目錄
- 1. Elasticsearch是什么
- 1.1 Elasticsearch簡介
- 1.2 全文搜索引擎
- 1.3 Elasticsearch VS Solr
- 1.5 Elasticsearch應用案例
- 2. Elasticsearch入門
- 2.1 Elasticsearch安裝
- 2.1.1 下載軟體
- 2.1.2 安裝軟體
- 2.1.3 問題解決
- 2.2 核心概念
- 2.2.1 索引(Index)
- 2.2.2 型別(Type)
- 2.2.3 檔案(Document)
- 2.2.4 欄位(Field)
- 2.2.5 映射(Mapping)
- 2.2.6 分片(Shards)
- 2.2.7 副本(Replicas)
- 2.2.8 分配(Allocation)
- 2.3 Elasticsearch核心概念 VS 資料庫核心概念
- 2.4 系統架構
1. Elasticsearch是什么
1.1 Elasticsearch簡介

??Elaticsearch,簡稱為 ES, ES 是一個開源的高擴展的分布式全文搜索引擎,是整個 Elastic Stack 技術堆疊的核心,它可以近乎實時的存盤、檢索資料;本身擴展性很好,可以擴展到上百臺服務器,處理 PB 級別的資料, ES 也使用 Java 開發并使用 Lucene 作為其核心來實作所有索引和搜索的功能,但是它的目的是通過簡單的 RESTful API 來隱藏 Lucene 的復雜性,從而讓全文搜索變得簡單,
1.2 全文搜索引擎
??Google,百度類的網站搜索,它們都是根據網頁中的關鍵字生成索引,我們在搜索的時候輸入關鍵字,它們會將該關鍵字即索引匹配到的所有網頁回傳;還有常見的專案中應用日志的搜索等等,對于這些非結構化的資料文本,關系型資料庫搜索不是能很好的支持,
??一般傳統資料庫,全文檢索都實作的很雞肋,因為一般也沒人用資料庫存文本欄位,進行全文檢索需要掃描整個表,如果資料量大的話即使對 SQL 的語法優化,也收效甚微,建立了索引,但是維護起來也很麻煩,對于 insert 和 update 操作都會重新構建索引,
??基于以上原因可以分析得出,在一些生產環境中,使用常規的搜索方式,性能是非常差的:
- 搜索的資料物件是大量的非結構化的文本資料;
- 檔案記錄量達到數十萬或數百萬個甚至更多;
- 支持大量基于互動式文本的查詢;
- 需求非常靈活的全文搜索查詢;
- 對高度相關的搜索結果的有特殊需求,但是沒有可用的關系資料庫可以滿足;
- 對不同記錄型別、非文本資料操作或安全事務處理的需求相對較少的情況;
??為了解決結構化資料搜索和非結構化資料搜索性能問題,我們就需要專業,健壯,強大的全文搜索引擎,
??這里說到的全文搜索引擎指的是目前廣泛應用的主流搜索引擎,它的作業原理是計算機索引程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程式就根據事先建立的索引進行查找,并將查找的結果反饋給用戶的檢索方式,這個程序類似于通過字典中的檢索字表查字的程序,
1.3 Elasticsearch VS Solr
??Lucene 是 Apache 軟體基金會 Jakarta 專案組的一個子專案,提供了一個簡單卻強大的應用程式介面,能夠做全文索引和搜尋,在 Java 開發環境里 Lucene 是一個成熟的免費開源工具,就其本身而言,Lucene 是當前以及最近幾年最受歡迎的免費 Java 資訊檢索程式庫,但 Lucene 只是一個提供全文搜索功能類別庫的核心工具包,而真正使用它還需要一個完善的服務框架搭建起來進行應用,
