文章目錄
- 一、理論基礎
- 1、金槍魚群優化演算法
- (1)初始化
- (2)螺旋覓食
- (3)拋物線覓食
- 2、TSO演算法偽代碼
- 二、仿真實驗與分析
- 三、參考文獻
一、理論基礎
1、金槍魚群優化演算法
金槍魚群優化(Tuna swarm optimization, TSO)演算法的主要靈感來自金槍魚群的合作覓食行為,該演算法模擬了金槍魚群體的兩種覓食行為,即螺旋覓食和拋物線覓食,
(1)初始化
與大多數基于群體的元啟發式演算法類似,TSO通過在搜索空間中均勻隨機生成初始種群來啟動優化程序, X i i n t = rand ? ( u b ? l b ) + l b , ?? i = 1 , 2 , ? ? , N P (1) \text{\bf X}_i^{\rm int}=\text{\bf rand}\cdot({\rm\bf ub-lb)+lb},\,\,i=1,2,\cdots,NP\tag{1} Xiint?=rand?(ub?lb)+lb,i=1,2,?,NP(1)其中, X i i n t \text{\bf X}_i^{\rm int} Xiint?是第 i i i個個體的初始位置, u b \rm\bf ub ub和 l b \rm\bf lb lb分別是搜索空間的上界和下界, N P NP NP是金槍魚種群的數量, r a n d \rm\bf rand rand是一個均勻分布在 [ 0 , 1 ] [0,1] [0,1]內的隨機向量,
(2)螺旋覓食
金槍魚群通過形成緊密的螺旋來追逐獵物,除了追逐獵物,成群的金槍魚還相互交換資訊,每一條金槍魚都跟在前一條魚的后面,因此可以在相鄰的金槍魚之間共享資訊,基于上述原理,螺旋覓食策略的數學公式如下:
X
i
t
+
1
=
{
α
1
?
(
X
b
e
s
t
t
+
β
?
∣
X
b
e
s
t
t
?
X
i
t
∣
)
+
α
2
?
X
i
t
,
?????
i
=
1
α
1
?
(
X
b
e
s
t
t
+
β
?
∣
X
b
e
s
t
t
?
X
i
t
∣
)
+
α
2
?
X
i
?
1
t
,
i
=
2
,
3
,
?
?
,
N
P
(2)
\text{\bf X}_i^{t+1}=\begin{dcases}\alpha_1\cdot\left(X_{best}^t+\beta\cdot|X_{best}^t-\text{\bf X}_i^t|\right)+\alpha_2\cdot\text{\bf X}_i^t,\quad\,\,\,\,\, i=1\\[2ex]\alpha_1\cdot\left(X_{best}^t+\beta\cdot|X_{best}^t-\text{\bf X}_i^t|\right)+\alpha_2\cdot\text{\bf X}_{i-1}^t,\quad i=2,3,\cdots,NP\end{dcases}\tag{2}
Xit+1?=????α1??(Xbestt?+β?∣Xbestt??Xit?∣)+α2??Xit?,i=1α1??(Xbestt?+β?∣Xbestt??Xit?∣)+α2??Xi?1t?,i=2,3,?,NP?(2)
α
1
=
a
+
(
1
?
a
)
?
t
t
max
?
(3)
\alpha_1=a+(1-a)\cdot\frac{t}{t_{\max}}\tag{3}
α1?=a+(1?a)?tmax?t?(3)
α
2
=
(
1
?
a
)
?
(
1
?
a
)
?
t
t
max
?
(4)
\alpha_2=(1-a)-(1-a)\cdot\frac{t}{t_{\max}}\tag{4}
α2?=(1?a)?(1?a)?tmax?t?(4)
β
=
e
b
l
?
cos
?
(
2
π
b
)
(5)
\beta=e^{bl}\cdot\cos(2\pi b)\tag{5}
β=ebl?cos(2πb)(5)
l
=
e
3
cos
?
