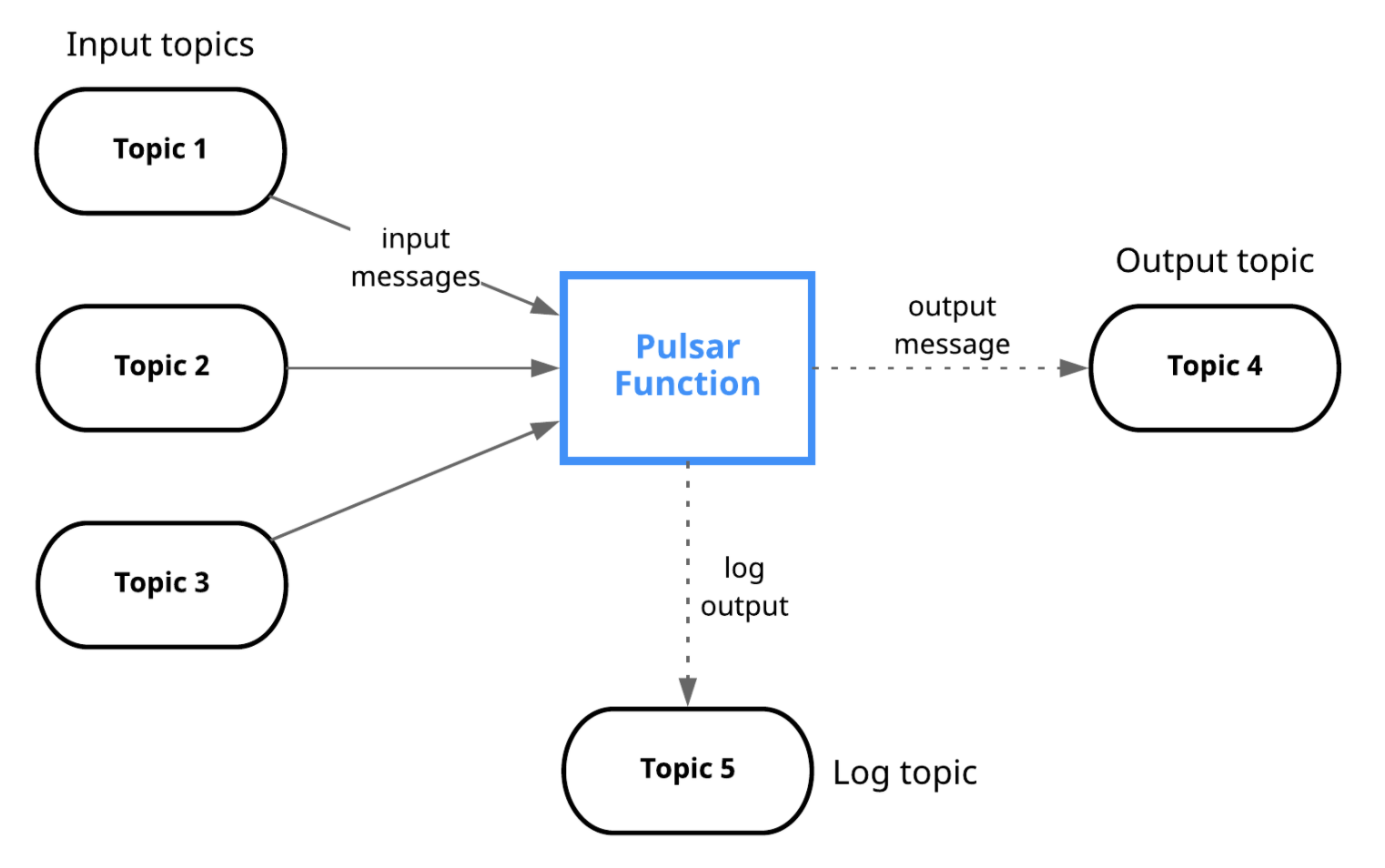
5.3 Pulsar Functions(輕量級計算框架)
- Pulsar Functions 是一個輕量級的計算框架,可以給用戶提供一個部署簡單、運維簡單、API 簡單的 FASS(Function as a service)平臺,Pulsar Functions 提供基于事件的服務,支持有狀態與無狀態的多語言計算,是對復雜的大資料處理框架的有力補充,
- Pulsar Functions 的設計靈感來自于 Apache Storm、Apache Heron、Apache Flink 這樣的流處理引擎,Pulsar Functions 將會拓展 Pulsar 和整個訊息領域的未來,使用 Pulsar Functions,用戶可以輕松地部署和管理 function,通過 function 從 Pulsar topic 讀取資料或者生產新資料到 Pulsar topic,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423507.html
標籤:其他