1.流水線介紹
流水線把資料挖掘程序的每個步驟保存在作業流中,
在資料挖掘程序中使用流水線,可以大大降低代碼及操作的復雜度,優化流程結構,可以有效減少常見問題的發生,
流水線通過 Pipeline() 來實體化,需要傳入的屬性是一連串資料挖掘的步驟,其中前幾個是轉換器,最后一個必須是估計器,
以經典的鳶尾資料為例,通過以下該簡單示例的代碼,我們來對比感受使用與不使用流水線下代碼的差別,
具體流程為:獲取資料后,首先進行歸一化處理,然后使用近鄰演算法預測,最后使用交叉檢驗輸出平均準確率,
2.示例
1.導包與獲取資料
import numpy as np
from sklearn.pipeline import Pipeline
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import cross_val_score
from sklearn.datasets import load_iris
# 獲取資料
dataset = load_iris()
# print(dataset)
X = dataset.data
y = dataset.target
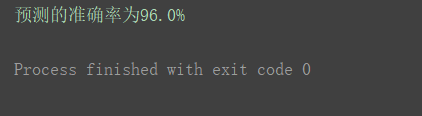
2.使用流水線前
X_transformed = MinMaxScaler().fit_transform(X)
estimator = KNeighborsClassifier()
scores = cross_val_score(estimator, X_transformed, y, scoring='accuracy')
print("預測的準確率為{0:.1f}%".format(np.mean(scores) * 100))
3.使用流水線后
scaling_pipeline = Pipeline([('scale', MinMaxScaler()),
('predict', KNeighborsClassifier())])
scores = cross_val_score(scaling_pipeline, X, y, scoring='accuracy')
print("預測的準確率為{0:.1f}%".format(np.mean(scores) * 100))
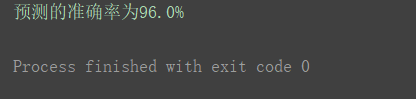
檢驗準確率也為96.0%,達到了和上邊傳統寫法一樣的效果,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423958.html
標籤:AI