OpenCV-Python實戰(19)——OpenCV與深度學習的碰撞
- 0. 前言
- 1. cv2.dnn.blobFromImage() 函式詳解
- 2. OpenCV DNN 人臉檢測器
- 3. OpenCV 影像分類
- 3.1 使用 AlexNet 進行影像分類
- 3.2 使用 GoogLeNet 進行影像分類
- 3.3 使用 ResNet 進行影像分類
- 3.4 使用 SqueezeNet 進行影像分類
- 4. OpenCV 目標檢測
- 4.1 使用 MobileNet-SSD 進行目標檢測
- 4.1 使用 YOLO V3 進行目標檢測
- 小結
- 系列鏈接
0. 前言
OpenCV 中包含深度神經網路 (Deep Neural Networks, DNN) 模塊,可以使用深度神經網路實作前向計算(推理階段),使用一些流行的深度學習框架進行預訓練的網路(例如 Caffe、TensorFlow、Pytorch、Darknet 等)就可以輕松用在 OpenCV 專案中了,
在《深度學習簡介與入門示例》中,我們已經介紹了許多流行的深度學習網路架構,在本文中,我們將學習如何將這些架構應用于目標檢測和影像分類,
1. cv2.dnn.blobFromImage() 函式詳解
OpenCV 中深度神經網路為了執行前向計算,其輸入應該是一個 blob,blob 可以看作是經過預處理(包括縮放、裁剪、歸一化、通道交換等)以饋送到網路的影像集合,
在 OpenCV 中,使用 cv2.dnn.blobFromImage() 構建 blob:
# 影像加載
image = cv2.imread("example.jpg")
# 利用 image 創建 4 維 blob
blob = cv2.dnn.blobFromImage(image, 1.0, (300, 300), [104., 117., 123.], False, False)
上述代碼意味著我們進行以下預處理:調整為 300 x 300 的 BGR 影像、分別對藍色、綠色和紅色通道執行 (104, 117, 123) 均值減法 ,
接下來,我們將可以將 blob 設定為輸入并獲得檢測結果如下:
# 將 blob 設定為輸入并獲取檢測結果
net.setInput(blob)
detections = net.forward()
接下來,首先詳細講解 cv2.dnn.blobFromImage() 和 cv2.dnn.blobFromImages() 函式,理解這些函式后,對于后續專案的構建將很有幫助,
cv2.dnn.blobFromImage() 函式的用法如下:
retval = cv2.dnn.blobFromImage(image[, scalefactor[, size[, mean[, swapRB[, crop[, ddepth]]]]]])
此函式從 image 創建一個四維 blob,引數含義如下所示:
| 引數 | 解釋 |
|---|---|
| image | 要預處理的輸入影像 |
| scalefactor | 縮放因子,用于縮放像素值,默認值為 1.0,即不執行縮放 |
| size | 輸出影像的尺寸 |
| mean | 將在影像中減去的標量,如果使用均值減法,在 swapRB =True 時,結果為 (mean-R, mean-G, mean-B) |
| swapRB | 若此標志設定為 True,此標志可用于交換影像中的 R 和 B 通道 |
| crop | 此標志用于指示在調整大小后是否會裁剪影像 |
| ddepth | 輸出 blob 的深度,可選值包括 CV_32F 或 CV_8U |
如果 crop=False,則在不裁剪的情況下執行影像的大小調整;否則,將首先調整大小,然后從中心裁剪影像
cv2.dnn.blobFromImage() 函式的默認值如下:scalefactor=1.0, size = Size(), mean = Scalar(), swapRB = false, crop = false, ddepth = CV_32F,
cv2.dnn.blobFromImages() 函式的用法如下:
retval = cv.dnn.blobFromImages(images[, scalefactor[, size[, mean[, swapRB[, crop[, ddepth]]]]]])
此函式可以從多個影像創建一個四維 blob,通過這種方式,可以對整個網路執行一次前向計算獲得多個影像的輸出:
# 創建影像串列
images = []
for img in glob.glob('*.png'):
images.append(cv2.imread(img))
blob_images = cv2.dnn.blobFromImages(images, 1.0, (300, 300), [104., 117., 123.], False, False)
# 前向計算
net.setInput(blob_images)
detections = net.forward()
為了測驗 cv2.dnn.blobFromImage() 函式,首先加載一個 BGR 影像,然后使用 cv2.dnn.blobFromImage() 函式創建一個四維 blob,然后,我們撰寫 get_image_from_blob() 函式,該函式可用于執行逆預處理變換以再次獲取輸入影像,以更好地理解 cv2.dnn.blobFromImage() 函式的預處理:
# 加載影像
image = cv2.imread("example.png")
# 呼叫 cv2.dnn.blobFromImage() 函式
blob_image = cv2.dnn.blobFromImage(image, 1.0, (300, 300), [104., 117., 123.], False, False)
# blob_image 的尺寸為 (1, 3, 300, 300)
print(blob_image.shape)
def get_image_from_blob(blob_img, scalefactor, dim, mean, swap_rb, mean_added):
images_from_blob = cv2.dnn.imagesFromBlob(blob_img)
image_from_blob = np.reshape(images_from_blob[0], dim) / scalefactor
