1. MapReduce 核心思想
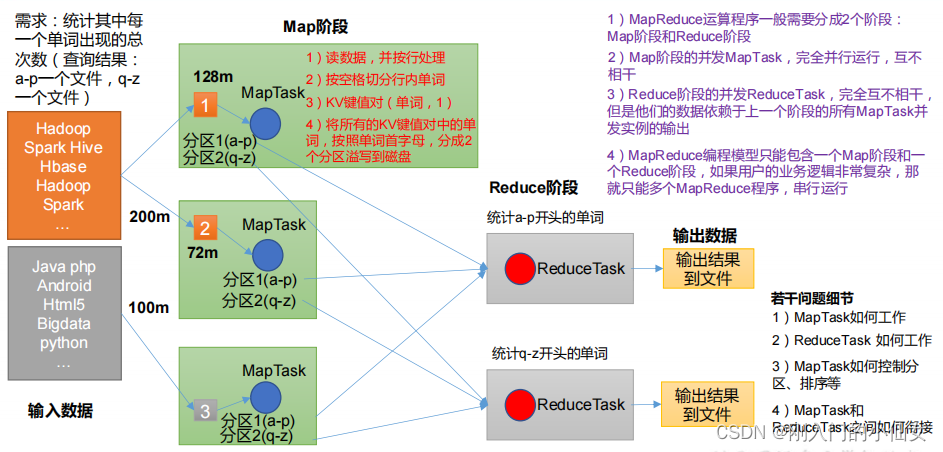
- 分布式的運算程式往往需要分成至少 2 個階段
- 第一個階段的 MapTask 并發實體,完全并行運行,互不相干
- 第二個階段的 ReduceTask 并發實體互不相干,但是他們的資料依賴于上一個階段的所有 MapTask 并發實體的輸出
- MapReduce 編程模型只能包含一個 Map 階段和一個 Reduce 階段,如果用戶的業務邏輯非常復雜,那就只能多個 MapReduce 程式,串行運行,
2. MapReduce 行程
一個完整的 MapReduce 程式在分布式運行時有三類實體行程:
- MrAppMaster :負責整個程式的程序調度及狀態協調
- MapTask :負責 Map 階段的整個資料處理流程
- ReduceTask :負責 Reduce 階段的整個資料處理流程
3. MapReduce 編程規范
用戶撰寫的程式分為三個部分:Mapper、Reducer 和 Driver,
-
Mapper階段
用戶自定義的Mapper要繼承自己的父類 Mapper的輸入資料是KV對的形式(KV的型別可自定義) Mapper中的業務邏輯寫在map()方法中 Mapper的輸出資料是KV對的形式(KV的型別可自定義) map()方法(MapTask行程)對每一個<K,V>呼叫一次 -
Ruducer 階段
用戶自定義的Reducer要繼承自己的父類 Reducer的輸入資料型別對應Mapper的輸出資料型別,也是KV Reducer的業務邏輯寫在reduce()方法中 ReduceTask行程對每一組相同k的<k,v>組呼叫一次reduce()方法 -
Driver 階段
相當于YARN集群的客戶端,用于提交我們整個程式到YARN集群 提交的是封裝了MapReduce程式相關運行引數的job物件
4. Hadoop序列化
4.1 概述
序列化就是把記憶體中的物件,轉換成位元組序列(或其他資料傳輸協議)以便于存盤到磁盤(持久化)和網路傳輸,
反序列化就是將收到位元組序列(或其他資料傳輸協議)或者是磁盤的持久化資料,轉換
4.2 自定義 bean 物件實作序列化介面(Writable)
具體實作 bean 物件序列化步驟如下 7 步:
- 必須實作 Writable 介面
- 反序列化時,需要反射呼叫空參建構式,所以必須有空參構造
- 重寫序列化方法 write
- 重寫反序列化方法 readFields
- 注意反序列化的順序和序列化的順序完全一致
- 要想把結果顯示在檔案中,需要重寫 toString(),可用"\t"分開,方便后續用
- 如果需要將自定義的 bean 放在 key 中傳輸,則還需要實作 Comparable 介面,因為 MapReduce 框中的 Shuffle 程序要求對 key 必須能排序
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/425052.html
標籤:其他