在通常的認知中,神經網路的模型是一個“黑盒”,即模型學到的內容很難用人能夠理解的方式來提取和表現,雖然對于某些型別的深度學習模型來說,這種表述部分正確,但對卷積神經網路來說絕對不是這樣,卷積神經網路學到的表示非常適合可視化,很大程度上是因為它們是視覺概念的表示,到現在為止,人們開發了多種技術來對這些表示進行可視化和理解,這里介紹3種最容易理解也是最有效的方法,
- 可視化卷積神經網路的中間輸出(中間激活):有助于理解卷積神經網路連續的層如何對輸入進行變換,也有助于初步了解卷積神經網路每個過濾器的含義,
- 可視化卷積神經網路的過濾器:有助于精確理解卷積神經網路中每個過濾器容易接受的視覺模式或視覺概念,
- 可視化影像中類激活的熱力圖:有助于理解影像的哪個部分被識別為屬于某個類別,從
而可以定位影像中的物體,
1 可視化卷積神經網路的中間輸出
可視化中間激活,是指對于給定輸入,展示網路中各個卷積層和池化層輸出的特征圖(層的輸出通常被稱為該層的激活,即激活函式的輸出),這讓我們可以看到輸入如何被分解為網路學到的不同過濾器,我們希望在三個維度對特征圖進行可視化:寬度、高度和深度(通道),每個通道都對應相對獨立的特征,所以將這些特征圖可視化的正確方法是將每個通道的內容分別繪制成二維影像,
我們使用這篇博客保存的模型來進行中間輸出的可視化:keras深度學習之貓狗分類二(資料增強)
加載該模型,列印其網路架構:
if __name__=='__main__':
#加載保存的模型
model=models.load_model('cats_and_dogs_1.h5')
model.summary()
``
```bash
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 32) 896
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 15, 15, 128) 147584
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 7, 7, 128) 0
_________________________________________________________________
flatten (Flatten) (None, 6272) 0
_________________________________________________________________
dropout (Dropout) (None, 6272) 0
_________________________________________________________________
dense (Dense) (None, 256) 1605888
_________________________________________________________________
dense_1 (Dense) (None, 1) 257
=================================================================
Total params: 1,846,977
Trainable params: 1,846,977
Non-trainable params: 0
_________________________________________________________________
顯示第一層輸出的某個通道影像:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from PIL import Image
