文章目錄
- Hadoop框架HDFS HA 的高可用
- hdfs的HA (高可用)
- HA的failover原理
- HDFS的federation
- federation架構圖-1
- federation架構圖-2
- 搭建HDFS HA 高可用
- 1、關閉防火墻
- 2、時間同步
- 3、免密(遠程執行命令)
- 4、修改Hadoop組態檔
- 5、啟動zookeeper 三臺都需要啟動
- 6、洗掉Hadoop資料存盤目錄下的檔案 每個節點都需要洗掉
- 7、啟動JN 存盤hdfs元資料
- 8、格式化 在一臺NN上執行,這里選擇master
- 9、執行同步 沒有格式化的NN上執行 在另外一個namenode上面執行 這里選擇node1
- 10、格式化ZK 在master上面執行
- 11、啟動hdfs集群,在master上執行
- 12、在IDEA中安裝zookeeper插件
- 13、master、node1 訪問web ui 50070埠
Hadoop框架HDFS HA 的高可用
hdfs的HA (高可用)
zk:指zookeeper,負責協調,監控
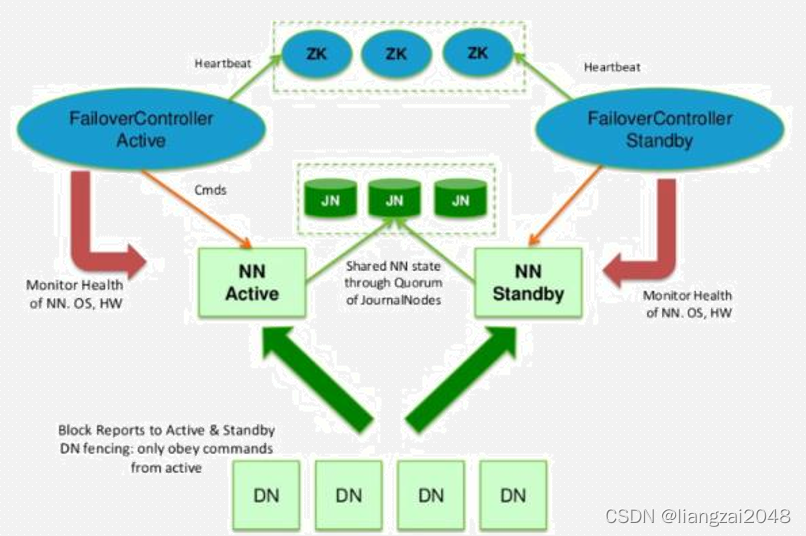
HA的failover原理
- HDFS的HA,指的是在一個集群中存在兩個NameNode,分別運行在獨立的物理節點上,在任何時間點,只有一個NameNodes是處于Active狀態,另一種是在Standby狀態, Active NameNode負責所有的客戶端的操作,而Standby NameNode用來同步Active NameNode的狀態資訊,以提供快速的故障恢復能力,
- 為了保證Active NN與Standby NN節點狀態同步,即元資料保持一致,除了DataNode需要向兩個NN發送block位置資訊外,還構建了一組獨立的守護行程”JournalNodes”,用來同步Edits資訊,當Active NN執行任何有關命名空間的修改,它需要持久化到一半以上的JournalNodes上,而Standby NN負責觀察JNs的變化,讀取從Active NN發送過來的Edits資訊,并更新自己內部的命名空間,一旦ActiveNN遇到錯誤,Standby NN需要保證從JNs中讀出了全部的Edits,然后切換成Active狀態,
使用HA的時候,不能啟動SecondaryNameNode,會出錯,
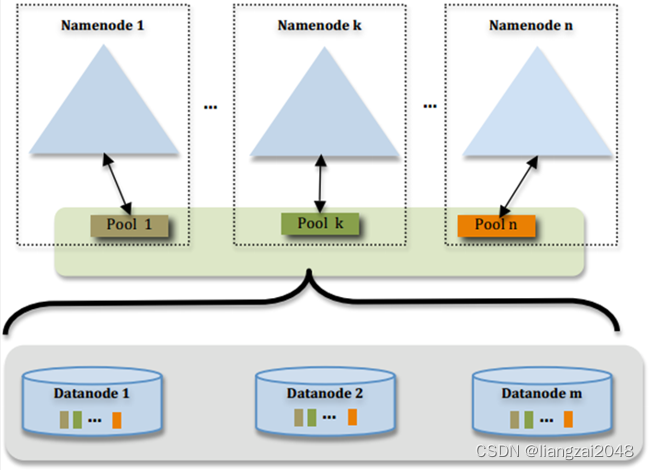
HDFS的federation
- HDFS Federation設計可解決單一命名空間存在的以下幾個問題:
- 1、 HDFS集群擴展性,多個NameNode分管一部分目錄,使得一個集群可以擴展到更多節點,不再像1.0中那樣由于記憶體的限制制約檔案存盤數目,
- 2、性能更高效,多個NameNode管理不同的資料,且同時對外提供服務,將為用戶提供更高的讀寫吞吐率,
- 3、良好的隔離性,用戶可根據需要將不同業務資料交由不同NameNode管理,這樣不同業務之間影響很小,
federation架構圖-1
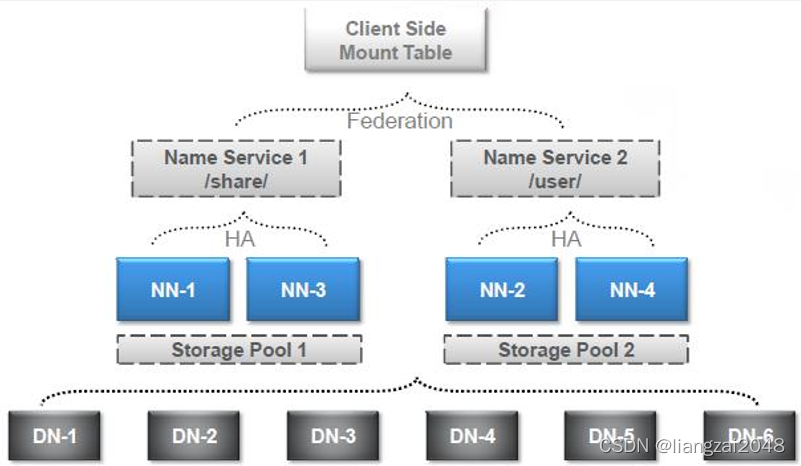
federation架構圖-2
搭建HDFS HA 高可用
| 節點 | zk | NN | DN | RM | NM | JN | ZKFC |
|---|---|---|---|---|---|---|---|
| master | 1 | 1 | 1 | 1 | 1 | ||