image_from_blob_mean = np.uint8(image_from_blob)
image_from_blob = image_from_blob_mean + np.uint8(mean)
if mean_added is True:
if swap_rb:
image_from_blob = image_from_blob[:, :, ::-1]
return image_from_blob
else:
if swap_rb:
image_from_blob_mean = image_from_blob_mean[:, :, ::-1]
return image_from_blob_mean
# 從 blob 中獲取不同的影像
# img_from_blob 影像對應于調整為 (300,300) 的原始 BGR 影像,并且已經添加了通道均值
img_from_blob = get_image_from_blob(blob_image, 1.0, (300, 300, 3), [104., 117., 123.], False, True)
# img_from_blob_swap 影像對應于調整大小為 (300,300) 的原始 RGB 影像
# img_from_blob_swap 交換了藍色和紅色通道,并且已經添加了通道均值
img_from_blob_swap = get_image_from_blob(blob_image, 1.0, (300, 300, 3), [104., 117., 123.], True, True)
# img_from_blob_mean 影像對應于調整大小為 (300,300) 的原始 BGR 影像,其并未添加通道均值
img_from_blob_mean = get_image_from_blob(blob_image, 1.0, (300, 300, 3), [104., 117., 123.], False, False)
# img_from_blob_mean_swap 影像對應于調整為 (300,300) 的原始 RGB 影像
# img_from_blob_mean_swap 交換了藍色和紅色通道,并未添加通道均值
img_from_blob_mean_swap = get_image_from_blob(blob_image, 1.0, (300, 300, 3), [104., 117., 123.], True, False)
# 可視化
def show_img_with_matplotlib(color_img, title, pos):
img_RGB = color_img[:, :, ::-1]
ax = plt.subplot(1, 4, pos)
plt.imshow(img_RGB)
plt.title(title, fontsize=10)
plt.axis('off')
show_img_with_matplotlib(img_from_blob, "img from blob " + str(img_from_blob.shape), 1)
show_img_with_matplotlib(img_from_blob_swap, "img from blob swap " + str(img_from_blob.shape), 2)
show_img_with_matplotlib(img_from_blob_mean, "img from blob mean " + str(img_from_blob.shape), 3)
show_img_with_matplotlib(img_from_blob_mean_swap, "img from blob mean swap " + str(img_from_blob.shape), 4)
程式的輸出如下圖所示:

接下來,我們首先加載目標檔案夾中的所有影像,然后使用 cv2.dnn.blobFromImages() 函式創建一個四維 blob,同樣,我們撰寫 get_images_from_blob() 函式用于執行逆預處理變換以再次獲取輸入影像,
get_images_from_blob 函式的代碼如下:
def get_images_from_blob(blob_imgs, scalefactor, dim, mean, swap_rb, mean_added):
images_from_blob = cv2.dnn.imagesFromBlob(blob_imgs)
imgs = []
for image_blob in images_from_blob:
image_from_blob = np.reshape(image_blob, dim) / scalefactor
image_from_blob_mean = np.uint8(image_from_blob)
image_from_blob = image_from_blob_mean + np.uint8(mean)
if mean_added is True:
if swap_rb:
image_from_blob = image_from_blob[:, :, ::-1]
imgs.append(image_from_blob)
else:
if swap_rb:
image_from_blob_mean = image_from_blob_mean[:, :, ::-1]
imgs.append(image_from_blob_mean)
return imgs
如前所述,get_images_from_blob() 函式使用 OpenCV cv2.dnn.imagesFromBlob() 函式從 blob 回傳影像,在腳本中,我們使用此函式從 blob 中獲取不同的影像,如下所示:
# 加載影像并構造影像串列
images = []
for img in glob.glob('*.png'):
images.append(cv2.imread(img))
# 呼叫 cv2.dnn.blobFromImages() 函式
blob_images = cv2.dnn.blobFromImages(images, 1.0, (300, 300), [104., 117., 123.], False, False)
# 列印形狀
print(blob_images.shape)