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import optimizers
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing import image as kimage
if __name__=='__main__':
#加載保存的模型
model=models.load_model('cats_and_dogs_1.h5')
model.summary()
#加載一張貓的影像
img=kimage.load_img(path='./dataset/training_set/cats/cat.1700.jpg',target_size=(150,150))
img_tensor=kimage.img_to_array(img)
img_tensor=img_tensor.reshape((1,)+img_tensor.shape)
img_tensor/=255.
plt.imshow(img_tensor[0])
plt.show()
#提取前8層的輸出
layer_outputs=[layer.output for layer in model.layers[:8]]
activation_model=models.Model(inputs=model.input,outputs=layer_outputs)
#以預測模式運行模型 activations包含卷積層的8個輸出
activations=activation_model.predict(img_tensor)
print(activations[0].shape)#(1, 148, 148, 32)
first_layer_activation = activations[0]
plt.matshow(first_layer_activation[0, :, :, 9], cmap='viridis')
plt.show()
原圖為:
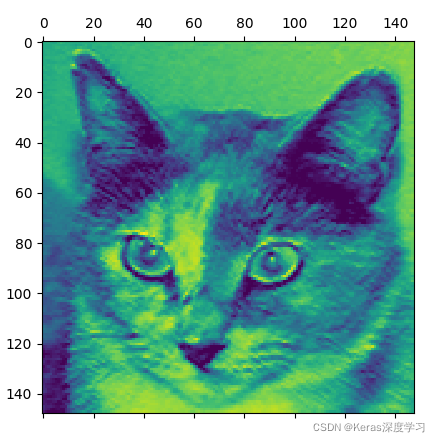
第一層的輸入第9個通道的特征圖為:
將每個中間激活的所有通道可視化
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from PIL import Image
from tensorflow.keras import layers
from tensorflow.keras import models
from tensorflow.keras import optimizers
import matplotlib.pyplot as plt
from tensorflow.keras.preprocessing import image as kimage
import numpy as np
if __name__=='__main__':
#加載保存的模型
model=models.load_model('cats_and_dogs_1.h5')
model.summary()
#加載一張貓的影像
img=kimage.load_img(path='./dataset/training_set/cats/cat.1700.jpg',target_size=(150,150))
img_tensor=kimage.img_to_array(img)
img_tensor=img_tensor.reshape((1,)+img_tensor.shape)
img_tensor/=255.
plt.imshow(img_tensor[0])
