1. Logistic 分布和對率回歸
監督學習的模型可以是概率模型或非概率模型,由條件概率分布\(P(Y|\bm{X})\)或決 策函式(decision function)\(Y=f(\bm{X})\)表示,隨具體學習方法而定,對具體的輸入\(\bm{x}\)進行相應的輸出預測并得到某個結果時,寫作\(P(y|\bm{x})\)或\(y=f(\bm{x})\),
我們這里的 Logistic 分類模型是概率模型,模型\(P(Y|\bm{X})\)表示給定隨機向量\(\bm{X}\)下,分類標簽\(Y\)的條件概率分布,這里我們只討論二分類問題,后面我們介紹多層感知機的時候會介紹多分類問題,道理是一樣的,
先介紹 Logistic 分布,
Logistic 的分布函式為:
\[F(x) = P(X<=x) = \frac{1}{1+e^{-(x-u)/\gamma}} \]該分布函式的影像為:
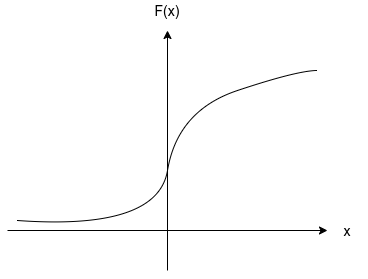
該函式以點\((u,1/2)\)中心對稱,在中心附近增長速度較快,在兩端增長速度較慢,
我們后面對于未歸一化的數\(z\),采用\(\text{sigmoid}\)函式
\[σ(z) = \frac{1}{1 + \text{exp}(?z)} \]將其“壓”在(0, 1)之間,這樣就可以使\(z\)歸一化,一般我們使歸一化后的值表示置信度(belief),可以理解成概率,但是與概率有著細微的差別,更體現 “屬于××類的把握”的意思,
對于二分類,標簽\(Y=0\)或\(Y=1\),我們將\(P(Y=0|\bm{X}=\bm{x})\)和\(P(Y=1|\bm{X}=\bm{x})\)表示如下,也就定義了二項邏輯回歸模型:
\[\begin{aligned} P(Y=1|\bm{X}=\bm{x}) &= \sigma(\bm{w}^T\bm{x}+b) \\ &= \frac{1}{1+\text{exp}(-(\bm{w}^T\bm{x}+b))} \end{aligned}\space (1) \\ \begin{aligned} P(Y=0|\bm{X}=\bm{x}) &= 1-\sigma(\bm{w}^T\bm{x}+b) \\ &= \frac{1}{1+\text{exp}(\bm{w}^T\bm{x}+b)} \end{aligned} \qquad (2) \]現在考察 Logistic 回歸模型的特點,一個事件的幾率(odds)是指該事件發生的概率與不發生的概率的比值,如果事件發生的概率是\(p\),那么該事件的幾率是\(p/(1-p)\),該事件的對數幾率(log odds,簡稱對率)或 logit 函式是
\[\text{logit}(p) = \text{log}\space p/(1-p) \]對 Logistic 回歸而言,由式子\((1)\)和式子\((2)\)得到:
\[\text{log}\frac{P(Y = 1|\bm{X}=\bm{x})}{1 ? P(Y = 1|\bm{X}=\bm{x})} = \bm{w}^T\bm{x} + b \]這玩意在統計學里面稱之為“對率回歸”,其實就是“Logistic regression 名稱”的由來,這里的 Logistic 和“邏輯”沒有任何關系,和對率才是有關系的, 可以看出,輸出\(Y=1\)的對數幾率是由輸入\(\bm{x}\)的線性函式表示的模型,即 Logistic 回歸模型,
2. Logistic 回歸模型的引數估計
我們在《統計推斷:極大似然估計、貝葉斯估計與方差偏差分解》)中說過,從概率模型的視角來看,機器模型學習的程序就是概率分布引數估計的程序,這里就是估計條件概率分布\(P(Y|\bm{X})\)的引數\(\bm{θ}\),對于給定的訓練資料集\(T=\{\{\bm{x}_1, y_1\},\{\bm{x}_2, y_2\}, \dots, \{\bm{x}_N, y_N\}\}\),其中,\(\bm{x}_i∈\mathbb{R}^n\),\(y_i∈\{0, 1\}\),可以應用極大似然估計法估計模型引數,從而得到Logistic回歸模型,
我們設\(P(Y=1|x)=π(\bm{x})\),\(P(Y=0|\bm{x})=1-π(\bm{x})\),很顯然\(P(Y|\bm{x})\)服從一個伯努利分 布,不過這個伯努利分布很復雜,它的引數\(p\)是一個函式\(π(\bm{x})\),我們這里采用一個抽象的觀念,將函式\(π(\bm{x})\)看做一個整體,這樣\(P(Y|\bm{x})\)服從二項分布,可以方便我們理解,我們的引數\(\bm{θ}=(w, b)\),不過我們還是采用之前的技巧,將權值向量和輸入向量加以擴充,直接記做\(\bm{θ}=\bm{w}\),
這樣,對于\(N\)個樣本,定義似然函式:
\[L(\bm{w}|\bm{x}_1,\bm{x}_2,...,\bm{x}_N) = \Pi_{i=1}^N[\pi(\bm{x}_i)]^{y_i}[1-\pi(\bm{x}_i)]^{1-y_i} \]因為函式比較復雜,我們采用數值優化進行求解,然而這個函式是非凸的, 如果直接用數值迭代演算法作用于次函式,可能陷入區域最優解不能保證到收斂到全域最優解,我們為了將其變為負對數似然函式(想一想為什么要取負號),也就是一個凸函式,方便用梯度下降法、牛頓法進行求解:
