目錄
題目:
前言
資料預處理:
模型假設
第一問
總體思路
預測模型
評價指標1
評價指標2
評價指標3
層次分析法(AHP)
交易模型
第二問
第三問
模型的不足
題目:
開發一個模型,該模型僅基于當天的價格資料提供最佳的每日交易策略,使用您的模型和策略,在 2021 年 9 月 10 日,最初的 1000 美元投資價值多少?
提供證據證明您的模型提供了最佳策略,
確定策略對交易成本的敏感程度,交易成本如何影響策略和結果?
在最多兩頁的備忘錄中將您的策略、模型和結果傳達給交易者,
前言
前幾天打美賽,我負責題目的資料處理,第一問預測模型和交易模型的建立,編碼,論文,以及第三問的交易成本靈敏度分析部分的編碼,論文,這里給大家分享一下自己的思路,
資料預處理:
根據已有的資料,我們發現有些日期格式并不正確,如2001/09/16,正確格式應該為1/09/16,但我們發現這種不正確的格式并不會影響日期的順序,我們觀察到,位元幣的資料是涵蓋了五年所有的日期的,而金價并非如此,金價在下一個交易日來臨之前價格保持原價,由此,我們對金價表單的日期,做出每一天的金價表格(見”篩選后的資料.xlsx“),方便我們之后每一天做決策,
在具體資料的處理程序中,一開始我打算直接用串列的分割字串功能,以”/“為分割得到幾個字串,將第一個字串轉化成int型,判斷它是不是四位數,如果是的話,就接著判斷他是否大于2009,因為如果大于,我們就要取這個20xx的后兩位,否則取后一位,
但在實際的處理程序中,我發現類似2001/09/16這樣的格式,用python讀取后的字串并非’/'分割的字串,而是類似”2001-09-16“的格式,這可能是因為excel把他當成正常格式的日期來保存了, 為了解決這個問題,我在excel中使用了text()函式將原先的日期格式轉化成字串格式,得到了新的一列,之后就是使用上文所述的方法讀取每一位數字,
在讀取數字之后我們就得到了每個交易日的年,月,日的資料,呼叫python內置的datetime()函式,得到了每一個交易日的真實日期,再直接把相鄰的兩個交易日日期相減,這樣就得到了我們當前金價保持的天數n,我們讓當前日期后n天保持當前金價即可,得出五年中每一天的黃金價格
但在第一次處理后,我發現我的excel中存盤了7000個數,這明顯是不正確的,我推測是有些資料出了問題,有些值重復順延了很多次,之后我使用plot(),繪制了每個交易日的順延日期,發現是在19,29這個地方有大幅跳動,打開excel表格后發現我的推測是正確的,是這塊的值出現了四五千此,洗掉多余的值后,得到1827個數,正好對應了五年的每一天,
雖然我找到了出問題的資料,但資料為什么出問題我還不是很清楚,發現的大佬可以在評論區指點,
下面是代碼模板,我后期有一定除錯,直接跑應該跑不出來,這里理解思路即可
import datetime
import numpy as np
import math
import pandas as pd
import numpy as np
import xlwt
import matplotlib.pyplot as plt
df=pd.read_excel("E://桌面//LBMA-GOLD.xlsm")
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('lbma-gold',cell_overwrite_ok=True)
value,data=[],[]
for i in range(1254):
data.append(df.values[i][2])
value.append(df.values[i][1])
#print(str(data[0]).split('/'))
#1253
price=[]
for i in range(125):
ans=str(data[i]).split('/')
#print(ans)
str1='null'
if len(ans[0])==4:
if int(ans[0])>2009:
str1=ans[0][-2:]
else:
str1=ans[0][-1:]
#print(str1)
else:
str1=ans[0]