plt.show()
#提取前8層的輸出
layer_outputs=[layer.output for layer in model.layers[:8]]
activation_model=models.Model(inputs=model.input,outputs=layer_outputs)
#以預測模式運行模型 activations包含卷積層的8個輸出
activations=activation_model.predict(img_tensor)
print(activations[0].shape)#(1, 148, 148, 32)
first_layer_activation = activations[0]
plt.matshow(first_layer_activation[0, :, :, 9], cmap='viridis')
plt.show()
#清空當前影像
#plt.clf()
#將每個中間激活的所有通道可視化
layer_names = []
for layer in model.layers[:8]:
layer_names.append(layer.name)
images_per_row = 16
for layer_name, layer_activation in zip(layer_names, activations):
n_features = layer_activation.shape[-1]
size = layer_activation.shape[1]
n_cols = n_features // images_per_row
display_grid = np.zeros((size * n_cols, images_per_row * size))
for col in range(n_cols):
for row in range(images_per_row):
channel_image = layer_activation[0,:, :,col * images_per_row + row]
channel_image -= channel_image.mean()
channel_image /= channel_image.std()
channel_image *= 64
channel_image += 128
channel_image = np.clip(channel_image, 0, 255).astype('uint8')
display_grid[col * size : (col + 1) * size,
row * size : (row + 1) * size] = channel_image
scale = 1. / size
plt.figure(figsize=(scale * display_grid.shape[1],
scale * display_grid.shape[0]))
plt.title(layer_name)
plt.grid(False)
plt.imshow(display_grid, aspect='auto', cmap='viridis')
plt.show()
顯示的各通道影像如下所示:
第1個:

第2個:

第3個:
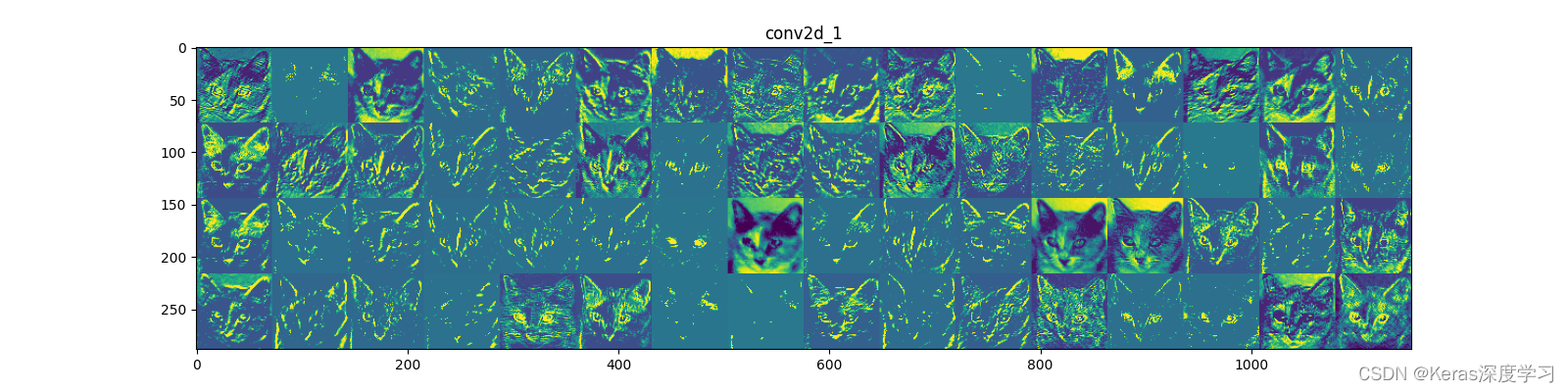
第4個:
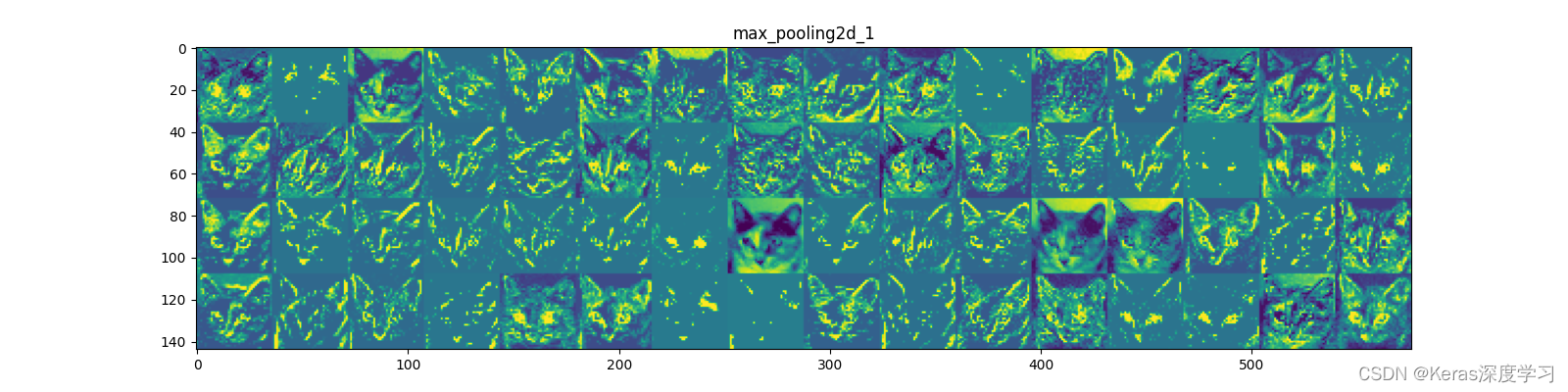
第5個:
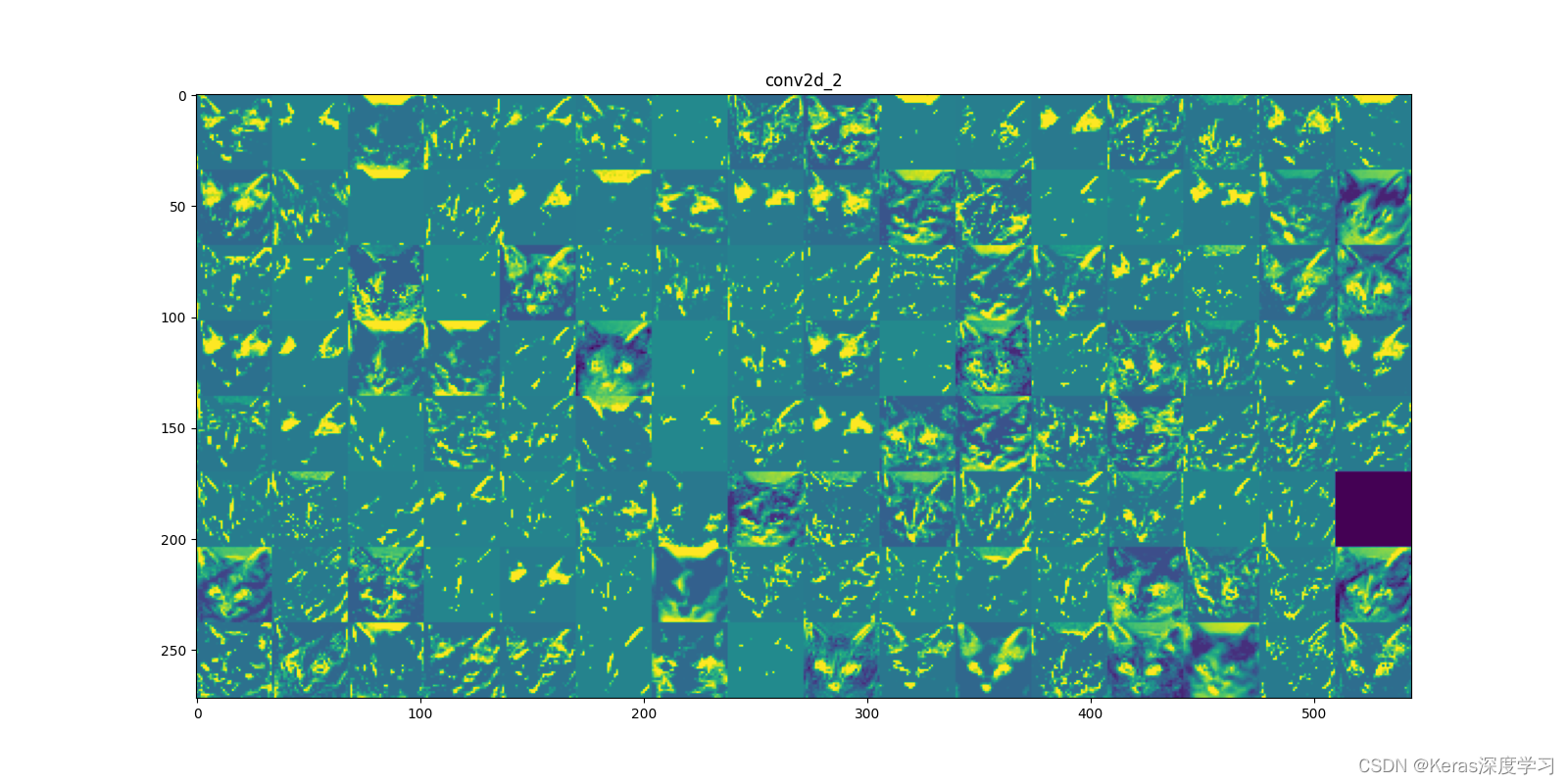
第6個:
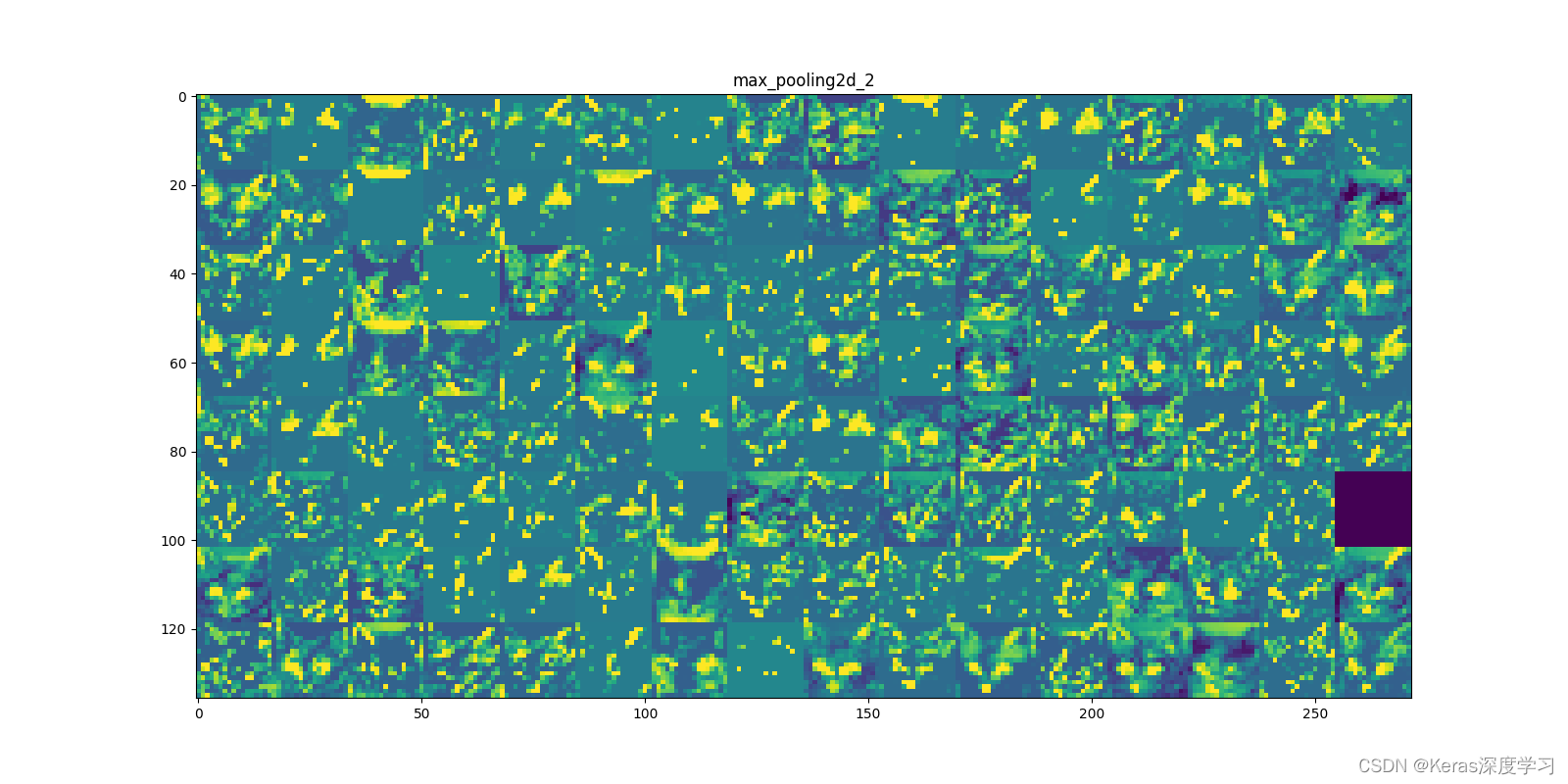
第7個:
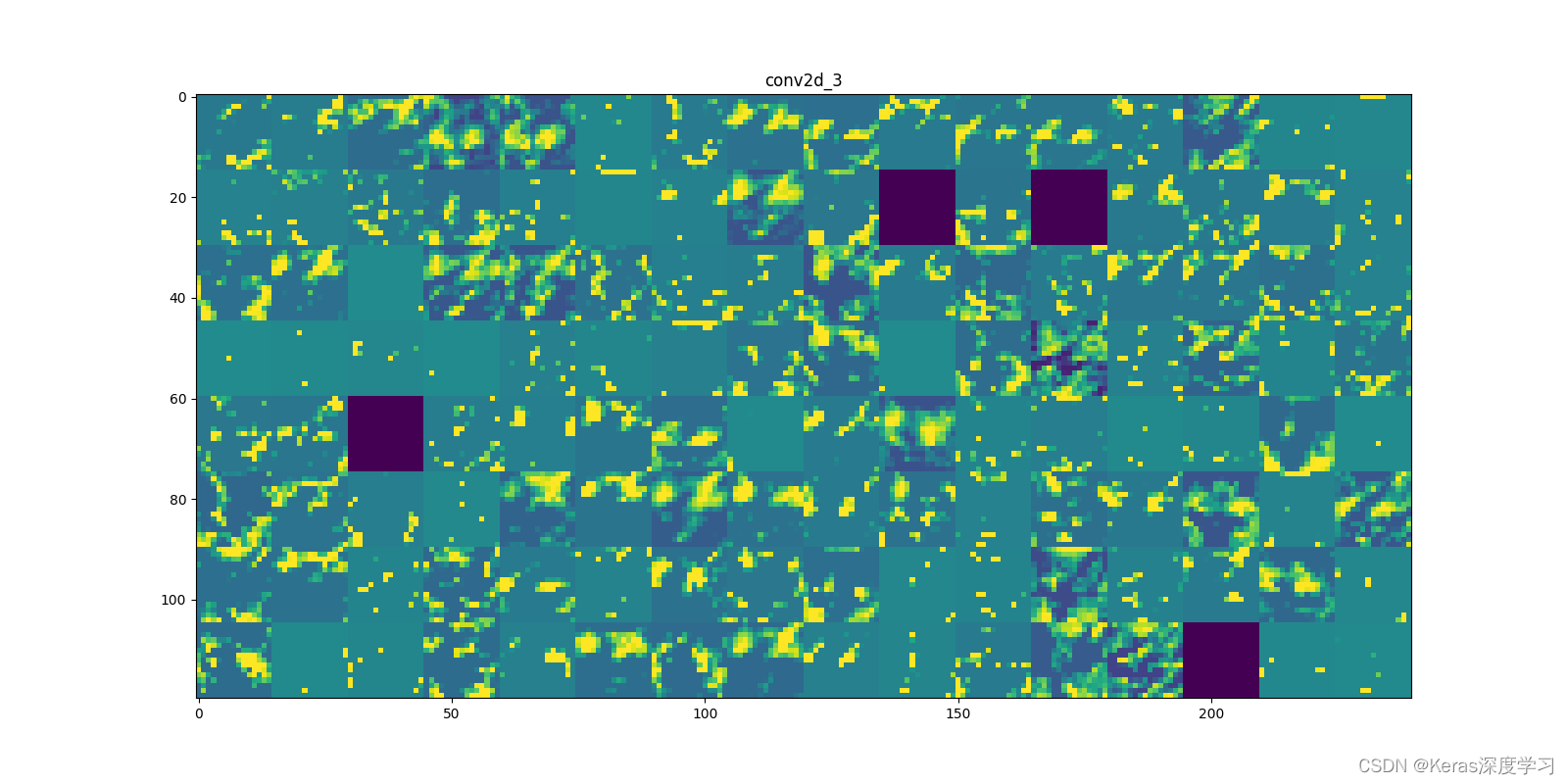
第8個:
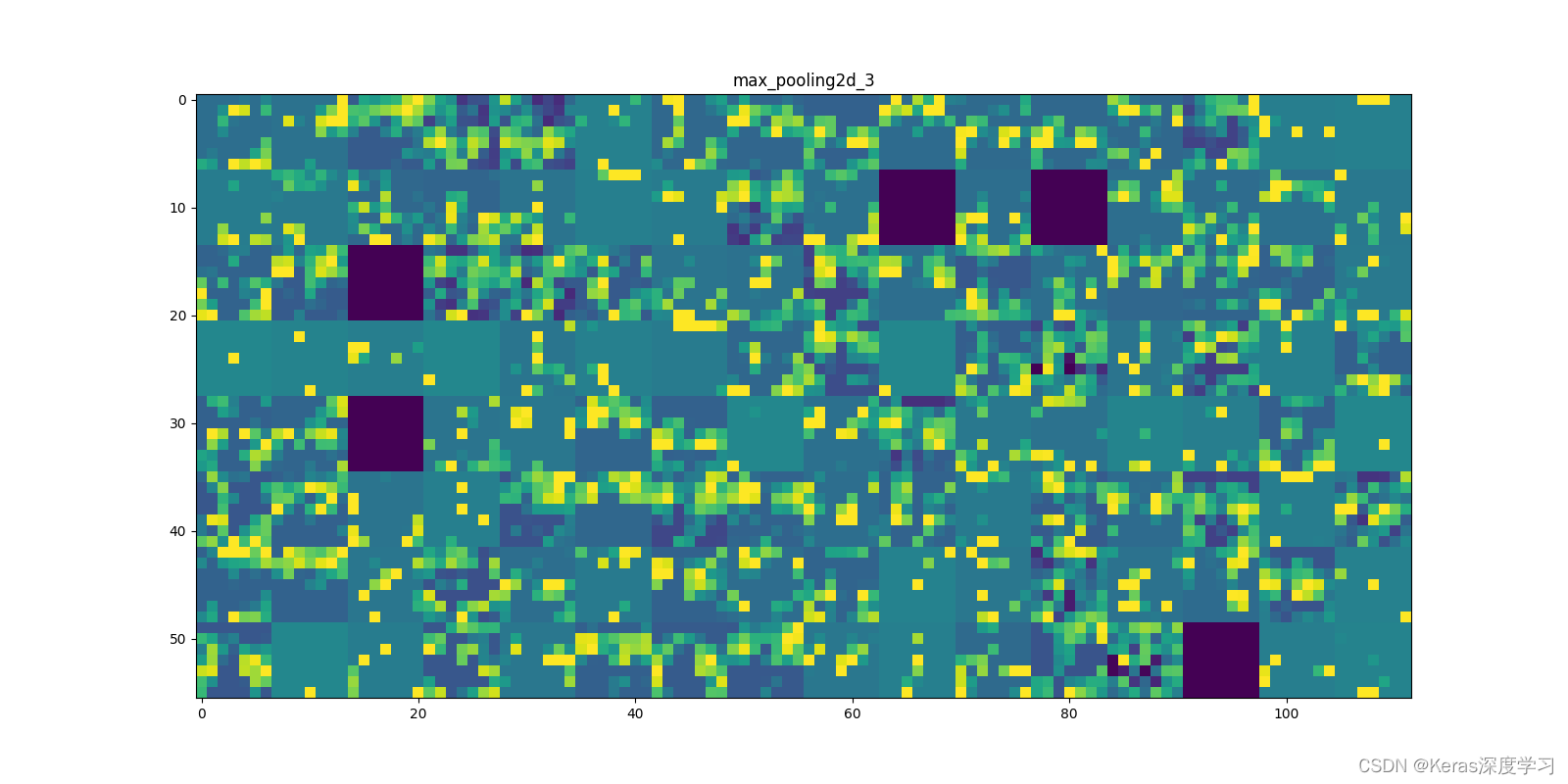
從上面顯示的各個卷積層和池化層的輸出特征圖,我們能夠得到如下幾點:
- 第一層是各種邊緣探測器的集合,在這一階段,激活幾乎保留了原始影像中的所有資訊,
- 隨著層數的加深,激活變得越來越抽象,并且越來越難以直觀地理解,它們開始表示更高層次的概念,比如“貓耳朵”和“貓眼睛”,層數越深,其表示中關于影像視覺內容的資訊就越少,而關于類別的資訊就越多,
- 激活的稀疏度(sparsity)隨著層數的加深而增大,在第一層里,所有過濾器都被輸入影像激活,但在后面的層里,越來越多的過濾器是空白的,也就是說,輸入影像中找不到這些過濾器所編碼的模式,
深度神經網路有一個重要普遍特征:隨著層數的加深,層所提取的特征變得越來越抽象,更高的層激活包含關于特定輸入的資訊越來越少,而關于目標的資訊越來越多(本例中即影像的類別:貓或狗),深度神經網路可以有效地作為資訊蒸餾管道(information distillation pipeline),輸入原始資料(本例中是 RGB 影像),反復對其進行變換,將無關資訊過濾掉(比如影像的具體外觀),并放大和細化有用的資訊(比如影像的類別),
2 可視化神經網路的過濾器
想要觀察卷積神經網路學到的過濾器,另一種簡單的方法是顯示每個過濾器所回應的視覺模式,這可以通過在輸入空間中進行梯度上升來實作:從空白輸入影像開始,將梯度下降應用于卷積神經網路輸入影像的值,其目的是讓某個過濾器的回應最大化,得到的輸入影像是選定過濾器具有最大回應的影像,
這個程序很簡單:我們需要構建一個損失函式,其目的是讓某個卷積層的某個過濾器的值最大化;然后,我們要使用隨機梯度下降來調節輸入影像的值,以便讓這個激活值最大化,
在這里我們使用在ImageNet上訓練的vgg16網路模型進行可視化濾波器,
通過如下代碼可以查看block3_conv1 層第 0 個過濾器回應的是波爾卡點(polka-dot)圖案,
from tensorflow.keras.applications import VGG16
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
#為過濾器的可視化定義損失張量
model = VGG16(weights='imagenet',
include_top=False)
model.summary()
layer_name = 'block3_conv1'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
#獲取損失相對于輸入的梯度
grads = K.gradients(loss, model.input)[0]
#梯度標準化技巧
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
#給定numpy輸入值,得到numpy輸出值
iterate = K.function([model.input], [loss, grads])
#通過隨機梯度下降讓損失最大化
input_img_data = np.random.random((1, 150, 150, 3)) * 20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
#將張量轉換為有效影像的實用函式
def deprocess_image(x):
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
x += 0.5
x = np.clip(x, 0, 1)
