1、引言
本系列文章介紹如何修復 Elasticsearch 集群的常見錯誤和問題,
這是系列文章的第一篇,主要探討:Elasticsearch 磁盤使用率超過警戒水位線,怎么辦?
2、從磁盤常見錯誤說開去
當客戶端向 Elasticsearch 寫入檔案時候報錯:
cluster_block_exception [FORBIDDEN/12/index read-only / allow delete (api)];在 elasticsearch 的日志檔案中報錯如下:
flood stage disk watermark [95%] exceeded ... all indices on this node will marked read-only出現如上問題多半是:磁盤使用量超過警戒水位線,索引存在 read-only-allow-delete 索引塊資料,
3、報錯釋義
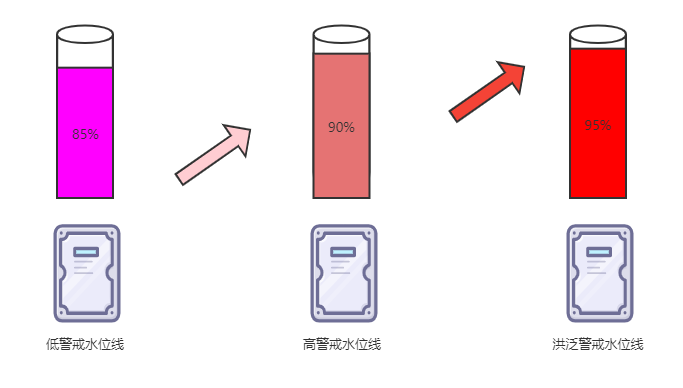
基礎認知:磁盤三個警戒水位線:
推薦閱讀:你不得不關注的 Elasticsearch Top X 關鍵指標,
| 屬性名 | 屬性值 | 含義 |
|---|---|---|
| cluster.routing.allocation.disk.watermark.low | 85% | 低警戒水位線 |
| cluster.routing.allocation.disk.watermark.high | 90% | 高警戒水位線 |
| cluster.routing.allocation.disk.watermark.flood_stage | 95% | 洪泛警戒水位線 |
文章第 2 小節的報錯表明資料節點的磁盤空間嚴重不足,并且已達到磁盤洪泛警戒水位線(磁盤使用率95%+,洪水泛濫的意思),
為防止磁盤變滿,當節點達到洪泛警戒水位線時,Elasticsearch 會阻止向該節點的任何索引分片寫入資料,后面還會具體介紹如何阻止,
如果該資料塊影響到相關的系統索引,可能會導致 Kibana 或者其他 Elastic Stack 功能不可用,
4、修復指南
4.1 cat shards 驗證分片分配
要驗證分片是否正在移出受影響的節點,請使用 cat shards API,
GET _cat/shards?v=true4.2 explain 驗證分配細節
如果分片仍然保留在節點上,請使用集群 allocation/explain API 獲取其分配狀態的說明,
GET _cluster/allocation/explain
{
"index": "my-index",
"shard": 0,
"primary": false,
"current_node": "my-node"
}如上 API幾個引數解釋如下:
index: 對應索引,
shard:分片號,
primary:是否主分片,
current_node: 節點名稱,
四個引數需要結合業務實際進行修改,
4.3 恢復寫入,可以上調磁盤警戒水位線,
要立即恢復寫入操作,你可以暫時上調磁盤警戒水位并移除寫入塊,
如下命令列是集群層面更新設定的操作,
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": "90%",
"cluster.routing.allocation.disk.watermark.high": "95%",
"cluster.routing.allocation.disk.watermark.flood_stage": "97%"
}
}索引塊的五種不同狀態如下:
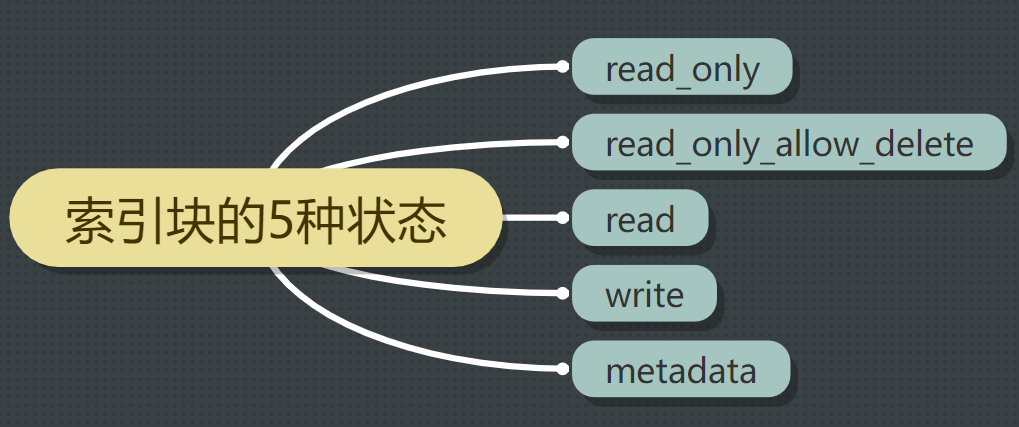
狀態一:index.blocks.read_only
設定為 "true"可以使索引和索引元資料只讀,"false "可以允許寫入和元資料改變,
狀態二:index.blocks.read_only_allow_delete
類似于index.blocks.read_only,但也允許洗掉索引釋放磁盤資源,
基于磁盤的分片分配器(The disk-based shard allocator)可以自動添加和洗掉index.blocks.read_only屬性的資料塊,
這里依然會引申出洗掉索引檔案和洗掉索引本身的區別等知識點:
