
本文回顧了經典的CNN結構,并附上相應的pytorch代碼,融合了部分Ng、沐神講解的內容(主要是ResNet),主要是寫一下反思,幫助理解CNN的一些核心思想,
PPT來自:計算機視覺與深度學習 北京郵電大學 魯鵬
代碼來自沐神《動手學深度學習》,
文章目錄
- 卷積概述
- 卷積特征圖
- 池化層
- AlexNet(2012)
- 貢獻
- 結構
- 呆碼
- *重要規律
- 反思:卷積層到底在做什么?
- ZFNet(2013)
- VGG(2014)
- VGG-11的呆碼
- 反思:小卷積核有什么優勢?
- 反思:為什么經過一次Pooling, 卷積核個數要增加一倍?
- GoogLeNet(2014)
- Inception塊呆碼
- 反思:關于1 * 1的卷積(NiN):
- ResNet(2015)
- Residual
- 兩種ResNet塊
- 反思:為什么ResNet可以訓練到1000層?
- 從反向傳播理解
- 集成模型(核心理解)
- ResNet18呆碼
- ResNet18結構圖
- Summary
卷積概述

ReLU接在卷積層后面,對卷積的結果進行處理(卷積得到的結果不都是正數)!
卷積層堆疊:后面的conv可以在前面conv的基礎上繼續提取特征,
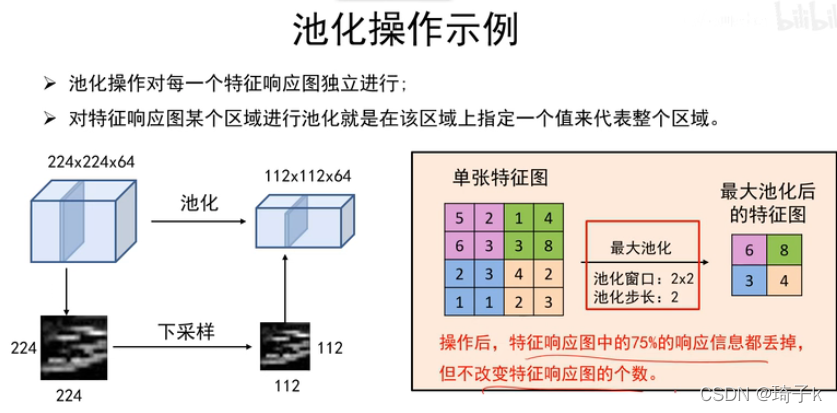
Pooling: 不改變深度資訊,只減小空間尺寸,之后卷積需要計算的空間位置就減少了,【一般每pooling一次,下降一倍】
雖然卷積核的大小不變,但是越靠后,感受野“相對越大”,相當于從一個更大的尺度上觀察影像【前面細粒度,后面粗粒度】,
卷積特征圖