# x *= 255
# x = np.clip(x, 0, 255)
# x/=255.
return x
#生成過濾器可視化的函式
#構建一個損失函式,將該層第 n 個過濾器的激活最大化
def generate_pattern(layer_name, filter_index, size=150):
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
grads = K.gradients(loss, model.input)[0]
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
iterate = K.function([model.input], [loss, grads])
input_img_data = np.random.random((1, size, size, 3)) * 20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
img = input_img_data[0]
return deprocess_image(img)
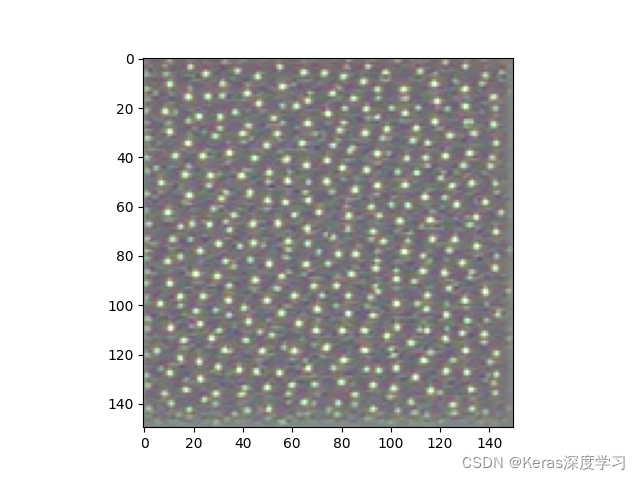
#block3_conv1 層第 0 個過濾器回應的是波爾卡點(polka-dot)圖案
plt.imshow(generate_pattern('block3_conv1', 0))
plt.show()
接下來我們把多個卷積層的每個層前64個過濾器的模式顯示出來,代碼如下:
from tensorflow.keras.applications import VGG16
from tensorflow.keras import backend as K
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
#為過濾器的可視化定義損失張量
model = VGG16(weights='imagenet',
include_top=False)
model.summary()
layer_name = 'block3_conv1'
filter_index = 0
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
#獲取損失相對于輸入的梯度
grads = K.gradients(loss, model.input)[0]
#梯度標準化技巧
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
#給定numpy輸入值,得到numpy輸出值
iterate = K.function([model.input], [loss, grads])
#通過隨機梯度下降讓損失最大化
input_img_data = np.random.random((1, 150, 150, 3)) * 20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
#將張量轉換為有效影像的實用函式
def deprocess_image(x):
x -= x.mean()
x /= (x.std() + 1e-5)
x *= 0.1
x += 0.5
x = np.clip(x, 0, 1)
# x *= 255
# x = np.clip(x, 0, 255)
# x/=255.
return x
#生成過濾器可視化的函式
#構建一個損失函式,將該層第 n 個過濾器的激活最大化
def generate_pattern(layer_name, filter_index, size=150):