??目前市面上流行的搜索引擎軟體,主流的就兩款:Elasticsearch 和 Solr,這兩款都是基于 Lucene 搭建的,可以獨立部署啟動的搜索引擎服務軟體,由于內核相同,所以兩者除了服務器安裝、部署、管理、集群以外,對于資料的操作 修改、添加、保存、查詢等等都十分類似,
??在使用程序中,一般都會將 Elasticsearch 和 Solr 這兩個軟體對比,然后進行選型,這兩個搜索引擎都是流行的,先進的的開源搜索引擎,它們都是圍繞核心底層搜索庫 Lucene 構建的,但它們又是不同的,像所有東西一樣,每個都有其優點和缺點:
| 特征 | Solr/SolrCloud | Elasticsearch |
|---|---|---|
| 社區和開發者 | Apache 軟體基金和社區支持 | 單一商業物體及其員工 |
| 節點發現 | Apache Zookeeper,在大量專案中成熟且經過實戰測驗 | Zen 內置于 Elasticsearch 本身,需要專用的主節點才能進行分裂腦保護 |
| 碎片放置 | 本質上是靜態,需要手動作業來遷移分片,從 Solr 7 開始 Autoscaling API 允許一些動態操作 | 動態,可以根據群集狀態按需移動分片 |
| 高速快取 | 全域,每個段更改無效 | 每段,更適合動態更改資料 |
| 分析引擎性能 | 非常適合精確計算的靜態資料 | 結果的準確性取決于資料放置 |
| 全文搜索功能 | 基于 Lucene 的語言分析,多建議,拼寫檢查,豐富的高亮顯示支持 | 基于 Lucene 的語言分析,單一建議 API 實作,高亮顯示重新計算 |
| DevOps 支持 | 尚未完全,但即將到來 | 非常好的 API |
| 非平面資料處理 | 嵌套檔案和父子支持 | 嵌套和物件型別的自然支持允許幾乎無限的嵌套和父子支持 |
| 查詢 DSL | JSON (有限),XML (有限)或URL引數 | JSON |
| 索引/收集領導控制 | 領導者安置控制和領導者重新平衡甚至可以節點上的負載 | 不可能 |
| 機器學習 | 內置在流聚合之上,專注于邏輯回歸和學習排名貢獻模塊 | 商業功能,專注于例外和例外值以及時間序列資料 |
??Elasticsearch 和 Solr 都是開源搜索引擎,那么我們在使用時該如何選擇呢?
- Google 搜索趨勢結果表明,與 Solr 相比,Elasticsearch 具有很大的吸引力,但這并不意味著 Apache Solr 已經死亡,雖然有些人可能不這么認為,但 Solr 仍然是最受歡迎的搜索引擎之一,擁有強大的社區和開源支持,
- 與 Solr 相比,Elasticsearch 易于安裝且非常輕巧,此外,可以在幾分鐘內安裝并運行 Elasticsearch,但是,如果 Elasticsearch 管理不當,這種易于部署和使用可能會成為一個問題,基于 JSON 的配置很簡單,但如果要為檔案中的每個配置指定注釋,那么它不適合我們,總的來說,如果我們的應用使用的是 JSON,那么 Elasticsearch 是一個更好的選擇,否則,請使用 Solr,因為它的 schema.xml 和 solrconfig.xml 都有很好的檔案記錄,
- Solr 擁有更大,更成熟的用戶,開發者和貢獻者社區,ES 雖擁有的規模較小但活躍的用戶社區以及不斷增長的貢獻者社區,Solr 貢獻者和提交者來自許多不同的組織,而 Elasticsearch 提交者來自單個公司,
- Solr 更成熟,但 ES 增長迅速,更穩定,
- Solr 是一個非常有據可查的產品,具有清晰的示例和 API 用例場景, Elasticsearch 的檔案組織良好,但它缺乏好的示例和清晰的配置說明,
??那么,到底是 Solr 還是 Elasticsearch?