卷積核的個數決定了這一層輸出的特征圖的個數,也是下一層卷積核的深度,
池化層
AlexNet(2012)
貢獻

動量:使得震蕩方向減小,運動比較慢的方向加強,更快的通過平坦的區域,
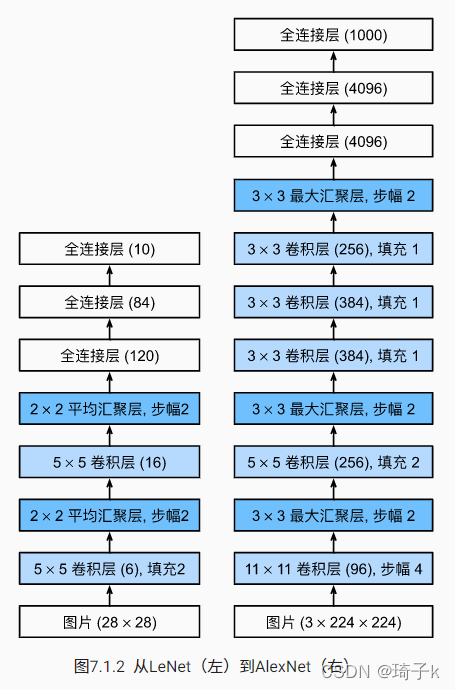
結構

注:
1、這個Norm現在已經不用了,并不是BN,
2、說“網路層數”,我們只算Conv層和FC層,
3、算引數的時候“+1”是bias.
4、輸入227 * 227 * 3的影像之前,進行了去均值處理【統計所有訓練樣本每個位置像素的均值,也是一個227 * 227 * 3的,然后對于每一個影像,減去這個均值向量】,
作用?——
在進行分類的時候,”絕對值“是無意義的,我們只需要比較”相對值“,去均值之后,保留了相對值,還可以使得資料減小,

這里使用的池化是重疊池化(但是在之后的網路中,一般還是使用不重疊的池化),
池化不學習引數!

Norm的作用:將差距拉大,“助紂為虐,落井下石”,從VGG開始就去掉了,
呆碼
以28 * 28 * 1的圖片為例,pytorch代碼:
# 這里由于是MINST資料集,所以輸入的通道是1; 如果是ImageNet資料集,就應該是3了
net = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2), nn.Flatten(),
nn.Linear(256 * 5 * 5, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5),
nn.Linear(4096, 10)
)
*重要規律
驗證集損失不下降時,可以手動降低10倍學習率,
反思:卷積層到底在做什么?

256是256種特征回應模板,亮代表此處切合度高,
ZFNet(2013)

1、將第一個卷積改成7 * 7,這樣方便感受更細粒度的內容;
2、步長設定成2,不讓解析度降低的太快,而是一點點降低;
3、之所以只增加后面層卷積核的個數:認為 “基元” 的內容是很少的(影像的底層特征),我們不需要很多的卷積核;但是他們之間組合出來的特征卻很多,越到后面,卷積核包含的語意資訊就越多,增加卷積核的個數,可以理解更多的語意資訊,
VGG(2014)

串聯小卷積核可以獲得更大的感受野,而不非用大卷積核,串聯小卷積核經過了多次變換,非線性性更強,
VGG處理歸一化和AlexNet不同,VGG統計所有圖片R, G, B的均值,然后將【R, G, B】作為均值,
之前是,若干圖片同一位置的像素的R、G、B求均值,現在是若干圖片所有像素的R、G、B求均值,

前層卷積核的個數少,后層卷積核的個數多,前層學習的是 “基元”資訊,后期學習的 “語意”資訊多,【與ZFNet類似】
但是并不越多越好,因為后面要接一個FC,如果太大,展開成向量輸入FC的話,會非常大,
VGG-11的呆碼
與VGG-16相比,每一個卷積塊都少一個卷積層,
# 超引數:需要的卷積層的個數、輸入輸出的channel數
def vgg_block(num_convs, in_channels, out_channels):
layers = []
for i in range(num_convs):
layers.append(nn.Conv2d(
in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(
num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(4096, 10)
)
反思:小卷積核有什么優勢?
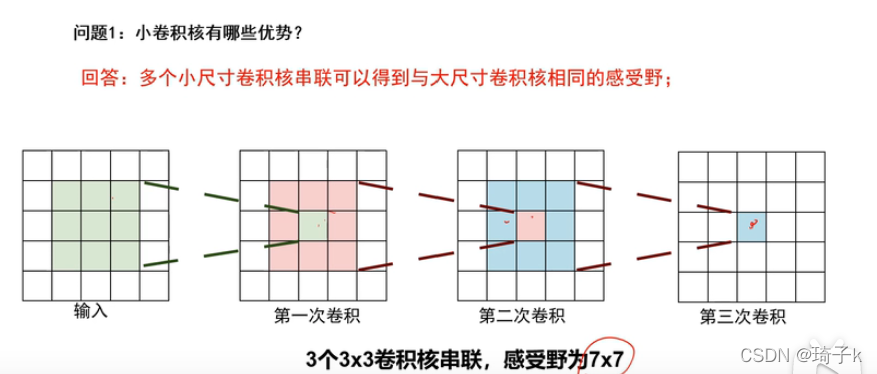
兩個3 * 3的小卷積核串聯,其實就等效于一個5 * 5的卷積核,他們的感受野是一樣的,
但是,串聯多經過了一次變換,非線性能力更強【感性理解:組合出來之后,會更復雜,得到更復雜的資訊】,
此外,引數也更少,
反思:為什么經過一次Pooling, 卷積核個數要增加一倍?

