系列文章目錄
實踐資料湖iceberg 第一課 入門
實踐資料湖iceberg 第二課 iceberg基于hadoop的底層資料格式
實踐資料湖iceberg 第三課 在sqlclient中,以sql方式從kafka讀資料到iceberg
實踐資料湖iceberg 第四課 在sqlclient中,以sql方式從kafka讀資料到iceberg(升級版本到flink1.12.7)
實踐資料湖iceberg 第五課 hive catalog特點
實踐資料湖iceberg 第六課 從kafka寫入到iceberg失敗問題 解決
實踐資料湖iceberg 第七課 實時寫入到iceberg
實踐資料湖iceberg 第八課 hive與iceberg集成
實踐資料湖iceberg 第九課 合并小檔案
實踐資料湖iceberg 第十課 快照洗掉
實踐資料湖iceberg 第十一課 測驗磁區表完整流程(造數、建表、合并、刪快照)
實踐資料湖iceberg 第十二課 catalog是什么
實踐資料湖iceberg 第十三課 metadata比資料檔案大很多倍的問題
實踐資料湖iceberg 第十四課 元資料合并(解決元資料隨時間增加而元資料膨脹的問題)
實踐資料湖iceberg 第十五課 spark安裝與集成iceberg(jersey包沖突)
實踐資料湖iceberg 第十六課 通過spark3打開iceberg的認知之門
實踐資料湖iceberg 第十七課 hadoop2.7,spark3 on yarn運行iceberg配置
實踐資料湖iceberg 第十八課 多種客戶端與iceberg互動啟動命令(常用命令)
實踐資料湖iceberg 第十九課 flink count iceberg,無結果問題
實踐資料湖iceberg 第二十課 flink + iceberg CDC場景(版本問題,測驗失敗)
實踐資料湖iceberg 第二十一課 flink1.13.5 + iceberg0.131 CDC(測驗成功INSERT,變更操作失敗)
實踐資料湖iceberg 第二十二課 flink1.13.5 + iceberg0.131 CDC(CRUD測驗成功)
實踐資料湖iceberg 第二十三課 flink-sql從checkpoint重啟
實踐資料湖iceberg 第二十四課 iceberg元資料詳細決議
3
文章目錄
- 系列文章目錄
- 前言
- 一、元資料管理概要
- 1.每次寫入都會成一個snapshot
- 2 讀寫并發原理
- 3 精準完善的元資料資訊:
- 二、測驗CRUD在iceberg中是如何記錄的
- 三、hdfs的影響
- 1.create表
- 2. insert
- 3.再insert
- 4.update
- 四、元資料分析
- 1.從簡單入手,看看看 version-hint.text
- 2.metadata.json檔案分析
- 2.1 v1.metadata.json (insert)
- 2.2 v2.metadata.json (insert)
- 2.3 v3.metadata.json (insert)
- 2.4 v4.metadata.json (update)
- 2.5 metadata.json特點總結
- 3. snapshot檔案分析
- 3.1 分析第一個快照
- 3.2 分析第二個snapshot
- 3.3 分析第三個快照(update)
- 四、資料變更圖解
- 總結
前言
一、元資料管理概要
1.每次寫入都會成一個snapshot
每次寫入都會成一個snapshot, 每個snapshot包含著一系列的檔案串列

2 讀寫并發原理
基于MVCC(Multi Version Concurrency Control)的機制,默認讀取檔案會從最新的的版本, 每次寫入都會產生一個新的snapshot, 讀寫相互不干擾
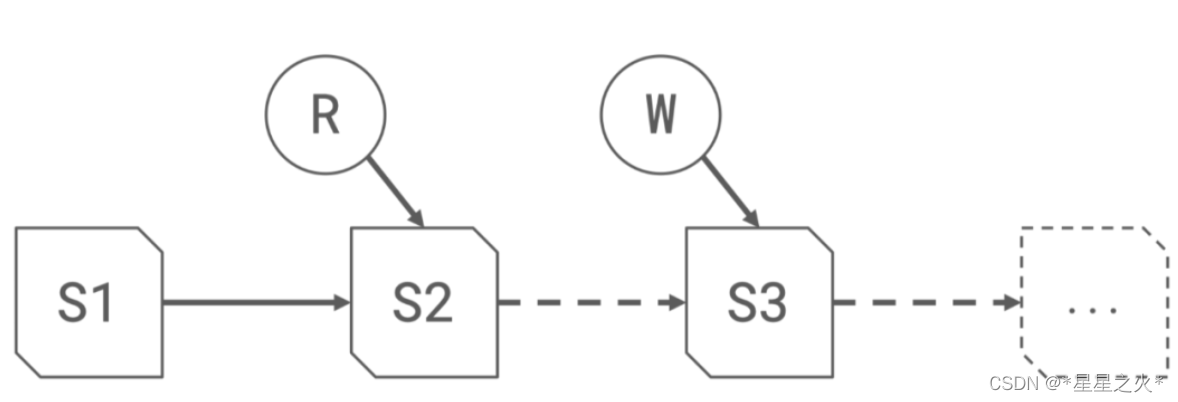
3 精準完善的元資料資訊:
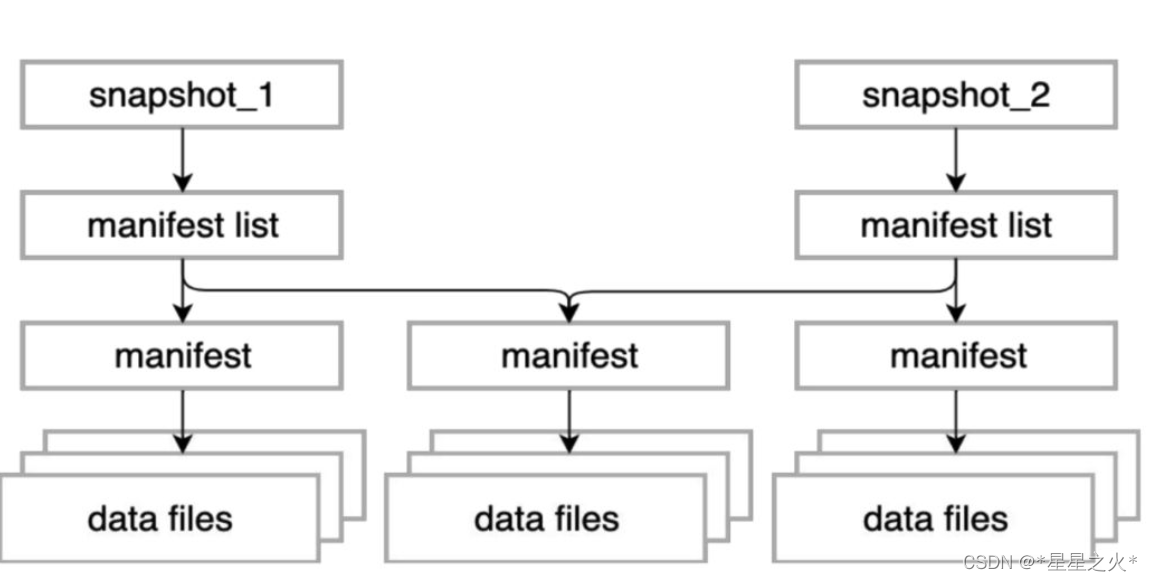
如上圖所示, snapshot資訊、manifest資訊以及檔案資訊, 一個snapshot包含一系列的manifest資訊, 每個manifest存盤了一系列的檔案串列
snapshot串列資訊:包含了詳細的manifest串列,產生snapshot的操作,以及詳細記錄數、檔案數、甚至任務資訊,充分考慮到了資料血緣的追蹤
manifest串列資訊:保存了每個manifest包含的磁區資訊
檔案串列資訊:保存了每個檔案欄位級別的統計資訊,以及磁區資訊
如此完善的統計資訊,利用查詢引擎層的條件下推,可以快速的過濾掉不必要檔案,提高查詢效率,熟悉了Iceberg 的機制,在寫入Iceberg 的表時按照需求以及欄位的分布,合理的寫入有序的資料,能夠達到非常好的過濾效果,
二、測驗CRUD在iceberg中是如何記錄的
CREATE TABLE local.db.table1 (id bigint, data string) USING iceberg;
INSERT INTO local.db.table1 VALUES (1, 'a'), (2, 'b'), (3, 'c');
INSERT INTO local.db.table1 VALUES (4, 'd'), (5, 'e'), (6, 'f');
update local.db.table1 set data='apple' where id=1;
delete from local.db.table1;
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# bin/spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.2_2.12:0.13.1 --conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions --conf spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog --conf spark.sql.catalog.spark_catalog.type=hive --conf spark.sql.catalog.local=org.apache.iceberg.spark.SparkCatalog --conf spark.sql.catalog.local.type=hadoop --conf spark.sql.catalog.local.warehouse=/tmp/iceberg/warehouse
三、hdfs的影響
1.create表
執行:
CREATE TABLE local.db.table1 (id bigint, data string) USING iceberg;
查hdfs檔案:
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -ls -R /tmp/iceberg/warehouse/db/table1
drwxrwx--- - root supergroup 0 2022-02-23 17:44 /tmp/iceberg/warehouse/db/table1/metadata
-rw-r--r-- 2 root supergroup 1169 2022-02-23 17:44 /tmp/iceberg/warehouse/db/table1/metadata/v1.metadata.json
-rw-r--r-- 2 root supergroup 1 2022-02-23 17:44 /tmp/iceberg/warehouse/db/table1/metadata/version-hint.text
2. insert
INSERT INTO local.db.table1 VALUES (1, ‘a’), (2, ‘b’), (3, ‘c’);
查詢:
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -ls -R /tmp/iceberg/warehouse/db/table1
drwxrwx--- - root supergroup 0 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet
drwxrwx--- - root supergroup 0 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata
-rw-r--r-- 2 root supergroup 5860 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7-m0.avro
-rw-r--r-- 2 root supergroup 3754 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/snap-1233304278810386445-1-e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7.avro
