文章目錄
- Spark Day06:Spark Core
- 01-[了解]-內容回顧
- 02-[了解]-內容提綱
- 03-[掌握]-Spark 內核調度之引例WordCount
- 04-[掌握]-Spark 內核調度之RDD 依賴
- 05-[掌握]-Spark 內核調度之DAG和Stage
- 06-[了解]-Spark 內核調度之Spark Shuffle
- 07-[掌握]-Spark 內核調度之Job 調度流程
- 08-[掌握]-Spark 內核調度之Spark 基本概念
- 09-[理解]-Spark 內核調度之并行度
- 10-[掌握]-SparkSQL應用入口SparkSession
- 11-[掌握]-詞頻統計WordCount之基于DSL編程
- 12-[掌握]-詞頻統計WordCount之基于SQL編程
Spark Day06:Spark Core

01-[了解]-內容回顧
主要講解三個方面內容:Sogou日志分析、外部資料源(HBase和MySQL)和共享變數,
1、Sogou日志分析
以搜狗官方提供用戶搜索查詢日志為基礎,使用SparkCore(RDD)業務分析
資料格式:
文本檔案資料,每條資料就是用戶搜索時點擊網頁日志資料
各個欄位之間使用制表符分割
業務需求:
- 搜索關鍵詞統計,涉及知識點中文分詞:HanLP
- 用戶搜索點擊統計
- 搜索時間段統計
編碼實作
第一步、讀取日志資料,封裝到物體類物件SougouRecord
第二步、按照業務需求分析資料
詞頻統計WordCount變形
2、外部資料源
SparkCore與HBase和MySQL資料庫互動
- HBase資料源,底層MapReduce從HBase表讀寫資料API
保存資料到HBase表
TableOutputFormat
RDD[(RowKey, Put)],其中RowKey = ImmutableBytesWritable
從HBase表加載資料
TableInputFormat
RDD[(RowKey, Result)]
從HBase 表讀寫資料,首先找HBase資料庫依賴Zookeeper地址資訊
- MySQL資料源
保存資料RDD到MySQL表中,考慮性能問題,5個方面
考慮降低RDD磁區數目
針對磁區資料進行操作,每個磁區創建1個連接
每個磁區資料寫入到MySQL資料庫表中,批量寫入
可以將每個磁區資料加入批次
批量將所有資料寫入
事務性,批次中資料要么都成功,要么都失敗
人為提交事務
考慮大資料分析特殊性,重復運行程式,處理相同資料,保存到MySQL表中
主鍵存在時,更新資料;不存在時,插入資料
REPLACE INTO ............
3、共享變數(Shared Variables)
表示某個值(變數)被所有Task共享
- 廣播變數
Broadcast Variables,共享變數值不能被改變
解決問題:
共享變數存盤問題,將變數廣播以后,僅僅在每個Executor中存盤一份;如果沒有對變數進行廣播的話,每個Task中存盤一份,
廣播變數節省記憶體使用
- 累加器
Accumulators,共享變數值可以被改變,只能“累加”
類似MapReduce框架種計數器Counter,起到累加統計作用
Spark框架提供三種型別累加器:
