導語:不知道大家會不會有天突發奇想,想知道樂高包裝上的經典紅底白字LOGO的尺寸,到底是標準統一的,還是設計師隨緣用PS拖拽出來的?
筆者偶然看到一篇文字:大家有沒有想過,樂高包裝的LEGO商標尺寸是不是隨緣的?
文章作者突然想到一個問題,如果樂高的LOGO尺寸是標準的,那能不能根據圖片的比例關系計算出包裝的尺寸?
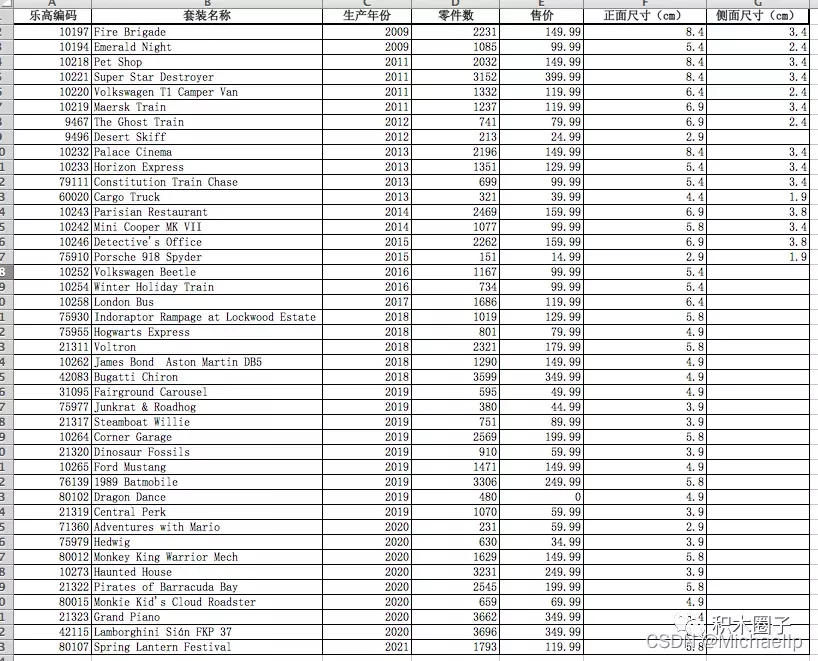
從感官上可以理解,零件數越多的套裝,包裝就越大,那么就會采用越大的LOGO,但是很快這個美好的猜測就破滅了,通過資料可以看出,不少巨型套裝,比如42115蘭博基尼的logo,卻是小的可憐
 基于上述原因,這篇文章的作者就專門認真的去研究了40+個套裝,然后把結果填寫到Excel里面,繼續分析,
基于上述原因,這篇文章的作者就專門認真的去研究了40+個套裝,然后把結果填寫到Excel里面,繼續分析,
----------------------------------------------------我是條分割線------------------------------------------------------------------------
當時作者迫于條件有限,只能用excel做簡單的分析,這讓我突發奇想, 能不能通過機器學習技術,利用多元線性回歸來預測LEGO商標尺寸,
為此,我如數家珍地將我這幾年的樂高盒子搬出來,以供研究,