| node1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| node2 | 1 | 1 | 1 | 1 |
1、關閉防火墻
service firewalld stop
2、時間同步
#查看3臺系統時間是否一致
date
#時間同步
yum install ntp
ntpdate -u s2c.time.edu.cn
#或者
date -s 20180503
3、免密(遠程執行命令)
#查看密鑰是否已經配置
##查看.ssh目錄下是否有私鑰 id_rsa 和公鑰 id_rsa.pub
cd~
cd .ssh/
ls
##使用ssh命令看是否可以免密遠程登錄
###master節點
ssh node1
ssh node2
### node1節點
ssh master
ssh node2
#### 退出
exit
#在兩個主節點生成密鑰檔案
#master-->master,node1,node2
#node1-->master,node1,node2
ssh-keygen -t rsa
ssh-copy-id ip
- 查看密鑰是否已經配置
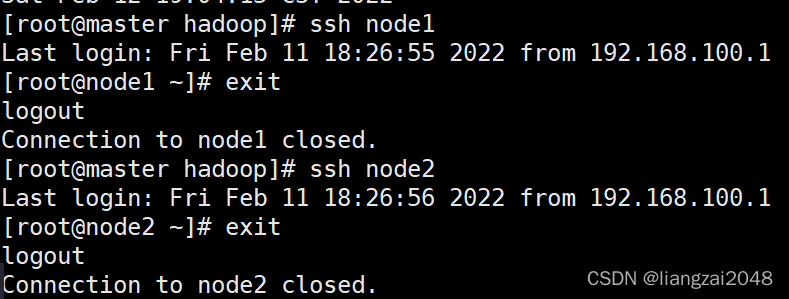

可見node1節點沒有配置免密

- node2配置免密成功

4、修改Hadoop組態檔
# 先在master節點上將hdfs行程停掉
stop-dfs.sh
#切換到hadoop目錄
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
#停止HDFS集群
stop-dfs.sh
#修改組態檔 vim 命令
core-site.xml
hdfs-site.xml
#保存退出
esc
:wq
#同步到其它節點
#切換到hadoop目錄
cd /usr/local/soft/hadoop-2.7.6/etc/hadoop/
scp ./* node1:`pwd`
scp ./* node2:`pwd`
- 在master節點上將hdfs行程停掉
- 修改core-site.xml組態檔
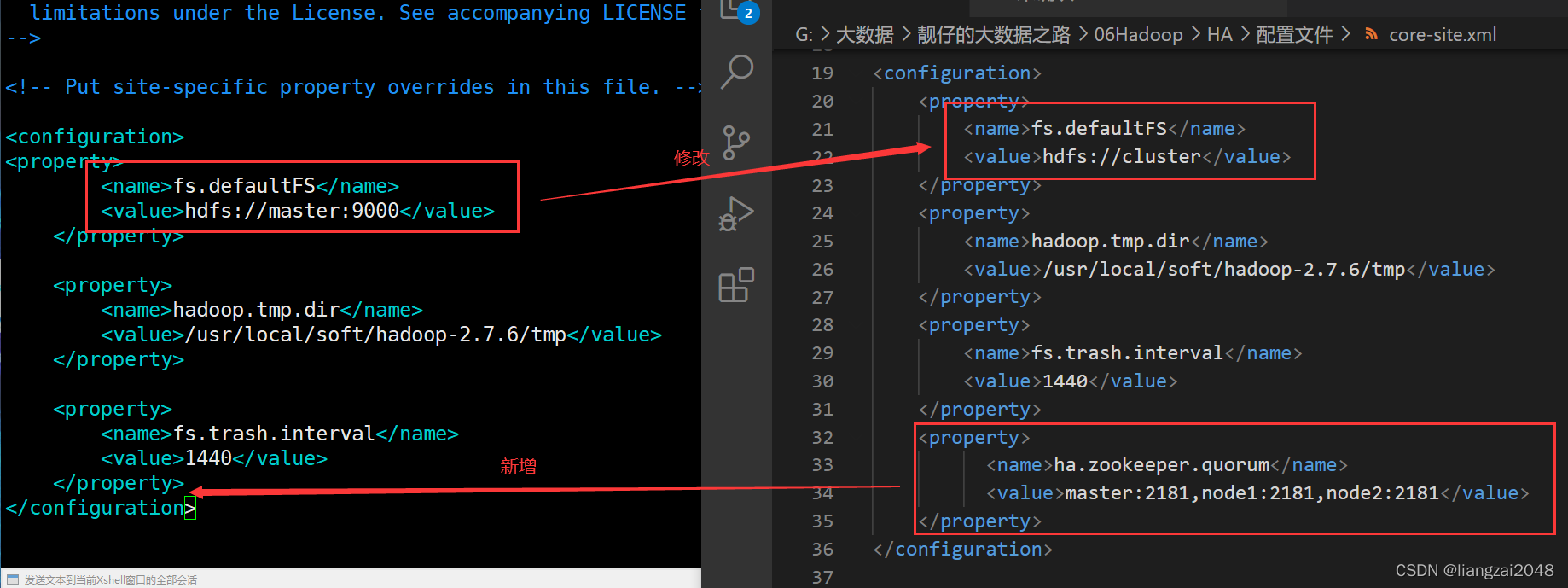
復制粘貼替換掉即可
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,node1:2181,node2:2181</value>
</property>
</configuration>
- 修改hdfs-site.xml組態檔
復制粘貼替換掉即可
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. See accompanying LICENSE file.
-->
<!-- Put site-specific property overrides in this file. -->
<configuration>
<!-- 指定hdfs元資料存盤的路徑 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/namenode</value>
</property>
<!-- 指定hdfs資料存盤的路徑 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/datanode</value>
</property>
