目錄
什么是邏輯回歸?
Sigmoid 函式
似然函式
梯度下降
判定邊界
損失函式
邏輯回歸優點
邏輯回歸缺點
代碼實作
Logistic Regression引數詳解
正則化選擇引數:penalty
優化演算法選擇引數:solver
其他引數
代碼案例
結果顯示
每文一語
什么是邏輯回歸?
邏輯回歸演算法是用來解決分類問題的,回歸與分類的區別在于:回歸所預測的目標量的取值是連續的(例如房屋的價格);而分類所預測的目標變數的取值是離散的(例如判斷腫瘤大小是否為惡性),
如圖所示,X為資料點-腫瘤的大小,Y為觀測值-是否為惡性腫瘤(0良性腫瘤,1惡性腫瘤),通過構建線性回歸模型,即可根據腫瘤大小,預測是否為惡性腫瘤,hθ(x)≥.05為惡性,hθ(x)<0.5為良性,
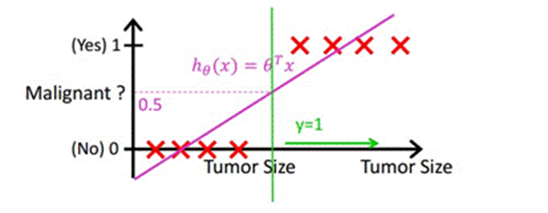
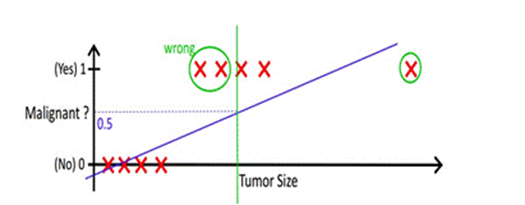
那有的人就會提出疑問,邏輯回歸可以做分類,那么線性回歸可不可以做分類呢?答案是可以,但是線性回歸的魯棒性(穩定和可靠)很差,如下圖所示,因最右邊噪點的存在,使回歸模型在訓練上表現很差,這主要是由于線性回歸在整個實數域內敏感度一致,而分類范圍,需要在[0,1],
邏輯回歸就是一種減小預測范圍,將預測值限定為[0,1]間的一種回歸模型,此時引入了一個sigmoid函式,這個函式的性質,非常好的滿足了,函式的定義域x的輸入是全體實數,而值域輸出y總是[0,1],以一種概率的形式表示. 并且當x=0的時,y=0.5, 這是決策邊界,
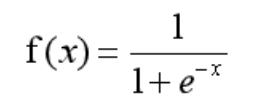
Sigmoid 函式
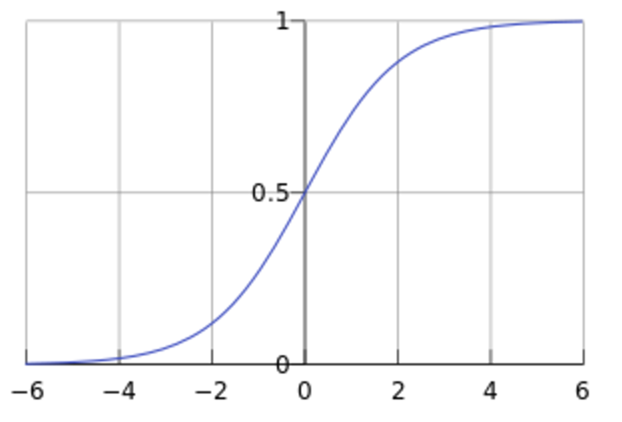
Sigmoid 函式在有個很漂亮的“S”形,如下圖所示:
對于線性回歸的情況,方程如下:
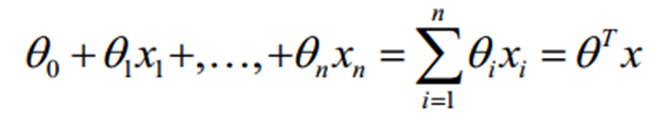
構造預測函式為:取值在[0,1]
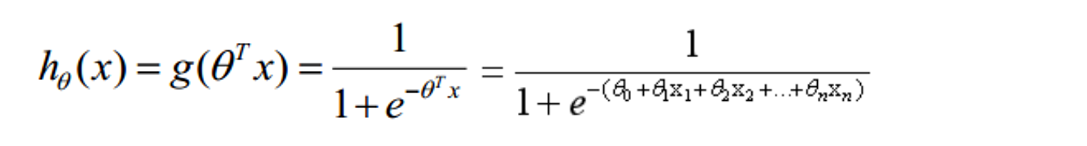
LogisticRegression回歸模型在Sklearn.linear_model子類下,呼叫sklearn邏輯回歸演算法步驟比較簡單,即:
(1) 匯入模型,呼叫邏輯回歸LogisticRegression()函式,
(2) fit()訓練,呼叫fit(x,y)的方法來訓練模型,其中x為資料的屬性,y為所屬型別,
