文章目錄
- Hive磁區
- 建立磁區表
- 增加磁區
- 洗掉磁區
- 查看某個表的所有磁區
- 往磁區中插入資料
- 查詢某個磁區的資料
- Hive動態磁區
- 開啟Hive的動態磁區支持
- 建立原始表并加載資料
- 建立磁區表并加載資料
- 使用動態磁區插入資料
- 多級磁區
Hive磁區
??磁區的概念和磁區表:
??磁區表指的是在創建表時指定磁區空間,實際上就是在hdfs上表的目錄下再創建子目錄,
??在使用資料時如果指定了需要訪問的磁區名稱,則只會讀取相應的磁區,避免全表掃描,提高查詢效率,
??作用:進行磁區裁剪,避免全表掃描,減少MapReduce處理的資料量,提高效率,
??一般在公司的hive中,所有的表基本上都是磁區表,通常按日期磁區、地域磁區,
??磁區表在使用的時候記得加上磁區欄位,
??磁區也不是越多越好,一般不超過3級,根據實際業務衡量,
建立磁區表
建立外部表的時候external一般和LOCATION一同使用
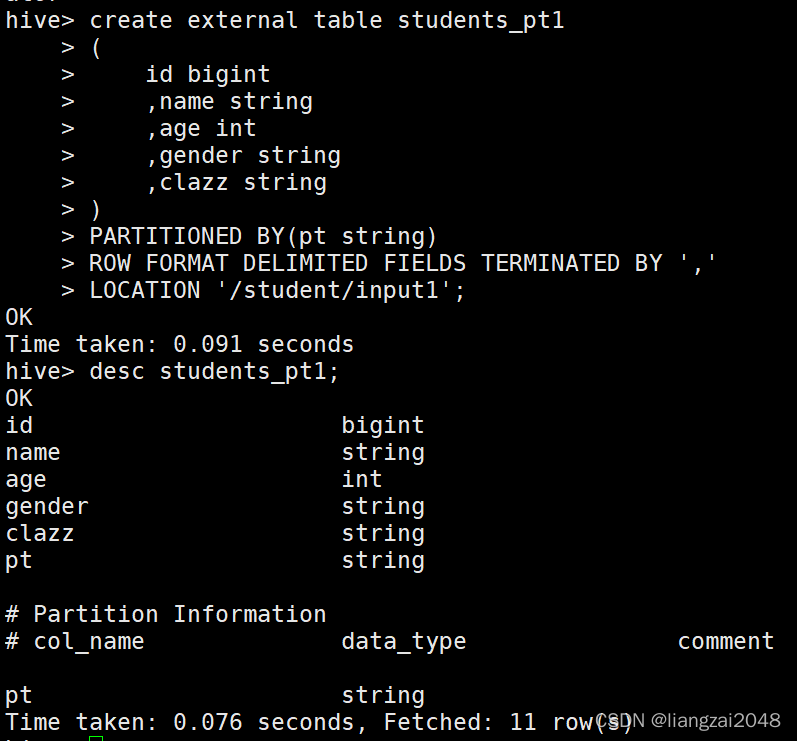
create external table students_pt1