LongAccumulator、DoubleAccumulator、CollectionAccumulator
02-[了解]-內容提綱
主要講解2個方面內容:Spark 內核調度和SparkSQL快速入門
1、Spark 內核調度(理解)
了解Spark框架如何執行Job程式,以詞頻統計WordCount程式為例,如何執行程式
RDD 依賴
DAG圖、Stage階段
Shuffle
Job 調度流程
Spark 基本概念
并行度
2、SparkSQL快速入門
SparkSQL中程式入口:SparkSession
基于SparkSQL實作詞頻統計
SQL陳述句,類似Hive
DSL陳述句,類似RDD中呼叫API,鏈式編程
SparkSQL模塊概述
前世今生
官方定義
幾大特性
03-[掌握]-Spark 內核調度之引例WordCount
? Spark的核心是根據RDD來實作的,
Spark Scheduler則為Spark核心實作的重要一環,其作用就是任務調度,? Spark的任務調度就是
如何組織任務去處理RDD中每個磁區的資料,根據RDD的依賴關系構建DAG,基于DAG劃分Stage,將每個Stage中的任務發到指定節點運行,
以詞頻統計WordCount程式為例,Job執行是DAG圖:
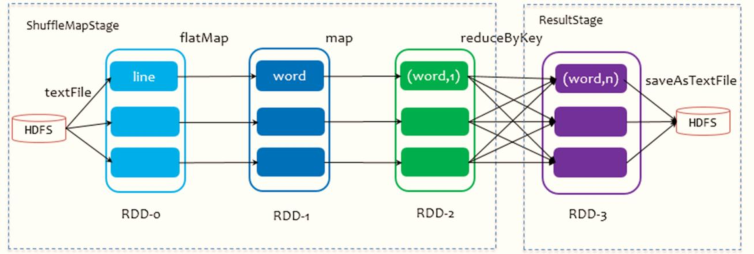
運行詞頻統計WordCount,截取4040監控頁面上DAG圖:
當RDD呼叫Action函式(Job觸發函式)時,產出1個Job,執行Job,
1、將Job中所有RDD按照依賴關系構建圖:DAG圖(有向無環圖)
2、將DAG圖劃分為Stage階段,分為2種型別
- ResultStage,對結果RDD進行處理Stage階段
- ShuffleMapStage,此Stage階段中最后1個RDD產生Shuffle
3、每個Stage中至少有1個RDD或多個RDD,每個RDD有多個磁區,每個磁區資料被1個Task處理
每個Stage中有多個Task處理資料,每個Task處理1個磁區資料
04-[掌握]-Spark 內核調度之RDD 依賴
RDD 間存在著血統繼承關系,其本質上是
RDD之間的依賴(Dependency)關系,每個RDD記錄,如何從父RDD得到的,呼叫哪個轉換函式
從DAG圖上來看,RDD之間依賴關系存在2種型別:
- 窄依賴,2個RDD之間依賴使用有向箭頭表示
- 寬依賴,又叫Shuffle 依賴,2個RDD之間依賴使用S曲線有向箭頭表示

- 窄依賴(Narrow Dependency)
定義:
父 RDD 與子 RDD 間的磁區是一對一的,一(父RDD)對一(子RDD)
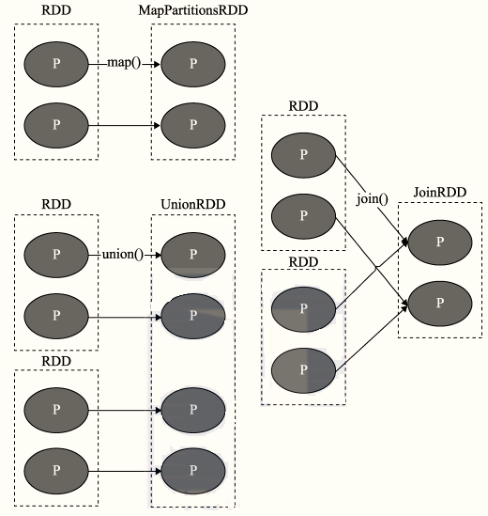
- Shuffle 依賴(寬依賴 Wide Dependency)
定義:父 RDD 中的磁區可能會被多個子 RDD 磁區使用,一(父)對多(子)
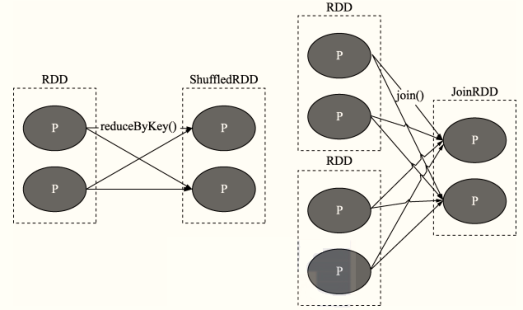

05-[掌握]-Spark 內核調度之DAG和Stage
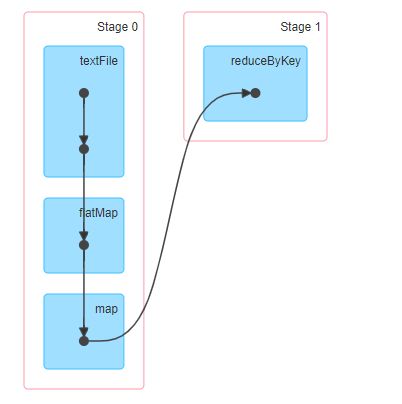
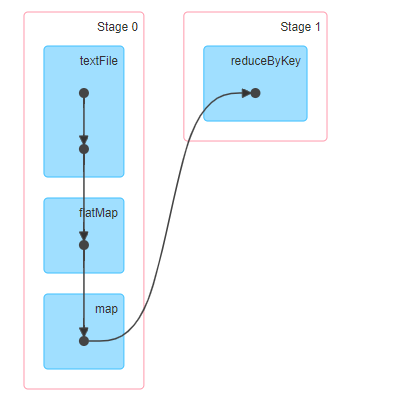
