應用場景,訊息可靠投遞,訊息丟失,訊息重復消費,訊息的冪等性,訊息的順序性,訊息佇列積壓,延遲佇列,訊息過期失效,訊息佇列的高可用
使用訊息佇列有解耦,擴展性,削峰,異步等功能,市面上主流的幾款mq,rabbitmq,rocketmq,kafka有各自的應用場景,kafka,有出色的吞吐量,比較強悍的性能,而且集群可以實作高可用,就是會丟資料,所以一般被用于日志分析和大資料采集,rabbitmq,訊息可靠性比較高,支持六種作業模式,功能比較全面,但是由于吞吐量比較低,訊息累積還會影響性能,加上erlang語言不好定制,所以一般使用于小規模的場景,大多數是中小企業用的比較多,rocketmq,高可用,高性能,高吞吐量,支持多種訊息型別,比如同步,異步,順序,廣播,延遲,批量,過濾,事務等等訊息,功能比較全面,只不過開源版本比不上商業版本的,加上開發這個中間件的大佬寫的檔案不多,檔案不太全,這也是它的一個缺點,不過這個中間件可以作用于幾乎全場景,
引入訊息中間件也會帶來很多問題,先說說訊息丟失,生產者往訊息佇列發送訊息,訊息佇列往消費者發送訊息,會有丟訊息的可能,訊息佇列也有可能丟訊息,通常MQ存盤時都會先寫入作業系統的快取頁中,然后再由作業系統異步的將訊息寫入硬碟,這個中間有個時間差,就可能會造成訊息丟失,如果服務掛了,快取中還沒有來得及寫入硬碟的訊息就會發生訊息丟失,不同的訊息中間件對于訊息丟失也有不同的解決方案,先說說最容易丟失訊息的kafka吧,生產者發訊息給Kafka Broker:訊息寫入Leader后,Follower是主動與Leader進行同步,然后發ack告訴生產者收到訊息了,這個程序kafka提供了一個引數,request.required.acks屬性來確認訊息的生產,0表示不進行訊息接收是否成功的確認,發生網路抖動訊息丟了,生產者不校驗ACK自然就不知道丟了,1表示當Leader接收成功時確認,只要Leader存活就可以保證不丟失,保證了吞吐量,但是如果leader掛了,恰好選了一個沒有ACK的follower,那也丟了,-1或者all表示Leader和Follower都接收成功時確認,可以最大限度保證訊息不丟失,但是吞吐量低,降低了kafka的性能,一般在不涉及金額的情況下,均衡考慮可以使用1,保證訊息的發送和性能的一個平衡,Kafka Broker 訊息同步和持久化:Kafka通過多磁區多副本機制,可以最大限度保證資料不會丟失,如果資料已經寫入系統快取中,但是還沒來得及刷入磁盤,這個時候機器宕機,或者沒電了,那就丟訊息了,當然這種情況很極端,Kafka Broker 將訊息傳遞給消費者:如果消費這邊配置的是自動提交,萬一消費到資料還沒處理完,就自動提交offset了,但是此時消費者直接宕機了,未處理完的資料丟失了,下次也消費不到了,所以為了避免這種情況,需要將配置改為,先消費處理資料,然后手動提交,這樣訊息處理失敗,也不會提交成功,沒有丟訊息,
rabbitmq整個訊息投遞的路徑是producer—>rabbitmq broker—>exchange—>queue—>consumer,