-rw-r--r-- 2 root supergroup 1169 2022-02-23 17:44 /tmp/iceberg/warehouse/db/table1/metadata/v1.metadata.json
-rw-r--r-- 2 root supergroup 2073 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/v2.metadata.json
-rw-r--r-- 2 root supergroup 1 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/version-hint.text
生成了三個資料檔案,猜一下應該是spark的并行度是3
3.再insert
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -ls -R /tmp/iceberg/warehouse/db/table1
drwxrwx--- - root supergroup 0 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/data
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet
-rw-r--r-- 2 root supergroup 642 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/data/00000-3-746396e4-6e79-4609-9933-867d1af62900-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/data/00001-4-1a16a1dc-b8f8-4897-8e4b-d4482618f50a-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/data/00002-5-e444dccc-e722-4bd6-8271-66875ab8ce01-00001.parquet
drwxrwx--- - root supergroup 0 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/metadata
-rw-r--r-- 2 root supergroup 5869 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/metadata/0336be7d-9a6c-45a9-af77-036cb4379b9a-m0.avro
-rw-r--r-- 2 root supergroup 5860 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7-m0.avro
-rw-r--r-- 2 root supergroup 3754 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/snap-1233304278810386445-1-e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7.avro
-rw-r--r-- 2 root supergroup 3827 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/metadata/snap-9179203419030846107-1-0336be7d-9a6c-45a9-af77-036cb4379b9a.avro
-rw-r--r-- 2 root supergroup 1169 2022-02-23 17:44 /tmp/iceberg/warehouse/db/table1/metadata/v1.metadata.json
-rw-r--r-- 2 root supergroup 2073 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/v2.metadata.json
-rw-r--r-- 2 root supergroup 3011 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/metadata/v3.metadata.json
-rw-r--r-- 2 root supergroup 1 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/metadata/version-hint.text
4.update
spark-sql (default)> select * from local.db.table1;
id data
1 a
2 b
3 c
4 d
5 e
6 f
Time taken: 0.159 seconds, Fetched 6 row(s)
spark-sql (default)> update local.db.table1 set data='apple' where id=1;
Response code
Time taken: 2.394 seconds
spark-sql (default)> select * from local.db.table1;
id data
1 apple
4 d
5 e
6 f
2 b
3 c
Time taken: 0.165 seconds, Fetched 6 row(s)
看日期,最新的時間,就是剛剛執行的效果,
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -ls -R /tmp/iceberg/warehouse/db/table1
drwxrwx--- - root supergroup 0 2022-02-23 17:50 /tmp/iceberg/warehouse/db/table1/data
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet
-rw-r--r-- 2 root supergroup 642 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/data/00000-3-746396e4-6e79-4609-9933-867d1af62900-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/data/00001-4-1a16a1dc-b8f8-4897-8e4b-d4482618f50a-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/data/00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet
-rw-r--r-- 2 root supergroup 643 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/data/00002-5-e444dccc-e722-4bd6-8271-66875ab8ce01-00001.parquet
-rw-r--r-- 2 root supergroup 686 2022-02-23 17:50 /tmp/iceberg/warehouse/db/table1/data/00112-11-2d333752-b387-43ff-ac6e-30fea75cb791-00001.parquet
drwxrwx--- - root supergroup 0 2022-02-23 17:50 /tmp/iceberg/warehouse/db/table1/metadata
-rw-r--r-- 2 root supergroup 5869 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/metadata/0336be7d-9a6c-45a9-af77-036cb4379b9a-m0.avro
-rw-r--r-- 2 root supergroup 5876 2022-02-23 17:50 /tmp/iceberg/warehouse/db/table1/metadata/c41a3e4d-1dae-4635-97af-fe57e2765335-m0.avro
-rw-r--r-- 2 root supergroup 5780 2022-02-23 17:50 /tmp/iceberg/warehouse/db/table1/metadata/c41a3e4d-1dae-4635-97af-fe57e2765335-m1.avro