(
id bigint
,name string
,age int
,gender string
,clazz string
)
PARTITIONED BY(pt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION '/student/input1';
??這個時候多了一個欄位:# Partition Information
增加磁區
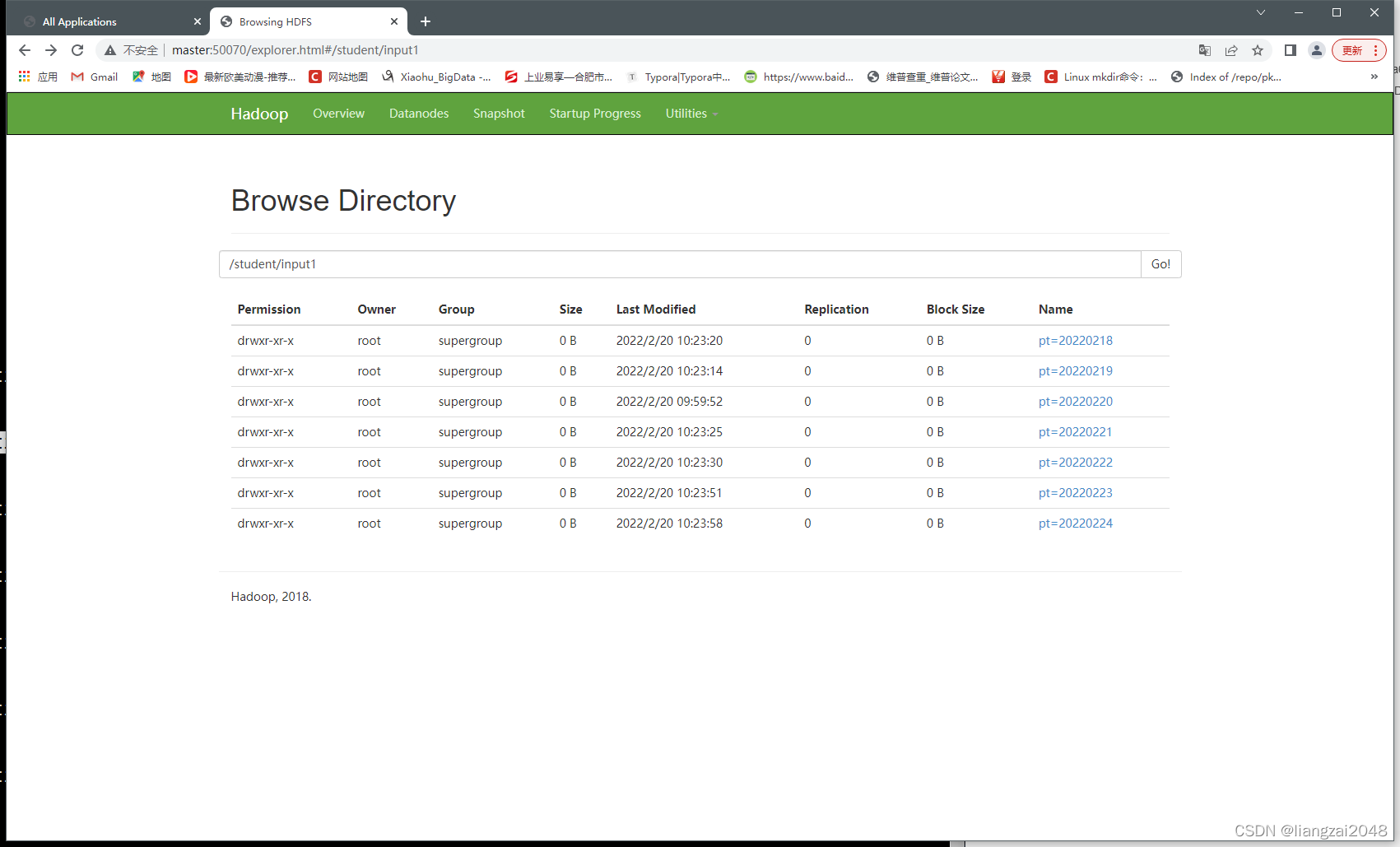
alter table students_pt1 add partition(pt='20220220');
alter table students_pt1 add partition(pt='20220219');
alter table students_pt1 add partition(pt='20220218');
alter table students_pt1 add partition(pt='20220221');
alter table students_pt1 add partition(pt='20220222');