\[-L(\bm{w}|\bm{x}_1,\bm{x}_2,...,\bm{x}_N) = - \sum_{i=1}^N[y_i\text{log}\space \pi(\bm{x}_i)+(1-y_i)\text{log}(1-\pi(\bm{x}_i))] \]配湊 \(1/N\)轉換為關于資料經驗分布期望的無偏估計 ,即\(\mathbb{E}_{\bm{x}\sim \hat{p}_{data}}\text{log}\space p_{model}(\bm{x}_i| \bm{\theta})\)而不改變目標函式的優化方向,
\[- \frac{1}{N}\sum_{i=1}^N[y_i\text{log}\space \pi(\bm{x}_i)+(1-y_i)\text{log}(1-\pi(\bm{x}_i))] \]上面這個式子,就是我們在深度學習里面常用的交叉熵損失函式(cross entropy loss function)的特殊情況,(交叉熵損失函式一般是多分類,這里是二分類),后面我們會學習,在深度學習領域中,我們用\(f(\cdot)\)表示神經網路對輸入\(\bm{x}\)加以的 映射(這里沒有激活函式,是線性的映射),\(f(\bm{x})\)就是輸出的條件概率分布\(P(Y|\bm{X}=\bm{x})\), 設類別總數為\(K\),\(\bm{x}_i\)為第\(i\)個樣本的特征向量(特征維度為\(D\)),\(f(\bm{x}_i)\)輸出維度也為\(K\),\(f(\bm{x}_i)_k\)表示\(P(y_k | \bm{x}_i)\),因為是多分類,\(P(y_k | \bm{x}_i)\)的計算方法就不能通過\(\text{sigmoid}\)函式來得到了,取而代之是更通用的\(\text{softmax}\)函式,我們給定輸入樣本\(\bm{x}\),設\(z_k=\sum_{j=1}^Dw_{zj}x_{j}\),其中\(\textbf{W} ∈\mathbb{R}^{K\times D}\)神經網路的權重矩陣\(D\)為特征向量維度,\(K\)為類別總數,則我們有:
\[f(\bm{x})_k = \text{softmax}(\bm{z})_k=\frac{\text{exp}(z_k)}{\sum_k\text{exp}(z_k)} \]我們規定第\(i\)個樣本的標簽\(\bm{y}_i\)為\(K\)維one-hot向量,則交叉熵函式表述如下:
\[- \frac{1}{N}\sum_{i=1}^N\sum_{k=1}^K y_{ik}\text{log}f(\bm{x}_i)_k \]因為\(\bm{y}_i\)為 one-hot 向量,只有一個維度為 1,設這個維度為\(c\)(即表示類別\(c\)),則交叉熵函式可以化簡為:
\[- \frac{1}{N}\sum_{i=1}^N \text{log}f(\bm{x}_i)_c \]很明顯,如果\(f(\bm{x}_i)_c\)越大,表示神經網路預測\(\bm{x}_i\)樣本類別為第\(c\)類的概率越大,這也是目標函式優化的方向——即對于類別為\(c\)的樣本\(\bm{x}_i\),優化器盡量使樣本\(\bm{x}_i\)被預測為第\(c\)類的概率更大,
如下為使用梯度下降法求解二分類邏輯回歸問題:
import numpy as np
import random
import torch
# batch_size表示單批次用于引數估計的樣本個數
# y_pred大小為(batch_size, 1)
# y大小為(batch_size, ),為類別型變數
def cross_entropy(y_pred, y):
# 這里y是創建新的物件,這里將y變為(batch_size. 1)形式
y = y.reshape(-1, 1)
return -(y*torch.log(y_pred) + (1-y)*torch.log(1-y_pred)).sum()/y_pred.shape[0]
# 前向函式
def logistic_f(X, w):
z = torch.matmul(X, w).reshape(-1, 1)
return 1/(1+torch.exp(-z))
# 之前實作的梯度下降法,做了一些小修改
def gradient_descent(X, w, y, n_iter, eta, loss_func, f):
# 初始化計算圖引數,注意:這里是創建新物件,非引數參考
w = torch.tensor(w, requires_grad=True)
X = torch.tensor(X)
y = torch.tensor(y)
for i in range(1, n_iter+1):
y_pred = f(X, w)
loss_v = loss_func(y_pred, y)
loss_v.backward()
with torch.no_grad():
w -= eta*w.grad
w.grad.zero_()
w_star = w.detach().numpy()
return w_star
# 本模型按照二分類架構設計
def LR(X, y, n_iter=200, eta=0.001, loss_func=cross_entropy, optimizer=gradient_descent):
# 初始化模型引數
# 我們使W和b融合,X后面添加一維
X = np.concatenate([X, np.ones([X.shape[0], 1])], axis=1)
w = np.zeros(X.shape[1], dtype=np.float64)
