1、Spark中的DataFrame是什么?
官方解釋:
DataFrame = RDD[Person] - 泛型 + Schema + SQL操作 + 優化
官方原文:A DataFrame is a DataSet organized into named columns.
中文翻譯:以列(列名,列型別,列值)的形式構成的分布式的資料集,
用大白話講:
在 Spark 中,DataFrame 是一種以 RDD 為基礎的分布式資料集,是一種特殊的RDD,是一個分布式的表,類似于傳統資料庫中的二維表格,DataFrame 與 RDD 的主要區別在于,前者帶有 schema 元資訊,即 DataFrame 所表示的二維表資料集的每一列都帶有名稱和型別,
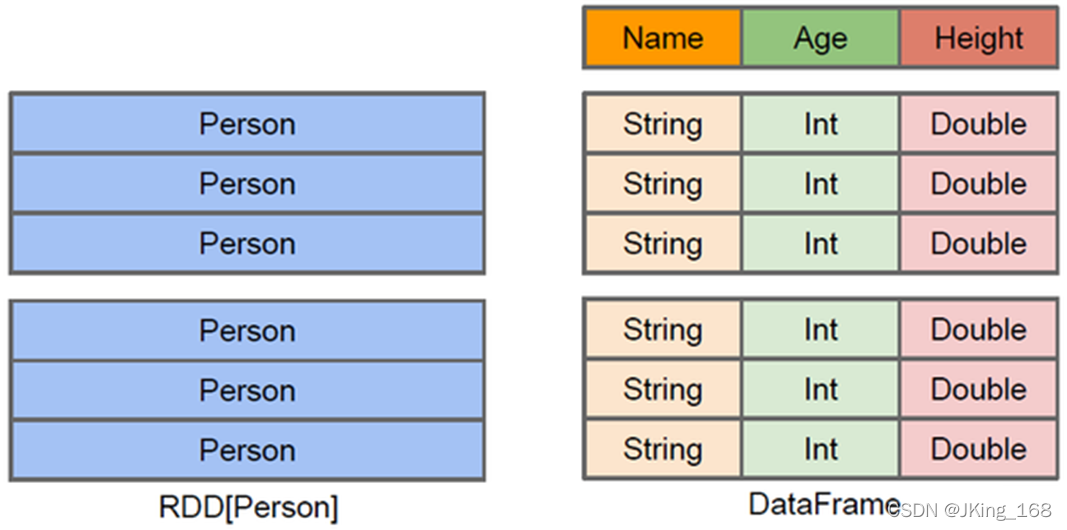
2、DataFrame中的Schema是什么?
解釋:其實就是結構表的列名與列型別,
Schema 的兩種定義方式:
- 使用 StructType 定義,是一個樣例類,屬性為 StructField 的陣列
- 使用 StructField 定義,同樣是一個樣例類,有四個屬性,其中欄位名稱和型別為必填
from pyspark.sql.types import *
# 構建 Schema 物件
schema=StructType([
StructField('name',StringType()),
StructField('age',IntegerType())
])3、DataFrame中的Row是什么?
解釋:DataFrame中每條資料封裝在Row中,Row表示每行資料,
如何構建Row物件?
from pyspark.sql import Row
# 構建 Row 物件
Row(value1, value2, value3, ...)4、構建DataFrame的幾種方式:
4.1 通過 RDD 轉換 DataFrame

4.1.1 通過 Row 構建 DataFrame
- 這種方法為使用反射方法Schema模式,Spark SQL 可以將 Row 物件的 RDD 轉換為 DataFrame,從而推斷資料型別,
from pyspark.sql import SparkSession
from pyspark import Row
if __name__ == '__main__':
# 創建背景關系物件
spark = SparkSession.builder.appName('test').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 創建RDD
rdd1 = sc.parallelize(['張三,30','李四,20','王五,50'])
# 將RDD的每個元素從String轉成Row
rdd2 = rdd1.map(lambda x:Row(name=x.split(',')[0],age=int(x.split(',')[1])))
# 直接通過RDD的Row創建DataFrame
df = spark.createDataFrame(rdd2)
# 列印DataFrame
df.printSchema()
df.show()
# 關閉退出
spark.stop()4.1.2 通過 StructedType 構建 DataFrame
- 從原始 RDD 創建元組或串列的 RDD,
- StructType 在步驟 1 中創建的 RDD 中創建由匹配的元組或串列結構表示的模式,
- 通過 createDataFrame 提供的方法將模式應用到 RDD SparkSession,
from pyspark.sql import SparkSession
from pyspark.sql.types import *
if __name__ == '__main__':
# 創建背景關系物件
spark = SparkSession.builder.appName('test').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 創建RDD
rdd1 = sc.parallelize(['張三,30','李四,20','王五,50'])
# 將RDD的每個元素從String轉成Tuple
rdd2 = rdd1.map(lambda x:(x.split(',')[0],int(x.split(',')[1])))
# 為上述tuple量身定義schema
schema = StructType([
StructField('name',StringType()),
StructField('age',IntegerType())
])
# 通過RDD和Schema創建DataFrame
df = spark.createDataFrame(rdd2,schema)
# 列印DataFrame
df.printSchema()
df.show()
# 關閉退出
spark.stop()4.1.3 通過 toDF 構建 DataFrame
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 創建背景關系物件
spark = SparkSession.builder.appName('test').master('local[*]').getOrCreate()
sc = spark.sparkContext
# 創建RDD
rdd1 = sc.parallelize(['張三,30','李四,20','王五,50'])
# 將RDD的每個元素從String轉成Tuple
rdd2 = rdd1.map(lambda x:(x.split(',')[0],int(x.split(',')[1])))
