目錄
走進LightGBM
什么是LightGBM?
XGBoost的缺點
LightGBM的優化
LightGBM的基本原理
Histogram 演算法
直方圖加速
LightGBM并行優化
代碼實踐
引數詳解
? 代碼實操
最優模型及引數(資料集1000)
模型調參
每文一語
👇👇🧐🧐??🎉🎉
歡迎點擊專欄其他文章(歡迎訂閱·持續更新中~)
機器學習之Python開源教程——專欄介紹及理論知識概述
機器學習框架及評估指標詳解
Python監督學習之分類演算法的概述
資料預處理之資料清理,資料集成,資料規約,資料變化和離散化
特征工程之One-Hot編碼、label-encoding、自定義編碼
卡方分箱、KS分箱、最優IV分箱、樹結構分箱、自定義分箱
特征選取之單變數統計、基于模型選擇、迭代選擇
機器學習分類演算法之樸素貝葉斯
【萬字詳解·附代碼】機器學習分類演算法之K近鄰(KNN)
《全網最強》詳解機器學習分類演算法之決策樹(附可視化和代碼)
機器學習分類演算法之支持向量機
機器學習分類演算法之Logistic 回歸(邏輯回歸)
機器學習分類演算法之隨機森林(集成學習演算法)
機器學習分類演算法之XGBoost(集成學習演算法)
持續更新中~
作者簡介
👦博客名:王小王-123
👀簡介:CSDN博客專家、CSDN簽約作者、華為云享專家,騰訊云、阿里云、簡書、InfoQ創作者,公眾號:書劇可詩畫,2020年度CSDN優秀創作者,左手詩情畫意,右手代碼人生,歡迎一起探討技術
走進LightGBM
什么是LightGBM?
在上一篇的文章里,我介紹了XGBoost演算法,它是是很多的比賽的大殺器,但是在使用程序中,其訓練耗時很長,記憶體占用比較大,
在2017年年1月微軟在GitHub的上開源了LightGBM,該演算法在不降低準確率的前提下,速度提升了10倍左右,占用記憶體下降了3倍左右,LightGBM是個快速的,分布式的,高性能的基于決策樹演算法的梯度提升演算法,可用于排序,分類,回歸以及很多其他的機器學習任務中,
GBDT (Gradient Boosting Decision Tree) 是機器學習中一個長盛不衰的模型,其主要思想是利用弱分類器(決策樹)迭代訓練以得到最優模型,該模型具有訓練效果好、不易過擬合等優點,GBDT不僅在工業界應用廣泛,通常被用于多分類、點擊率預測、搜索排序等任務;在各種資料挖掘競賽中也是致命武器,據統計Kaggle上的比賽有一半以上的冠軍方案都是基于GBDT,
而LightGBM(Light Gradient Boosting Machine)是一個實作GBDT演算法的框架,支持高效率的并行訓練,并且具有更快的訓練速度、更低的記憶體消耗、更好的準確率、支持分布式可以快速處理海量資料等優點,
LightGBM是一個梯度提升框架,使用基于樹的學習演算法,
常用的機器學習演算法,例如神經網路等演算法,都可以以mini-batch的方式訓練,訓練資料的大小不會受到記憶體限制,而GBDT在每一次迭代的時候,都需要遍歷整個訓練資料多次,如果把整個訓練資料裝進記憶體則會限制訓練資料的大小;如果不裝進記憶體,反復地讀寫訓練資料又會消耗非常大的時間,尤其面對工業級海量的資料,普通的GBDT演算法是不能滿足其需求的,
LightGBM提出的主要原因就是為了解決GBDT在海量資料遇到的問題,讓GBDT可以更好更快地用于工業實踐,
XGBoost的缺點
在LightGBM提出之前,最有名的GBDT工具就是XGBoost了,它是基于預排序方法的決策樹演算法,這種構建決策樹的演算法基本思想是:首先,對所有特征都按照特征的數值進行預排序,其次,在遍歷分割點的時候用O(#data)的代價找到一個特征上的最好分割點,最后,在找到一個特征的最好分割點后,將資料分裂成左右子節點,
這樣的預排序演算法的優點是能精確地找到分割點,但是缺點也很明顯:首先,空間消耗大,這樣的演算法需要保存資料的特征值,還保存了特征排序的結果(例如,為了后續快速的計算分割點,保存了排序后的索引),這就需要消耗訓練資料兩倍的記憶體,其次,時間上也有較大的開銷,在遍歷每一個分割點的時候,都需要進行分裂增益的計算,消耗的代價大,最后,對cache優化不友好,在預排序后,特征對梯度的訪問是一種隨機訪問,并且不同的特征訪問的順序不一樣,無法對cache進行優化,同時,在每一層長樹的時候,需要隨機訪問一個行索引到葉子索引的陣列,并且不同特征訪問的順序也不一樣,也會造成較大的cache miss,
