知識回顧
###(1)hadoop簡介
資料存盤與資料計算
hdfs :通過分布式檔案存盤對資料進行存盤;
MapReduce:通過MapReduce進行資料的計算;
(2)hadoop生態圈簡介
實時數倉:
spark 、 kafka等等
離線數倉:
hdfs 、 MapReduce 、 sqoop 、 hive等工具
(3)關系型資料庫與非關系型資料庫
關系型資料庫:傳統的資料庫,Oracle、MySQL等等;
非關系型資料庫:HBASE 、 Redis等等
- 注:非關系型資料庫中存盤資料本來沒有任何關系,在使用之前需要通過Java等語言進行關系建立再對資料進行操作;
(4)HDFS中一些簡單的操作陳述句
a.增
b.刪
c.改
d.查
e.關閉安全模式
d.從主機上傳檔案到hdfs
一、HIVE簡單介紹
HIVE - 建立數倉的一種工具,數倉引擎
hdfs MapReduce sqoop hive
作業原理:
sqoop 會將資料匯入到hdfs中進行存盤,任何MapReduce 對hdfs中存盤的資料進行計算,但MapReduce中使用的是Java語言,而我們就可以通過hive通過hivesql語言在hive中編譯好之后,通過hadoop生態圈將hivesql轉換為MapReduce程式;
二、啟動hive
1. 存放元資料的地方

要了解標題中的意思,就得先了解什么是元資料
- 元資料:用于描述資料的資料(相當于Oracle的欄位名)
這些元資料由MySQL來存放;
2.啟動hadoop
3.啟動hive
hive 在/opt/moudle/檔案下的apache-hive-2.1.1-bin目錄之下;
4.hive的一些基本操作
4.1 查看資料庫
show databases
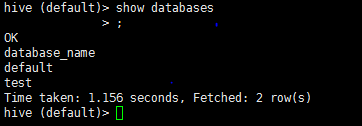
查出來兩個資料庫,一個default和一個test;
4.2 查看表
show tables
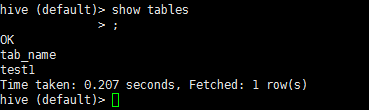
上面是我上午建的一個test1表
4.3 使用(選擇)資料庫
use default #對應的資料庫名
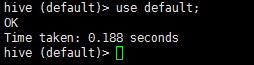
4.4 創建表
在hive中可以直接使用類SQL語言(MySQL)進行表的創建操作,如下所示:

再通過show tables命令查看表是否創建成功,如下所示:
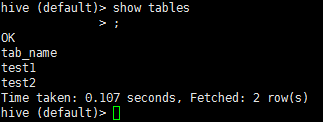
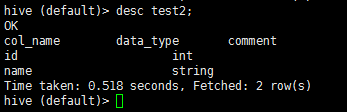
上面明顯可以看到我們創建的test2表已經被創建,我們還可以通過desc test2 #目標表名指令查看目標表結構:
4.5 創建資料庫
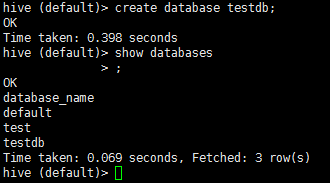
create database testdb #要創建的資料庫名
創建后并查看的結果:
4.6 表的查詢與資料插入
查詢表:
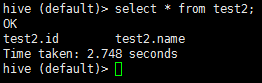
原先創建的表test2中沒有資料,下面我們試著向其中插入資料后再進行查詢:
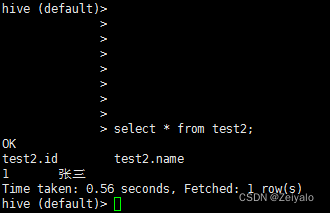
hive中的沒有delete和update陳述句;
4.7 在hdfs上運行hive中的陳述句及運行檔案
hive -e "select * from t5" #雙引號中加上需要運行的陳述句
hive -f './test5' #單引號中加上需要運行檔案的路徑
示例:創建一個學生表,里面包含學生ID(s_id)、學生姓名(s_name)、學生性別(s_sex);
建立資料檔案stu_data(資料間使用Tab鍵進行分割):
1 張三 男
2 李四 男
3 王菲 女
4 劉玥 女
5 劉墉 男
6 黃輝馮 男
7 陳美嘉 女
8 胡一菲 不詳
9 張偉 男
10 曾小賢 男
11 呂子喬 男
12 陸展博 男
13 林宛瑜 女
14 唐悠悠 女
15 秦羽墨 女
16 關谷神奇 男
17 大師兄 男
18 樓下小黑 男
建立建表檔案c_stu_table(檔案中限定使用Tab鍵作為分隔符):
create table stu_table (s_id int ,s_name string ,s_sex string)
row format delimited
fields terminated by '\t';
使用hive -f './c_stu_table'創建表stu_table;
然后使用hive -e "select * from stu_table"檢查一下表是否被創建:

表創建成功,下面進行資料上傳操作,代碼如下
hive -e "load data local inpath'./stu_data'into table stu_table"
運行完上訴代碼后驗證一下表中資料是否以及上傳進去:
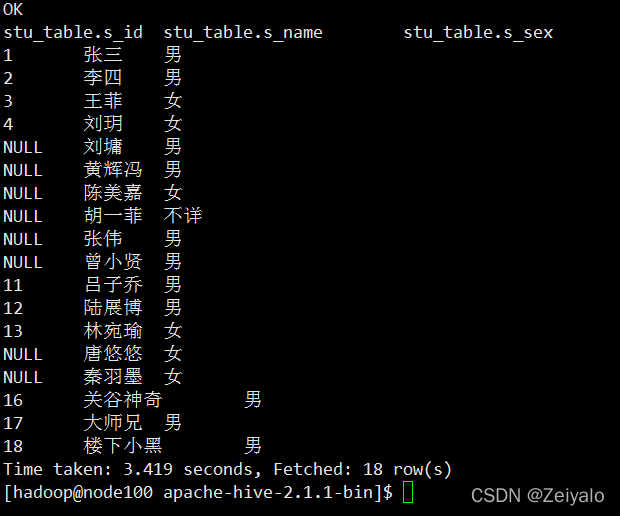
OK
題目完成;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426512.html
標籤:其他