序言
之前我們都是使用Jdbc的形式連接到Hive或者Spark的服務操作資料.這次我們使用spark-submit命令來提交Jar的形式來操作資料.故此不需要啟動Thrift JDBC/ODBC server服務cuiyaonan2000@163.com
參考資料:
- Quick Start - Spark 3.2.1 Documentation --- 整體搭建資訊
- Hive Tables - Spark 3.2.1 Documentation ---Hive 相關
官方用例
官網有Java的示例,同時也是使用Maven構建的在我們下載好的Spark包中就有源代碼.
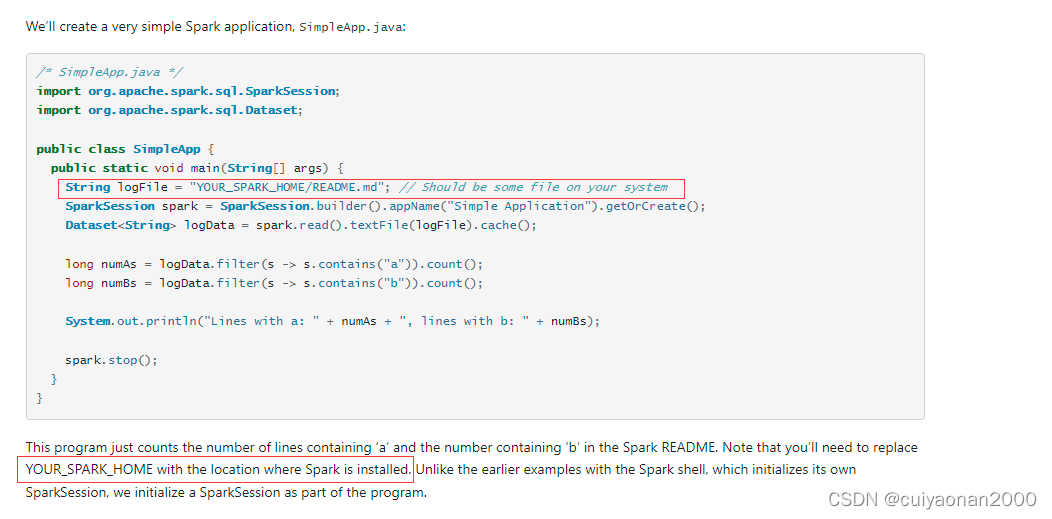
Maven的依賴資訊,注意紅色字體,同時根據我們在搭建Spark集群的時候都是需要依賴Scala包的.所以這里也不例外.只是官方實體沒有寫出來而已,大家要自己摸索cuiyaonan2000@163.com
代碼如下:
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package cui.yao.nan.config;
// $example on:spark_hive$
import java.io.File;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Encoders;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
// $example off:spark_hive$
public class JavaSparkHiveExample {
// $example on:spark_hive$
public static class Record implements Serializable {
private int key;
private String value;
public int getKey() {
return key;
}
public void setKey(int key) {
this.key = key;
}
public String getValue() {
return value;
}
public void setValue(String value) {
this.value = value;
}
}
// $example off:spark_hive$
public static void main(String[] args) {
// $example on:spark_hive$
// warehouseLocation points to the default location for managed databases and tables
String warehouseLocation = new File("spark-warehouse").getAbsolutePath();
SparkSession spark = SparkSession
.builder()
.appName("Java Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate();
spark.sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING) USING hive");
spark.sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src");
// Queries are expressed in HiveQL
spark.sql("SELECT * FROM src").show();
// +---+-------+
// |key| value|
// +---+-------+
// |238|val_238|
// | 86| val_86|
// |311|val_311|
// ...
// Aggregation queries are also supported.
spark.sql("SELECT COUNT(*) FROM src").show();
// +--------+
// |count(1)|
// +--------+
// | 500 |
// +--------+
// The results of SQL queries are themselves DataFrames and support all normal functions.
Dataset<Row> sqlDF = spark.sql("SELECT key, value FROM src WHERE key < 10 ORDER BY key");
// The items in DataFrames are of type Row, which lets you to access each column by ordinal.
Dataset<String> stringsDS = sqlDF.map(
(MapFunction<Row, String>) row -> "Key: " + row.get(0) + ", Value: " + row.get(1),
Encoders.STRING());
stringsDS.show();
// +--------------------+
// | value|
// +--------------------+
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// |Key: 0, Value: val_0|
// ...
// You can also use DataFrames to create temporary views within a SparkSession.
