文章目錄
- 一、前言
- 二、資料經常被質疑不準怎么辦?
- 三、資料質量問題的根源
- 1、業務系統變更
- 2、系統資源不足
- 3、基礎設施不穩定
- 4、系統代碼bug
- 四、如何提高資料質量
- 1、如何提前發現資料問題
- 基礎設施資源告警
- 添加資料稽查規則
- 稽查任務可視化
- 稽查任務是不是越多越好
- 2、如何快速定位問題出現原因
- 資料血緣
- 資料血緣的實作
- 3.如何加快資料恢復速度?
- 五、管理制度的規范化
一、前言
大家好,我是王老獅,細心地小伙伴應該發現我改名字了,具體改名原因呢?畢竟過了一年了,我也成長了,DarkKing感覺有點太中二了,因此換個成熟穩重一點的名字,(難道我會告訴你我有起名困難癥嗎?)
隨著互聯網后期以及物聯網的崛起,甚至互聯網公司們已經不滿足現實世界,誕生了元宇宙概念開始往虛擬世界方向走,包括上海也將元宇宙當做重點建設方向去布局,身為韭菜的你是不是瑟瑟發抖,現實中收割完之后,虛擬世界里繼續收割,真是走廊上鋪地鋪,不留余地啊,

到底元宇宙是好是壞,我們不做評論,但同時隨著大家通過云端互聯互動越多,產生的資料也會越來越多,大資料存盤也從數倉進化到資料湖的概念,因此,掌握一些大資料的知識對于未來發展以及了解趨勢是非常有必要的,接下來將會開設新專欄,詳細講解下資料架構從0到1建設的程序,同時對于遇到的一些問題該如何解決提供一些見解,有興趣的朋友可以一起討論,今天我們就來聊一聊,資料質量這一塊,
二、資料經常被質疑不準怎么辦?
每天各產業負責人來到公司第一件事一般都是打開電腦看下昨天的經營資料,看整體效益怎么樣,對資料進行分析來制定后面的運營策略,有一天產線同事早上打開資料,準備進行資料分析制定運營策略時,發現昨天資料都是0,之后一通電話例外上報給資料部門,
接到資料例外的投訴后,資料部門開始介入定位問題原因,從下游ADS應用層表開始查看,但是資料指標的產出可能是有幾張甚至幾十張表資料產生,一張一張的檢查check,很顯然是非常耗時的,通過一層一層向上排查,最終發現是采集層資料沒有采集到ODS,采集模塊存在一些問題,因為物理資源不足導致采集功能不可用,之后開始擴容,重新采集,跑資料,進行資料恢復,
排查問題時間將近花了一上午,問題處理資料重新計算基本上又花了半天,資料將近一天不可用,其他部門的業務進展也受到了影響,
因此作為業務部門會對資料部門滿意嗎?因此如何保證資料質量,是資料團隊必須要攻克的問題,那么為了保證資料質量,我們要做到哪幾個目標呢?
