前言
讀完本文,你將了解到如下知識點:
- kafka 的消費者 和 消費者組
- 如何正確使用 kafka consumer
- 常用的 kafka consumer 配置
消費者 和 消費者組
- 什么是消費者?
顧名思義,消費者就是從kafka集群消費資料的客戶端,
如下圖,展示了一個消費者從一個topic中消費資料的模型
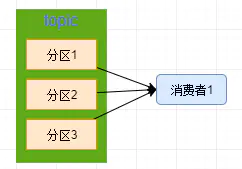
單個消費者模型存在的問題?
如果這個時候 kafka 上游生產的資料很快,
超過了這個消費者1的消費速度,
那么就會導致資料堆積,
產生一些大家都知道的蛋疼事情了,
那么我們只能加強消費者的消費能力,
所以也就有了我們下面來說的消費者組-
什么是消費者組?
所謂消費者組,其實就是一組消費者的集合,
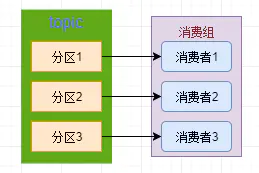
當我們看到下面這張圖是不是就特別舒服了,
我們采用了一個消費組來消費這個topic,
眾人拾柴火焰高,其消費能力那是按倍數遞增的,
所以這里我們一般來說都是采用消費者組來消費資料,
而不會是單消費者來消費資料的,
這里值得我們注意的是:- 一個
topic可以被 多個消費者組消費,
但是每個消費者組消費的資料是 互不干擾 的,
也就是說,每個消費組消費的都是 完整的資料 , - 一個磁區只能被 同一個消費組內 的一個
消費者消費,
而 不能拆給多個消費者 消費,
也就是說如果你某個 消費者組內的消費者數 比 該 Topic 的磁區數還多,
那么多余的消費者是不起作用的
- 一個
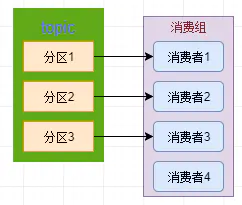
- 是不是一個 消費組 的 消費者 越多其消費能力就越強呢?
從圖3我們就很好的可以回答這個問題了,
我們可以看到消費者4是完全沒有消費任何的資料的,
所以如果你想要加強消費者組的能力,
除了添加消費者,磁區的數量也是需要跟著增加的,
只有這樣他們的并行度才能上的去,消費能力才會強,
-
為了提高 消費組 的 消費能力,我是不是可以隨便添加 磁區 和 消費者 呢?
答案當然是否定的啦,,,嘿嘿
我們看到圖2,一般來說我們建議消費者數量 和磁區數量是一致的,
當我們的消費能力不夠時,
就必須通過調整磁區的數量來提高并行度,
但是,我們應該盡量來避免這種情況發生,
比如:
現在我們需要在圖2的基礎上增加一個磁區4,
那么這個磁區4該由誰來消費呢?