??有時很難找到明確的答案,無論我們選擇 Solr 還是 Elasticsearch,首先需要了解正確的用例和未來需求,總結他們的每個屬性,
- 由于易于使用,Elasticsearch 在新開發者中更受歡迎,一個下載和一個命令就可以啟動一切;
- 如果除了搜索文本之外還需要它來處理分析查詢,Elasticsearch 是更好的選擇;
- 隨著資料量的增加,Solr 的搜索效率會變得更低,而 ElasticSearch 卻沒有明顯的變化;
- Solr 利用 Zookeeper 進行分布式管理,而 Elasticsearch 自身帶有分布式協調管理功能;
- Solr 支持更多格式的資料,比如 JSON、XML、CSV,而 Elasticsearch 僅支持 Json 檔案格式;
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高級功能多有第三方插件提供,例如圖形化界面需要 Kibana 友好支撐;
- 單純的對已有資料進行搜索時,Solr 更快,但更新索引時慢(即插入洗掉慢),用于電商等查詢多的應用;
- ES 建立索引快(即查詢慢),即實時性查詢快,用于 facebook、新浪等搜索,
- 如果需要分布式索引,則需要選擇 Elasticsearch,對于需要良好可伸縮性和以及性能分布式環境,Elasticsearch 是更好的選擇;
- Solr 是傳統搜索應用的有力解決方案,但 Elasticsearch 更適用于新興的實時搜索應用;
- Solr 比較成熟,有一個更大,更成熟的用戶、開發和貢獻者社區,而 Elasticsearch 相對開發維護者較少,更新太快,學習使用成本較高;
- 如果你喜歡監控和指標,那么可以使用 Elasticsearch,因為相對于 Solr,Elasticsearch 暴露了更多的關鍵指標,
1.5 Elasticsearch應用案例
- GitHub:2013 年初,拋棄了 Solr,采取 Elasticsearch 來做 PB 級的搜索,GitHub 使用 Elasticsearch 搜索 20TB 的資料,包括 13 億檔案和 1300 億行代碼,
- 維基百科:啟動以 Elasticsearch 為基礎的核心搜索架構 ,
