目錄
0. 相關文章鏈接
1. 開發說明
2. 環境構建
2.1. 構建服務器環境
2.2. 構建Maven專案
3. Maven依賴
4. 核心代碼
0. 相關文章鏈接
大資料基礎知識點 文章匯總
1. 開發說明
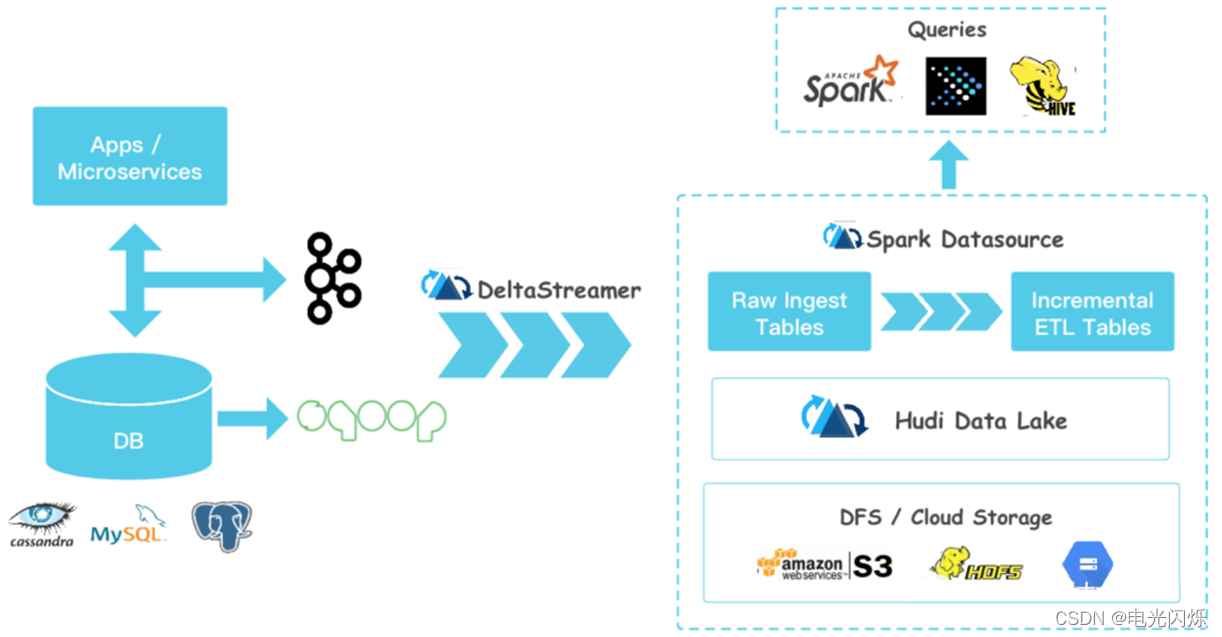
Apache Hudi最初是由Uber開發的,旨在以高效率實作低延遲的資料庫訪問,Hudi 提供了Hudi 表的概念,這些表支持CRUD操作,基于Spark框架使用Hudi API 進行讀寫操作,
2. 環境構建
2.1. 構建服務器環境
關于構建Spark向Hudi中插入資料的服務器環境,可以參考博文的另外一篇博文,在CentOS7上安裝HDFS即可,博文連接:資料湖之Hudi(6):Hudi與Spark和HDFS的集成安裝使用
2.2. 構建Maven專案
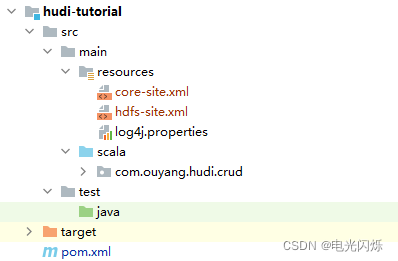
需要在IDEA中創建一個Maven工程,并將服務器上的core-site.xml 和 hdfs-site.xml 這2個組態檔匯入,以及創建一個log4j.properties檔案,如下圖所示:
log4j.properties 檔案內容如下:
log4j.rootCategory=WARN, console
log4j.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n注意,這是本地跑程式,需要配置好域名映射,
3. Maven依賴
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>3.0.0</spark.version>
<hadoop.version>3.0.0</hadoop.version>
<hudi.version>0.9.0</hudi.version>
</properties>
<dependencies>
<!-- 依賴Scala語言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依賴 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依賴 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依賴 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- hudi-spark3 -->
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark3-bundle_2.12</artifactId>
<version>${hudi.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 編譯的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>4. 核心代碼
在上述圖片的包中新建scala的object物件,物件名為:Demo01_InsertForCOW,用于實作模擬資料,插入Hudi表,采用COW模式,
具體需求:使用官方QuickstartUtils提供模擬產生Trip資料,模擬100條交易Trip乘車資料,將其轉換為DataFrame資料集,保存至Hudi表中,代碼基本與spark-shell命令列一致
具體代碼如下:
package com.ouyang.hudi.crud
import org.apache.hudi.QuickstartUtils.DataGenerator
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
/**
* @ date: 2022/2/23