- 資料例外如何早于業務方發現?不要等到業務方投訴過來了還沒有發現問題
- 如何快速的定位問題?而不是一張一張表的check,
- 資料問題如何快速的修復?資料的故障在資料采集層就出現了問題,那么后期的資料的同步,加工處理,計算輸出都要重新運行,修復時間極高,
三、資料質量問題的根源
通過幾年的資料開發經驗,資料的開發問題主要有以下幾點
1、業務系統變更
因為資料主要還是依賴業務方的,所以當業務方發布版本迭代時,對應產出資料的表,日志發生異動時,沒有通知到資料方,那么就有可能會導致資料發生例外,一般常見的有以下4種情況,
- 業務系統資料切換新表,老表不在寫入,導致資料團隊資料更新例外,
- 業務系統表結構變更,導致資料同步存在例外,
- 業務系統環境異動,導致資料采集存在例外
- 業務系統日志格式有例外,導致采集例外
2、系統資源不足
大資料體系下,資料的計算基本都是在公共集群上進行處理的,資源通過yarn進行管理,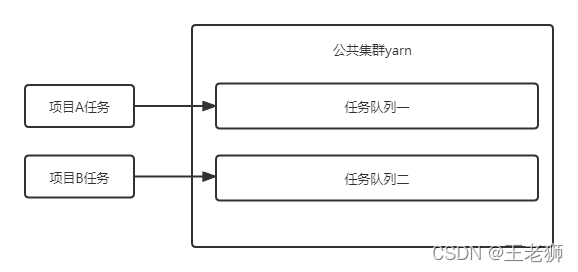
資源是個非常稀缺的東西,計算資源分配不合理,或者SQL優化的不是很好,都可能導致資源的不足,導致計算失敗,主要也有一下幾個原因,
- 資料計算記憶體資源不足,導致資料任務例外
- 資料存盤磁盤不足導致任務例外,
- 任務計算時間擁擠,系統資源搶占,
- 臨時增加計算任務,沒有及時擴充系統資源
- 系統中存在慢SQL查詢,導致計算時間延遲,計算任務積壓,
3、基礎設施不穩定
這種一般出現的例外不多,但一旦出現,影響都是全域性的并且是致命的,
- 機房停電
- 物理機掛掉
- 網路不穩等
- 開源系統組件自身的bug
4、系統代碼bug
這種問題一般出現的是最多的,特別是大資料本身業務代碼的一些例外或者任務配置有問題,導致資料計算錯誤或者任務執行失敗