- SoundCloud:SoundCloud 使用 Elasticsearch 為 1.8 億用戶提供即時而精準的音樂搜索服務,
- 百度:目前廣泛使用 Elasticsearch 作為文本資料分析,采集百度所有服務器上的各類指標資料及用戶自定義資料,通過對各種資料進行多維分析展示,輔助定位分析實體例外或業務層面例外,目前覆寫百度內部 20 多個業務線(包括云分析、網盟、預測、文庫、直達號、錢包、風控等),單集群最大 100 臺機器,200 個 ES 節點,每天匯入 30TB+ 資料,
- 新浪:使用 Elasticsearch 分析處理 32 億條實時日志,
- 阿里:使用 Elasticsearch 構建日志采集和分析體系,
- Stack Overflow:解決 Bug 問題的網站,全英文,編程人員交流的網站,
2. Elasticsearch入門
2.1 Elasticsearch安裝
2.1.1 下載軟體
??Elasticsearch 的官方地址:https://www.elastic.co/cn/
??Elasticsearch 目前最新的版本是 8.0.0,我們選擇 7.17.0 版本(最好不要選最新的版本)
??下載地址:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
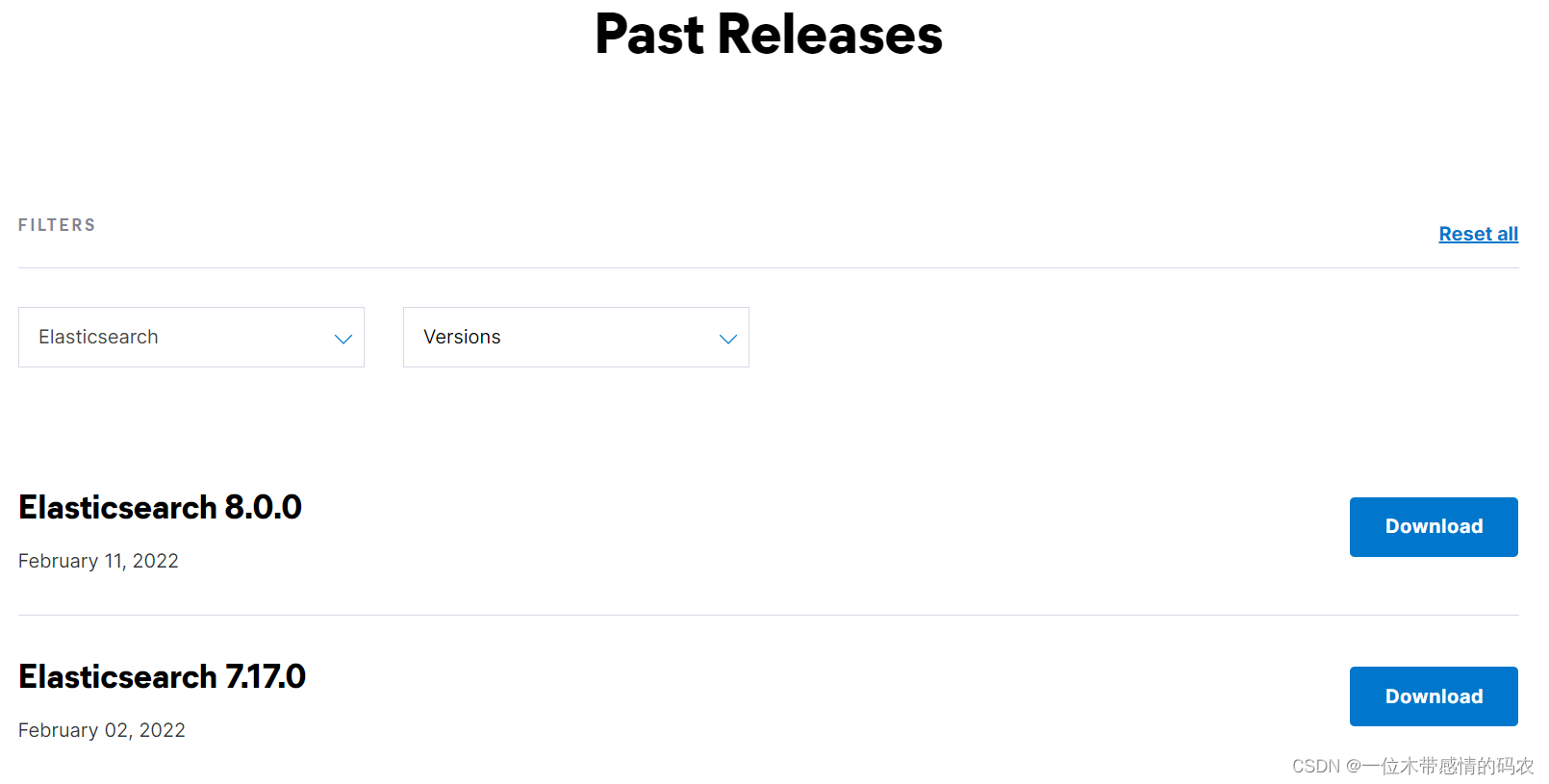
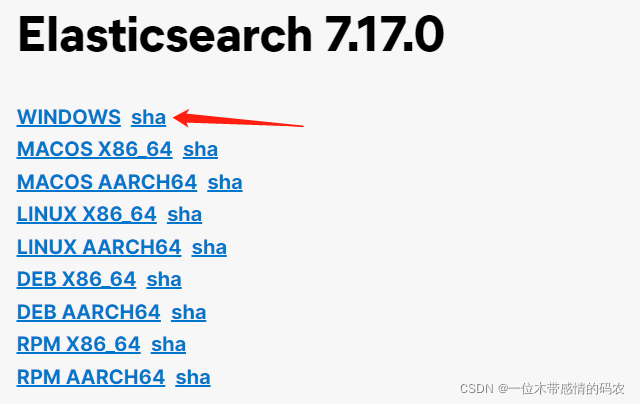
??Elasticsearch 分為 Linux 和 Windows 版本,基于我們主要學習的是 Elasticsearch 的 Java 客戶端的使用,所以課程中使用的是安裝較為簡便的 Windows 版本(后續再單獨開一篇博客詳細說 Linux 的部署教程),
2.1.2 安裝軟體
??Windows 版的 Elasticsearch 的安裝很簡單,解壓即安裝完畢,解壓后的 Elasticsearch 的目錄結構如下:
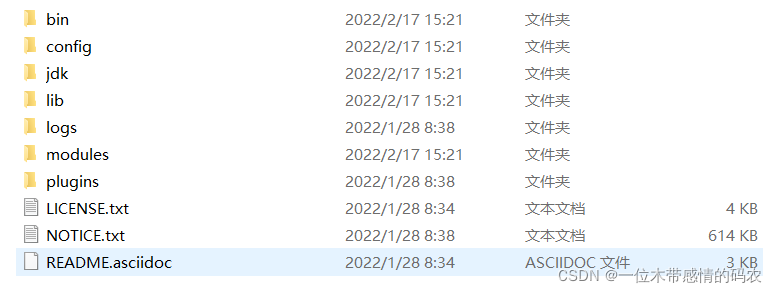
| 目錄 | 含義 |
|---|---|
| bin | 可執行腳本目錄 |
| config | 配置目錄 |
| jdk | 內置 JDK 目錄 |
