目錄
- 相關鏈接
- 1 題目
- 2 思路決議
- 3 Python 實作
- 3.1 資料分析和預處理
- 3.2 預測
- 3.3 進階的預測方案和代碼
- 3.4 動態規劃
- 3.4.1 思路方案
- 3.4.2 思路2
- 3.4.3 思路3
- 3.3.2 Python實作
更新時間:2022-2-21 15:00
相關鏈接
完整代碼和參考文獻下載
https://mianbaoduo.com/o/bread/YpeclJhr
1 題目
要求開發一個模型, 這個模型只使用到目前為止的過去的每日價格流來確定,每天應該買入、 持有還是賣出他們投資組合中的資產,
2016 年 9 月 11 日, 將從 1000 美元開始, 將使用五年交易期, 從 2016 年 9 月 11 日到2021 年 9 月 10 日, 在每個交易日, 交易者的投資組合將包括現金、 黃金和位元幣[C, G, B],分別是美元、 金衡盎司和位元幣, 初始狀態為[1000,0,0], 每筆交易(購買或銷售)的傭金是交易金額的α%, 假設
α
g
o
l
d
\alpha _{gold}
αgold?= 1%,
α
b
i
t
c
o
i
n
\alpha_{bitcoin}
αbitcoin? = 2%, 持有資產沒有成本,
請注意, 位元幣可以每天交易, 但黃金只在市場開放的日子交易(即周末不交易), 這反映在定價資料檔案LBMA-GOLD.csv 和 BCHAIN-MKPRU.csv 中, 你的模型應該考慮到這個交易計劃, 但在建模程序中你只能使用其中之一,
-
開發一個模型, 僅根據當天的價格資料給出最佳的每日交易策略, 使用你的模型和策略,
在 2021 年 9 月 10 日最初的 1000 美元投資價值多少? -
提供證據證明你的模型提供了最佳策略,
-
確定該策略對交易成本的敏感度, 交易成本如何影響戰略和結果?
-
將你的策略、 模型和結果以一份不超過兩頁的備忘錄的形式傳達給交易者,
注意: 您的 PDF 總頁數不超過 25 頁, 解決方案應包括: -
一頁摘要表, 目錄, 完整的解決方案, 一到兩頁附錄, 參考文獻,
注:MCM 競賽有 25 頁的限制, 您提交的所有方面都計入 25 頁的限制(摘要頁、 目錄、 參考文獻和任何附錄), 必須在你的報告中標注你的想法、 影像和其他材料的來源參考
2 思路決議
3 Python 實作
3.1 資料分析和預處理
(1)資料分析
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
gold = pd.read_csv('./data/LBMA-GOLD.csv')
bitcoin = pd.read_csv('./data/BCHAIN-MKPRU.csv')
gold.info()
<class ‘pandas.core.frame.DataFrame’>
RangeIndex: 1265 entries, 0 to 1264 Data columns (total 2 columns):
Column Non-Null Count Dtype — ------ -------------- -----
0 Date 1265 non-null object
1 USD (PM) 1255 non-null float64
dtypes: float64(1), object(1)
# 缺失值查看
gold.isnull().any()
Date False
USD (PM) True
dtype: bool
黃金序列存在缺失值
bitcoin.isnull().any()
Date False
Value False
dtype: bool
位元幣序列沒有缺失值
可視化資料
x1 = range(len(gold))
y1 = gold['USD (PM)']
x2 = range(len(bitcoin))
y2 = bitcoin['Value']
plt.plot(x1,y1)
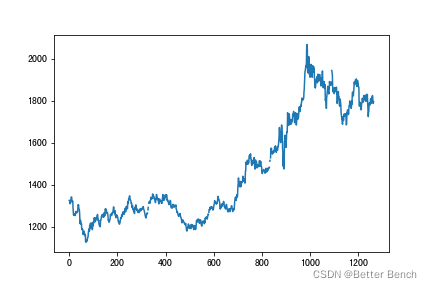
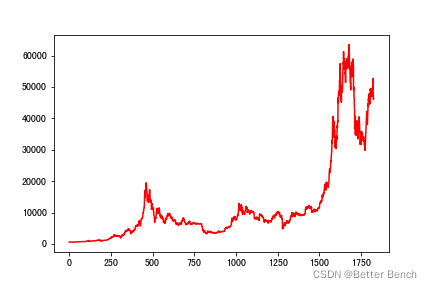
plt.plot(x2,y2,color='r')
(2)資料預處理
黃金序列是有缺失值,且周末不存在資料,時間序列是中斷的,以下采用插值法進行填充資料,將補充為完整的時間序列
gold.index = list(pd.DatetimeIndex(gold.Date))
gold_datalist = pd.date_range(start='2016-09-12',end='2021-09-10')