<!-- 資料備份的個數 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 關閉權限驗證 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!-- 開啟WebHDFS功能(基于REST的介面服務) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<!-- //以下為HDFS HA的配置// -->
<!-- 指定hdfs的nameservices名稱為mycluster -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property>
<!-- 指定cluster的兩個namenode的名稱分別為nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property>
<!-- 配置nn1,nn2的rpc通信埠 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>node1:8020</value>
</property>
<!-- 配置nn1,nn2的http通信埠 -->
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>master:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>node1:50070</value>
</property>
<!-- 指定namenode元資料存盤在journalnode中的路徑 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;node1:8485;node2:8485/cluster</value>
</property>
<!-- 指定journalnode日志檔案存盤的路徑 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/soft/hadoop-2.7.6/data/journal</value>
</property>
<!-- 指定HDFS客戶端連接active namenode的java類 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔離機制為ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 指定秘鑰的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 開啟自動故障轉移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
5、啟動zookeeper 三臺都需要啟動
- 利用XShell撰寫視窗發送到全部回話

zkServer.sh start
zkServer.sh status
6、洗掉Hadoop資料存盤目錄下的檔案 每個節點都需要洗掉
rm -rf /usr/local/soft/hadoop-2.7.6/tmp
7、啟動JN 存盤hdfs元資料
JournalNode負責同步NameNode元資料
#三臺JN上執行 啟動命令
/usr/local/soft/hadoop-2.7.6/sbin/hadoop-daemon.sh start journalnode
#jps查看三臺JournalNode是否啟動
jps

8、格式化 在一臺NN上執行,這里選擇master
警告!這里使用格式化命令如果失敗,恢復快照重寫搭建一定是組態檔上出了問題!