alter table students_pt1 add partition(pt='20220223');
alter table students_pt1 add partition(pt='20220224');
洗掉磁區
alter table students_pt1 drop partition(pt='20200218');
alter table students_pt1 drop if exists partition(pt='20220218');
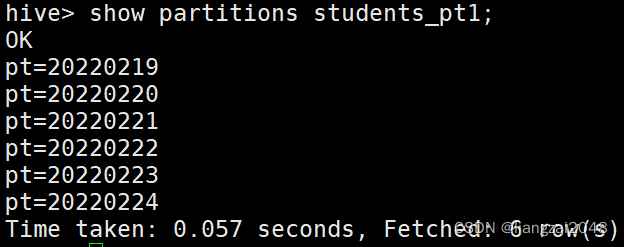
查看某個表的所有磁區
??推薦這種方式(直接從元資料中獲取磁區資訊)
show partitions students_pt1;
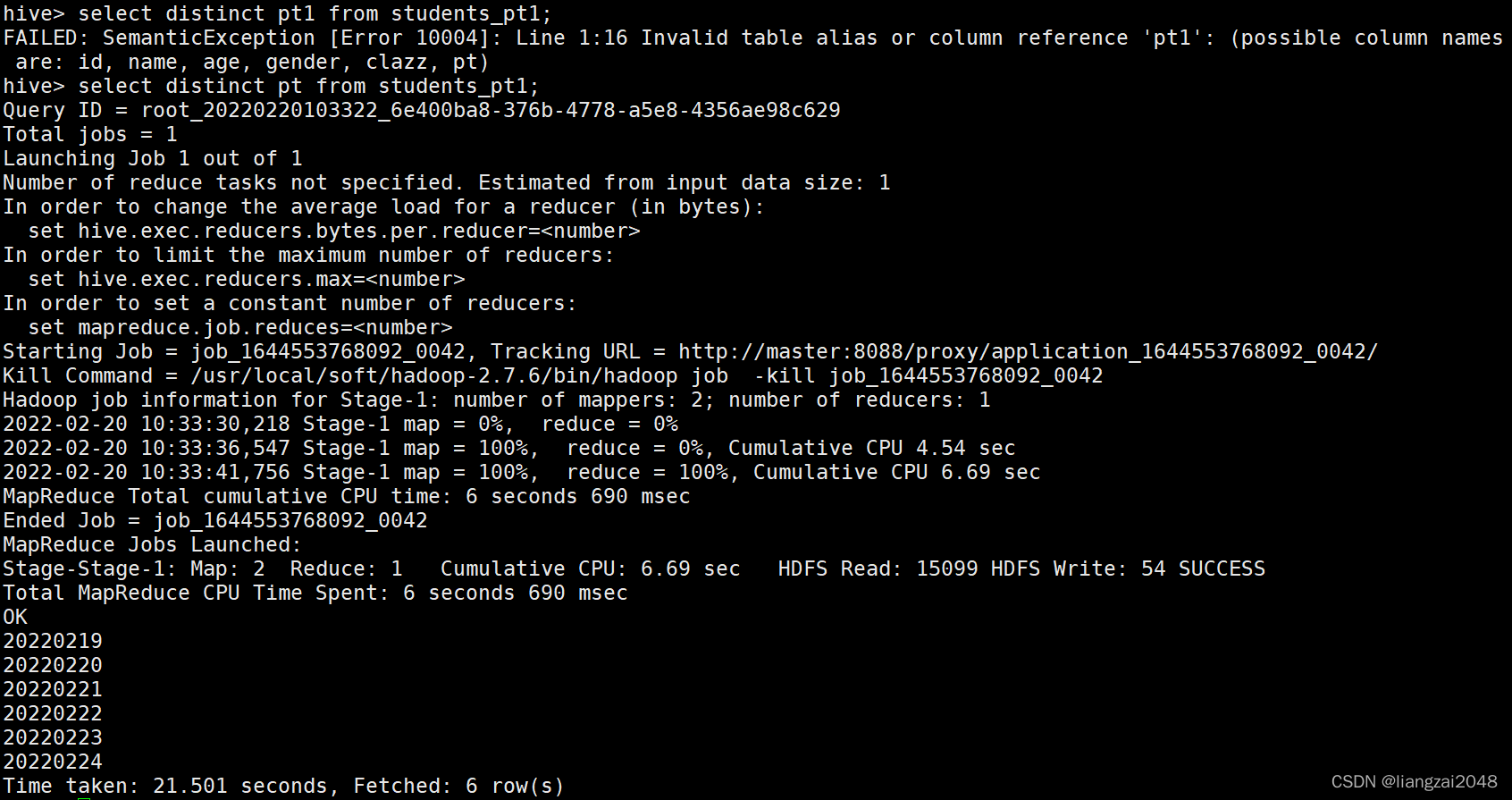
??不推薦(這種方式會執行MapReduce)
select distinct pt from students_pt1;
往磁區中插入資料