ts = pd.Series(len(gold_datalist)*[np.nan],index=gold_datalist)
gold_s = gold['USD (PM)']
for i in gold.index:
ts[i] = gold_s[i]
# 線性插值法
ts = ts.interpolate(method='linear')
gold_df = ts.astype(float).to_frame()
gold_df.rename(columns={0:'USD'},inplace=True)
gold_df.sort_index()
gold_df.index = range(len(gold_df))
gold_df
補充完整后,黃金的時間序列有1825條資料
3.2 預測
(1)特征工程
# 提取特征
from tsfresh import extract_features, extract_relevant_features, select_features
from tsfresh.utilities.dataframe_functions import impute
gold_df['id'] = range(len(gold_df))
extracted_features = extract_features(gold_df,column_id='id')
extracted_features.index = gold_df.index
# 去除NAN特征
extracted_features2 = impute(extracted_features)
構造訓練集
import re
# 向未來移動一個時間步長
timestep = 1
Y = list(gold_df['USD'][timestep:])
X_t = extracted_features2[:-timestep]
X = select_features(X_t, np.array(Y), fdr_level=0.5)
X = X.rename(columns = lambda x:re.sub('[^A-Za-z0-9_]+', '', x))
(2)模型訓練預測
# 劃分30%作為測驗集
s = 0.3
tra_len = int((1-s)*len(X))
test_len = len(X)-tra_len
X_train, X_test, y_train, y_test = X[0:tra_len], X[-test_len:], Y[0:tra_len],Y[-test_len:]
# 方法一
import lightgbm as lgb
# clf = lgb.LGBMRegressor(
# learning_rate=0.01,
# max_depth=-1,
# n_estimators=5000,
# boosting_type='gbdt',
# random_state=2022,
# objective='regression',
# )
# clf.fit(X=X_train, y=y_train, eval_metric='MSE', verbose=50)
# y_predict = clf.predict(X_test)
# 方法二
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
linreg = LinearRegression()
model = linreg.fit(X_train, y_train)
y_pred = linreg.predict(X_test)
預測及輸出評價指標
from sklearn import metrics
def metric_regresion(y_true,y_pre):
mse = metrics.mean_squared_error(y_true,y_pre)
mae = metrics.mean_absolute_error(y_true,y_pre)
rmse = np.sqrt(metrics.mean_squared_error(y_true,y_pre)) # RMSE
r2 = metrics.r2_score(y_true,y_pre)
print('MSE:{}'.format(mse))
print('MAE:{}'.format(mae))
print('RMSE:{}'.format(rmse))
print('R2:{}'.format(r2))
metric_regresion(y_test,y_pred)
MSE:267.91294723114646
MAE:10.630377450265746
RMSE:16.368046530699576