(1)洗掉索引檔案會出現洗掉后磁盤使用率反而增加的現象,因為洗掉的本質是 version 的 update;只有洗掉索引才相當于物理洗掉,會立即釋放磁盤空間,
(2)當 index.blocks.read_only_allow_delete 被設定為true時,洗掉檔案是不允許的,僅允許洗掉索引,
(3)當磁盤使用率達到洪泛警戒水位線 95% 時,Elasitcsearch 會強制所有包含分片資料的索引的資料庫設定為:index.blocks.read_only_allow_delete 屬性,
(4)當磁盤使用率低于高警戒水位線 90% 時,index.blocks.read_only_allow_delete 屬性會自動釋放,
狀態三:index.blocks.read
設定為 "true",代表禁止對索引進行讀操作,
狀態四:index.blocks.write
設定為 "true "代表禁止對索引的資料寫入操作,
與read_only不同,這個設定并不影響元資料,例如,你可以用一個 write 塊關閉一個索引,但是你不能用一個 read_only 塊關閉一個索引,
狀態五:index.blocks.metadata
設定為 "true "代表禁用索引元資料的讀寫,
所以,如下的設定本質上是破除磁盤洪泛警戒水位線 95% 的 index.blocks.read_only_allow_delete 的限制,讓索引繼續可以寫入資料,
個人評價:應急可以用,
PUT */_settings?expand_wildcards=all
{
"index.blocks.read_only_allow_delete": null
}4.4 長期解決方案
作為長期解決方案,我們建議您將節點添加到受影響的資料層或升級現有節點實作節點磁盤擴容以增加磁盤空間,
比如:data_hot 熱節點爆滿,建議:
添加新的熱節點
為已有熱節點磁盤擴容,
要釋放額外的磁盤空間,你可以使用洗掉索引 API 洗掉不需要的索引,
DELETE my-index4.5 重置磁盤警戒水位線操作
當長期解決方案到位時,可使用如下命令列重置磁盤警戒水位線,
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.disk.watermark.low": null,
"cluster.routing.allocation.disk.watermark.high": null,
"cluster.routing.allocation.disk.watermark.flood_stage": null
}
}5、小結
為避免磁盤使用率吃緊的問題,建議如下:
第一:“不等下雨天之前就修好屋頂”,而不是“下了雨之后應急修補屋頂”,
第二:做好磁盤使用率監控和預警操作,
第三:提前規劃設定 total_shards_per_node 引數,以使得各個節點分片分配數相對均衡,
你在磁盤方面遇到哪些問題?如何解決的?歡迎留言反饋討論,
和你一起,死磕 Elasticsearch!
參考
https://stackoverflow.com/questions/50609417/elasticsearch-error-cluster-block-exception-forbidden-12-index-read-only-all
https://www.elastic.co/guide/en/elasticsearch/reference/current/fix-common-cluster-issues.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.16/index-modules-blocks.html
推薦
1、重磅 | 死磕 Elasticsearch 方法論認知清單(2021年國慶更新版)
2、Elasticsearch 7.X 進階實戰私訓課(口碑不錯)
3、如何系統的學習 Elasticsearch ?
更短時間更快習得更多干貨!
已帶領88位球友通過 Elastic 官方認證!

比同事搶先一步學習進階干貨!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423506.html
標籤:其他