自己通過閱讀了解論文和極客時間相關講解,并通過自己已有的框架知識,總結該文章,閱讀需要有一定的大資料基礎知識,
文章目錄
- GFS的三個原則
- GFS是一個簡單的單Master架構,
- 依據硬體進行設計
- 一致性(重點)
GFS的三個原則
-
簡單:使用 Linux 服務上的普通檔案作為基礎存盤層,并且選擇了最簡單的單Master 設計,一旦 Master 出現故障,整個集群就無法寫入資料(算不上高可用),雖然有Backup Master的存在,但是從檢測到,讀取最新CheckPoint,重放日志,可能是分鐘級別的,這期間仍舊是不可用的,
-
對硬體特性進行設計取舍:
采用流水線式的資料傳輸,而非樹形;檔案復制時,直接在本地拷貝,減少資料在網路上的傳輸,避免網路帶寬成為瓶頸,
-
資料一致性:
GFS在并發的隨機寫入中是,一致但非確定的,而對于并發的追加寫入,也只是做出了“至少一次”的保證,
現在我們依次看這三個原則所描述的,
GFS是一個簡單的單Master架構,
Master有三種作用:相對于存盤資料的 Chunkserver,Master 是一個目錄服務;相對于為了災難恢復的 Backup Master,它是一個同步復制的主從架構下的主節點;相對于為了保障讀資料的可用性而設立的 Shadow Master,它是一個異步復制的主從架構下的主節點,
-
目錄服務:
master 里面會存放三種主要的元資料:
檔案和 chunk 的命名空間資訊,即是路徑和檔案名,
這些檔案被拆分成了哪幾個 chunk(每一個chuck都有唯一對應的chunk handle編號),即是檔案到多個chunk handle的映射,
這些 chunk 實際被存盤在了哪些 chunkserver 上,也就是 chunk handle 到chunkserver 的映射關系,
通過這三種元資料,master可以找到客戶端要讀取的資料在哪里,回傳給客戶端,
HDFS中NameNode即是第一關系和第二關系,
第一關系:檔案與block資料塊(chuck)的關系,第二關系:資料塊與資料節點的映射關系,
-
master的快速恢復和可用性
master接受所有客戶端的查詢請求,且只有一個節點,所以為保證master的性能,將master的資料都保存在記憶體中,
為了解決掛掉后,資料丟失的風險,master 會通過記錄操作日志和定期生成對應的 Checkpoints 進行持久化,(掛掉后,重啟讀取Checkpoints 和 日志即可)
-
Backup Master:
如果master節點真的硬體出現故障,這時候需要快速恢復,即是Backup Master,它會進行同步復制,只有當資料在 master 上操作成功,對應的操作記錄重繪到硬碟上,并且這幾個 Backup Master 的資料也寫入成功,并把操作記錄重繪到硬碟上,整個操作才會被視為操作成功,當當前master掛掉后,會從Backup Master中選出一個即為新的master,
-
Shadow Master:
在新的master選舉成功,并讀取Checkpoints 和 日志時,仍舊是一個空檔期,因此為解決這個問題,并誕生了異步復制的Shadow Master,盡可能保持追上 master 的最新狀態,