? 在Spark應用執行時,每個Job執行時(RDD呼叫Action函式時),依據最后一個RDD(呼叫Action函式RDD),依據RDD依賴關系,向前推到,構建Job中所有RDD依賴關系圖,稱之為DAG圖,
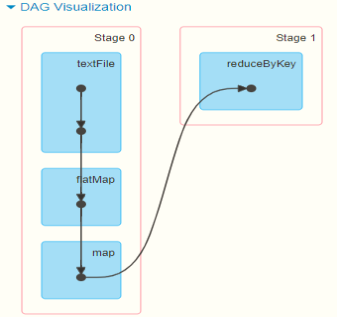
? 當構建完成Job DAG圖以后,繼續從Job最后一個RDD開始,依據RDD之間依賴關系,將DAG圖劃分為Stage階段,當RDD之間依賴為Shuffle依賴時,劃分一個Stage,
- 對于窄依賴,RDD之間的資料不需要進行Shuffle,多個資料處理可以在同一臺機器的記憶體中完
成,所以窄依賴在Spark中被劃分為同一個Stage;- 對于寬依賴,由于Shuffle的存在,必須等到父RDD的Shuffle處理完成后,才能開始接下來的計
算,所以會在此處進行Stage的切分,
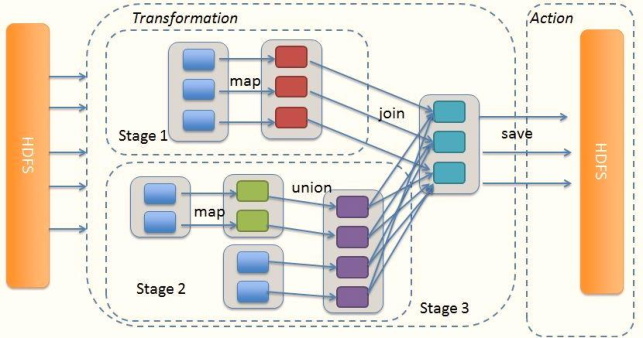
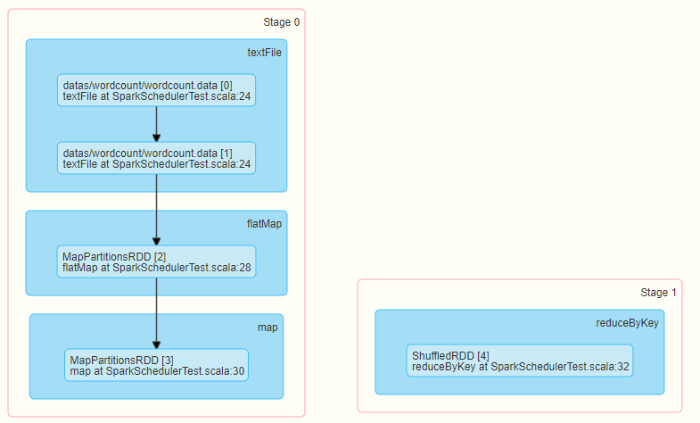
可以運行詞頻統計WordCount查看對應DAG圖和Stage階段
把DAG劃分成互相依賴的多個Stage,劃分依據是RDD之間的寬依賴,Stage是由一組并行的Task組成,
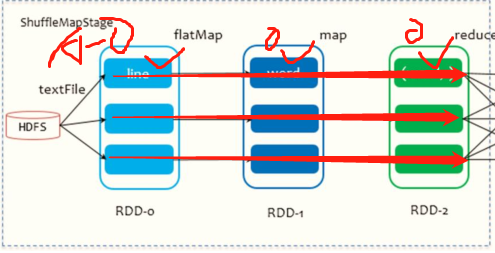
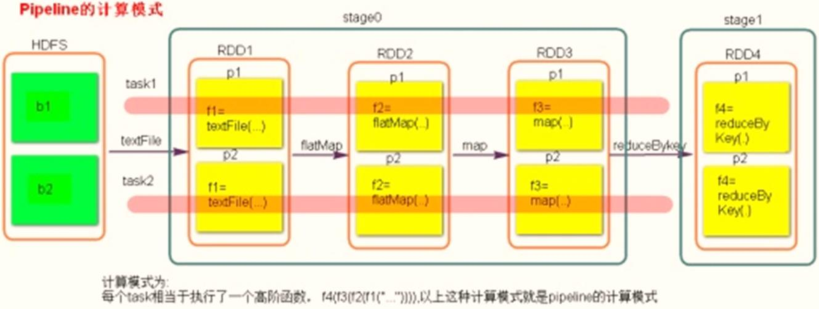
1、Stage切割規則:從后往前,遇到寬依賴就切割Stage,
2、Stage計算模式:pipeline管道計算模式
pipeline只是一種計算思想、模式,來一條資料然后計算一條資料,把所有的邏輯走完,然后落地,
以詞頻統計WordCount為例:
從HDFS上讀取資料,每個Block對應1個磁區,當從Block中讀取一條資料以后,經過flatMap、map和reduceByKey操作,最后將結果資料寫入到本地磁盤中(Shuffle Write),
block0: hadoop spark spark
|textFile
RDD-0 hadoop spark spark
|flatMap
RDD-1 hadoop\spark\spark
|map
RDD-2 (hadoop, 1)\(spark, 1)\(spark, 1)
|reduceByKey
寫入磁盤 hadoop, 1 || spark, 1\ spark, 1
3、準確的說:一個task處理一串磁區的資料,整個計算邏輯全部走完
面試題如下:Spark Core中一段代碼,判斷執行結果
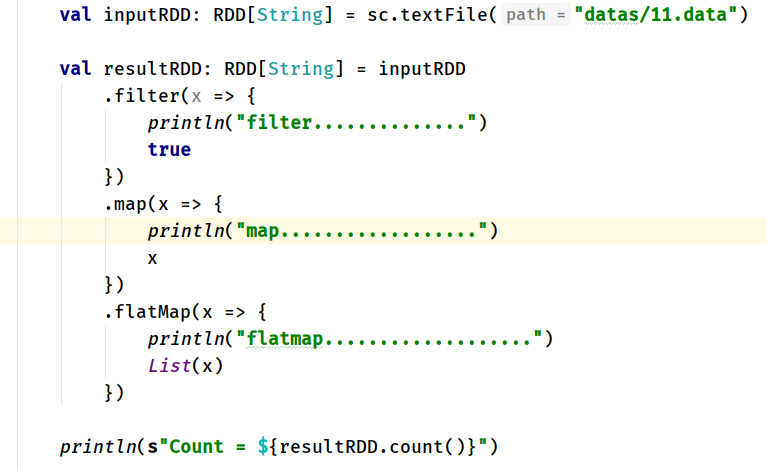
前提條件:11.data中三條資料
結果A:
filter..................
filter..................
filter..................
map..................
map..................
map..................
flatMap..................
flatMap..................
flatMap..................