insert into table students_pt1 partition(pt='20220220') select * from student1;
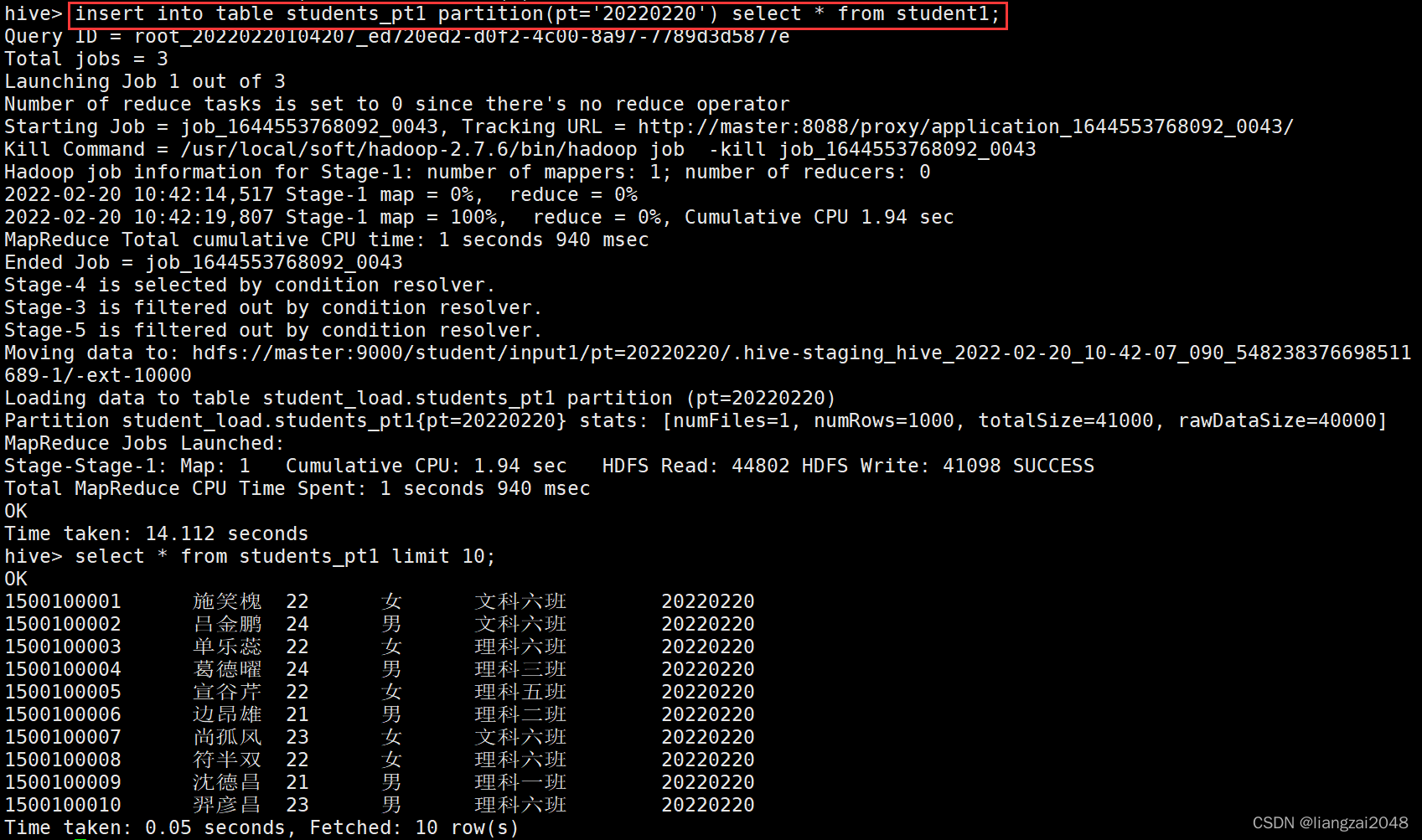
load data local inpath '/usr/local/soft/data/students.txt' into table students_pt1 partition(pt='20200221');

查詢某個磁區的資料
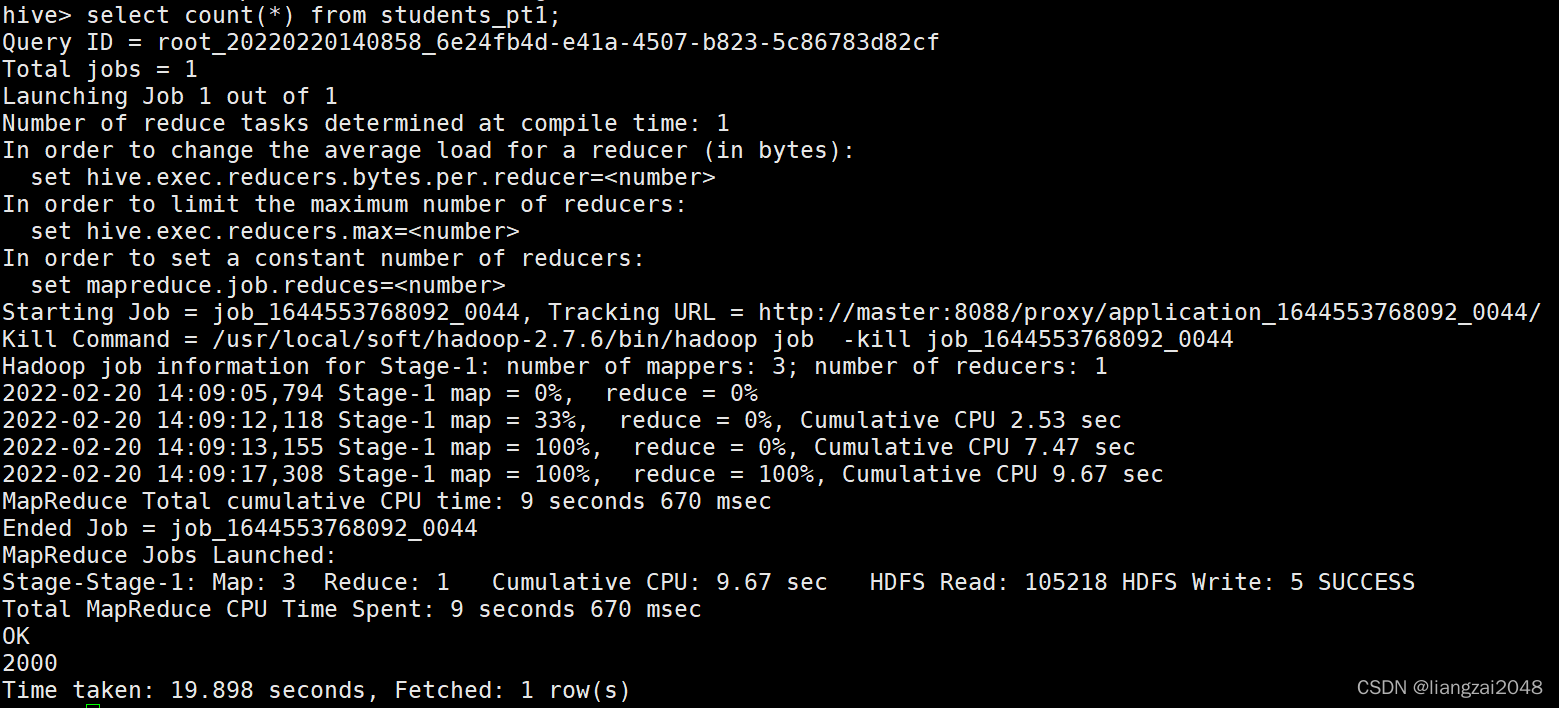
??全盤掃描,不推薦,效率低,
select count(*) from students_pt1;
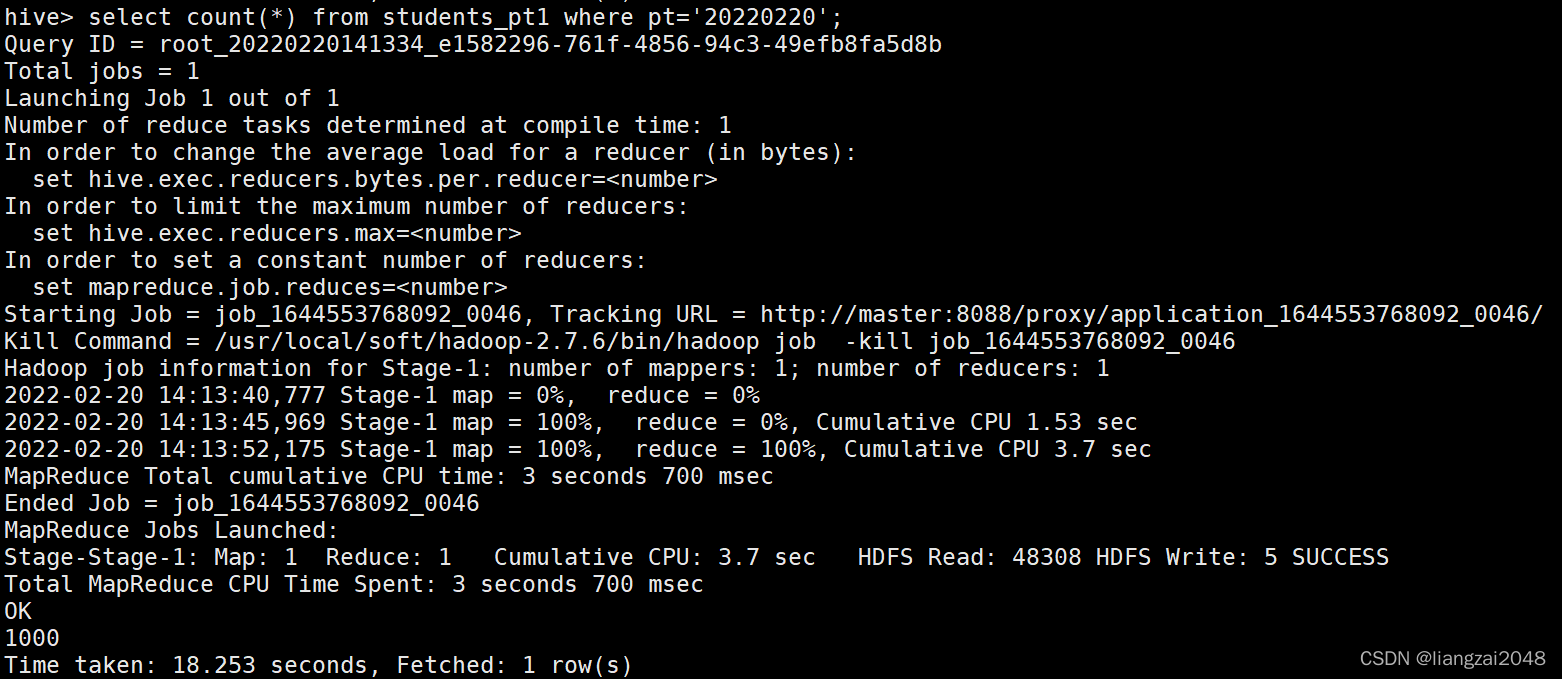
??使用where條件進行磁區裁剪,避免了全表掃描,效率高,
select count(*) from students_pt1 where pt='20220220';
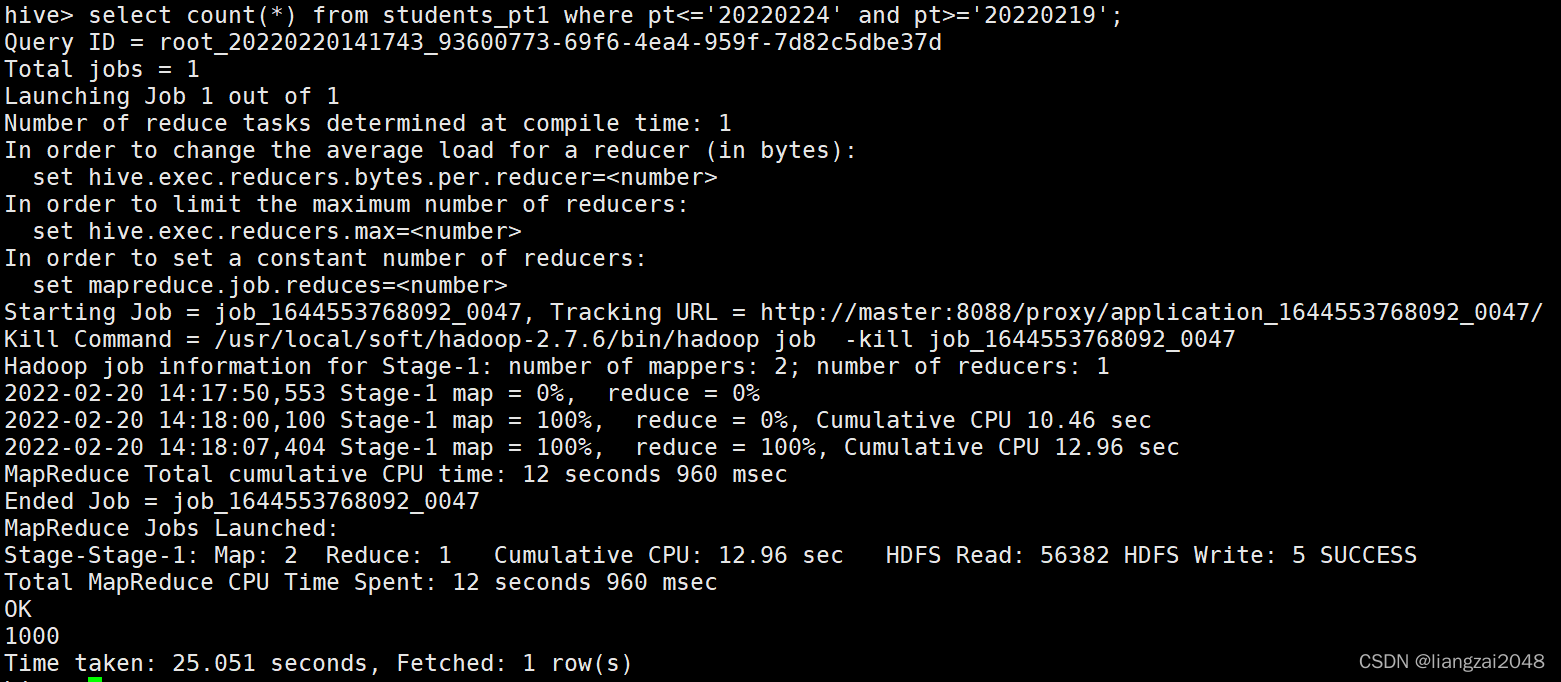
??也可以在where條件中使用非等值判斷,
