PySpark環境搭建
配置hadoop
spark訪問本地檔案并執行運算時,可能會遇到權限問題或是dll錯誤,這是因為spark需要使用到Hadoop的winutils和hadoop.dll,首先我們必須配置好Hadoop相關的環境,可以到github下載:https://github.com/4ttty/winutils
gitcode提供了鏡像加速:https://gitcode.net/mirrors/4ttty/winutils
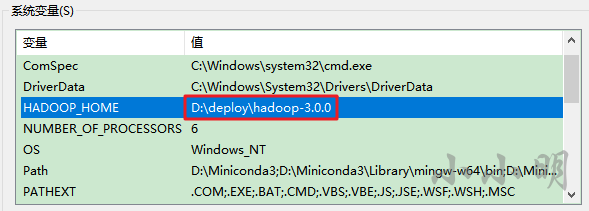
我選擇了使用這個倉庫提供的最高的Hadoop版本3.0.0將其解壓到D:\deploy\hadoop-3.0.0目錄下,然后配置環境變數:
我們還需要將對應的hadoop.dll復制到系統中,用命令表達就是:
copy D:\deploy\hadoop-3.0.0\bin\hadoop.dll C:\Windows\System32
不過這步需要擁有管理員權限才可以操作,
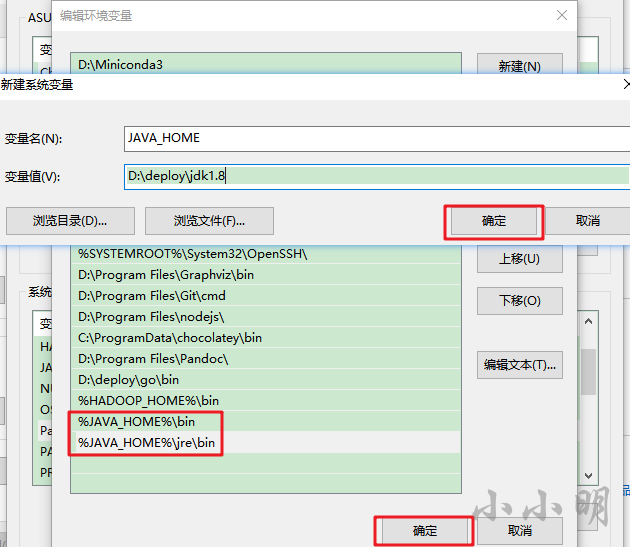
為了能夠在任何地方使用winutils命令工具,將%HADOOP_HOME%\bin目錄加入環境變數中:

安裝pyspark與Java
首先,我們安裝spark當前(2022-2-17)的最新版本:
pip install pyspark==3.2.1
需要注意pyspark的版本決定了jdk的最高版本,例如假如安裝2.4.5版本的pyspark就只能安裝1.8版本的jdk,否則會報出java.lang.IllegalArgumentException: Unsupported class file major version 55的錯誤,
這是因為pyspark內置了Scala,而Scala是基于jvm的編程語言,Scala與jdk的版本存在兼容性問題,JDK與scala的版本兼容性表:
| JDK version | Minimum Scala versions | Recommended Scala versions |
|---|---|---|
| 17 | 2.13.6, 2.12.15 (forthcoming) | 2.13.6, 2.12.15 (forthcoming) |
| 16 | 2.13.5, 2.12.14 | 2.13.6, 2.12.14 |
| 13, 14, 15 | 2.13.2, 2.12.11 | 2.13.6, 2.12.14 |
| 12 | 2.13.1, 2.12.9 | 2.13.6, 2.12.14 |
| 11 | 2.13.0, 2.12.4, 2.11.12 | 2.13.6, 2.12.14, 2.11.12 |
| 8 | 2.13.0, 2.12.0, 2.11.0, 2.10.2 | 2.13.6, 2.12.14, 2.11.12, 2.10.7 |
| 6, 7 | 2.11.0, 2.10.0 | 2.11.12, 2.10.7 |
當前3.2.1版本的pyspark內置的Scala版本為2.12.15,意味著jdk17與其以下的所有版本都支持,
這里我依然選擇安裝jdk8的版本:
測驗一下:
>java -version
java version "1.8.0_201"
Java(TM) SE Runtime Environment (build 1.8.0_201-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.201-b09, mixed mode)
jdk11的詳細安裝教程(jdk1.8在官網只有安裝包,無zip綠化壓縮包):
綠化版Java11的環境配置與Python呼叫Java
https://xxmdmst.blog.csdn.net/article/details/118366166
graphframes安裝
pip安裝當前最新的graphframes:
pip install graphframes==0.6
然后在官網下載graphframes的jar包,
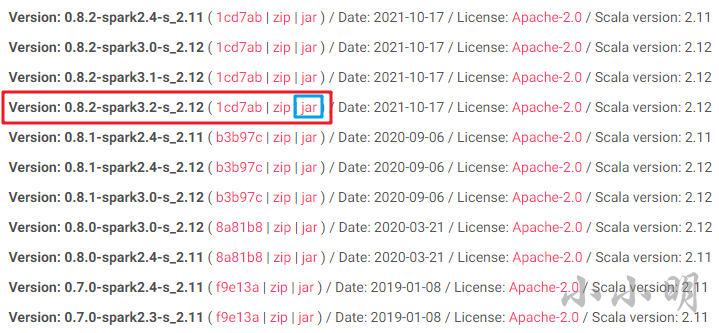
下載地址:https://spark-packages.org/package/graphframes/graphframes
由于安裝的pyspark版本是3.2,所以這里我選擇了這個jar包:
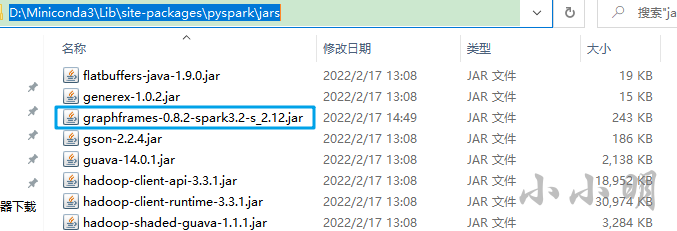
然后將該jar包放入pyspark安裝目錄的jars目錄下:
pyspark安裝位置可以通過pip查看:
C:\Users\ASUS>pip show pyspark
Name: pyspark
Version: 3.2.1
Summary: Apache Spark Python API
Home-page: https://github.com/apache/spark/tree/master/python
Author: Spark Developers
Author-email: dev@spark.apache.org
License: http://www.apache.org/licenses/LICENSE-2.0
Location: d:\miniconda3\lib\site-packages
Requires: py4j
Required-by:
使用方法
學習pyspark的最佳路徑是官網:https://spark.apache.org/docs/latest/quick-start.html
在下面的網頁,官方提供了在線jupyter:
https://spark.apache.org/docs/latest/api/python/getting_started/index.html
啟動spark并讀取資料
本地模式啟動spark:
from pyspark.sql import SparkSession, Row
spark = SparkSession \
.builder \
.appName("Python Spark") \
.master("local[*]") \
.getOrCreate()
sc = spark.sparkContext
spark
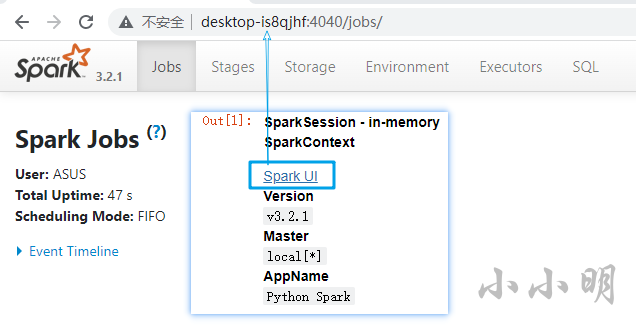
SparkSession輸出的內容中包含了spark的web頁面,新標簽頁打開頁面后大致效果如上,
點擊Environment選項卡可以查看當前環境中的變數:
啟動hive支持
找到pyspark的安裝位置,例如我的電腦在D:\Miniconda3\Lib\site-packages\pyspark
手動創建conf目錄并將hive-site.xml組態檔復制到其中,如果hive使用了MySQL作為原資料庫,則還需要將MySQL對應的驅動jar包放入spark的jars目錄下,