逐一測量:
 記錄下編號和logo尺寸
記錄下編號和logo尺寸

一共57個套裝,加上之前文章作者的42個資料, 一共99條實驗資料(100條資料都不夠T,T)
之前文章作者用到了生產年份, 零件數, 售價這三個維度,我覺得反正仍給機械讀,何不擴展多幾個維度,于是我添加了:
人仔個數, 實物長寬高,盒子的長寬高,重量,適合歲數,
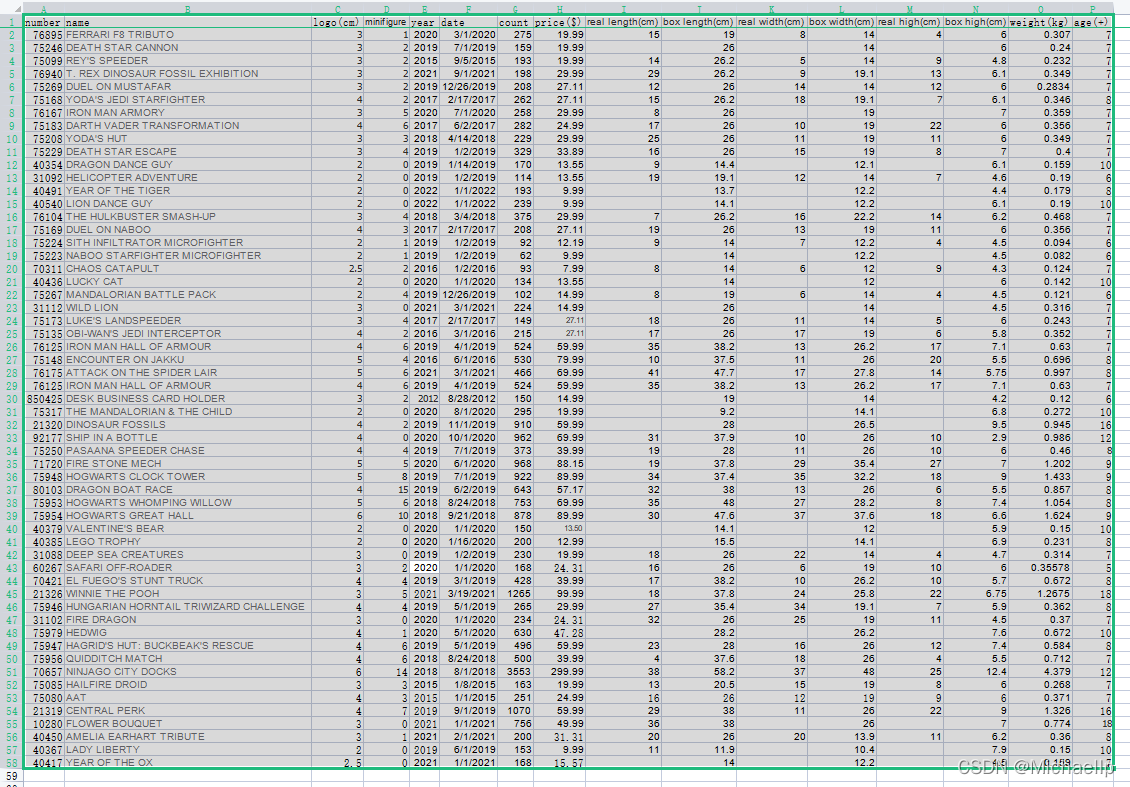
這里感謝“積木圈子”這個公眾賬號,方便了我完善資料:
Python代碼:
import pandas as pd
import numpy as np
import seaborn as sns
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
#通過read_csv來讀取我們的目的資料集
lego_logo_data = pd.read_csv("lego-logo.csv")
#清洗不需要的資料
new_data = lego_logo_data.drop(labels=['name', 'number', 'year', 'date', 'real length(cm)', 'real width(cm)', 'real high(cm)'], axis=1)
#得到我們所需要的資料集且查看其前幾列以及資料形狀