- 展示層代碼存在bug
- 資料開發代碼存在bug
- 資料任務發布上線例外
- 資料任務配置例外
四、如何提高資料質量
如何提高我們的資料質量,提高業務部門對資料團隊的滿意度,那么就要針對我們的目標,和發現問題的根源提供針對性的解決方案,
- 提前發現資料問題
- 快速定位問題出現原因
- 提高資料恢復速度
1、如何提前發現資料問題
基礎設施資源告警
通過對基礎設施添加資源告警,保證計算資源的充足
如計算資源到達90%進行警告提醒,98以上可能要進行電話提醒,
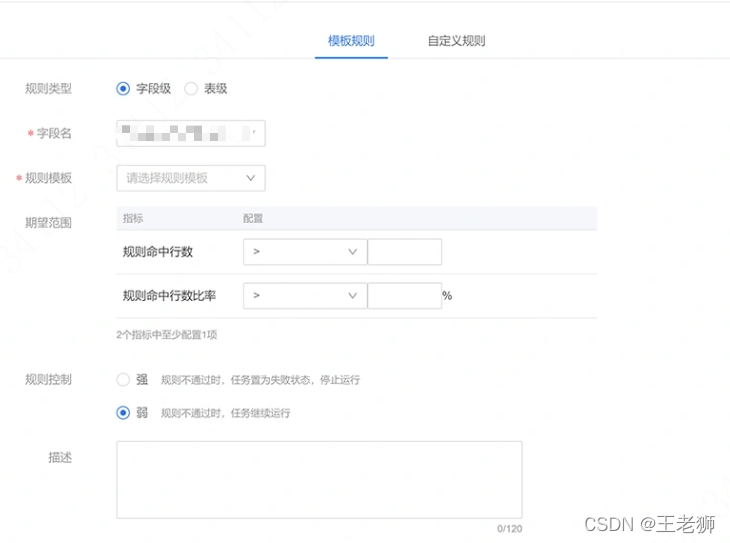
添加資料稽查規則
通過對任務處理完成的資料,針對業務設計一套校驗規則,如前后表行數是否一致,關鍵欄位的列舉,欄位的最大和最小值是否在預期內等,這是提升資料質量最有效的方法,也是最能保證資料準確的方法,同時添加欄位級別的校驗規則還可以對業務方的資料質量做一些回溯,發現業務方資料庫的一些不合理的值,從而進行治理,
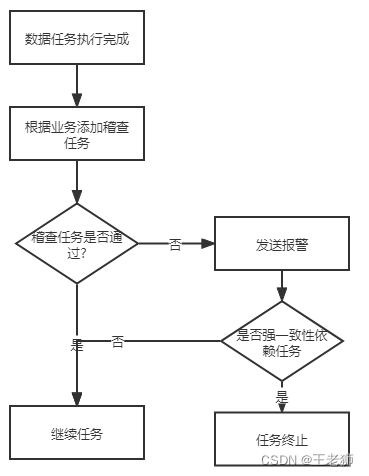
因為稽查規則和業務息息相關,所以業界沒有開源組件,基本都是公司自研,不過實作也比較簡單,一般做法如下:
- 根據每個資料任務添加對應的稽查規則,資料同步或者計算任務執行完畢之后執行稽查務,
- 稽查任務檢查是否通過,通過的話則本次任務執行為正常
- 稽查任務如果沒有通過則發送報警,由開發來判斷是否需要重新執行或者檢查任務是否存在例外
- 如果該計算任務為強規則依賴任務,則停止繼續執行后續計算任務,
- 如果不是強規則業務,不會影響后續計算任務進行,那么可以繼續執行任務,
常用的資料稽查規則要滿足以下需求: - 資料的完整性