(3) predict()預測,利用訓練得到的模型對資料集進行預測,回傳預測結果,
似然函式
最大似然估計就是通過已知結果去反推最大概率導致該結果的引數,極大似然估計是概率論在統計學中的應用,它提供了一種給定觀察資料來評估模型引數的方法,即 “模型已定,引數未知”,通過若干次試驗,觀察其結果,利用實驗結果得到某個引數值能夠使樣本出現的概率為最大,則稱為極大似然估計,邏輯回歸是一種監督式學習,是有訓練標簽的,就是有已知結果的,從這個已知結果入手,去推導能獲得最大概率的結果引數,只要我們得出了這個引數,那我們的模型就自然可以很準確的預測未知的資料了,
梯度下降
當我們確定了目標之后,我們就需要一個演算法來解決問題,現在最常用也比較好用的就是梯度下降,
我們先來看看官網是怎么介紹梯度下降的:梯度的本意是一個向量(矢量),表示某一函式在該點處的方向導數沿著該方向取得最大值,即函式在該點處沿著該方向(此梯度的方向)變化最快,變化率最大(為該梯度的模),
大白話理解:就是你現在蒙眼在山頂要下山,你肯定要順著山的一側一步一步的往下挪是把,山的一側就是梯度的,你每往下挪一點,就是在下降,當你達到山底的時候就成功了,
稍微專業點的:我們對一個多元函式求偏導,會得到多個偏導函式.這些導函陣列成的向量,就是梯度.我們用梯度下降是用來求解一個損失函式的最小值,所謂下降實際上是這個損失函式的值在下降,
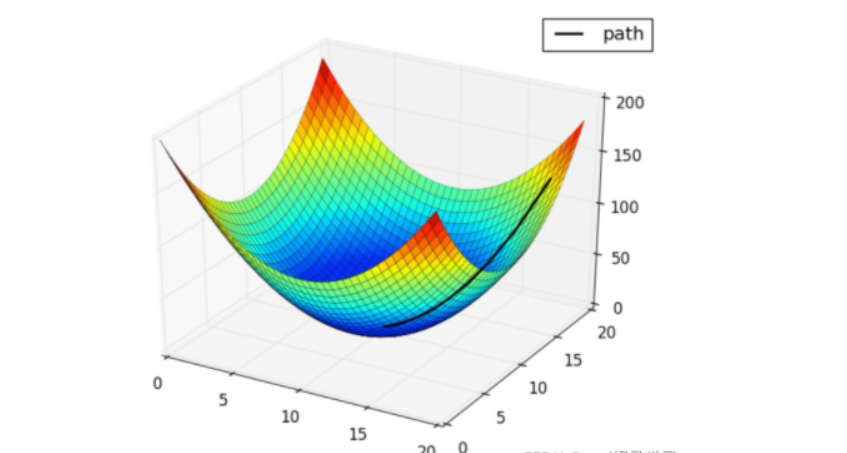
在梯度下降的演算法中,還有兩個比較重要的點叫做學習率和步數,
學習率是指你在下山的程序中每走的一步大小,你要是厲害能一步跨到山底也算是你厲害,當然你也有可能跨到對面山上,所以學習率我們在設定的時候就要設定的稍微小點,當然也別太小了,這樣學習的會很慢,學習率是自己設定的,比如0.01,
迭代次數就是指你在下山程序中你要走多少步,小了的話你可能沒有走到山底,多了的話可能你就會在山底來回的走,
學習率和迭代次數都是自定義的,需要通過經驗和實際操作去驗證和設定,最好在運行代碼的時候列印出來,這個就會看到收斂的情況,當很長一段時間內,收斂的效果已經不明顯了,基本就到頭了,
梯度下降有三種方法:
批量梯度下降BGD(Batch Gradient Descent):優點:會獲得全域最優解,易于并行實作,缺點:更新每個引數時需要遍歷所有的資料,計算量會很大并且有很多的冗余計算,導致當資料量大的時候每個引數的更新都會很慢,
隨機梯度下降SGD:優點:訓練速度快;缺點:準確率下降,并不是全域最優,不易于并行實作,它的具體思路是更新沒一個引數時都是用一個樣本來更新,(以高方差頻繁更新,優點是使得sgd會跳到新的和潛在更好的區域最優解,缺點是使得收斂到區域最優解的程序更加的復雜)