LightGBM的優化
為了避免XGBoost的缺陷,并且能夠在不損害準確率的條件下加快GBDT模型的訓練速度,lightGBM在傳統的GBDT演算法上進行了如下優化:
- 基于Histogram的決策樹演算法,
- 單邊梯度采樣 Gradient-based One-Side Sampling(GOSS):使用GOSS可以減少大量只具有小梯度的資料實體,這樣在計算資訊增益的時候只利用剩下的具有高梯度的資料就可以了,相比XGBoost遍歷所有特征值節省了不少時間和空間上的開銷,
- 互斥特征捆綁 Exclusive Feature Bundling(EFB):使用EFB可以將許多互斥的特征系結為一個特征,這樣達到了降維的目的,
- 帶深度限制的Leaf-wise的葉子生長策略:大多數GBDT工具使用低效的按層生長 (level-wise) 的決策樹生長策略,因為它不加區分的對待同一層的葉子,帶來了很多沒必要的開銷,實際上很多葉子的分裂增益較低,沒必要進行搜索和分裂,LightGBM使用了帶有深度限制的按葉子生長 (leaf-wise) 演算法,
- 直接支持類別特征(Categorical Feature)
- 支持高效并行
- Cache命中率優化
LightGBM的基本原理
LightGBM樹的生長方式是垂直方向的,其他的演算法都是水平方向的,也就是說Light GBM生長的是樹的葉子,其他的演算法生長的是樹的層次,
LightGBM選擇具有最大誤差的樹葉進行生長,當生長同樣的樹葉,生長葉子的演算法可以比基于層的演算法減少更多的loss,
下面的圖解釋了LightGBM和其他的提升演算法的實作
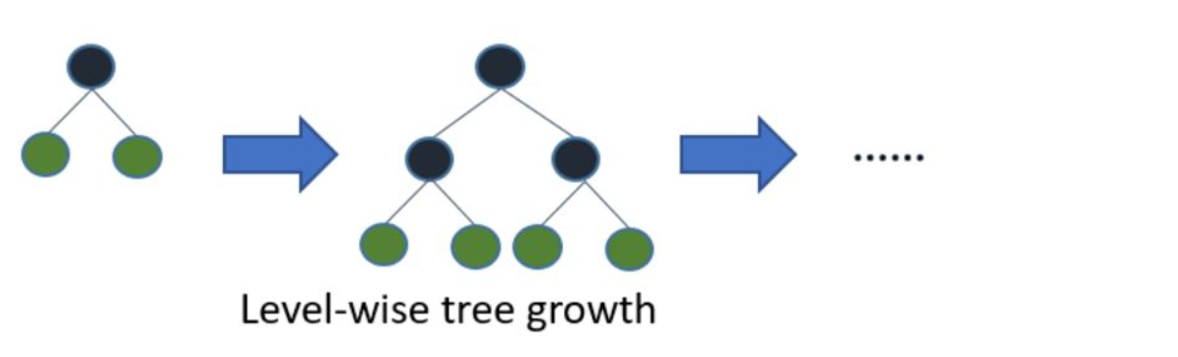
在 Histogram 演算法之上,LightGBM 進行進一步的優化,首先它拋棄了大多數 GBDT 工具使用的按層生長 (level-wise) 的決策樹生長策略,而使用了帶有深度限制的按葉子生長 (leaf-wise) 演算法,Level-wise 過一次資料可以同時分裂同一層的葉子,容易進行多執行緒優化,也好控制模型復雜度,不容易過擬合,但實際上 Level-wise 是一種低效的演算法,因為它不加區分的對待同一層的葉子,帶來了很多沒必要的開銷,因為實際上很多葉子的分裂增益較低,沒必要進行搜索和分裂,
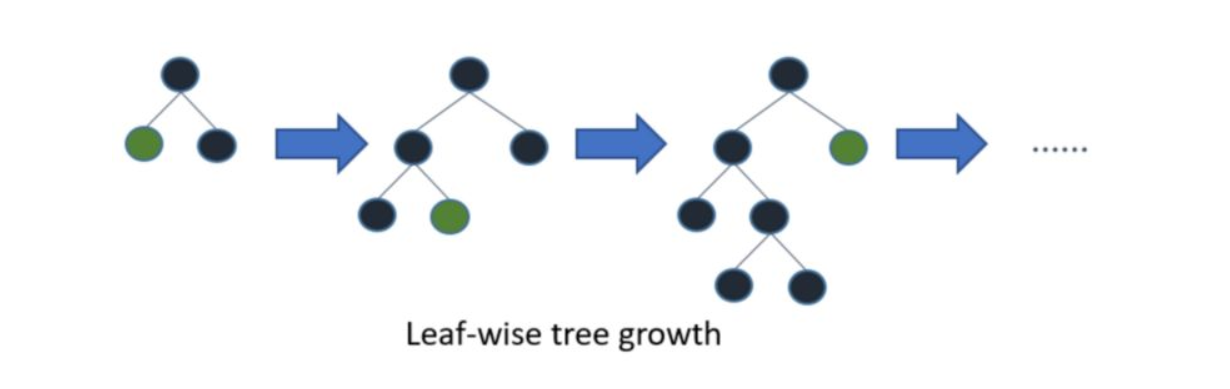
Leaf-wise 則是一種更為高效的策略,每次從當前所有葉子中,找到分裂增益最大的一個葉子,然后分裂,如此回圈,因此同 Level-wise 相比,在分裂次數相同的情況下,Leaf-wise 可以降低更多的誤差,得到更好的精度,Leaf-wise 的缺點是可能會長出比較深的決策樹,產生過擬合,因此 LightGBM 在 Leaf-wise 之上增加了一個最大深度的限制,在保證高效率的同時防止過擬合,
 資料的數量每天都在增加,對于傳統的資料科學演算法來說,很難快速的給出結果,LightGBM的前綴‘Light’表示速度很快,LightGBM可以處理大量的資料,運行時占用很少的記憶體,另外一個理由,LightGBM為什么這么受歡迎是因為它把重點放在結果的準確率上,LightGBM還支持GPU學習,因此,資料科學家廣泛的使用LightGBM來進行資料科學應用的部署,
資料的數量每天都在增加,對于傳統的資料科學演算法來說,很難快速的給出結果,LightGBM的前綴‘Light’表示速度很快,LightGBM可以處理大量的資料,運行時占用很少的記憶體,另外一個理由,LightGBM為什么這么受歡迎是因為它把重點放在結果的準確率上,LightGBM還支持GPU學習,因此,資料科學家廣泛的使用LightGBM來進行資料科學應用的部署,
既然可以提升速度,那么它可以在小資料集上面使用嗎?