# 從 blob 中獲取不同的影像
# imgs_from_blob 影像對應于調整大小為 (300,300) 的原始 BGR 影像,并且已經添加了通道均值
imgs_from_blob = get_images_from_blob(blob_images, 1.0, (300, 300, 3), [104., 117., 123.], False, True)
# img_from_blob_swap 影像對應于調整大小為 (300,300) 的原始 RGB 影像
# img_from_blob_swap 交換了藍色和紅色通道,并且已經添加了通道均值
imgs_from_blob_swap = get_images_from_blob(blob_images, 1.0, (300, 300, 3), [104., 117., 123.], True, True
# img_from_blob_mean 影像對應于調整大小為 (300,300) 的原始 BGR 影像,其并未添加通道均值
imgs_from_blob_mean = get_images_from_blob(blob_images, 1.0, (300, 300, 3), [104., 117., 123.], False, False)
# img_from_blob_mean_swap 影像對應于調整為 (300,300) 的原始 RGB 影像
# img_from_blob_mean_swap 交換了藍色和紅色通道,并未添加通道均值
imgs_from_blob_mean_swap = get_images_from_blob(blob_images, 1.0, (300, 300, 3), [104., 117., 123.], True, False)
# 可視化,show_img_with_matplotlib() 函式與上例相同
for i in range(len(images)):
show_img_with_matplotlib(imgs_from_blob[i], "img from blob " + str(imgs_from_blob[i].shape), i * 4 + 1)
show_img_with_matplotlib(imgs_from_blob_swap[i], "img from blob swap " + str(imgs_from_blob_swap[i].shape), i * 4 + 2)
show_img_with_matplotlib(imgs_from_blob_mean[i], "img from blob mean " + str(imgs_from_blob_mean[i].shape), i * 4 + 3)
show_img_with_matplotlib(imgs_from_blob_mean_swap[i], "img from blob mean swap " + str(imgs_from_blob_mean_swap[i].shape), i * 4 + 4)
程式輸出如下圖所示:

cv2.dnn.blobFromImage() 和 cv2.dnn.blobFromImages() 的最后一個重要的引數是 crop 引數,它指示影像是否需要裁剪,在 crop = True 的情況下,影像從中心進行裁剪,為了更好的理解 OpenCV 在 cv2.dnn.blobFromImage() 和 cv2.dnn.blobFromImages() 函式中執行的裁剪,我們撰寫 get_cropped_img() 函式進行復刻:
def get_cropped_img(img):
img_copy = img.copy()
size = min(img_copy.shape[1], img_copy.shape[0])
x1 = int(0.5 * (img_copy.shape[1] - size))
y1 = int(0.5 * (img_copy.shape[0] - size))
return img_copy[y1:(y1 + size), x1:(x1 + size)]
如上所示,裁剪影像的大小基于原始影像的最小邊,
images = []
for img in glob.glob('*.png'):
images.append(cv2.imread(img))
# 使用 get_cropped_img() 函式進行裁剪
cropped_img = get_cropped_img(images[0])
# crop = False 不進行裁剪
blob_images = cv2.dnn.blobFromImages(images, 1.0, (300, 300), [104., 117., 123.], False, False)
print(blob_images)
# crop = True 進行裁剪
blob_blob_images_cropped = cv2.dnn.blobFromImages(images, 1.0, (300, 300), [104., 117., 123.], False, True)
imgs_from_blob = get_images_from_blob(blob_images, 1.0, (300, 300, 3), [104., 117., 123.], False, True)
imgs_from_blob_cropped = get_images_from_blob(blob_blob_images_cropped, 1.0, (300, 300, 3), [104., 117., 123.], False, True)
# 可視化,show_img_with_matplotlib() 函式與上例相同
for i in range(len(images)):
show_img_with_matplotlib(imgs_from_blob[i], "img {} from blob ".format(i) + str(imgs_from_blob[i].shape), i + 1)
show_img_with_matplotlib(imgs_from_blob_cropped[i], "img {} from blob cropped ".format(i) + str(imgs_from_blob[i].shape), i + 5)
程式輸出結果如下圖所示,可以看到裁剪保持了影像的縱橫比:

2. OpenCV DNN 人臉檢測器
接下來,將多個影像饋送到網路進行前向計算輸出人臉檢測結果,以更好的理解 cv2.dnn.blobFromImages() 函式,