# 呼叫梯度下降法對函式進行優化
# 這里采用單次迭代對所有樣本進行估計,后面我們會介紹小批量法減少時間復雜度
w_star = optimizer(X, w, y, n_iter, eta, loss_func, logistic_f)
return w_star
if __name__ == '__main__':
# 資料矩陣,一共4個樣本,每個樣本特征維度為3
X = np.array([
[1, 5, 3],
[4, 5, 6],
[7, 1, 9],
[10, 1, 12]
], dtype=np.float64)
# 標簽向量,注意要從0開始編碼
y = np.array([1, 1, 0, 0], dtype=np.int64)
# 迭代次數
n_iter = 200
# 學習率
eta = 0.001
w = LR(X, y, n_iter, eta, cross_entropy, gradient_descent)
# 學得的權重,最后一維是偏置b
print(w)
最終學得的權重向量為(最后一維為偏置\(b\)):
[-0.10717712 0.20524747 -0.06932763 0.01892475]
如下是多分類邏輯回歸問題,我們需要將\(\text{sigmoid}\)函式修改為\(\text{softmax}\)函式,損失函式修改為更為通用的交叉熵函式,根據輸出維度變化將權重向量修改為權重矩陣等,
import numpy as np
import random
import torch
# batch_size表示單批次用于引數估計的樣本個數
# n_feature為特征向量維度
# n_class為類別個數
# y_pred大小為(batch_size, n_class)
# y大小為(batch_size, ),為類別型變數
def cross_entropy(y_pred, y):
# 這里y是創建新的物件,這里將y變為(batch_size. 1)形式
y = y.reshape(-1, 1)
return -torch.log(torch.gather(y_pred, 1, y)).sum()/ y_pred.shape[0]
# 前向函式,注意,這里的sigmoid改為多分類的softmax函式
def logistic_f(X, W):
z = torch.matmul(X, W)
return torch.exp(z)/torch.exp(z).sum()
# 之前實作的梯度下降法,做了一些小修改
def gradient_descent(X, W, y, n_iter, eta, loss_func, f):
# 初始化計算圖引數,注意:這里是創建新物件,非引數參考
W = torch.tensor(W, requires_grad=True)
X = torch.tensor(X)
y = torch.tensor(y)
for i in range(1, n_iter+1):
y_pred = f(X, W)
loss_v = loss_func(y_pred, y)
loss_v.backward()
with torch.no_grad():
W -= eta*W.grad
W.grad.zero_()
W_star = W.detach().numpy()
return W_star
# 本模型按照多分類架構設計
def LR(X, y, n_iter=200, eta=0.001, loss_func=cross_entropy, optimizer=gradient_descent, n_class=2):
# 初始化模型引數
# 我們使W和b融合,X后面添加一維
X = np.concatenate([X, np.ones([X.shape[0], 1])], axis=1)
W = np.zeros((X.shape[1], n_class), dtype=np.float64)
# 呼叫梯度下降法對函式進行優化
# 這里采用單次迭代對所有樣本進行估計,后面我們在深度學習專欄中會介紹小批量法
W_star = optimizer(X, W, y, n_iter, eta, loss_func, logistic_f)
return W_star
if __name__ == '__main__':
X = np.array([
[1, 5, 3],
[4, 5, 6],
[7, 1, 9],
[10, 1, 12]
], dtype=np.float64)
# 標簽向量,注意要從0開始編碼
y = np.array([1, 2, 0, 0], dtype=np.int64)
# 迭代次數
n_iter = 200
# 學習率
eta = 0.001
# 分類類別數
n_class = 3
W = LR(X, y, n_iter, eta, cross_entropy, gradient_descent, n_class)
# 學得的權重矩陣,最后一行是偏置向量
print(W)
最終學得的權重為(同樣,最后一行為偏置向量\(\bm{b}\),因為是多分類,每一個類別維度\(k\)都會對應一個偏置\(b_k\)):
[[ 0.07124357 -0.10592994 -0.03893547]
[-0.13648944 0.10387124 0.07448013]
[ 0.04985565 -0.08291154 -0.04056595]
[-0.01069396 0.0115092 -0.00081524]]
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423827.html
標籤:其他