small batch梯度下降:結合了上述兩點的優點,每次更新引數時僅使用一部分樣本,減少了引數更新的次數,可以達到更加穩定的結果,一般在深度學習中采用這種方法,
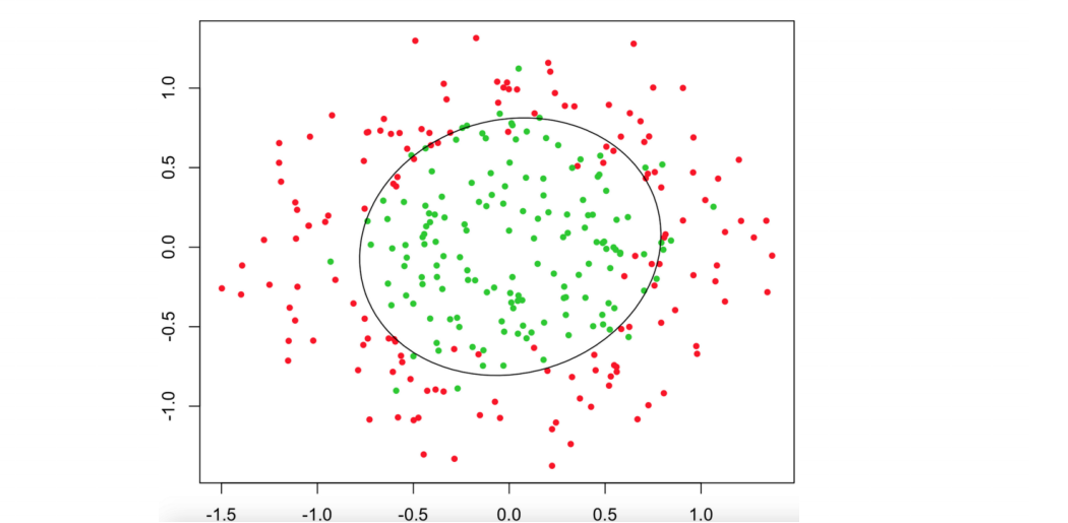
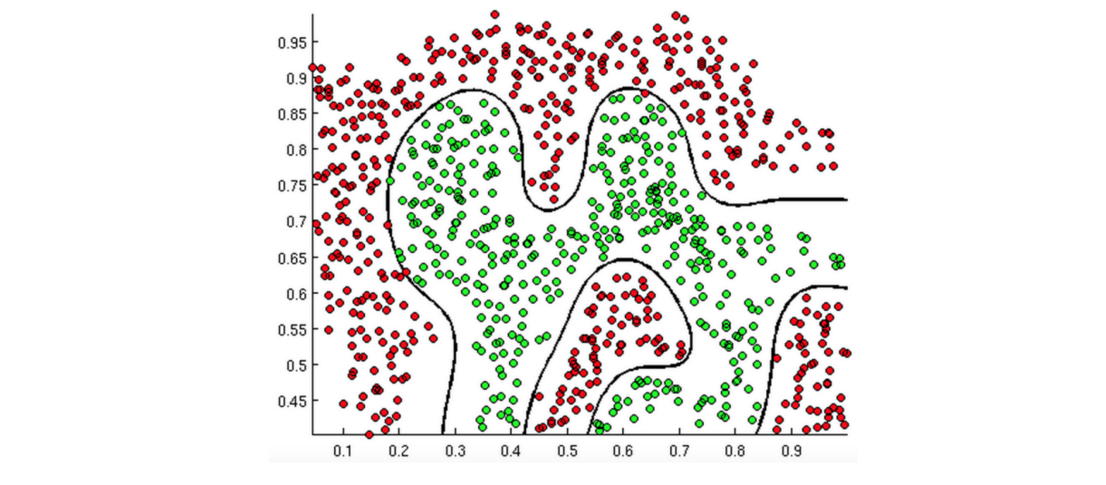
判定邊界
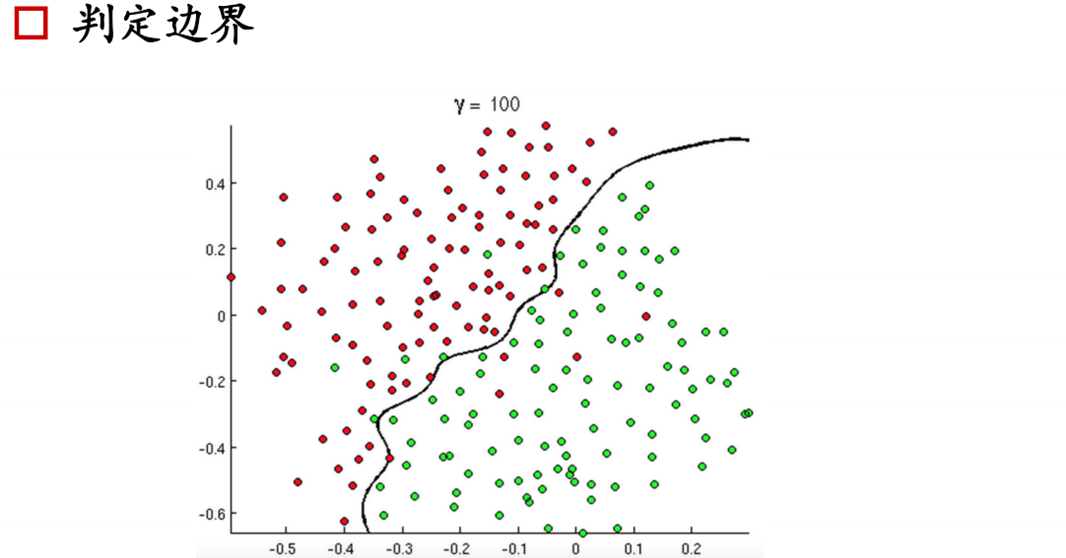
通過上述的邊界,應該也可以了解到邏輯回歸的原理了,很容易想到我們的支持向量機采用的超平面,而邏輯回歸則是使用的線性可分,那么必然會有損失函式

損失函式
損失函式用來評價模型的預測值和真實值不一樣的程度,損失函式越好,通常模型的性能越好,不同的模型用的損失函式一般也不一樣,
損失函式分為經驗風險損失函式和結構風險損失函式,經驗風險損失函式指預測結果和實際結果的差別,結構風險損失函式是指經驗風險損失函式加上正則項,
通俗點講,損失函式 = 代價函式 = 目標函式,它們三個是一個意思,
但是它們之間還是有細微的差別的,
損失函式(Loss Function )是定義在單個樣本上的,算的是一個樣本的誤差,
代價函式(Cost Function )是定義在整個訓練集上的,是所有樣本誤差的平均,也就是損失函式的平均,
目標函式:目標函式跟它倆有聯系,但不是一個意思,目標函式是一個最優化函式,它是由經驗風險+結構風險(也就是Cost Function + 正則化項)構成,
比如說:我們需要優化模型,我們得有個目標把,比如說我們誤差不能大于0.1 ,那這個0.1就是我們的目標函式,但是技術不行,最后只能把誤差維持在0.2,那么0.1就是目標函式,0.2就是損失函式,當技術好的情況下,將誤差降低在0.1 那么損失=目標,
下面介紹下 邏輯回歸中常用的損失函式,邏輯回歸主要是是分類模型,所以用的也都是分類方面的損失函式:
1)交叉熵損失:上面基本也都介紹了就不多說了,
2)Hinge Loss/多分類 SVM 損失:簡言之,在一定的安全間隔內(通常是 1),正確類別的分數應高于所有錯誤類別的分數之和,因此 hinge loss 常用于最大間隔分類(maximum-margin classification),最常用的是支持向量機,
盡管不可微,但它是一個凸函式,因此可以輕而易舉地使用機器學習領域中常用的凸優化器,
邏輯回歸優點