#print(str1)
str2=ans[1]
str3=ans[2]
num1,num2,num3=int("20"+str3),int(str1),int(str2)
d1 = datetime.datetime(num1,num2,num3)# 第一個日期
ans=str(data[i+1]).split('/')
#print(ans)
str1='null'
if len(ans[0])==4:
if int(ans[0])>2009:
str1=ans[0][-2:]
else:
str1=ans[0][-1:]
#print(str1)
else:
str1=ans[0]
#print(str1)
str2=ans[1]
str3=ans[2]
num1,num2,num3=int("20"+str3),int(str1),int(str2)
d2 = datetime.datetime(num1,num2,num3)
interval = d2 - d1
#price.append(interval.days)
#print(interval.days)
for j in range(interval.days):
price.append(value[i])
for i in range(len(price)):
sheet.write(i,0,price[i])
savepath = 'E:/桌面/篩選后的資料.xlsx'
book.save(savepath)模型假設
第一問:
假設1:為了合理的預測出股價未來的走勢之后再進行交易,我們假設觀察者觀測十五天金價和位元幣的的價格變化,再做投資,
假設2:為了防止本金全部虧空,我們假設交易的程序中每次交易的金額不能超過初始金額
第三問:
假設:通過我們第一問的模型求解,我們發現單筆交易金額越接近初始值,最后的收益就會越好,所以投資者傾向于單筆投資額接近于初始金額越好,對于初始金額的確定,由于第三問是分析不同傭金下,對交易結果和策略的影響,所以我們不考慮金子和位元幣的初始值的分配關系,且由第一問可知,開始金額越大整體收益越好,由以上,我們假設位元幣和金子的初始金額為1000,單次交易為1000元,
第一問
總體思路
第一問中我們需要考慮兩個模型,一個是預測模型,一個是交易模型,預測模型預測了未來股票的走勢,判斷了我們交易的買點和賣點,交易模型則明確了我們以何種策略進行交易,
在預測模型中,我們采用層次分析法,設定了三個指標,RSI, MACD,以及灰色預測法對未來趨勢的判定,計算得出當日交易指標的總分,判斷總分sum是否滿足買入賣出標準,不滿足則觀望,滿足則進入交易模型,模擬交易,
我們的交易策略是,如果預測模型預測到商品價格上漲,則買入的值為a元的貨物,對a做靈敏度分析,確定買入多少能實作我們最終利潤的最大化,如果預測模型預測到商品價格大跌,我們賣出全部的存貨,以避免損失,值得注意的一點是,我們在買入時,要將買到的貨物存到一個變數中,且在總資金中減去購買貨物用到的錢,在賣出時,當前的貨物要乘以此時的單價,加上我們現有的現金,
需要考慮的是題目開始要求我們黃金的交易傭金是1%,位元幣是2%,且黃金只有在開盤日交易,位元幣可以每天交易,這點體現在我們交易模型中,是否交易的判斷準則中,
預測模型
評價指標1
MACD:
MACD(Moving Average Convergence and Divergence) 是Geral Appel 于1979年提出的,利用收盤價的短期(常用為12日)指數移動平均線與長期(常用為26日)指數移動平均線之間的聚合與分離狀況,對買進、賣出時機作出研判的技術指標
上面是關于macd的介紹,是要寫在論文當中的,但在我們實際的編碼程序中,我們只要找到macd的演算法,計算出每一天的macd的值,如果macd穿過零點,如果導數為負,則賦權-5,給出強烈的賣出信號,導數為正,則賦權5給出強烈的買入信號,
有關macd的具體演算法,感興趣的同學可以去網上自行搜索
下面是代碼:
import pandas as pd
import numpy as np
import datetime
import time
#獲取資料