不可以!不建議在小資料集上使用LightGBM,LightGBM對過擬合很敏感,對于小資料集非常容易過擬合,對于多小屬于小資料集,并沒有什么閾值,但是從我的經驗,我建議對于10000+以上的資料的時候,再使用LightGBM,這也很明顯,因為小的資料集使用XGBoost就可以了呀,
實作LightGBM非常簡單,復雜的是引數的除錯,LightGBM有超過100個引數,但是不用擔心,你不需要所有的都學,
Histogram 演算法
直方圖演算法的基本思想是先把連續的浮點特征值離散化成k個整數,同時構造一個寬度為k的直方圖,在遍歷資料的時候,根據離散化后的值作為索引在直方圖中累積統計量,當遍歷一次資料后,直方圖累積了需要的統計量,然后根據直方圖的離散值,遍歷尋找最優的分割點,
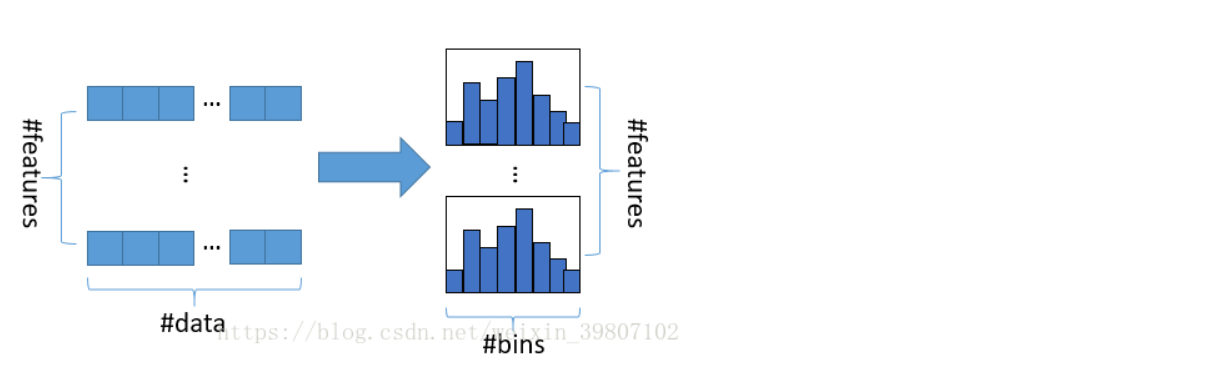
使用直方圖演算法有很多優點,首先,最明顯就是記憶體消耗的降低,直方圖演算法不僅不需要額外存盤預排序的結果,而且可以只保存特征離散化后的值,而這個值一般用 8 位整型存盤就足夠了,記憶體消耗可以降低為原來的1/8, (記憶體消耗低)

? 然后在計算上的代價也大幅降低,預排序演算法每遍歷一個特征值就需要計算一次分裂的增益,而直方圖演算法只需要計算k次(k可以認為是常數),時間復雜度從O(#data*#feature)優化到O(k*#features),
? 當然,Histogram 演算法并不是完美的,由于特征被離散化后,找到的并不是很精確的分割點,所以會對結果產生影響,但在不同的資料集上的結果表明,離散化的分割點對最終的精度影響并不是很大,甚至有時候會更好一點,
直方圖加速
? LightGBM 另一個優化是 Histogram(直方圖)做差加速,一個容易觀察到的現象:一個葉子的直方圖可以由它的父親節點的直方圖與它兄弟的直方圖做差得到,通常構造直方圖,需要遍歷該葉子上的所有資料,但直方圖做差僅需遍歷直方圖的k個桶,利用這個方法,LightGBM 可以在構造一個葉子的直方圖后,可以用非常微小的代價得到它兄弟葉子的直方圖,在速度上可以提升一倍,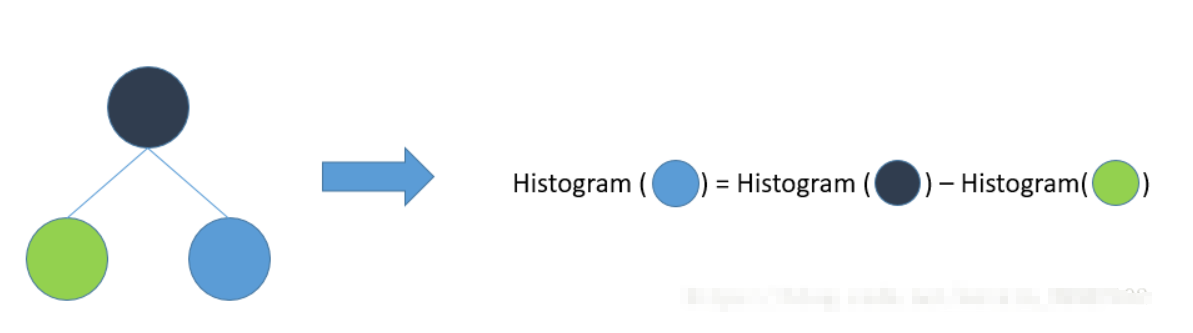