生產者將訊息投遞到Broker時產生confirm狀態,會出現二種情況,ack:表示已經被Broker簽收,nack:表示表示已經被Broker拒收,原因可能有佇列滿了,限流,IO例外等,生產者將訊息投遞到Broker,被Broker簽收,但是沒有對應的佇列進行投遞,將訊息回退給生產者會產生return狀態,這二種狀態是rabbitmq提供的訊息可靠投遞機制,生產者開啟確認模式和退回模式,使用rabbitTemplate.setConfirmCallback設定回呼函式,當訊息發送到exchange后回呼confirm方法,在方法中判斷ack,如果為true,則發送成功,如果為false,則發送失敗,需要處理,使用rabbitTemplate.setReturnCallback設定退回函式,當訊息從exchange路由到queue失敗后,如果設定了rabbitTemplate.setMandatory(true)引數,則會將訊息退回給producer,消費者在rabbit:listener-container標簽中設定acknowledge屬性,設定ack方式 none:自動確認,manual:手動確認,none自動確認模式很危險,當生產者發送多條訊息,消費者接收到一條資訊時,會自動認為當前發送的訊息已經簽收了,這個時候消費者進行業務處理時出現了例外情況,也會認為訊息已經正常簽收處理了,而佇列里面顯示都被消費掉了,所以真實開發都會改為手動簽收,可以防止訊息丟失,消費者如果在消費端沒有出現例外,則呼叫channel.basicAck方法確認簽收訊息,消費者如果出現例外,則在catch中呼叫 basicNack或 basicReject,拒絕訊息,讓MQ重新發送訊息,通過一系列的操作,可以保證訊息的可靠投遞以及防止訊息丟失的情況,
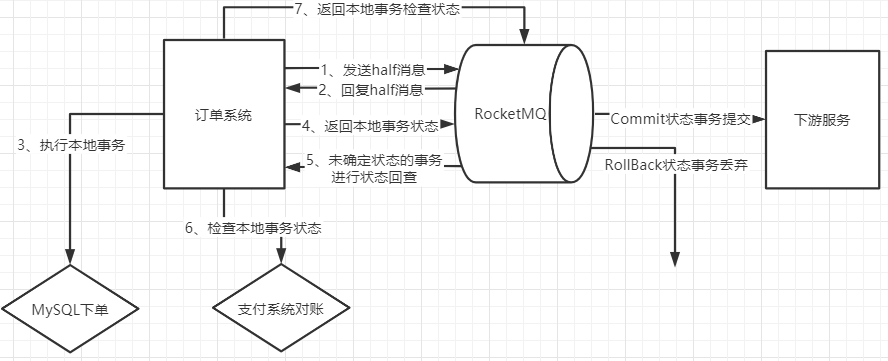
然后說一下rocketmq,生產者使用事務訊息機制保證訊息零丟失,第一步就是確保Producer發送訊息到了Broker這個程序不會丟訊息,發送half訊息給rocketmq,這個half訊息是在生產者操作前發送的,對下游服務的消費者是不可見的,這個訊息主要是確認RocketMQ的服務是否正常,通知RocketMQ,馬上要發一個訊息了,做好準備,half訊息如果寫入失敗就認為MQ的服務是有問題的,這個時候就不能通知下游服務了,給生產者的操作加上一個狀態標記,然后等待MQ服務正常后再進行補償操作,等MQ服務正常后重新下單通知下游服務,然后執行本地事務,比如說下了個訂單,把下單資料寫入到mysql,回傳本地事務狀態給rocketmq,在這個程序中,如果寫入資料庫失敗,可能是資料庫崩了,需要等一段時間才能恢復,這個時候把訂單一直標記為"新下單"的狀態,訂單的訊息先快取起來,比如Redis、文本或者其他方式,然后給RocketMQ回傳一個未知狀態,未知狀態的事務狀態回查是由RocketMQ的Broker主動發起的,RocketMQ過一段時間來回查事務狀態,在回查事務狀態的時候,再嘗試把資料寫入資料庫,如果資料庫這時候已經恢復了,繼續后面的業務,而且即便這個時候half訊息寫入成功后RocketMQ掛了,只要存盤的訊息沒有丟失,等RocketMQ恢復后,RocketMQ就會再次繼續狀態回查的流程,第二步就是確保Broker接收到的訊息不會丟失,因為RocketMQ為了減少磁盤的IO,會先將訊息寫入到os快取中,不是直接寫入到磁盤里面,消費者從os快取中獲取訊息,類似于從記憶體中獲取訊息,速度更快,過一段時間會由os執行緒異步的將訊息刷入磁盤中,此時才算真正完成了訊息的持久化,在這個程序中,如果訊息還沒有完成異步刷盤,RocketMQ中的Broker宕機的話,就會導致訊息丟失,所以第二步,訊息支持持久化到Commitlog里面,即使宕機后重啟,未消費的訊息也是可以加載出來的,把RocketMQ的刷盤方式 flushDiskType配置成同步刷盤,一旦同步刷盤回傳成功,可以保證接收到的訊息一定存盤在本地的記憶體中,采用主從機構,集群部署,Leader中的資料在多個Follower中都存有備份,防止單點故障,同步復制可以保證即使Master 