交叉驗證(Cross Validation)和網格搜索(Grid Search)常結合在一起并用來篩選模型的最優引數,本文將從零開始一步步講解交叉驗證和網格搜索的由來,并基于sklearn實作它們,
目錄
- 一、交叉驗證法
- 1.1 交叉驗證法的由來
- 1.2 交叉驗證法的定義
- 1.3 sklearn.model_selection.train_test_split()
- 1.4 sklearn.metrics.accuracy_score()
- 1.4.1 clf.score 與 accuracy_score 的區別
- 1.5 sklearn.model_selection.cross_val_score()
- 二、網格搜索法
- 2.1 網格搜索法的由來
- 2.2 使用 for 回圈實作網格搜索
- 2.3 sklearn.model_selection.GridSearchCV()
- 2.3.1 引數
- 2.3.2 方法
- 2.3.3 屬性
- 三、專案實戰——鳶尾花分類
- 3.1 鳶尾花資料集介紹
- 3.2 sklearn.datasets.load_iris()
- 3.3 代碼實作
- References
一、交叉驗證法
1.1 交叉驗證法的由來
在機器學習中,我們通常是將已有的資料集(Data Set)一分為二(不一定等分),一部分是訓練集(Training Set),一部分是測驗集(Test Set),通常,我們會在訓練集上訓練模型(Model),然后在測驗集上評估模型的性能(Performance),評估性能需要用到性能度量(Performance Measure),即衡量模型好壞的指標,本文將使用準確率(accuracy)作為性能度量,
以軟間隔SVM為例,其中的引數 C C C 需要事先給定,我們將這種需要事先給定的引數稱為超引數(Hyperparameter),如果選用高斯核、多項式核、Sigmoid核,則其中的引數 γ , r , d \gamma, r, d γ,r,d 也是超引數,我們先只考慮線性核,也就是只有一個超引數的情形,
首先將資料集分為訓練集和測驗集,這個時候訓練集和測驗集已經固定了:

對于每個固定的 C C C,我們在訓練集上訓練都會得到一個軟間隔SVM模型,然后在測驗集上評估該模型的分類準確率,如果準確率高,我們就說模型是好的,反之則較差,我們自然是想找到使得分類準確率最高的那個 C C C,因為它對應的模型是最好的,尋找 “最好” 的 C C C 的這一程序稱為調參(Parameter Tuning),即不斷調整引數使得訓練出來的模型最優,“最好” 的 C C C 也稱為最優引數(Best Parameter),
為了敘述方便起見,我們接下來將模型在測驗集上的分類準確率稱為得分(Score),此外,因為當確定引數 C C C 后,模型也就隨之確定了,即引數和模型之間是一個一一對應的關系,所以我們后續也會使用 “引數的得分” 這種說法,
假設我們已經找到了最優引數: C b e s t C_{best} Cbest?,它所對應的模型的得分最高,現在,我們想測驗這個最優模型的泛化能力,可已經沒有資料供我們測驗了,如果還在測驗集上去測驗這個最優模型的性能,那無疑是重復勞動,因為我們在調參的程序中就已經在測驗集上測驗了每個模型的性能,另一方面,因為我們的 C C C 是根據模型在測驗集上的得分來進行選取的,也就是說,測驗集中的 “知識” 已經滲入到了我們的最優模型當中,這就會導致過擬合,從而降低了模型的泛化能力,
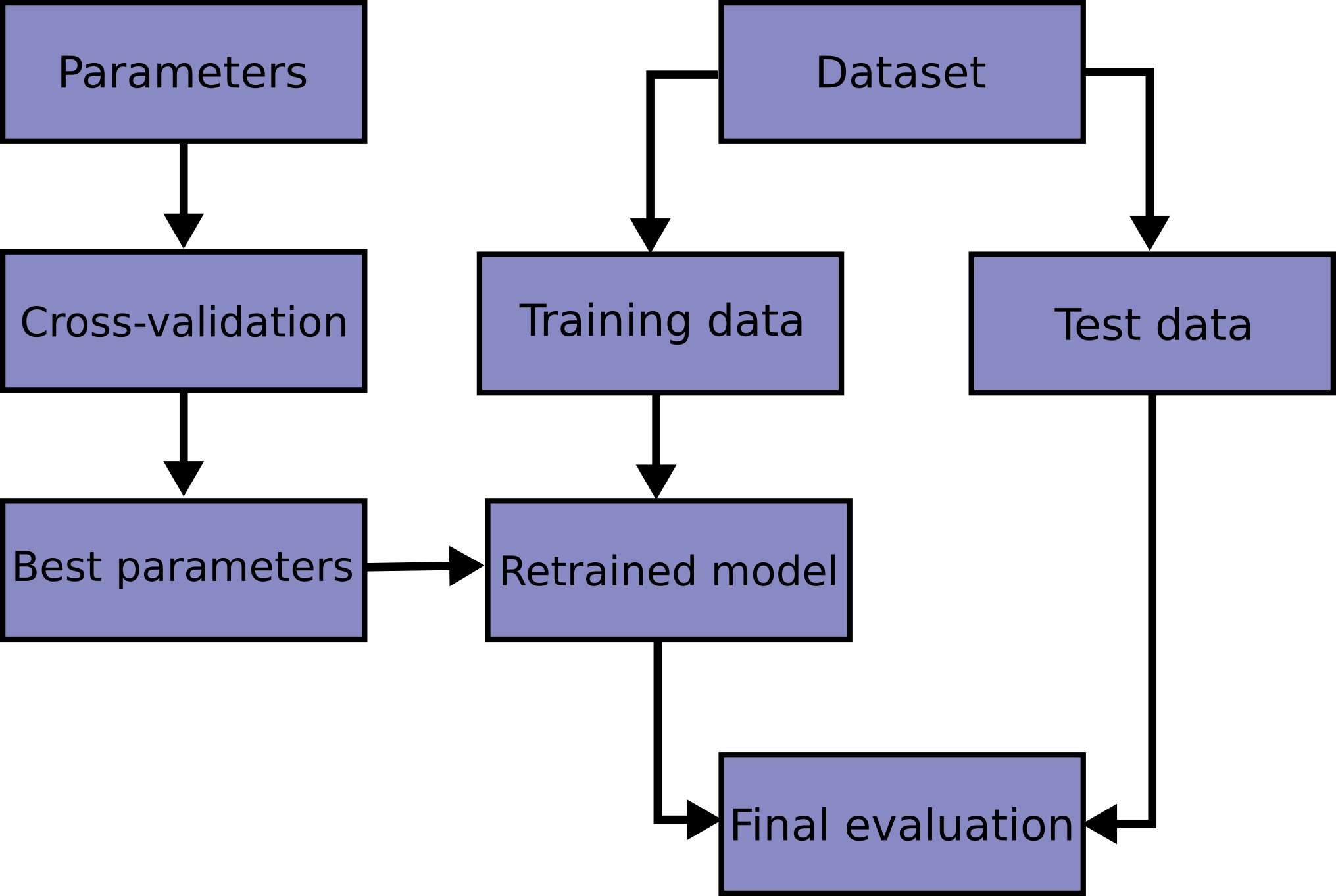