只能格式化一次,不能格式化第二次
#格式化
hdfs namenode -format
#啟動當前的NN
hadoop-daemon.sh start namenode
- 格式化成功會在data目錄下生成一個namenode/current目錄
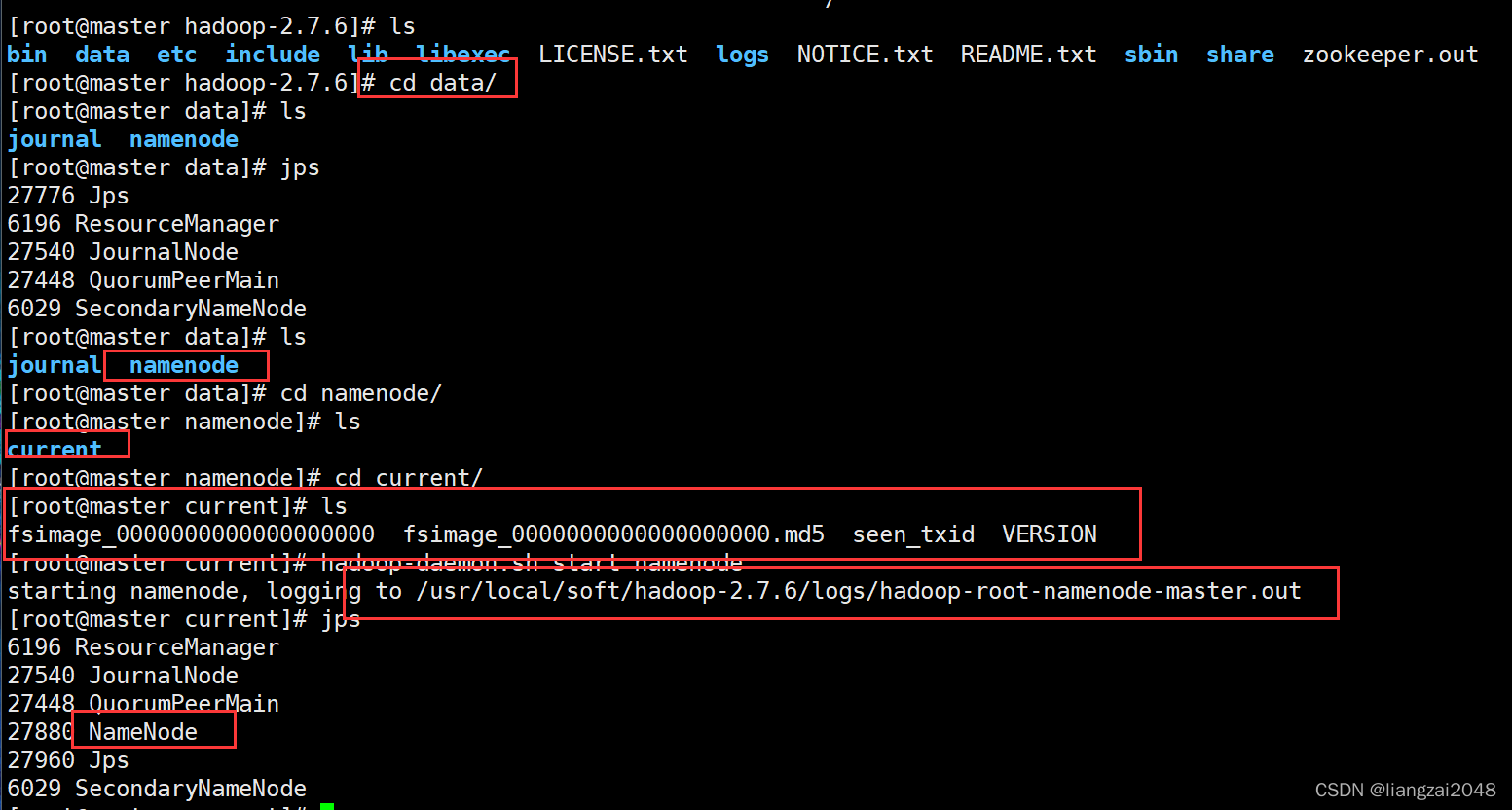
9、執行同步 沒有格式化的NN上執行 在另外一個namenode上面執行 這里選擇node1
/usr/local/soft/hadoop-2.7.6/bin/hdfs namenode -bootstrapStandby