這個時候kafka會進行磁區再均衡,
來為這個磁區分配消費者,磁區再均衡 期間該 Topic 是不可用的,
并且作為一個被消費者,
磁區數的改動將影響到每一個消費者組,
所以在創建topic的時候,我們就應該考慮好磁區數,
來盡量避免這種情況發生這里我們額外補充一點關于如何避免 磁區再均衡 的知識,
這里主要補充的是生產環境中因為不正確的配置引起的不需要的 磁區再均衡,
正常集群變動不再考慮范圍內:- 防止 因為未能及時發送心跳,導致Consumer 超時被踢出消費者組,
這里可以設定session.timeout.ms超時時間 和heartbeat.interval.ms心跳間隔
一般可以把 超時時間設定為 心跳間隔的 3倍, - Consumer消費時間過長導致的,
Consumer端如果無法在規定時間內消費完poll來的訊息,
那么就認為該消費者有問題,從而該消費者會自主離組,
所以我們可以設定max.poll.interval.ms比處理時間略長, - 從第二點我們還可能引申一點就是,如果集群經常發生 磁區在均衡,
那么你可能需要去觀察下消費者執行任務的耗時,
特別注意觀察下 GC 的占用時間
- 防止 因為未能及時發送心跳,導致Consumer 超時被踢出消費者組,
-
磁區分配程序
上面我們提到了為 磁區分配消費者,
那么我們現在就來看看分配程序是怎么樣的,確定 群組協調器
每當我們創建一個消費組,
kafka 會為我們分配一個 broker 作為該消費組的 coordinator(協調器)注冊消費者 并選出 leader consumer
當我們的有了 coordinator 之后,
消費者將會開始往該 coordinator上進行注冊,
第一個注冊的 消費者將成為該消費組的 leader,
后續的 作為 follower當 leader 選出來后,
他會從coordinator那里實時獲取磁區 和 consumer 資訊,
并根據磁區策略給每個consumer 分配 磁區,
并將分配結果告訴 coordinator,follower 消費者將從 coordinator 那里獲取到自己相關的磁區資訊進行消費,
對于所有的 follower 消費者而言,
他們只知道自己消費的磁區,
并不知道其他消費者的存在,至此,消費者都知道自己的消費的磁區,
磁區程序結束,
當發生 磁區再均衡 的時候,
leader 將會重復分配程序
實踐——kafka 消費者的使用
咱們以 java api 為例,下面是一個簡單的 kafka consumer
public static void main(String[] args) {
//consumer 的配置屬性
Properties props = new Properties();
///brokers 地址
props.put("bootstrap.servers", "localhost:9092");
//指定該 consumer 將加入的消費組
props.put("group.id", "test");
// 開啟自動提交 offset,關于offset提交,我們后續再來詳細說說
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
//指定序列化類
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
//創建 consumer
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//訂閱消費主題,這里一個消費者可以同時消費 foo 和 bar 兩個主題的資料
consumer.subscribe(Arrays.asList("foo", "bar"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
使用起來還是很簡單的,不過如果想要用好 consumer,
可能你還需要了解以下這些東西:
- 磁區控制策略
- consumer 的一些常用配置
- offset 的控制
ok,那么我們接下來一個個來看吧,,,
磁區控制策略
- 手動控制磁區
咱們先來說下最簡單的手動磁區控制,代碼如下:
String topic = "foo";
TopicPartition partition0 = new TopicPartition(topic, 0);
TopicPartition partition1 = new TopicPartition(topic, 1);
consumer.assign(Arrays.asList(partition0, partition1));
看起來只是把普通的訂閱方式修改成了訂閱 topic 指定的磁區,
其余的還是照常使用,不過這里也需要注意一下的是:
一般只作為獨立消費者,
也就是不能加入消費組,
或者說他本身就是作為一個消費組存在,
要保證這一點,我們只需要保證其group id是唯一的就可以了,對于
topic的磁區變動不敏感,
也就是說當topic新增了磁區,
磁區的資料將會發生改變,
但該消費組對此確是不感知的,依然照常運行,