(
(
(
t
max
?
+
1
)
/
t
)
?
1
)
π
)
(6)
l=e^{3\cos(((t_{\max}+1)/t)-1)\pi)}\tag{6}
l=e3cos(((tmax?+1)/t)?1)π)(6)其中,
X
i
t
+
1
\text{\bf X}_i^{t+1}
Xit+1?是第
t
+
1
t+1
t+1次迭代的第
i
i
i個個體,
X
b
e
s
t
t
X_{best}^t
Xbestt?是當前最佳個體(食物),
α
1
\alpha_1
α1?和
α
2
\alpha_2
α2?是控制個體向最佳個體和前一個個體移動趨勢的權重系數,
a
a
a是一個常數,用于確定金槍魚在初始階段跟隨最佳個體和前一個體的程度,
t
t
t表示當前迭代次數,
t
m
a
x
t_{max}
tmax?表示最大迭代次數,
b
b
b是均勻分布在0到1之間的亂數,
當最優個體找不到食物時,盲目跟隨最優個體覓食不利于群體覓食,因此,考慮在搜索空間中生成一個隨機坐標,作為螺旋搜索的參考點,它使每個個體都能在更廣闊的空間里探索,并使TSO具有全域探索能力,具體的數學模型描述如下:
X
i
t
+
1
=
{
α
1
?
(
X
r
a
n
d
t
+
β
?
∣
X
r
a
n
d
t
?
X
i
t
∣
)
+
α
2
?
X
i
t
,
?????
i
=
1
α
1
?
(
X
r
a
n
d
t
+
β
?
∣
X
r
a
n
d
t
?
X
i
t
∣
)
+
α
2
?
X
i
?
1
t
,
i
=
2
,
3
,
?
?
,
N
P
(7)
\text{\bf X}_i^{t+1}=\begin{dcases}\alpha_1\cdot\left(X_{rand}^t+\beta\cdot|X_{rand}^t-\text{\bf X}_i^t|\right)+\alpha_2\cdot\text{\bf X}_i^t,\quad\,\,\,\,\, i=1\\[2ex]\alpha_1\cdot\left(X_{rand}^t+\beta\cdot|X_{rand}^t-\text{\bf X}_i^t|\right)+\alpha_2\cdot\text{\bf X}_{i-1}^t,\quad i=2,3,\cdots,NP\end{dcases}\tag{7}
Xit+1?=????α1??(Xrandt?+β?∣Xrandt??Xit?∣)+α2??Xit?,i=1α1??(Xrandt?+β?∣Xrandt??Xit?∣)+α2??Xi?1t?,i=2,3,?,NP?(7)其中,
X
r
a
n
d
t
X_{rand}^t
Xrandt?是搜索空間中隨機生成的參考點,
特別地,元啟發式演算法通常在早期階段進行廣泛的全域探索,然后逐漸過渡到精確的區域開發,因此,隨著迭代次數的增加,TSO將螺旋覓食的參考點從隨機個體更改為最優個體,綜上所述,螺旋覓食策略的最終數學模型如下:
X
i
t
+
1
=
{
{
α
1
?
(
X
r
a
n
d
t
+
β
?
∣
X
r
a
n
d
t
?
X
i
t
∣
)
+
α
2
?
X
i
t
,
?????
i
=
1
α
1
?
(
X
r
a
n
d
t
+
β
?
∣
X
r
a
n
d
t
?
X
i
t
∣
)
+
α
2
?
X
i
?
1
t
,
i
=
2
,
3
,
?
?
,
N
P
,
if
??
rand
<
t
t
max
?
{
α
1
?
(
X
b
e
s
t
t
+
β
?
∣
X
b
e
s
t
t
?
X
i
t
∣
)
+
α
2
?
X
i
t
,
?????
i
=
1
α
1
?
(
X
b
e
s
t
t
+
β
?
