目錄
一、先上手擼代碼!
1、導庫、導資料
2、核心演算法
3、可視化部分
二、調庫代碼!(sklearn)
一、先上手擼代碼!
1、首先是匯入所需要的庫和資料
import pandas as pd
import numpy as np
import random
import math
import matplotlib.pyplot as plt
# 這兩行代碼解決 plt 中文顯示的問題
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_excel('13信科學生成績.xlsx')
data = np.array(df)
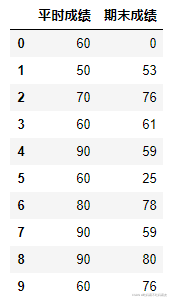
df.head(10)先給大伙們看看資料集長啥樣:
用matplotlib簡單的可視化一下初始資料:
# 輸入資料
x = data.T[0]
y = data.T[1]
plt.scatter(x, y, s=50, c='r') # 畫散點圖
plt.xlabel('平時') # 橫坐標軸標題
plt.ylabel('期末') # 縱坐標軸標題
plt.show()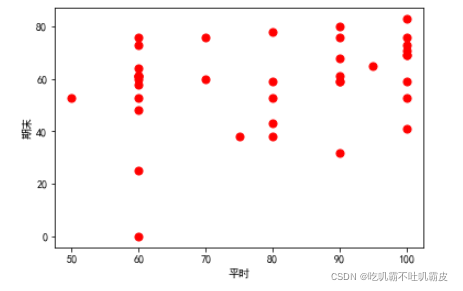
2、接下來就是kmeans的核心演算法了
k=3
i = 1
min1 = data.min(axis = 0)
max1 = data.max(axis = 0)
#在資料最大最小值中隨機生成k個初始聚類中心,保存為t
centre = np.empty((k,2))
for i in range(k):
centre[i][0] = random.randint(min1[0],max1[0])#平時成績
centre[i][1] = random.randint(min1[1],max1[1])#期末成績
while i<500:
#計算歐氏距離
def euclidean_distance(List,t):
return math.sqrt(((List[0] - t[0])**2 + (List[1] - t[1])**2))
#每個點到每個中心點的距離矩陣
dis = np.empty((len(data),k))
for i in range(len(data)):
for j in range(k):
dis[i][j] = euclidean_distance(data[i],centre[j])
#初始化分類矩陣
classify = []
for i in range(k):
classify.append([])
#比較距離并分類
for i in range(len(data)):
List = dis[i].tolist()
index = List.index(dis[i].min())
classify[index].append(i)
#構造新的中心點
new_centre = np.empty((k,2))
for i in range(len(classify)):
new_centre[i][0] = np.sum(data[classify[i]][0])/len(classify[i])
new_centre[i][1] = np.sum(data[classify[i]][1])/len(classify[i])
#比較新的中心點和舊的中心點是否一樣
if (new_centre == centre).all():
break
else:
centre = new_centre
i = i + 1
# print('迭代次數為:',i)
print('聚類中心為:',new_centre)
print('分類情況為:',classify)注意!!!這里的k是指分成k類,讀者可以自行選取不同的k值做實驗

3、可視化部分(將不用類用不同顏色區分開來~~)
mark = ['or', 'ob', 'og', 'ok','sb', 'db', '<b', 'pb'] #紅、藍、綠、黑四種顏色的圓點
#mark=['sb', 'db', '<b', 'pb']
plt.figure(3)#創建圖表1
for i in range(0,k):
x=[]
y=[]
for j in range(len(classify[i])):
x.append(data[classify[i][j]][0])
y.append(data[classify[i][j]][1])
plt.xlim(xmax=105,xmin=45)
plt.ylim(ymax=85,ymin=-5)
plt.plot(x,y,mark[i])
#plt.show()
一起來康康可視化結果8!!
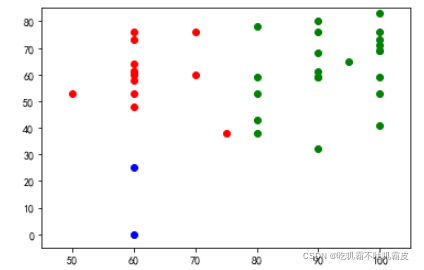
二、接下來是調庫代碼!(sklearn)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn import metrics
df = pd.read_excel('13信科學生成績.xlsx')
data = np.array(df)
y_pred=KMeans(n_clusters=3,random_state=9).fit_predict(data)
plt.scatter(data[:,0],data[:,1],c=y_pred)
plt.show()
print(metrics.calinski_harabasz_score(data,y_pred))可視化結果和手擼的結果略有差別,有可能是資料集的問題,也有可能是k值選取的問題,各位親們不需要擔心!!!
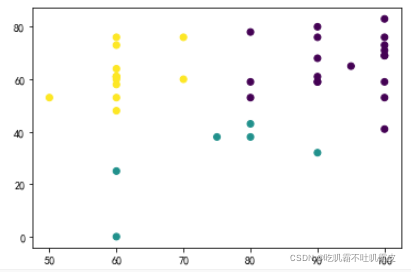
嗚嗚嗚本人第一次發博客記錄自己的學習瞬間,有什么建議或者問題都可以提出來喔!copy了代碼的小朋友不要忘了關注點贊么么噠!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426488.html
標籤:AI