df=pd.read_csv('E:/桌面/美賽代碼/macd.csv',encoding='gbk')
#df.columns=['date','code','name','close','high','low','open','preclose',
#'change','change_per','volume','amt']
#df=df[['date','open','high','low','close','volume','amt']]
#print(df.head())
print(df.iloc[0,3])
def get_EMA(df,N):
for i in range(len(df)):
if i==0:
df.iloc[i,12]=df.iloc[i,3]
# df.ix[i,'ema']=0
if i>0:
df.iloc[i,12]=(2*df.iloc[i,3]+(N-1)*df.iloc[i-1,12])/(N+1)
ema=list(df['ema'])
return ema
def get_MACD(df,short=12,long=26,M=9):
a=get_EMA(df,short)
b=get_EMA(df,long)
df['diff']=pd.Series(a)-pd.Series(b)
#print(df['diff'])
for i in range(len(df)):
if i==0:
df.iloc[i,14]=df.iloc[i,13]
if i>0:
df.iloc[i,14]=((M-1)*df.iloc[i-1,14]+2*df.iloc[i,13])/(M+1)
df['macd']=2*(df['diff']-df['dea'])
return df
get_MACD(df,12,26,9)
print(df)
with pd.ExcelWriter('macd_gold.xlsx') as writer:
df.to_excel(writer, 'df1')評價指標2
建立RSI指標:
| RSI值 | 市場特征 | 投資操作 |
| 80—100 | 極強 | 賣出 |
| 50—80 | 強 | 觀望 |
| 20—50 | 弱 | 觀望 |
| 0—20 | 極弱 | 買入 |
計算方法:
RS(相對強度)=N日內收盤價漲數和之均值÷N日內收盤價跌數和之均值
RSI(相對強弱指標)=100-100÷(1+RS)
解釋:
RSI的計算公式實際上就是反映了某一階段價格上漲所產生的波動占總的波動的百分比率,百分比越大,強勢越明顯;百分比越小,弱勢越明顯,
(1)相對強弱指數能顯示市場超賣和超買,預期價格將見頂回軟或見底回升等,但RSI只能作為一個警告訊號,并不意味著市勢必然朝這個方向發展,尤其在市場月烈震蕩時,趕賣還有超賣,超買還有超買,這時須參考其他指標綜合分析,不能單獨依賴RSI的訊號而作出買賣決定,
(2)背離走勢的訊號通常者都是事后歷史,而且有背離走勢發生之后,行情并無反轉的現象,有時背離一,二次才真正反轉,因此這方面研判須不斷分析歷史資料以提高經驗,
(3)在牛皮行情時RSl徘徊于40-60之間,雖有時突破阻力線和壓力線,但價位無實際變化,
(4)更適用小時線以上的行情,更利于判斷中長期的趨勢,同時RS拼并不能給出明確說明走勢的幅度,只能作為輔助工具并不適用直接來做交易指導,在KSI中所畫的趨勢線,由于S有預先示警的作用,所以第一次的趨勢線突破并不能提供展的買賣時機,但在突破趨勢線的后續的走勢中所畫趨勢線具有的效用會增強(通常在再次接按近所畫趨勢線時,可以有較強的支撐,阻力作用)
如果rsi判斷買入,我們就給這項賦權為5,如果賣出則賦權-5
代碼:
import numpy as np
import math
import pandas as pd
import numpy as np
import xlwt
import matplotlib.pyplot as plt
#相對強弱指標RSI
#計算公式:
#<1> N日RSI =A/(A+B)×100
#<2> A=N日內收盤漲幅之和的平均 A = (前一日A*(n-1) + 當日漲值)/n