∣
X
b
e
s
t
t
?
X
i
t
∣
)
+
α
2
?
X
i
?
1
t
,
i
=
2
,
3
,
?
?
,
N
P
,
????
if
??
rand
≥
t
t
max
?
(8)
\text{\bf X}_i^{t+1}=\begin{cases}{\begin{cases}\alpha_1\cdot\left(X_{rand}^t+\beta\cdot|X_{rand}^t-\text{\bf X}_i^t|\right)+\alpha_2\cdot\text{\bf X}_i^t,\quad\,\,\,\,\, i=1\\[2ex]\alpha_1\cdot\left(X_{rand}^t+\beta\cdot|X_{rand}^t-\text{\bf X}_i^t|\right)+\alpha_2\cdot\text{\bf X}_{i-1}^t,\quad i=2,3,\cdots,NP\end{cases},\text{if}\,\,\text{rand}<\frac{t}{t_{\max}}}\\[2ex]\\{\begin{cases}\alpha_1\cdot\left(X_{best}^t+\beta\cdot|X_{best}^t-\text{\bf X}_i^t|\right)+\alpha_2\cdot\text{\bf X}_i^t,\quad\,\,\,\,\, i=1\\[2ex]\alpha_1\cdot\left(X_{best}^t+\beta\cdot|X_{best}^t-\text{\bf X}_i^t|\right)+\alpha_2\cdot\text{\bf X}_{i-1}^t,\quad i=2,3,\cdots,NP\end{cases},\,\,\,\,\text{if}\,\,\text{rand}\geq \frac{t}{t_{\max}}}\end{cases}\tag{8}
Xit+1?=??????????????????????????α1??(Xrandt?+β?∣Xrandt??Xit?∣)+α2??Xit?,i=1α1??(Xrandt?+β?∣Xrandt??Xit?∣)+α2??Xi?1t?,i=2,3,?,NP?,ifrand<tmax?t?????α1??(Xbestt?+β?∣Xbestt??Xit?∣)+α2??Xit?,i=1α1??(Xbestt?+β?∣Xbestt??Xit?∣)+α2??Xi?1t?,i=2,3,?,NP?,ifrand≥tmax?t??(8)
(3)拋物線覓食