實際上大多數機器學習工具都無法直接支持類別特征,一般需要把類別特征,轉化到多維的0/1 特征,降低了空間和時間的效率,而類別特征的使用是在實踐中很常用的,基于這個考慮,LightGBM 優化了對類別特征的支持,可以直接輸入類別特征,不需要額外的0/1 展開,并在決策樹演算法上增加了類別特征的決策規則,在 Expo 資料集上的實驗,相比0/1 展開的方法,訓練速度可以加速 8 倍,并且精度一致,據我們所知,LightGBM 是第一個直接支持類別特征的 GBDT 工具,
? LightGBM 的單機版本還有很多其他細節上的優化,比如 cache 訪問優化,多執行緒優化,稀疏特征優化等等,優化匯總如下:
LightGBM并行優化
LightGBM 還具有支持高效并行的優點,LightGBM 原生支持并行學習,目前支持特征并行和資料并行的兩種,
特征并行的主要思想是在不同機器在不同的特征集合上分別尋找最優的分割點,然后在機器間同步最優的分割點,
資料并行則是讓不同的機器先在本地構造直方圖,然后進行全域的合并,最后在合并的直方圖上面尋找最優分割點,
? LightGBM 針對這兩種并行方法都做了優化:
在特征并行演算法中,通過在本地保存全部資料避免對資料切分結果的通信;
在資料并行中使用分散規約 (Reduce scatter) 把直方圖合并的任務分攤到不同的機器,降低通信和計算,并利用直方圖做差,進一步減少了一半的通信量,基于投票的資料并行則進一步優化資料并行中的通信代價,使通信代價變成常數級別,在資料量很大的時候,使用投票并行可以得到非常好的加速效果,
注意:
- 當生長相同的葉子時,Leaf-wise 比 level-wise 減少更多的損失,
- 高速,高效處理大資料,運行時需要更低的記憶體,支持 GPU
- 不要在少量資料上使用,會過擬合,建議 10,000+ 行記錄時使用,
代碼實踐
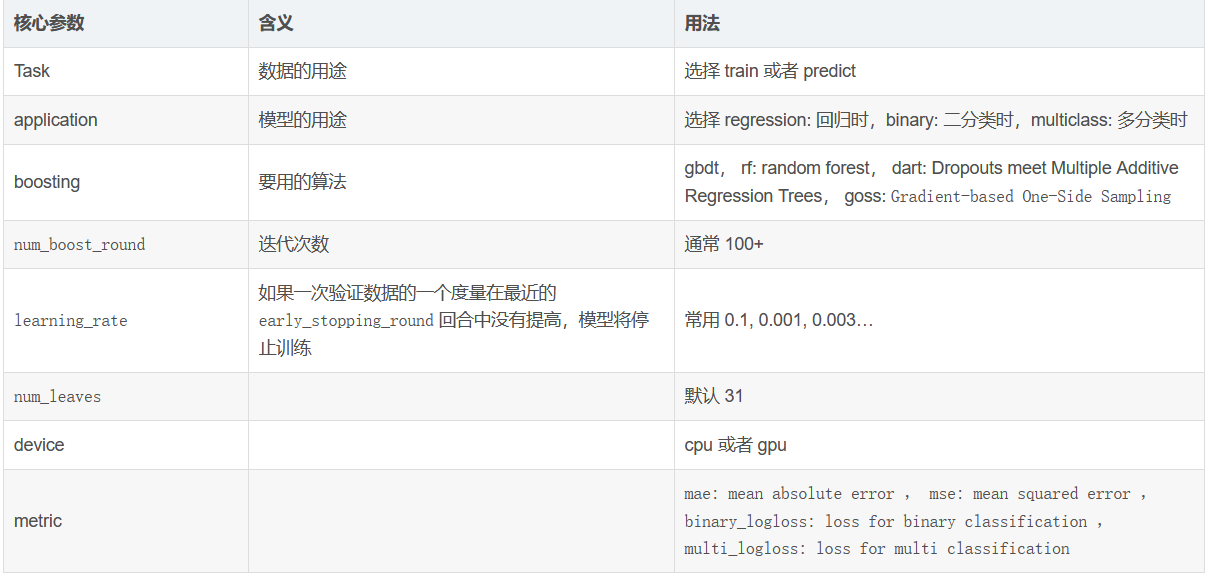
引數詳解
一下引數可以提高準確率
learning_rate:學習率.