print('head:', new_data.head(), '\nShape:', new_data.shape)
#熱力圖分析
a = pd.DataFrame(new_data)
fig,ax = plt.subplots(figsize=(16,16))
sns.heatmap(np.round(a.corr(),2),linewidths = 0.5,annot=True,ax=ax, vmax=1,vmin = 0, xticklabels=True , yticklabels=True, square=True)
ax.set_yticklabels(ax.get_xticklabels(), rotation=0,fontsize=16)
ax.set_xticklabels(ax.get_xticklabels(), rotation=90,fontsize=16)
plt.show()
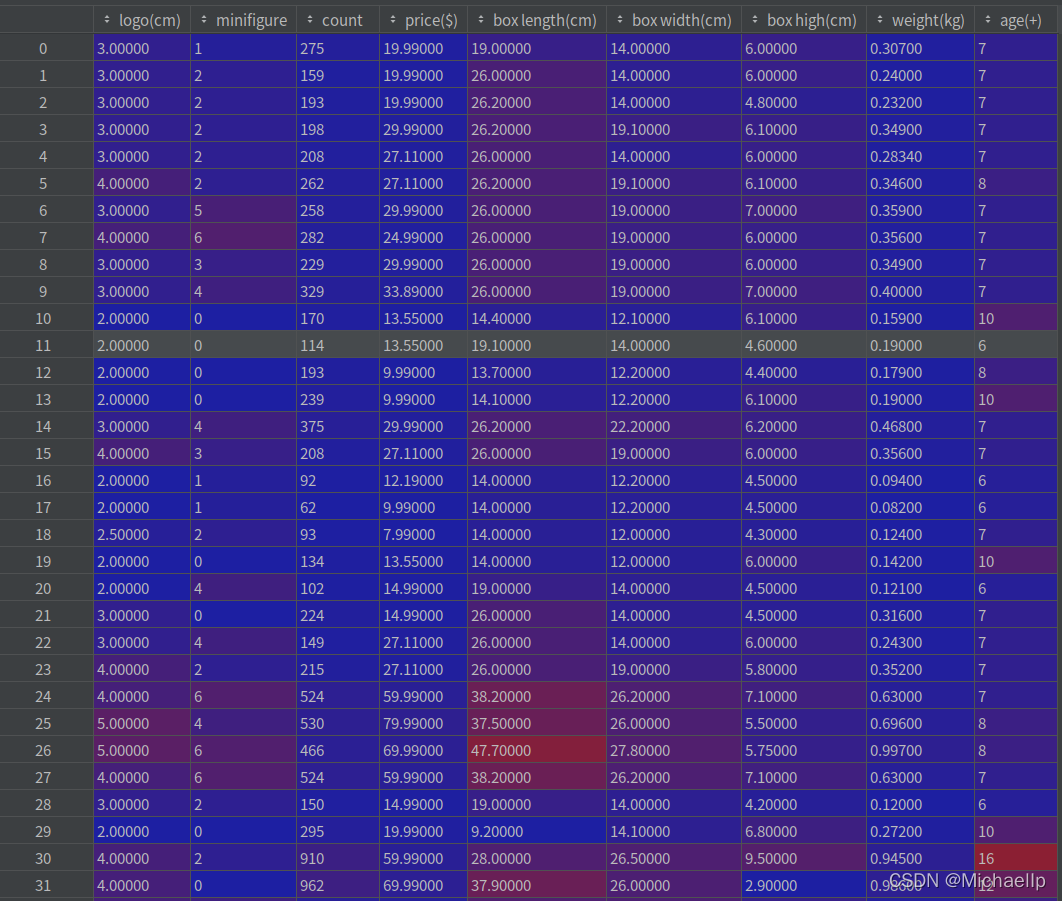
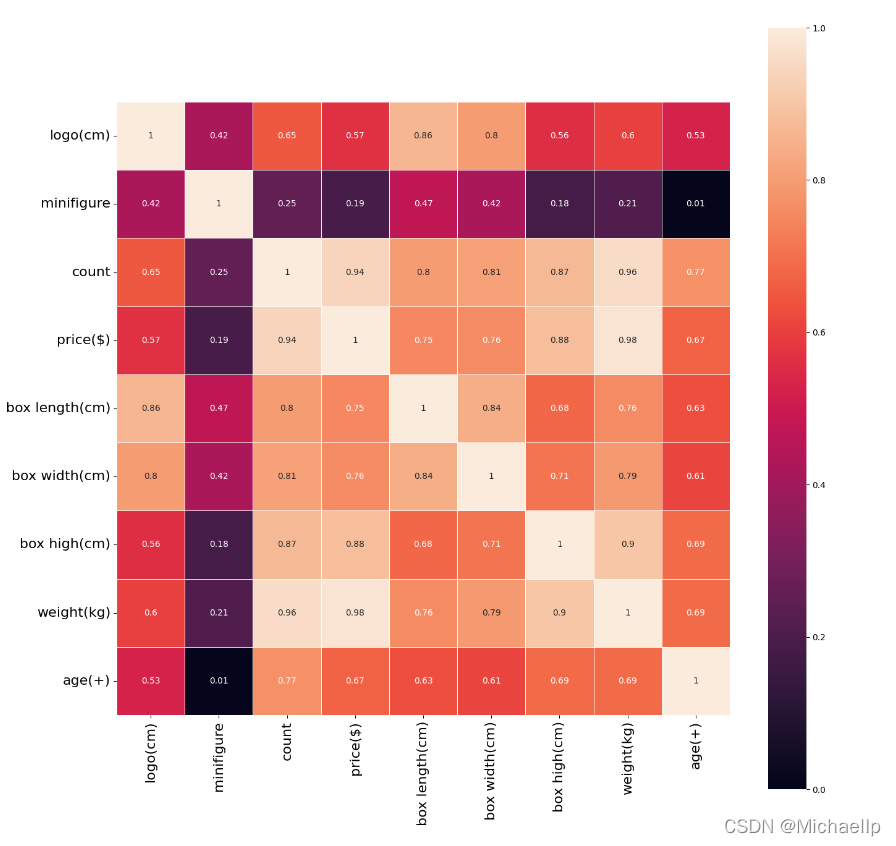
通過上面熱力圖可以看到, 和logo標簽大小相關性最大的是盒子的長度,有0.85的相關性,其次就是盒子的寬度, 有0.8的相關性,最無相關性的是人仔數量, 只有0.42的相關性(都猜到人仔沒什么相關性,沒想到比年齡的相關性還要度,年齡也有0.53的相關性),
接下來建立散點圖來查看資料集里的資料分布,