金槍魚除了形成螺旋覓食外,還形成拋物線合作覓食,金槍魚以食物為參照點形成拋物線形,此外,金槍魚通過在周圍搜索來尋找食物,假設兩種方法的選擇概率均為50%,則兩種方法同時進行,具體的數學模型描述如下: X i t + 1 = { X b e s t t + r a n d ? ( X b e s t t ? X i t ) + T F ? p 2 ? ( X b e s t t ? X i t ) , if ?? rand < 0.5 T F ? p 2 ? X i t , ? if ?? rand ≥ 0.5 (9) \text{\bf X}_i^{t+1}=\begin{dcases}\text{\bf X}_{best}^{t}+{\bf rand}\cdot({\bf X}_{best}^t-{\bf X}_i^t)+TF\cdot p^2\cdot({\bf X}_{best}^t-{\bf X}_i^t),\quad\text{if}\,\,\text{rand}<0.5\\[2ex]TF\cdot p^2\cdot{\bf X}_i^t,\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\quad\,\text{if}\,\,\text{rand}\geq0.5\end{dcases}\tag{9} Xit+1?=????Xbestt?+rand?(Xbestt??Xit?)+TF?p2?(Xbestt??Xit?),ifrand<0.5TF?p2?Xit?,ifrand≥0.5?(9) p = ( 1 ? t t max ? ) t / t max ? (10) p=\left(1-\frac{t}{t_{\max}}\right)^{t/t_{\max}}\tag{10} p=(1?tmax?t?)t/tmax?(10)其中, T F TF TF是一個值為1或?1的亂數,
2、TSO演算法偽代碼
金槍魚通過兩種覓食策略進行合作狩獵,然后找到獵物,對于TSO的優化程序,首先在搜索空間中隨機生成種群,在每次迭代中,每個個體隨機選擇兩種覓食策略中的一種執行,或根據概率
z
z
z選擇重新生成搜索空間中的位置,在整個優化程序中,TSO的所有個體都會不斷更新和計算,直到滿足最終條件,然后回傳最優個體和相應的適應度值,TSO偽代碼如圖1所示,

二、仿真實驗與分析
將TSO與HHO、EO、TSA、GWO、SSA和WOA進行對比,以文獻[1]中的F1、F3(單峰函式/30維)、F10、F11(多峰函式/30維)、F20、F21(固定維度多峰函式/6維、4維)為例,種群規模設定為50,最大迭代次數設定為1000,每個演算法獨立運算30次,結果顯示如下:
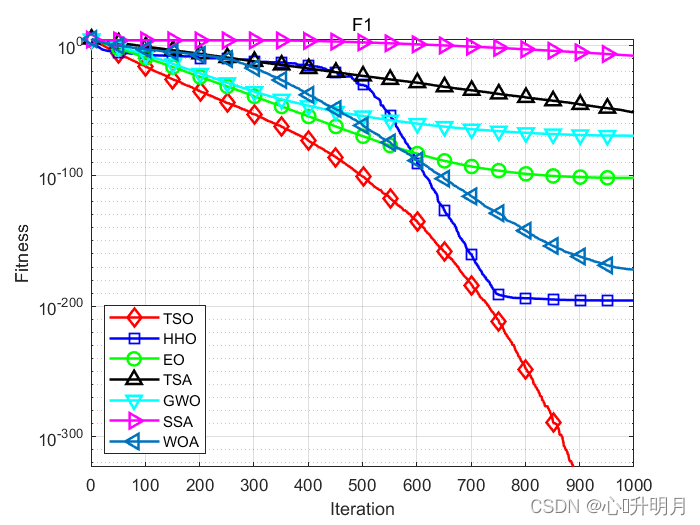
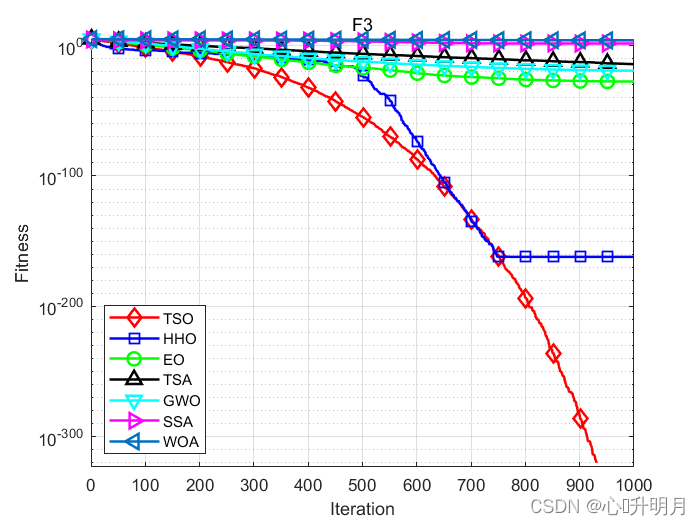
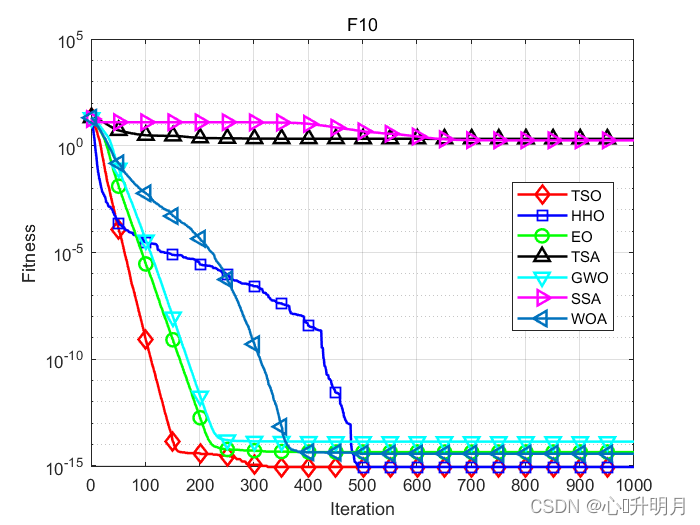
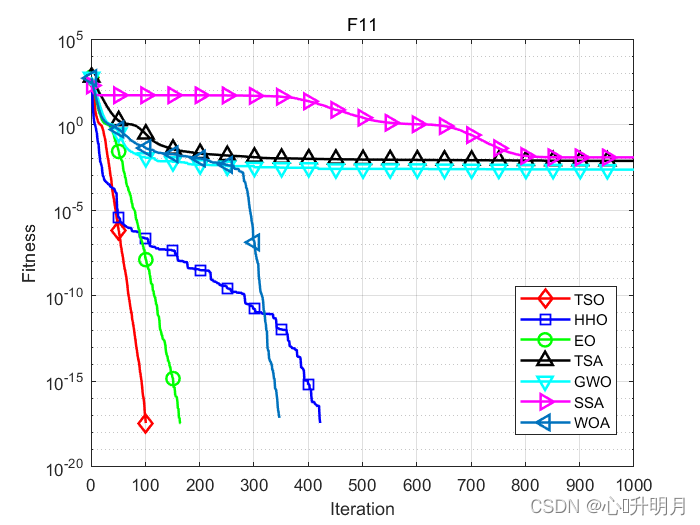