創建spark會話物件時可通過enableHiveSupport()開啟hive支持:
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.enableHiveSupport() \
.getOrCreate()
sc = spark.sparkContext
spark
spark訪問hive自己創建的表有可能會出現如下的權限報錯:
Caused by: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS s
hould be writable. Current permissions are: rwx------
是因為當前用戶不具備對\tmp\hive的操作權限:
>winutils ls \tmp\hive
drwx------ 1 BUILTIN\Administrators XIAOXIAOMING\None 0 May 4 2020 \tmp\hive
把\tmp\hive目錄的權限改為777即可順利訪問:
>winutils chmod 777 \tmp\hive
>winutils ls \tmp\hive
drwxrwxrwx 1 BUILTIN\Administrators XIAOXIAOMING\None 0 May 4 2020 \tmp\hive
Spark的DataFrame與RDD
從spark2.x開始將RDD和DataFrame的API統一抽象成dataset,DataFrame就是Dataset[Row],RDD則是Dataset.rdd,可以將DataFrame理解為包含結構化資訊的RDD,
將含row的RDD轉換為DataFrame只需要呼叫toDF方法或SparkSession的createDataFrame方法即可,也可以傳入schema覆寫型別或名稱設定,
DataFrame的基礎api
DataFrame默認支持DSL風格語法,例如:
//查看DataFrame中的內容
df.show()
//查看DataFrame部分列中的內容
df.select(df['name'], df['age'] + 1).show()
df.select("name").show()
//列印DataFrame的Schema資訊
df.printSchema()
//過濾age大于等于 21 的
df.filter(df['age'] > 21).show()
//按年齡進行分組并統計相同年齡的人數
personDF.groupBy("age").count().show()
將DataFrame注冊成表或視圖之后即可進行純SQL操作:
df.createOrReplaceTempView("people")
//df.createTempView("t_person")
//查詢年齡最大的前兩名
spark.sql("select * from t_person order by age desc limit 2").show()
//顯示表的Schema資訊
spark.sql("desc t_person").show()
Pyspark可以直接很方便的注冊udf并直接使用:
strlen = spark.udf.register("len", lambda x: len(x))
print(spark.sql("SELECT len('test') length").collect())
print(spark.sql("SELECT 'foo' AS text").select(strlen("text").alias('length')).collect())
執行結果:
[Row(length='4')]
[Row(length='3')]
RDD的簡介
DataFrame的本質是對RDD的包裝,可以理解為DataFrame=RDD[Row]+schema,
RDD(A Resilient Distributed Dataset)叫做彈性可伸縮分布式資料集,是Spark中最基本的資料抽象,它代表一個不可變、自動容錯、可伸縮性、可磁區、里面的元素可并行計算的集合,
在每一個RDD內部具有五大屬性:
- 具有一系列的磁區
- 一個計算函式操作于每一個切片
- 具有一個對其他RDD的依賴串列
- 對于 key-value RDDs具有一個Partitioner磁區器
- 存盤每一個切片最佳計算位置
一組分片(Partition),即資料集的基本組成單位,對于RDD來說,每個分片都會被一個計算任務處理,并決定并行計算的粒度,用戶可以在創建RDD時指定RDD的分片個數,如果沒有指定,那么就會采用默認值,默認值就是程式所分配到的CPU Core的數目,
**一個計算每個磁區的函式,**Spark中RDD的計算是以分片為單位的,每個RDD都會實作compute函式以達到這個目的,compute函式會對迭代器進行復合,不需要保存每次計算的結果,
**RDD之間的依賴關系,**RDD的每次轉換都會生成一個新的RDD,所以RDD之間就會形成類似于流水線一樣的前后依賴關系,在部分磁區資料丟失時,Spark可以通過這個依賴關系重新計算丟失的磁區資料,而不是對RDD的所有磁區進行重新計算,
**一個Partitioner,即RDD的分片函式,**當前Spark中實作了兩種型別的分片函式,一個是基于哈希的HashPartitioner,另外一個是基于范圍的RangePartitioner,只有對于于key-value的RDD,才會有Partitioner,非key-value的RDD的Parititioner的值是None,Partitioner函式不但決定了RDD本身的分片數量,也決定了parent RDD Shuffle輸出時的分片數量,
**一個串列,存盤存取每個Partition的優先位置(preferred location),**對于一個HDFS檔案來說,這個串列保存的就是每個Partition所在的塊的位置,按照“移動資料不如移動計算”的理念,Spark在進行任務調度的時候,會盡可能地將計算任務分配到其所要處理資料塊的存盤位置,
RDD的API概覽
RDD包含Transformation API和 Action API,Transformation API都是延遲加載的只是記住這些應用到基礎資料集上的轉換動作,只有當執行Action API時這些轉換才會真正運行,
Transformation API產生的兩類RDD最重要,分別是MapPartitionsRDD和ShuffledRDD,