# 呼叫toDF傳輸欄位名稱,直接創建DataFrame
df = rdd2.toDF(['name','age'])
# 列印DataFrame
df.printSchema()
df.show()
# 關閉退出
spark.stop()4.1.4 通過 Pandas 構建 DataFrame
from pyspark.sql import SparkSession
import pandas as pd
from datetime import *
if __name__ == '__main__':
# 創建背景關系物件
spark=SparkSession.builder.appName('test').master('local[*]').getOrCreate()
pdf=pd.DataFrame({
'a': [1, 2, 3],
'b': [2.9, 3.9, 4.9],
'c': ['string1', 'string2', 'string3'],
'd': [date(2000, 1, 1), date(2000, 2, 1), date(2000, 3, 1)],
'e': [datetime(2000, 1, 1, 12, 0), datetime(2000, 1, 2, 12, 0), datetime(2000, 1, 3, 12, 0)]
})
print(pdf)
# spark.createDataFrame(pd.DataFrame)
df=spark.createDataFrame(pdf)
# 列印df的schema資訊
df.printSchema()
# 列印df的行資料
df.show()
# 關閉退出
spark.stop()4.2 讀取外部資料 轉化為 DataFrame
4.2.1 讀取 Json 檔案創建 DataFrame
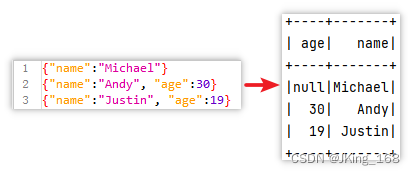
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 創建SparkSession入口
spark=SparkSession.builder.appName('test').master('local[*]').getOrCreate()
# spark.read讀取json檔案,并列印schema,和資料
df1=spark.read.json('file:///root/test.json')
df1.printSchema()
df1.show()
4.2.2 讀取 parquet 列式存盤格式檔案創建 DataFrame
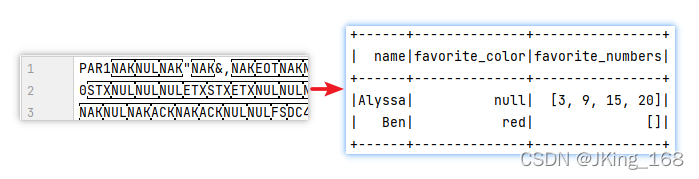
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 創建SparkSession入口
spark=SparkSession.builder.appName('test').master('local[*]').getOrCreate()
# spark.read讀取parquet檔案,并列印schema,和資料
df2=spark.read.parquet('file:///root/test.parquet')
df2.printSchema()
df2.show()4.2.3 讀取 csv 檔案創建 DataFrame

from pyspark.sql import SparkSession
if __name__ == '__main__':
# 1-創建SparkSession入口
spark=SparkSession.builder.appName('test').master('local[*]').getOrCreate()
# 2-spark.read讀取csv檔案,并列印schema,和資料
df3=spark.read.option('sep',';').option('header',True).option('inferSchema',True).csv('file:///root/test.csv')
df3.printSchema()
df3.show()
spark.stop()4.3 加載檔案時,什么時候用textFile?什么時候用read?
- 如果加載的資料結構化程度不高,則用 textFile 回傳 RDD 再處理
from pyspark.sql import SparkSession if __name__ == '__main__': spark = SparkSession.builder.appName('test').master('local[*]').getOrCreate() sc = spark.sparkContext # 讀取檔案生成 RDD rdd1 = sc.textFile('file:///root/1.txt') - 如果加載的資料結構化程度很高,比如 mysql 或 半結構化資料 json、csv,則用 read 回傳 DataFrame 再處理
from pyspark.sql import SparkSession if __name__ == '__main__': spark = SparkSession.builder.appName('test').master('local[*]').getOrCreate() sc = spark.sparkContext # 讀取檔案生成 DataFrame(特殊RDD) rdd1 = spark.read.text('file:///root/1.txt')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/431488.html
標籤:其他