#<3>B=N日內收盤跌幅之和的平均 B = (前一日B*(n-1) + 當日跌值)/n (跌值取正值:如下跌-4.32,跌值=4.32)
#<4> 0<=RSI<=100
# 輸入:
# close_k: 收盤價list
# periods:周期
#從第periods+1個周期開始預測
def RSI(close_k,periods):
length = len(close_k)
ans = [np.nan]*length
A = 0
B = 0
sum1,sum2=0,0
for j in range(periods):
up = 0
down = 0
if close_k[j]>=close_k[j-1]:
up = close_k[j]-close_k[j-1]
down = 0
else:
up=0
down = close_k[j-1]-close_k[j]
sum1+=up
sum2+=down
A=sum1/periods
B=sum2/periods
for j in range(periods,length):
up = 0
down = 0
if close_k[j]>=close_k[j-1]:
up = close_k[j]-close_k[j-1]
down = 0
else:
up=0
down = close_k[j-1]-close_k[j]
#計算N日內增長的均值,A為增加值的和的均值,B為減少值的和的均值
A = (A*(periods-1)+up)/periods
B = (B*(periods-1)+down)/periods
if A + B!=0:
ans[j] = 100 * A / (A + B)
return ans
if __name__=='__main__':
df=pd.read_excel("E://桌面//篩選后的資料.xlsx")
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('lbma-gold',cell_overwrite_ok=True)
data=[]
for i in range(1825):
data.append(df.values[i][1])
ans=RSI(data,6)
for i in range(1825):
sheet.write(i,0,ans[i])
savepath = 'E:/桌面/rsi_mkpur.xlsx'
book.save(savepath)
#print(RSI(date,12))
#print(len(RSI(date1,12)))評價指標3
預測模型預測未來連續上漲或者下降的天數:
我們使用灰色預測法,以十個樣本點為一組進行訓練,得到兩種貨幣的下一個預測值,得到了未來十天的預測值,注意此時這十天的真實的價格資料我們是已經拿到了的,那么我們就將這十天的資料重新進入灰色預測模型訓練,得到下一個十天周期的預測值,
我們在編程實作灰色預測法進行實驗的時候,需要對預測值進行檢驗,計算出P,C后進行等級判斷:
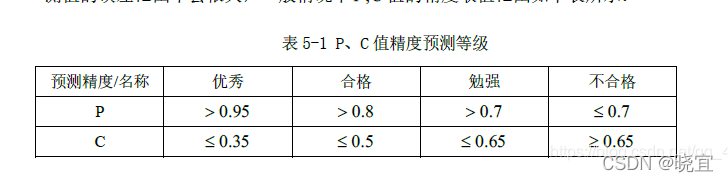
符合標準后則回傳給我們預測值,
代碼:
import numpy as np
import math
import pandas as pd
import numpy as np
import xlwt
import matplotlib.pyplot as plt #畫圖的庫
def predict(history_data):
n = len(history_data)
X0 = np.array(history_data)
#累加生成
history_data_agg = [sum(history_data[0:i+1]) for i in range(n)]
X1 = np.array(history_data_agg)
#計算資料矩陣B和資料向量Y
B = np.zeros([n-1,2])
Y = np.zeros([n-1,1])
for i in range(0,n-1):
B[i][0] = -0.5*(X1[i] + X1[i+1])