所以很多時候需要你手動consumer.partitionsFor()去查看topic的磁區情況不要和
subscription混合使用
- 使用
partition.assignment.strategy進行磁區策略配置
這里的話 kafka 是自帶兩種磁區策略的,
為了方便理解,
我們以如下場景為例來進行解釋:
已知:
TopicA 有 3 個 partition(磁區):A-1,A-2,A-3;
TopicB 有 3 個 partition(磁區):B-1,B-2,B-3;
ConsumerA 和 ConsumerB 作為一個消費組 ConsumerGroup 同時消費 TopicA 和 TopicB
-
Range
該方式最大的特點就是會將連續的磁區分配給一個消費者,
根據示例,我們可以得出如下結論:ConsumerGroup 消費 TopicA 的時候:
ConsumerA 會分配到 A-1,A-2
ConsumerB 會分配到 A-3ConsumerGroup 消費 TopicB 的時候:
ConsumerA 會分配到 B-1,B-2
ConsumerB 會分配到 B-3所以:
ConsumerA 分配到了4個磁區: A-1,A-2,B-1,B-2
ConsumerB 分配到了2個磁區:A-3,B-3 -
RoundRobin
該方式最大的特點就是會以輪詢的方式將磁區分配給一個個消費者,
根據示例,我們可以得出如下結論:ConsumerGroup 消費 TopicA 的時候:
ConsumerA 分配到 A-1
ConsumerB 分配到 A-2
ConsumerA 分配到 A-3ConsumerGroup 消費 TopicB 的時候,
因為上次分配到了 ConsumerA,
那么這次輪到 ConsumerB了 所以:ConsumerB 分配到 B-1
ConsumerA 分配到 B-2
ConsumerB 分配到 B-3所以:
ConsumerA 分配到了4個磁區: A-1,A-3,B-2
ConsumerB 分配到了2個磁區:A-2,B-1,B-3
從上面我們也是可以看出這兩種策略的異同,
RoundRobin 相比較 Range 會使得磁區分配的更加的均衡,
也是經常使用的一種方式,
Range則重在對于消費者消費的資料和 磁區 關聯上了,
在一些特殊的場景可能會用到
-
StickyAssignor
這是Kafka 0.11.x 引入的一種磁區策略,
該磁區演算法的復雜度比較高,
筆者目前沒有研究,參考了一些博客和書籍,
整理如下:
該方式的特點:- 磁區的分配要盡可能均勻,
- 磁區的分配盡可能與上次分配的保持相同,
- 當兩者發生沖突時,第一個目標優先于第二個目標
之前的兩種策略在再均衡的時候都沒有考慮上次的磁區的分配情況,
該策略則對這一方面進行了補足,
如果你之前使用的是 RoundRobin 這種方式,
不妨換成 StickyAssignor 來試試, -
自定義的磁區策略
上面三種磁區策略是 kafka 默認自帶的策略,
雖然大多數情況下夠用了,
但是可能針對一些特殊需求,
我們也可以定義自己的磁區策略- Range磁區策略原始碼
如何自定義呢?
最好的方式莫過于看原始碼是怎么實作的,
然后自己依葫蘆畫瓢來一個,
所以我們先來看看 Range磁區策略原始碼,
如下,我只做了簡單的注釋,因為它本身也很簡單,
重點看下assign的引數以及回傳注釋就 ok了
- Range磁區策略原始碼
public class RangeAssignor extends AbstractPartitionAssignor{
//省略部分代碼,,,,
/**
* 根據訂閱者 和 磁區數量來進行磁區
* @param partitionsPerTopic: topic->磁區數量
* @param subscriptions: memberId 消費者id -> subscription 消費者資訊
* @return: memberId ->list<topic名稱 和 磁區序號(id)>
*/
@Override
public Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic, Map<String, Subscription> subscriptions) {
//topic -> list<消費者>
Map<String, List<String>> consumersPerTopic = consumersPerTopic(subscriptions);
//初始化 回傳結果
Map<String, List<TopicPartition>> assignment = new HashMap<>();
for (String memberId : subscriptions.keySet())
assignment.put(memberId, new ArrayList<TopicPartition>());
for (Map.Entry<String, List<String>> topicEntry : consumersPerTopic.entrySet()) {
//topic