-rw-r--r-- 2 root supergroup 5860 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7-m0.avro
-rw-r--r-- 2 root supergroup 3754 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/snap-1233304278810386445-1-e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7.avro
-rw-r--r-- 2 root supergroup 3827 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/metadata/snap-9179203419030846107-1-0336be7d-9a6c-45a9-af77-036cb4379b9a.avro
-rw-r--r-- 2 root supergroup 3848 2022-02-23 17:50 /tmp/iceberg/warehouse/db/table1/metadata/snap-941010551389488871-1-c41a3e4d-1dae-4635-97af-fe57e2765335.avro
-rw-r--r-- 2 root supergroup 1169 2022-02-23 17:44 /tmp/iceberg/warehouse/db/table1/metadata/v1.metadata.json
-rw-r--r-- 2 root supergroup 2073 2022-02-23 17:45 /tmp/iceberg/warehouse/db/table1/metadata/v2.metadata.json
-rw-r--r-- 2 root supergroup 3011 2022-02-23 17:48 /tmp/iceberg/warehouse/db/table1/metadata/v3.metadata.json
-rw-r--r-- 2 root supergroup 4048 2022-02-23 17:50 /tmp/iceberg/warehouse/db/table1/metadata/v4.metadata.json
-rw-r--r-- 2 root supergroup 1 2022-02-23 17:50 /tmp/iceberg/warehouse/db/table1/metadata/version-hint.text
四、元資料分析
1.從簡單入手,看看看 version-hint.text
每次修改時,version-hint.text的日期都變更,
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -cat /tmp/iceberg/warehouse/db/table1/metadata/version-hint.text
4[root@hadoop103 spark-3.2.0-bin-hadoop2.7]#
結合version-hint的名字, 猜一下就知道是獲取當前是第幾個版本
2.metadata.json檔案分析
2.1 v1.metadata.json (insert)
建表的元資訊
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -text /tmp/iceberg/warehouse/db/table1/metadata/v1.metadata.json
{
"format-version" : 1,
"table-uuid" : "756090df-d197-4881-9d8d-aea0b9354077",
"location" : "/tmp/iceberg/warehouse/db/table1",
"last-updated-ms" : 1645609485795,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "root"
},
"current-snapshot-id" : -1,
"snapshots" : [ ],
"snapshot-log" : [ ],
"metadata-log" : [ ]
2.2 v2.metadata.json (insert)
這個檔案:manifest-list, snapshot-log,metadata-log 都有資料了
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -text /tmp/iceberg/warehouse/db/table1/metadata/v2.metadata.json
{
"format-version" : 1,
"table-uuid" : "756090df-d197-4881-9d8d-aea0b9354077",
"location" : "/tmp/iceberg/warehouse/db/table1",
"last-updated-ms" : 1645609519412,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "root"
},
"current-snapshot-id" : 1233304278810386445,
"snapshots" : [ {
"snapshot-id" : 1233304278810386445,
"timestamp-ms" : 1645609519412,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1645609363060",
"added-data-files" : "3",
"added-records" : "3",
"added-files-size" : "1929",
"changed-partition-count" : "1",
"total-records" : "3",
"total-files-size" : "1929",
"total-data-files" : "3",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "/tmp/iceberg/warehouse/db/table1/metadata/snap-1233304278810386445-1-e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7.avro",
"schema-id" : 0
} ],
"snapshot-log" : [ {
"timestamp-ms" : 1645609519412,
"snapshot-id" : 1233304278810386445
} ],
"metadata-log" : [ {
"timestamp-ms" : 1645609485795,
"metadata-file" : "/tmp/iceberg/warehouse/db/table1/metadata/v1.metadata.json"
} ]
}
2.3 v3.metadata.json (insert)
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -text /tmp/iceberg/warehouse/db/table1/metadata/v3.metadata.json
{
"format-version" : 1,
"table-uuid" : "756090df-d197-4881-9d8d-aea0b9354077",
"location" : "/tmp/iceberg/warehouse/db/table1",
"last-updated-ms" : 1645609708761,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "root"
},
"current-snapshot-id" : 9179203419030846107,
"snapshots" : [ {
"snapshot-id" : 1233304278810386445,
"timestamp-ms" : 1645609519412,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1645609363060",
"added-data-files" : "3",
"added-records" : "3",
"added-files-size" : "1929",
"changed-partition-count" : "1",
"total-records" : "3",
"total-files-size" : "1929",