seaborn的pairplot函式繪制X的每一維度和對應Y的散點圖,通過設定size和aspect引數來調節顯示的大小和比例,
通過加入一個引數kind=‘reg’,seaborn可以添加一條最佳擬合直線和95%的置信帶,
sns.pairplot(new_data, x_vars=['minifigure', 'count', 'price($)', 'box length(cm)', 'box width(cm)', 'box high(cm)', 'weight(kg)', 'age(+)'], y_vars='logo(cm)', height=7, aspect=0.8, kind ='reg')
plt.savefig("pairplot.jpg")
plt.show()
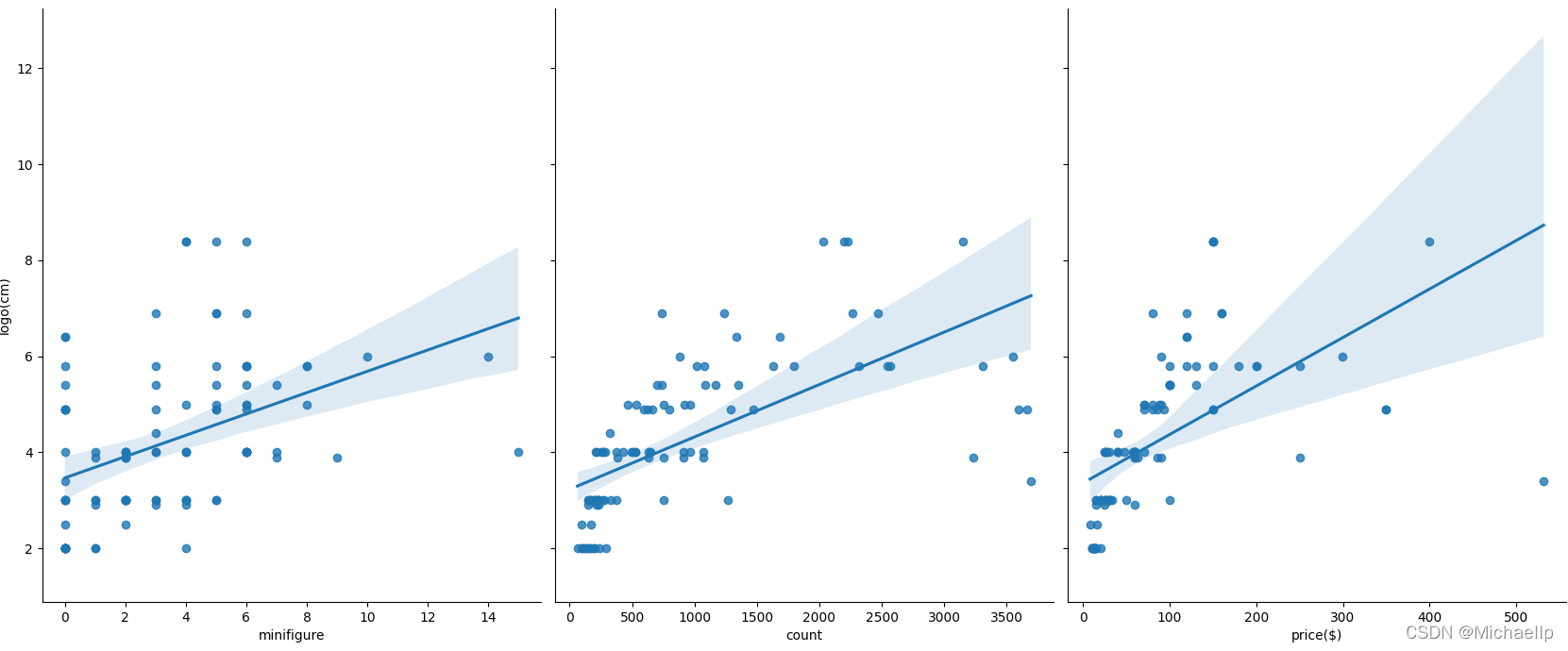
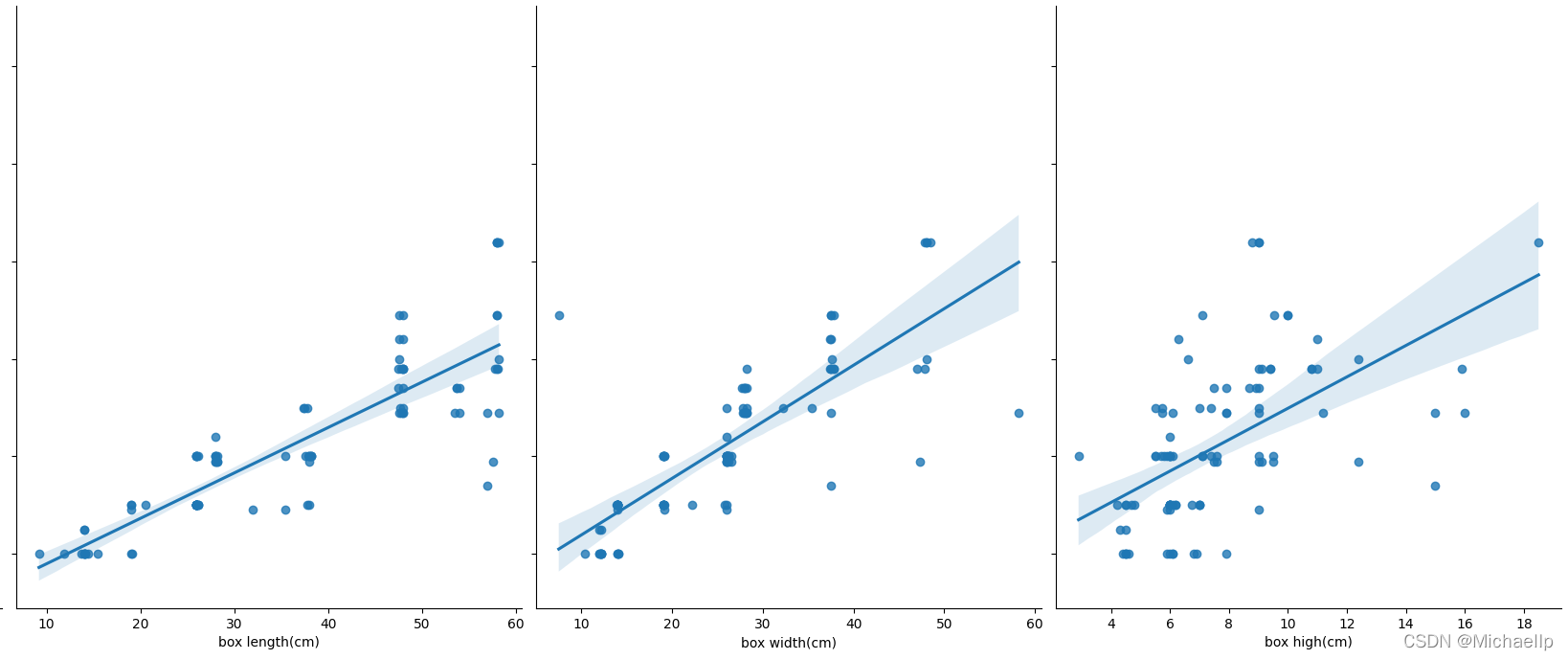
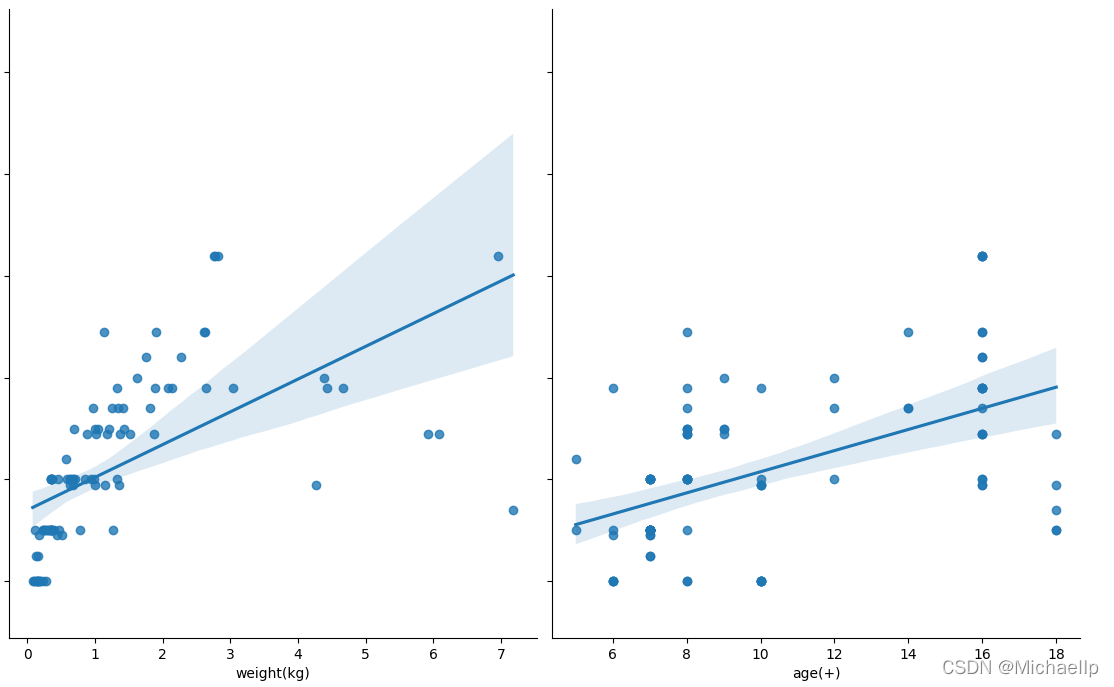 物理可見,盒子長度(box length)的散點圖分散的密度比較呈現出一條直線,
物理可見,盒子長度(box length)的散點圖分散的密度比較呈現出一條直線,
這里偷懶就沒有,沒有手寫LinearRegression(),利用sklearn里面的包來對資料集進行劃分,以此來創建訓練集和測驗集