“動態平衡”的思想,如果不Pooling,那顯存占用太大,
GoogLeNet(2014)

核心改進:網路結構發生本質改變,引入Inception塊,

為什么不采用串聯結構了呢?
舉一個栗子,如果圖中有一條很寬的線,但是用小卷積核,只能把他提取成四條邊,這樣一個重要資訊就丟失了,
所以,這個錯誤是“疊加”的,前面丟失了資訊,后面無法挽回,
【注:沐神在《動手學深度學習》中提供另外一種說法:“小學生才做選擇題,我全都要!”
既然不知道什么時候用3 * 3, 5 * 5,那我不如全都留下來,一起算,】
解決方案:保留前面層更多的資訊,
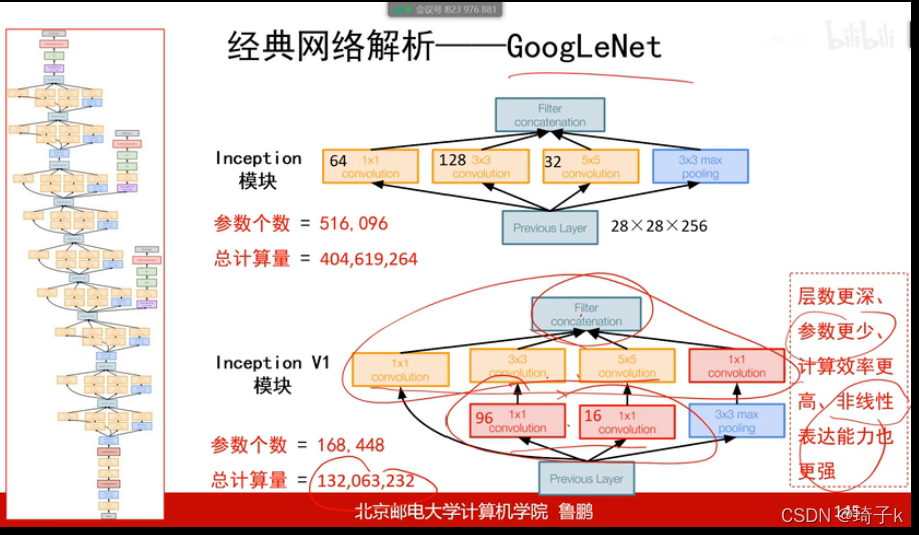
兵分四路,1 * 1的卷積對于通道做融合(相當于全連接);3 * 3的卷積感受細粒度的資訊,提取3 * 3區域資訊; 5 * 5的卷積感受相對粗粒度的資訊,提取5 * 5區域資訊;MaxPooling對強資訊做擴張【理解:如果有一個極大值像素,那么所有卷積操作包含它的部分都會變成這個值】,最后將所有的層concat(在深度方向拼接)起來,這四個層都不改變H * W的大小,
但是問題在于,如果直接這樣做,會很慢,所以在前面先用NiN(Network in Netwok),不改變寬高,但是改變通道數(深度).所以第2,3路的1 * 1塊與1,4路的1 * 1塊功能不同,1,4路的是融合資訊,對深度進行壓縮,2,3路是主要減少計算量(當然也會融合資訊),