"total-data-files" : "3",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "/tmp/iceberg/warehouse/db/table1/metadata/snap-1233304278810386445-1-e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7.avro",
"schema-id" : 0
}, {
"snapshot-id" : 9179203419030846107,
"parent-snapshot-id" : 1233304278810386445,
"timestamp-ms" : 1645609708761,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1645609363060",
"added-data-files" : "3",
"added-records" : "3",
"added-files-size" : "1928",
"changed-partition-count" : "1",
"total-records" : "6",
"total-files-size" : "3857",
"total-data-files" : "6",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "/tmp/iceberg/warehouse/db/table1/metadata/snap-9179203419030846107-1-0336be7d-9a6c-45a9-af77-036cb4379b9a.avro",
"schema-id" : 0
} ],
"snapshot-log" : [ {
"timestamp-ms" : 1645609519412,
"snapshot-id" : 1233304278810386445
}, {
"timestamp-ms" : 1645609708761,
"snapshot-id" : 9179203419030846107
} ],
"metadata-log" : [ {
"timestamp-ms" : 1645609485795,
"metadata-file" : "/tmp/iceberg/warehouse/db/table1/metadata/v1.metadata.json"
}, {
"timestamp-ms" : 1645609519412,
"metadata-file" : "/tmp/iceberg/warehouse/db/table1/metadata/v2.metadata.json"
} ]
}
2.4 v4.metadata.json (update)
[root@hadoop103 spark-3.2.0-bin-hadoop2.7]# hadoop fs -text /tmp/iceberg/warehouse/db/table1/metadata/v4.metadata.json
{
"format-version" : 1,
"table-uuid" : "756090df-d197-4881-9d8d-aea0b9354077",
"location" : "/tmp/iceberg/warehouse/db/table1",
"last-updated-ms" : 1645609828216,
"last-column-id" : 2,
"schema" : {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
},
"current-schema-id" : 0,
"schemas" : [ {
"type" : "struct",
"schema-id" : 0,
"fields" : [ {
"id" : 1,
"name" : "id",
"required" : false,
"type" : "long"
}, {
"id" : 2,
"name" : "data",
"required" : false,
"type" : "string"
} ]
} ],
"partition-spec" : [ ],
"default-spec-id" : 0,
"partition-specs" : [ {
"spec-id" : 0,
"fields" : [ ]
} ],
"last-partition-id" : 999,
"default-sort-order-id" : 0,
"sort-orders" : [ {
"order-id" : 0,
"fields" : [ ]
} ],
"properties" : {
"owner" : "root"
},
"current-snapshot-id" : 941010551389488871,
"snapshots" : [ {
"snapshot-id" : 1233304278810386445,
"timestamp-ms" : 1645609519412,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1645609363060",
"added-data-files" : "3",
"added-records" : "3",
"added-files-size" : "1929",
"changed-partition-count" : "1",
"total-records" : "3",
"total-files-size" : "1929",
"total-data-files" : "3",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "/tmp/iceberg/warehouse/db/table1/metadata/snap-1233304278810386445-1-e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7.avro",
"schema-id" : 0
}, {
"snapshot-id" : 9179203419030846107,
"parent-snapshot-id" : 1233304278810386445,
"timestamp-ms" : 1645609708761,
"summary" : {
"operation" : "append",
"spark.app.id" : "local-1645609363060",
"added-data-files" : "3",
"added-records" : "3",
"added-files-size" : "1928",
"changed-partition-count" : "1",
"total-records" : "6",
"total-files-size" : "3857",
"total-data-files" : "6",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "/tmp/iceberg/warehouse/db/table1/metadata/snap-9179203419030846107-1-0336be7d-9a6c-45a9-af77-036cb4379b9a.avro",
"schema-id" : 0
}, {
"snapshot-id" : 941010551389488871,
"parent-snapshot-id" : 9179203419030846107,
"timestamp-ms" : 1645609828216,
"summary" : {
"operation" : "overwrite",
"spark.app.id" : "local-1645609363060",
"added-data-files" : "1",
"deleted-data-files" : "1",
"added-records" : "1",
"deleted-records" : "1",
"added-files-size" : "686",
"removed-files-size" : "643",
"changed-partition-count" : "1",
"total-records" : "6",
"total-files-size" : "3900",
"total-data-files" : "6",
"total-delete-files" : "0",
"total-position-deletes" : "0",
"total-equality-deletes" : "0"
},
"manifest-list" : "/tmp/iceberg/warehouse/db/table1/metadata/snap-941010551389488871-1-c41a3e4d-1dae-4635-97af-fe57e2765335.avro",
"schema-id" : 0
} ],
"snapshot-log" : [ {
"timestamp-ms" : 1645609519412,