函式:F1
TSO:最差值: 0, 最優值: 0, 平均值: 0, 標準差: 0, 秩和檢驗: NaN
HHO:最差值: 3.8853e-195, 最優值: 1.9148e-221, 平均值: 2.0518e-196, 標準差: 0, 秩和檢驗: 1.2118e-12
EO:最差值: 2.4784e-101, 最優值: 3.7885e-107, 平均值: 1.9732e-102, 標準差: 4.8432e-102, 秩和檢驗: 1.2118e-12
TSA:最差值: 7.8376e-51, 最優值: 4.3609e-55, 平均值: 3.2757e-52, 標準差: 1.4217e-51, 秩和檢驗: 1.2118e-12
GWO:最差值: 8.7456e-69, 最優值: 1.7964e-72, 平均值: 4.7536e-70, 標準差: 1.6422e-69, 秩和檢驗: 1.2118e-12
SSA:最差值: 1.3295e-08, 最優值: 5.7796e-09, 平均值: 9.0763e-09, 標準差: 2.0069e-09, 秩和檢驗: 1.2118e-12
WOA:最差值: 2.0236e-171, 最優值: 1.8763e-186, 平均值: 1.088e-172, 標準差: 0, 秩和檢驗: 1.2118e-12
函式:F3
TSO:最差值: 0, 最優值: 0, 平均值: 0, 標準差: 0, 秩和檢驗: NaN
HHO:最差值: 2.676e-161, 最優值: 8.6031e-195, 平均值: 8.9199e-163, 標準差: 4.9702e-162, 秩和檢驗: 1.2118e-12
EO:最差值: 7.1477e-27, 最優值: 3.7095e-35, 平均值: 3.0203e-28, 標準差: 1.299e-27, 秩和檢驗: 1.2118e-12
TSA:最差值: 1.905e-13, 最優值: 1.3326e-28, 平均值: 6.4746e-15, 標準差: 3.4762e-14, 秩和檢驗: 1.2118e-12
GWO:最差值: 6.6695e-19, 最優值: 6.8916e-27, 平均值: 6.8592e-20, 標準差: 1.5409e-19, 秩和檢驗: 1.2118e-12
SSA:最差值: 140.278, 最優值: 5.2169, 平均值: 46.9785, 標準差: 34.4463, 秩和檢驗: 1.2118e-12
WOA:最差值: 24685.2948, 最優值: 1019.7777, 平均值: 11455.0503, 標準差: 5820.31, 秩和檢驗: 1.2118e-12
函式:F10
TSO:最差值: 8.8818e-16, 最優值: 8.8818e-16, 平均值: 8.8818e-16, 標準差: 0, 秩和檢驗: NaN