Count = 3
結果B:
filter..................
map..................
flatMap..................
filter..................
map..................
flatMap..................
filter..................
map..................
flatMap..................
Count = 3
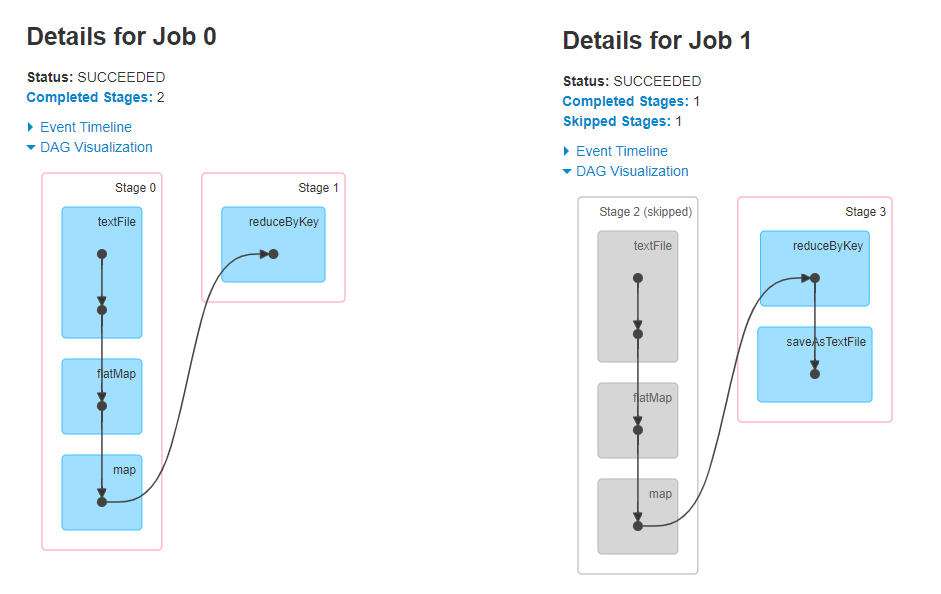
? 在1個Spark Application應用中,如果某個RDD,呼叫多次Action函式,觸發Job執行,重用RDD結果產生程序中Shuffle資料(寫入到本地磁盤),節省重新計算RDD時間,提升性能,
可以將某個多次使用RDD資料,認為手動進行快取,
06-[了解]-Spark 內核調度之Spark Shuffle
首先回顧MapReduce框架中Shuffle程序,整體流程圖如下:
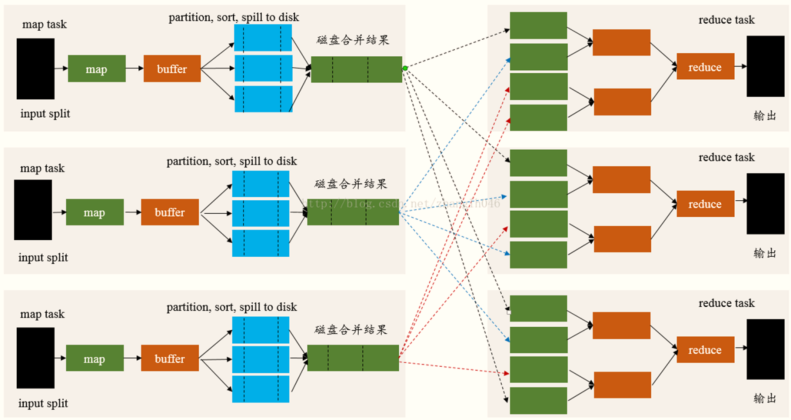
? Spark在DAG調度階段會將
一個Job劃分為多個Stage,上游Stage做map作業,下游Stage做reduce作業,其本質上還是MapReduce計算框架,? Shuffle是連接map和reduce之間的橋梁,它將map的輸出對應到reduce輸入中,涉及到序列化反序列化、跨節點網路IO以及磁盤讀寫IO等,
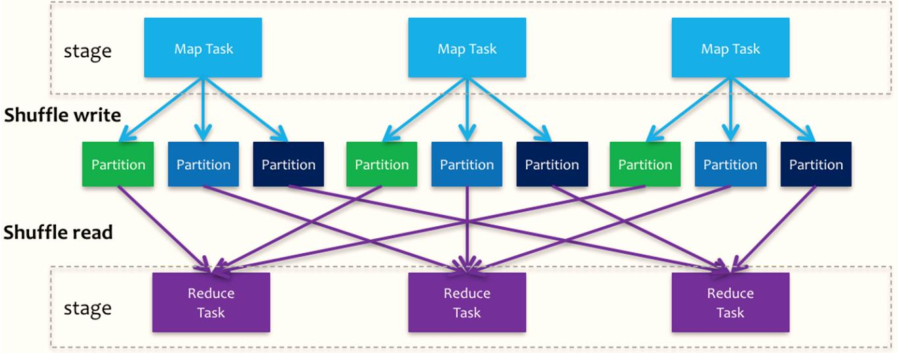
? Spark的Shuffle分為Write和Read兩個階段,分屬于兩個不同的Stage,前者是Parent Stage的最后一步,后者是Child Stage的第一步,
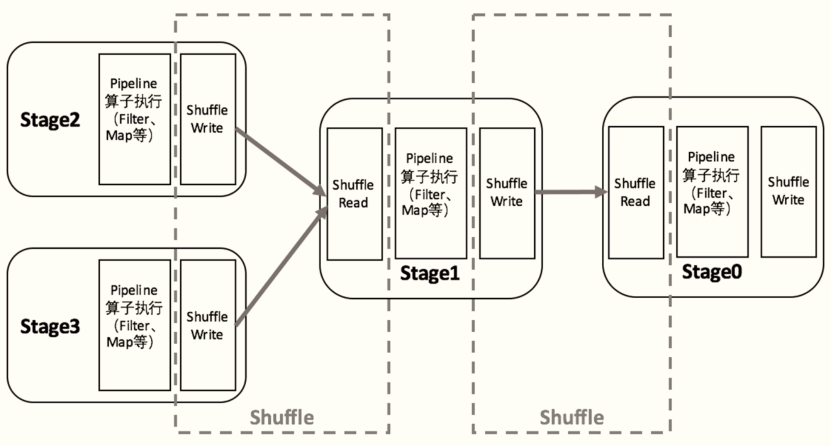
Stage劃分為2種型別:
- 1)、ShuffleMapStage,在Spark 1個Job中,除了最后一個Stage之外,其他所有的Stage都是此型別
- 將Shuffle資料寫入到本地磁盤,ShuffleWriter
- 在此Stage中,所有的Task稱為:ShuffleMapTask
- 2)、ResultStage,在Spark的1個Job中,最后一個Stage,對結果RDD進行操作
- 會讀取前一個Stage中資料,ShuffleReader
- 在此Stage中,所有的Task任務稱為ResultTask,
ShuffleMapTask要進行Shuffle,ResultTask負責回傳計算結果,一個Job中只有最后的Stage采用ResultTask,其他的均為ShuffleMapTask,
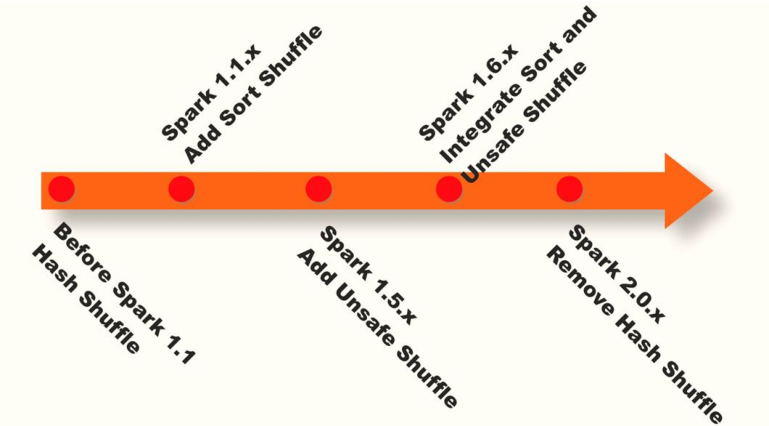
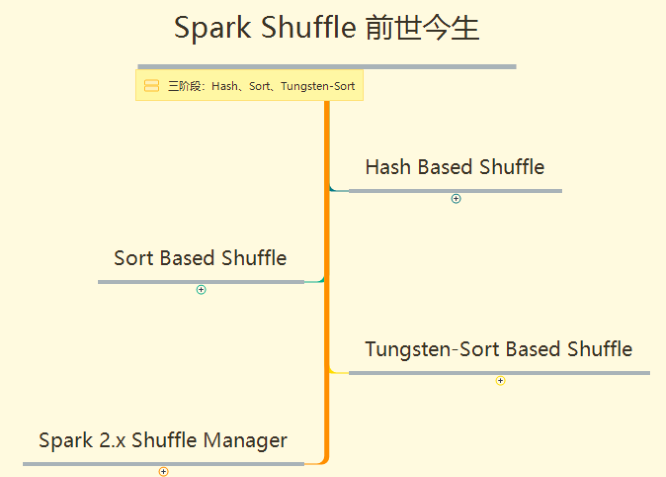
Spark Shuffle實作歷史:
- Spark在1.1以前的版本一直是采用Hash Shuffle的實作的方式
- 到1.1版本時參考HadoopMapReduce的實作開始引入Sort Shuffle
- 在1.5版本時開始Tungsten鎢絲計劃,引入UnSafe Shuffle優化記憶體及CPU的使用
- 在1.6中將Tungsten統一到Sort Shuffle中,實作自我感知選擇最佳Shuffle方式
- 到的2.0版本,Hash Shuffle已被洗掉,所有Shuffle方式全部統一到Sort Shuffle一個實作中,
具體各階段Shuffle如何實作,參考思維導圖XMIND,大綱如下:
07-[掌握]-Spark 內核調度之Job 調度流程
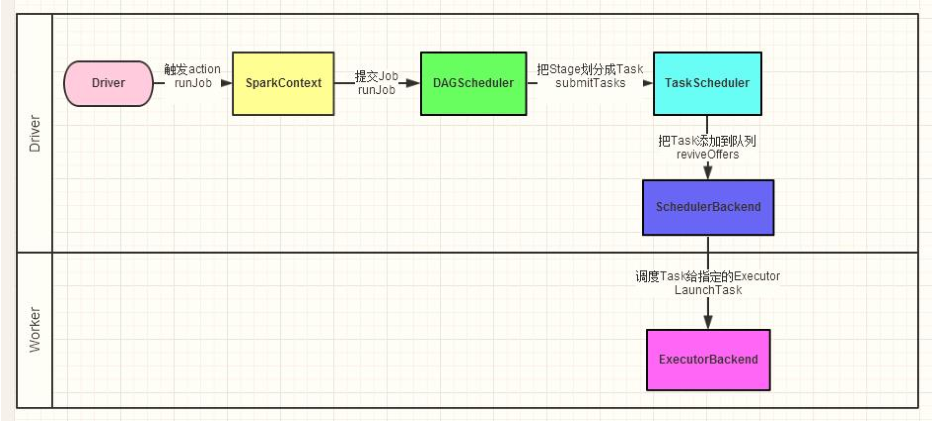