"snapshot-id" : 1233304278810386445
}, {
"timestamp-ms" : 1645609708761,
"snapshot-id" : 9179203419030846107
}, {
"timestamp-ms" : 1645609828216,
"snapshot-id" : 941010551389488871
} ],
"metadata-log" : [ {
"timestamp-ms" : 1645609485795,
"metadata-file" : "/tmp/iceberg/warehouse/db/table1/metadata/v1.metadata.json"
}, {
"timestamp-ms" : 1645609519412,
"metadata-file" : "/tmp/iceberg/warehouse/db/table1/metadata/v2.metadata.json"
}, {
"timestamp-ms" : 1645609708761,
"metadata-file" : "/tmp/iceberg/warehouse/db/table1/metadata/v3.metadata.json"
} ]
}
2.5 metadata.json特點總結
- 新的metadata.json包含前面修改的全部資訊
- table1.snapshots 查的就是metadata檔案
spark-sql (default)> select * from local.db.table1.snapshots;
committed_at snapshot_id parent_id operation manifest_list summary
2022-02-23 17:45:19.412 1233304278810386445 NULL append /tmp/iceberg/warehouse/db/table1/metadata/snap-1233304278810386445-1-e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7.avro {"added-data-files":"3","added-files-size":"1929","added-records":"3","changed-partition-count":"1","spark.app.id":"local-1645609363060","total-data-files":"3","total-delete-files":"0","total-equality-deletes":"0","total-files-size":"1929","total-position-deletes":"0","total-records":"3"}
2022-02-23 17:48:28.761 9179203419030846107 1233304278810386445 append /tmp/iceberg/warehouse/db/table1/metadata/snap-9179203419030846107-1-0336be7d-9a6c-45a9-af77-036cb4379b9a.avro {"added-data-files":"3","added-files-size":"1928","added-records":"3","changed-partition-count":"1","spark.app.id":"local-1645609363060","total-data-files":"6","total-delete-files":"0","total-equality-deletes":"0","total-files-size":"3857","total-position-deletes":"0","total-records":"6"}
2022-02-23 17:50:28.216 941010551389488871 9179203419030846107 overwrite /tmp/iceberg/warehouse/db/table1/metadata/snap-941010551389488871-1-c41a3e4d-1dae-4635-97af-fe57e2765335.avro {"added-data-files":"1","added-files-size":"686","added-records":"1","changed-partition-count":"1","deleted-data-files":"1","deleted-records":"1","removed-files-size":"643","spark.app.id":"local-1645609363060","total-data-files":"6","total-delete-files":"0","total-equality-deletes":"0","total-files-size":"3900","total-position-deletes":"0","total-records":"6"}
Time taken: 0.179 seconds, Fetched 3 row(s)
3. snapshot檔案分析
3.1 分析第一個快照
把表檔案down會本地
[root@hadoop101 software]# hadoop fs -get /tmp/iceberg/warehouse/db/table1 .
分析第一個 snap
[root@hadoop101 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty snap-1233304278810386445-1-e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7.avro
22/02/23 20:09:11 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"manifest_path" : "/tmp/iceberg/warehouse/db/table1/metadata/e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7-m0.avro",
"manifest_length" : 5860,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 1233304278810386445
},
"added_data_files_count" : {
"int" : 3
},
"existing_data_files_count" : {
"int" : 0
},
"deleted_data_files_count" : {
"int" : 0
},
"partitions" : {
"array" : [ ]
},
"added_rows_count" : {
"long" : 3
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 0
}
}
分析這個manifest檔案
“manifest_path” : “/tmp/iceberg/warehouse/db/table1/metadata/e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7-m0.avro”,
[root@hadoop101 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7-m0.avro
22/02/23 20:12:15 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"status" : 1,
"snapshot_id" : {
"long" : 1233304278810386445
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 643,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 46
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "a"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "a"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
{
"status" : 1,
"snapshot_id" : {
"long" : 1233304278810386445
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 643,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 46