R2:0.9707506268528148
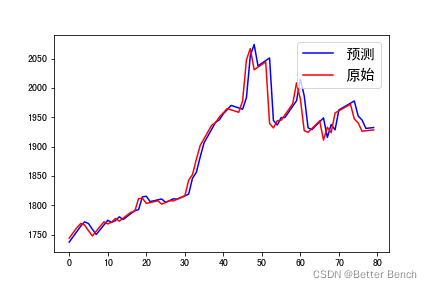
可視化預測結果
import matplotlib.pyplot as plt
plt.figure()
plt.plot(range(len(y_pred[100:180])), y_pred[100:180], 'b', label="預測")
plt.plot(range(len(y_test[100:180])), y_test[100:180], 'r', label="原始")
plt.legend(loc="upper right", prop={'size': 15})
plt.show()
3.3 進階的預測方案和代碼
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import statsmodels.api as sm
import matplotlib.pyplot as plt
import matplotlib as mpl
import itertools
plt.style.use("fivethirtyeight")
gold = pd.read_csv('LBMA-GOLD.csv')
bitcoin = pd.read_csv('BCHAIN-MKPRU.csv')
gold.index = list(pd.DatetimeIndex(gold.Date))
bitcoin.index = list(pd.DatetimeIndex(bitcoin.Date))
bitcoin['Date'] = bitcoin.index
gold['Date'] = gold.index
y=bitcoin["Value"].resample("MS").mean()#獲得每個月的平均值
print(y.isnull().sum)#5個 檢測空白值
#處理資料中的缺失項
y=y.fillna(y.bfill())#填充缺失值
plt.figure(figsize=(15,6))
plt.title("intial",loc="center",fontsize=20)
plt.plot(y)
#找合適的p d q
#初始化 p d q
p=d=q=range(0,2)
print("p=",p,"d=",d,"q=",q)
#產生不同的pdq元組,得到 p d q 全排列
pdq=list(itertools.product(p,d,q))
print("pdq:\n",pdq)
seasonal_pdq=[(x[0],x[1],x[2],12) for x in pdq]
print('SQRIMAX:{} x {}'.format(pdq[1],seasonal_pdq[1]))
# 時間序列搜索最優引數(位元幣為例,黃金同理)
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param, seasonal_order=param_seasonal, enforce_stationarity=False, enforce_invertibility=False)
results = mod.fit()
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
mod = sm.tsa.statespace.SARIMAX(y,
order=(1, 1, 1),
seasonal_order=(1, 1, 0, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print(results.summary().tables[1])
results.plot_diagnostics(figsize=(15, 12))
plt.show()
# #進行驗證預測
pred=results.get_prediction(start=pd.to_datetime('2017-01-01'),dynamic=False)
pred_ci=pred.conf_int()
print("pred ci:\n",pred_ci)#獲得的是一個預測范圍,置信區間
print("pred:\n",pred)#為一個預測物件
print("pred mean:\n",pred.predicted_mean)#為預測的平均值
#進行繪制預測影像
plt.figure(figsize=(10,6))
ax=y['1990':].plot(label="observed")
pred.predicted_mean.plot(ax=ax,label="static ForCast",alpha=.7,color='red',linewidth=2)