* @ author: yangshibiao
* @ desc: 模擬資料,插入Hudi表,采用COW模式
* 使用官方QuickstartUtils提供模擬產生Trip資料,
* 模擬100條交易Trip乘車資料,將其轉換為DataFrame資料集,
* 保存至Hudi表中,代碼基本與spark-shell命令列一致
*/
object Demo01_InsertForCOW {
def main(args: Array[String]): Unit = {
// 創建SparkSession實體物件,設定屬性
val spark: SparkSession = {
SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[4]")
// 設定序列化方式:Kryo
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
}
// 定義變數:表名稱、保存路徑
val tableName: String = "tbl_trips_cow"
val tablePath: String = "/hudi-warehouse/tbl_trips_cow"
// 構建資料生成器,模擬產生業務資料
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConverters._
import spark.implicits._
// 第1步、模擬乘車資料
val dataGen: DataGenerator = new DataGenerator()
val inserts = convertToStringList(dataGen.generateInserts(100))
// 將集合物件寫入到df中
val insertDF: DataFrame = spark.read.json(
spark.sparkContext.parallelize(inserts.asScala, 2).toDS()
)
insertDF.printSchema()
insertDF.show(10, truncate = false)
// TOOD: 第2步、插入資料到Hudi表
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
insertDF.write
.mode(SaveMode.Append)
.format("hudi")
.option("hoodie.insert.shuffle.parallelism", "2")
.option("hoodie.upsert.shuffle.parallelism", "2")
// Hudi 表的屬性值設定
.option(PRECOMBINE_FIELD.key(), "ts")
.option(RECORDKEY_FIELD.key(), "uuid")
.option(PARTITIONPATH_FIELD.key(), "partitionpath")
.option(TBL_NAME.key(), tableName)
.save(tablePath)
}
}
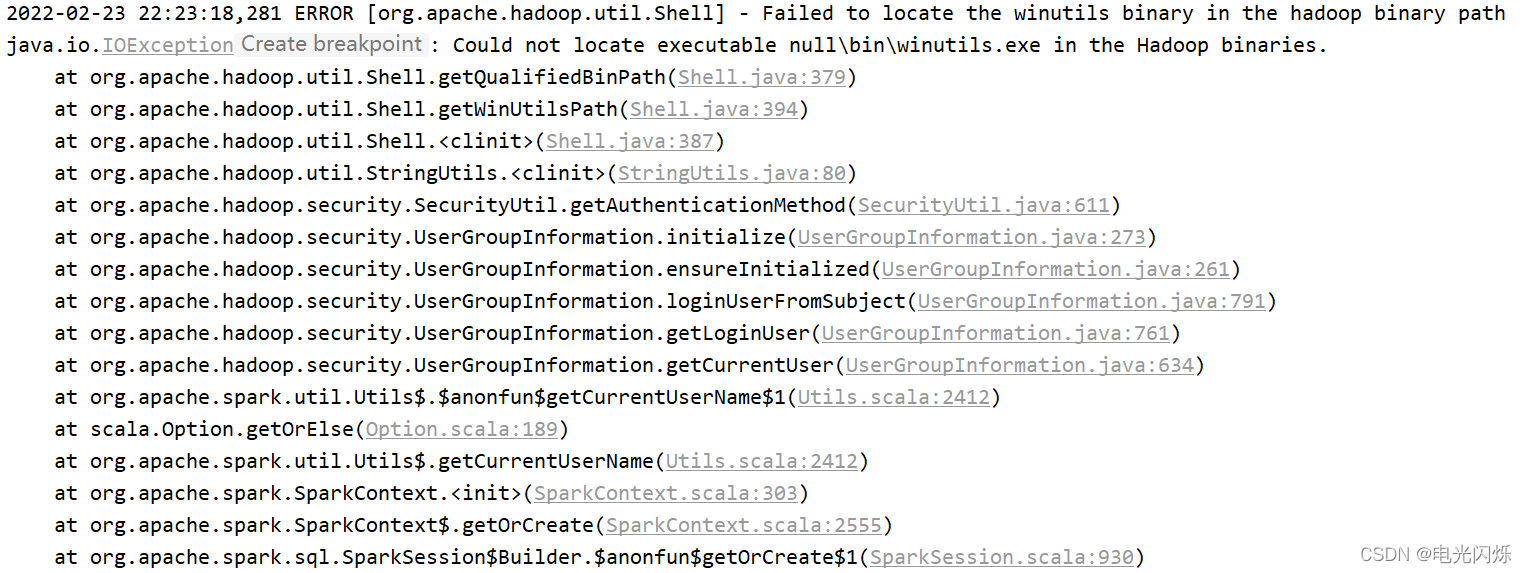
點擊執行后可能會碰到 null\bin\winutils.exe in the Hadoop binaries 問題,這個是在windows本地執行時沒有對應環境,可以忽略,如下圖所示:
在代碼中列印了資料格式和部分資料,如下所示:
root
|-- begin_lat: double (nullable = true)
|-- begin_lon: double (nullable = true)
|-- driver: string (nullable = true)