默認值:0.1
調參策略:最開始可以設定得大一些,如0.1,調整完其他引數之后最后再將此引數調小,
取值范圍:0.01~0.3.
max_depth:樹模型深度
默認值:-1
調整策略:無
取值范圍:3-8(不超過10)
num_leaves:葉子節點數,數模型復雜度

降低過擬合
max_bin:工具箱數(葉子結點數+非葉子節點數?)
bin的最大數 決定 特征的最大組數(類似特征會被組合)
小的bin數量會降低訓練精度(accuracy),但是可能可以提高泛化性能(genreal power)
LightGBM 將根據 max_bin 自動壓縮記憶體, 例如, 如果 maxbin=255, 那么 LightGBM 將使用 uint8t 的特性值
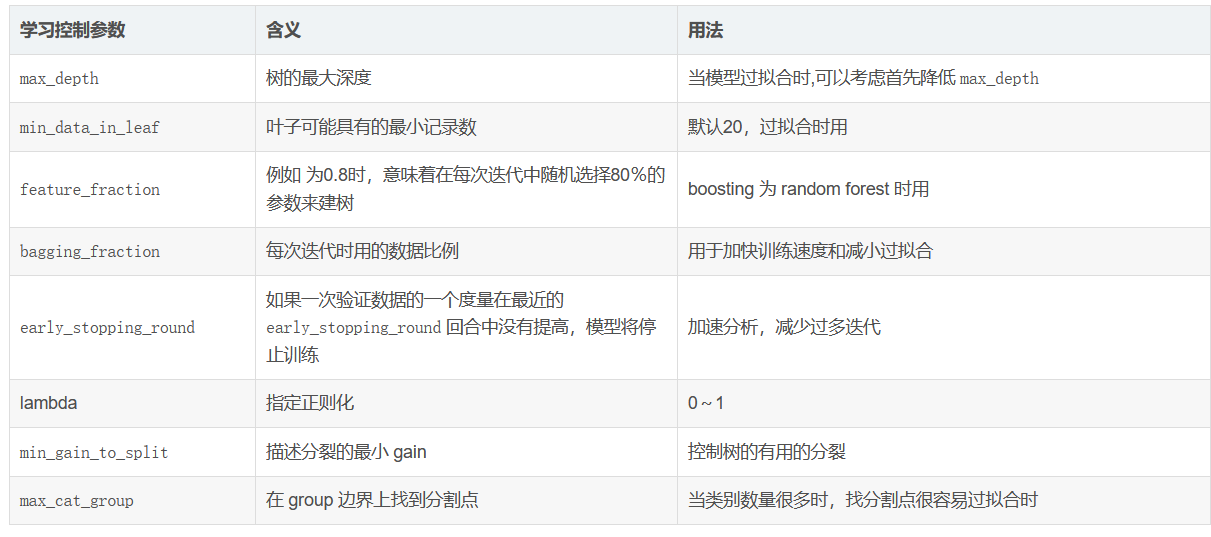
min_data_in_leaf:一個葉子上資料的最小數量. 可以用來處理過擬合
默認值:20
調參策略:搜索,盡量不要太大,
feature_fraction:每次迭代中隨機選擇特征的比例,
默認值:1.0
調參策略:0.5-0.9之間調節,
可以用來加速訓練
可以用來處理過擬合
bagging_fraction:不進行重采樣的情況下隨機選擇部分資料
默認值:1.0
調參策略:0.5-0.9之間調節,
可以用來加速訓練
可以用來處理過擬合
bagging_freq:bagging的次數,0表示禁用bagging,非零值表示執行k次bagging
默認值:0
調參策略:3-5
其他
lambda_l1:L1正則
lambda_l2:L2正則min_split_gain:執行切分的最小增益
默認值:0.1

 代碼實操
代碼實操
#匯入所需要的包
from sklearn.metrics import precision_score
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn.preprocessing import LabelEncoder
from sklearn.metrics import classification_report#評估報告
from sklearn.model_selection import cross_val_score #交叉驗證
from sklearn.model_selection import GridSearchCV #網格搜索
import matplotlib.pyplot as plt#可視化
import seaborn as sns#繪圖包
from sklearn.preprocessing import StandardScaler,MinMaxScaler,MaxAbsScaler#歸一化,標準化
# 忽略警告
import warnings
warnings.filterwarnings("ignore")
from sklearn.metrics import precision_score
import lightgbm as lgb 最優模型及引數(資料集1000)
有的小伙伴會有疑問,咋我們的lightGBM效果沒有XGBoost好呀,原因出在我們的資料上,因為這個是一個小的資料集,效果可以達到這個,完全是不斷迭代優化引數的效果,
df=pd.read_csv(r"資料.csv")
X=df.iloc[:,:-1]
y=df.iloc[:,-1]
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.2,stratify=y,random_state=1)
model=lgb.LGBMClassifier(n_estimators=39,max_depth=8,num_leaves=12,max_bin=7,min_data_in_leaf=10,bagging_fraction=0.5,