一是邏輯回歸的演算法已經比較成熟,預測較為準確;
二是模型求出的系數易于理解,便于解釋,尤其在銀行業,80%的預測是使用邏輯回歸;
三是結果是概率值;
四是訓練快,

邏輯回歸缺點
分類較多的y都不是很適用;(多分類不適用)
對于自變數的多重共線性比較敏感,所以需要利用因子分析或聚類分析來選擇代表性的自變數;(要做特征篩選)
另外預測結果呈現S型,兩端概率變化小,中間概率變化大比較敏感,導致很多區間的變數的變化對目標概率的影響沒有區分度,無法確定閾值,
總結一下:回歸假設資料服從伯努利分布,通過極大似然函式的方法,運用梯度下降來求解引數,最終達到資料二分類的目的,
代碼實作
Logistic Regression引數詳解
LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
verbose=0, warm_start=False)其中,引數 penalty 表示懲罰項( L1 、 L2 值可選
L1 向量中各元素絕對值的和,作用是產生少量的特征,而其他特征都是0,常用于特征選擇;
L2向量中各個元素平方之和再開根號,作用是選擇較多的特征,使他們都趨近于0,);
C值的目標函式約束條件:s.t.||w||1<C,默認值是0,C值越小,則正則化強度越大,
正則化選擇引數:penalty
在調參時如果我們主要的目的只是為了解決過擬合,一般penalty選擇L2正則化就夠了,但是如果選擇L2正則化發現還是過擬合,即預測效果差的時候,就可以考慮L1正則化,另外,如果模型的特征非常多,我們希望一些不重要的特征系數歸零,從而讓模型系數稀疏化的話,也可以使用L1正則化,
penalty引數的選擇會影響我們損失函式優化演算法的選擇,即引數solver的選擇,如果是L2正則化,那么4種可選的演算法{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’}都可以選擇,
但是如果penalty是L1正則化的話,就只能選擇‘liblinear’了,這是因為L1正則化的損失函式不是連續可導的,而{‘newton-cg’, ‘lbfgs’,‘sag’}這三種優化演算法時都需要損失函式的一階或者二階連續導數,而‘liblinear’并沒有這個依賴,
優化演算法選擇引數:solver
solver引數決定了我們對邏輯回歸損失函式的優化方法,有4種演算法可以選擇,分別是:
a) liblinear:使用了開源的liblinear庫實作,內部使用了坐標軸下降法來迭代優化損失函式,