10、格式化ZK 在master上面執行
!!一定要先 把zk集群正常 啟動起來
/usr/local/soft/hadoop-2.7.6/bin/hdfs zkfc -formatZK
#啟動node1的zk服務
zkCli.sh -server node1:2181
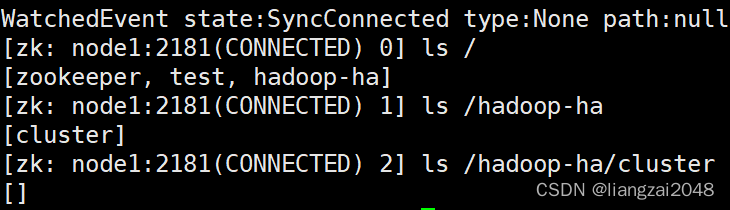
ls /
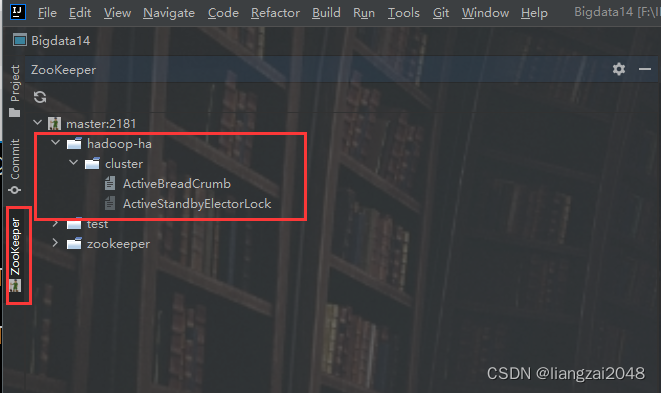
ls /hadoop-ha/cluster
這里多了一個hadoop-ha/cluster目錄