解決該問題的一個方法就是,將原先的訓練集一分為二,一部分用作訓練集,一部分用作驗證集(Validation Set),驗證集用來選擇最優引數,得到最優引數后再在原先的訓練集上重新訓練,得到的模型在測驗集上評估最終性能(Final Evaluation),

因為我們在得到最優引數之前都是在驗證集上對每個模型(引數)進行打分的,得分最高的成為最優引數,換句話說,最優引數與驗證集有關,而驗證集是從原先的訓練集劃分得來,這種劃分具有一定的偶然性,這就可能導致我們的最優引數是在眾多引數之中 “僥幸” 取勝,即最優引數更適合這個驗證集,如果換成另外一個驗證集,它可能就不是最優的了,
舉個例子,設原先的訓練集為 T T T,考慮兩種劃分方式: T = ( T \ V 1 ) ? ? ? V 1 T=(T\backslash V_1)\,\bigcup\, V_1 T=(T\V1?)?V1?, T = ( T \ V 2 ) ? ? ? V 2 T=(T\backslash V_2)\,\bigcup\, V_2 T=(T\V2?)?V2?,其中 V 1 , V 2 V_1, V_2 V1?,V2? 是不同的驗證集, T \ V 1 , T \ V 2 T\backslash V_1, T\backslash V_2 T\V1?,T\V2? 是訓練集,則可能會出現:
- 驗證集為 V 1 V_1 V1? 時,最優引數為 C = 1 C=1 C=1,最差引數為 C = 1000 C=1000 C=1000
- 驗證集為 V 2 V_2 V2? 時,最優引數為 C = 1000 C=1000 C=1000,最差引數為 C = 1 C=1 C=1
那么如何減少這種偶然性呢?直觀來看,應該取多個驗證集 V 1 , V 2 , ? ? , V m V_1, V_2,\cdots, V_m V1?,V2?,?,Vm?,引數在每個驗證集 V i V_i Vi? 上都會有一個得分 S i S_i Si?,這些得分的平均 S  ̄ = ( S 1 + ? + S m ) / m \overline{S}=(S_1+\cdots+S_m)/m S=(S1?+?+Sm?)/m 就作為這個引數的得分,
注意到驗證集是從原先的訓練集劃分得來,即 V i ? T , ?? i = 1 , ? ? , m V_i\subset T,\; i=1,\cdots,m Vi??T,i=1,?,m,為了進一步減少偶然性,很自然的一個想法就是把原先的訓練集全部用上并要求驗證集兩兩互斥且大小相等,即:
T = V 1 ? ∪ ? V 2 ? ∪ ? ∪ ? V m , ∣ V 1 ∣ = ∣ V 2 ∣ = ? = ∣ V m ∣ , V i ? ∩ ? V j = ? ( i ≠ j ) T=V_1\, \cup\, V_2\, \cup\cdots\cup\, V_m,\quad |V_1|=|V_2|=\cdots=|V_m|,\quad V_i\,\cap\, V_j=\varnothing(i\neq j) T=V1?∪V2?∪?∪Vm?,∣V1?∣=∣V2?∣=?=∣Vm?∣,Vi?∩Vj?=?(i?=j)
這樣我們就得到了 m m m 組訓練集 / / /驗證集,對于每一個引數,它的得分就是在這 m m m 個驗證集上得分的均值:
T = ( T \ V 1 ) ? ∪ ? V 1 ? S 1 T = ( T \ V 2 ) ? ∪ ? V 2 ? S 2 ?????????????????????????????????????????????????????????????????????????????????? ? ? T = ( T \ V m ) ? ∪ ? V m ? S m ? S  ̄ = S 1 + ? + S m m \begin{aligned} T=(T\backslash V_1)\,\cup\, V_1 \quad\Rightarrow\quad &S_1 \\ T=(T\backslash V_2)\,\cup\, V_2 \quad\Rightarrow\quad &S_2\\ &\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\!\vdots\quad\quad\quad\quad\quad\quad\quad\vdots \\ T=(T\backslash V_m)\,\cup\, V_m \quad\Rightarrow\quad &S_m \\ \end{aligned} \quad\Longrightarrow\quad \overline{S}=\frac{S_1+\cdots +S_m}{m} T=(T\V1?)∪V1??T=(T\V2?)∪V2??T=(T\Vm?)∪Vm???S1?S2???Sm???S=mS1?+?+Sm??
S  ̄ \overline{S} S 最高的引數成為我們的最優引數,下面的圖更形象的展示了這一程序:
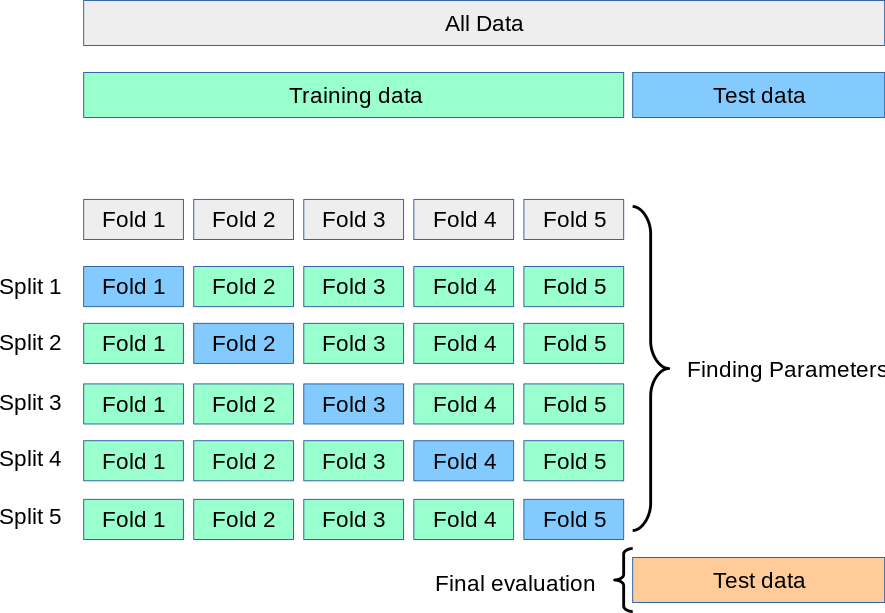
得到最優引數后,我們再在原先的訓練集上重新訓練,完整的流程圖如下:
很多時候,我們的 T T T 做不到 m m m 等分,那只能退而求其次,要求
∣ V 1 ∣ ≈ ∣ V 2 ∣ ≈ ? ≈ ∣ V m ∣ |V_1|\approx|V_2|\approx\cdots\approx|V_m| ∣V1?∣≈∣V2?∣≈?≈∣Vm?∣
這便是交叉驗證法,
1.2 交叉驗證法的定義
( 交 叉 驗 證 法 ) ?? \textcolor{purple}{(交叉驗證法)}\; (交叉驗證法) 將資料集 D D D(原先的訓練集)劃分為 k k k 個大小相似的互斥子集,每個子集 D i D_i Di? 盡可能保持資料分布的一致性,即從 D D D 中通過分層采樣得到,然后每次用 k ? 1 k - 1 k?1 個子集的并集作為訓練集,余下的那個子集作為驗證集;這樣就可以獲得 k k k 組訓練 / / /驗證集,從而可以進行 k k k 次訓練和驗證,最侄訓傳的是這 k k k 個結果的均值, 該方法又稱為 k k k 折交叉驗證(k-fold cross validation), k k k 常用的取值為 5 , 10 , 20 5,10,20 5,10,20 等,
( 留 一 法 ) ?? \textcolor{purple}{(留一法)}\; (留一法) 若 k = ∣ D ∣ k=|D| k=∣D∣,則得到了交叉驗證法的一個特例:留一法(Leave-One-Out,簡稱LOO),LOO使用的訓練集與初始資料集相比只少了一個樣本,這就使得在絕大多數情況下,LOO中被實際評估的模型與期望評估的用 D D D 訓練出的模型很相似,因此,LOO的評估結果往往被認為比較準確,但LOO也有缺陷: ∣ D ∣ |D| ∣D∣ 較大時,訓練 ∣ D ∣ |D| ∣D∣ 個模型的計算開銷可能是難以忍受的(這還是在未考慮調參的情況下),
1.3 sklearn.model_selection.train_test_split()
該函式的主要作用是將現有的資料集隨機劃分成訓練集和測驗集,其主要引數如下:
t r a i n _ t e s t _ s p l i t ( X , y , t e s t _ s i z e = N o n e , t r a i n _ s i z e = N o n e , r a n d o m _ s t a t e = N o n e ) \mathrm{train\_test\_split(X, y, test\_size=None, train\_size=None, random\_state=None)} train_test_split(X,y,test_size=None,train_size=None,random_state=None)
| 引數 | 描述 |
|---|---|
| X | 示例矩陣 |
| y | 標簽向量 |
| test_size | 可以為浮點數或整數;當為浮點數時,表示測驗集在整個資料集中所占的比例,當為整數時,表示測驗集的大小;當test_size和train_size都為None時,test_size默認調整至0.25 |
| train_size | 同上;當train_size為None時,默認調整至測驗集的補集的大小 |
對示例矩陣和標簽向量不了解的讀者可參考我的上一篇文章,
該函式會回傳一個串列 [ X _ t r a i n , X _ t e s t , y _ t r a i n , y _ t e s t ] [X\_train, X\_test, y\_train, y\_test] [X_train,X_test,y_train,y_test],我們只需要用相應的四個引數去接收即可,
from sklearn.model_selection import train_test_split
X = [[1, 2], [2, 3], [3, 3], [2, 1], [3, 2]]
y = [1, 1, 1, -1, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=42)
print(X_train)
# [[3, 3], [1, 2], [2, 1]]
print(X_test)
# [[2, 3], [3, 2]]
print(y_train)
# [1, 1, -1]
print(y_test)
# [1, -1]
1.4 sklearn.metrics.accuracy_score()
在進一步講解有關交叉驗證的函式之前,我們先來講一下有關性能度量的函式,
我們已經知道,SVC類的score方法 clf.score() 可以用來計算模型在測驗集上的分類準確率,例如:
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
clf = SVC(kernel='linear')
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.912
即分類準確率為 91.2 % 91.2\% 91.2%,
accuracy_score的使用方法:
a
c
c
u
r
a
c
y
_
s
c
o
r
e
(
y
_
t
r
u
e
,
y
_
p
r
e
d
)
\mathrm{accuracy\_score(y\_true, y\_pred)}
accuracy_score(y_true,y_pred),其中 y_true 是真實的標簽串列,而 y_pred 是預測的標簽串列,
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
clf = SVC(kernel='linear')
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(accuracy_score(y_test, y_pred))
# 0.912
看到這里,可能會有讀者疑惑,clf.score 和 accuracy_score 的結果一樣,那它們之間到底有什么區別呢?