首先查看當 cv2.dnn.blobFromImages() 函式中 crop=True 時的檢測效果:
net = cv2.dnn.readNetFromCaffe("deploy.prototxt", "res10_300x300_ssd_iter_140000_fp16.caffemodel")
# 加載圖片,構建 blob
img_1 = cv2.imread('example_1.png')
img_2 = cv2.imread('example_2.png')
images = [img_1.copy(), img_2.copy()]
blob_images = cv2.dnn.blobFromImages(images, 1.0, (300, 300), [104., 117., 123.], False, False)
# 前向計算
net.setInput(blob_images)
detections = net.forward()
for i in range(0, detections.shape[2]):
# 首先,獲得檢測結果所屬的影像
img_id = int(detections[0, 0, i, 0])
# 獲取預測的置信度
confidence = detections[0, 0, i, 2]
# 過濾置信度較低的預測
if confidence > 0.25:
# 獲取當前影像尺寸
(h, w) = images[img_id].shape[:2]
# 獲取檢測的 (x, y) 坐標
box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
(startX, startY, endX, endY) = box.astype("int")
# 繪制邊界框和概率
text = "{:.2f}%".format(confidence * 100)
y = startY - 10 if startY - 10 > 10 else startY + 10
cv2.rectangle(images[img_id], (startX, startY), (endX, endY), (0, 0, 255), 2)
cv2.putText(images[img_id], text, (startX, y), cv2.FONT_HERSHEY_SIMPLEX, 1.5, (0, 0, 255), 2)
# 可視化
show_img_with_matplotlib(img_1, "input img 1", 1)
show_img_with_matplotlib(img_2, "input img 2", 2)
show_img_with_matplotlib(images[0], "output img 1", 3)
show_img_with_matplotlib(images[1], "output img 2", 4)

接下來使用保持縱橫比進行裁剪后的檢測結果,可以看到縱橫比保持的情況下,檢測到的置信度更高:
# 只需修改 cv2.dnn.blobFromImages() 中的 crop 引數為 True
blob_images = cv2.dnn.blobFromImages(images, 1.0, (300, 300), [104., 117., 123.], False, True)

3. OpenCV 影像分類
接下來將介紹使用不同的預訓練深度學習模型執行影像分類,為了對比不同模型的運行效率,可以使用 net.getPerfProfile() 方法獲取推理階段所用時間:
# 前向計算獲取預測結果
net.setInput(blob)
preds = net.forward()
# 獲取推理時間
t, _ = net.getPerfProfile()
print('Inference time: %.2f ms' % (t * 1000.0 / cv2.getTickFrequency()))
如上所示,在執行推理后呼叫 net.getPerfProfile() 方法獲取推理時間, 通過這種方式,可以比較使用不同深度學習架構的推理時間,
3.1 使用 AlexNet 進行影像分類
使用 Caffe 預訓練的 AlexNet 模型進行影像分類可以分為以下步驟:
- 加載類別的名稱
- 加載的
Caffe模型 - 加載輸入影像,并對輸入影像進行預處理獲取
blob - 將輸入的
blob饋送到網路,進行推理,并得到輸出 - 得到概率最高的 10 個預測類別(降序排列)
- 在影像上繪制置信度最高的類別和概率
類別名、模型架構和模型權重引數均可在 Gitbub 進行下載,
# 1. 加載類的名稱
rows = open('synset_words.txt').read().strip().split('\n')
classes = [r[r.find(' ') + 1:].split(',')[0] for r in rows]
# 2. 加載的 Caffe 模型
net = cv2.dnn.readNetFromCaffe("bvlc_alexnet.prototxt", "bvlc_alexnet.caffemodel")
# 3. 加載輸入影像,并對輸入影像進行預處理獲取 blob
image = cv2.imread('pandas.jpeg')
blob = cv2.dnn.blobFromImage(image, 1, (227, 227), (104, 117, 123))
print(blob.shape)
# 4. 將輸入的 `blob` 饋送到網路,進行推理,并得到輸出
net.setInput(blob)
preds = net.forward()
# 獲取推理時間
t, _ = net.getPerfProfile()
print('Inference time: %.2f ms' % (t * 1000.0 / cv2.getTickFrequency()))
# 5. 得到概率最高的 10 個預測類別(降序排列)
indexes = np.argsort(preds[0])[::-1][:10]
# 6. 在影像上繪制置信度最高的類別和概率
text = "label: {}\nprobability: {:.2f}%".format(classes[indexes[0]], preds[0][indexes[0]] * 100)
y0, dy = 30, 30
for i, line in enumerate(text.split('\n')):