feature_fraction=0.59,boosting_type="gbdt",application="binary",min_split_gain=0.15,
n_jobs=-1,bagging_freq=30,lambda_l1=1e-05,lambda_l2=1e-05,learning_rate=0.1,
random_state=90)
model.fit(X_train,y_train)
# 預測值
y_pred = model.predict(X_test)
'''
評估指標
'''
# # 求出預測和真實一樣的數目
true = np.sum(y_pred == y_test )
print('預測對的結果數目為:', true)
print('預測錯的的結果數目為:', y_test.shape[0]-true)
# 評估指標
from sklearn.metrics import accuracy_score,precision_score,recall_score,f1_score,cohen_kappa_score
print('預測資料的準確率為: {:.4}%'.format(accuracy_score(y_test,y_pred)*100))
print('預測資料的精確率為:{:.4}%'.format(
precision_score(y_test,y_pred)*100))
print('預測資料的召回率為:{:.4}%'.format(
recall_score(y_test,y_pred)*100))
# print("訓練資料的F1值為:", f1score_train)
print('預測資料的F1值為:',
f1_score(y_test,y_pred))
print('預測資料的Cohen’s Kappa系數為:',
cohen_kappa_score(y_test,y_pred))
# 列印分類報告
print('預測資料的分類報告為:','\n',
classification_report(y_test,y_pred))
# ROC曲線、AUC
from sklearn.metrics import precision_recall_curve
from sklearn import metrics
# 預測正例的概率
y_pred_prob=model.predict_proba(X_test)[:,1]
# y_pred_prob ,回傳兩列,第一列代表類別0,第二列代表類別1的概率
#https://blog.csdn.net/dream6104/article/details/89218239
fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred_prob, pos_label=2)
#pos_label,代表真陽性標簽,就是說是分類里面的好的標簽,這個要看你的特征目標標簽是0,1,還是1,2
roc_auc = metrics.auc(fpr, tpr) #auc為Roc曲線下的面積
# print(roc_auc)
plt.figure(figsize=(8,6))
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.plot(fpr, tpr, 'r',label='AUC = %0.2f'% roc_auc)
plt.legend(loc='lower right')
# plt.plot([0, 1], [0, 1], 'r--')
plt.xlim([0, 1.1])
plt.ylim([0, 1.1])
plt.xlabel('False Positive Rate') #橫坐標是fpr
plt.ylabel('True Positive Rate') #縱坐標是tpr
plt.title('Receiver operating characteristic example')