List<Record> records = new ArrayList<>();
for (int key = 1; key < 100; key++) {
Record record = new Record();
record.setKey(key);
record.setValue("val_" + key);
records.add(record);
}
Dataset<Row> recordsDF = spark.createDataFrame(records, Record.class);
recordsDF.createOrReplaceTempView("records");
// Queries can then join DataFrames data with data stored in Hive.
spark.sql("SELECT * FROM records r JOIN src s ON r.key = s.key").show();
// +---+------+---+------+
// |key| value|key| value|
// +---+------+---+------+
// | 2| val_2| 2| val_2|
// | 2| val_2| 2| val_2|
// | 4| val_4| 4| val_4|
// ...
// $example off:spark_hive$
spark.stop();
}
}
Spark任務啟動方式
現在隨著Spark版本的更迭,網上會有很多種的啟動方式.但是我們可以從最新的官網上看到Spark的主啟動程式是由SparkSession 來啟動的.但是很多網上的代碼由于Spark版本原因使用的是老的物件啟動的.同時博主沒有更新博客所以會引起困擾,所以這里順便說明下cuiyaonan2000@163.com
SparkContext
- 它可以幫助執行Spark任務,并與資源管理器(如YARN 或Mesos)進行協調,
- 使用SparkContext,可以訪問其他背景關系,比如SQLContext和HiveContext,
- 使用SparkContext,我們可以為Spark作業設定配置引數,
如果還沒有SparkContext,可以先創建一個SparkConf,
//set up the spark configuration
val sparkConf = new SparkConf().setAppName("hirw").setMaster("yarn")
//get SparkContext using the SparkConf
val sc = new SparkContext(sparkConf)SQLContext
SQLContext是通往SparkSQL的入口,下面是如何使用SparkContext創建SQLContext,
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)HiveContext
HiveContext是通往hive入口,
HiveContext集成了SQLContext的所有功能,并且進行了擴展.這意味著它支持SQLContext支持的功能以及更多(Hive特定的功能)
public class HiveContext extends SQLContext implements Logging同理也是通過sc(sparkcontext)創建
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
SparkSession
它使開發人員可以輕松地使用它,這樣我們就不用擔心不同的背景關系,
并簡化了對不同背景關系的訪問,通過訪問SparkSession,我們可以自動訪問SparkContext,
下面是如何創建一個SparkSession
val spark = SparkSession
.builder()
.appName("hirw-hive-test")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate()
總結
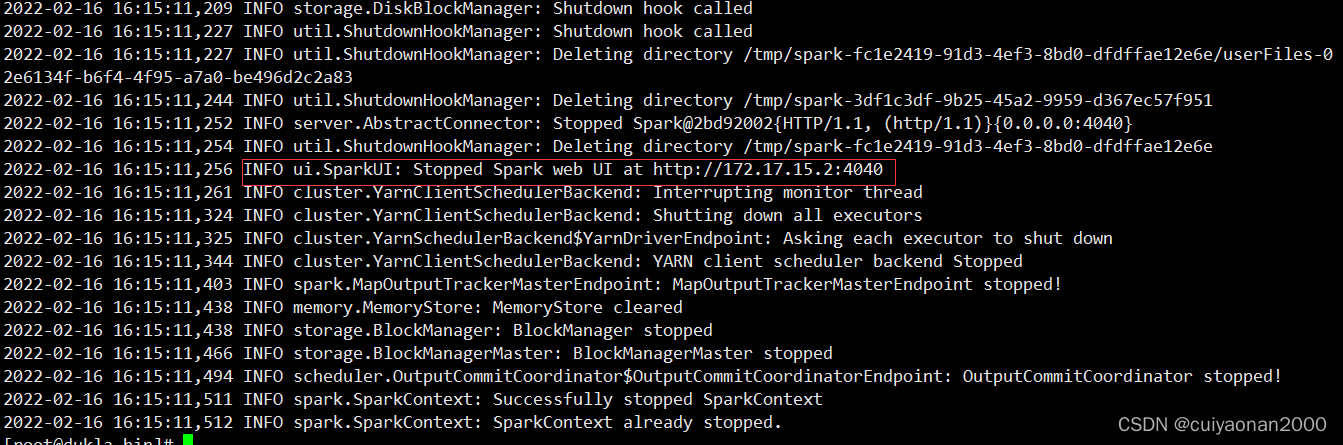
通過spark-submit jar的形式提交的任務,其實也是需要啟動Spark web UI的(這個直接連接spark thriftserver 其實更好,沒有必要提交了cuiyaonan2000@163.com),查看日志可以看到 當任務結束的時候需要依次關掉SparkContext和thriftserver.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/425054.html
標籤:其他
上一篇:MapReduce核心思想、編程規范及bean序列化
下一篇:云計算——讓學習更輕松