|-- end_lat: double (nullable = true)
|-- end_lon: double (nullable = true)
|-- fare: double (nullable = true)
|-- partitionpath: string (nullable = true)
|-- rider: string (nullable = true)
|-- ts: long (nullable = true)
|-- uuid: string (nullable = true)
+-------------------+-------------------+----------+-------------------+-------------------+------------------+------------------------------------+---------+-------------+------------------------------------+
|begin_lat |begin_lon |driver |end_lat |end_lon |fare |partitionpath |rider |ts |uuid |
+-------------------+-------------------+----------+-------------------+-------------------+------------------+------------------------------------+---------+-------------+------------------------------------+
|0.4726905879569653 |0.46157858450465483|driver-213|0.754803407008858 |0.9671159942018241 |34.158284716382845|americas/brazil/sao_paulo |rider-213|1645620263263|550e7186-203c-48a8-9964-edf12e0dfbe3|
|0.6100070562136587 |0.8779402295427752 |driver-213|0.3407870505929602 |0.5030798142293655 |43.4923811219014 |americas/brazil/sao_paulo |rider-213|1645074858260|c8d5e237-6589-419e-bef7-221faa4faa13|
|0.5731835407930634 |0.4923479652912024 |driver-213|0.08988581780930216|0.42520899698713666|64.27696295884016 |americas/united_states/san_francisco|rider-213|1645298902122|d64b94ec-d8e8-44f3-a5c0-e205e034aa5d|
|0.21624150367601136|0.14285051259466197|driver-213|0.5890949624813784 |0.0966823831927115 |93.56018115236618 |americas/united_states/san_francisco|rider-213|1645132033863|fd8f9051-b5d2-4403-8002-8bb173df5dc8|