? 當啟動Spark Application的時候,運行MAIN函式,首先創建SparkContext物件(構建
DAGScheduler和TaskScheduler),
- 第一點、
DAGScheduler實體物件
- 將每個Job的DAG圖劃分為Stage,依據RDD之間依賴為寬依賴(產生Shuffle)
- 第二點、
TaskScheduler實體物件
- 調度每個Stage中所有Task:
TaskSet,發送到Executor上執行- 每個Stage中會有多個Task,所有Task處理資料不一樣(每個磁區資料被1個Task處理),但是處理邏輯一樣的,
- 將每個Stage中所有Task任務,放在一起稱為
TaskSet,
? 當RDD呼叫
Action函式(比如count、saveTextFile或foreachPartition)時,觸發一個Job執行,調度中流程如下圖所示:
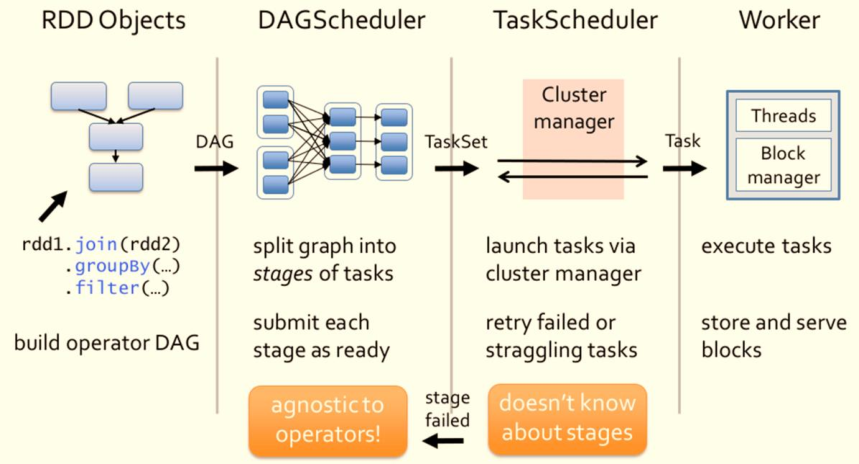
? Spark RDD通過其Transactions操作,形成了RDD血緣關系圖,即DAG,最后通過Action的呼叫,觸發Job并調度執行,
- 1)、DAGScheduler負責Stage級的調度,主要是將DAG切分成若干Stages,并將每個Stage打包成TaskSet交給TaskScheduler調度,
- 2)、TaskScheduler負責Task級的調度,將DAGScheduler給過來的TaskSet按照指定的調度策略分發到Executor上執行,調度程序中SchedulerBackend負責提供可用資源,其中
SchedulerBackend有多種實作,分別對接不同的資源管理系統,
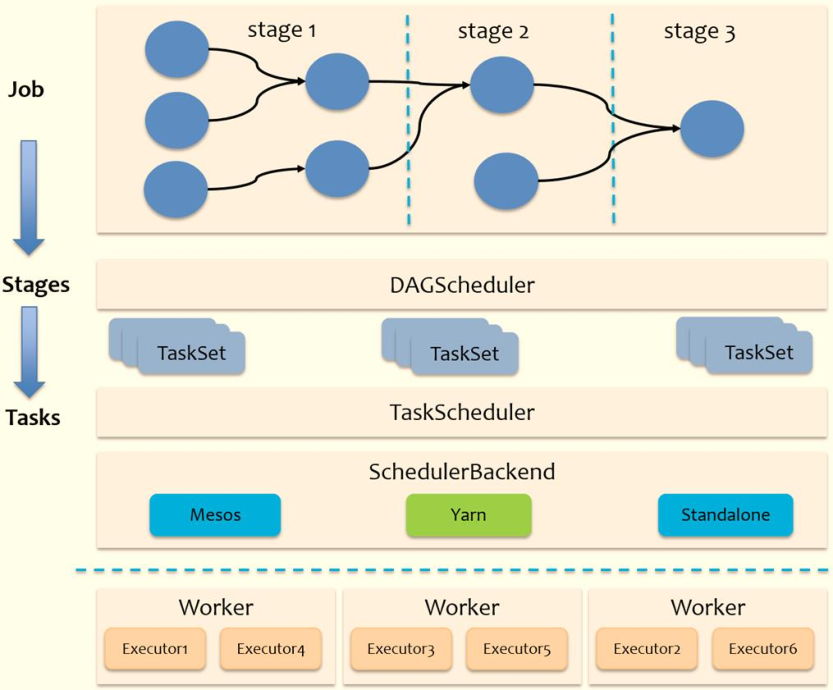
Spark的任務調度總體來說分兩路進行,一路是Stage級的調度,一路是Task級的調度,
一個Spark應用程式包括Job、Stage及Task:
第一、Job是以Action方法為界,遇到一個Action方法則觸發一個Job;
第二、Stage是Job的子集,以RDD寬依賴(即Shuffle)為界,遇到Shuffle做一次劃分;
第三、Task是Stage的子集,以并行度(磁區數)來衡量,磁區數是多少,則有多少個task,
08-[掌握]-Spark 內核調度之Spark 基本概念
Spark Application運行時,涵蓋很多概念,主要如下表格:

官方檔案:http://spark.apache.org/docs/2.4.5/cluster-overview.html#glossary
09-[理解]-Spark 內核調度之并行度
在Spark Application運行時,并行度可以從兩個方面理解:
- 1)、資源的并行度:由
節點數(executor)和cpu數(core)決定的- 2)、資料的并行度:task的資料,
partition大小Task數目要是core總數的2-3倍為佳
引數spark.defalut.parallelism默認是沒有值的,如果設定了值,是在shuffle的程序才會起作用

在實際專案中,運行某個Spark Application應用時,需要設定資源,尤其Executor個數和CPU核數,如何計算?
- 首先確定總的CPU Core核數,依據資料量(原始資料大小)及考慮業務分析中資料量
- 再確定Executor個數,假定每個Executor核數,獲取個數
- 最后確定Executor記憶體大小,一般情況下,每個Executor記憶體往往是CPU核數2-3倍
分析網站日志資料:20GB,存盤在HDFS上,160Block,從HDFS讀取資料,
RDD 磁區數目:160 個磁區
1、RDD磁區數目160,那么Task數目為160個
2、總CPU Core核數
160/2 = 80
CPU Core = 60
160/3 = 50
3、假設每個Executor:6 Core