y = y0 + i * dy
cv2.putText(image, line, (5, y), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 255, 255), 2)
# 列印置信度排名前十的類別
for (index, idx) in enumerate(indexes):
print("{}. label: {}, probability: {:.10}".format(index + 1, classes[idx], preds[0][idx]))
show_img_with_matplotlib(image, "AlexNet and caffe pre-trained models", 1)
plt.show()

如上圖所示,圖片以 0.9948046803 的置信度被分類為大熊貓,置信度前 10 的預測結果如下:
1. label: giant panda, probability: 0.9948046803
2. label: lesser panda, probability: 0.002839741996
3. label: Arctic fox, probability: 0.001207351917
4. label: teddy, probability: 0.0001851956185
5. label: Samoyed, probability: 0.0001801071776
6. label: Old English sheepdog, probability: 0.0001742217282
7. label: Border collie, probability: 8.865840209e-05
8. label: badger, probability: 6.369451148e-05
9. label: indri, probability: 5.878169759e-05
10. label: dalmatian, probability: 4.750319204e-05
3.2 使用 GoogLeNet 進行影像分類
使用 GoogLeNet 模型進行影像分類的步驟與使用 Caffe 預訓練的 AlexNet 模型進行影像分類步驟相同,唯一的區別在于其加載的模型為 Caffe 預訓練的 GoogLeNet 模型(類別名、GoogLeNet 模型架構和模型權重引數均可在 Gitbub 進行下載):
net = cv2.dnn.readNetFromCaffe("bvlc_googlenet.prototxt", "bvlc_googlenet.caffemodel")
程式的輸出結果如下所示:

如上圖所示,圖片以 0.997341454 的置信度被分類為大熊貓,置信度前 10 的預測結果如下:
1. label: giant panda, probability: 0.997341454
2. label: lesser panda, probability: 0.00163484423
3. label: Arctic fox, probability: 0.0001777200523
4. label: Madagascar cat, probability: 0.0001774487464
5. label: indri, probability: 0.000139524127
6. label: teddy, probability: 8.606248593e-05
7. label: langur, probability: 4.349003575e-05
8. label: soccer ball, probability: 4.122937389e-05
9. label: dalmatian, probability: 3.438878412e-05
10. label: capuchin, probability: 2.523723379e-05
3.3 使用 ResNet 進行影像分類
使用 ResNet 模型進行影像分類的步驟與使用 AlexNet 模型進行影像分類步驟相同,唯一的區別在于其加載的模型為 Caffe 預訓練的 ResNet 模型(這里對類別名、訓練后 ResNet 模型架構和模型權重引數檔案進行壓縮供大家進行下載,也可以自己構建模型訓練獲得 ResNet 模型引數):
net = cv2.dnn.readNetFromCaffe("ResNet-50-deploy.prototxt", "ResNet-50-model.caffemodel")
程式的輸出結果如下所示:

如上圖所示,圖片以 0.9906288981 的置信度被分類為大熊貓,置信度前 10 的預測結果如下:
1. label: giant panda, probability: 0.9906288981
2. label: badger, probability: 0.002265424468
3. label: lesser panda, probability: 0.00156865106
4. label: dalmatian, probability: 0.0008186288178
5. label: skunk, probability: 0.0004198730458
6. label: indri, probability: 0.0004003143404
7. label: ram, probability: 0.0002219640737
8. label: Madagascar cat, probability: 0.0001818448509
9. label: ice bear, probability: 0.000126767889
10. label: Newfoundland, probability: 0.0001197585734
3.4 使用 SqueezeNet 進行影像分類
接下來使用 SqueezeNet 神經網路架構執行影像分類,引數量相比 AlexNet 網路架構減少了 50 倍,對以上程式進行修改,將其加載的模型修改為 Caffe 預訓練的 SqueezeNet 模型(類別名、SqueezeNet 模型架構和模型權重引數均可在 Gitbub 進行下載):
net = cv2.dnn.readNetFromCaffe('squeezenet_v1.1_deploy.prototxt', "squeezenet_v1.1.caffemodel")