layer_output = model.get_layer(layer_name).output
loss = K.mean(layer_output[:, :, :, filter_index])
grads = K.gradients(loss, model.input)[0]
grads /= (K.sqrt(K.mean(K.square(grads))) + 1e-5)
iterate = K.function([model.input], [loss, grads])
input_img_data = np.random.random((1, size, size, 3)) * 20 + 128.
step = 1.
for i in range(40):
loss_value, grads_value = iterate([input_img_data])
input_img_data += grads_value * step
img = input_img_data[0]
return deprocess_image(img)
#block3_conv1 層第 0 個過濾器回應的是波爾卡點(polka-dot)圖案
# plt.imshow(generate_pattern('block3_conv1', 0))
# plt.show()
# 生成某一層中所有過濾器回應模式組成的網格
#查看如下5個層的過濾器模式
layer_names=['block1_conv1','block2_conv1','block3_conv1','block4_conv1','block5_conv1']
for layer_name in layer_names:
#顯示通道中的前64個濾波器
size = 64
margin = 5
results = np.zeros((8 * size + 7 * margin, 8 * size + 7 * margin, 3))
for i in range(8):
for j in range(8):
filter_img = generate_pattern(layer_name, i + (j * 8), size=size)
horizontal_start = i * size + i * margin
horizontal_end = horizontal_start + size
vertical_start = j * size + j * margin
vertical_end = vertical_start + size
results[horizontal_start: horizontal_end,vertical_start: vertical_end, :] = filter_img
plt.figure(figsize=(20, 20))
plt.imshow(results)
plt.show()
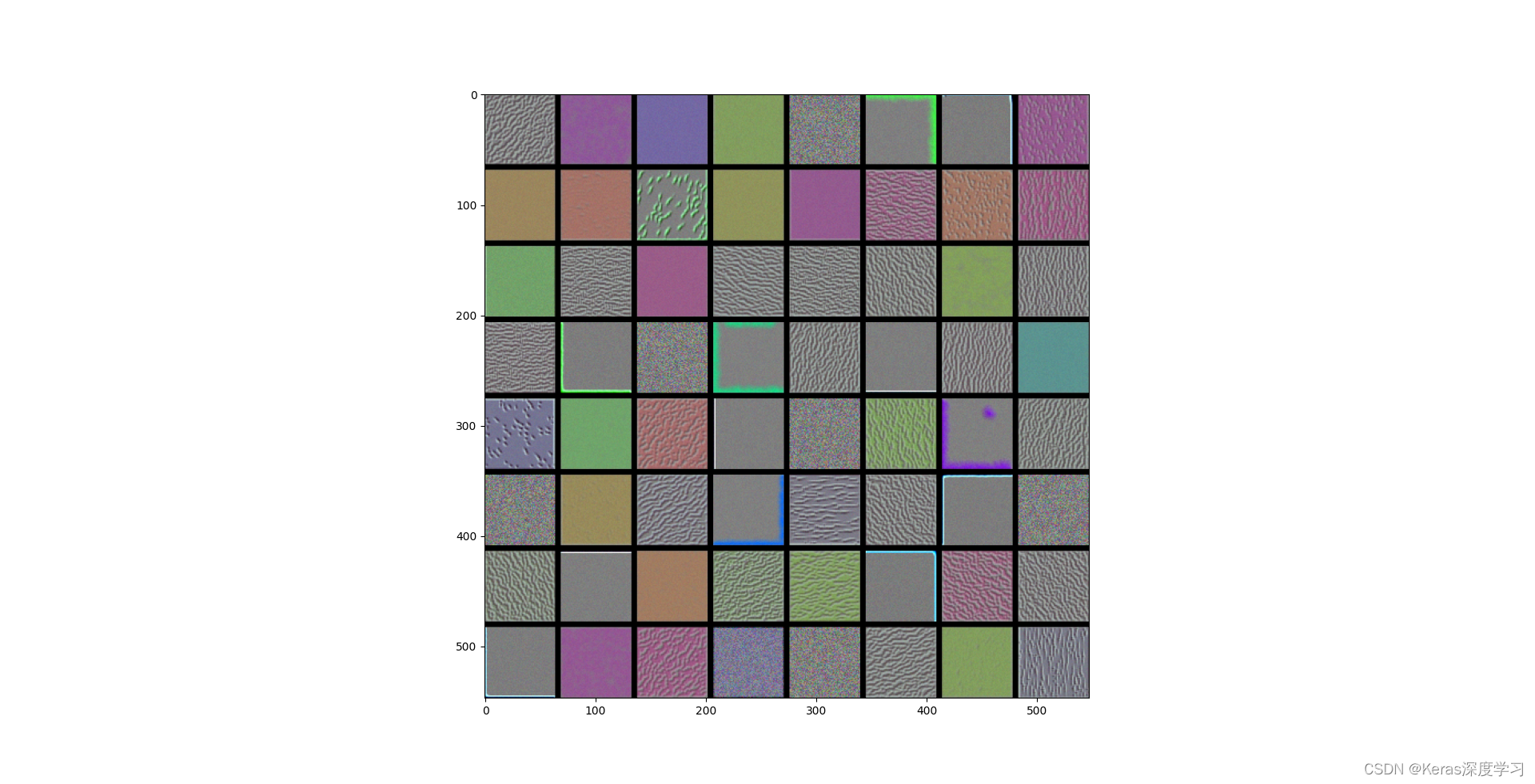
block1_conv1層過濾器模式為:
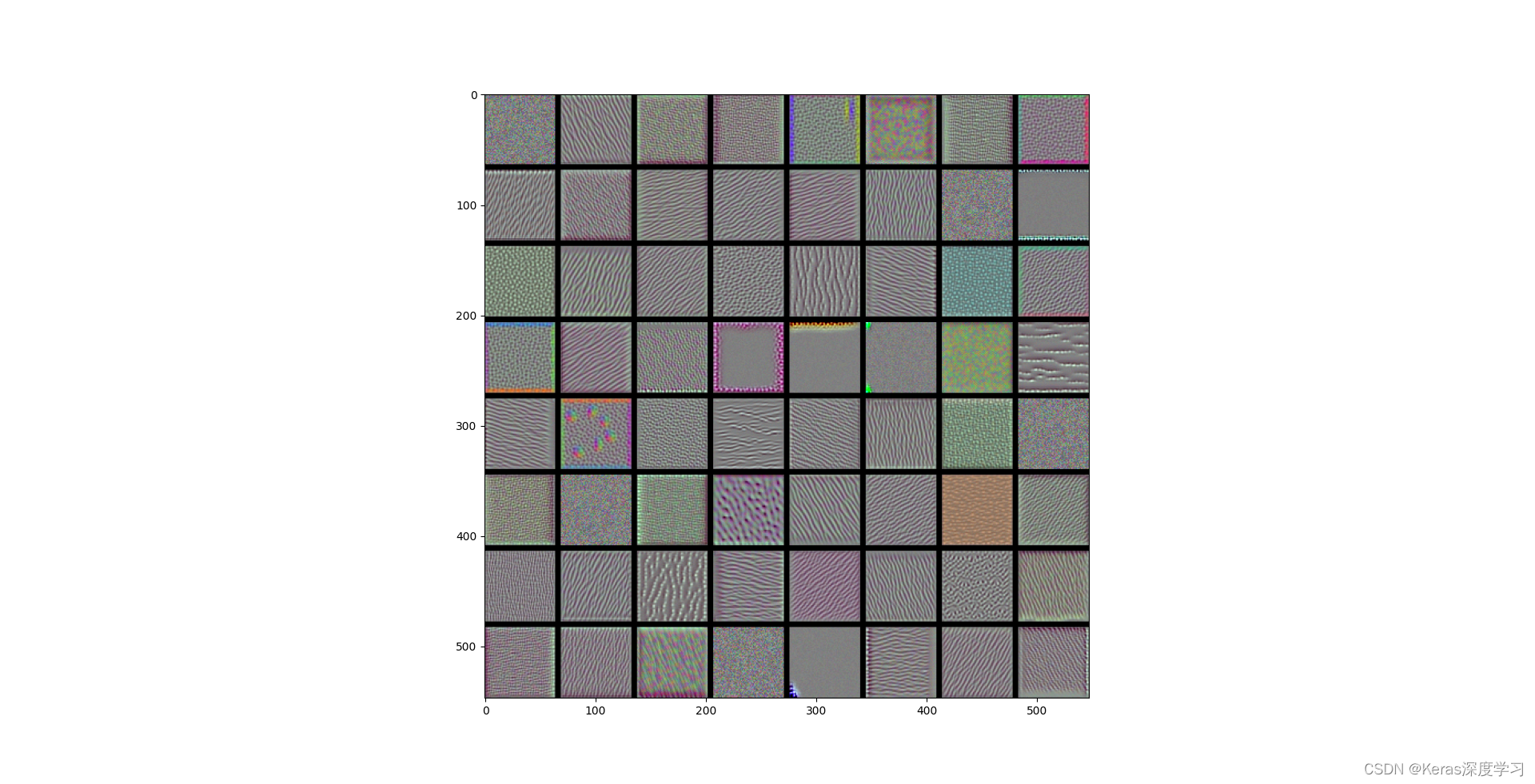
block2_conv1層過濾器模式為:
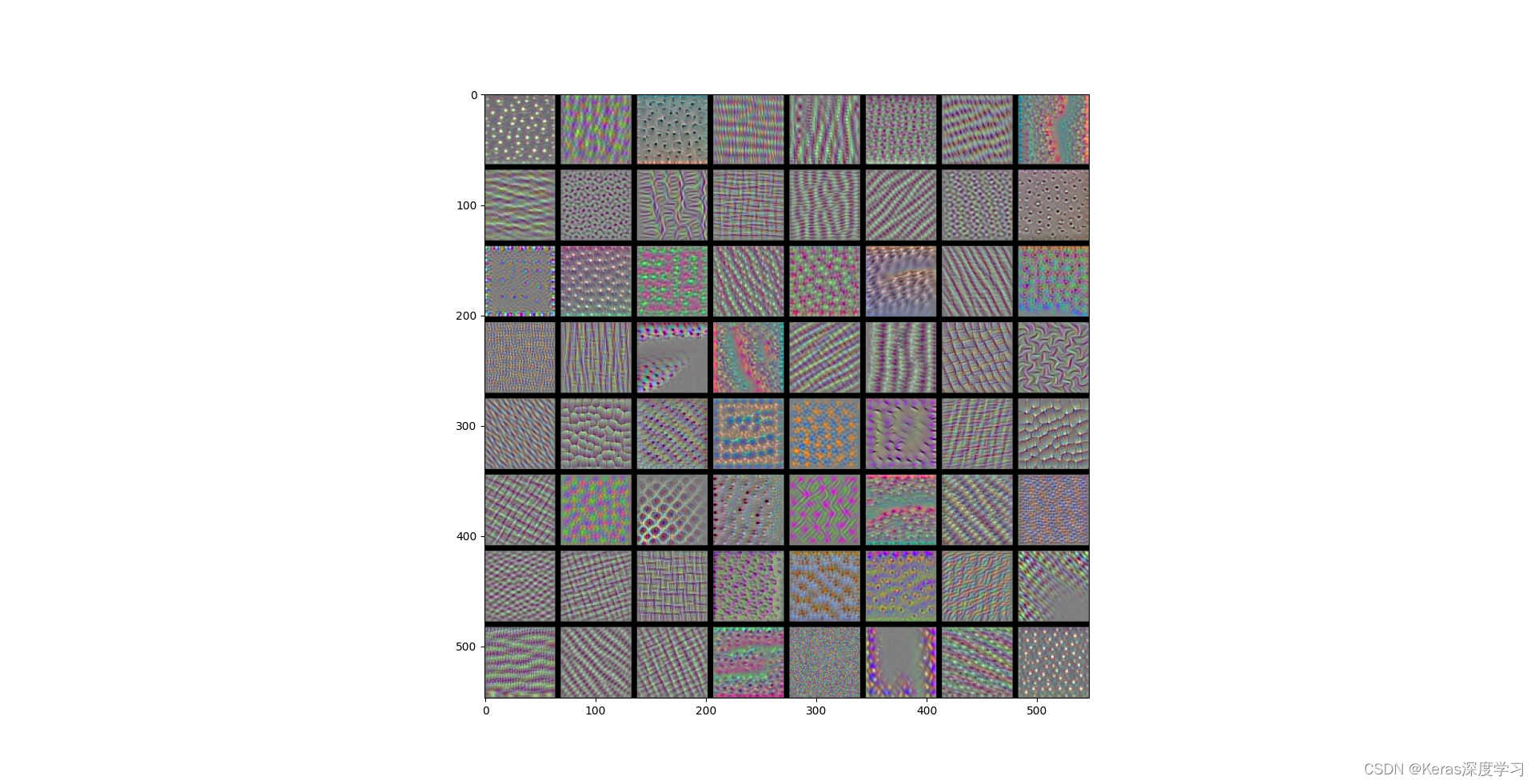
block3_conv1層過濾器模式為:
block4_conv1層過濾器模式為:
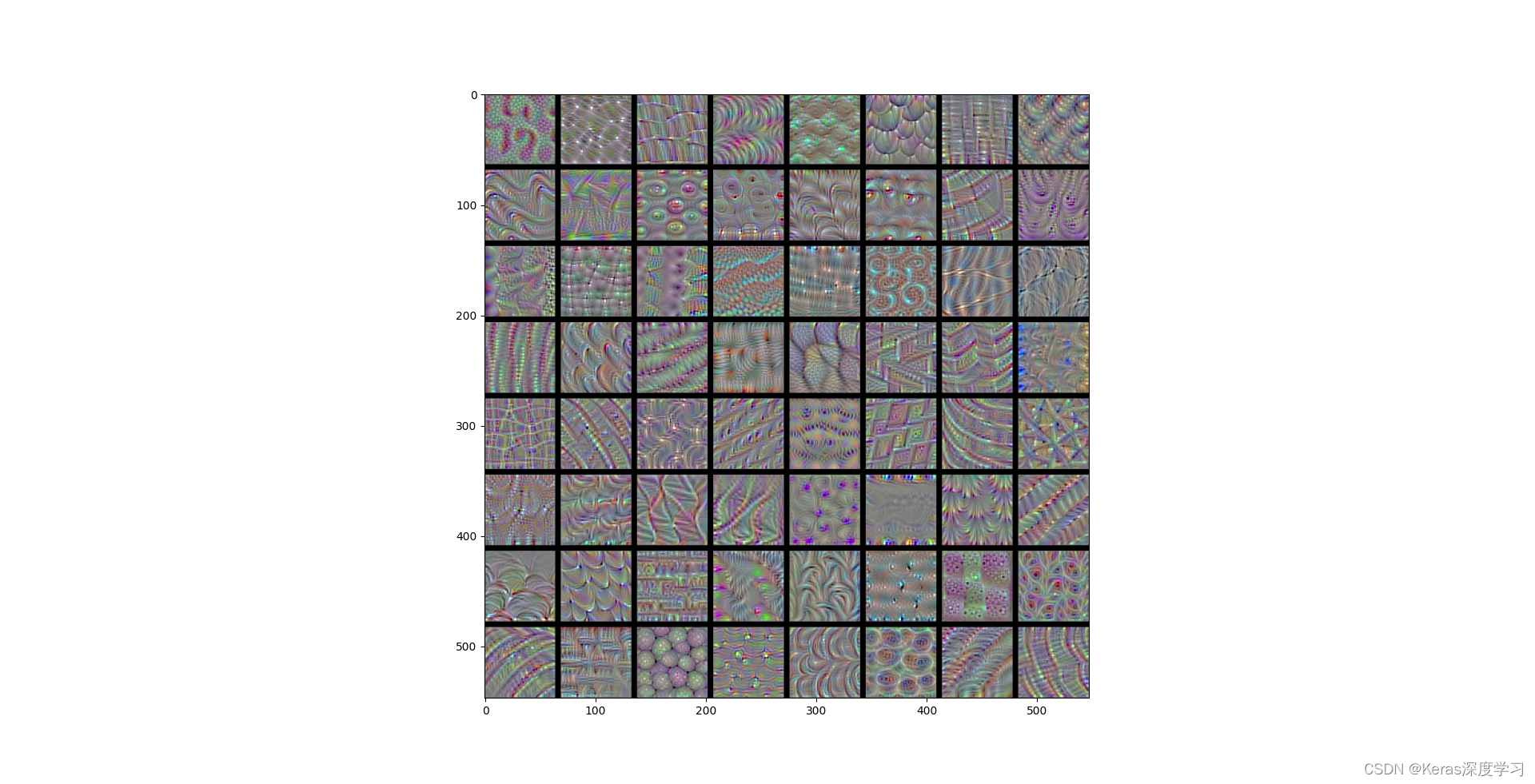
block5_conv1層過濾器模式為:
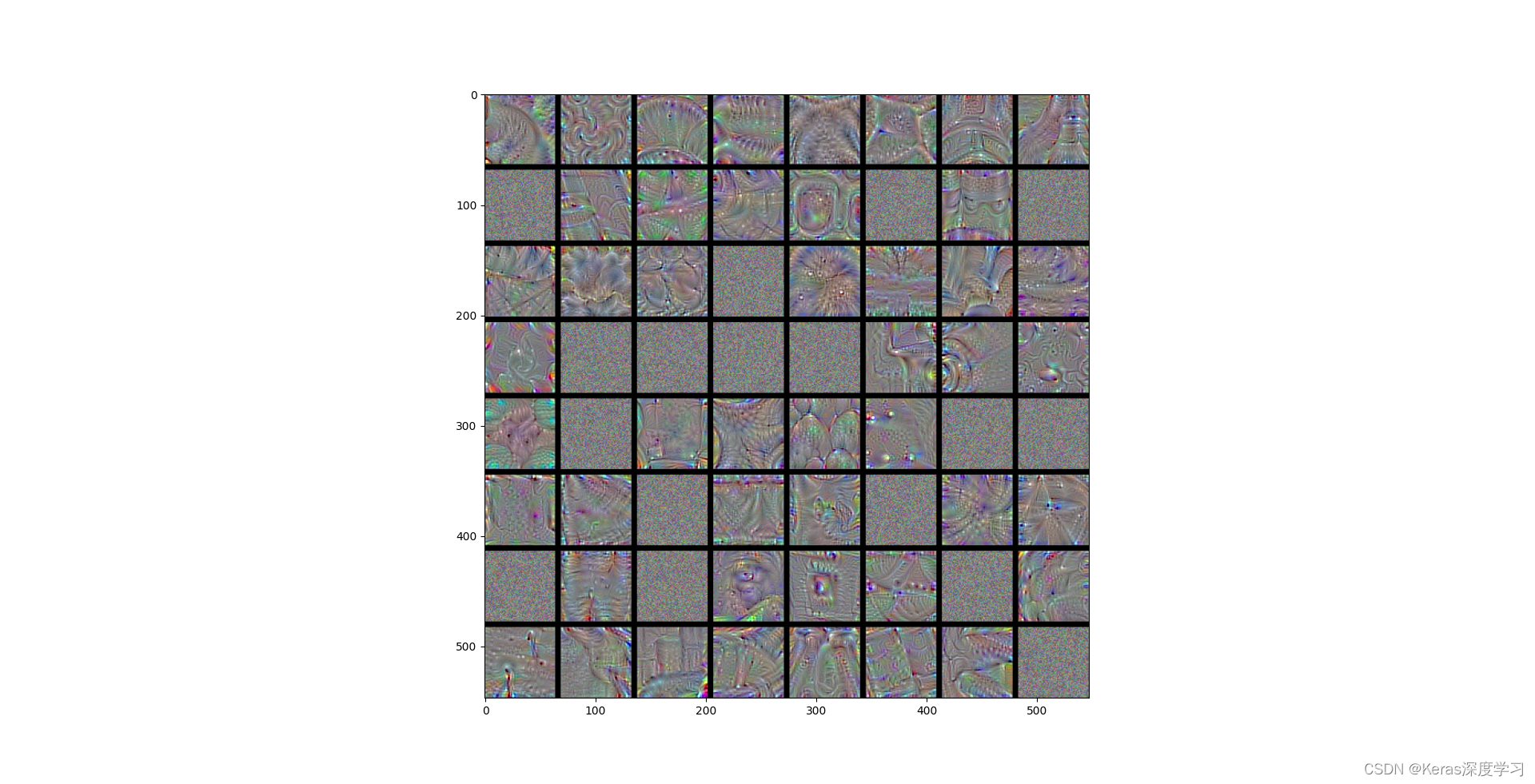