select count(*) from students_pt1 where pt<='20220224' and pt>='20220219';
Hive動態磁區
??有的時候我們原始表中的資料里面包含了“日期欄位dt”,我們需要根據dt中不同的時期,分為不同的磁區,將原始表改造成磁區表,
??hive默認不開啟動態磁區,
??動態磁區:根據資料中某幾列的不同的取值 劃分 不同的磁區,
開啟Hive的動態磁區支持
# 表示開啟動態磁區
set hive.exec.dynamic.partition=true;
# 表示動態磁區模式:strict(需要配合靜態磁區一起使用)、nostrict
# strict: insert into table students_pt partition(dt='anhui',pt) select ......,pt from students;
set hive.exec.dynamic.partition.mode=nostrict;
# 表示支持的最大的磁區數量為1000,可以根據業務自己調整
set hive.exec.max.dynamic.partitions.pernode=1000;
建立原始表并加載資料
create table students_dt
(
id bigint,
name string,
age int,
gender string,
clazz string,
dt string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
load data local inpath '/usr/local/soft/data/students_dt.txt' into table students_dt;
建立磁區表并加載資料
create table students_dt_p
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(dt string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
使用動態磁區插入資料
??磁區欄位需要放在 select 的最后,如果有多個磁區欄位 同理,它是按位置匹配,不是按名字匹配