磁盤崩潰,訊息仍然不會丟失,但是這里還會有一個問題,主從結構是只做資料備份,沒有容災功能的,也就是說當一個master節點掛了后,slave節點是無法切換成master節點繼續提供服務的,所以在RocketMQ4.5以后的版本支持Dledge,DLedger是基于Raft協議選舉Leader Broker的,當master節點掛了后,Dledger會接管Broker的CommitLog訊息存盤 ,在Raft協議中進行多臺機器的Leader選舉,發起一輪一輪的投票,通過多臺機器互相投票選出來一個Leader,完成master節點往slave節點的訊息同步,資料同步會通過兩個階段,一個是uncommitted階段,一個是commited階段,Leader Broker上的Dledger收到一條資料后,會標記為uncommitted狀態,然后他通過自己的DledgerServer組件把這個uncommitted資料發給Follower Broker的DledgerServer組件,接著Follower Broker的DledgerServer收到uncommitted訊息之后,必須回傳一個ack給Leader Broker的Dledger,然后如果Leader Broker收到超過半數的Follower Broker回傳的ack之后,就會把訊息標記為committed狀態,再接下來, Leader Broker上的DledgerServer就會發送committed訊息給Follower Broker上的DledgerServer,讓他們把訊息也標記為committed狀態,這樣,就基于Raft協議完成了兩階段的資料同步,第三步,Cunmser確保拉取到的訊息被成功消費,就需要消費者不要使用異步消費,有可能造成訊息狀態回傳后消費者本地業務邏輯處理失敗造成訊息丟失的可能,用同步消費方式,消費者端先處理本地事務,然后再給MQ一個ACK回應,這時MQ就會修改Offset,將訊息標記為已消費,不再往其他消費者推送訊息,在Broker的這種重新推送機制下,訊息是不會在傳輸程序中丟失的,
然后再說說訊息重復消費的問題,第一種情況是發送時訊息重復,當一條訊息已被成功發送到服務端并完成持久化,此時出現了網路抖動或者客戶端宕機,導致服務端對客戶端應答失敗, 如果此時生產者意識到訊息發送失敗并嘗試再次發送訊息,消費者后續會收到兩條內容相同并且 Message ID 也相同的訊息,第二種情況是投遞時訊息重復,訊息消費的場景下,訊息已投遞到消費者并完成業務處理,當客戶端給服務端反饋應答的時候網路閃斷, 為了保證訊息至少被消費一次,tMQ 的服務端將在網路恢復后再次嘗試投遞之前已被處理過的訊息,消費者后續會收到兩條內容相同并且 Message ID 也相同的訊息,第三種情況是負載均衡時訊息重復,比如網路抖動、Broker 重啟以及訂閱方應用重啟,當MQ的Broker或客戶端重啟、擴容或縮容時,會觸發Rebalance,此時消費者可能會收到重復訊息,那么怎么解決訊息重復消費的問題呢?就是對訊息進行冪等性處理,在MQ中,是無法保證每個訊息只被投遞一次的,因為網路抖動或者客戶端宕機等其他因素,基本都會配置重試機制,所以要在消費者端的業務上做消費冪等處理,MQ的每條訊息都有一個唯一的MessageId,這個引數在多次投遞的程序中是不會改變的,業務上可以用這個MessageId加上業務的唯一標識來作為判斷冪等的關鍵依據,例如訂單ID,而這個業務標識可以使用Message的Key來進行傳遞,消費者獲取到訊息后先根據id去查詢redis/db是否存在該訊息,如果不存在,則正常消費,消費完后寫入redis/db,如果存在,則證明訊息被消費過,直接丟棄,