產生MapPartitionsRDD的算子有map、keyBy、keys、values、flatMap、mapValues 、flatMapValues、mapPartitions、mapPartitionsWithIndex、glom、filter和filterByRange ,其中用的最多的是map和flatMap,但任何產生MapPartitionsRDD的算子都可以直接使用mapPartitions或mapPartitionsWithIndex實作,
產生ShuffledRDD的算子有combineByKeyWithClassTag、combineByKey、aggregateByKey、foldByKey 、reduceByKey 、distinct、groupByKey、groupBy、partitionBy、sortByKey 和 repartitionAndSortWithinPartitions,
combineByKey到groupByKey 底層均是呼叫combineByKeyWithClassTag方法:
@Experimental
def combineByKeyWithClassTag[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C)(implicit ct: ClassTag[C]): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner,mergeValue,mergeCombiners
,defaultPartitioner(self))
}
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C): RDD[(K, C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners)(null)
}
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])] = self.withScope {
val createCombiner = (v: V) => CompactBuffer(v)
val mergeValue = (buf: CompactBuffer[V], v: V) => buf += v
val mergeCombiners = (c1: CompactBuffer[V], c2: CompactBuffer[V]) => c1 ++= c2
val bufs = combineByKeyWithClassTag[CompactBuffer[V]](
createCombiner, mergeValue, mergeCombiners, partitioner, mapSideCombine = false)
bufs.asInstanceOf[RDD[(K, Iterable[V])]]
}
三個重要引數的含義:
- createCombiner:根據每個磁區的第一個元素操作產生一個初始值
- mergeValue:對每個磁區內部的元素進行迭代合并
- mergeCombiners:對所有磁區的合并結果進行合并
groupByKey的partitioner未指定時會傳入默認的defaultPartitioner,例如:
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2).keyBy(_.length)
a.groupByKey.collect
res9: Array[(Int, Iterable[String])] = Array((4,CompactBuffer(lion)), (6,CompactBuffer(spider)), (3,CompactBuffer(dog, cat)), (5,CompactBuffer(tiger, eagle)))
aggregateByKey:每個磁區使用zeroValue作為初始值,迭代每一個元素用seqOp進行合并,對所有磁區的結果用combOp進行合并,例如:
val pairRDD = sc.parallelize(List( ("cat",2), ("cat", 5), ("mouse", 4),("cat", 12), ("dog", 12), ("mouse", 2)), 2)
pairRDD.aggregateByKey(0)(math.max(_, _), _ + _).collect
res6: Array[(String, Int)] = Array((dog,12), (cat,17), (mouse,6))
pairRDD.aggregateByKey(100)(math.max(_, _), _ + _).collect
res7: Array[(String, Int)] = Array((dog,100), (cat,200), (mouse,200))
reduceByKey :每個磁區迭代每一個元素用func進行合并,對所有磁區的結果用func再進行合并,例如:
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
b.reduceByKey(_ + _).collect
Action API有:
| 動作 | 含義 |
|---|---|
| reduce(func) | 通過func函式聚集RDD中的所有元素,這個功能必須是課交換且可并聯的 |
| collect() | 在驅動程式中,以陣列的形式回傳資料集的所有元素 |
| count() | 回傳RDD的元素個數 |
| first() | 回傳RDD的第一個元素(類似于take(1)) |
| take(n) | 回傳一個由資料集的前n個元素組成的陣列 |
| takeSample(withReplacement*,*num, [seed]) | 回傳一個陣列,該陣列由從資料集中隨機采樣的num個元素組成,可以選擇是否用亂數替換不足的部分,seed用于指定亂數生成器種子 |
| takeOrdered(n, [ordering]) | 排序并取前N個元素 |
| saveAsTextFile(path) | 將資料集的元素以textfile的形式保存到HDFS檔案系統或者其他支持的檔案系統,對于每個元素,Spark將會呼叫toString方法,將它裝換為檔案中的文本 |
| saveAsSequenceFile(path) | 將資料集中的元素以Hadoop sequencefile的格式保存到指定的目錄下,可以使HDFS或者其他Hadoop支持的檔案系統, |
| saveAsObjectFile(path) | 將RDD中的元素用NullWritable作為key,實際元素作為value保存為sequencefile格式 |
| countByKey() | 針對(K,V)型別的RDD,回傳一個(K,Int)的map,表示每一個key對應的元素個數, |
| foreach(func) | 在資料集的每一個元素上,運行函式func進行更新, |