HHO:最差值: 8.8818e-16, 最優值: 8.8818e-16, 平均值: 8.8818e-16, 標準差: 0, 秩和檢驗: NaN
EO:最差值: 4.4409e-15, 最優值: 4.4409e-15, 平均值: 4.4409e-15, 標準差: 0, 秩和檢驗: 1.6853e-14
TSA:最差值: 3.5268, 最優值: 7.9936e-15, 平均值: 2.0839, 標準差: 1.5156, 秩和檢驗: 1.1824e-12
GWO:最差值: 1.5099e-14, 最優值: 7.9936e-15, 平均值: 1.3678e-14, 標準差: 2.5721e-15, 秩和檢驗: 2.5728e-13
SSA:最差值: 3.8858, 最優值: 1.9806e-05, 平均值: 1.789, 標準差: 1.0741, 秩和檢驗: 1.2118e-12
WOA:最差值: 7.9936e-15, 最優值: 8.8818e-16, 平均值: 3.7303e-15, 標準差: 2.1681e-15, 秩和檢驗: 2.642e-08
函式:F11
TSO:最差值: 0, 最優值: 0, 平均值: 0, 標準差: 0, 秩和檢驗: NaN
HHO:最差值: 0, 最優值: 0, 平均值: 0, 標準差: 0, 秩和檢驗: NaN
EO:最差值: 0, 最優值: 0, 平均值: 0, 標準差: 0, 秩和檢驗: NaN
TSA:最差值: 0.051756, 最優值: 0, 平均值: 0.0075514, 標準差: 0.0099096, 秩和檢驗: 8.8658e-07
GWO:最差值: 0.027924, 最優值: 0, 平均值: 0.0023552, 標準差: 0.0074256, 秩和檢驗: 0.081523
SSA:最差值: 0.068771, 最優值: 2.5447e-08, 平均值: 0.012144, 標準差: 0.013381, 秩和檢驗: 1.2118e-12
WOA:最差值: 0, 最優值: 0, 平均值: 0, 標準差: 0, 秩和檢驗: NaN
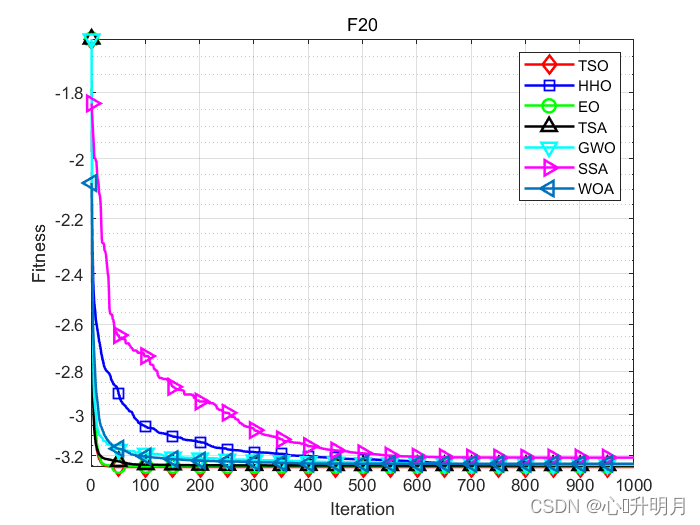
函式:F20
TSO:最差值: -3.2031, 最優值: -3.322, 平均值: -3.2586, 標準差: 0.060328, 秩和檢驗: 1
HHO:最差值: -3.2025, 最優值: -3.322, 平均值: -3.2545, 標準差: 0.059959, 秩和檢驗: 0.00034656
EO:最差值: -3.1974, 最優值: -3.322, 平均值: -3.2544, 標準差: 0.060101, 秩和檢驗: 0.17391