| lib | 類別庫 |
| logs | 日志目錄 |
| modules | 模塊目錄 |
| plugins | 插件目錄 |
??解壓后,進入bin檔案目錄,點擊elasticsearch.bat檔案啟動 ES 服務:
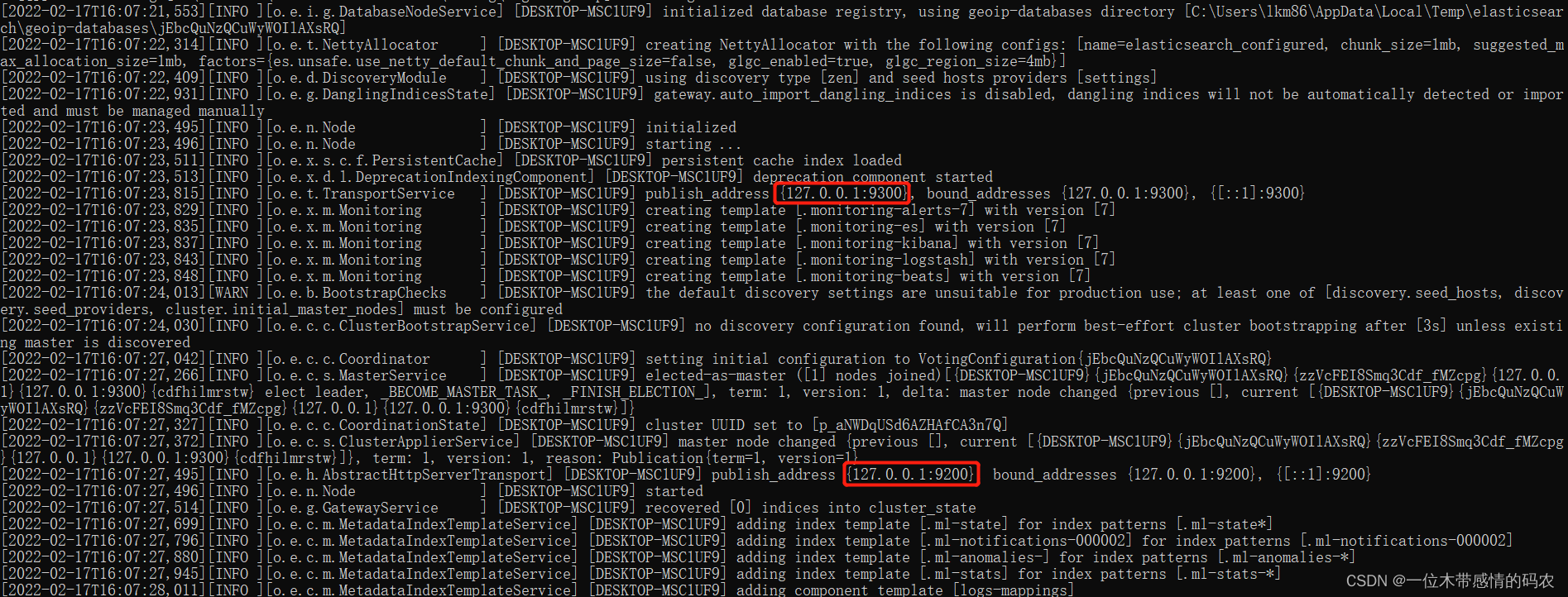
??注意:9300埠為 Elasticsearch 集群間組件的通信埠,9200埠為瀏覽器訪問的 http 協議 RESTful 埠,
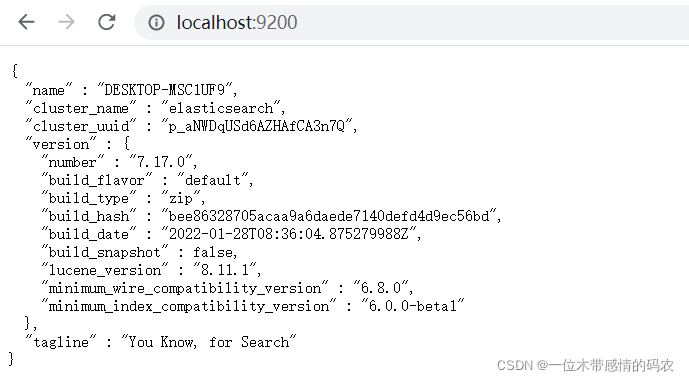
??打開瀏覽器(推薦使用谷歌瀏覽器),輸入地址:http://localhost:9200,測驗結果:
2.1.3 問題解決
- Elasticsearch 是使用 java 開發的,且 7.11 版本的 ES 需要 JDK 版本 1.8 以上,默認安裝包帶有 jdk 環境,如果系統配置 JAVA_HOME,那么使用系統默認的 JDK,如果沒有配置使用自帶的 JDK,一般建議使用系統配置的 JDK,
- 雙擊啟動視窗閃退,通過路徑訪問追蹤錯誤,如果是 “空間不足”,請修改 config/jvm.options 組態檔,添加以下內容:
# 設定JVM初始記憶體為1G,此值可以設定與-Xmx相同,以避免每次垃圾回收完成后JVM重新分配記憶體
# Xms represents the initial size of total heap space
# 設定JVM最大可用記憶體為1G
# Xmx represents the maximum size of total heap space
-Xms1g
-Xmx1g
??如果本地 JDK 版本不夠高,可以手動指定使用自帶高版本 JDK,在bin目錄下找到elasticsearch-env.bat并打開,加入我們 ES 本身自帶的 jdk 路徑:
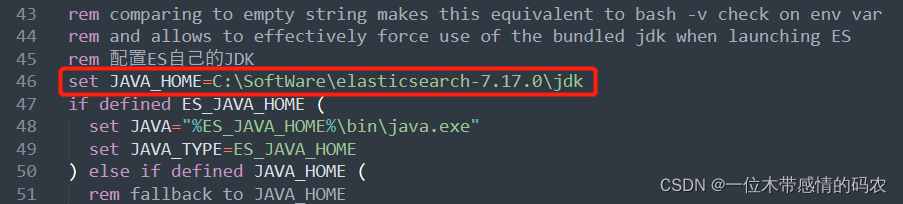
??保存后重新執行elasticsearch.bat即可,
2.2 核心概念
2.2.1 索引(Index)