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0002\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "b"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0002\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "b"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
{
"status" : 1,
"snapshot_id" : {
"long" : 1233304278810386445
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 643,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 46
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0003\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "c"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0003\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "c"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
提到的這個三個data檔案,去查一下:
/tmp/iceberg/warehouse/db/table1/data/00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet
/tmp/iceberg/warehouse/db/table1/data/00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet
/tmp/iceberg/warehouse/db/table1/data/00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 1| a|
+---+----+
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 2| b|
+---+----+
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 3| c|
+---+----+
其實記錄有哪幾個資料檔案,以及他們的位置,
3.2 分析第二個snapshot
查內容:
發現:它存盤了所有snapshot資訊(目前是2個),
[root@hadoop101 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty snap-9179203419030846107-1-0336be7d-9a6c-45a9-af77-036cb4379b9a.avro
22/02/23 20:24:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"manifest_path" : "/tmp/iceberg/warehouse/db/table1/metadata/0336be7d-9a6c-45a9-af77-036cb4379b9a-m0.avro",
"manifest_length" : 5869,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 9179203419030846107
},
"added_data_files_count" : {
"int" : 3
},
"existing_data_files_count" : {
"int" : 0
},
"deleted_data_files_count" : {
"int" : 0
},
"partitions" : {
"array" : [ ]
},
"added_rows_count" : {
"long" : 3
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 0
}
}
{
"manifest_path" : "/tmp/iceberg/warehouse/db/table1/metadata/e66a1dcc-15bd-43d8-bba2-5b8a5b2726a7-m0.avro",
"manifest_length" : 5860,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 1233304278810386445
},
"added_data_files_count" : {
"int" : 3
},
"existing_data_files_count" : {
"int" : 0
},
"deleted_data_files_count" : {
"int" : 0
},
"partitions" : {
"array" : [ ]
},
"added_rows_count" : {
"long" : 3
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 0
}
}
查本manifest檔案的內容
[root@hadoop101 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty 0336be7d-9a6c-45a9-af77-036cb4379b9a-m0.avro
22/02/23 20:29:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"status" : 1,
"snapshot_id" : {
"long" : 9179203419030846107
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00000-3-746396e4-6e79-4609-9933-867d1af62900-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 642,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 45
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "d"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0004\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "d"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
{
"status" : 1,
"snapshot_id" : {
"long" : 9179203419030846107
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00001-4-1a16a1dc-b8f8-4897-8e4b-d4482618f50a-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 643,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 46
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0005\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "e"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0005\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "e"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
{
"status" : 1,
"snapshot_id" : {
"long" : 9179203419030846107
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00002-5-e444dccc-e722-4bd6-8271-66875ab8ce01-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 643,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 46