train_size表示訓練集所占總資料集的比例
X_train,X_test,Y_train,Y_test = train_test_split(new_data.iloc[:, 1:9], new_data['logo(cm)'], train_size=.80)
print("原始資料特征:", new_data.iloc[:, 1:9].shape,
",訓練資料特征:", X_train.shape,
",測驗資料特征:", X_test.shape)
print("原始資料標簽:", new_data['logo(cm)'].shape,
",訓練資料標簽:", Y_train.shape,
",測驗資料標簽:", Y_test.shape)
model = LinearRegression()
model.fit(X_train,Y_train)
a = model.intercept_#截距
b = model.coef_#回歸系數
print("最佳擬合線:截距",a,",回歸系數:",b)
輸出:
原始資料特征: (99, 8) ,訓練資料特征: (79, 8) ,測驗資料特征: (20, 8)
原始資料標簽: (99,) ,訓練資料標簽: (79,) ,測驗資料標簽: (20,)
最佳擬合線:截距 0.041345452337445465 ,回歸系數: [-2.05281380e-02 -2.78971278e-05 -1.23070046e-02 8.95558033e-02
4.13082677e-02 7.33723245e-02 3.84568201e-01 -3.09070948e-03]
R方檢測
決定系數r平方
對于評估模型的精確度
y誤差平方和 = Σ(y實際值 - y預測值)^2
y的總波動 = Σ(y實際值 - y平均值)^2
有多少百分比的y波動沒有被回歸擬合線所描述 = SSE/總波動
有多少百分比的y波動被回歸線描述 = 1 - SSE/總波動 = 決定系數R平方
對于決定系數R平方來說
1) 回歸線擬合程度:有多少百分比的y波動刻印有回歸線來描述(x的波動變化)
2)值大小:R平方越高,回歸模型越精確(取值范圍0~1),1無誤差,0無法完成擬合
score = model.score(X_test,Y_test)
print(score)
輸出
0.8009888167527538
對線性回歸進行預測
Y_pred = model.predict(X_test)
print(Y_pred)
plt.plot(range(len(Y_pred)),Y_pred,'b',label="predict")
plt.figure()
plt.plot(range(len(Y_pred)),Y_pred,'b',label="predict")
plt.plot(range(len(Y_pred)),Y_test,'r',label="test")