plt.show()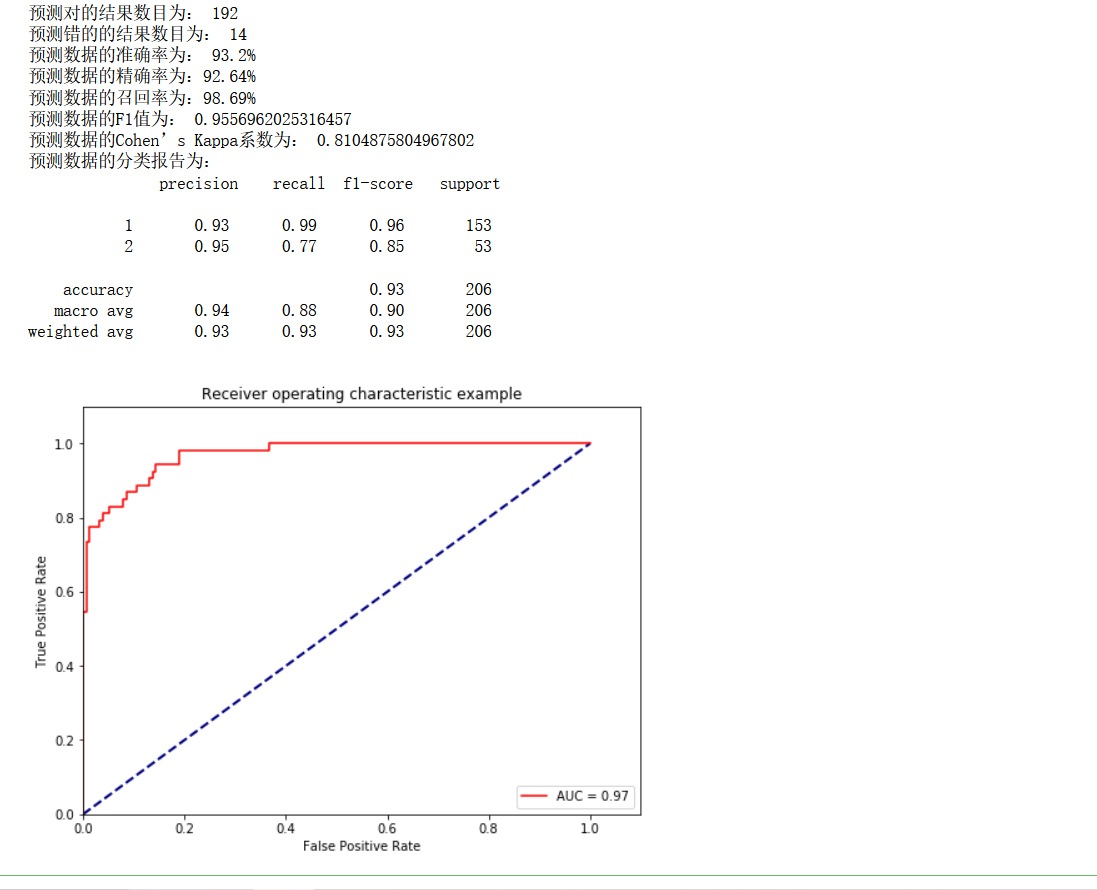
模型調參
嘗試學習曲線進行調參
初始化我們的引數,也可以通過在訓練集上的網格搜索確定大致的引數位置,然后利用學習曲線去迭代最佳的引數
model=lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.01, n_estimators=39, max_depth=4,
num_leaves=12,max_bin=15,min_data_in_leaf=11,bagging_fraction=0.8,bagging_freq=20, feature_fraction= 0.7,
lambda_l1=1e-05,lambda_l2=1e-05,min_split_gain=0.5)例如:
params_test5={'min_split_gain':[0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0]}
gsearch5 = GridSearchCV(estimator = lgb.LGBMClassifier(boosting_type='gbdt',objective='binary',metrics='auc',learning_rate=0.01,
n_estimators=1000, max_depth=4, num_leaves=12,max_bin=15,min_data_in_leaf=11,
bagging_fraction=0.8,bagging_freq=20, feature_fraction= 0.7,
lambda_l1=1e-05,lambda_l2=1e-05,min_split_gain=0.5),
param_grid = params_test5, scoring='roc_auc',cv=5)
gsearch5.fit(X_train,y_train)
gsearch5.best_params_, gsearch5.best_score_學習曲線
scorel = []
for i in range(0,200,10):
model = lgb.LGBMClassifier(n_estimators=i+1,random_state=2022).fit(X_train,y_train)
score = model.score(X_test,y_test)
scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1) #作圖反映出準確度隨著估計器數量的變化,110的附近最好
plt.figure(figsize=[20,5])
plt.plot(range(1,200,10),scorel)
plt.show()
## 根據上面的顯示最優點在51附近,進一步細化學習曲線
scorel = []
for i in range(35,45):
RFC = lgb.LGBMClassifier(n_estimators=i,
n_jobs=-1,
random_state=90).fit(X_train,y_train)
score = RFC.score(X_test,y_test)
scorel.append(score)
print(max(scorel),([*range(35,45)][scorel.index(max(scorel))])) #112是最優的估計器數量 #最優得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(range(35,45),scorel)
plt.show()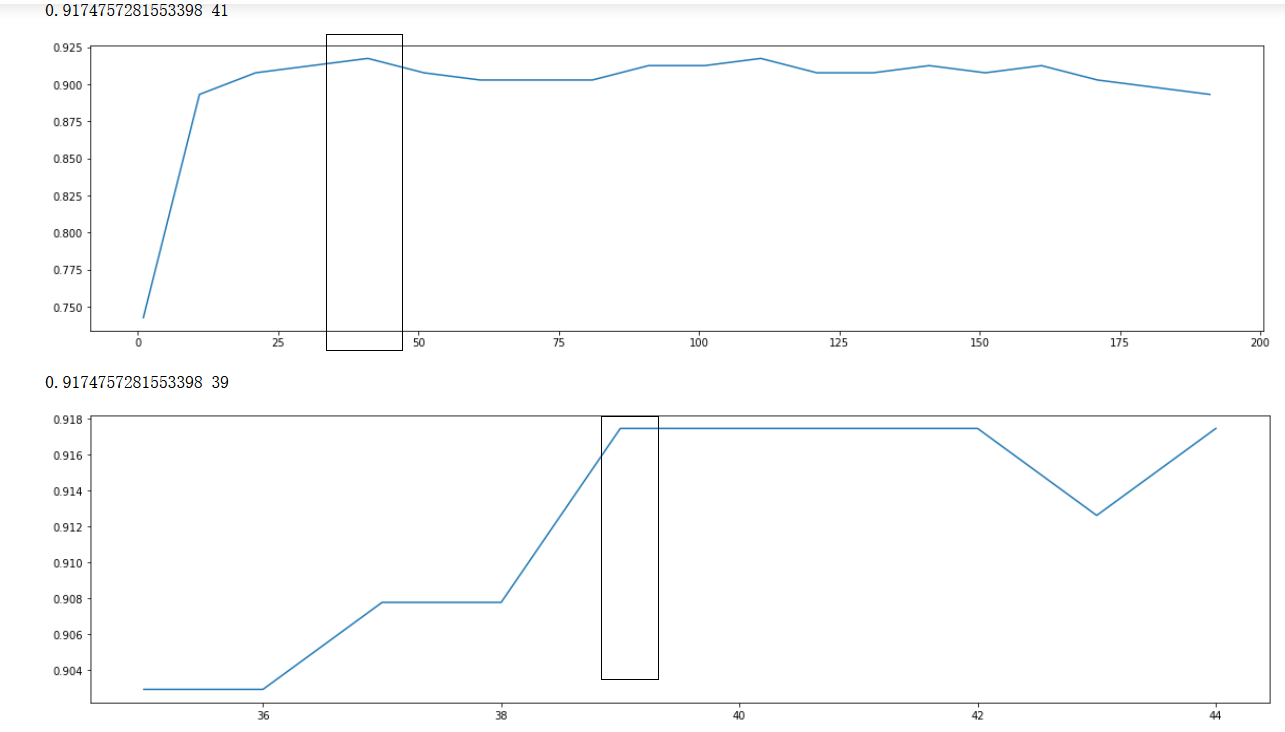
max_depth
scorel = []
for i in range(3,20):
