文章目錄
- 前言
- 一、以普通例子循序漸進講解什么是機器學習
- 二、通過西瓜的例子類比學習一些相關術語
- 1. 以資料表格方式學習
- 2. 還記得坐標系么
- 3. 訓練相關的一些術語
- 三、假設空間
- 四、歸納偏好
- 總結
前言
機器學習和人工智能,一直覺得挺神秘而且又高大上的,經常聽說,但又因為各種數學概念而沒有付諸實踐,
但是,如果不做專職的相關崗位開發,自己跑一些學習程式是否可行呢?比較現在各種框架都挺多的了,即使再不濟,了解一下具體都能做哪些東西也是很不錯的,
入手了周志華的《人工智能》一書,剛看了開頭,覺得講的非常好,以例子開始逐步深入,做了如下筆記,

一、以普通例子循序漸進講解什么是機器學習
以挑西瓜的例子開篇: 為什么色澤青綠、根蒂蜷縮、敲聲濁晌,就能判斷出是正熟的好瓜?
因為我們吃過、看過很多西瓜,所以基于色澤、根蒂、敲聲這幾個特征我們就可以做出相當好的判斷,
**過渡,引出學習經驗:**類似的,我們從以往的學習經驗知道,下足了工夫、弄清了概念、做好了作業,自然會取得好成績,可以看出,我們能做出有效的預判?是因為我們已經積累了許多經驗,而通過對經驗的利用?就能對新情況做出有效的決策,
**進而來說機器學習:**如果說計算機科學是研究關于"演算法"的學問,那么類似的,可以說機器學習是研究關于"學習演算法"的學問,

二、通過西瓜的例子類比學習一些相關術語
1. 以資料表格方式學習
將西瓜的例子歸納為下面的表格:
| 序號 | 色澤 | 根蒂 | 敲聲 |
|---|---|---|---|
| 1 | 青綠 | 蜷縮 | 濁響 |
| 2 | 烏黑 | 稍蜷 | 沉悶 |
| … |
對照表格,了解一些相關術語:
- **資料集:**整個表格的記錄集合,
- 示例 (instance) 或樣本 (sample):每條記錄是關于一個事件或物件(這里是一個西瓜)的描述,稱為一個示例 (instance) 或樣本 (sample),有時整個資料集亦稱一個"樣本"因為它可看作對樣本空間的一個采樣,通過背景關系可判斷出"樣本"是指單個示例還是資料集,
- **屬性 (attribute) 或特征(feature):**表格中的“色澤”、“根蒂”、“敲聲”,
- **屬性值 (attribute va1ue):**表格中的“色澤”、“根蒂”、“敲聲”對應的值,
2. 還記得坐標系么
對于單條記錄,以“色澤”、“根蒂”、“敲聲”三個屬性標識如下圖:
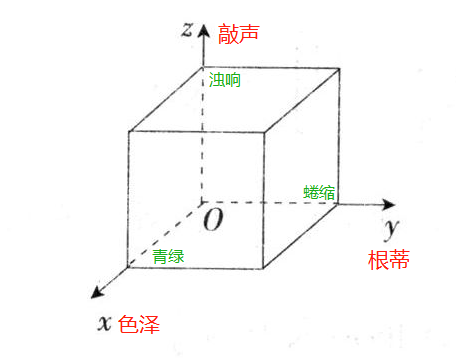
每個屬性作為一個坐標軸,就形成了一個三維的坐標系, 坐標系還記得吧,希望還沒全還給老師,
屬性張成的空間稱為**“屬性空間” (attribute space) “樣本空間” (sample space) 或"輸入空間"**,即圖中的長方體,
當然,實際上一個樣本(西瓜)肯定不止這三個屬性,這里只是舉例,每個屬性代表一個坐標軸,那就會組成一個d維空間,d為樣本的屬性數,
每個西瓜都可在這個空間中找到自己的坐標位置,由于空間中的每個點對應一個坐標向量,因此我們也把…個示例稱為一個**“特征向量” (feature vector),**
3. 訓練相關的一些術語
從資料中學得模型的程序稱為**“學習” (learning) 或"訓練" (training)**;
這個程序通過執行某個學習演算法來完成.訓練程序中使用的資料稱為**“訓練資料” (training data)** ;
其中每個樣本稱為一個訓練樣本" (training sample),;
訓練樣本組成的集合稱為"訓練集" (training set).
學得模型對應了關于資料的某種潛在的規律,因此亦稱"假設" (hypothesis);
這種潛在規律自身,則稱為**“真相"或"真實” (ground-truth)** ;
學習程序就是為了找出或逼近真相.本書有時將模型稱為"學習器" (learner) ,可看作學習演算法在給定資料和引數空間上的實體化.
訓練不止需要樣本的屬性資訊,還需要樣本的"結果"資訊,例如" ((色澤:青綠;根蒂二蜷縮;敲聲=濁響),好瓜)" .這里關于示例結果的資訊,例如"好瓜",稱為標記 (labe1);
擁有了標記資訊的示例,則稱為**“樣例” (example)**,如下圖