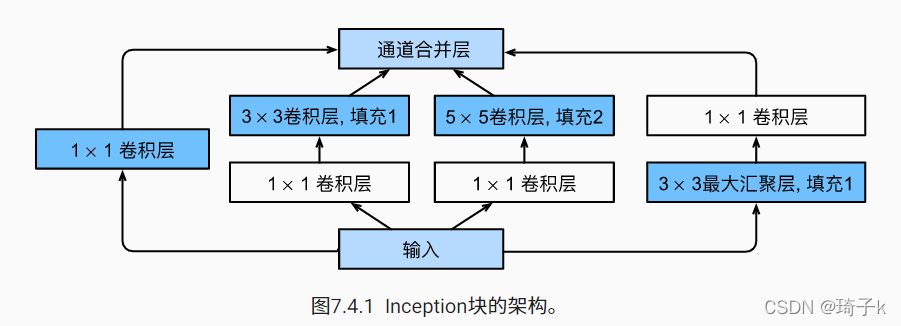
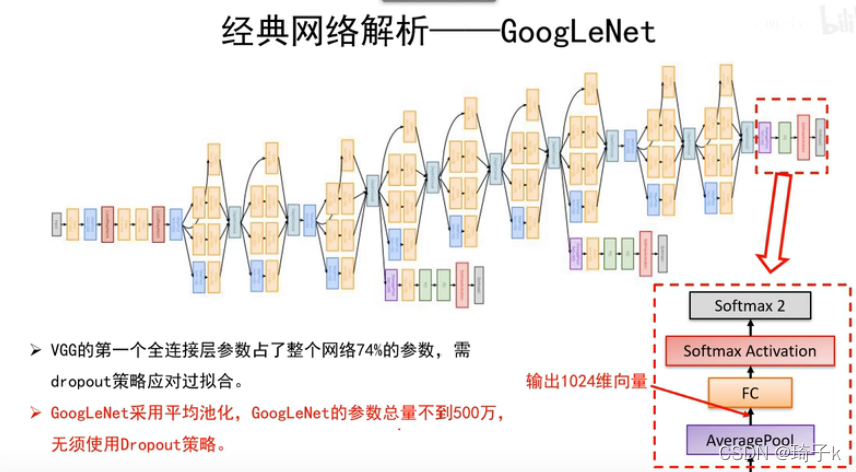
最后也砍掉了2個FC,大大減少了引數個數,取而代之的是一個AvgPooling,每個特征圖用一個最大值代替,【之前是每一個特征圖展開成一個長向量,現在是每個特征圖只保留一個值】
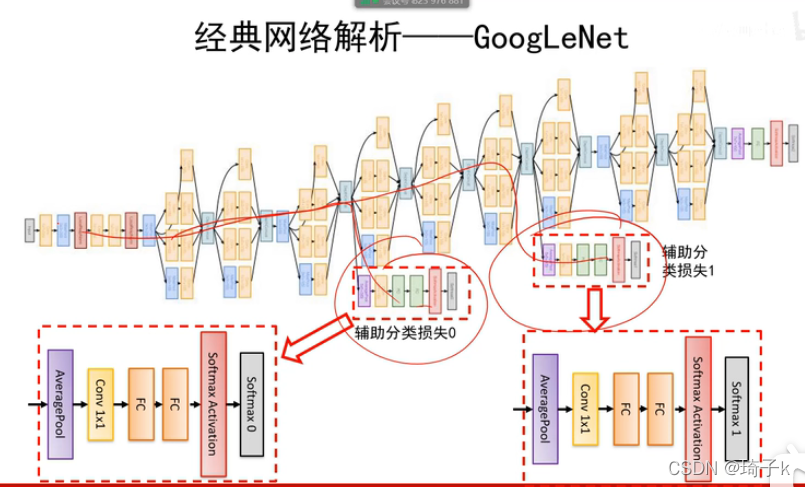
此外,GoogLeNet中還有兩個輔助分類器,因為網路太深,所以使用輔助分類器讓前面也能有梯度回傳(PPT中的兩條紅線)從而解決梯度消失問題,
ReLU雖然也可以一定程度解決梯度消失,但是并不能完全解決深層網路難以訓練的問題,加上輔助分類器之后,前面的層更好訓練,前面層學到的特征也能讓網路更快的收斂,
Inception塊呆碼
class Inception(nn.Module):
# c1--c4是每條路徑的輸出通道數
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 線路1,單1x1卷積層
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 線路2,1x1卷積層后接3x3卷積層