b) lbfgs:擬牛頓法的一種,利用損失函式二階導數矩陣即海森矩陣來迭代優化損失函式,
c) newton-cg:也是牛頓法家族的一種,利用損失函式二階導數矩陣即海森矩陣來迭代優化損失函式,
d) sag:即隨機平均梯度下降,是梯度下降法的變種,和普通梯度下降法的區別是每次迭代僅僅用一部分的樣本來計算梯度,適合于樣本資料多的時候,SAG是一種線性收斂演算法,這個速度遠比SGD快,關于SAG的理解,參考博文線性收斂的隨機優化演算法之 SAG、SVRG(隨機梯度下降)
從上面的描述可以看出,newton-cg, lbfgs和sag這三種優化演算法時都需要損失函式的一階或者二階連續導數,因此不能用于沒有連續導數的L1正則化,只能用于L2正則化,而liblinear通吃L1正則化和L2正則化,
同時,sag每次僅僅使用了部分樣本進行梯度迭代,所以當樣本量少的時候不要選擇它,而如果樣本量非常大,比如大于10萬,sag是第一選擇,但是sag不能用于L1正則化,所以當你有大量的樣本,又需要L1正則化的話就要自己做取舍了,要么通過對樣本采樣來降低樣本量,要么回到L2正則化,
newton-cg, lbfgs和sag這三種優化演算法時都需要損失函式的一階或者二階連續導數,因此不能用于沒有連續導數的L1正則化,只能用于L2正則化,而liblinear通吃L1正則化和L2正則化,
其他引數
這里的引數只做介紹,一般也不需要除錯
sag每次僅僅使用了部分樣本進行梯度迭代,所以當樣本量少的時候不要選擇它,而如果樣本量非常大,比如大于10萬,sag是第一選擇,
但是sag不能用于L1正則化,所以當你有大量的樣本,又需要L1正則化的話就要自己做取舍了,要么通過對樣本采樣來降低樣本量,要么回到L2正則化,
對于多分類問題,只有 'newton-cg'、'sag'、'saga' 和 'lbfgs' 能夠處理多項損失,
而 'liblinear' 面對多分類問題,得先把一種類別作為一個類別,剩余的所有類別作為另外一個類別,依次類推,遍歷所有類別,進行分類,
max_iter: int, default: 100 ——最大迭代次數,當選擇newton - cg, sag and lbfgs這三種演算法時才能用,multi_class: str, {‘ovr’, ‘multinomial’}, default: ‘ovr’ ——指定對于多分類問題的策略,可以為如下的值,
‘ovr’ :采用one - vs - rest策略,OvR的思想很簡單,無論你是多少元邏輯回歸,我們都可以看做二元邏輯回歸,