這些過濾器可視化包含卷積神經網路的層如何觀察世界的很多資訊:卷積神經網路中每一層都學習一組過濾器,以便將其輸入表示為過濾器的組合,這類似于傅里葉變換將信號分解為一組余弦函式的程序,隨著層數的加深,卷積神經網路中的過濾器變得越來越復雜,越來越精細,
- 模型第一層(block1_conv1)的過濾器對應簡單的方向邊緣和顏色(還有一些是彩色邊緣),
- block2_conv1 層的過濾器對應邊緣和顏色組合而成的簡單紋理,
- 更高層的過濾器類似于自然影像中的紋理:羽毛、眼睛、樹葉等,
3 可視化類激活的熱力圖
我還要介紹另一種可視化方法,它有助于了解一張影像的哪一部分讓卷積神經網路做出了最終的分類決策,這有助于對卷積神經網路的決策程序進行除錯,特別是出現分類錯誤的情況下,這種方法還可以定位影像中的特定目標,
這種通用的技術叫作類激活圖(CAM,class activation map)可視化,它是指對輸入影像生成類激活的熱力圖,類激活熱力圖是與特定輸出類別相關的二維分數網格,對任何輸入影像的每個位置都要進行計算,它表示每個位置對該類別的重要程度,舉例來說,對于輸入到貓狗分類卷積神經網路的一張影像,CAM 可視化可以生成類別“貓”的熱力圖,表示影像的各個部分與“貓”的相似程度,CAM 可視化也會生成類別“狗”的熱力圖,表示影像的各個部分與“狗”的相似程度,
我們將使用的具體實作方式是“Grad-CAM: visual explanations from deep networks via gradient-based localization” 這篇論文中描述的方法,這種方法非常簡單:給定一張輸入影像,對于一個卷積層的輸出特征圖,用類別相對于通道的梯度對這個特征圖中的每個通道進行加權,直觀上來看,理解這個技巧的一種方法是,你是用“每個通道對類別的重要程度”對“輸入影像對不同通道的激活強度”的空間圖進行加權,從而得到了“輸入影像對類別的激活強度”的空間圖,
為模型預處理一張輸入影像,在這里采用非洲象影像:

預測代碼如下:
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input, decode_predictions
from tensorflow.keras.applications import VGG16
import numpy as np
img_path = './creative_commons_elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
model = VGG16(weights='imagenet')
preds = model.predict(x)
print('Predicted:', decode_predictions(preds, top=3)[0])
print(np.argmax(preds[0]))
預測結果為:
Predicted: [('n02504458', 'African_elephant', 0.90988594), ('n01871265', 'tusker', 0.085724816), ('n02504013', 'Indian_elephant', 0.00434713)]
對這張影像預測的前三個類別分別為:
- 非洲象(African elephant,92.5% 的概率)
- 長牙動物(tusker,7% 的概率)
- 印度象(Indian elephant,0.4% 的概率)
網路識別出影像中包含數量不確定的非洲象,預測向量中被最大激活的元素是對應“非洲象”類別的元素,索引編號為 386,
為了展示影像中哪些部分最像非洲象,我們來使用 Grad-CAM 演算法,
測驗影像的“非洲象”類激活熱力圖,代碼為:
from tensorflow.keras.preprocessing import image