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
# 線路3,1x1卷積層后接5x5卷積層
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 線路4,3x3最大匯聚層后接1x1卷積層
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 在通道維度上連結輸出
return torch.cat((p1, p2, p3, p4), dim=1)
反思:關于1 * 1的卷積(NiN):
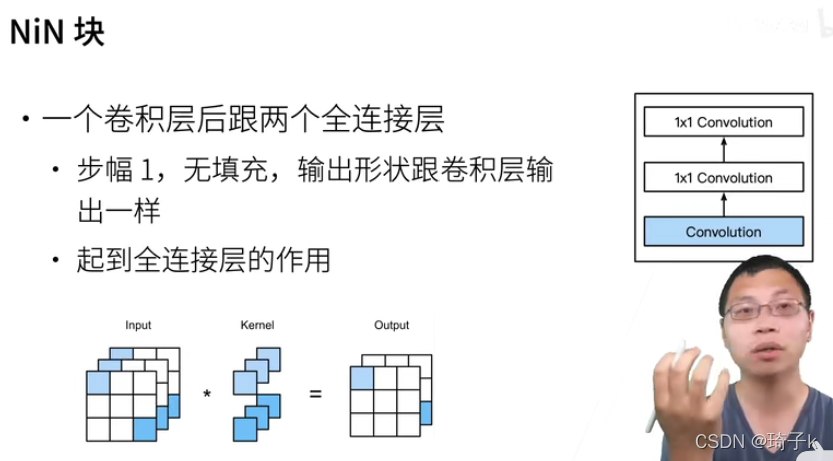
對于卷積層,可以理解為每一個像素有多個通道,如果通道數是100,可以理解為一個像素有一個長為100的向量,可以認為這個向量是這個像素的特征,那么可以理解為,每一個像素就是一個樣本,共有批量大小 * 高 * 寬個樣本,故,可以把通道層當做卷積層的特征維度,【這也是1 * 1的卷積相當于全連接的解釋】,
NiN會導致資訊的損失嗎?
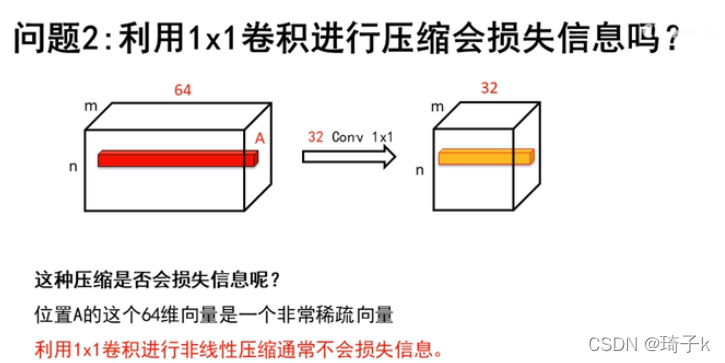
理論上壓碩訓損失,但損失的是“不存在”的特征,所以實際上未太損失,