資料的完整性顧名思義就是我們要確保記錄是完整的沒有丟失,如表級別的表行數是否一致,主鍵是否唯一等,采集程序中資料的波動率,
還有欄位級別的監控,如關鍵欄位是否非null,非0值,以及是否不再列舉范圍之內, - 資料的一致性
資料的一致性主要是指我們的資料在不同的模型中資料應該是一樣的,比如昨天累計用戶為2w,昨天活躍用戶為2000,活躍用戶占比為20%,那么這三個指標就存在不一致了,因為活躍用戶應該為活躍用戶/累計用戶為10%,而這個活躍用戶占比可能使用了其他模型中的注冊數進行計算導致資料不一致性,因此資料的一致性強調資料的來源應該只有一份,其他依賴該資料的資料指標理應都從這張表產生,這個在資料建模的時候是非常重要的一個標準, - 資料的準確性
資料的準確性主要就是保證資料的條目是準確地,就比如用戶的下單日期不可能早入商品的發布日期,當天用戶活躍不可能高于注冊用戶等,
稽查任務執行如下:
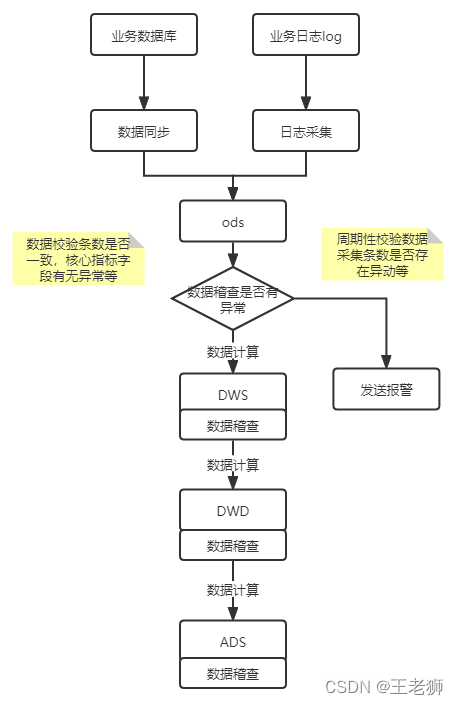
計算任務和稽查任務掛鉤,保證資料運行時業務資料的準確性,
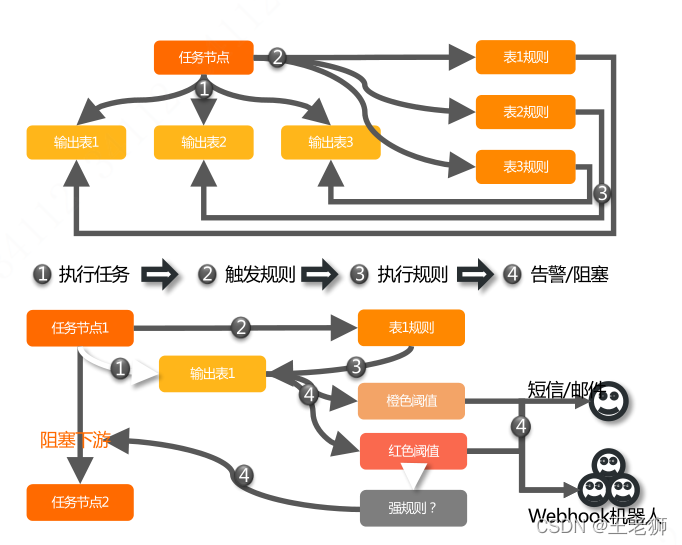
網易的模板稽查規則配置模型,有興趣的可以參考:
稽查任務可視化
通過對稽查任務大盤的可視化,可以幫助研發更加清晰地發現任務執行情況,快速分析問題原因,
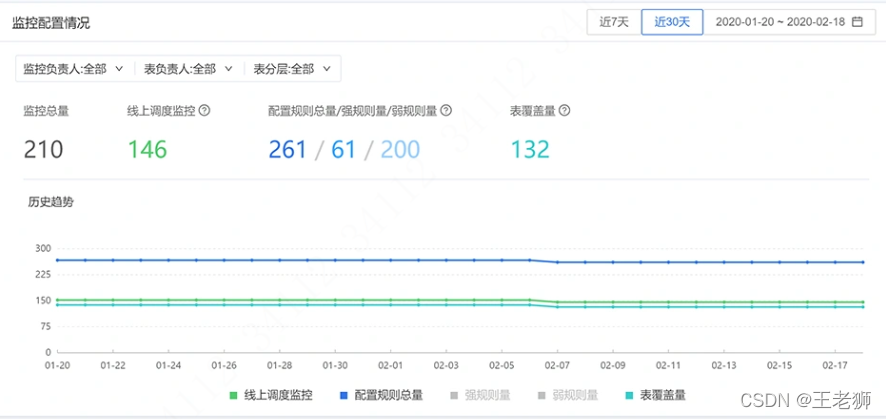
稽查任務是不是越多越好
稽查任務本身是一個比較耗資源的任務,因此我們要區分業務指標的重要等級,重要級別的必須增加稽查任務,一般重要的按需增加,以合理的利用資源和減少成本,
2、如何快速定位問題出現原因
資料血緣