spark模擬實作mapreduce版wordcount:
object MapreduceWordcount {
def main(args: Array[String]): Unit = {
import org.apache.spark._
val sc: SparkContext = new SparkContext(new SparkConf().setAppName("wordcount").setMaster("local[*]"))
sc.setLogLevel("WARN")
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.rdd.HadoopRDD
import scala.collection.mutable.ArrayBuffer
def map(k: LongWritable, v: Text, collect: ArrayBuffer[(String, Int)]) = {
for (word <- v.toString.split("\\s+"))
collect += ((word, 1))
}
def reduce(key: String, value: Iterator[Int], collect: ArrayBuffer[(String, Int)]) = {
collect += ((key, value.sum))
}
val rdd = sc.hadoopFile("/hdfs/wordcount/in1/*", classOf[TextInputFormat], classOf[LongWritable], classOf[Text], 2)
.asInstanceOf[HadoopRDD[LongWritable, Text]]
.mapPartitionsWithInputSplit((split, it) =>{
val collect: ArrayBuffer[(String, Int)] = ArrayBuffer[(String, Int)]()
it.foreach(kv => map(kv._1, kv._2, collect))
collect.toIterator
})
.repartitionAndSortWithinPartitions(new HashPartitioner(2))
.mapPartitions(it => {
val collect: ArrayBuffer[(String, Int)] = ArrayBuffer[(String, Int)]()
var lastKey: String = ""
var values: ArrayBuffer[Int] = ArrayBuffer[Int]()
for ((currKey, value) <- it) {
if (!currKey.equals(lastKey)) {
if (values.length != 0)
reduce(lastKey, values.toIterator, collect)
values.clear()
}
values += value
lastKey = currKey
}
if (values.length != 0) reduce(lastKey, values.toIterator, collect)
collect.toIterator
})
rdd.foreach(println)
}
}
各類RDD
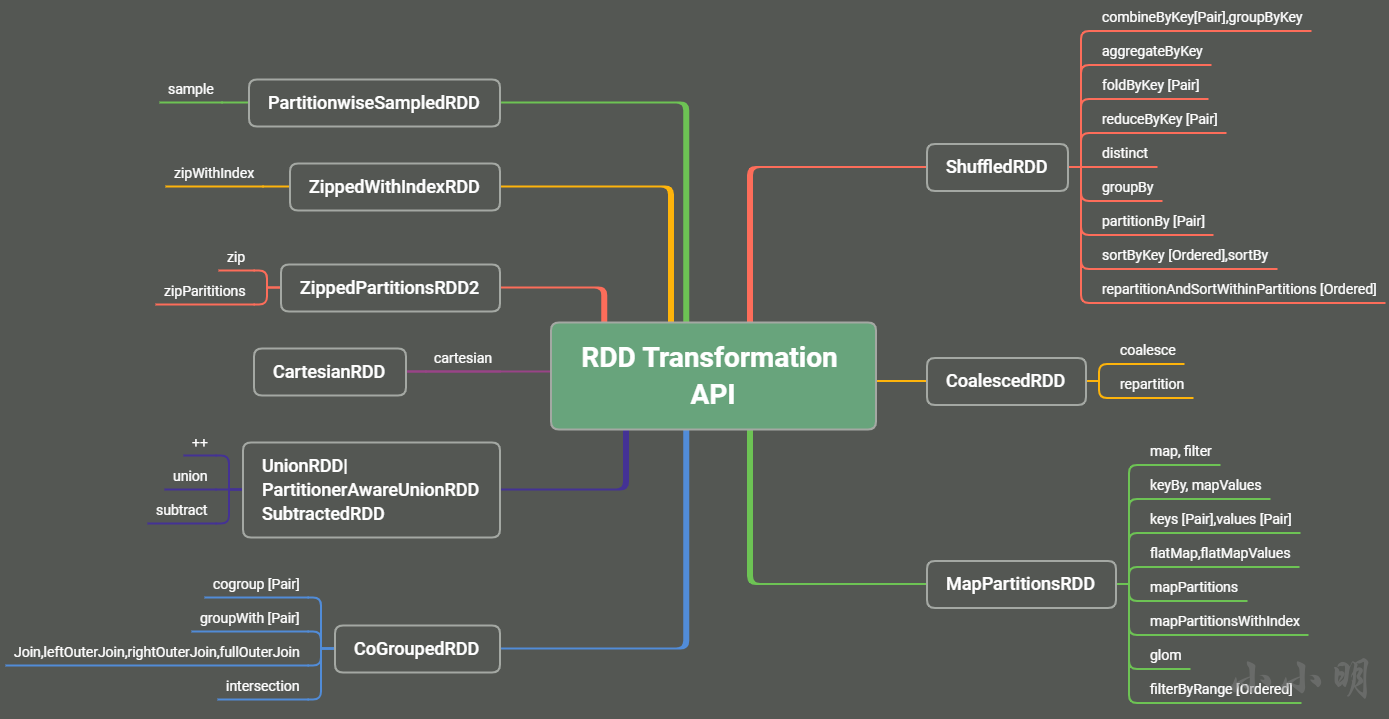
-
ShuffledRDD :表示需要走Shuffle程序的網路傳輸
-
CoalescedRDD :用于將一臺機器的多個磁區合并成一個磁區
-
CartesianRDD :對兩個RDD的所有元素產生笛卡爾積
-
MapPartitionsRDD :用于對每個磁區的資料進行特定的處理
-
CoGroupedRDD :用于將2~4個rdd,按照key進行連接聚合
-
SubtractedRDD :用于對2個RDD求差集
-
UnionRDD和PartitionerAwareUnionRDD :用于對2個RDD求并集
-
ZippedPartitionsRDD2:zip拉鏈操作產生的RDD
-
ZippedWithIndexRDD:給每一個元素標記一個自增編號
-
PartitionwiseSampledRDD:用于對rdd的元素按照指定的百分比進行隨機采樣
當我們需要給Datafream添加自增列時,可以使用zipWithUniqueId方法:
from pyspark.sql.types import StructType, LongType
schema = data.schema.add(StructField("id", LongType()))
rowRDD = data.rdd.zipWithUniqueId().map(lambda t: t[0]+Row(t[1]))
data = rowRDD.toDF(schema)
data.show()
API用法詳情可參考:https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.RDD.html#pyspark.RDD
cache&checkpoint
RDD通過persist方法或cache方法可以將前面的計算結果快取,但是并不是這兩個方法被呼叫時立即快取,而是觸發后面的action時,該RDD將會被快取在計算節點的記憶體中,并供后面重用,
rdd.persist()
checkpoint的原始碼注釋可以看到:
- 標記該RDD作為檢查點,
- 它將被保存在通過SparkContext#setCheckpointDir方法設定的檢查點目錄中
- 它所參考的所有父RDD參考將全部被移除
- 這個方法在這個RDD上必須在所有job執行前運行,
- 強烈建議將這個RDD快取在記憶體中,否則這個保存檔案的計算任務將重新計算,
從中我們得知,在執行checkpoint方法時,最好同時,將該RDD快取起來,否則,checkpoint也會產生一個計算任務,
sc.setCheckpointDir("checkpoint")
rdd.cache()
rdd.checkpoint()
graphframes 的用法
GraphFrame是將Spark中的Graph演算法統一到DataFrame介面的Graph操作介面,為Scala、Java和Python提供了統一的圖處理API,
Graphframes是開源專案,原始碼工程如下:https://github.com/graphframes/graphframes
可以參考:
- 官網:https://graphframes.github.io/graphframes/docs/_site/index.html
