文章目錄
- Hadoop集群搭建(分布式版本)
- 一、準備作業
- 二、搭建Hadoop集群
- 1、上傳安裝包并解壓
- 2、配置環境變數
- 3、修改Hadoop組態檔
- 4、分發Hadoop到node1、node2
- 5、格式化namenode(第一次啟動的時候需要執行)
- 6、啟動Hadoop集群
- 7、檢查master、node1、node2上的行程
- 8、訪問HDFS的WEB界面
- 9、訪問YARN的WEB界面
- 10、使用hdfs命令上傳檔案
Hadoop集群搭建(分布式版本)
一、準備作業
-
三臺虛擬機:master、node1、node2
-
時間同步
ntpdate ntp.aliyun.com -
jdk1.8
java -version -
修改主機名
三臺分別執行 vim /etc/hostname 并將內容指定為對應的主機名 -
關閉防火墻:systemctl stop firewalld
- 查看防火墻狀態:systemctl status firewalld
- 取消防火墻自啟:systemctl disable firewalld
-
靜態IP配置
-
直接使用圖形化界面配置(不推薦)
-
手動編輯組態檔進行配置
1、編輯網路組態檔 vim /etc/sysconfig/network-scripts/ifcfg-ens33 TYPE=Ethernet BOOTPROTO=static HWADDR=00:0C:29:E2:B8:F2 NAME=ens33 DEVICE=ens33 ONBOOT=yes IPADDR=192.168.100.100 GATEWAY=192.168.190.2 NETMASK=255.255.255.0 DNS1=192.168.100.2 DNS2=223.6.6.6 