B[i][1] = 1
Y[i][0] = X0[i+1]
#計算GM(1,1)微分方程的引數a和u
#A = np.zeros([2,1])
A = np.linalg.inv(B.T.dot(B)).dot(B.T).dot(Y)
a = A[0][0]
u = A[1][0]
#建立灰色預測模型
XX0 = np.zeros(n)
XX0[0] = X0[0]
for i in range(1,n):
XX0[i] = (X0[0] - u/a)*(1-math.exp(a))*math.exp(-a*(i));
#模型精度的后驗差檢驗
e = 0 #求殘差平均值
for i in range(0,n):
e += (X0[i] - XX0[i])
e /= n
#求歷史資料平均值
aver = 0;
for i in range(0,n):
aver += X0[i]
aver /= n
#求歷史資料方差
s12 = 0;
for i in range(0,n):
s12 += (X0[i]-aver)**2;
s12 /= n
#求殘差方差
s22 = 0;
for i in range(0,n):
s22 += ((X0[i] - XX0[i]) - e)**2;
s22 /= n
#求后驗差比值
C = s22 / s12
#求小誤差概率
cout = 0
for i in range(0,n):
if abs((X0[i] - XX0[i]) - e) < 0.6754*math.sqrt(s12):
cout = cout+1
else:
cout = cout
P = cout / n
if (C < 0.5 and P > 0.7):
#預測精度為一級
m = 1 #請輸入需要預測的年數
#print('往后m各年負荷為:')
f = np.zeros(m)
for i in range(0,m):
return (X0[0] - u/a)*(1-math.exp(a))*math.exp(-a*(i+n))
print(f)
else:
print('灰色預測法不適用')
if __name__ == '__main__':
df=pd.read_excel("E://桌面//美賽代碼//lbma-gold(篩選).xlsx")
df1=pd.read_excel("E://桌面//美賽代碼//bchain-mkpru(篩選).xlsx")
data=[]
for i in range(727):
data.append(df.values[i][1])
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('lbma-gold',cell_overwrite_ok=True)
#print(data[726])
cnt=9
ans=[]
history_data=[0]*10
#print(history_data)
#過去若干個交易日的資料,從第十個資料開始預測
for i in range(11,727):
#更新預測模型的資料
cnt+=1
if cnt%10==0:
temp = data[i-10:i]
#print(temp)
for j in range(10):
history_data[j]=temp[j]
cnt=0
#預測資料
ans.append(predict(history_data))
#print(ans)
for i in range(702):
sheet.write(i,0,ans[i])
savepath = 'E:/桌面/灰色預測_gold.xlsx'
book.save(savepath)
plt.figure()
plt.plot(list(range(len(ans))), ans, color='b')
plt.plot(list(range(727)), data[:727], color='y')
plt.show()經過我們的計算發現,改進后的灰色預測預測模型所得出的預測值與真實值擬合度非常高,如下圖
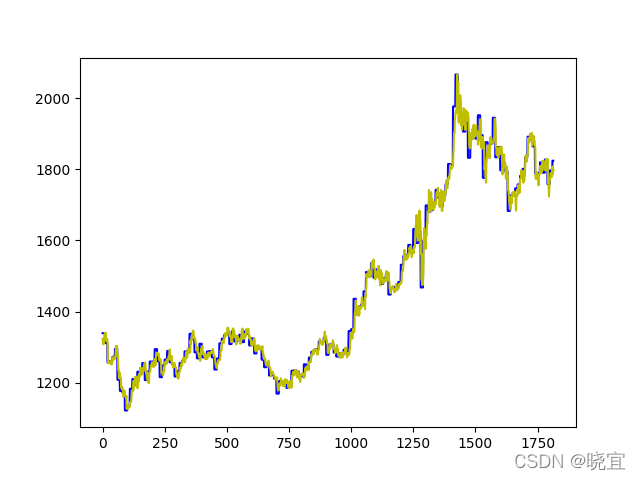