#在某個范圍內進行填充
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('bi Levels')
plt.legend()
plt.show()
pred_dynamic = results.get_prediction(start=pd.to_datetime('2017-01-01'), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()
# #使用動態預測
pred_dynamic = results.get_prediction(start=pd.to_datetime('2017-01-01'), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()
ax = y['2017':].plot(label='observed', figsize=(20, 15))
pred_dynamic.predicted_mean.plot(label='Dynamic Forecast', ax=ax)
ax.fill_between(pred_dynamic_ci.index,
pred_dynamic_ci.iloc[:, 0],
pred_dynamic_ci.iloc[:, 1], color='k', alpha=.25)
ax.fill_betweenx(ax.get_ylim(), pd.to_datetime('2017-01-01'), y.index[-1],
alpha=.1, zorder=-1)
ax.set_xlabel('Date')
ax.set_ylabel('bi Levels')
plt.legend()
plt.show()
# Get forecast 500 steps ahead in future
pred_uc = results.get_forecast(steps=200)#steps 可以代表(200/12)年左右
# Get confidence intervals of forecasts
pred_ci = pred_uc.conf_int()
plt.title("預測",fontsize=15,color="red")
ax = y.plot(label='observed', figsize=(20, 15))
pred_uc.predicted_mean.plot(ax=ax, label='Forecast')
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.25)
ax.set_xlabel('Date',fontsize=15)
ax.set_ylabel('bi Levels',fontsize=15)
plt.legend()
plt.show()
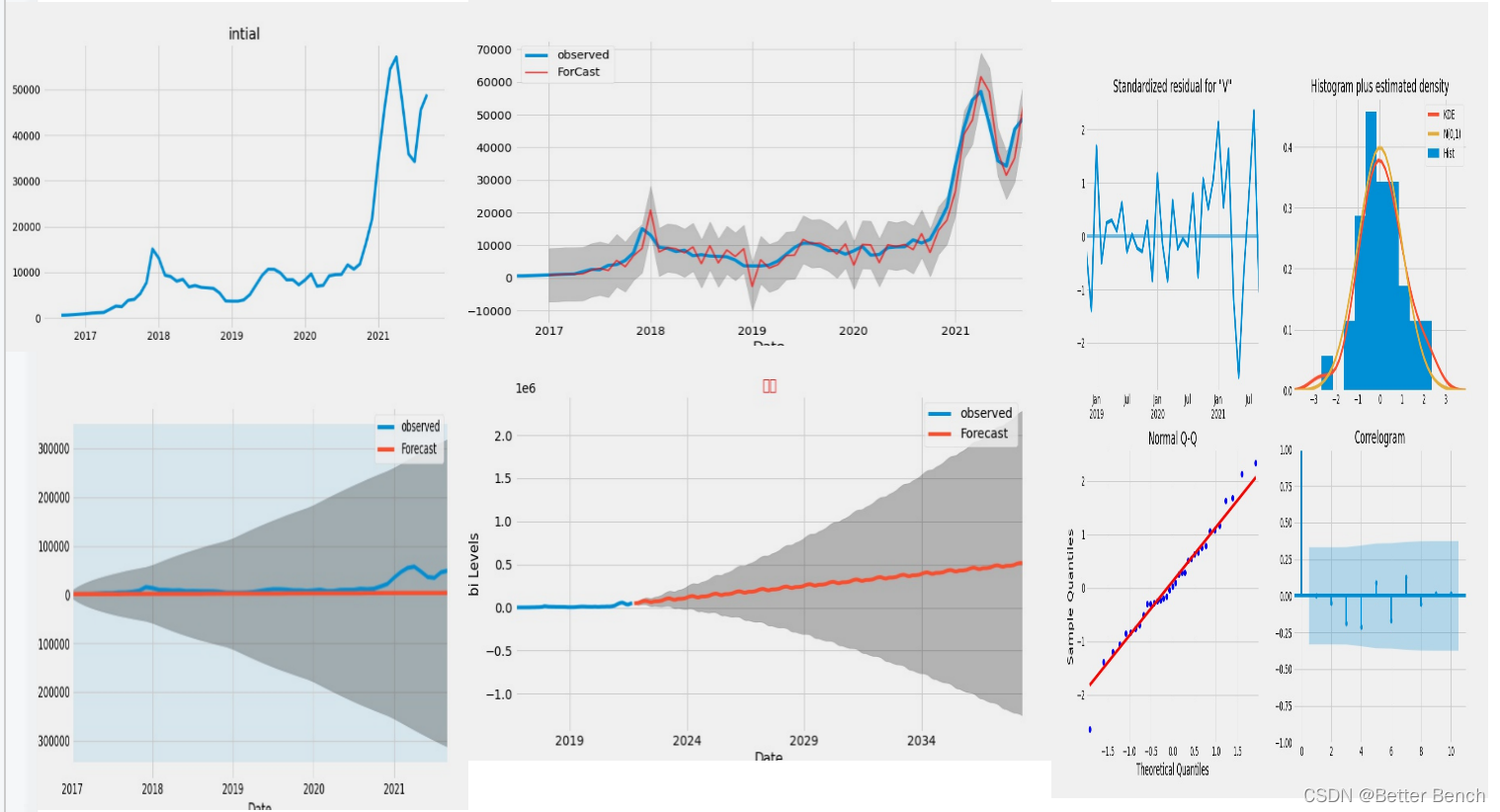
完整數學模型和代碼下載
3.4 動態規劃
3.4.1 思路方案
符號說明
w
1
w_1
w1?,
w
2
w_2
w2? 初始買入比例
P
t
P_t
Pt?,
P
t
?
1
P_{t-1}
Pt?1? 前后一天價格
diff 前后一天價格差
Y
t
Y_t
Yt? 變化收益
b% 中途賣出比例(也是買入比例)
目標函式:
m
a
x
max
max
Y
t
Y_t
Yt? =
W
1
W_1
W1?
P
黃
P_黃
P黃?+
W
2
W_2
W2?
P
比
P_比
P比?
約束條件:
1、
C
=
W
1
×
P
×
b
%
×
1
%
+
W
i
×
P
×
b
%
×
2
%
C=W_1×P × b\% ×1\%+W_i × P × b \% × 2 \%
C=W1?×P×b%×1%+Wi?×P×b%×2%(成本約束)(買出賣出成本)
2、
X
i
=
{
0
x
0
=周末
1
x
1
!=周末
X_i= \begin{cases} 0& \text{$x_0$=周末}\\ 1& \text{$x_1$ !=周末} \end{cases}
Xi?={01?x0?=周末x1? !=周末?
3、diff=
P
t
P_t
Pt?-
P
t
?
1
P_{t-1}
Pt?1? (持有會帶來的成本)
4、
0
≤
r
≤
1
0 \leq r \leq 1
0≤r≤1 風險系數約束(可用預測模型的置信區間權衡風險)
3.4.2 思路2
符號說明
目標函式 M a x ∑ i n g a i n i Max {\sum _i^n{gain_i}} Max∑in?gaini?
