目錄
- 前言
- 1 原理
- 2 實體
- 2.1 特征提取
- 2.2 微調
前言
??遷移學習在計算機視覺任務和自然語言處理任務中經常使用,這些模型往往需要大資料、復雜的網路結構,如果使用遷移學習,可將預訓練的模型作為新模型的起點,這些預訓練的模型在開發神經網路的時候已經在大資料集上訓練好、模型設計也比較好,這樣的模型通用性也比較好,如果要解決的問題與這些模型相關性較強,那么使用這些預訓練模型,將大大地提升模型的性能和泛化能力,
1 原理
??遷移學習(Transfer Learning)是機器學習的一個研究方向,主要研究如何將任務 A 上面學習到的知識遷移到任務 B 上,以提高在任務 B 上的泛化性能,例如任務 A 為貓狗分類問題,需要訓練一個分類器能夠較好的分辨貓和狗的樣本圖片,任務 B 為牛羊分類問題,可以發現,任務 A 和任務 B 存在大量的共享知識,比如這些動物都可以從毛發、體型、形 態、發色等方面進行辨別,因此在任務 A 訓練獲得的分類器已經掌握了這部份知識,在訓練任務 B 的分類器時,可以不從零開始訓練,而是在任務 A 上獲得的知識的基礎上面進行訓練(Feature Extraction)或微調(Fine tuning),這和“站在巨人的肩膀上”思想非常類似,通過遷移任務 A 上學習的知識,在任務 B 上訓練分類器可以使用更少的樣本和更少的訓練代價,并且獲得不錯的泛化能力,
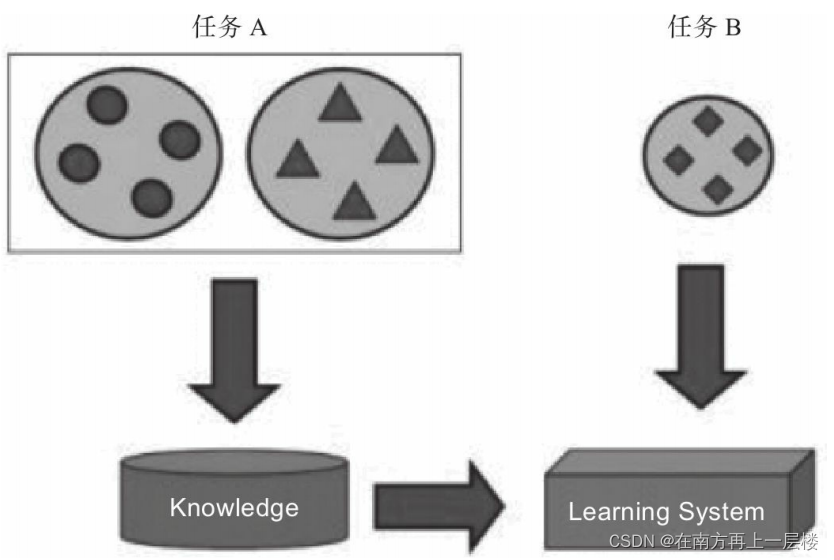
在神經網路遷移學習中,主要有兩個應用場景:特征提取和微調,
? 特征提取(Feature Extraction) :凍結除最終完全連接層之外的所有網路的權重,最后一個全連接層被替換為具有隨機權重的新層,因只需要更新最后一層全連接層,使得更新引數極大地減少,節省大量的 訓練時間 和 GPU 資源,
? 微調(Fine Tuning) :對于卷積神經網路,一般認為它能夠逐層提取特征,越末層的網路的抽象特征提取能力越強,輸出層一般使用與類別數相同輸出節點的全連接層,作為分類網路的概率分布預測,對于相似的任務 A 和 B,如果它們的特征提取方法是相近的,則網路的前面數層可以重用,而微調技術就是使用預訓練網路初始化網路,而不是隨機初始化,用新資料訓練部分或整個網路,小幅度更新前面的層的引數,
2 實體
??進行遷移學習需要使用對應的預訓練模型,PyTorch提供了很多現成的預 訓練模塊,我們直接拿來使用就可以,主要集成在 torchvision.models 模塊中,預訓練模型可以通過傳遞引數 pretrained = True 構造,主要的模型有 AlexNet,VGG,ResNet,SqueezeNet,DenseNet,Inception v3,GoogLeNet,ShuffleNet v2 等,
??所有的預訓練模型都要求輸入圖片以相同的方式進行標準化,即:小批l量3通道RGB格式 (3 × H × W) ,其中H和W應等于 224 ,圖片加載時像素值的范圍應在 [0, 1] 內,然后通過指定 mean = [0.485, 0.456, 0.406] 和 std = [0.229, 0.224, 0.225] 進行標準化,
2.1 特征提取
??本次案例使用的資料集是 CIFAR-10資料集 ,目標是對資料集中10類物體進行分類,只使用幾層的卷積和全連接層的分類正確率只有 68% 左右,結果不算好,此案例使用遷移學習中特征提取方法來實作這個任務,預訓練模型采用 retnet18 網路,
#匯入相關包
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.models as models
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from datetime import datetime
#為適合預訓練模型,增加了一些預處理功能,如資料標準化,對圖片進行裁剪等
trans_train = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225])])
#對測驗集的預處理有一定不同,這一點對結果的影響很大
trans_vaild = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225])])
#CIFAR10資料集下載
trainset = torchvision.datasets.CIFAR10(
root = 'data',
download = False,
train = True,
transform = trans_train
)
trainloader = DataLoader(trainset, batch_size = 64, shuffle = True)
testset = torchvision.datasets.CIFAR10(
root = 'data',
download = False,
train = False,
transform = trans_vaild
)
testloader = DataLoader(testset, batch_size = 64, shuffle = False)
#這里會自動下載預訓練模型,該模型網路架構為resnet18,
#已經在 ImageNet大資料集上訓練好了,該資料集有1000類別
net = models.resnet18(pretrained = True)
#凍結于訓練模型的全部引數
for param in net.parameters() :
param.requires_grad = False
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
#修改最后的全連接層,CIFAR10資料集只有10類
net.fc = nn.Linear(512, 10)
#查看總引數及訓練引數
total_params = sum(p.numel() for p in net.parameters())
print(f'原引數的數量 : {total_params}') #11181642
total_params_trainable = sum(p.numel() for p in net.parameters() if p.requires_grad)
print(f'需要訓練的引數 : {total_params_trainable}') #5130
criterion = nn.CrossEntropyLoss()