RFC = lgb.LGBMClassifier(n_estimators=39,max_depth=i,
n_jobs=-1,
random_state=90).fit(X_train,y_train)
score = RFC.score(X_test,y_test)
scorel.append(score)
print(max(scorel),([*range(3,20)][scorel.index(max(scorel))])) #112是最優的估計器數量 #最優得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(range(3,20),scorel)
plt.show()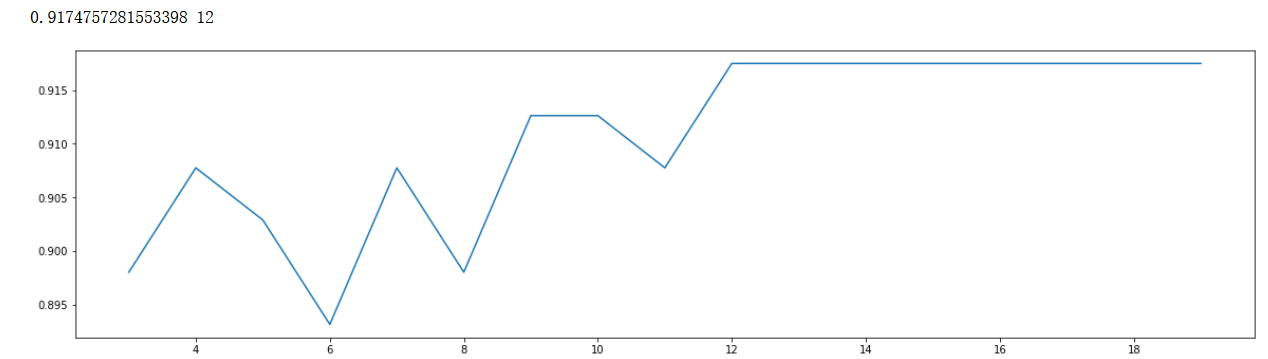
整數區間引數調優(手動修改即可)
scorel = []
for i in np.arange(7,45,1):
RFC = lgb.LGBMClassifier(n_estimators=39,max_depth=8,num_leaves=12,max_bin=7,min_data_in_leaf=10,bagging_fraction=0.5,feature_fraction=0.6,
n_jobs=-1,bagging_freq=30,
random_state=90).fit(X_train,y_train)
score = RFC.score(X_test,y_test)
scorel.append(score)
print(max(scorel),([*np.arange(7,45,1)][scorel.index(max(scorel))])) #112是最優的估計器數量 #最優得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(np.arange(7,45,1),scorel)
plt.show()
# num_leaves=12,max_bin=15,min_data_in_leaf=11,bagging_fraction=0.8,bagging_freq=20, feature_fraction= 0.7,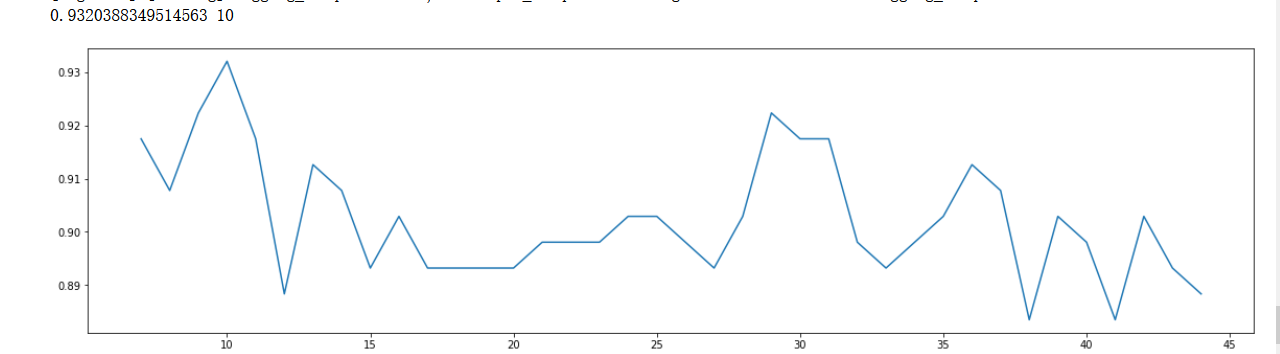
浮點數引數(手動修改)
scorel = []
for i in np.arange(0.01,1,0.01):
RFC = lgb.LGBMClassifier(n_estimators=39,max_depth=8,num_leaves=12,max_bin=7,min_data_in_leaf=10,bagging_fraction=0.5,
feature_fraction=0.59,min_split_gain=i,
n_jobs=-1,bagging_freq=30,
random_state=90).fit(X_train,y_train)
score = RFC.score(X_test,y_test)
scorel.append(score)
print(max(scorel),([*np.arange(0.01,1,0.01)][scorel.index(max(scorel))])) #112是最優的估計器數量 #最優得分是0.98945
plt.figure(figsize=[20,5])
plt.plot(np.arange(0.01,1,0.01),scorel)
plt.show()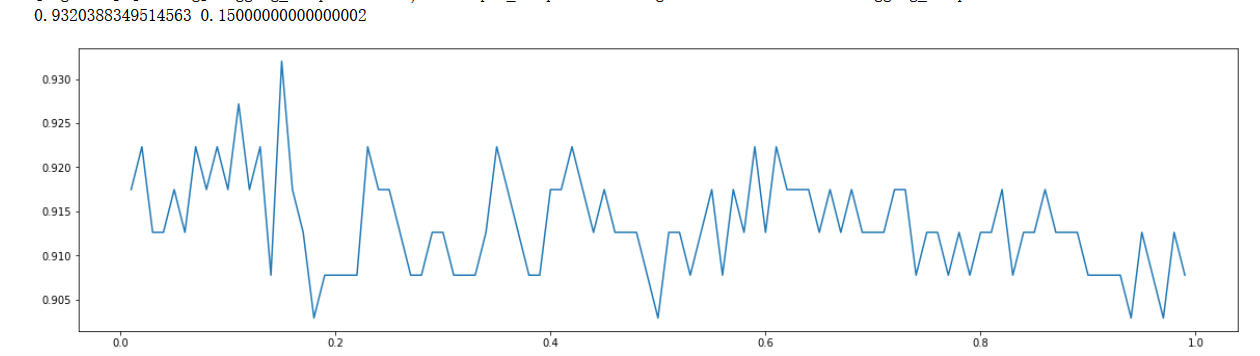
寫到最后:
該演算法所使用的場景一定要記住,在資料量大的情況下
每文一語
每天都要加油呀!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426509.html
標籤:AI
下一篇:22/02/17學習筆記