String topic = topicEntry.getKey();
// 消費該topic的 consumer-id
List<String> consumersForTopic = topicEntry.getValue();
//topic 的磁區數量
Integer numPartitionsForTopic = partitionsPerTopic.get(topic);
if (numPartitionsForTopic == null)
continue;
Collections.sort(consumersForTopic);
//平均每個消費者分配的 磁區數量
int numPartitionsPerConsumer = numPartitionsForTopic / consumersForTopic.size();
//平均之后剩下的 磁區數
int consumersWithExtraPartition = numPartitionsForTopic % consumersForTopic.size();
//這里就是將連續磁區切開然后分配給每個消費者
List<TopicPartition> partitions = AbstractPartitionAssignor.partitions(topic, numPartitionsForTopic);
for (int i = 0, n = consumersForTopic.size(); i < n; i++) {
int start = numPartitionsPerConsumer * i + Math.min(i, consumersWithExtraPartition);
int length = numPartitionsPerConsumer + (i + 1 > consumersWithExtraPartition ? 0 : 1);
assignment.get(consumersForTopic.get(i)).addAll(partitions.subList(start, start + length));
}
}
return assignment;
}
}
- 自定義一個 磁區策略
這里先緩緩把,太簡單把,沒什么用,太復雜把,一時也想不出好的場景,
如果你有需求,歡迎留言,我們一起來實作
Consumer 常用配置
首先,我們都應該知道,最全最全的檔案應該是來自官網(雖然有時候可能官網找不到):
http://kafka.apachecn.org/documentation.html#newconsumerconfigs
嗯,以下內容來自 kafka權威指南 ,
請原諒我的小懶惰,,,后續有時間會把作業中的遇到的補充上
fetch.min.bytes
該屬性指定了消費者從服務器獲取記錄的最小位元組數,
broker 在收到消費者的資料請求時,
如果可用的資料量小于fetch.min.bytes 指定的大小,
那么它會等到有足夠的可用資料時才把它回傳給消費者,
這樣可以降低消費者和 broker 的作業負載,
因為它們在主題不是很活躍的時候(或者一天里的低谷時段),
就不需要來來回回地處理訊息,
如果沒有很多可用資料,但消費者的 CPU 使用率卻很高,
那么就需要把該屬性的值設得比默認值大,
如果消費者的數量比較多,
把該屬性的值設定得大一點可以降低broker 的作業負載,fetch.max.wait.ms
我們通過 fetch.min.bytes 告訴 Kafka,
等到有足夠的資料時才把它回傳給消費者,
而feth.max.wait.ms則用于指定 broker 的等待時間,默認是 500ms,
如果沒有足夠的資料流入 Kafka,
消費者獲取最小資料量的要求就得不到滿足,
最終導致 500ms 的延遲,
如果要降低潛在的延遲(為了滿足 SLA),
可以把該引數值設定得小一些,
如果fetch.max.wait.ms被設為 100ms,
并且fetch.min.bytes 被設為 1MB,
那么 Kafka 在收到消費者的請求后,
要么回傳 1MB 資料,
要么在100ms 后回傳所有可用的資料,
就看哪個條件先得到滿足,max.partition.fetch.bytes
該屬性指定了服務器從每個磁區里回傳給消費者的最大位元組數,它的默認值是 1MB,也就是說,KafkaConsumer.poll() 方法從每個磁區里回傳的記錄最多不超過 max.partition.fetch.bytes指定的位元組,如果一個主題有 20 個磁區和 5 個消費者,那么每個消費者需要至少 4MB 的可用記憶體來接收記錄,在為消費者分配記憶體時,可以給它們多分配一些,因為如果群組里有消費者發生崩潰,剩下的消費者需要處理更多的磁區,
max.partition.fetch.bytes 的值必須比 broker 能夠接收的最大訊息的位元組數(通過 max.message.size 屬性配置)大,否則消費者可能無法讀取這些訊息,導致消費者一直掛起重試,在設定該屬性時,另一個需要考慮的因素是消費者處理資料的時間,消費者需要頻繁呼叫poll() 方法來避免會話過期和發生磁區再均衡,如果單次呼叫 poll() 回傳的資料太多,消費者需要更多的時間來處理,可能無法及時進行下一個輪詢來避免會話過期,