60 / 6 = 10 個
4、每個Executor記憶體
6 * 2 = 12 GB
6 * 3 = 18 GB
5、引數設定
--executor-memory= 12GB
--executor-cores= 6
--num-executors=10
10-[掌握]-SparkSQL應用入口SparkSession
? Spark 2.0開始,應用程式入口為
SparkSession,加載不同資料源的資料,封裝到DataFrame/Dataset集合資料結構中,使得編程更加簡單,程式運行更加快速高效,

1、SparkSession
程式入口,加載資料
底層SparkContext,進行封裝
2、DataFrame/Dataset
Dataset[Row] = DataFrame
資料結構,從Spark 1.3開始出現,一直到2.0版本,確定下來
底層RDD,加上Schema約束(元資料):欄位名稱和欄位型別
- 1)、SparkSession在SparkSQL模塊中,添加MAVEN依賴
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
- 2)、SparkSession物件實體通過
建造者模式構建,代碼如下:

? 其中①表示匯入SparkSession所在的包,②表示建造者模式構建物件和設定屬性,③表示匯入SparkSession類中implicits物件object中隱式轉換函式,
- 3)、范例演示:構建SparkSession實體,加載文本資料,統計條目數,
package cn.itcast.spark.sql.start
import org.apache.spark.sql.{Dataset, SparkSession}
/**
* Spark 2.x開始,提供了SparkSession類,作為Spark Application程式入口,
* 用于讀取資料和調度Job,底層依然為SparkContext
*/
object _03SparkStartPoint {
def main(args: Array[String]): Unit = {
// 使用建造者設計模式,創建SparkSession實體物件
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.getOrCreate()
import spark.implicits._
// TODO: 使用SparkSession加載資料
val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount.data")
// 顯示前5條資料
println(s"Count = ${inputDS.count()}")
inputDS.show(5, truncate = false)
// 應用結束,關閉資源
spark.stop()
}
}
學習任務:Java中設計模式【建造者設計模式】,在大資料很多框架種,API設計都是建造者設計模式,
11-[掌握]-詞頻統計WordCount之基于DSL編程
? DataFrame 資料結構相當于給RDD加上約束Schema,知道資料內部結構(欄位名稱、欄位型別),提供兩種方式分析處理資料
:DataFrame API(DSL編程)和SQL(類似HiveQL編程),下面以WordCount程式為例編程實作,體驗DataFrame使用,
使用SparkSession加載文本資料,封裝到Dataset/DataFrame中,呼叫API函式處理分析資料(類似RDD中API函式,如flatMap、map、filter等),編程步驟:
第一步、構建SparkSession實體物件,設定應用名稱和運行本地模式;
第二步、讀取HDFS上文本檔案資料;
第三步、使用DSL(Dataset API),類似RDD API處理分析資料;