客戶端只有在該種情況下會讀到過時的master資訊,
1.master 掛掉了;2.是掛掉的 master 或者 Backup Master 上的 Checkpoints 和操作日志,還沒
有被影子 Master 同步完;3.則是我們要讀取的內容,恰恰是在沒有同步完的那部分操作上,
HDFS中為了減少NameNode的壓力,設計出Secondary NameNode來幫助其合并產生新的fsimage,(并非HA),
依據硬體進行設計
-
分離控制流和資料流
實際的資料讀寫都不需要通過 master,客戶端無論讀寫都只需要拿到master的元資料即可,(具體可看HDFS),
-
流水線式的網路資料傳輸,
如果用樹形,同時對三個副本進行網路發送,master的帶寬可以占滿,但是三個chuckserver的資料只占用了1/3,如果用流水線式資料傳輸,能充分的利用帶寬,
GFS中在傳輸時有主副本,GFS面對幾百個并發的客戶端,將傳輸過來的資料放在緩沖區,主副本進行排序,次副本以同樣的順序寫入,
HDFS寫入時不允許并發,因此在寫入時也不用考慮太多,也無主副本之說,但是在租約恢復時會選出一個主副本,保證一致性,(下面會詳細講到),
為什么優先選擇最近的副本寫入,而非主副本
同一個機架Rack上的服務器都會接入一臺接入層交換機(Access Switch);
各個機架上的接入層交換機都會連接到一臺匯聚層交換機(Aggregation Switch);
匯聚層交換機會再連接到核心交換機(Core Switch);
減少交換機的占用資源,
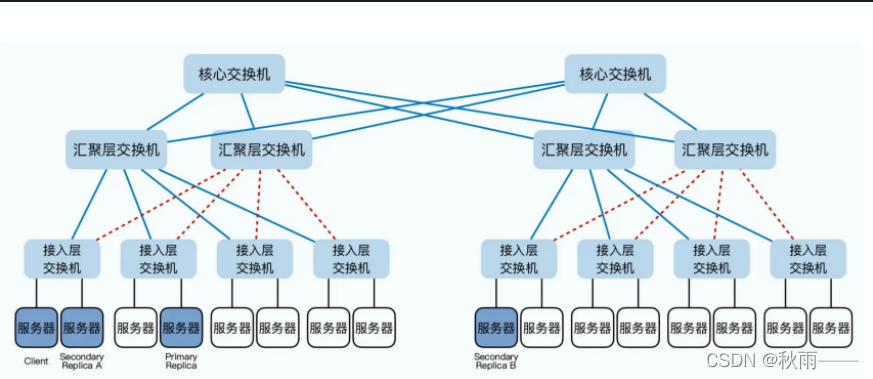
由圖可以知道,如果由客戶端到B再傳輸給A,將會比由客戶端到A再到B經過的交換機更多,
-
Snapshot
檔案的復制會直接在本地拷貝,不會進行網路傳輸進行拷貝,
一致性(重點)
-
GFS中的“ 一致性”
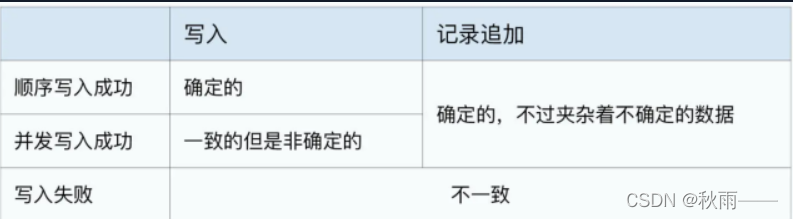
第一個,就指“一致的(Consistent)”:多個客戶端無論是從主副本讀取資料,還是從次副本讀取資料,讀到的資料都是一樣的,
第二個,指“確定的(Defined)”:就是客戶端寫入的資料能夠完整地被讀到,即:每個客戶端寫入指定offset的資料 和 再從offset讀出來的資料是相同的,
GFS中的一個表格
-
隨機寫入
多個客戶端并發寫入資料,即使寫入成功了,GFS 里的資料也可能會進入一個一致但是非確定的狀態
如果客戶端寫入GFS中指定offset,客戶端A寫入資料范圍[50, 80],客戶端B寫入資料范圍[70, 100],就有可能出現B覆寫A,或者A覆寫B的情況(不確定的)(寫入大小是不確定的),但是三個副本按同樣的順序寫入,是一致的,
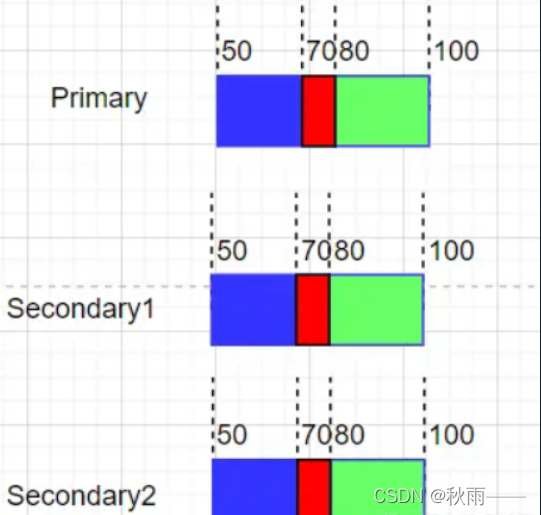
出現的原因:
資料的寫入順序并不需要通過Master來協調,而是直接發送給ChunkServer,由ChunkServer來管理資料的寫入順序;
-
記錄追加Record Append的“至少一次”的保障,(并發)
只是進行追加將不會產生不確定的情況A、B、C各自的結尾處寫入對應的資料,A客戶端可以讀取A的完整資料,同理BC一樣,
如果副本寫入失敗,怎么辦?