# ...
# 使用 SqueezeNet 時需要對預測結果 preds 進行整形
preds = preds.reshape((1, len(classes)))
indexes = np.argsort(preds[0])[::-1][:10]
程式的輸出結果如下所示:

如上圖所示,圖片以 0.9963214397 的置信度被分類為大熊貓,置信度前 10 的預測結果如下:
1. label: giant panda, probability: 0.9963214397
2. label: lesser panda, probability: 0.003480769461
3. label: teddy, probability: 4.718080891e-05
4. label: Arctic fox, probability: 4.203413118e-05
5. label: Samoyed, probability: 2.355617653e-05
6. label: soccer ball, probability: 1.932817031e-05
7. label: langur, probability: 1.073173735e-05
8. label: gibbon, probability: 7.374388133e-06
9. label: weasel, probability: 4.493716915e-06
10. label: Eskimo dog, probability: 3.58794864e-06
4. OpenCV 目標檢測
接下來將介紹使用不同的預訓練模型執行目標檢測,目標檢測的任務是檢測影像或視頻中預定義類(例如,貓、汽車和人類)的實體,
4.1 使用 MobileNet-SSD 進行目標檢測
MobileNets 是用于移動視覺應用的高效卷積神經網路,MobileNet-SSD 在 COCO 資料集上進行了訓練,達到了 72.27% mAP,可以用于檢測到 20 種物件類別(這里對訓練后 MobileNet-SSD 模型架構和模型權重引數檔案進行壓縮供大家進行下載,也可以自己構建模型訓練獲得 MobileNet-SSD 模型引數):
Person(人): Person(人)
Animal(動物): Bird(鳥), cat(貓), cow(牛), dog(狗), horse(馬), sheep(羊)
Vehicle(交通工具): Aeroplane(飛機), bicycle(自行車), boat(船), bus(公共汽車), car(小轎車), motorbike(摩托車), train(火車)
Indoor(室內): Bottle(水瓶), chair(椅子), dining table(餐桌), potted plant(盆栽), sofa(沙發), TV/monitor(電視/顯示幕)
通過使用 MobileNet-SSD 和 Caffe 預訓練模型,使用 OpenCV DNN 模塊執行物件檢測:
# 加載模型及引數
net = cv2.dnn.readNetFromCaffe('MobileNetSSD_deploy.prototxt', 'MobileNetSSD_deploy.caffemodel')
# 圖片讀取
image = cv2.imread('test_img.jpg')
# 定義類別名
class_names = {0: 'background', 1: 'aeroplane', 2: 'bicycle', 3: 'bird', 4: 'boat', 5: 'bottle', 6: 'bus', 7: 'car',8: 'cat', 9: 'chair', 10: 'cow', 11: 'diningtable', 12: 'dog', 13: 'horse', 14: 'motorbike', 15: 'person', 16: 'pottedplant', 17: 'sheep', 18: 'sofa', 19: 'train', 20: 'tvmonitor'}
# 預處理
blob = cv2.dnn.blobFromImage(image, 0.007843, (300, 300), (127.5, 127.5, 127.5))
print(blob.shape)
# 前向計算
net.setInput(blob)
detections = net.forward()
t, _ = net.getPerfProfile()
print('Inference time: %.2f ms' % (t * 1000.0 / cv2.getTickFrequency()))