需要修改:HWADDR(mac地址,centos7不需要手動指定mac地址) IPADDR(根據自己的網段,自定義IP地址) GATEWAY(根據自己的網段填寫對應的網關地址) 2、關閉NetworkManager,并取消開機自啟 systemctl stop NetworkManager systemctl disable NetworkManager 3、重啟網路服務 systemctl restart network
-
-
免密登錄
# 1、生成密鑰 ssh-keygen -t rsa # 2、配置免密登錄 ssh-copy-id master ssh-copy-id node1 ssh-copy-id node2 # 3、測驗免密登錄 ssh node1 -
配置好映射檔案:/etc/hosts
192.168.100.100 master 192.168.100.101 node1 192.168.100.102 node2
二、搭建Hadoop集群
1、上傳安裝包并解壓
# 使用xftp上傳壓縮包至master的/usr/local/soft/moudle/
cd /urs/local/soft/moudle/
# 解壓
tar -zxvf hadoop-2.7.6.tar.gz -C /usr/local/soft/
2、配置環境變數
vim /etc/profile
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
REDIS_HOME=/usr/local/soft/redis
HADOOP_HOME=/usr/local/soft/hadoop-2.7.6
export PATH=$JAVA_HOME/bin:$REDIS_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
# 重新加載環境變數
source /etc/profile
3、修改Hadoop組態檔
-
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/ -
core-site.xml
<property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/usr/local/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property> -
hadoop-env.sh
export JAVA_HOME=/usr/local/soft/jdk1.8.0_171
-
hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> -
mapred-site.xml.template
# 1、重命名檔案 cp mapred-site.xml.template mapred-site.xml # 2、修改 <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property> -
slaves
#注意這里沒有master node1 node2 -
yarn-site.xml
<property> <name>yarn.resourcemanager.hostname</name> <value>master</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
4、分發Hadoop到node1、node2
cd /usr/local/soft/
scp -r hadoop-2.7.6/ node1:`pwd`
scp -r hadoop-2.7.6/ node2:`pwd`