1.4.1 clf.score 與 accuracy_score 的區別
不嚴謹地來講,accuracy_score 僅僅是按序比較兩個串列(array_like 物件),然后回傳相同元素的個數所占的比例:
from sklearn.metrics import accuracy_score
A = [1, 2, 3, 4]
B = [2, 2, 3, 5]
C = [4, 3, 2, 1]
print(accuracy_score(A, B))
# 0.5
print(accuracy_score(A, C))
# 0.4
從第二個輸出可以看出,雖然兩個串列的內容相同,但因為 accuracy_score 是按序(索引)進行比較的,所以準確率為
0
0
0;從第一個輸出可以看出,兩個串列只有索引
1
1
1 和
2
2
2 處的元素相同,所以準確率為
2
/
4
=
0.5
2/4=0.5
2/4=0.5,
再來看看 clf.score,其底層實作為
def score(self, X, y, sample_weight=None):
from .metrics import accuracy_score
return accuracy_score(y, self.predict(X), sample_weight=sample_weight)
可以看出本質上和 accuracy_score 沒有什么區別,但 clf.score 使用起來更為方便,因此更加推薦,
1.5 sklearn.model_selection.cross_val_score()
我們已經知道,
k
k
k 折交叉驗證一共會產生
k
k
k 個得分(這些得分的均值作為交叉驗證的得分),而 cross_val_score() 回傳的就是這
k
k
k 個得分,
該函式主要有以下引數:
c r o s s _ v a l _ s c o r e ( e s t i m a t o r , X , y , s c o r i n g = N o n e , c v = N o n e ) \mathrm{cross\_val\_score(estimator, X, y, scoring=None, cv=None)} cross_val_score(estimator,X,y,scoring=None,cv=None)
| 引數 | 描述 |
|---|---|
| estimator | SVM任務下就是SVC實體 |
| scoring | 性能度量;默認值為None,即采用SVC類中的score方法;有關scoring的可選引數請見官方檔案 |
| cv | k k k 折交叉驗證中的 k k k;默認值為None,即采用 5 5 5 折交叉驗證 |
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
clf = SVC(kernel='linear')
print(cross_val_score(clf, X, y, cv=3))
# [0.94011976 0.94011976 0.93373494]
print(cross_val_score(clf, X, y, cv=3, scoring='accuracy'))
# [0.94011976 0.94011976 0.93373494]
該例子也進一步說明了 clf.score 和 accuracy_score 是一樣的,
scores = cross_val_score(clf, X, y, cv=3)
print("%.4f accuracy with a standard deviation of %.4f" % (scores.mean(), scores.std()))
# 0.938 accuracy with a standard deviation of 0.003
即我們交叉驗證的得分為 0.938 0.938 0.938,
基于此,我們可以使用 cross_val_score 來選擇最優引數:
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
for C in [1, 10, 100, 1000, 10000, 100000]:
clf = SVC(C=C, kernel='linear')
scores = cross_val_score(clf, X, y, cv=4) # 四折交叉驗證
print('C: %d, accuracy: %.3f' % (C, scores.mean()))
# C: 1, accuracy: 0.936
# C: 10, accuracy: 0.936
# C: 100, accuracy: 0.936
# C: 1000, accuracy: 0.938
# C: 10000, accuracy: 0.938
# C: 100000, accuracy: 0.940
從輸出結果可以看出, C = 100000 C=100000 C=100000 是這六個引數中的最優引數(不過要注意的是,我們是直接將原有的資料集劃分為訓練集和驗證集,并未劃分出測驗集),
正確的流程應該是:先將原有的資料集劃分為訓練集和測驗集,在訓練集上進行 k k k 折交叉驗證來選取最優引數,得到最優引數后,在訓練集上訓練模型,在測驗集上測驗性能,完整的代碼如下:
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# 初始化
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
params = [1, 10, 100, 1000, 10000, 100000, 1000000]
params_score = []
# 尋找最優引數
for C in params:
clf = SVC(C=C, kernel='linear')
scores = cross_val_score(clf, X_train, y_train, cv=4)
params_score.append(scores.mean())
best_param = params[params_score.index(max(params_score))]
# 重新訓練
clf_best = SVC(C=best_param, kernel='linear')
clf_best.fit(X_train, y_train)
# 測驗性能
accuracy = clf_best.score(X_test, y_test)
print(best_param)
# 1000000
print(accuracy)
# 0.95
可以看出,我們使用最優引數訓練出來的模型在測驗集上的分類準確率為 95 % 95\% 95%,
二、網格搜索法
網格搜索法的本質是遍歷,
2.1 網格搜索法的由來
在訓練線性核軟間隔SVM時,會涉及到超引數 C C C,選取合適的 C C C 值能夠使我們訓練出來的模型最優,那么該如何去尋找這個最合適的 C C C 值呢?