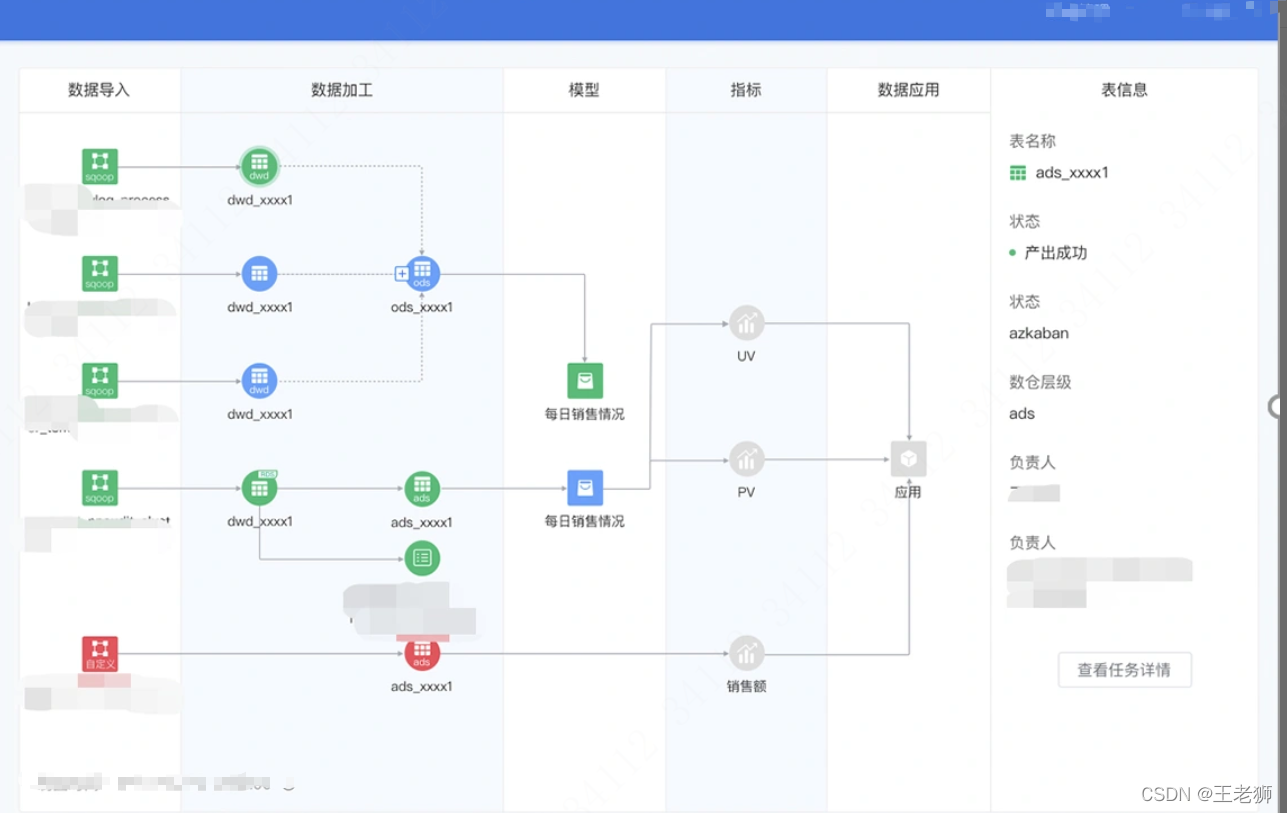
資料倉庫的設計中我們一般都是進行分層的,好的模型資料資料復用率會很高,可能一個中間結果被多個資料模型服用,那么這會導致我們資料加工鏈路變差,排查定位問題的時間也會比較長,因此建立資料的全鏈路監控,資料的血緣關系是非常有必要的,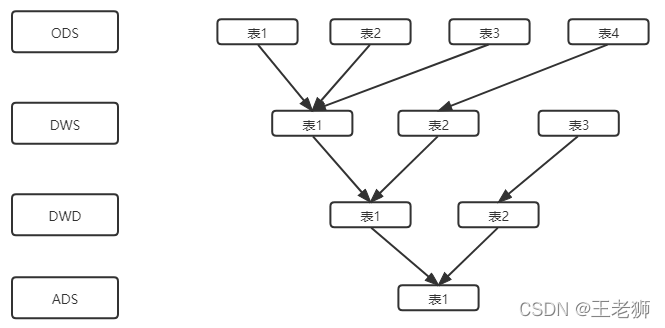
從下圖可以看到,血緣的建立一般都是我們通過業務方資料源起點,記錄大資料加工程序,到指標的系結以及指標的應用,建立起資料的全加工路徑,這樣那個資料指標出現了問題,通過資料鏈路就可以很快的定位到那個節點發生故障,從而快速回應去解決,
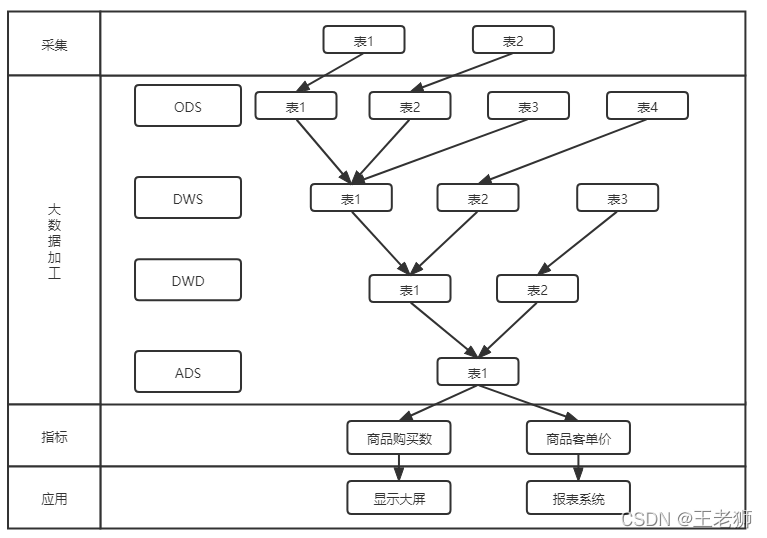
資料血緣的實作
基于hadoop生態的資料血緣業界有apache的Atlas,Altas是apache開源的一套元資料治理的系統,它為Hadoop集群提供了包括資料分類、集中策略引擎、資料血緣、安全和生命周期管理在內的元資料治理核心能力,通過在hadooop生態組件里面配置hook的方式,自動將任務執行資訊以及資料元資訊倒入到Atlas中,Atlas的安裝我之前有寫過博客,大家感興趣可以了解一下:Atlas的安裝和使用
Altas 表元資料資訊

Altas 資料血緣
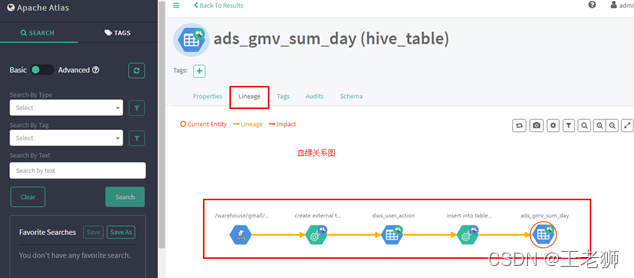
如果脫離了hadoop集群組件的,那可能就要自己實作對應的hook函式了,
因為大資料以及業務存盤組件當前很多,因此要完全實作各個存盤組件以及同步任務的血緣系統難度大,因此更多的還是根據業務來自研自己的血緣組件,
血緣組件關聯一般有手動和自動兩種,
手動血緣關聯