??一個索引就是一個擁有幾分相似特征的檔案的集合,比如說,我們可以有一個客戶資料的索引,另一個產品目錄的索引,還有一個訂單資料的索引,一個索引由一個名字來標識(必須全部是小寫字母),并且當我們要對這個索引中的檔案進行索引、搜索、更新和洗掉的時候,都要使用到這個名字,在一個集群中,可以定義任意多的索引,
??能搜索的資料必須索引,這樣的好處是可以提高查詢速度,比如:新華字典前面的目錄就是索引的意思,目錄可以提高查詢速度,
??Elasticsearch 索引的精髓:一切設計都是為了提高搜索的性能,
2.2.2 型別(Type)
??在一個索引中,我們可以定義一種或多種型別,
??一個型別是我們索引的一個邏輯上的分類/磁區,其語意完全由我們自己來定,通常,會為具有一組共同欄位的檔案定義一個型別,不同的版本,型別發生了不同的變化,
| 版本 | Type |
|---|---|
| 5.x | 支持多種 type |
| 6.x | 只能有一種 type |
| 7.x | 默認不再支持自定義索引型別(默認型別為:_doc) |
2.2.3 檔案(Document)
??一個檔案是一個可被索引的基礎資訊單元,也就是一條資料
??比如:我們可以擁有某一個客戶的檔案,某一個產品的一個檔案,當然,也可以擁有某個訂單的一個檔案,檔案以 JSON(Javascript Object Notation)格式來表示,而 JSON 是一個到處存在的互聯網資料互動格式,
??在一個 index/type 里面,我們可以存盤任意多的檔案,
2.2.4 欄位(Field)
??相當于是資料表的欄位,對檔案資料根據不同屬性進行的分類標識,
2.2.5 映射(Mapping)
??mapping 是處理資料的方式和規則方面做一些限制,如:某個欄位的資料型別、默認值、分析器、是否被索引等等,這些都是映射里面可以設定的,其它就是處理 ES 里面資料的一些使用規則設定也叫做映射,按著最優規則處理資料對性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能對性能更好,
2.2.6 分片(Shards)
??一個索引可以存盤超出單個節點硬體限制的大量資料,比如,一個具有 10 億檔案資料的索引占據 1TB 的磁盤空間,而任一節點都可能沒有這樣大的磁盤空間,或者單個節點處理搜索請求,回應太慢,為了解決這個問題,Elasticsearch 提供了將索引劃分成多份的能力,每一份就稱之為分片,當我們創建一個索引的時候,我們可以指定自己想要的分片的數量,每個分片本身也是一個功能完善并且獨立的 “索引”,這個 “索引” 可以被放置到集群中的任何節點上,