# 輸入影像尺寸
dim = 300
# 處理檢測結果
for i in range(detections.shape[2]):
# 獲得預測的置信度
confidence = detections[0, 0, i, 2]
# 去除置信度較低的預測
if confidence > 0.2:
# 獲取類別標簽
class_id = int(detections[0, 0, i, 1])
# 獲取檢測到目標物件框的坐標
xLeftBottom = int(detections[0, 0, i, 3] * dim)
yLeftBottom = int(detections[0, 0, i, 4] * dim)
xRightTop = int(detections[0, 0, i, 5] * dim)
yRightTop = int(detections[0, 0, i, 6] * dim)
# 縮放比例系數
heightFactor = image.shape[0] / dim
widthFactor = image.shape[1] / dim
# 根據縮放比例系數計算檢測結果最終坐標
xLeftBottom = int(widthFactor * xLeftBottom)
yLeftBottom = int(heightFactor * yLeftBottom)
xRightTop = int(widthFactor * xRightTop)
yRightTop = int(heightFactor * yRightTop)
# 繪制矩形框
cv2.rectangle(image, (xLeftBottom, yLeftBottom), (xRightTop, yRightTop), (0, 255, 0), 2)
# 繪制置信度和類別
if class_id in class_names:
label = class_names[class_id] + ": " + str(confidence)
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 1, 2)
yLeftBottom = max(yLeftBottom, labelSize[1])
cv2.rectangle(image, (xLeftBottom, yLeftBottom - labelSize[1]),
(xLeftBottom + labelSize[0], yLeftBottom + 0), (0, 255, 0), cv2.FILLED)
cv2.putText(image, label, (xLeftBottom, yLeftBottom), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 0), 2)
程式輸出如下圖所示,幾乎所有物件都被正確且高精度地檢測到:

4.1 使用 YOLO V3 進行目標檢測
YOLO v3 使用一些技巧來改進訓練和提高性能,包括多尺度預測和更好的主干分類器等(這里同樣對訓練后 YOLO V3 模型架構和模型權重引數檔案進行整理壓縮供大家進行下載,也可以自己構建模型訓練獲得 YOLO V3 模型引數,或者在以下地址下載 yolov3.weights 檔案):
# 加載類別名
class_names = open('coco.names').read().strip().split('\n')
# 加載網路及引數
net = cv2.dnn.readNetFromDarknet('yolov3.cfg', 'yolov3.weights')
# 加載測驗影像
image = cv2.imread('test_img.jpg')
(H, W) = image.shape[:2]
# 獲取網路輸出
layer_names = net.getLayerNames()
layer_names = [layer_names[i[0] - 1] for i in net.getUnconnectedOutLayers()]
# 預處理
blob = cv2.dnn.blobFromImage(image, 1 / 255.0, (416, 416), swapRB=True, crop=False)
print(blob.shape)
# 前向計算
net.setInput(blob)
layerOutputs = net.forward(layer_names)
t, _ = net.getPerfProfile()
print('Inference time: %.2f ms' % (t * 1000.0 / cv2.getTickFrequency()))