TSA:最差值: -3.0832, 最優值: -3.3215, 平均值: -3.2513, 標準差: 0.070318, 秩和檢驗: 0.00083562
GWO:最差值: -3.1327, 最優值: -3.322, 平均值: -3.2468, 標準差: 0.069581, 秩和檢驗: 0.00034656
SSA:最差值: -3.1998, 最優值: -3.322, 平均值: -3.2103, 標準差: 0.030378, 秩和檢驗: 6.2047e-10
WOA:最差值: -3.0942, 最優值: -3.322, 平均值: -3.2418, 標準差: 0.080749, 秩和檢驗: 0.00083562
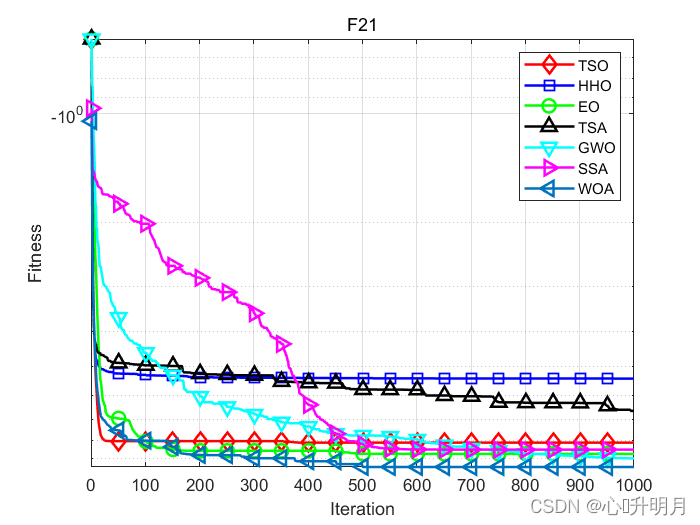
函式:F21
TSO:最差值: -5.0552, 最優值: -10.1532, 平均值: -8.114, 標準差: 2.5402, 秩和檢驗: 1
HHO:最差值: -5.0551, 最優值: -10.1528, 平均值: -5.395, 標準差: 1.2933, 秩和檢驗: 1.9883e-10
EO:最差值: -2.6305, 最優值: -10.1532, 平均值: -8.7129, 標準差: 2.4655, 秩和檢驗: 0.14135
TSA:最差值: -2.6166, 最優值: -10.1439, 平均值: -6.627, 標準差: 3.1565, 秩和檢驗: 1.1412e-05
GWO:最差值: -5.0552, 最優值: -10.1532, 平均值: -8.9695, 標準差: 2.1818, 秩和檢驗: 0.060583
SSA:最差值: -2.6305, 最優值: -10.1532, 平均值: -8.48, 標準差: 2.8942, 秩和檢驗: 0.039787
WOA:最差值: -5.0552, 最優值: -10.1532, 平均值: -9.4732, 標準差: 1.7625, 秩和檢驗: 0.039787
仿真結果表明:與其他比較演算法相比,TSO演算法具有更好的性能,
三、參考文獻
[1] Lei Xie, Tong Han, Huan Zhou, et al. Tuna Swarm Optimization: A Novel Swarm-Based Metaheuristic Algorithm for Global Optimization[J]. Computational Intelligence and Neuroscience, vol. 2021, Article ID 9210050, 22 pages, 2021.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433222.html
標籤:AI
上一篇:python實作柵格影像的裁剪
下一篇:機器學習(十一) 遷移學習