??分片很重要,主要有兩方面的原因:
- 允許我們水平分割 / 擴展自己的內容容量,
- 允許我們在分片之上進行分布式的、并行的操作,進而提高性能/吞吐量,
??至于一個分片怎樣分布,它的檔案怎樣聚合和搜索請求,是完全由 Elasticsearch 管理的,對于作為用戶的我們來說,這些都是透明的,無需過分關心,
??被混淆的概念是,一個 Lucene 索引 我們在 Elasticsearch 稱作分片 , 一個 Elasticsearch 索引是分片的集合, 當 Elasticsearch 在索引中搜索的時候,他發送查詢到每一個屬于索引的分片(Lucene 索引),然后合并每個分片的結果到一個全域的結果集,
2.2.7 副本(Replicas)
??在一個網路 / 云的環境里,失敗隨時都可能發生,在某個分片/節點不知怎么的就處于離線狀態,或者由于任何原因消失了,這種情況下,有一個故障轉移機制是非常有用并且是強烈推薦的,為此目的,Elasticsearch 允許我們創建分片的一份或多份拷貝,這些拷貝叫做復制分片(副本),
??復制分片之所以重要,有兩個主要原因:
- 在分片/節點失敗的情況下,提供了高可用性,因為這個原因,注意到復制分片從不與原/主要(original/primary)分片置于同一節點上是非常重要的,
- 擴展我們的搜索量/吞吐量,因為搜索可以在所有的副本上并行運行,總之,每個索引可以被分成多個分片,一個索引也可以被復制 0 次(意思是沒有復制)或多次,一旦復制了,每個索引就有了主分片(作為復制源的原來的分片)和復制分片(主分片的拷貝)之別,分片和復制的數量可以在索引創建的時候指定,在索引創建之后,我們可以在任何時候動態地改變復制的數量,但是我們事后不能改變分片的數量,默認情況下, Elasticsearch 中的每個索引被分片 1 個主分片和 1 個復制,這意味著,如果我們的集群中至少有兩個節點,我們的索引將會有 1 個主分片和另外 1 個復制分片(1 個完全拷貝),這樣的話每個索引總共就有 2 個分片,我們需要根據索引需要確定分片個數,