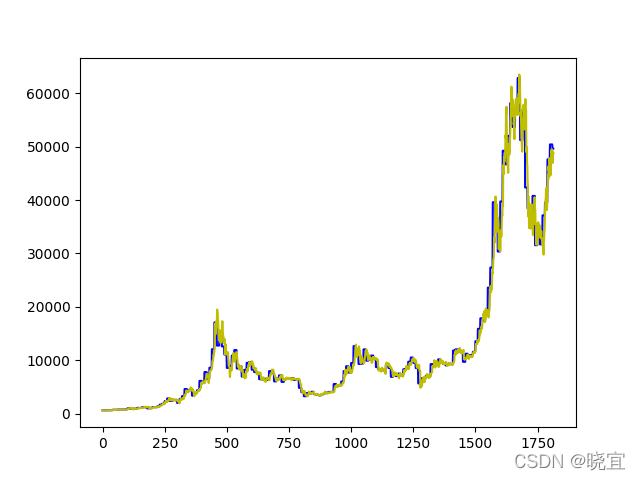
其實第一問的預測模型僅僅只是使用不斷迭代的灰色預測模型也是可以解決的,只是在第二問中的交易模型中需要改變判斷標準,例如連續上漲或者下降的天數,單次上漲或下降的幅度,但在這里,我只是用它去預測未來時天的漲勢,連續上漲n天則評分為n,下降n天則評分-n,詳情見下面的層次分析法,
層次分析法(AHP)
- 構建層次結構模型(論文中不是這樣的,這里是自己畫的):
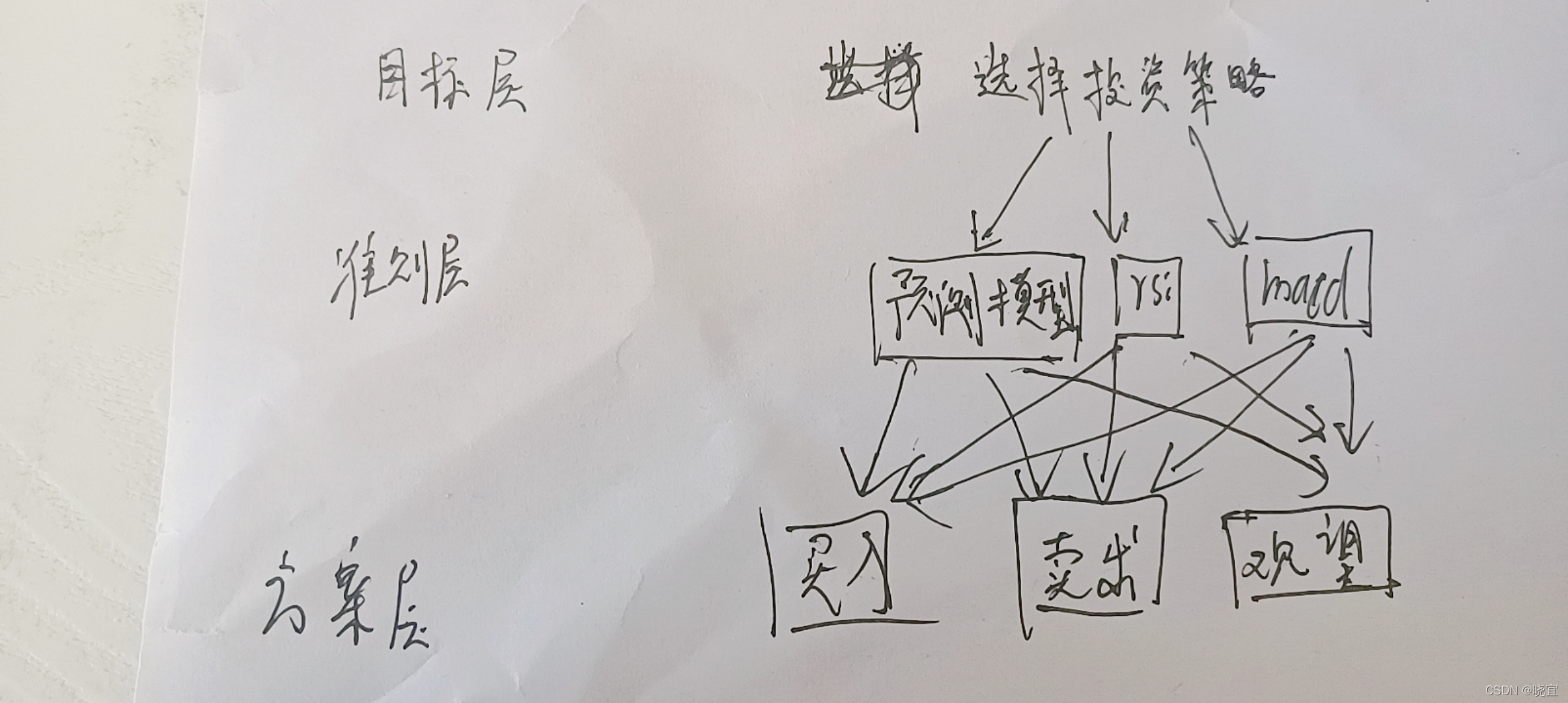
2.構造判斷矩陣:
我們在這里使用,對三個指標進行分析,由于我們的預測模型擬合度非常高,故我們將其的重要性為最高,其余兩個指標的權重相同,在構建3*3判斷矩陣時將預測模型的的重要性設定為其余二者的3倍,其余都設定為1,
判斷矩陣如下:
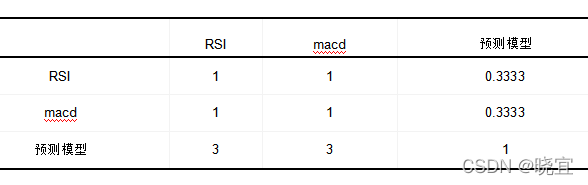
經過我們的分析得到如下結果:
| RSI | MACD | 預測模型 | 特征向量 | 權重值 | |
| RSI | 1 | 1 | 0.3333 | 0.6934 | 0.2 |
| MACD | 1 | 1 | 0.3333 | 0.6934 | 0.2 |
| 灰色預測 | 3 | 3 | 1 | 2.0801 | 0.6 |
特征向量:(0.6934,0.6934,2.0801)的轉置
該判斷矩陣最大特征值為3,CI值為0,RI值為0.525,層次單排序一致性檢驗通過
CR值為0,層次總排序一致性檢驗通過
由圖表可得,RSI,MACD,預測模型的權重分別為0.2,0.2,0.6.
我們先假設一開始投資人黃金和位元幣各分出500元進行投資,對三個指標在(-5,5)內設定不同的打分規則,
RSI:如果RSI>80,則這項為滿分5,如果RSI<20,則這項賦分-5,其余情況為0分
macd:如果為零的話,判斷此時的斜率,斜率大于零,則此項賦值為5,如果斜率小于零則賦值為-5,
灰色預測:我們通過預測未來的十個值進行判斷,未來連續上漲幾次權值就為幾
sum=三個模型的得分相加除以20,用這個值乘以我們每次交易設定的最大值,就是我們買入(大于零)或者賣出(小于零)的值a,
我們先對原始金價和位元幣的資料進行處理,得到這五年中每一天金價和位元幣的rsi,macd,灰色預測模型預測的連續上漲或下跌的值,(見”總數居匯總(AHP)“)
并且計算未來上漲的金額與傭金相比較,如果大于傭金的三倍,則賦值,否則觀望處理,賦值為0,
計算出三個指標的最終得分后,我們使用這個公式計算出ratio:
名詞解釋:
1.ratio為價格預測指標,如果tation大于零,則說明有上漲趨勢,小于零則有下降趨勢
2.point1~3為三個指標的分數
3.p1~3為權值
4.”8“我們的模型中分數的最大值即0.2*5+0.2*5+10*0.6
關于這部分的代碼將會在交易模型中給出
交易模型
計算出計算出ratio之后,經過靈敏度檢驗我發現:,當ratio大于0時買入,小于0時賣出,這樣的收益最大,但是這樣一來,我們最終的收益將會非常大,我在解題的時候覺得不時很合理,所以在論文中寫的是這段話:
”對于位元幣,買入賣出邊界為0.3最好,即如果ratio>0.3或者ratio<-0.3,則進行買入,賣出操作,否則不處理,對于金價,經過靈敏度分析,其最優邊界,買入邊界為0.25,賣出邊界為-0.3“
其實作在想想,當扯訓是過于謹慎了,按照位元幣的漲勢來說如果我們可以準確的判斷出買入賣出的點,那么我們確實可以實作極大的收益,而我們的預測模型準確性很高,所以幾百萬的收益也是合乎常理的,
而且在買入時,我還在假設中設定了上限,即不超過初始金額,相信如果把這一限制改成本金的70%,甚至100%,將會得到更加巨大的收益,這點我也寫進了模型的改進與缺點中,
我們在買入操作時,我們一方面要減去我們花的錢,另一方面要重新設定一個變數存盤我們買下的貨物,由于題目中給定的資料為:盎司/美元,枚/美元,故我們采用公式:
計算存盤的貨物,其中vast為我們單次交易的金額
在執行賣出操作時,執行預判到價格下降則全部賣出的策略,使用公式:
其中cost_m為我們的損耗率,earn為我們賺的錢,我們將他加在我們最后的end值上,此輪投資結束,
邊界確定:當我們進行到最后一個交易日時,將所有的資產美元化,得出我們在2021年10月9日的最終收益,同時要注意一點,黃金只有在交易日可以交易,這點反映在我們的代碼中,作為判斷是否買入的條件出現,
接著,我們對vast做靈敏度分析,發現vast約接近初始金額,得到的收益越大,我們也對初始金額做了靈敏度分析,發現對于位元幣和金子來說初始金額越大,最終的收益率越高,
經過我們對初始金額和單次交易量二者的的分析,我們發現投資位元幣的收益要遠遠大于投資黃金,1000美元的初始資金如果全投位元幣的話可以得到147545,而黃金僅僅為3086,通過計算1000美元不同的分配下位元幣和黃金的總收益,我們發現最終的交易策略是1000美元全部用來交易位元幣,單次交易金額為1000元,最后的的收益率為1276454%,雖然這個收益率是極大的,但卻十分符合位元幣價格的趨勢和市場發展,側面體現了預測模型和決策模型的正確性,有關更多正確性的的證明,我們會在第二問中講到,
注:在我實際運行程式時,會發現當單次交易金額大于本金時,程式也能跑通,應該是某個邊界條件設定的失誤,大佬發現的話可以指出來,
代碼
import numpy as np
import math
import pandas as pd
import numpy as np
import xlwt
import matplotlib.pyplot as plt #畫圖的庫
mkpru=pd.read_excel("E://桌面//美賽代碼//總資料匯總.xlsx",sheet_name="gold")
start=1000 #初始投資額
end=start #結束時的投資額
a = 0.3 #每次投資的最大值占總投資額的百分比
cost_m=0.15 #設定傭金
cost_g=[0.002,0.005,0.007,0.01,0.02,0.03,0.05,0.06,0.08,0.09,0.1,0.2,0.3]
p1,p2,p3=0.2,0.2,0.6 #三項指標的權重,順序為macd,rsi,預測模型
sum1=0 #投出去的美元
sum2=0 #手中持有的位元幣
vast=1000
#vast=100 #每次購買的值
col,row,li=[],[],[]
for n in range(len(cost_g)):
cnt=0 #計算拒絕的次數
cnt1=0#計算買入的次數
cnt2=0#計算賣出的次數
for i in range(1,1813):
#計算macd的得分
if mkpru.values[i-1][0]<0 and mkpru.values[i][0]>0:
point1=5
elif mkpru.values[i-1][0]>0 and mkpru.values[i][0]<0:
point1=-5
else:
point1=0
#計算rsi的得分
if mkpru.values[i][1]>80:
point2=5
elif mkpru.values[i][1]<20:
point2=-5
else:
point2=0
#計算灰色預測的得分
point3=0
for j in range(10):
if mkpru.values[i+j][2]<mkpru.values[i+j+1][2]:
point3+=1
else:
break
for j in range(10):
if mkpru.values[i+j][2]>mkpru.values[i+j+1][2]:
point3-=1
else:
break
#預測收益,如果收益率大于傭金的三倍,執行交易,否則不執行
if mkpru.values[i+1][0]/mkpru.values[i][0]-1 < 3*cost_g[n]:
cnt+=1
point1,point2,point3=0,0,0
ratio=(point1*p1+point2*p2+point3*p3)/8
if ratio>0.1 and end-vast>=0 and mkpru.values[i][3]!=mkpru.values[i-1][3]:
cnt1+=1