|0.40613510977307 |0.5644092139040959 |driver-213|0.798706304941517 |0.02698359227182834|17.851135255091155|asia/india/chennai |rider-213|1645254343160|160c7699-7f5e-4ec3-ba76-9ae63ae815af|
|0.8742041526408587 |0.7528268153249502 |driver-213|0.9197827128888302 |0.362464770874404 |19.179139106643607|americas/united_states/san_francisco|rider-213|1645452263906|fe9d75c0-f326-4cef-8596-4248a57d1fea|
|0.1856488085068272 |0.9694586417848392 |driver-213|0.38186367037201974|0.25252652214479043|33.92216483948643 |americas/united_states/san_francisco|rider-213|1645133755620|5d149bc7-78a8-46df-b2b0-a038dc79e378|
|0.0750588760043035 |0.03844104444445928|driver-213|0.04376353354538354|0.6346040067610669 |66.62084366450246 |americas/brazil/sao_paulo |rider-213|1645362187498|da2dd8e5-c2d9-45e2-8c96-520927e5458d|
|0.651058505660742 |0.8192868687714224 |driver-213|0.20714896002914462|0.06224031095826987|41.06290929046368 |asia/india/chennai |rider-213|1645575914370|f01e9d28-df30-454c-a780-b56cd5b43ce7|
|0.11488393157088261|0.6273212202489661 |driver-213|0.7454678537511295 |0.3954939864908973 |27.79478688582596 |americas/united_states/san_francisco|rider-213|1645094601577|bd4ae628-3885-4b26-8a50-c14f8e42a265|
+-------------------+-------------------+----------+-------------------+-------------------+------------------+------------------------------------+---------+-------------+------------------------------------+
only showing top 10 rows
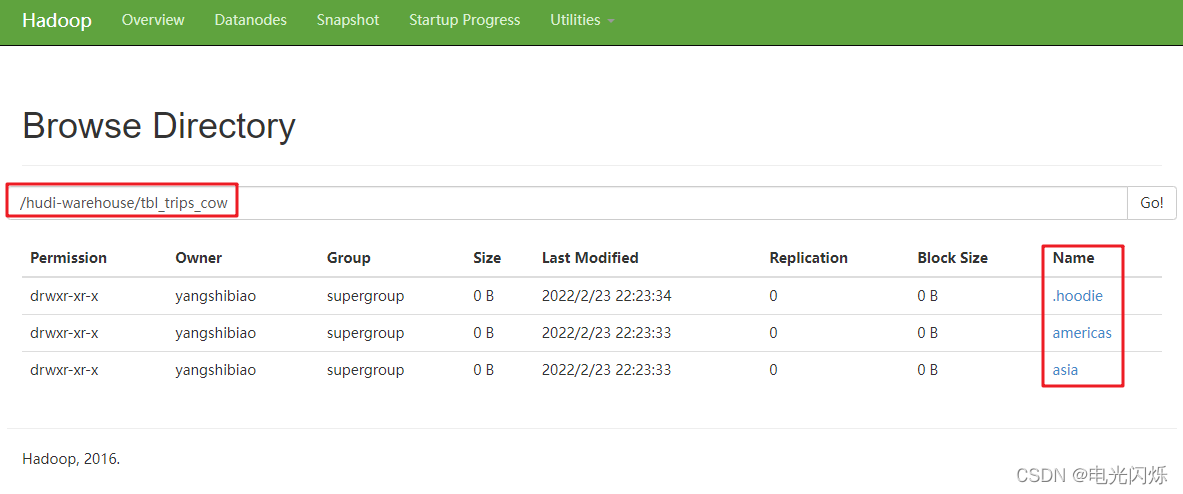
運行程式后會發現資料已經插入到HDFS中了,如下圖所示:
注:Hudi系列博文為通過對Hudi官網學習記錄所寫,其中有加入個人理解,如有不足,請各位讀者諒解???
注:其他相關文章鏈接由此進(包括Hudi在內的各大資料相關博文) -> 大資料基礎知識點 文章匯總
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433251.html
標籤:其他
上一篇:elasticsearch8.0和kibana8.0安裝
下一篇:22年美賽c題-交易策略