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0006\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "f"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0006\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "f"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
資料檔案對應的內容:
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00000-3-746396e4-6e79-4609-9933-867d1af62900-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 4| d|
+---+----+
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00001-4-1a16a1dc-b8f8-4897-8e4b-d4482618f50a-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 5| e|
+---+----+
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00002-5-e444dccc-e722-4bd6-8271-66875ab8ce01-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 6| f|
+---+----+
3.3 分析第三個快照(update)
分析發現:包含三個快照的內容,也就可以推出,這個檔案是存盤所有快照資訊的元資料
update分為delete和insert,觀察snap檔案如何記錄
記錄洗掉:/tmp/iceberg/warehouse/db/table1/metadata/c41a3e4d-1dae-4635-97af-fe57e2765335-m0.avro
記錄新增:/tmp/iceberg/warehouse/db/table1/metadata/c41a3e4d-1dae-4635-97af-fe57e2765335-m1.avro
上一個snapshot的manifest: /tmp/iceberg/warehouse/db/table1/metadata/0336be7d-9a6c-45a9-af77-036cb4379b9a-m0.avro
[root@hadoop101 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty snap-941010551389488871-1-c41a3e4d-1dae-4635-97af-fe57e2765335.avro
22/02/23 20:35:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"manifest_path" : "/tmp/iceberg/warehouse/db/table1/metadata/c41a3e4d-1dae-4635-97af-fe57e2765335-m1.avro",
"manifest_length" : 5780,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 941010551389488871
},
"added_data_files_count" : {
"int" : 1
},
"existing_data_files_count" : {
"int" : 0
},
"deleted_data_files_count" : {
"int" : 0
},
"partitions" : {
"array" : [ ]
},
"added_rows_count" : {
"long" : 1
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 0
}
}
{
"manifest_path" : "/tmp/iceberg/warehouse/db/table1/metadata/0336be7d-9a6c-45a9-af77-036cb4379b9a-m0.avro",
"manifest_length" : 5869,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 9179203419030846107
},
"added_data_files_count" : {
"int" : 3
},
"existing_data_files_count" : {
"int" : 0
},
"deleted_data_files_count" : {
"int" : 0
},
"partitions" : {
"array" : [ ]
},
"added_rows_count" : {
"long" : 3
},
"existing_rows_count" : {
"long" : 0
},
"deleted_rows_count" : {
"long" : 0
}
}
{
"manifest_path" : "/tmp/iceberg/warehouse/db/table1/metadata/c41a3e4d-1dae-4635-97af-fe57e2765335-m0.avro",
"manifest_length" : 5876,
"partition_spec_id" : 0,
"added_snapshot_id" : {
"long" : 941010551389488871
},
"added_data_files_count" : {
"int" : 0
},
"existing_data_files_count" : {
"int" : 2
},
"deleted_data_files_count" : {
"int" : 1
},
"partitions" : {
"array" : [ ]
},
"added_rows_count" : {
"long" : 0
},
"existing_rows_count" : {
"long" : 2
},
"deleted_rows_count" : {
"long" : 1
}
}
manifest內容:
[root@hadoop101 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty c41a3e4d-1dae-4635-97af-fe57e2765335-m1.avro
22/02/23 20:37:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"status" : 1,
"snapshot_id" : {
"long" : 941010551389488871
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00112-11-2d333752-b387-43ff-ac6e-30fea75cb791-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 686,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 52
}, {
"key" : 2,
"value" : 56
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "apple"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "apple"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
資料檔案內容(update操作: 把id=1改為 apple)
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00112-11-2d333752-b387-43ff-ac6e-30fea75cb791-00001.parquet").show
+---+-----+
| id| data|
+---+-----+
| 1|apple|
+---+-----+
哪還有個delete操作,回去看看delete是怎樣存盤的
原來在snap檔案中,記錄各個manifest_path,manaifest檔案增加,洗掉的資訊,
c41a3e4d-1dae-4635-97af-fe57e2765335-m0.avro
“deleted_rows_count” : {
“long” : 1
}
但洗掉具體哪一行,是怎樣記錄呢?