如果出現這種情況,可以把max.partition.fetch.bytes 值改小,或者延長會話過期時間,session.timeout.ms
該屬性指定了消費者在被認為死亡之前可以與服務器斷開連接的時間,
默認是 3s,
如果消費者沒有在session.timeout.ms指定的時間內發送心跳給群組協調器,
就被認為已經死亡,
協調器就會觸發再均衡,
把它的磁區分配給群組里的其他消費者,
該屬性與heartbeat.interval.ms緊密相關,
heartbeat.interval.ms指定了 poll() 方法向協調器發送心跳的頻率,
session.timeout.ms則指定了消費者可以多久不發送心跳,
所以,一般需要同時修改這兩個屬性,
heartbeat.interval.ms必須比session.timeout.ms小,
一般是session.timeout.ms的三分之一,
如果session.timeout.ms是 3s,那么heartbeat.interval.ms應該是 1s,
把session.timeout.ms 值設得比默認值小,
可以更快地檢測和恢復崩潰的節點,
不過長時間的輪詢或垃圾收集可能導致非預期的再均衡,
把該屬性的值設定得大一些,
可以減少意外的再均衡,
不過檢測節點崩潰需要更長的時間,auto.offset.reset
該屬性指定了消費者在讀取一個沒有偏移量的磁區或者偏移量無效的情況下
(因消費者長時間失效,包含偏移量的記錄已經過時并被洗掉)該作何處理,
它的默認值是 latest,
意思是說,
在偏移量無效的情況下,
消費者將從最新的記錄開始讀取資料(在消費者啟動之后生成的記錄),
另一個值是earliest,
意思是說,
在偏移量無效的情況下,
消費者將從起始位置讀取磁區的記錄,enable.auto.commit
我們稍后將介紹幾種不同的提交偏移量的方式,
該屬性指定了消費者是否自動提交偏移量,默認值是true,
為了盡量避免出現重復資料和資料丟失,可以把它設為 false,
由自己控制何時提交偏移量,
如果把它設為true,還可以通過配置auto.commit.interval.ms屬性來控制提交的頻率,-
partition.assignment.strategy(這部分好像重復了 ~~~)
我們知道,磁區會被分配給群組里的消費者,
PartitionAssignor 根據給定的消費者和主題,
決定哪些磁區應該被分配給哪個消費者,
Kafka 有兩個默認的分配策略,Range
該策略會把主題的若干個連續的磁區分配給消費者,假設消費者 C1 和消費者 C2 同時訂閱了主題T1 和 主題 T2,并且每個主題有 3 個磁區,那么消費者 C1 有可能分配到這兩個主題的磁區 0 和磁區 1,而消費者 C2 分配到這兩個主題的磁區 2,因為每個主題擁有奇數個磁區,而分配是在主題內獨立完成的,第一個消費者最后分配到比第二個消費者更多的磁區,只要使用了 Range 策略,而且磁區數量無法被消費者數量整除,就會出現這種情況,RoundRobin
該策略把主題的所有磁區逐個分配給消費者,如果使用 RoundRobin 策略來給消費者 C1 和消費者C2 分配磁區,那么消費者 C1 將分到主題 T1 的磁區 0 和磁區 2 以及主題 T2 的磁區 1,消費者 C2 將分配到主題 T1 的磁區 1 以及主題 T2 的磁區 0 和磁區 2,一般來說,如果所有消費者都訂閱相同的主題(這種情況很常見),RoundRobin 策略會給所有消費者分配相同數量的磁區(或最多就差一個磁區),可以通過設定 partition.assignment.strategy 來選擇磁區策略,
默認使用的是org.apache.kafka.clients.consumer.RangeAssignor,這個類實作了 Range 策略,不過也可以把它改成 org.apache.kafka.clients.consumer.RoundRobinAssignor,我們還可以使用自定義策略,在這種情況下,partition.assignment.strategy 屬性的值就是自定義類的名字,
client.id
該屬性可以是任意字串,
broker 用它來標識從客戶端發送過來的訊息,
通常被用在日志、度量指標和配額里,max.poll.records
該屬性用于控制單次呼叫 call() 方法能夠回傳的記錄數量,
可以幫你控制在輪詢里需要處理的資料量,receive.buffer.bytes 和 send.buffer.bytes
socket 在讀寫資料時用到的 TCP 緩沖區也可以設定大小,
如果它們被設為 -1,就使用作業系統的默認值,
如果生產者或消費者與 broker 處于不同的資料中心內,
可以適當增大這些值,
因為跨資料中心的網路一般都有比較高的延遲和比較低的帶寬
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423707.html
標籤:其他
上一篇:企業上云的好處