第四步、控制臺列印結果資料和關閉SparkSession;
package cn.itcast.spark.sql.wordcount
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 使用SparkSQL進行詞頻統計WordCount:DSL
*/
object _04SparkDSLWordCount {
def main(args: Array[String]): Unit = {
// 使用建造設設計模式,創建SparkSession實體物件
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.getOrCreate()
import spark.implicits._
// TODO: 使用SparkSession加載資料
val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount.data")
// DataFrame/Dataset = RDD + schema
/*
root
|-- value: string (nullable = true)
*/
//inputDS.printSchema()
/*
+----------------------------------------+
|value |
+----------------------------------------+
|hadoop spark hadoop spark spark |
|mapreduce spark spark hive |
|hive spark hadoop mapreduce spark |
|spark hive sql sql spark hive hive spark|
|hdfs hdfs mapreduce mapreduce spark hive|
+----------------------------------------+
*/
//inputDS.show(10, truncate = false)
// TODO: 使用DSL(Dataset API),類似RDD API處理分析資料
val wordDS: Dataset[String] = inputDS.flatMap(line => line.trim.split("\\s+"))
/*
root
|-- value: string (nullable = true)
*/
//wordDS.printSchema()
/*
+---------+
|value |
+---------+
|hadoop |
|spark |
+---------+
*/
// wordDS.show(10, truncate = false)
/*
table: words , column: value
SQL: SELECT value, COUNT(1) AS count FROM words GROUP BY value
*/
val resultDS: DataFrame = wordDS.groupBy("value").count()
/*
root
|-- value: string (nullable = true)
|-- count: long (nullable = false)
*/
resultDS.printSchema()
/*
+---------+-----+
|value |count|
+---------+-----+
|sql |2 |
|spark |11 |
|mapreduce|4 |
|hdfs |2 |
|hadoop |3 |
|hive |6 |
+---------+-----+
*/
resultDS.show(10, truncate = false)
// 應用結束,關閉資源
spark.stop()
}
}