plt.legend(loc="upper right") #顯示圖中的標簽
plt.xlabel("the number of set")
plt.ylabel('value of logo(cm)')
plt.savefig("ROC.jpg")
plt.show()
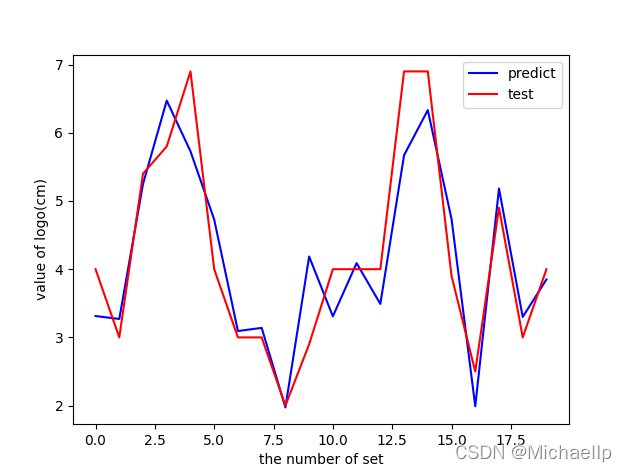 紅色是測驗資料,藍色是預測資料,R方去到0.8,看上去還行吧,
紅色是測驗資料,藍色是預測資料,R方去到0.8,看上去還行吧,
試下去掉人仔數和年齡,R方去到0.86,其實差不多,
0.8647729279218498
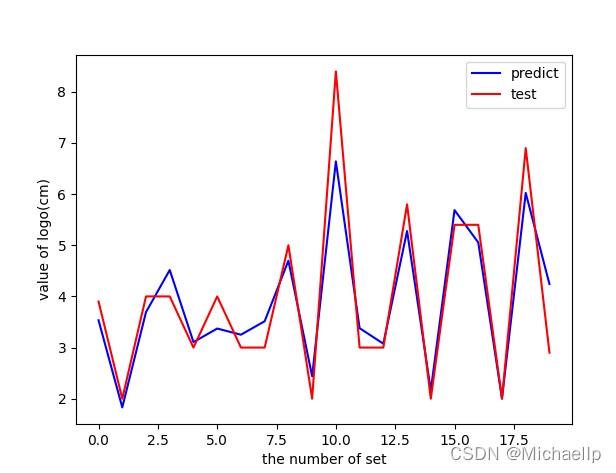
雖然還是沒達到0.9,不過也表示相關性有點強了,能基本預測到logo大小,彌補了之前作者的局限,
后記 —— 預測價格
預測商標大小好像有點大材小用,既然有這么多個維度資料,不如預測下價格,
拿回之前的熱力圖,這里加入年份(year)
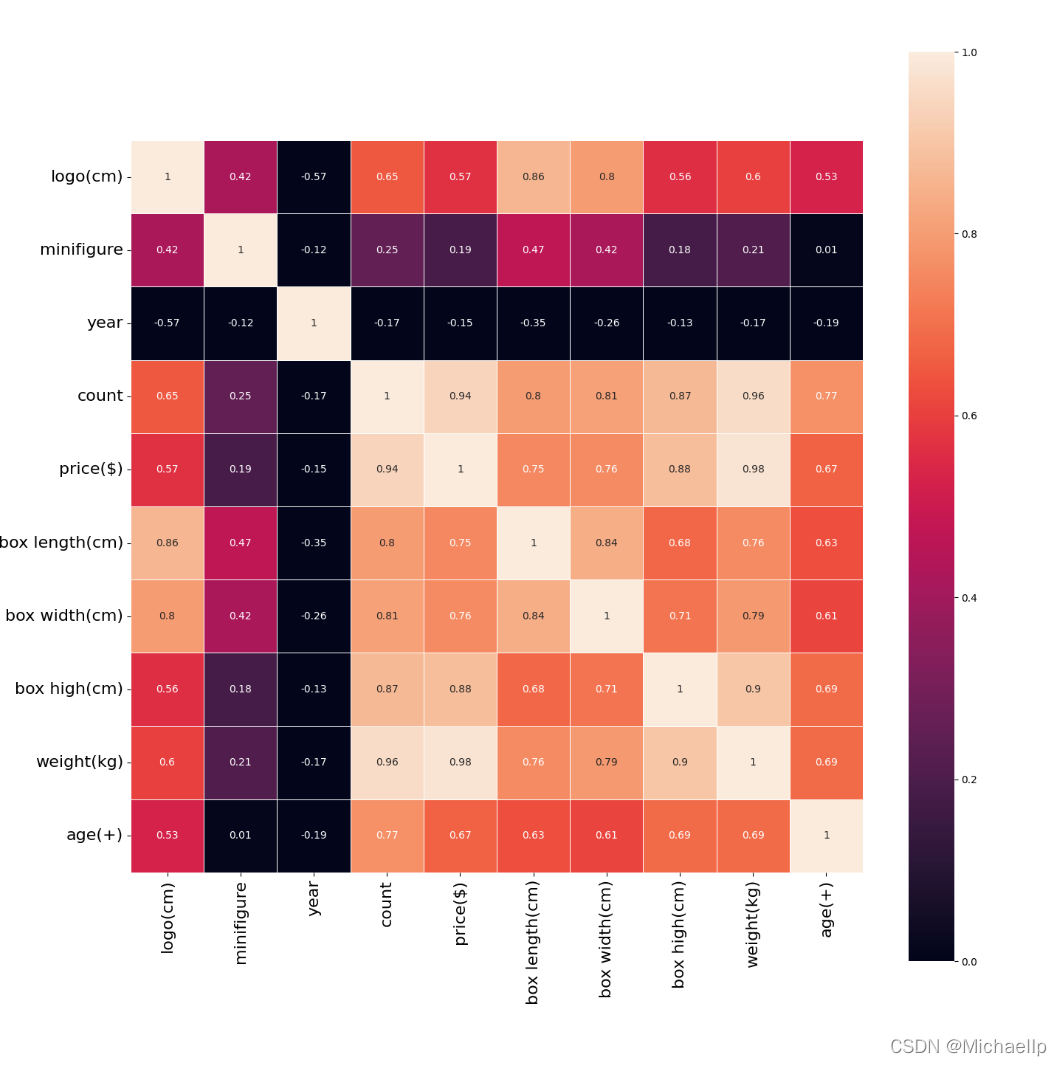
基于上面的熱力圖:
1.價格(price)那一行中, 本以為年份會和價格有關,沒想到年份和價格還呈現弱的負相關(-0.15),也就是越來越便宜,,,我覺得這可能是資料量不夠導致的,忽略它吧,