查一下這個檔案內容:
[root@hadoop101 metadata]# java -jar /opt/software/avro-tools-1.11.0.jar tojson --pretty c41a3e4d-1dae-4635-97af-fe57e2765335-m0.avro
22/02/24 10:37:36 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
{
"status" : 2,
"snapshot_id" : {
"long" : 941010551389488871
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 643,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 46
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "a"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0001\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "a"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
{
"status" : 0,
"snapshot_id" : {
"long" : 1233304278810386445
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 643,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 46
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0002\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "b"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0002\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "b"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
{
"status" : 0,
"snapshot_id" : {
"long" : 1233304278810386445
},
"data_file" : {
"file_path" : "/tmp/iceberg/warehouse/db/table1/data/00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet",
"file_format" : "PARQUET",
"partition" : { },
"record_count" : 1,
"file_size_in_bytes" : 643,
"block_size_in_bytes" : 67108864,
"column_sizes" : {
"array" : [ {
"key" : 1,
"value" : 46
}, {
"key" : 2,
"value" : 48
} ]
},
"value_counts" : {
"array" : [ {
"key" : 1,
"value" : 1
}, {
"key" : 2,
"value" : 1
} ]
},
"null_value_counts" : {
"array" : [ {
"key" : 1,
"value" : 0
}, {
"key" : 2,
"value" : 0
} ]
},
"nan_value_counts" : {
"array" : [ ]
},
"lower_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0003\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "c"
} ]
},
"upper_bounds" : {
"array" : [ {
"key" : 1,
"value" : "\u0003\u0000\u0000\u0000\u0000\u0000\u0000\u0000"
}, {
"key" : 2,
"value" : "c"
} ]
},
"key_metadata" : null,
"split_offsets" : {
"array" : [ 4 ]
},
"sort_order_id" : {
"int" : 0
}
}
}
看它指向的檔案名:一看就是第一次insert對應的檔案
00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet
00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet
00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet
讀出來看看:
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00000-0-59d54827-c03f-47f6-a6a1-fc74e6861dcf-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 1| a|
+---+----+
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00001-1-3445ca12-3b21-4795-8fd7-5124ecc16c85-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 2| b|
+---+----+
scala> spark.read.parquet("/tmp/iceberg/warehouse/db/table1/data/00002-2-6659369d-638d-432a-83e8-0da1b0abce4f-00001.parquet").show
+---+----+
| id|data|
+---+----+
| 3| c|
+---+----+
四、資料變更圖解
下圖下載后,打開,放大,能夠看清的,
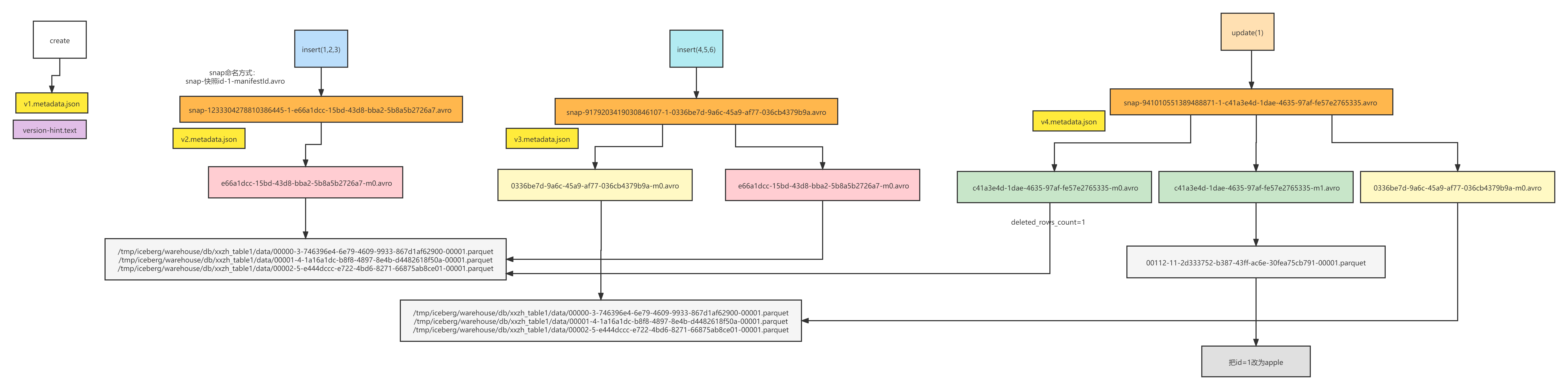
分析結論:
- 把涉及到洗掉快照對應的所有檔案(不僅僅是update的,沒變更的也記錄),進行記錄
- 沒有說明哪個記錄被改,也沒有直接改原來資料
- 重復insert也是可以寫入,怎么知道需要合并呢?
總結
manifest-list 對應一個snap檔案,這個snap檔案下記錄多個manifest檔案(本次新增、本次修改、上一次snap 新增的manifest檔案),一個manifest檔案記錄多個資料檔案,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/432153.html
標籤:其他
上一篇:Flink查詢關聯Hbase輸出
下一篇:【MQ我可以講一個小時】