- GraphFrames用戶指南-Python — Databricks檔案:https://docs.databricks.com/spark/latest/graph-analysis/graphframes/user-guide-python.html
在GraphFrames中圖的頂點(Vertex)和邊(edge)都是以DataFrame形式存盤的:
- 頂點DataFrame:必須包含列名為“id”的列,用于作為頂點的唯一標識
- 邊DataFrame:必須包含列名為“src”和“dst”的列,根據唯一標識id標識關系
創建圖的示例:
from graphframes import GraphFrame
vertices = spark.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
("d", "David", 29),
("e", "Esther", 32),
("f", "Fanny", 36),
("g", "Gabby", 60)], ["id", "name", "age"])
edges = spark.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
("f", "c", "follow"),
("e", "f", "follow"),
("e", "d", "friend"),
("d", "a", "friend"),
("a", "e", "friend")
], ["src", "dst", "relationship"])
# 生成圖
g = GraphFrame(vertices, edges)
GraphFrame提供三種視圖:
print("頂點表視圖:")
graph.vertices.show() # graph.vertices 就是原始的vertices
print("邊表視圖:")
graph.edges.show() # graph.edges 就是原始的 edges
print("三元組視圖:")
graph.triplets.show()
獲取頂點的度、入度和出度:
# 頂點的度
graph.degrees.show()
# 頂點的入度
graph.inDegrees.show()
# 頂點的出度
graph.outDegrees.show()
Motif finding (模式發現)
示例:
# 多個路徑條件
motif = graph.find("(a)-[e]->(b); (b)-[e2]->(a)")
# 在搜索的結果上進行過濾
motif.filter("b.age > 30")
# 不需要回傳路徑中的元素時,可以使用匿名頂點和邊
motif = graph.find("(start)-[]->()")
# 設定路徑不存在的條件
motif = graph.find("(a)-[]->(b); !(b)-[]->(a)")
假設我們要想給用戶推薦關注的人,可以找出這樣的關系:A關注B,B關注C,但是A未關注C,找出這樣的關系就可以把C推薦給A:
# Motif: A->B->C but not A->C
results = graph.find("(A)-[]->(B); (B)-[]->(C); !(A)-[]->(C)")
# 排除自己
results = results.filter("A.id != C.id")
# 選擇需要的列
results = results.select(results.A.id.alias("A"), results.C.id.alias("C"))
results.show()
結果:
+---+---+
| A| C|
+---+---+
| e| c|
| e| a|
| d| b|
| a| d|
| f| b|
| d| e|
| a| f|
| a| c|
+---+---+
Motif在查找路徑程序的程序中,還可以沿著路徑攜帶狀態,例如我們想要找出關系鏈有4個頂點,而且其中3條邊全部都是"friend"關系:
from pyspark.sql.functions import col, lit, when
from functools import reduce
chain4 = graph.find("(a)-[ab]->(b); (b)-[bc]->(c); (c)-[cd]->(d)")
def sumFriends(cnt, relationship):
"定義下一個頂點更新狀態的條件:如果關系為friend則cnt+1"
return when(relationship == "friend", cnt+1).otherwise(cnt)
# 將更新方法應用到整個鏈的,鏈上每有一個關系是 friend 就加一,鏈上共三個關系,
condition = reduce(lambda cnt, e: sumFriends(
cnt, col(e).relationship), ["ab", "bc", "cd"], lit(0))
chainWith2Friends2 = chain4.where(condition >= 3)
chainWith2Friends2.show()
結果:
+---------------+--------------+---------------+--------------+---------------+--------------+---------------+
| a| ab| b| bc| c| cd| d|
+---------------+--------------+---------------+--------------+---------------+--------------+---------------+
| {a, Alice, 34}|{a, e, friend}|{e, Esther, 32}|{e, d, friend}| {d, David, 29}|{d, a, friend}| {a, Alice, 34}|
|{e, Esther, 32}|{e, d, friend}| {d, David, 29}|{d, a, friend}| {a, Alice, 34}|{a, b, friend}| {b, Bob, 36}|
| {d, David, 29}|{d, a, friend}| {a, Alice, 34}|{a, e, friend}|{e, Esther, 32}|{e, d, friend}| {d, David, 29}|
|{e, Esther, 32}|{e, d, friend}| {d, David, 29}|{d, a, friend}| {a, Alice, 34}|{a, e, friend}|{e, Esther, 32}|