若我們欲預測的是離散值,例如"好瓜" “壞瓜”,此類學習任務稱為**“分類” (classification)**;
若欲預測的是連續值?例如西瓜成熟度 0.95 0.37,此類學習任務稱為**“回歸” (regression)**.
對只涉及兩個類別的**“二分類” (binary classification)** 任務,通常稱其中一個類為正類(positive class),另一個類為**“反類” (negative class);**
涉及多個類別時,則稱為**“多分類” (multi-class classificatio)**任務,
學得模型適用于新樣本的能力,稱為"泛化" (generalization) 能力.具有強泛化能力的模型能很好地適用于整個樣本空間.

三、假設空間
在數學公理系鏡中,基于一組公理和推理規則推匯出與之相洽的定理,這是演繹;而"從樣例中學習"顯然是一個歸納的程序,因此亦稱"歸納學習" (inductive learning) .,
我們可以把學習程序看作一個在所有假設(hypothesis) 組成的空間中進行搜索的程序,如下圖
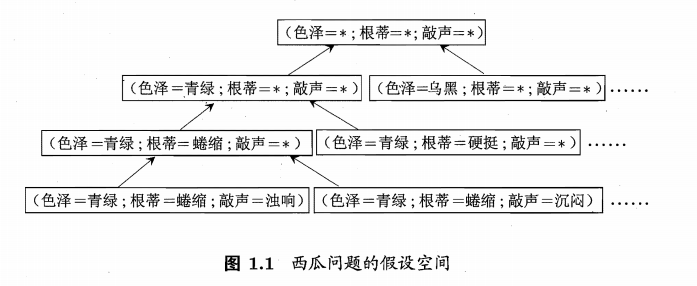
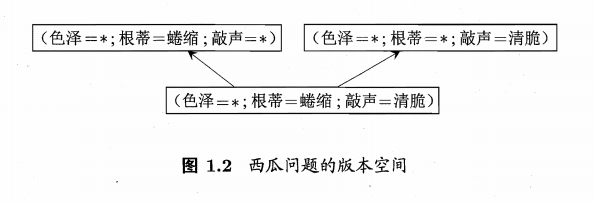
有多少種可能呢,就是一個排列組合,現實問題中我們常面臨很大的假設空間,但學習程序是基于有限樣本訓練集進行的,因此,可能有多個假設與訓練集一致,即存在著一個與訓練集一致的"假設集合",我們稱之為**“版本空間” (version space)**,

四、歸納偏好
對于圖1.2的西瓜版本空間,對應(色澤口=青綠;根蒂=蜷縮;敲聲=沉悶)這個新收來的瓜,如果我們采用的是"好瓜<->(色澤=* )(根蒂=蜷縮)(敲聲=*),那么將會把新瓜判斷為好瓜,而如果采用了另外兩個假設,則判斷的結果將不是好瓜,若僅有表1. 中的訓練樣本,則無法斷定上述三個假設中明哪一個"更好, 那么計算機就傻了,
怎么辦,任何一個有效的機器學習演算法必有其歸納偏好,否則它將被假設空間中看似在訓練集上"等效"的假設所迷惑,而無法產生確定的學習結果,
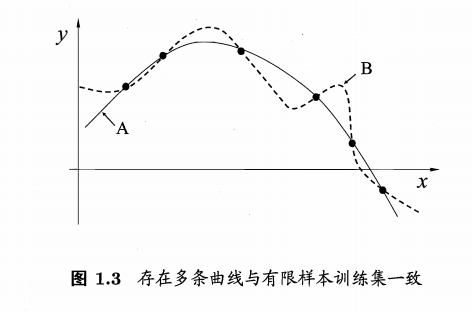
那么,有沒有一般性的原則來引導演算法確立"正確的"偏好呢? “奧卡姆剃刀” (Occam’s razor) 是一種常用的、自然科學研究中最基本的原則,即"若有多個假設與觀察一致,則選最簡單的那個,
總結
脫離具體問題,空泛地談論"什么學習演算法更好"毫無意義,因為若考慮所有潛在的問題,則所有學習演算法都一樣好,要談論演算法的相對優劣,必須要針對具體的學習問題;在某些問題上表現好的學習演算法,在另一些問題上卻可能不盡如人意,學習演算法自身的歸納偏好與問題是否相配,往往會起到決定性的作用,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423979.html
標籤:AI
上一篇:Anchor free系列網路之YOLOX原始碼逐行講解篇(七)--Head中Obj_loss、Cls_loss及Reg_loss的計算及反傳一