2.除此外,人仔數(minifigure)是最沒有相關性的,只有0.19. 也就是人仔越多未必賣得越貴,而事實上人仔在玩家心目中還是很占分量的,人仔才是一個樂高套裝的靈魂!

3.而相關性最大的是零件數量(count)和重量(weight),分別是0.94和0.98 ,這個就很容易理解, 一分錢一分貨,零件數越多,重量就越重, 價格也越貴,

某程度樂高還是有良心的,樂高完全可以抓住玩家心理,人仔越多賣越貴,而從資料上來說,樂高的定價都是base on零件成本,
然后我再去掉年份(year),標簽大小(logo),人仔數(minifigure),年齡(age),得出R2盡然竟然有,,,!
0.9866196081280411
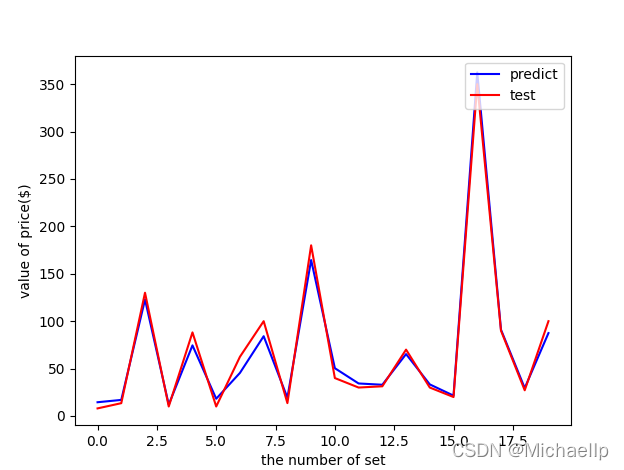 0.98的R2值可以說很高了,也就是說,base on它零件數,盒子創寬高,重量,基本上可以預測到樂高套裝的定價,
0.98的R2值可以說很高了,也就是說,base on它零件數,盒子創寬高,重量,基本上可以預測到樂高套裝的定價,
這也和坊間傳聞“一個零件一塊錢,多少零件多少錢“的概念大體一致啦,
Thanks for watching! 本期文章就到這里,如果大家有什么好的演算法或者有趣的💡idea歡迎大家留言
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431044.html
標籤:AI
上一篇:jQuery檔案上傳