一個很自然的想法就是把 C C C 的所有取值都試一遍,用交叉驗證法對每一個 C C C 值打分,得分最高的 C C C 成為我們的最優引數,但現實中,我們的引數一般都是連續取值的,我們不可能去遍歷所有的 C C C 值,因此只能考慮有限個 C C C 值,考慮到 C C C 一般較大,我們可以假設 C C C 的取值集合為
C = { 1 , 10 , 1 0 2 , ? ? , 1 0 6 } \boldsymbol C=\{1,10,10^2,\cdots,10^6\} C={1,10,102,?,106}
于是我們只需要去遍歷集合 C \boldsymbol C C,
現在考慮高斯核的情形,這時候會涉及到兩個引數: ( C , γ ) (C,\gamma) (C,γ),因為 γ \gamma γ 取值一般較小,我們可以假設它的取值集合為
γ = { 1 0 ? 6 , 1 0 ? 5 , ? ? , 1 0 ? 1 , 1 } \boldsymbol \gamma =\{10^{-6}, 10^{-5},\cdots,10^{-1},1\} γ={10?6,10?5,?,10?1,1}
現在作笛卡爾積 C × γ \boldsymbol C\times \boldsymbol\gamma C×γ,則該集合的大小為 ∣ C ∣ ? ∣ γ ∣ |\boldsymbol C|\cdot|\boldsymbol \gamma| ∣C∣?∣γ∣,且其中元素的形式為 ( C , γ ) (C,\gamma) (C,γ),遍歷 C × γ \boldsymbol C\times \boldsymbol\gamma C×γ 就相當于遍歷 ( C , γ ) (C,\gamma) (C,γ) 所有可能的組合,注意到 C × γ \boldsymbol C\times \boldsymbol\gamma C×γ 還可以用 “網格” 來進行表示:
| C = 1 C=1 C=1 | C = 10 C=10 C=10 | ? \cdots ? | C = 1 0 6 C=10^6 C=106 | |
|---|---|---|---|---|
| γ = 1 0 ? 6 \gamma=10^{-6} γ=10?6 | ( C = 1 , γ = 1 0 ? 6 ) (C=1, \gamma=10^{-6}) (C=1,γ=10?6) | ( C = 10 , γ = 1 0 ? 6 ) (C=10, \gamma=10^{-6}) (C=10,γ=10?6) | ? \cdots ? | ( C = 1 0 6 , γ = 1 0 ? 6 ) (C=10^6, \gamma=10^{-6}) (C=106,γ=10?6) |
| γ = 1 0 ? 5 \gamma=10^{-5} γ=10?5 | ( C = 1 , γ = 1 0 ? 5 ) (C=1, \gamma=10^{-5}) (C=1,γ=10?5) | ( C = 10 , γ = 1 0 ? 5 ) (C=10, \gamma=10^{-5}) (C=10,γ=10?5) | ? \cdots ? | ( C = 1 0 6 , γ = 1 0 ? 5 ) (C=10^6, \gamma=10^{-5}) (C=106,γ=10?5) |
| ? \vdots ? | ? \vdots ? | ? \vdots ? | ? \cdots ? | ? \vdots ? |
| γ = 1 \gamma=1 γ=1 | ( C = 1 , γ = 1 ) (C=1, \gamma=1) (C=1,γ=1) | ( C = 10 , γ = 1 ) (C=10, \gamma=1) (C=10,γ=1) | ? \cdots ? | ( C = 1 0 6 , γ = 1 ) (C=10^6, \gamma=1) (C=106,γ=1) |
因此遍歷 C × γ \boldsymbol C\times \boldsymbol\gamma C×γ 就相當于遍歷上面的網格,又因為我們需要在網格中找出最優引數,故該方法又稱網格搜索法,
不難看出,網格搜索法的本質就是暴力遍歷,即把每一種情況都試一遍,然后找出最優的那個,
2.2 使用 for 回圈實作網格搜索
因為網格搜索的本質是遍歷,所以我們完全可以使用 for 回圈來實作這種遍歷,
事實上,1.5 節中的最后一個例子就用到了網格搜索法,不過我們當時也僅僅是遍歷了一個引數的取值集合,現在我們考慮兩個引數的情形,即使用高斯核的軟間隔SVM,
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# 初始化
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
best_score = 0
# 尋找最優引數
for C in [1, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6]:
for gamma in [1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1]:
clf = SVC(C=C, gamma=gamma)
cv_scores = cross_val_score(clf, X_train, y_train, cv=4)
current_score = cv_scores.mean()
if current_score > best_score:
best_score = current_score
best_parameters = {'C': C, 'gamma': gamma}
# 重新訓練
clf_best = SVC(**best_parameters)
clf_best.fit(X_train, y_train)
# 測驗性能
accuracy = clf_best.score(X_test, y_test)
print(best_parameters)
# {'C': 100000.0, 'gamma': 0.01}
print(accuracy)
# 0.94
輸出結果表明,最優引數為 ( C = 100000 , γ = 0.01 ) (C=100000, \gamma=0.01) (C=100000,γ=0.01),最終的分類準確率為 94 % 94\% 94%,