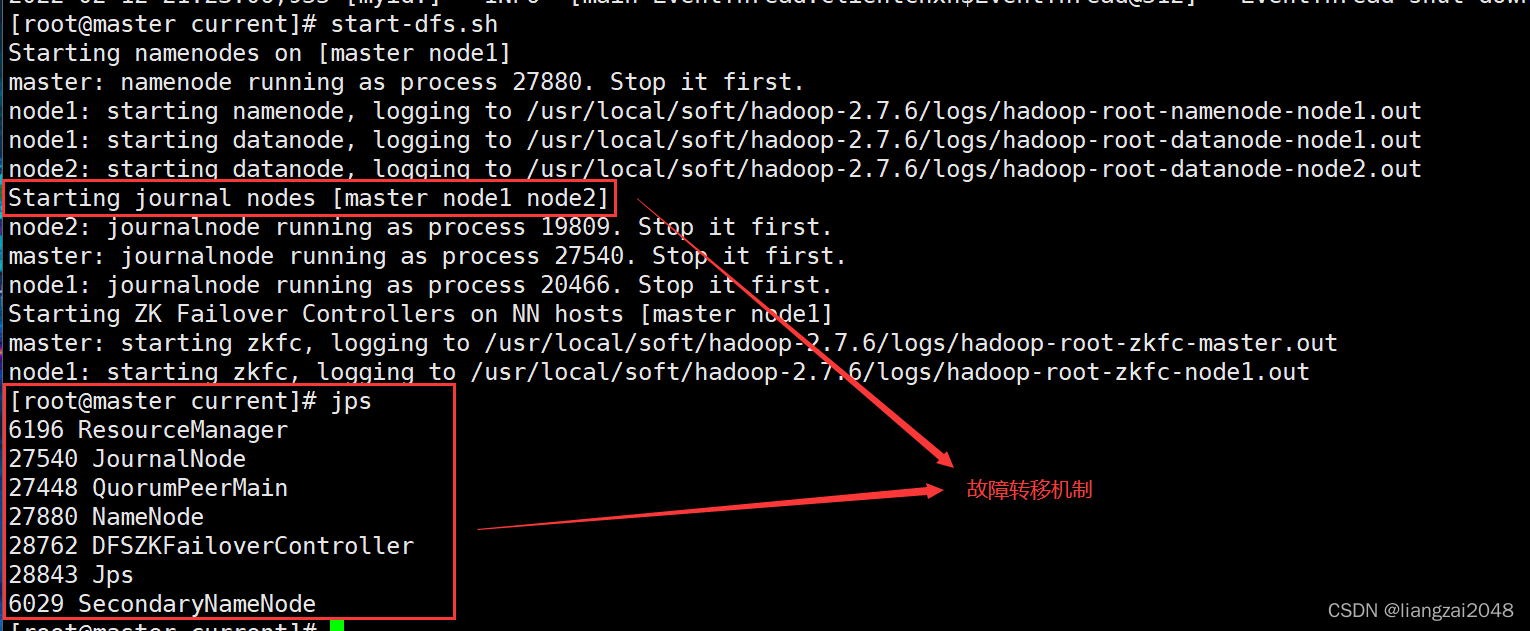
11、啟動hdfs集群,在master上執行
start-dfs.sh
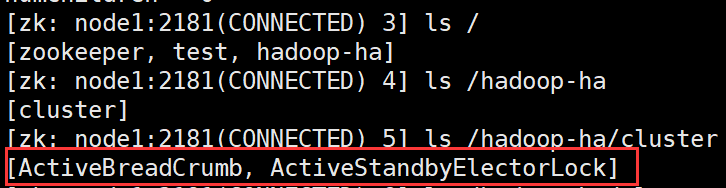
這個時候再啟動node1的ZK
#啟動node1的zk服務
zkCli.sh -server node1:2181
12、在IDEA中安裝zookeeper插件
File->Settings->Plugins->搜索zookeeper
- 重啟IDEA
- 開啟集群