以上圖為例,m * n * 64的特征圖,每一個卷積核都是描述一種結構【這個向量描述的是某個點A被64個卷積核卷積的結果】,但是影像在同一個位置只會有1種結構(或再多一點點,2-3種,但是不會很多),不可能卷積核描述的特征在原影像同一個位置都有,所以描述影像上A位置的這個向量(64維)是一個很稀疏的向量,壓縮之后,會把很多的0壓縮掉,所以不會丟失資訊,
ResNet(2015)
發現問題——網路并不是越深越好!
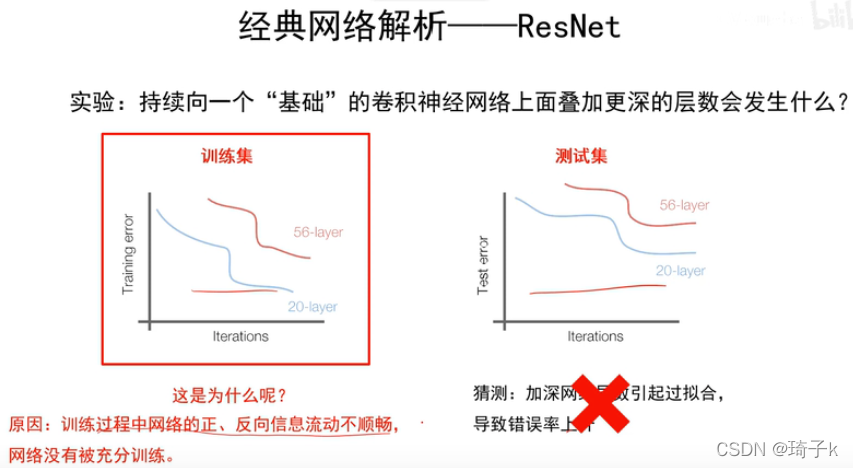
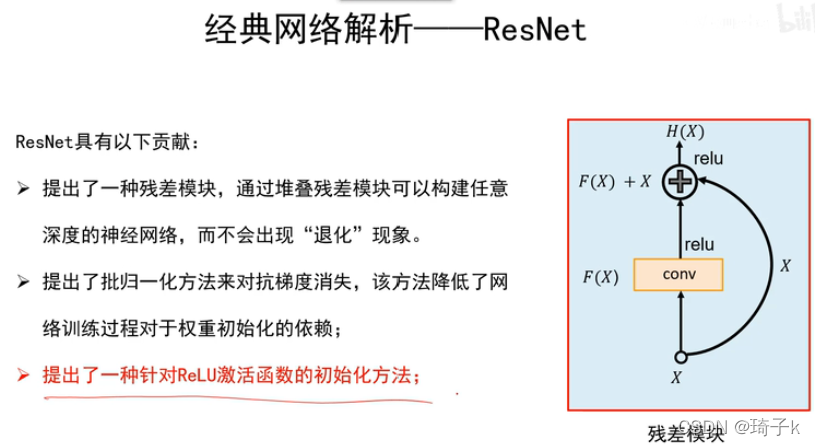
Residual
大名鼎鼎的殘差塊,幾乎成為之后深層網路的必備了(如Transformer中的Add&Norm層),
可以用下面的圖理解殘差塊,【這主要是從正向傳播的角度理解的】
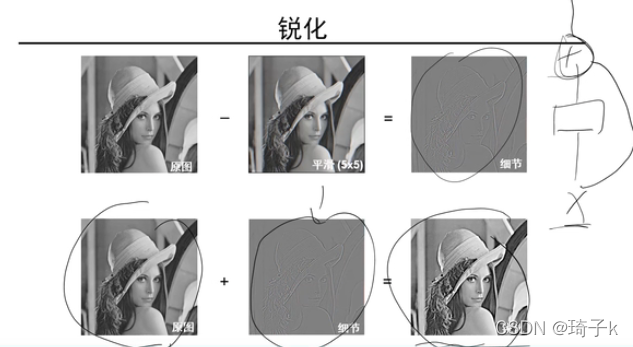
原圖 + 邊緣圖 = 銳化后的圖,在保證了原圖資訊的同時,把細節進行了強化,那我們可以這樣理解:輸入的X就是原圖,特征提取之后輸出的F(X)就是這個邊緣細節圖,他們和在一起的H(X)就是最后的輸出,【卷積在這里可以理解為那個邊緣提取器,】當然,銳化的增強是“人的視覺效果”最關心的資訊,在ResNet中增強的可不一定是人視覺上感興趣的資訊,有可能是對分類比較有興趣的資訊,這里只是拿銳化來對比理解下,
之前的網路,要學習的直接就是H(x),但是現在要學習的是F(X) = H(x) - X, 這也就是“殘差”的思想,即輸出和輸入的差異,