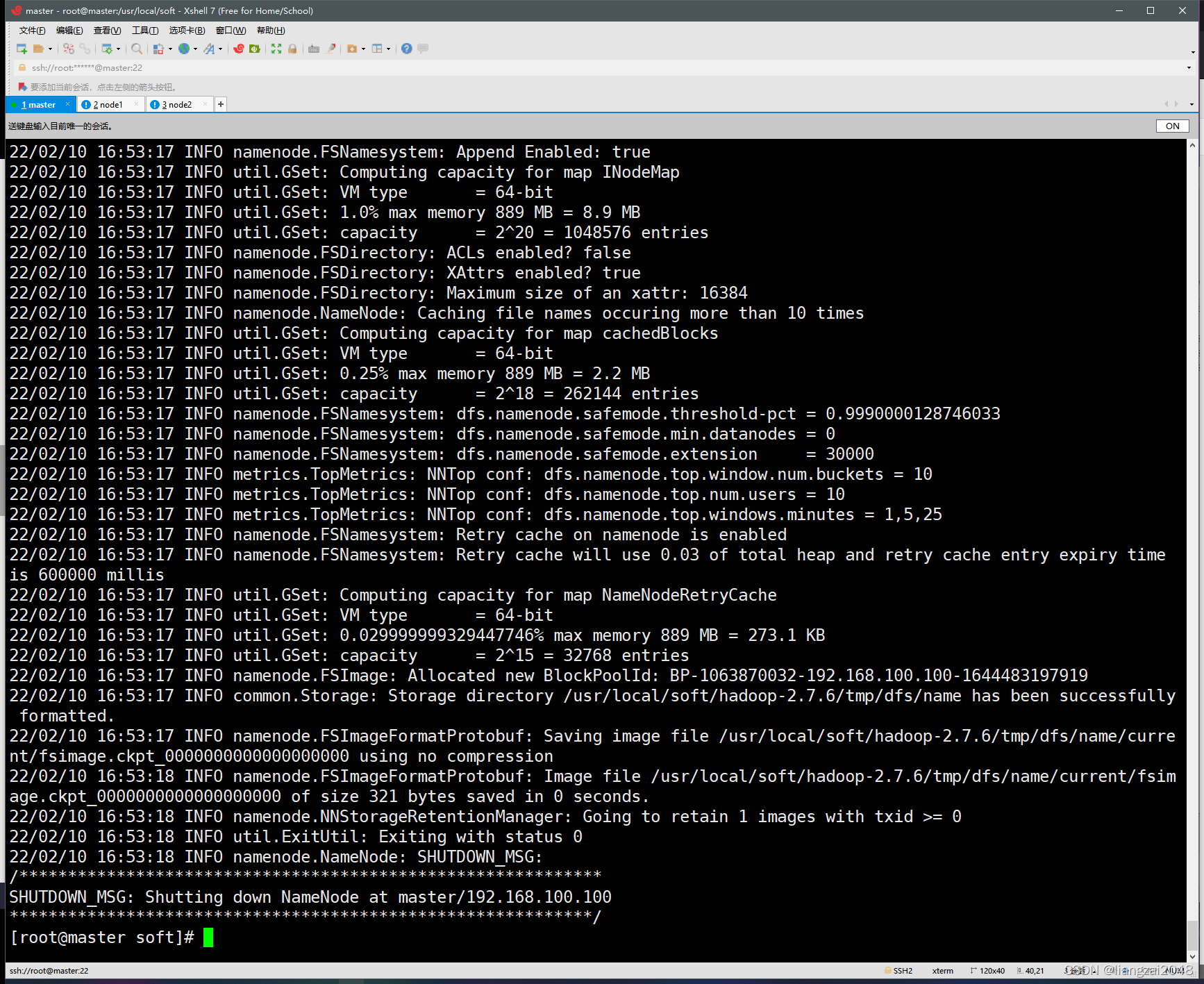
5、格式化namenode(第一次啟動的時候需要執行)
hdfs namenode -format
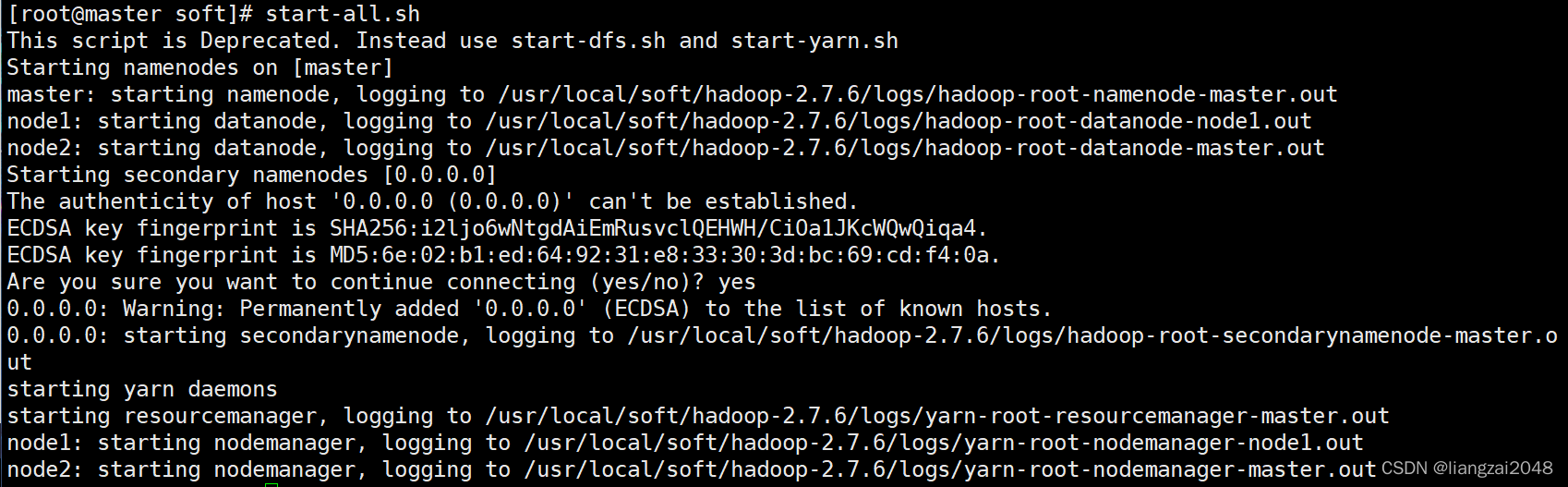
6、啟動Hadoop集群
start-all.sh
7、檢查master、node1、node2上的行程
- master:
[root@master soft]# jps
111738 NameNode
111934 SecondaryNameNode
112094 ResourceManager
112366 Jps
- node1:
[root@node1 ~]# jps
56432 Jps
56275 NodeManager
56171 DataNode
- node2:
[root@master ~]# jps
56500 DataNode
56612 NodeManager
56799 Jps
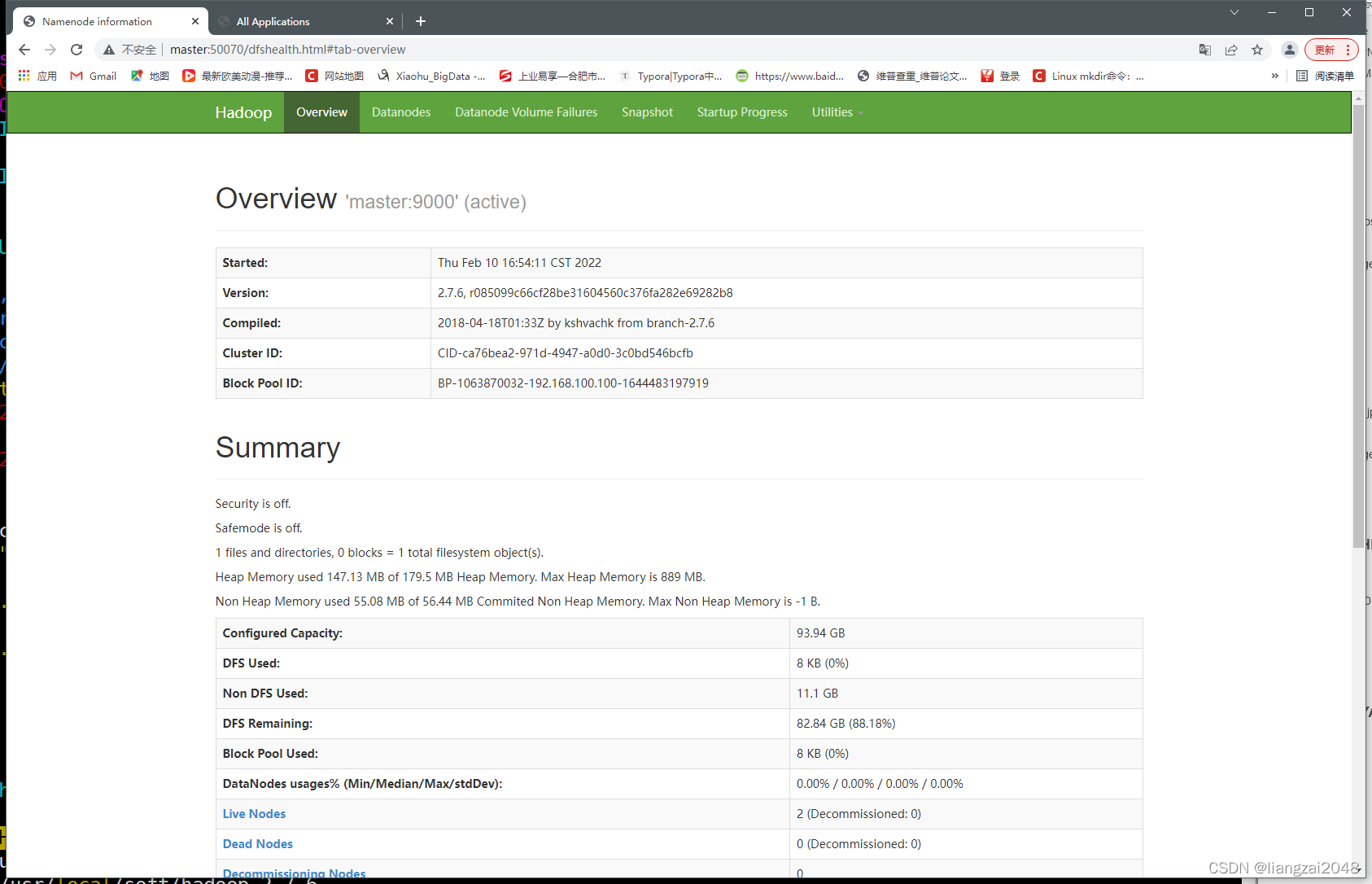
8、訪問HDFS的WEB界面
http://master:50070
9、訪問YARN的WEB界面
http://master:8088
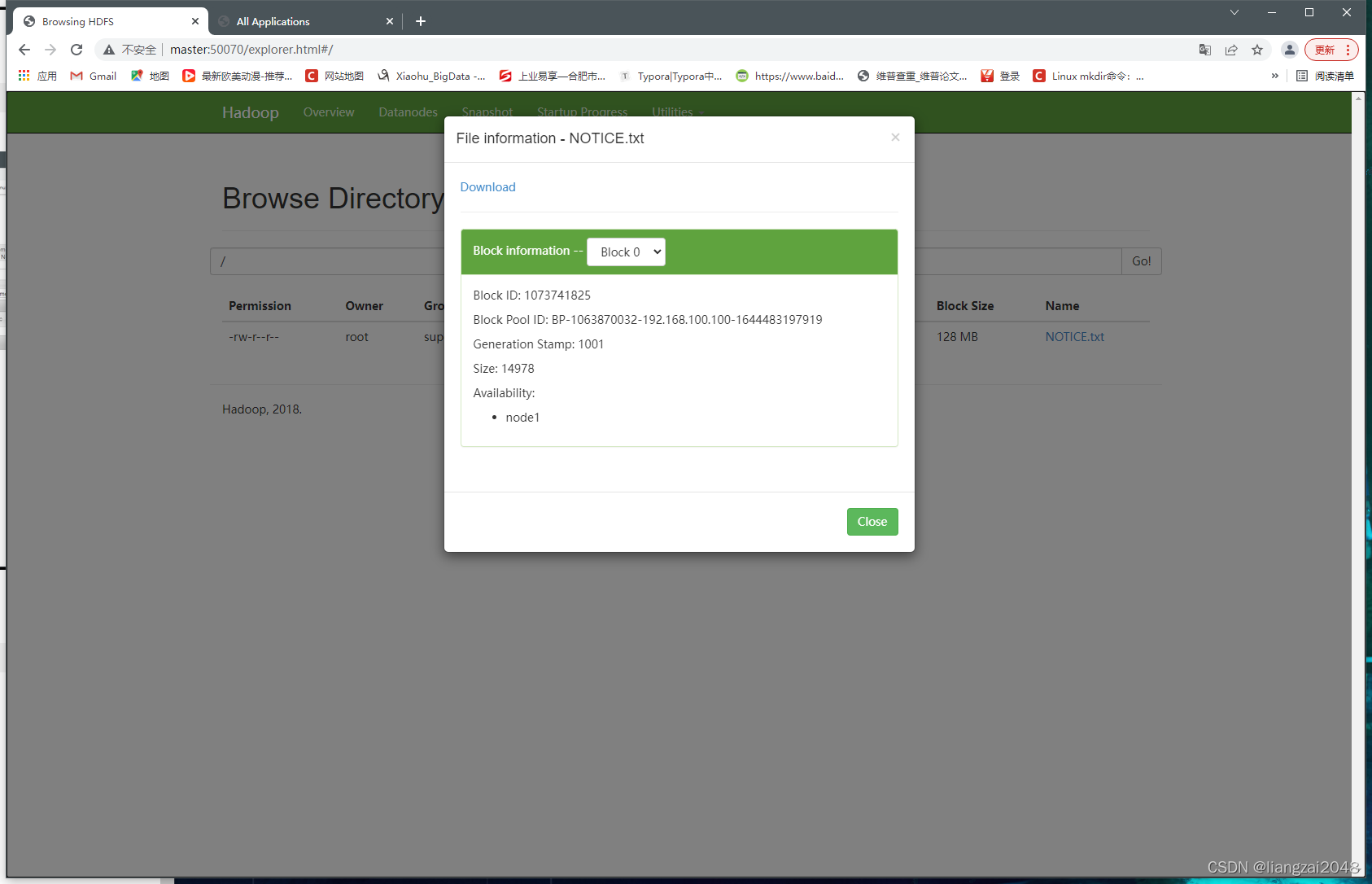
10、使用hdfs命令上傳檔案
hdfs dfs -put NOTICE.txt /
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423708.html
標籤:其他
上一篇:kafka 消費者詳解
下一篇:原始碼決議Spark各個ShuffleWriter的實作機制(二)——BypassMergeSortShuffleWriter