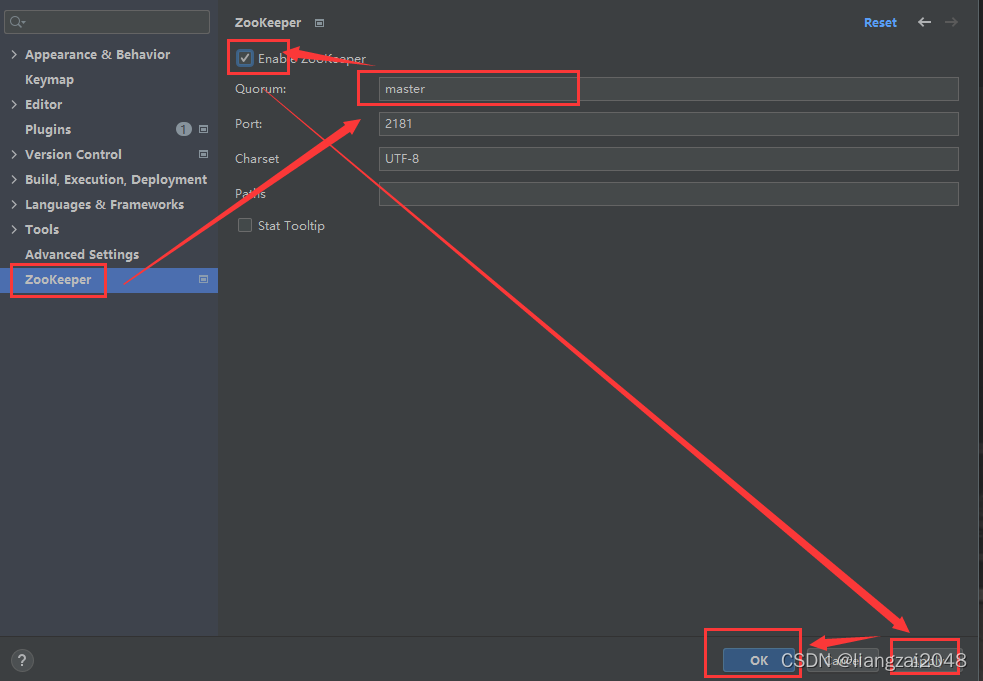
- 查看
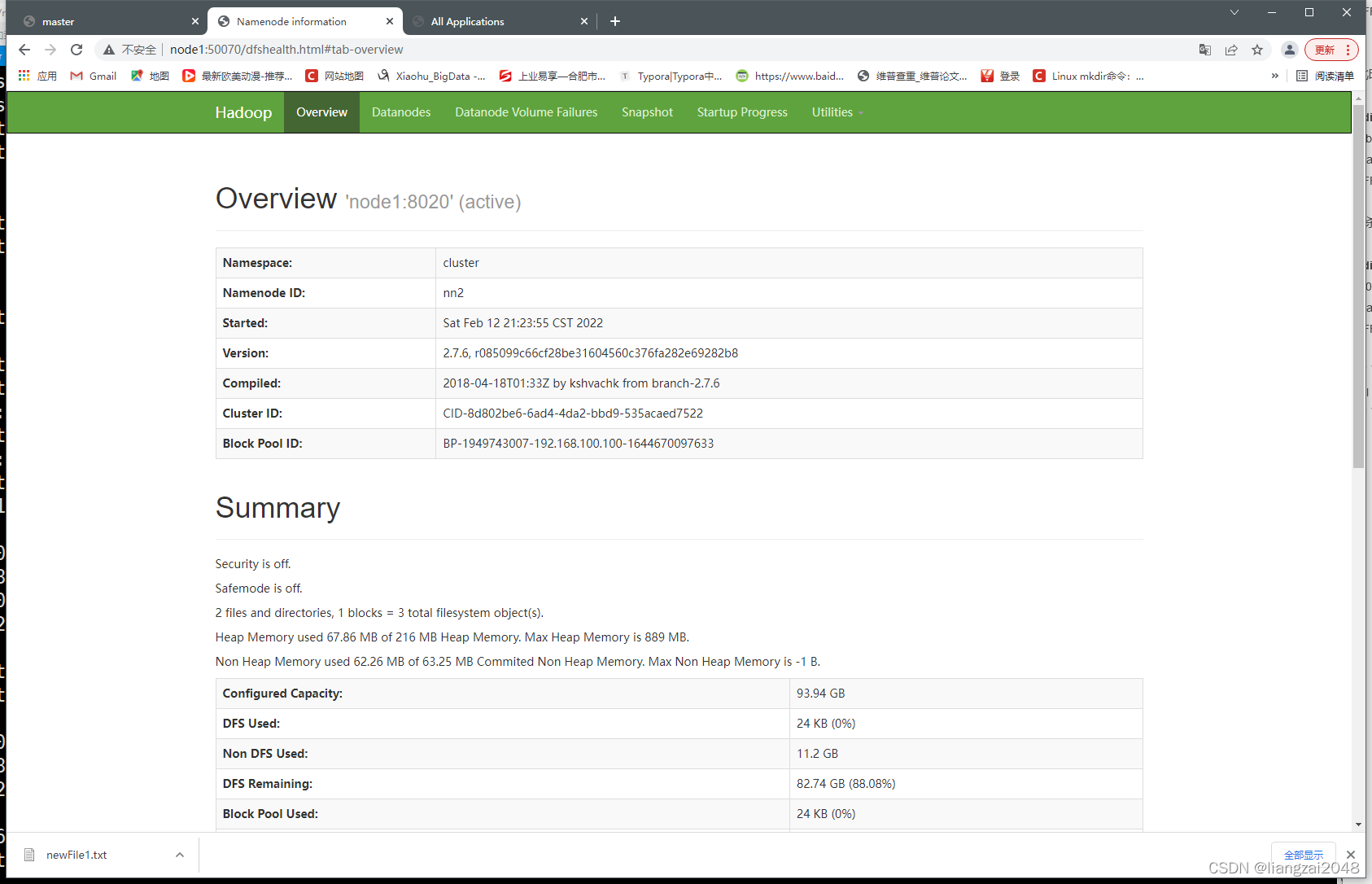
13、master、node1 訪問web ui 50070埠
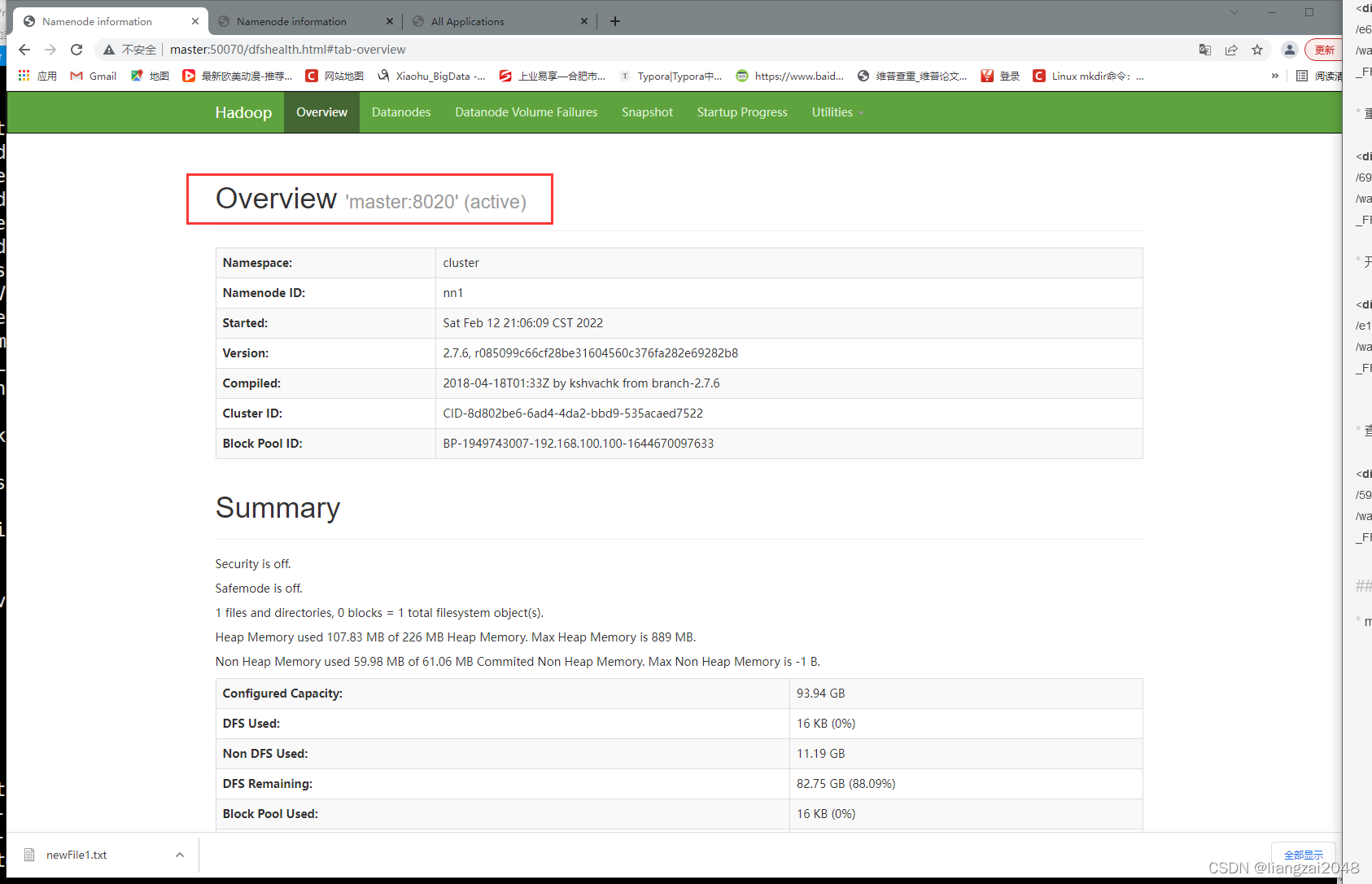
- master:50070
active狀態
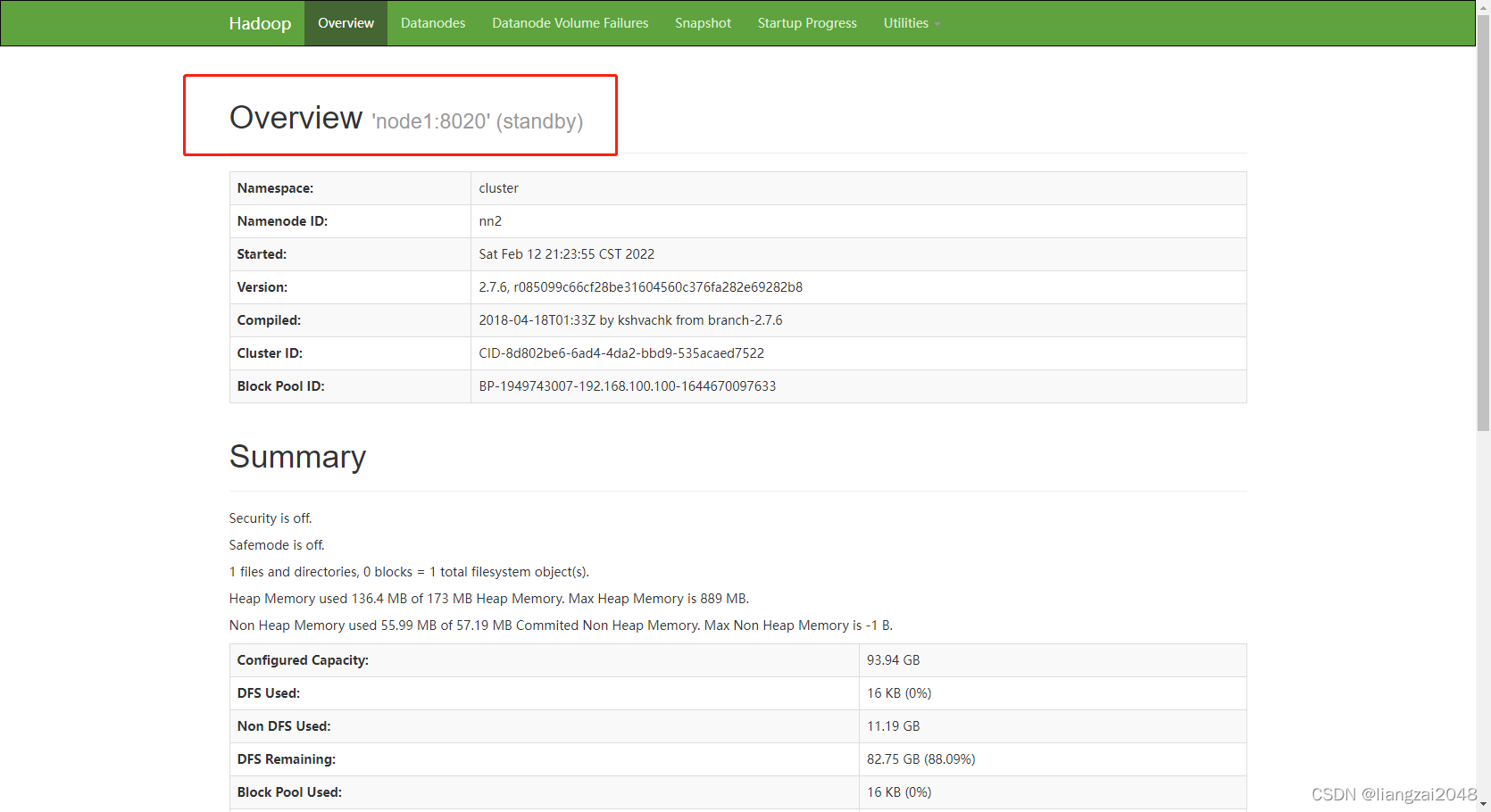
- node1:50070
standby狀態
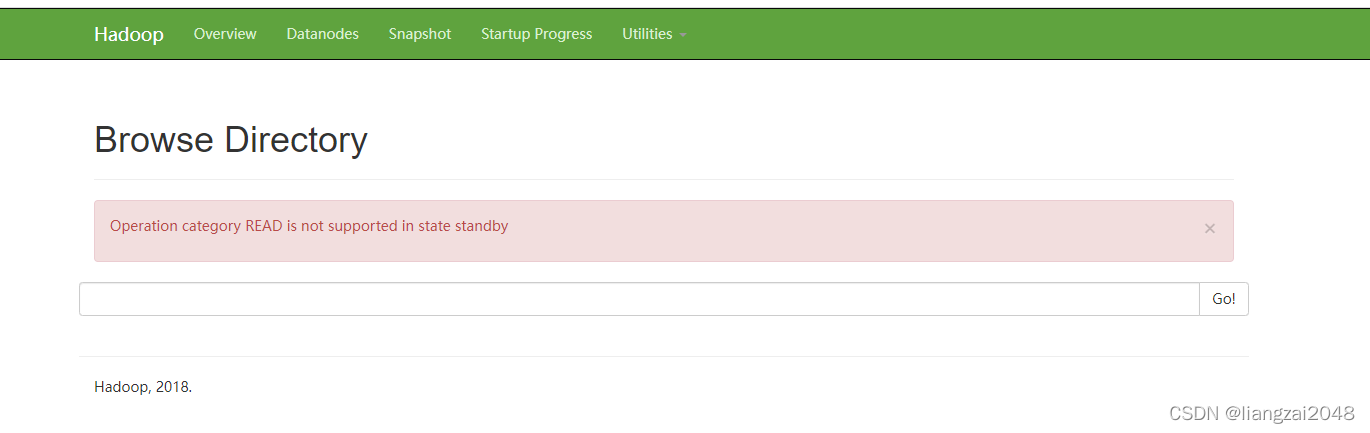
此時node1里沒有檔案
- 殺死master的NameNode行程
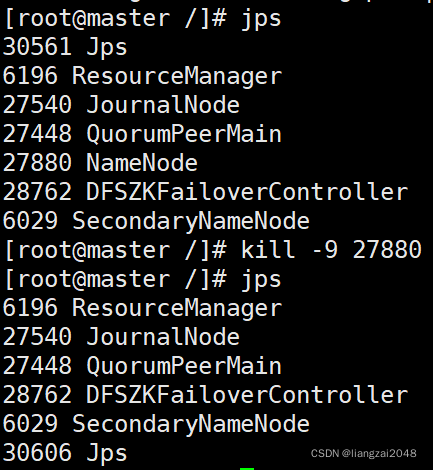
kill -9 27880
- 此時node1就變成了active狀態了 (高可用)
到底啦!覺得靚仔的文章對你學習Hadoop有所幫助的話,一波三連吧!q(≧▽≦q)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423766.html
標籤:其他
上一篇:情人節撩妹裝逼小方法,一學就會