12-[掌握]-詞頻統計WordCount之基于SQL編程
類似HiveQL方式進行詞頻統計,直接對單詞分組group by,再進行count即可,步驟如下:
第一步、構建SparkSession物件,加載檔案資料,分割每行資料為單詞;
第二步、將DataFrame/Dataset注冊為臨時視圖(Spark 1.x中為臨時表);
第三步、撰寫SQL陳述句,使用SparkSession執行獲取結果;
第四步、控制臺列印結果資料和關閉SparkSession;
package cn.itcast.spark.sql.wordcount
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 使用SparkSQL進行詞頻統計WordCount:SQL
*/
object _05SparkSQLWordCount {
def main(args: Array[String]): Unit = {
// 使用建造設設計模式,創建SparkSession實體物件
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[2]")
.getOrCreate()
import spark.implicits._
// TODO: 使用SparkSession加載資料
val inputDS: Dataset[String] = spark.read.textFile("datas/wordcount.data")
/*
root
|-- value: string (nullable = true)
*/
//inputDS.printSchema()
/*
+--------------------+
| value|
+--------------------+
|hadoop spark hado...|
|mapreduce spark ...|
|hive spark hadoop...|
+--------------------+
*/
//inputDS.show(5, truncate = false)
// 將每行資料按照分割劃分為單詞
val wordDS: Dataset[String] = inputDS.flatMap(line => line.trim.split("\\s+"))
/*
table: words , column: value
SQL: SELECT value, COUNT(1) AS count FROM words GROUP BY value
*/
// step 1. 將Dataset或DataFrame注冊為臨時視圖
wordDS.createOrReplaceTempView("tmp_view_word")
// step 2. 撰寫SQL并執行
val resultDF: DataFrame = spark.sql(
"""
|SELECT value as word, COUNT(1) AS count FROM tmp_view_word GROUP BY value
|""".stripMargin)
/*
+---------+-----+
|word |count|
+---------+-----+
|sql |2 |
|spark |11 |
|mapreduce|4 |
|hdfs |2 |
|hadoop |3 |
|hive |6 |
+---------+-----+
*/
resultDF.show(10, truncate = false)
// 應用結束,關閉資源
spark.stop()
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/423980.html
標籤:其他
下一篇:【CentOS7離線ansible-playbook自動化安裝CDH5.16(內附離線安裝包地址,及自動化腳本)】