#要注意這個地方 net.fc.parameters(),只更新最后的全連接引數而不是net.parameters()
optimizer = optim.SGD(net.fc.parameters(), lr = 0.001, weight_decay = 0.001, momentum = 0.9)
#訓練
net = net.to(device)
for epoch in range(20) :
prev_time = datetime.now()
train_losses = 0.0
train_acc = 0.0
net.train()
for x, label in trainloader :
x, label = x.to(device), label.to(device)
optimizer.zero_grad()
out = net(x)
loss = criterion(out, label)
train_losses += loss.item()
_, pred = torch.max(out, dim = 1)
num_correct = (pred == label).sum().item()
train_acc += num_correct / x.size(0)
loss.backward()
optimizer.step()
#計算每個回圈所花費的時間
cur_time = datetime.now()
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = "Time %02d:%02d:%02d" % (h, m, s)
#測驗
with torch.no_grad() :
net.eval()
test_losses = 0.0
test_acc = 0.0
for x, label in testloader :
x, label = x.to(device), label.to(device)
out = net(x)
loss = criterion(out, label)
test_losses += loss.item()
_, pred = torch.max(out, dim = 1)
num_correct = (pred == label).sum().item()
test_acc += num_correct / x.size(0)
print(f'Eopch {epoch}. Train Loss: {(train_losses / len(trainloader)):.4f}, '
f'Train Acc: {(train_acc / len(trainloader)):.3f}, '
f'Vaild Loss: {(test_losses / len(testloader)):.4f}, '
f'Vaild Acc: {(test_acc / len(testloader)):.3f}, '
f'Time: {time_str}')
結果:
在前三個Epoch準確率就達到了 73.6% ,最終結果會達到 75% 左右,從精確率比第6章提升了近10個百分點,但是對于分類效果來說仍不是很理想,
2.2 微調
??微調允許修改預先訓練好的網路引數來學習目標任務,所以,雖然訓練時間要位元征抽取方法長,但精度更高,微調的大致程序是在預先訓練過的網路上添加新的隨機初始化層,此外預先訓練的網路引數也會被更新,但會使用較小的學習率以防止預先訓練好的引數發生較大的改變,
??在本次的微調任務中采用了資料增強的方法來使得分類效果更加,因為資料增強是提高模型的泛化能力最重要因素,資料增強技術主要有 水平或垂直翻轉影像、裁剪、色彩 變換、擴展和旋轉 等,通過資料增強技術不僅可以擴大訓練資料集的規 模、降低模型對某些屬性的依賴,從而提高模型的泛化能力,同時可以對影像進行不同方式的裁剪,使感興趣的物體出現在不同的位置,從而減輕模型對物體出現位置的依賴性,并通過調整亮度、色彩等因素來降低模型對色彩的敏感度等,在PyTorch中影像增強的方法集成在 torchvision.transforms 模塊中,主要的有:
? torchvision.transforms.Resize() :隨機比例縮放,
? torhvision.transforms.RandomCrop() :在影像隨機位置進行裁取,
? torhvision.transforms.CenterCrop() :在影像中心置進行裁取,
? torchvision.transforms.RandomHorizontalFlip() :隨機水平翻轉,
? torchvision.transforms.RandomVerticalFlip() :隨機豎直翻轉,
? torchvision.transforms.RandomRotation() :隨機旋轉,
? torchvision.transforms.ColorJitter() :改變亮度、對比度和顏色,
微調的代碼與特征提取的不同地方主要在影像預處理部分和引數更新部分,
這里對訓練資料添加了幾種資料增強方法,如影像裁剪、旋轉、顏色改變等方法,測驗資料與特征提取一樣,沒有變化,
trans_train = transforms.Compose([
transforms.RandomResizedCrop(256, scale = (0.8, 1.0)),
transforms.RandomRotation(degrees = 15),
transforms.ColorJitter(),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean = [0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225])])
優化器部分,注意不要凍結預訓練模型的引數,
optimizer = optim.SGD(net.parameters(), lr = 0.001, weight_decay = 0.001, momentum = 0.9)
結果:

由結果知微調+資料增強的方法在第三個Epoch正確率就可以達到 92% ,最終結果可達到 95% 左右,正確很高,本次實驗只設定了20個Eopch,當繼續增加Epoch時,正確率會接近 100% ,
參考文獻:
? :Python深度學習基于PyTorch
? :TensorFlow深度學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433223.html
標籤:AI