from tensorflow.keras.applications.vgg16 import preprocess_input,decode_predictions
import numpy as np
from tensorflow.keras.applications.vgg16 import VGG16
import matplotlib.pyplot as plt
from tensorflow.keras import backend as K
import cv2
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
model = VGG16(weights='imagenet') # 包含最后的全連接層
img_path = 'creative_commons_elephant.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
preds = model.predict(x)
print('predicted: ', decode_predictions(preds, top=3)[0])
print(np.argmax(preds[0]))
elephant_output = model.output[:, 386]
last_conv_layer = model.get_layer('block5_conv3')
grads = K.gradients(elephant_output, last_conv_layer.output)[0]
pooled_grads = K.mean(grads, axis=(0, 1, 2))
iterate = K.function([model.input], [pooled_grads, last_conv_layer.output[0]])
pooled_grads_value, conv_layer_output_value = iterate([x])
for i in range(512):
conv_layer_output_value[:, :, i] *= pooled_grads_value[i]
heatmap = np.mean(conv_layer_output_value, axis=-1)
#熱力圖后處理
heatmap = np.maximum(heatmap, 0)
heatmap /= np.max(heatmap)
plt.matshow(heatmap)
plt.show()
img = cv2.imread(img_path)
heatmap = cv2.resize(heatmap, (img.shape[1], img.shape[0]))
heatmap = np.uint8(255 * heatmap)
heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET)
superimposed_img = heatmap * 0.4 + img
cv2.imwrite('elephant_cam.jpg', superimposed_img)
得到的影像為:
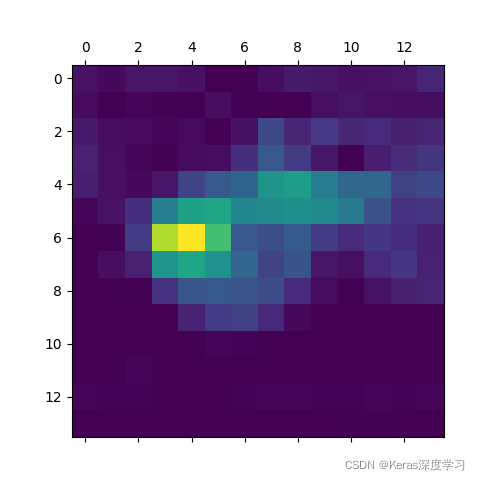

這種可視化方法回答了兩個重要問題:
- 網路為什么會認為這張影像中包含一頭非洲象?
- 非洲象在影像中的什么位置?
尤其值得注意的是,小象耳朵的激活強度很大,這可能是網路找到的非洲象和印度象的不
同之處,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426484.html
標籤:AI