# 構建結果陣列
boxes = []
confidences = []
class_ids = []
# 回圈輸出結果
for output in layerOutputs:
# 回圈檢測結果
for detection in output:
# 獲取類別 id 和置信度
scores = detection[5:]
class_id = np.argmax(scores)
confidence = scores[class_id]
# 過濾低置信度目標
if confidence > 0.25:
# 使用原始影像的尺寸縮放邊界框坐標
box = detection[0:4] * np.array([W, H, W, H])
(centerX, centerY, width, height) = box.astype("int")
# 計算邊界框左上角坐標
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
# 將結果添加到結果陣列中
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
class_ids.append(class_id)
# 應用非極大值抑制
indices = cv2.dnn.NMSBoxes(boxes, confidences, 0.5, 0.3)
# 繪制結果
if len(indices) > 0:
for i in indices.flatten():
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)
label = "{}: {:.4f}".format(class_names[class_ids[i]], confidences[i])
labelSize, baseLine = cv2.getTextSize(label, cv2.FONT_HERSHEY_SIMPLEX, 1, 2)
y = max(y, labelSize[1])
cv2.rectangle(image, (x, y - labelSize[1]), (x + labelSize[0], y + 0), (0, 255, 0), cv2.FILLED)
cv2.putText(image, label, (x, y), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 0), 2)
程式輸出如下圖所示:
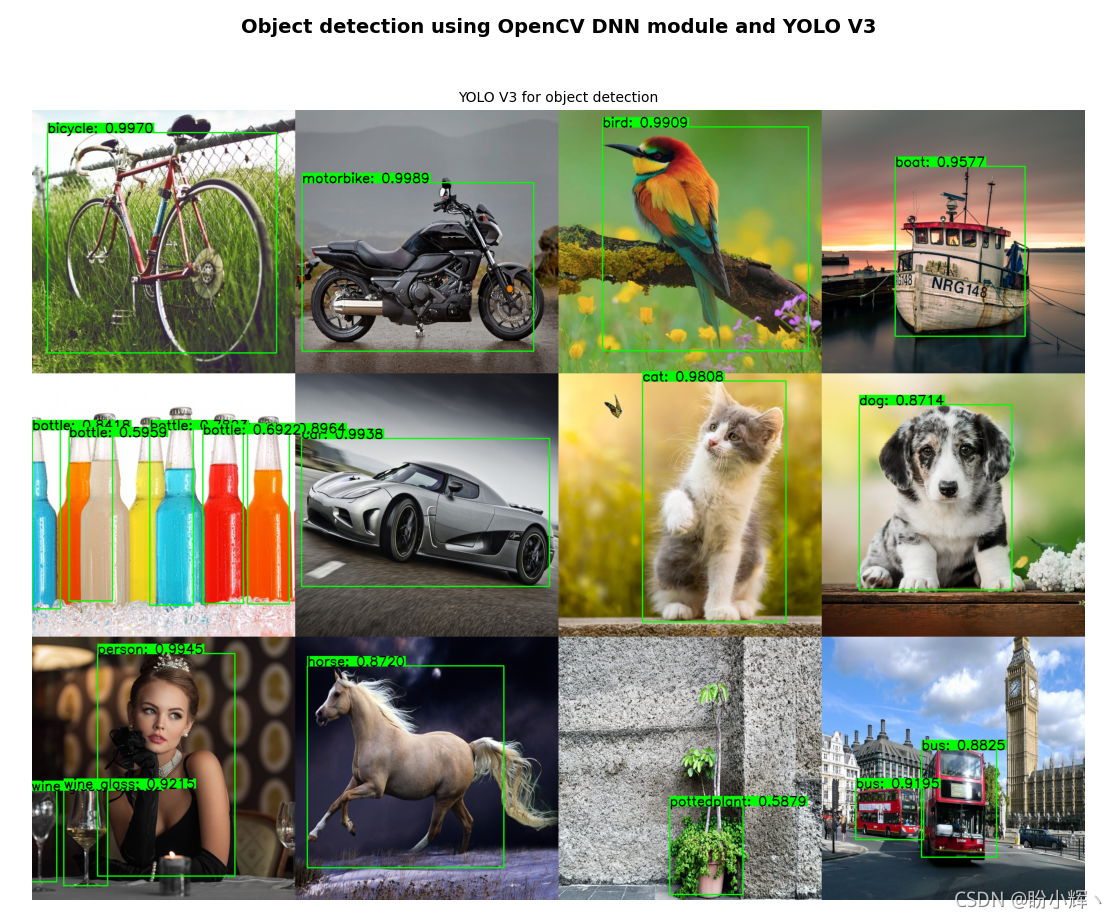
小結
在本文中,我們首先通過 cv2.dnn.blobFromImage() 和 cv2.dnn.blobFromImages() 函式了解了如何在 OpenCV 中構建網路輸入 blob,然后通過實戰學習將流行的深度學習模型架構應用于目標檢測和影像分類中,構建 OpenCV 計算機視覺專案,
系列鏈接
OpenCV-Python實戰(1)——OpenCV簡介與影像處理基礎
OpenCV-Python實戰(2)——影像與視頻檔案的處理
OpenCV-Python實戰(3)——OpenCV中繪制圖形與文本
OpenCV-Python實戰(4)——OpenCV常見影像處理技術
OpenCV-Python實戰(5)——OpenCV影像運算
OpenCV-Python實戰(6)——OpenCV中的色彩空間和色彩映射
OpenCV-Python實戰(7)——直方圖詳解
OpenCV-Python實戰(8)——直方圖均衡化
OpenCV-Python實戰(9)——OpenCV用于影像分割的閾值技術
OpenCV-Python實戰(10)——OpenCV輪廓檢測
OpenCV-Python實戰(11)——OpenCV輪廓檢測相關應用
OpenCV-Python實戰(12)——一文詳解AR增強現實
OpenCV-Python實戰(13)——OpenCV與機器學習的碰撞
OpenCV-Python實戰(14)——人臉檢測詳解
OpenCV-Python實戰(15)——面部特征點檢測詳解
OpenCV-Python實戰(16)——人臉追蹤詳解
OpenCV-Python實戰(17)——人臉識別詳解
OpenCV-Python實戰(18)——深度學習簡介與入門示例
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423960.html
標籤:AI
下一篇:python使用matplotlib可視化subplots繪制子圖、自定義幾行幾列子圖,如果M行N列,那么最終包含M*N個子圖、在指定的子圖中添加可視化結果