+---------------+--------------+---------------+--------------+---------------+--------------+---------------+
Subgraphs 子圖
可以直接過濾其頂點或邊,dropIsolatedVertices()方法用于洗掉孤立沒有連接的點:
graph.filterVertices("age > 30").filterEdges("relationship = 'friend'").dropIsolatedVertices()
還可以基于模式發現獲取到的邊創建Subgraphs :
paths = graph.find("(a)-[e]->(b)")\
.filter("e.relationship = 'follow'")\
.filter("a.age < b.age")
# 抽取邊資訊e2 = paths.select("e.src", "e.dst", "e.relationship")
e2 = paths.select("e.*")
# 創建Subgraphs
g2 = GraphFrame(graph.vertices, e2)
GraphFrames支持的GraphX演算法
-
PageRank:查找圖中的重要頂點,
-
廣度優先搜索(BFS):查找從一組頂點到另一組頂點的最短路徑
-
連通組件(ConnectedComponents):為具備連接關系的頂點分配相同的組件ID
-
強連通組件(StronglyConnectedConponents):根據每個頂點的強連通分量分配SCC,
-
最短路徑(Shortest paths):查找從每個頂點到目標頂點集的最短路徑,
-
三角形計數(TriangleCount):計算每個頂點所屬的三角形的數量,經常用于確定組的穩定性(相互連接的數量代表了穩定性)或作為其他網路度量(如聚類系數)的一部分,在社交網路分析中用來檢測社區,
-
標簽傳播演算法(LPA):檢測圖中的社區,
pageRank演算法:
results = graph.pageRank(resetProbability=0.15, maxIter=10)
results.vertices.sort("pagerank", ascending=False).show()
結果:
+---+-------+---+-------------------+
| id| name|age| pagerank|
+---+-------+---+-------------------+
| b| Bob| 36| 2.7025217677349773|
| c|Charlie| 30| 2.6667877057849627|
| a| Alice| 34| 0.4485115093698443|
| e| Esther| 32| 0.3613490987992571|
| f| Fanny| 36|0.32504910549694244|
| d| David| 29|0.32504910549694244|
| g| Gabby| 60|0.17073170731707318|
+---+-------+---+-------------------+
可以設定起始頂點:
graph.pageRank(resetProbability=0.15, maxIter=10, sourceId="a")
graph.parallelPersonalizedPageRank(resetProbability=0.15, sourceIds=["a", "b", "c", "d"], maxIter=10)
廣度優先搜索BFS:
搜索從姓名叫Esther到年齡小于32的最小路徑:
paths = graph.bfs("name = 'Esther'", "age < 32")
paths.show()
+--------------+--------------+---------------+
| from| e0| to|
+--------------+--------------+---------------+
|{a, Alice, 34}|{a, e, friend}|{e, Esther, 32}|
+--------------+--------------+---------------+
可以指定只能在指定的邊搜索:
graph.bfs("name = 'Esther'",
"age < 32",
edgeFilter="relationship != 'friend'",
maxPathLength=4
).show()
+---------------+--------------+--------------+--------------+----------------+
| from| e0| v1| e1| to|
+---------------+--------------+--------------+--------------+----------------+
|{e, Esther, 32}|{e, f, follow}|{f, Fanny, 36}|{f, c, follow}|{c, Charlie, 30}|
+---------------+--------------+--------------+--------------+----------------+
Connected components 連通組件:
必須先設定檢查點:
sc.setCheckpointDir("checkpoint")
graph.connectedComponents().show()
結果:
+---+-------+---+------------+
| id| name|age| component|
+---+-------+---+------------+
| a| Alice| 34|412316860416|
| b| Bob| 36|412316860416|
| c|Charlie| 30|412316860416|
| d| David| 29|412316860416|
| e| Esther| 32|412316860416|
| f| Fanny| 36|412316860416|
| g| Gabby| 60|146028888064|
+---+-------+---+------------+
可以看到僅g點在一個連通區域內,可以呼叫dropIsolatedVertices()方法,洗掉這種孤立的沒有連接的點:
graph.dropIsolatedVertices().connectedComponents().show()
結果:
+---+-------+---+------------+
| id| name|age| component|
+---+-------+---+------------+