接著說說訊息順序的問題,如果發送端配置了重試機制,mq不會等之前那條訊息完全發送成功,才去發送下一條訊息,這樣可能會出現發送了1,2,3條訊息,但是第1條超時了,后面兩條發送成功,再重試發送第1條訊息,這時訊息在broker端的順序就是2,3,1了,RocketMQ訊息有序要保證最終消費到的訊息是有序的,需要從Producer、Broker、Consumer三個步驟都保證訊息有序才行,在發送者端:在默認情況下,訊息發送者會采取Round Robin輪詢方式把訊息發送到不同的磁區佇列,而消費者消費的時候也從多個MessageQueue上拉取訊息,這種情況下訊息是不能保證順序的,而只有當一組有序的訊息發送到同一個MessageQueue上時,才能利用MessageQueue先進先出的特性保證這一組訊息有序,而Broker中一個佇列內的訊息是可以保證有序的,在消費者端:消費者會從多個訊息佇列上去拿訊息,這時雖然每個訊息佇列上的訊息是有序的,但是多個佇列之間的訊息仍然是亂序的,消費者端要保證訊息有序,就需要按佇列一個一個來取訊息,即取完一個佇列的訊息后,再去取下一個佇列的訊息,而給consumer注入的MessageListenerOrderly物件,在RocketMQ內部就會通過鎖佇列的方式保證訊息是一個一個佇列來取的,MessageListenerConcurrently這個訊息監聽器則不會鎖佇列,每次都是從多個Message中取一批資料,默認不超過32條,因此也無法保證訊息有序,RocketMQ 在默認情況下不保證順序,要保證全域順序,需要把 Topic 的讀寫佇列數設定為 1,然后生產者和消費者的并發設定也是 1,不能使用多執行緒,所以這樣的話高并發,高吞吐量的功能完全用不上,全域有序就是無論發的是不是同一個磁區,我都可以按照你生產的順序來消費,磁區有序就只針對發到同一個磁區的訊息可以順序消費,kafka保證全鏈路訊息順序消費,需要從發送端開始,將所有有序訊息發送到同一個磁區,然后用一個消費者去消費,但是這種性能比較低,可以在消費者端接收到訊息后將需要保證順序消費的幾條消費發到記憶體佇列(可以搞多個),一個記憶體佇列開啟一個執行緒順序處理訊息,RabbitMq沒有屬性設定訊息的順序性,不過我們可以通過拆分為多個queue,每個queue由一個consumer消費,或者一個queue對應一個consumer,然后這個consumer內部用記憶體佇列做排隊,然后分發給底層不同的worker來處理,保證訊息的順序性,
然后再說說訊息積壓,線上有時因為發送方發送訊息速度過快,或者消費方處理訊息過慢,可能會導致broker積壓大量未消費訊息,訊息資料格式變動或消費者程式有bug,導致消費者一直消費不成功,也可能導致broker積壓大量未消費訊息,解決方案可以修改消費端程式,讓其將收到的訊息快速轉發到其他主題,可以設定很多磁區,然后再啟動多個消費者同時消費新主題的不同磁區,可以將這些消費不成功的訊息轉發到其它佇列里去,類似死信佇列,后面再慢慢分析死信佇列里的訊息處理問題,另外在RocketMQ官網中,還分析了一個特殊情況,如果RocketMQ原本是采用的普通方式搭建主從架構,而現在想要中途改為使用Dledger高可用集群,這時候如果不想歷史訊息丟失,就需要先將訊息進行對齊,也就是要消費者把所有的訊息都消費完,再來切換主從架構,因為Dledger集群會接管RocketMQ原有的CommitLog日志,所以切換主從架構時,如果有訊息沒有消費完,這些訊息是存在舊的CommitLog中的,就無法再進行消費了,這個場景下也是需要盡快的處理掉積壓的訊息,