手動關聯要求對整個資料開發程序要求可視化,在配置采集,計算任務,指標關聯時,通過配置的方式把血緣關系寫進血緣系統中,最后做一個資料呈現即可,此方法對資料開發可視化要求比較高,如果研發手動執行腳本,那么可能就記錄不了血緣,導致血緣確實,維護難度大,
自動血緣關聯
自動血緣關聯即在資料任務執行程序中,通過SQL決議或者日志的方式,記錄資料的流轉,自動寫入血緣系統中,
一般常用的方法有:
1、資料引擎的埋點
2、SQL PROXY LOG等
根據使用的存盤引擎不同選擇不同的方式,像使用SQL語言的則可以通過sql決議的方式,記錄資料從哪來到哪去,如果是ES則可以通過資料引擎埋點的方式記錄,
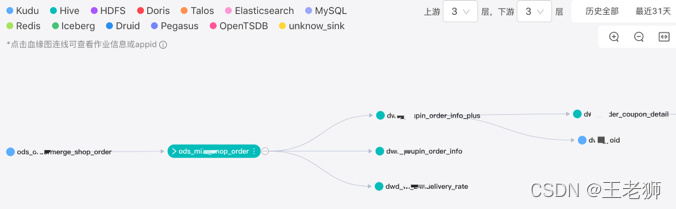
資料血緣的展示
小米公司的資料血緣展示形式
網易的資料血緣展示形式
3.如何加快資料恢復速度?
有了前兩道關,及時發現了并且定位到資料問題,那么接下來就是要進行資料恢復了,資料例外恢復一般我們要通過經常出現的一些問題進行分析,增強程式的健壯性以及容錯性,比如日志任務漏采要有離線補齊的能力,資料同步中斷要有中斷補償機制或者增量更新的能力,當然更重要的是我們要根據的資料重要性區分等級,按照優先級進行恢復,
五、管理制度的規范化
在強大的技術也抵不過混亂的管理,即使已經有了前面描述的那么多能力,如果并沒有開發添加規則或者規則不全面,報警發出無人處理,還是無法達早發現早處理的要求,因此建立完整的資料開發流程制度是保證資料質量的一個重要保證,好了,今天先聊到這里,后面在和大家繼續聊一下資料治理相關的內容,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423767.html
標籤:其他