insert into students_dt_p partition(dt) select id,name,age,gender,clazz,dt from students_dt;
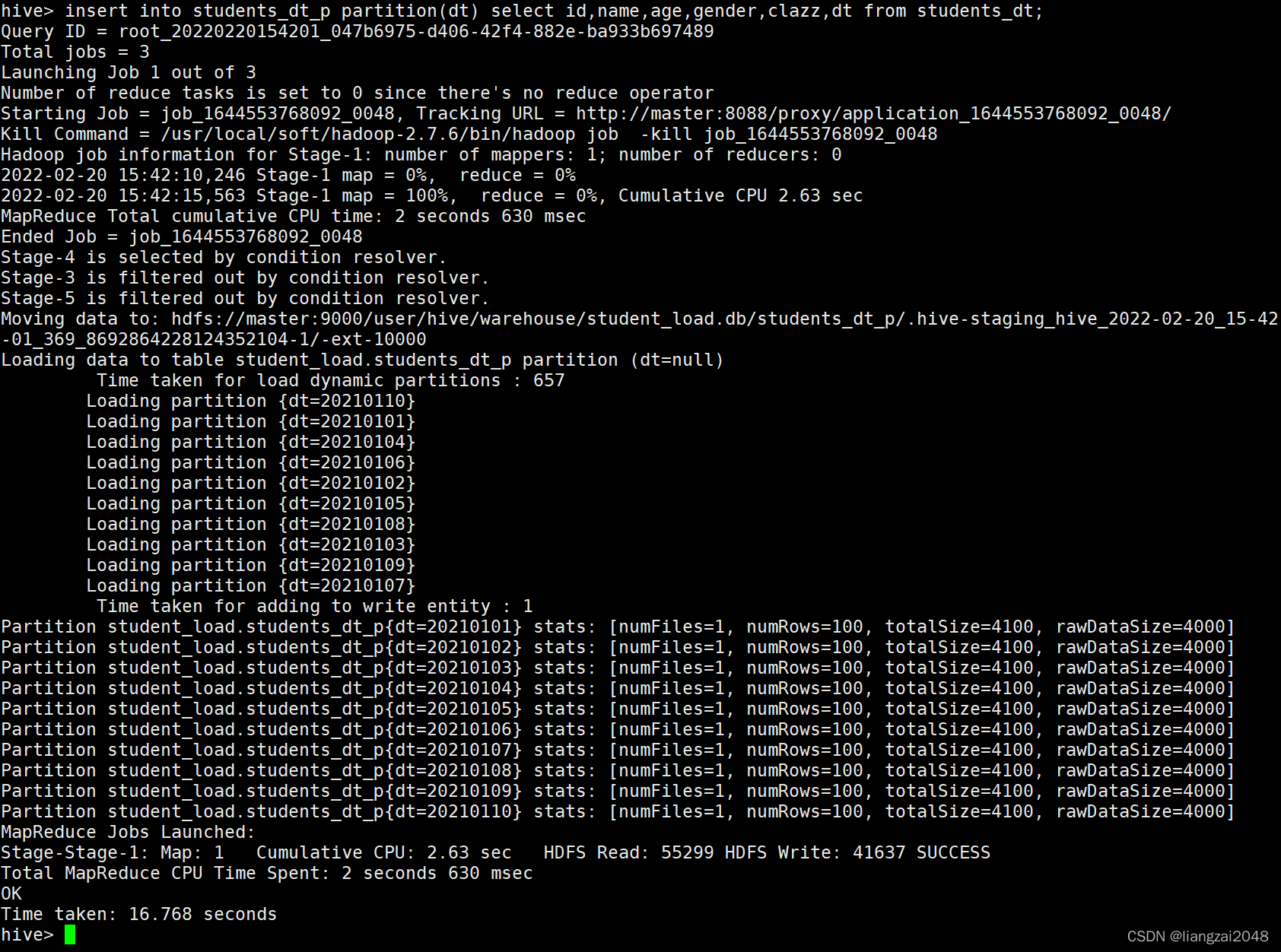
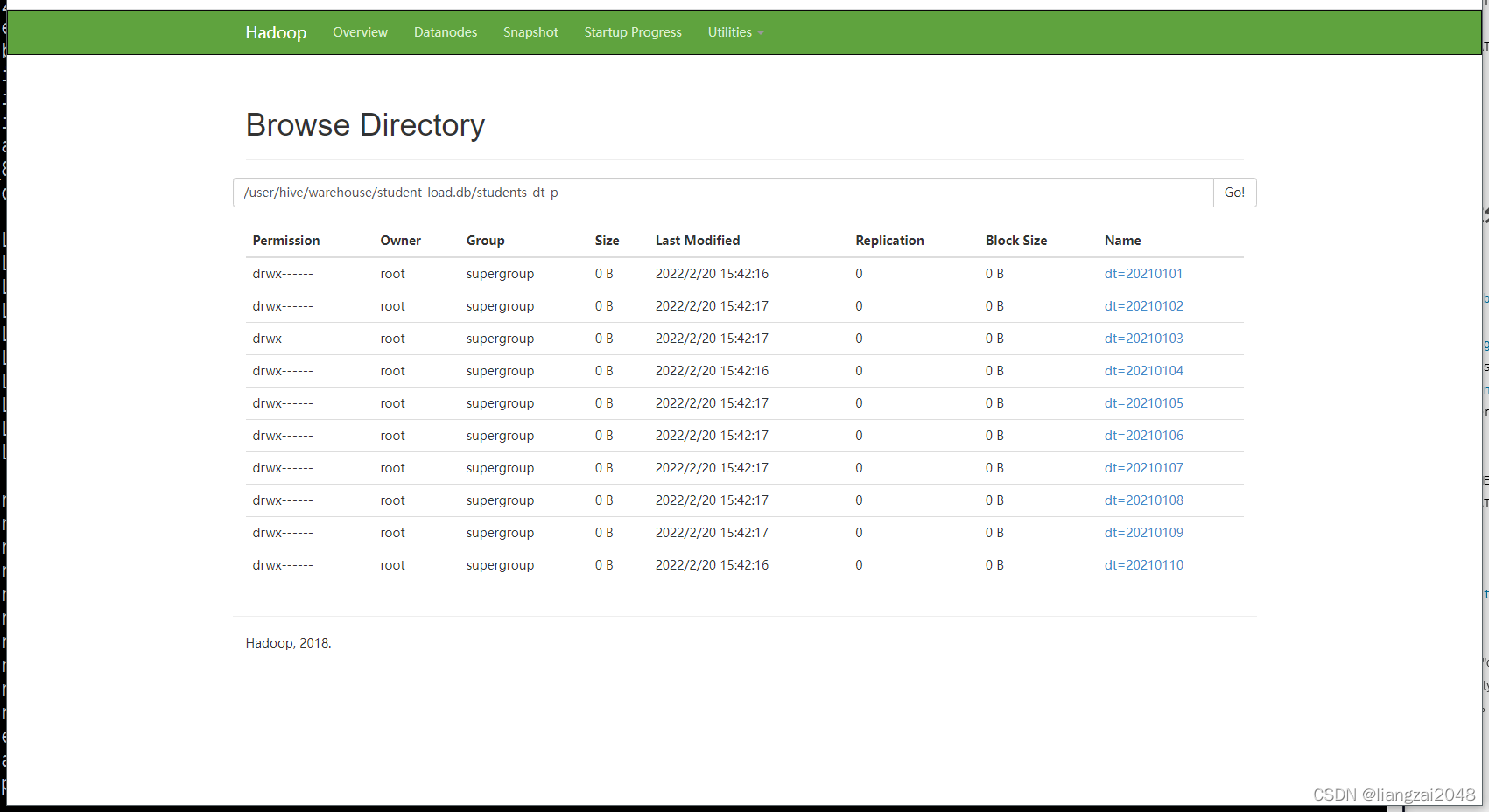
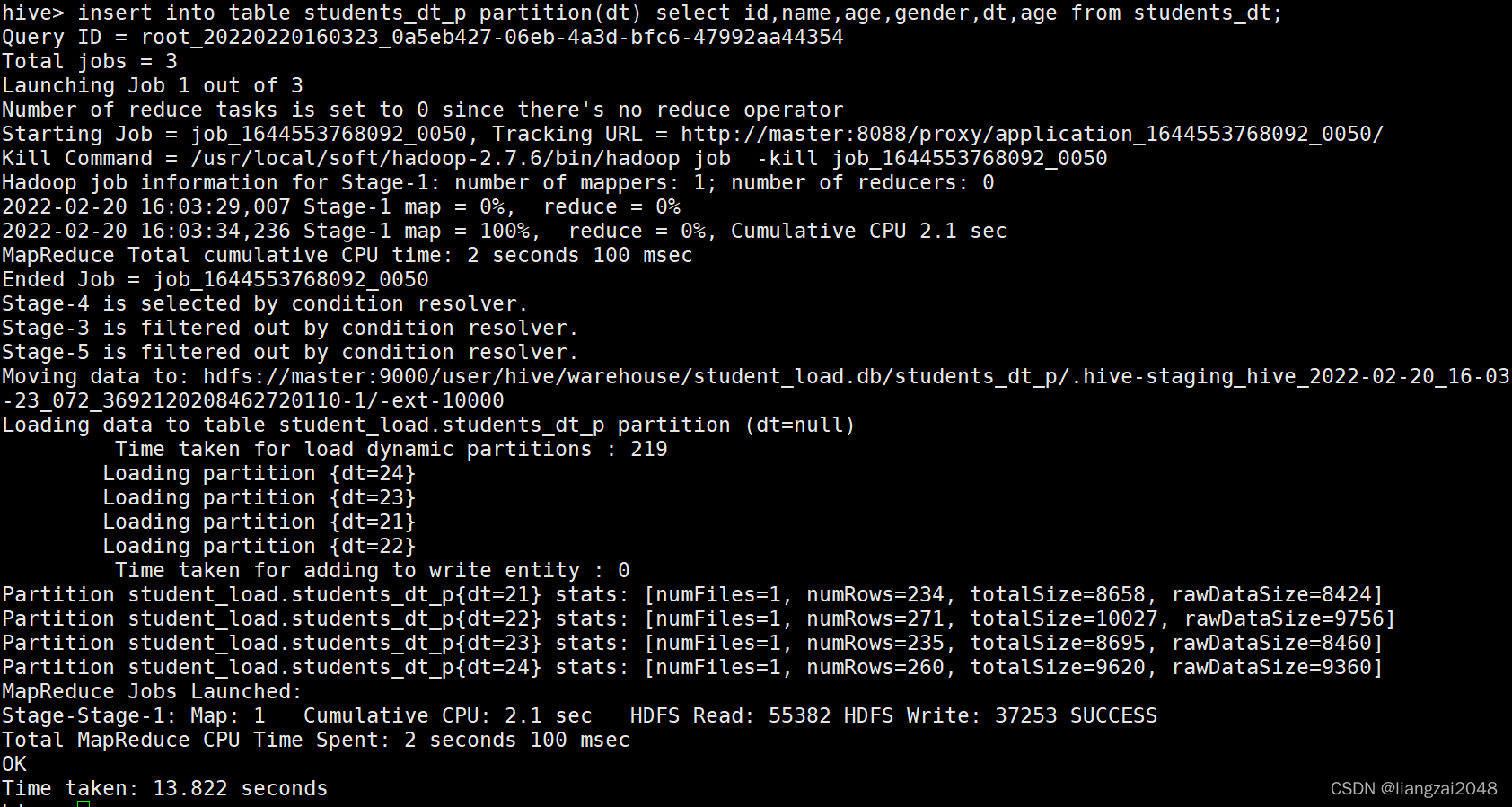
??比如下面這條陳述句會使用age作為磁區欄位,而不會使用student_dt中的dt作為磁區欄位
insert into table students_dt_p partition(dt) select id,name,age,gender,dt,age from students_dt;
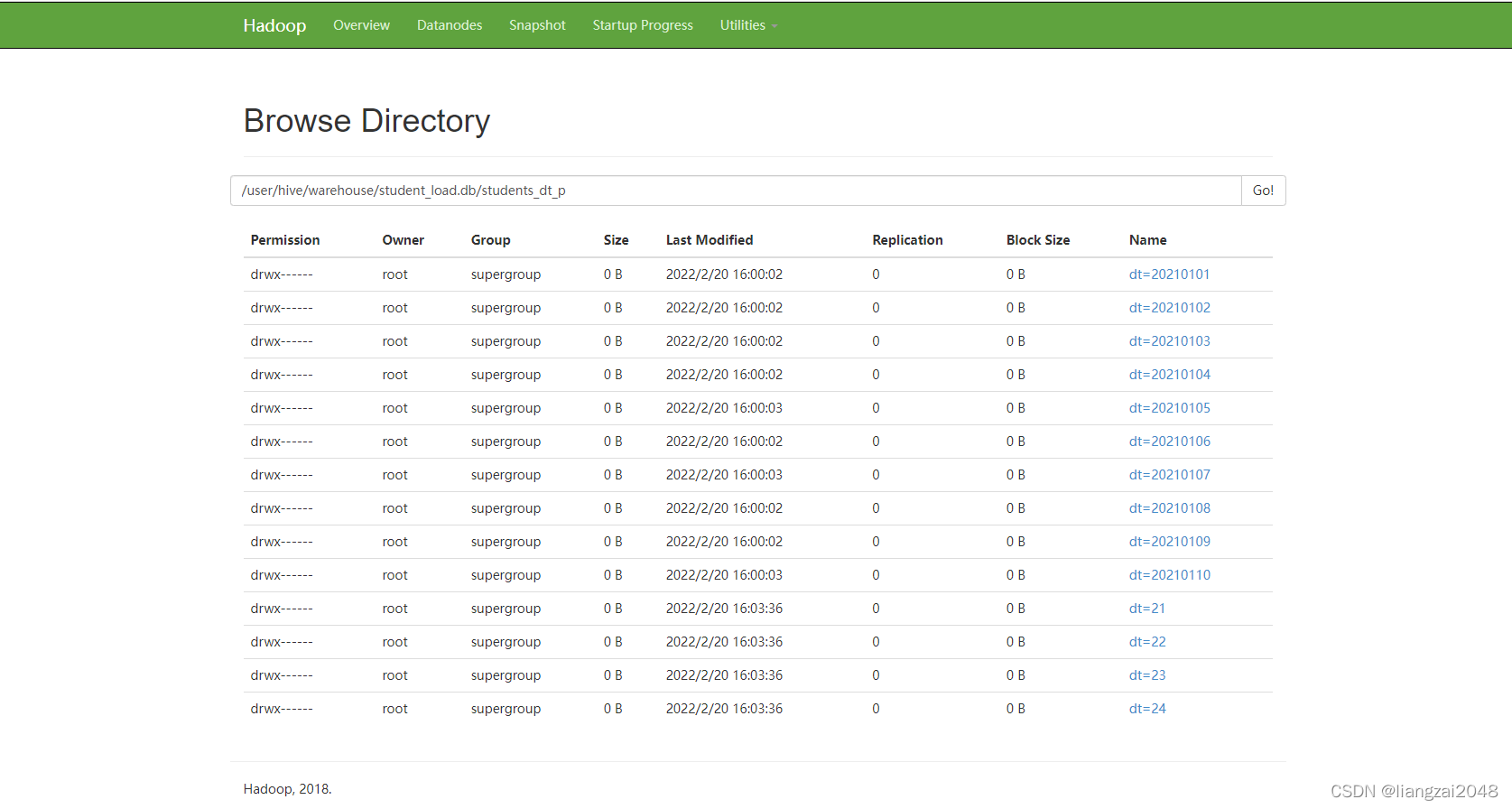
多級磁區
create table students_year_month
(
id bigint,
name string,
age int,
gender string,
clazz string,
year string,
month string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
create table students_year_month_pt
(
id bigint,
name string,
age int,
gender string,
clazz string
)
PARTITIONED BY(year string,month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
insert into table students_year_month_pt partition(year,month) select id,name,age,gender,clazz,year,month from students_year_month;
到底啦!關注靚仔學習更多的大資料知識 (?′?`?)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/429380.html
標籤:其他