如下:
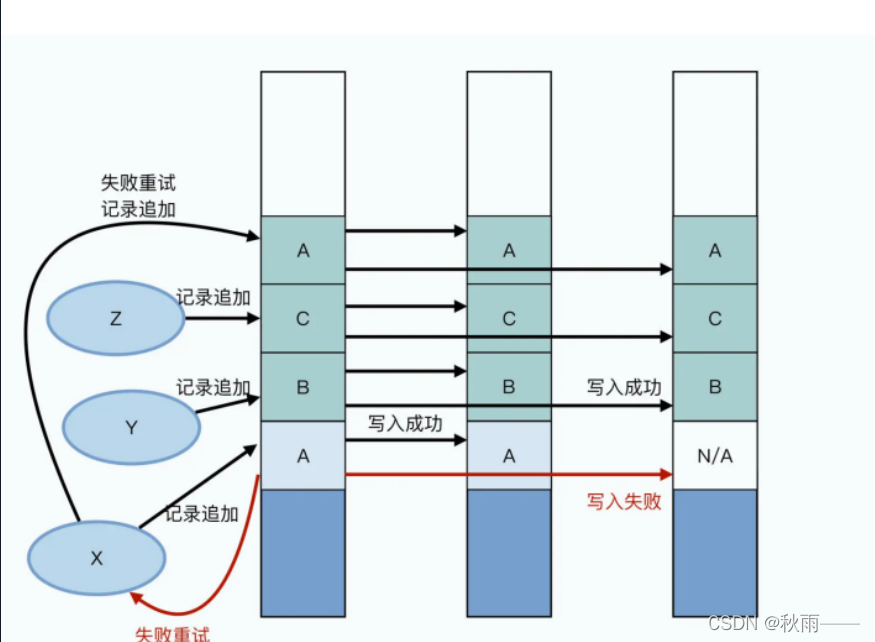
失敗后,X會重新在后面進行記錄追加(不止失敗的副本)
記錄追加使得大部分資料都是一致的,并且是確定的,但是整個檔案中,會夾雜著少數不一致也不確定的資料,(保證了至少一次,但不保證順序,可能使得客戶端拿到重復的資料和空資料)(Google的網頁存盤并不在乎網頁是存盤了兩遍,還是兩個網頁的順序),
但是我們可以在客戶端處進行解決,比如在資料中加入校驗和,加入唯一的包含時間戳的ID,這樣我們可以進行進一步的去重或者排序的操作,
注:,GFS 限制了一次記錄追加的資料量是16MB,而 chunkserver 里的一個 chunk 的大小是 64MB,所以,在記錄追加需要在chunk 里填空資料的時候,最多也就是填入 16MB,也就是 chunkserver 的存盤空間最多會浪費 1/4,
GFS的至少一次保證了高并發和高性能,
在HDFS中,不允許并發且只能追加,也就沒有了原來的復雜步驟(如主副本的排序),這樣同時保證了一致和確定的,
如果是客戶端故障,為保證一致性,會進行租約恢復,
如果是DataNode出現問題,分為三種情況:
- 從 pipeline setup(準備階段) 錯誤中恢復:
新寫檔案:Client 重新請求 NameNode 分配 block 和 DataNodes,重新設定 pipeline,
追加檔案:Client 從 pipeline 中移除出錯的 DataNode,然后繼續,
- 從 close 錯誤中恢復:
到了 close 階段才出錯,實際資料已經全部寫入了 DataNodes 中,所以影響很小了,Client 依然根據剩下正常的 DataNode 重建 pipeline,讓剩下的 DataNode 繼續完成 close 階段需要做的作業,
- 當 pipeline 中一個 DataNode 掛了,Client 重建 pipeline 時是可以移除掛了的 DataNode,也可以使用新的 DataNode 來替換,這里有策略是可配置的,稱為 DataNode Replacement Policy upon Failure,包括下面幾種情況:
NEVER:從不替換,針對 Client 的行為
DISABLE:禁止替換,DataNode 服務端拋出例外,表現行為類似 Client 的 NEVER 策略
DEFAULT:默認根據副本數要求來決定,簡單來說若配置的副本數為 3,如果壞了 2 個 DataNode,則會替換,否則不替換
ALWAYS:總是替換,
HDFS會每6小時進行檢測,然后進行資料塊的恢復,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/427500.html
標籤:其他
下一篇:2022年C題翻譯