2.3 sklearn.model_selection.GridSearchCV()
看到這里可能有讀者會想,雖然 for 回圈是可以實作網格搜索,那有沒有更簡便快捷的方法呢?好在 sklearn 提供了這樣的一個類:sklearn.model_selection.GridSearchCV,它結合了網格搜索與交叉驗證,能夠方便地給出你想要的結果,
2.3.1 引數
創建一個 GridSearchCV 實體常用到以下引數:
G r i d S e a r c h C V ( e s t i m a t o r , p a r a m _ g r i d , s c o r i n g = N o n e , r e f i t = T r u e , c v = N o n e ) \mathrm{GridSearchCV(estimator, param\_grid, scoring=None, refit=True,cv=None)} GridSearchCV(estimator,param_grid,scoring=None,refit=True,cv=None)
e s t i m a t o r : \textcolor{blue}{\mathrm{estimator:}} estimator:
在SVM場景下,estimator 指的是SVC實體,因為后續我們還需要向 GridSearchCV() 中傳入引數網格,所以創建SVC實體的時候不需要任何引數,即:
estimator = SVC()
clf = GridSearchCV(estimator, ...)
甚至可以更簡便地寫成
clf = GridSearchCV(SVC(), ...)
p a r a m _ g r i d : \textcolor{blue}{\mathrm{param\_grid:}} param_grid:
引數網格,可以為字典或字典串列,
例如對于2.2節中的例子,我們的引數網格就是一個字典:
param_grid = {
'C': [1, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6],
'gamma': [1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1],
}
該情形一共有 7 × 7 = 49 7\times7=49 7×7=49 種引陣列合,
對于某些復雜的任務,我們可能需要用到字典串列:
param_grid = [
{"kernel": ["rbf"], "gamma": [1e-3, 1e-4], "C": [1, 10, 100, 1000]},
{"kernel": ["linear"], "C": [1, 10, 100, 1000]},
]
該情形一共有 1 × 2 × 4 ? + ? 1 × 4 = 12 1\times 2\times4\,+\,1\times 4=12 1×2×4+1×4=12 種引陣列合,
s c o r i n g : \textcolor{blue}{\mathrm{scoring:}} scoring:
性能度量,默認值為None,常用引數為 'accuracy',
r e f i t : \textcolor{blue}{\mathrm{refit:}} refit:
默認值為 True,
refit 為 True 時,程式會使用得到的最優引數在原先的訓練集上重新訓練,結果會存盤在 GridSearchCV 實體的 best_estimator_ 屬性中(注意,best_estimator_ 是已經擬合了的 estimator),
2.3.2 方法
本小節僅列出最常用的三個方法,其他方法可自行參閱官方檔案,
| 方法 | 描述 |
|---|---|
| fit(X, y) | 基于所有引陣列合擬合estimator |
| predict(X) | 使用最優模型預測樣本;當 refit=True 時才可用 |
| score(X_test, y_test) | 除非 scoring 給定,否則采用 best_estimator_.score 方法計算得分 |
現在,我們將使用 GridSearchCV 來簡化2.2節中的代碼,
from sklearn.datasets import make_blobs
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
X, y = make_blobs(n_samples=500, centers=2, random_state=34)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
param_grid = {
'C': [1, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6],
'gamma': [1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1],
}
clf = GridSearchCV(SVC(), param_grid, cv=4)
clf.fit(X_train, y_train)
print(clf.score(X_test, y_test))
# 0.94
輸出結果與2.2節中的一致,但代碼大大得到了簡化,
2.3.3 屬性
這里僅列出常用的屬性,
| 屬性 | 描述 |
|---|---|
| cv_results_ | 以字典形式回傳交叉驗證的結果 |
| best_estimator_ | 使用最優引數在原先的訓練集上重新訓練得到的estimator |
| best_score_ | best_estimator的交叉驗證的得分(均值) |
| best_params_ | best_estimator中的引數 |
| best_index_ | best_params在 clf.cv_results_['params'] 中的索引 |
接下來我們通過一些例子進一步熟悉這些屬性,
為了簡便起見,我們將引數網格設定的 “小” 一點,其他不變
......