2.2.8 分配(Allocation)
??將分片分配給某個節點的程序,包括分配主分片或者副本,如果是副本,還包含從主分片復制資料的程序,這個程序是由 master 節點完成的,
2.3 Elasticsearch核心概念 VS 資料庫核心概念
| 關系型資料庫(比如Mysql) | 非關系型資料庫(Elasticsearch) |
|---|---|
| 資料庫Database | 索引Index |
| 表Table | 索引Index(原為Type) |
| 資料行Row | 檔案Document |
| 資料列Column | 欄位Field |
| 約束 Schema | 映射Mapping |
??Elasticsearch(集群)中可以包含多個索引(資料庫),每個索引中可以包含多個型別(表),每個型別下又包含多個檔案(行),每個檔案中又包含多個欄位(列),
2.4 系統架構
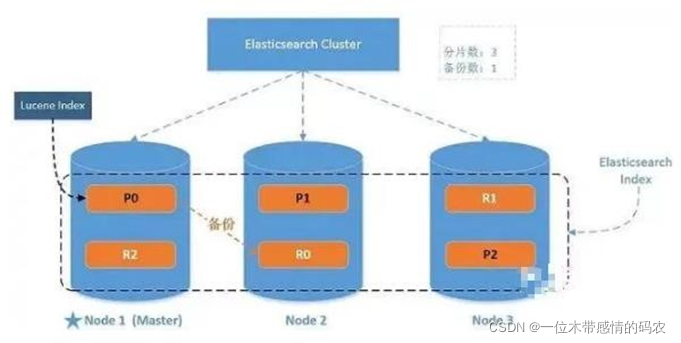
??一個運行中的 Elasticsearch 實體稱為一個節點,而集群是由一個或者多個擁有相同 cluster.name 配置的節點組成, 它們共同承擔資料和負載的壓力,當有節點加入集群中或者從集群中移除節點時,集群將會重新平均分布所有的資料,
??當一個節點被選舉成為主節點時, 它將負責管理集群范圍內的所有變更,例如增加、洗掉索引,或者增加、洗掉節點等, 而主節點并不需要涉及到檔案級別的變更和搜索等操作,所以當集群只擁有一個主節點的情況下,即使流量的增加它也不會成為瓶頸, 任何節點都可以成為主節點,我們的示例集群就只有一個節點,所以它同時也成為了主節點,
??作為用戶,我們可以將請求發送到集群中的任何節點 ,包括主節點, 每個節點都知道任意檔案所處的位置,并且能夠將我們的請求直接轉發到存盤我們所需檔案的節點, 無論我們將請求發送到哪個節點,它都能負責從各個包含我們所需檔案的節點收集回資料,并將最終結果回傳給客戶端, Elasticsearch 對這一切的管理都是透明的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/426513.html
標籤:其他
上一篇:22/02/17學習筆記