具體做法是,對于第K類的分類決策,我們把所有第K類的樣本作為正例,除了第K類樣本以外的所有樣本都作為負例,
然后在上面做二元邏輯回歸,得到第K類的分類模型,其他類的分類模型獲得以此類推,T-1
‘multinomial’:many-vs-many(MvM) 直接采用多分類邏輯回歸策略,如果模型有T類,我們每次在所有的T類樣本里面選擇兩類樣本出來,
不妨記為T1類和T2類,把所有的輸出為T1和T2的樣本放在一起,把T1作為正例,T2作為負例,進行二元邏輯回歸,得到模型引數,我們一共需要T(T-1)/2次分類,
從上面的描述可以看出OvR相對簡單,但分類效果相對略差(這里指大多數樣本分布情況,某些樣本分布下OvR可能更好),而MvM分類相對精確,但是分類速度沒有OvR快,
'auto' 顧名思義根據實際情況,自動選擇,它主要依據 solver 引數來決定,邏輯為如果 solver 為 liblinear,multi_class 為 ovr,如果分類類別大于 2,multi_class 為 multinomial,否則為 ovr
warm_start: bool, default: False ——如果為True,那么使用前一次訓練結果繼續訓練,否則從頭開始訓練,n_jobs: int, default: 1 ——指定任務并行時的CPU數量,如果為 - 1則使用所有了用的CPU,
一般來說,我們知道這些引數所使用的的場景,那么就會少走一些坑,比如我們知道L1,L2正則項的意義是什么,L2主要解決過擬合,L1特征選取,也可以解決過擬合,默認是L2
代碼案例
具體的代碼步驟,我這里就不一一的做詳細的解釋了,因為我喜歡在jupyter notebook中機器學習,每一步都可以知道如何優化,下面的案例我首先通過邏輯回歸進行調參,并使用相關系數進行特征選取,然后得出的效果分數可以達到91%,這比不做特征選取要好很多,隨后我又使用邏輯回歸自帶的特征評估權重做了一次選取,最后效果有所提升,
feature_weight = model.coef_.tolist()[0]
feature_name = X_name
feature_sort = pd.Series(data = feature_weight ,index = feature_name)
feature_sort = feature_sort.sort_values(ascending = False)
print(feature_sort.index)
plt.figure(figsize=(10,8))