然后說說延遲佇列,訊息被發送以后,并不想讓消費者立刻獲取,而是等待特定的時間后,消費者才能獲取這個訊息進行消費,例如10分鐘,內完成訂單支付,支付完成后才會通知下游服務進行進一步的營銷補償,往MQ發一個延遲1分鐘的訊息,消費到這個訊息后去檢查訂單的支付狀態,如果訂單已經支付,就往下游發送下單的通知,而如果沒有支付,就再發一個延遲1分鐘的訊息,最終在第10個訊息時把訂單回收,就不用對全部的訂單表進行掃描,而只需要每次處理一個單獨的訂單訊息,這個就是延遲對列的應用場景,rabbittmq,rocketmq都可以通過設定ttl來設定延遲時間,kafka則是可以在發送延時訊息的時候,先把訊息按照不同的延遲時間段發送到指定的佇列中,比如topic_1s,topic_5s,topic_10s,topic_2h,然后通過定時器進行輪訓消費這些topic,查看訊息是否到期,如果到期就把這個訊息發送到具體業務處理的topic中,佇列中訊息越靠前的到期時間越早,具體來說就是定時器在一次消費程序中,對訊息的發送時間做判斷,看下是否延遲到對應時間了,如果到了就轉發,如果還沒到這一次定時任務就可以提前結束了,
mq設定過期時間,就會有訊息失效的情況,如果訊息在佇列里積壓超過指定的過期時間,就會被mq給清理掉,這個時候資料就沒了,解決方案也有手動寫程式,將丟失的那批資料,一點點地查出來,然后重新插入到 mq 里面去,
最后再聊聊訊息佇列高可用問題,對于RocketMQ來說可以使用Dledger主從架構來保證訊息佇列的高可用,這個在上面也有提到過,然后在說說rabbitmq,它提供了一種叫鏡像集群模式,在鏡像集群模式下,你創建的 queue,無論元資料還是 queue 里的訊息都會存在于多個實體上,就是說,每個 RabbitMQ 節點都有這個 queue 的一個完整鏡像,包含 queue 的全部資料的意思,然后每次你寫訊息到 queue 的時候,都會自動把訊息同步到多個實體的 queue 上,RabbitMQ 有很好的管理控制臺,可以在后臺新增一個策略,這個策略是鏡像集群模式的策略,指定的時候是可以要求資料同步到所有節點的,也可以要求同步到指定數量的節點,再次創建 queue 的時候,應用這個策略,就會自動將資料同步到其他的節點上去了,只不過訊息需要同步到所有機器上,導致網路帶寬壓力和消耗很重,最后再說說kafka,它是天然的分布式訊息佇列,在Kafka 0.8 以后,提供了副本機制,一個 topic要求指定partition數量,每個 partition的資料都會同步到其它機器上,形成自己的多個 replica 副本,所有 replica 會選舉一個 leader 出來,其他 replica 就是 follower,寫的時候,leader 會負責把資料同步到所有 follower 上去,如果某個 broker 宕機了,沒事兒,那個 broker上面的 partition 在其他機器上都有副本的,如果這上面有某個 partition 的 leader,那么此時會從 follower 中重新選舉一個新的 leader 出來,

整個圖片,歇歇眼,文章大多不換行,排版基本都是一塊的,七千四百字,口速快的話,一個小時差不多可以講完,這篇博文主要是針對面試口述的,備戰面試,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/432154.html
標籤:其他
上一篇:實踐資料湖iceberg 第二十四課 iceberg元資料詳細決議
下一篇:kafka架構開篇