| a| Alice| 34|412316860416|
| b| Bob| 36|412316860416|
| c|Charlie| 30|412316860416|
| d| David| 29|412316860416|
| e| Esther| 32|412316860416|
| f| Fanny| 36|412316860416|
+---+-------+---+------------+
Strongly connected components 強連通組件:
graph.stronglyConnectedComponents(maxIter=10).show()
Shortest paths 最短路徑:
每個頂點到a或d的最短路徑:
graph.shortestPaths(landmarks=["a", "d"]).show()
+---+-------+---+----------------+
| id| name|age| distances|
+---+-------+---+----------------+
| g| Gabby| 60| {}|
| f| Fanny| 36| {}|
| e| Esther| 32|{a -> 2, d -> 1}|
| d| David| 29|{a -> 1, d -> 0}|
| c|Charlie| 30| {}|
| b| Bob| 36| {}|
| a| Alice| 34|{a -> 0, d -> 2}|
+---+-------+---+----------------+
Triangle count 三角形計數:
graph.triangleCount().show()
+-----+---+-------+---+
|count| id| name|age|
+-----+---+-------+---+
| 1| a| Alice| 34|
| 0| b| Bob| 36|
| 0| c|Charlie| 30|
| 1| d| David| 29|
| 1| e| Esther| 32|
| 0| g| Gabby| 60|
| 0| f| Fanny| 36|
+-----+---+-------+---+
說明頂點a/e/d構成三角形,
標簽傳播演算法(LPA):
graph.labelPropagation(maxIter=5).orderBy("label").show()
+---+-------+---+-------------+
| id| name|age| label|
+---+-------+---+-------------+
| g| Gabby| 60| 146028888064|
| f| Fanny| 36|1047972020224|
| b| Bob| 36|1047972020224|
| a| Alice| 34|1382979469312|
| c|Charlie| 30|1382979469312|
| e| Esther| 32|1460288880640|
| d| David| 29|1460288880640|
+---+-------+---+-------------+
PySpark3.X與pandas融合
Pyspark從3.0版本開始出現了pandas_udf裝飾器、applyInPandas和mapInPandas,基于這些方法,我們就可以使用熟悉的pandas的語法處理spark物件的資料,
首先創建幾條測驗資料,并啟動 Apache Arrow:
spark.conf.set("spark.sql.execution.arrow.pyspark.enabled", "true")
df = spark.createDataFrame(
[(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
("id", "v"))
df.show()
自定義UDF和UDAF
pyspark暫不支持自定義UDTF,
使用pandas_udf裝飾器我們可以創建出基于pandas的udf自定義函式,在DSL的語法中可以被直接使用:
from pyspark.sql.functions import pandas_udf
import pandas as pd
@pandas_udf("double")
def multiply_func(a: pd.Series, b: pd.Series) -> pd.Series:
return a * b
df.select(multiply_func("id", "v").alias("product")).show()
注冊函式和視圖后,可以直接在SQL中使用:
df.createOrReplaceTempView("t")
spark.udf.register("multiply", multiply_func)
spark.sql('select multiply(id, v) product from t').show()
結果均為:
+-------+
|product|
+-------+
| 1.0|
| 2.0|
| 6.0|
| 10.0|
| 20.0|
+-------+
還支持聚合函式和視窗函式:
from pyspark.sql import Window
@pandas_udf("double")
def mean_udf(v: pd.Series) -> float:
return v.mean()
# 對欄位'v'進行求均值
df.select(mean_udf('v').alias("mean_v")).show()
# 按照‘id’分組,求'v'的均值
df.groupby("id").agg(mean_udf('v').alias("mean_v")).show()
# 按照‘id’分組,求'v'的均值,并賦值給新的一列
df.withColumn('mean_v', mean_udf("v").over(Window.partitionBy('id'))).show()
注冊到udf之后同樣可以直接使用SQL實作:
spark.udf.register("mean2", mean_udf)
spark.sql('select mean2(v) mean_v from t').show()
spark.sql('select id,mean2(v) mean_v from t group by id').show()
spark.sql('select id,v,mean2(v) over(partition by id) mean_v from t').show()
結果均為:
+--------+
| mean_v |
+--------+
| 4.2|
+--------+
+---+--------+
| id| mean_v |