end-=vast
sum1+=vast
sum2+=vast/mkpru.values[i][3]
earn=sum2*mkpru.values[i][3]*(1-cost_m)-sum1*(1+cost_g[n])
if ratio<-0.3 and earn>=0:
cnt2+=1
earn=sum2*mkpru.values[i][3]-sum1*(1+cost_g[n])
end+=earn
#假設最后一天會賣出
earn=sum2*mkpru.values[1813][3]*(1-cost_m)-sum1*(1+cost_g[n])
end+=earn
print(end," ",cnt," ",cnt1)
col.append(cnt)
row.append(end)
li.append(cnt1)
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
sheet = book.add_sheet('lbma-gold',cell_overwrite_ok=True)
for i in range(10):
sheet.write(i,0,row[i])
sheet.write(i,1,col[i])
sheet.write(i,2,li[i])
savepath = 'E:/桌面/200.xlsx'
book.save(savepath)第二問
第二問是我的隊友負責的,通過計算均線,得出黃金和位元幣的布林帶,統計黃金和位元幣不在布林帶的范圍的次數,最后得出位元幣的投資風險比黃金低,是更優質的投資選擇,證明了第一問中全部投資位元幣的策略的正確性,他在此問中沒有用到編程,但我想如果用python會比單純使用excel簡單,
第三問
交易傭金的靈敏度分析
我們分別對位元幣和黃金的交易傭金進行靈敏度分析,設定:
cost_g=cost_m=[0.002,0.005,0.007,0.01,0.02,0.03,0.05,0.06,0.08,0.09,0.1,0.2,0.3]
注:cost_g為黃金的交易傭金占總交易量的百分比,cost_m為位元幣的交易傭金占總交易量的百分比
由第一問可知,無論是黃金還是位元幣,當二者初始金額為1000,單次交易量為1000時,最終收益最大,我們在這一問中不考慮二者初始值的關系,都設定成1000,單筆交易額設定成1000,即通過不同的交易傭金對最優模型的影響來推斷交易成本如何影響策略和結果,
經過計算,見表”交易傭金的靈敏度分析.Xlsm”,黃金的最終收益隨著傭金的升高先升高再小幅度回落,最后再升高,觀望的次數增多,買入的次數變化不大;位元幣的收益存在先下降后上升的程序,其觀望次數也隨著傭金的增加而增加,買入次數保持平穩,
我們看到,交易傭金的變化與最終收益的影響并不相關,其原因是我們觀望的次數增加了,隨著傭金的增加,某些買入的時間點被過濾掉,從而在下一個滿足要求的時間點購買了產品,但是這個時間點決策相對于上一個時間點決策的好壞我們無從得知,而我們的買入次數也幾乎不受影響,
模型的不足
模型有兩方面的不足:
1.首先是上文所說的買進時設定了上限,不能讓每次買入花費的金額大于初始投資額,這是一種非常謹慎的投資策略,但是我們的預測模型預測的非常準確,可以很好的判斷出未來的趨勢,所以可以大膽一點,如果取消這個限制,我們最終的收益應該會更棒
2.單次買入金額的確定,我在開始設定單次金額時曾試圖設定動態調價機制,但嘗試了許久,也未能成功,計算出的值虧本了,加上比賽時間有限,就換用簡單的策略,代替了原先策略,好在取得了不錯的收益,有大佬設計了動態調價模型可以在評論區指點,
具體的代碼和資料可以在csdn資源下載,(注:此壓縮包的思路部分為一開始的思路,未作改動,本文為真實做法)
美賽壓縮包
也可以在百度網盤下載
鏈接: https://pan.baidu.com/s/1nfoJt7uf3ZPXgB3eqE5DfQ?pwd=s7gb
提取碼: s7gb 復制這段內容后打開百度網盤手機App,操作更方便哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433252.html
標籤:其他