i表示第i天的交易,取值1-n
j表示是否是周末,取值0或1,0表示不是周末, 1表示周末
g a i n i gain_i gaini?表示第i天的最大收益
g i j g_{ij} gij?表示第i天的黃金價格
b i j b_{ij} bij?表示第i天的位元幣價格
x i j x_{ij} xij?表示第i天購入的黃金數量,單位美元/盎司
y i j y_{ij} yij?表示第i天購入的位元幣數量,單位美元/個
g_i =[5,20,56,23,4,5,6]
b_i =[2,3,4,4,5,5,66,7]
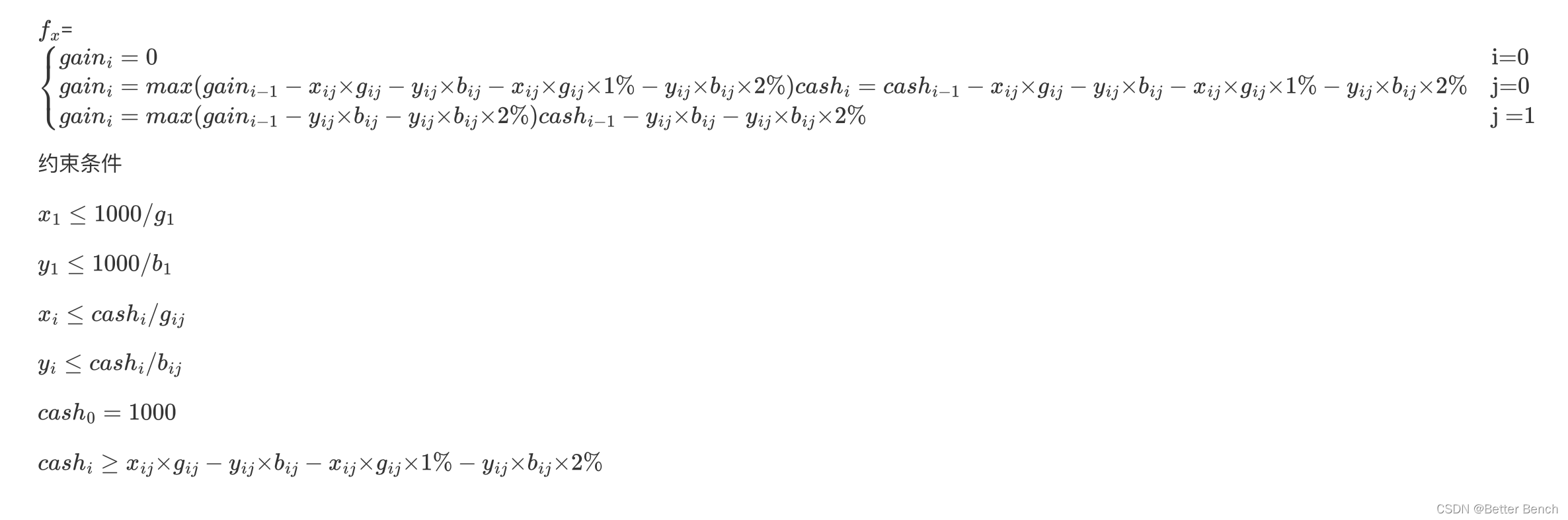
3.4.3 思路3
我們用buy表示在最大化收益的前提下,如果我們手上擁有一支股票,那么它的最低買入價格是多少,在初始時,buy 的值為prices[0] 加上手續費fee,那么當我們遍歷到第 i (i>0) 天時:
如果當前的股票價格prices[i] 加上手續費fee 小于buy,那么與其使用buy 的價格購買股票,我們不如以prices[i]+fee 的價格購買股票,因此我們將buy 更新為prices[i]+fee;
如果當前的股票價格prices[i] 大于buy,那么我們直接賣出股票并且獲得prices[i]?buy 的收益,但實際上,我們此時賣出股票可能并不是全域最優的(例如下一天股票價格繼續上升),
因此我們可以提供一個反悔操作,看成當前手上擁有一支買入價格為 prices[i] 的股票,將buy 更新為prices[i],這樣一來,如果下一天股票價格繼續上升,
我們會獲得prices[i+1]?prices[i] 的收益,加上這一天prices[i]?buy 的收益,恰好就等于在這一天不進行任何操作,而在下一天賣出股票的收益;
對于其余的情況,prices[i] 落在區間[buy?fee,buy] 內,它的價格沒有低到我們放棄手上的股票去選擇它,也沒有高到我們可以通過賣出獲得收益,因此我們可以賣出去交易位元幣,
上面的貪心思想可以濃縮成一句話,即當我們賣出一支股票時,我們就立即獲得了以相同價格并且免除手續費買入一支股票的權利,在遍歷完整個陣列prices 之后之后,我們就得到了最大的總收益,
3.3.2 Python實作
完整數學模型和代碼下載
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/429539.html
標籤:其他