這里第一次使用1 * 1的卷積,依然是為了降低通道數【減少運算量】; 而第二次使用1 * 1的卷積,是為了增加通道數【不升回去沒法相加】,所謂 “瓶頸”就是深度先減小再增大,
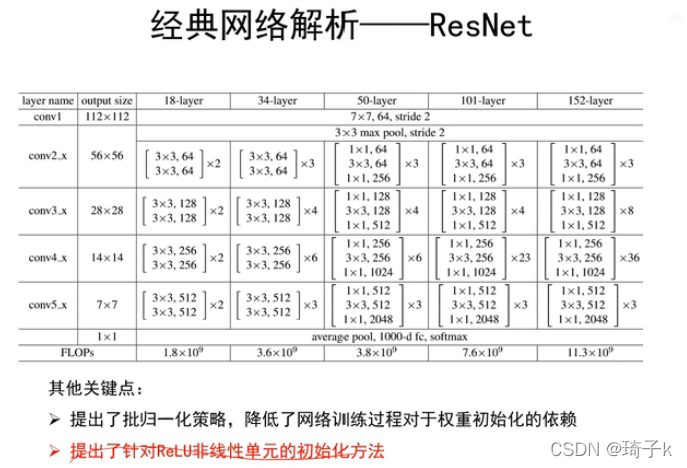
兩種ResNet塊
只看上圖會發現一個問題:維度對不上!因為Residual結構的存在,所以輸入輸出的維度應該完全不變才對(和X一致),
這里魯鵬老師沒有講,其實是因為有兩種ResNet結構:高寬減半的resnet塊和高寬不變的resnet塊,【注:這里李沐老師講的和上面的resnet結構稍有不同,因為魯鵬老師講的是resnet152,沐神講的是resnet18,但是原理一樣】,具體細節可以看下面的代碼,
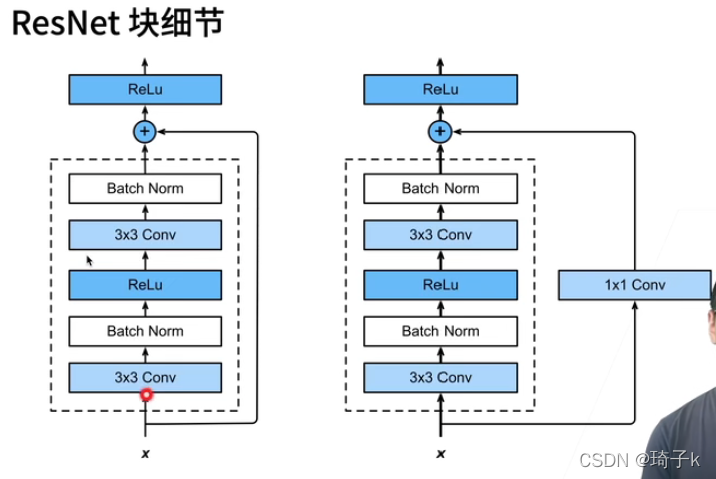
反思:為什么ResNet可以訓練到1000層?
從反向傳播理解
之前網路一個很大的問題——深度太深之后,梯度會消失,前面的網路訓練不好,
如何避免梯度消失?-> 乘法變加法
梯度消失: 新加的層如果擬合能力很強(例如AlexNet的全連接層),那么高層的梯度會很快變得非常小【導數可以理解為:真實值和預測值之間的差別(可以去看softmax求導)】,如果梯度很小的話,只能增大學習率,但是增的太大,高層的學習率也大了,會使得訓練很不穩定(這里假設的是全域統一的學習率),
但是resnet:每一層都會把上一層的導數傳過來,于是不會太小,貼近資料的W的梯度可以由上層直接經過高速公路傳下來,一開始下面的層也可以拿到比較大的梯度,才可以對很深的網路做訓練,