sns.barplot(feature_sort.values,feature_sort.index, orient='h')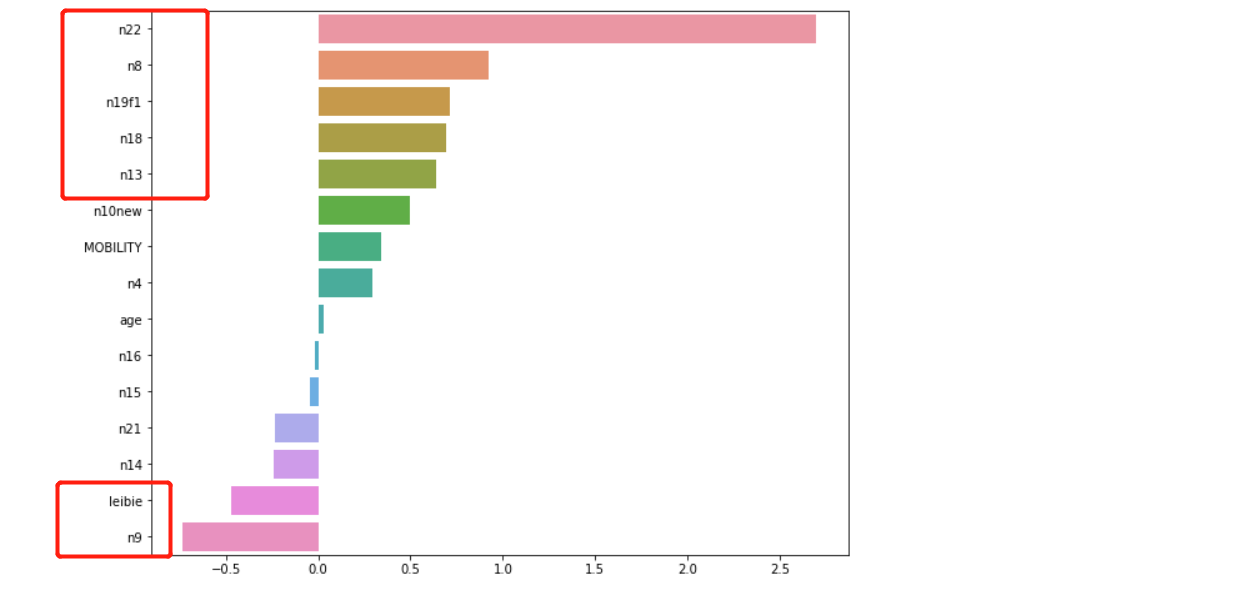
選取了8個重要的特征
完整代碼如下,由于資料集是科研的資料,這里就不做匯入說明了
# 匯入資料 分割資料
df=**************不做展示***********************
# # 特征篩選(經過一番測驗,不需要進行特征篩選)
# X_name=df.corr()[["n23"]].sort_values(by="n23",ascending=False).iloc[1:9].index.values.astype("U")
# X_name=feature_sort.index[:1]
# 測驗出來的最佳特征!!!!!!!!
X_name=['n22', 'n8', 'n19f1', 'n18', 'n13', 'n10new','n9','leibie']
print(X_name)
X=df.loc[:,X_name]
# X=df.iloc[:,:-1]
y=df.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
# X_train
score = []
C_range = np.linspace(0.01, 30, 50)
for i in C_range:
clf = LogisticRegression(C=i,penalty="l2").fit(X_train, y_train)
score.append(clf.score(X_test, y_test))
print(max(score), C_range[score.index(max(score))])
best_C=C_range[score.index(max(score))]
#設定標題
plt. title(f' LogisticRegression {max(score)}')
#設定x軸標簽
plt. xlabel(' C')
#設定y軸標簽
plt. ylabel(' Score')
#添加圖例
# plt. legend()
plt.plot(C_range, score)
plt.show()
solvers = ["newton-cg", "lbfgs", "liblinear","sag"]
for solver in solvers:
clf = LogisticRegression(solver=solver,