+---+--------+
| 1| 1.5|
| 2| 6.0|
+---+--------+
+---+----+------+
| id| v|mean_v|
+---+----+------+
| 1| 1.0| 1.5|
| 1| 2.0| 1.5|
| 2| 3.0| 6.0|
| 2| 5.0| 6.0|
| 2|10.0| 6.0|
+---+----+------+
分組聚合與JOIN
applyInPandas需要在datafream呼叫groupby之后才能使用:
def subtract_mean(pdf):
v = pdf.v
pdf['v1'] = v - v.mean()
pdf['v2'] = v + v.mean()
return pdf
t = df.groupby("id")
t.applyInPandas(
subtract_mean, schema="id long, v double, v1 double, v2 double").show()
結果:
+---+----+----+----+
| id| v| v1| v2|
+---+----+----+----+
| 1| 1.0|-0.5| 2.5|
| 1| 2.0| 0.5| 3.5|
| 2| 3.0|-3.0| 9.0|
| 2| 5.0|-1.0|11.0|
| 2|10.0| 4.0|16.0|
+---+----+----+----+
subtract_mean函式接收的是對應id的dataframe資料,schema指定了回傳值的名稱和型別串列,
通過以下代碼我們可以知道,applyInPandas可以借助cogroup進行表連接:
val a = sc.parallelize(List(1, 2, 1, 3))
val b = a.map((_, "b"))
val c = a.map((_, "c"))
val d = a.map((_, "d"))
val e = a.map((_, "e"))
scala> b.cogroup(c).foreach(println)
(3,(CompactBuffer(b),CompactBuffer(c)))
(1,(CompactBuffer(b, b),CompactBuffer(c, c)))
(2,(CompactBuffer(b),CompactBuffer(c)))
示例:
df1 = spark.createDataFrame(
[(20000101, 1, 1.0), (20000101, 2, 2.0), (20000102, 1, 3.0), (20000102, 2, 4.0)],
("time", "id", "v1"))
df2 = spark.createDataFrame(
[(20000101, 1, "x"), (20000101, 2, "y")],
("time", "id", "v2"))
def asof_join(l, r):
# l、r is a pandas.DataFrame
# 這里是按照id分組
# 那么,l和r分別是對應id的df1和df2資料
return pd.merge_asof(l, r, on="time", by="id")
df1.groupby("id").cogroup(df2.groupby("id")).applyInPandas(
asof_join, schema="time int, id int, v1 double, v2 string").show()
# +--------+---+---+---+
# | time| id| v1| v2|
# +--------+---+---+---+
# |20000101| 1|1.0| x|
# |20000102| 1|3.0| x|
# |20000101| 2|2.0| y|
# |20000102| 2|4.0| y|
# +--------+---+---+---+
map迭代
執行以下代碼:
def filter_func(iterator):
for i, pdf in enumerate(iterator):
print(i, pdf.values.tolist())
yield pdf
df.mapInPandas(filter_func, schema=df.schema).show()
后臺看到執行結果為:
0 [[2.0, 5.0]]
0 [[2.0, 3.0]]
0 [[1.0, 1.0]]
0 [[1.0, 2.0]]
0 [[2.0, 10.0]]
前臺結果幾乎保持原樣,可以知道iterator是一個磁區迭代器,迭代出當前磁區的每一行資料都被封裝成一個pandas物件,
Pyspark與Pandas的互動
將spark的Datafream物件轉換為原生的pandas物件只需呼叫toPandas()方法即可:
sdf.toPandas()
將原生的pandas物件轉換為spark物件可以使用spark的頂級方法:
spark.createDataFrame(pdf)
習慣使用pandas的童鞋,還可以直接使用pandas-on-Spark,在spark3.2.0版本時已經匹配到pandas 1.3版本的API,通過pandas-on-Spark,我們可以完全用pandas的api操作資料,而底層執行卻是spark的并行化,
使用pandas-on-Spark最好設定一下環境變數:
import os
os.environ["PYARROW_IGNORE_TIMEZONE"] = "1"
將spark物件轉換為pandas-on-Spark物件:
df = spark.createDataFrame(
[(1, 1.0), (1, 2.0), (2, 3.0), (2, 5.0), (2, 10.0)],
("id", "v"))
pdf = df.to_pandas_on_spark()
print(type(pdf))
pdf
pandas-on-Spark物件也可以還原成spark物件:
pdf.to_spark()
另外spark提供直接將檔案讀取成pandas-on-Spark物件的api,例如:
import pyspark.pandas as ps
pdf = ps.read_csv("example_csv.csv")
ps物件與原生pandas物件的API幾乎完全一致,
ps物件相對于原生pandas物件的API幾乎一致,同時還支持一些強悍的功能,例如直接以SQL形式訪問:
ps.sql("SELECT count(*) as num FROM {pdf}")
{pdf}訪問了變數名為pdf的pandas-on-Spark物件,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/427507.html
標籤:其他