param_grid = {
'C': [1e4, 1e5],
'gamma': [1e-2, 1e-1],
}
......
print(clf.cv_results_)
輸出為:
{
'mean_fit_time': array([0.00424391, 0.01795793, 0.02118272, 0.12142873]),
'std_fit_time': array([0.00044348, 0.00522967, 0.00470208, 0.01951696]),
'mean_score_time': array([0. , 0.00074494, 0.0007624 , 0.00074446]),
'std_score_time': array([0. , 0.00043013, 0.00044034, 0.00042986]),
'param_C': masked_array(data=[10000.0, 10000.0, 100000.0, 100000.0],
mask=[False, False, False, False], fill_value='?', dtype=object),
'param_gamma': masked_array(data=[0.01, 0.1, 0.01, 0.1],
mask=[False, False, False, False], fill_value='?', dtype=object),
'params': [{'C': 10000.0, 'gamma': 0.01}, {'C': 10000.0, 'gamma': 0.1},
{'C': 100000.0, 'gamma': 0.01}, {'C': 100000.0, 'gamma': 0.1}],
'split0_test_score': array([0.94, 0.94, 0.95, 0.94]),
'split1_test_score': array([0.93, 0.95, 0.94, 0.94]),
'split2_test_score': array([0.97, 0.95, 0.98, 0.95]),
'split3_test_score': array([0.94, 0.94, 0.93, 0.93]),
'mean_test_score': array([0.945, 0.945, 0.95 , 0.94 ]),
'std_test_score': array([0.015 , 0.005 , 0.01870829, 0.00707107]),
'rank_test_score': array([2, 2, 1, 4])
}
注意:
'params'中存盤了所有的引陣列合,mean_fit_time,std_fit_time,mean_score_time和std_score_time的單位均是秒,
print(clf.best_estimator_)
# SVC(C=100000.0, gamma=0.01)
print(clf.best_params_)
# {'C': 100000.0, 'gamma': 0.01}
print(clf.best_index_)
# 2
print(clf.best_score_)
# 0.9500000000000001
不難看出,clf.best_estimator_ 等價于 SVC(**clf.best_params_),且最優引數 clf.best_params_ 在串列 clf.cv_results_['params'] 中的索引為 2,即
print(clf.cv_results_['params'][clf.best_index_] == clf.best_params_)
# True
三、專案實戰——鳶尾花分類
3.1 鳶尾花資料集介紹
sklearn 中有現成的鳶尾花資料集,我們可以從其中的 datasets 匯入加載鳶尾花資料集的函式:
from sklearn.datasets import load_iris
鳶尾花資料集介紹:
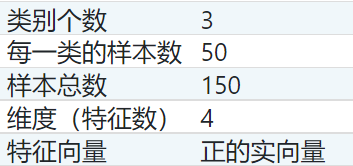
可以看出我們將面臨的問題是一個多(三)分類問題,
3.2 sklearn.datasets.load_iris()
該函式最主要的引數只有一個:return_X_y,
r e t u r n _ X _ y : \textcolor{blue}{\mathrm{return\_X\_y:}} return_X_y:
默認值為 False,
當值為 True 時,load_iris() 將回傳元組 (data, target) (即 (X, y) ),否則將以 Bunch 物件(類字典物件)回傳,
這里建議將 return_X_y 設定為 True,這樣我們就能很方便地使用兩個引數進行接收:
X, y = load_iris(return_X_y=True)
如果設定為 False (即默認狀態),我們就只能:
iris = load_iris()
X, y = iris.data, iris.target
3.3 代碼實作
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
X, y = load_iris(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
param_grid = {
'C': [1, 1e1, 1e2, 1e3, 1e4, 1e5, 1e6],
'kernel': ['rbf', 'linear'],
'gamma': [1e-6, 1e-5, 1e-4, 1e-3, 1e-2, 1e-1, 1],
}
clf = GridSearchCV(SVC(), param_grid, cv=5)
clf.fit(X_train, y_train)
print(clf.best_params_)
# {'C': 10.0, 'gamma': 0.1, 'kernel': 'rbf'}
print(clf.score(X_test, y_test))
# 0.9777777777777777
使用五折交叉驗證,我們的最優引數為 ( C = 10 , γ = 0.1 ) (C=10, \gamma=0.1) (C=10,γ=0.1),且核為高斯核,最終模型在測驗集上的分類準確率為 97.8 % 97.8\% 97.8%,
References
[1] Cross-validation: evaluating estimator performance.
[2] Tuning the hyper-parameters of an estimator.
[3] sklearn.datasets.load_iris.
[4] 機器學習. 周志華
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423959.html
標籤:AI
上一篇:python機器學習之流水線