C=best_C
).fit(X_train, y_train)
print("The accuracy under solver %s is %f" % (solver, clf.score(X_test, y_test)))
best_sover='liblinear'
model=LogisticRegression(C=11.02673469387755,penalty='l2',solver=best_sover)
# 訓練模型
model.fit(X_train,y_train)
# 預測值
y_pred = model.predict(X_test)
'''
評估指標
'''
# 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
print('預測資料的分類報告為:','\n',
classification_report(y_test,y_pred))
from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 預測正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,回傳兩列,第一列代表類別0,第二列代表類別1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真陽性標簽,就是說是分類里面的好的標簽,這個要看你的特征目標標簽是0,1,還是1,2
roc_auc = metrics.auc(fpr, tpr) #auc為Roc曲線下的面積
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #橫坐標是fpr
plt.ylabel('True Positive Rate') #縱坐標是tpr
plt.title('Receiver operating characteristic example')
plt.show()結果顯示
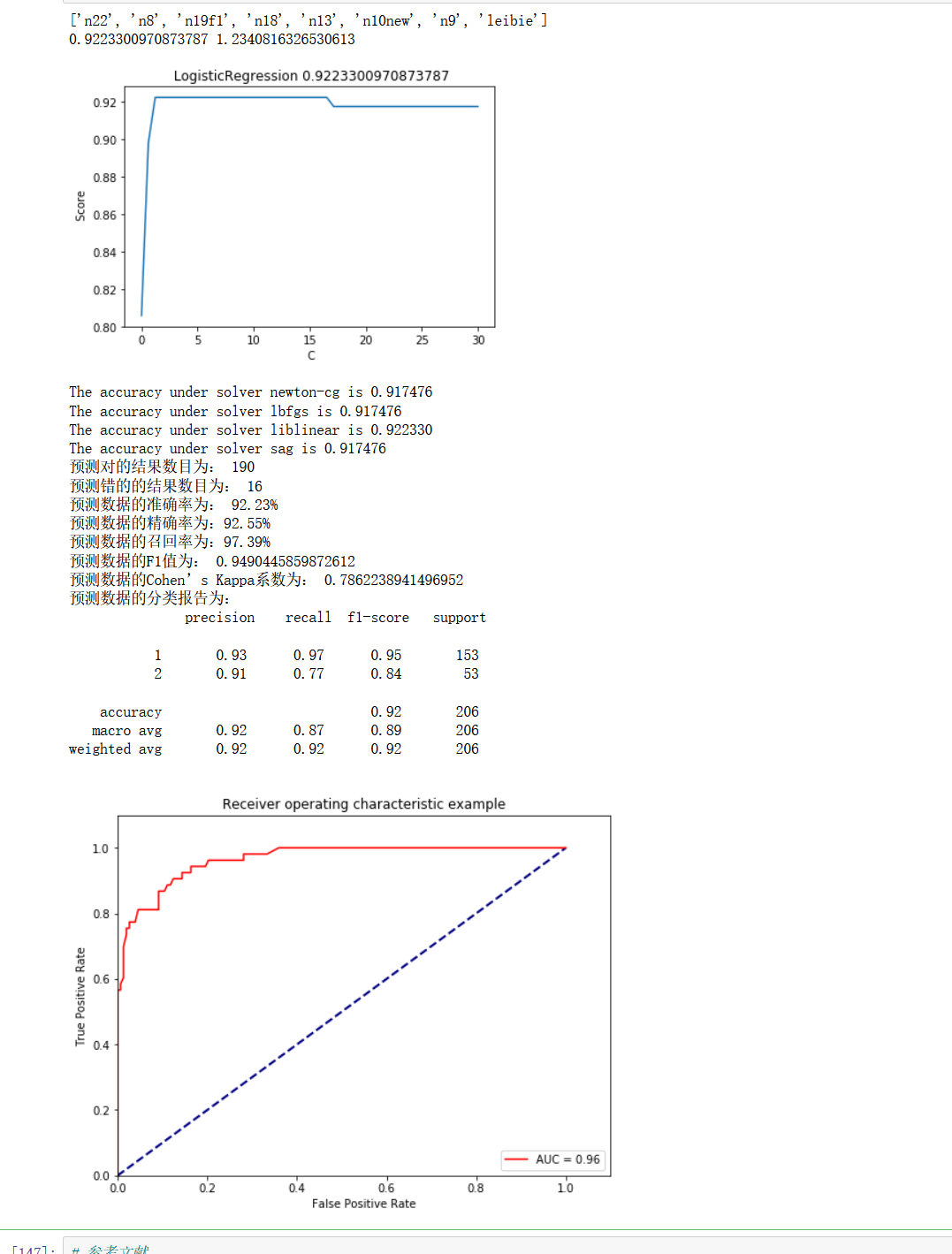
效果還是有所提升,通過反復的除錯,我們的邏輯回歸已經大功告成了!
每文一語
快樂是自己給的,而不是索取的!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423699.html
標籤:AI
上一篇:基礎工資提高至35萬美元、帶薪病假天數翻倍,亞馬遜、蘋果為留人才又出新動作
下一篇:用普通攝像頭測量距離