結合吳恩達老師的再理解下,如果我們在此基礎上再使用L2正則化(權重衰退),會進一步壓縮W的值,
如果W學到了0,那么a[l + 2]就會學習到a[l](因為是relu函式,a[l]肯定是大于0的),這就實作了恒等式的傳遞,

也就是說,當網路足夠深的時候,開始起反作用的時候,這個模塊可以保證你網路性能不變(盡管加了兩層),這里是假設很深的時候梯度消失了,此時這個網路可以退回到梯度消失之前,但是plain NN 是做不到這樣的,隨著深度的加深,會學的更爛,
吳恩達老師提出觀點,residual有用的原因就是:他學習恒等函式很容易,
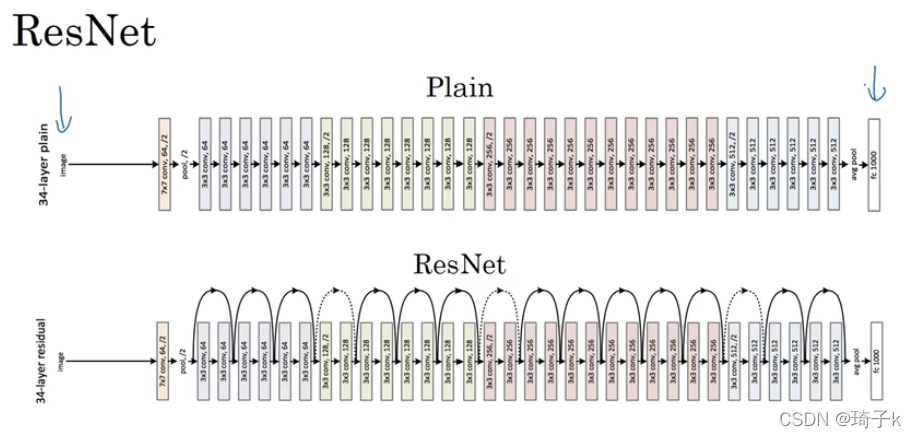
集成模型(核心理解)
殘差可以看成很多子網路的求和,
Ensemble當然效果好鴨,
研究人員發現,隨便蓋住ResNet中的某幾層,效果依然很好,但是如果對VGG這么干,就GG了,后面提出的DenseNet也是對ResNet的優化,他發現Ensemble的壞處在于,“投票“雖然好,但是有很多冗余資訊,這里就不在深究了,
ResNet18呆碼
注意resnet的“加法“是直接數值相加【見下面Y += X】,而不是像GoogLeNet那樣做通道堆積合并,
class Residual(nn.Module): # use_1x1conv:要不要使用1x1的卷積
def __init__(self, input_channels, num_channels, use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3, padding=1) # 這里輸入通道數=輸出通道數,這是左邊的第二個3x3
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels, kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(implace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X #!!!!!
return F.relu(Y)
使用兩種不同的resnet塊:
blk = Residual(3, 3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
torch.Size([4, 3, 6, 6])
增加輸出通道的同時,高寬減半,
blk = Residual(3, 6, use_1x1conv=True, strides=2)
Y = blk(X)
Y.shape
torch.Size([4, 6, 3, 3])
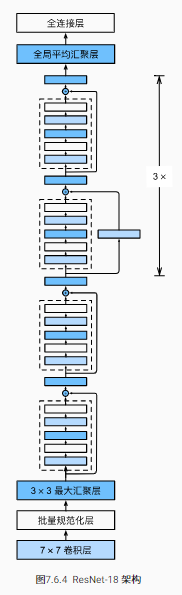
下面是RetNet18網路的實作:
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
ResNet則使用4個由殘差塊組成的模塊,每個模塊使用若干個同樣輸出通道數的殘差塊, 第一個模塊的通道數同輸入通道數一致, 由于之前已經使用了步幅為2的最大匯聚層,所以無須減小高和寬, 之后的每個模塊在第一個殘差塊里將上一個模塊的通道數翻倍,并將高和寬減半,
# 一個stage要多少個residual小塊,是不是第一個stage
def residual_block(input_channels, num_channels, num_residuals, first_block=False):
blk = []
for i in range(num_residuals): # 只在第一個stage(b2)才減半,其余的都不減半
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*residual_block(64, 64, 2, True))
b3 = nn.Sequential(*residual_block(64, 128, 2))
b4 = nn.Sequential(*residual_block(128, 256, 2))
b5 = nn.Sequential(*residual_block(256, 512, 2))
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1]) # 用池化變成1 * 1
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
ResNet18結構圖
Summary

一般要自己做任務的時候,建議使用resnet或InceptionV4.
當然最新的研究表明,swin transformer好像吊錘CNN?不過我不會,長大后在學習,

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433322.html
標籤:AI
上一篇:測驗-3-測驗分類