摘要:本文詳細介紹基于深度學習的中文車牌識別與管理系統,在介紹演算法原理的同時,給出Python的實作代碼以及PyQt的UI界面,在界面中既可以選擇需要識別的車牌視頻、圖片檔案、批量圖片進行檢測識別,也可以通過電腦自帶的攝像頭進行實時檢測、識別、管理車牌,通過車牌記錄查看歷史識別的車牌,博文提供了完整的Python代碼和使用教程,適合新入門的朋友參考,完整代碼資源檔案請轉至文末的下載鏈接,本博文目錄如下:
文章目錄
- 前言
- 1. 效果演示
- 2. 車牌檢測與識別
- 下載鏈接
- 結束語
?點擊跳轉至文末所有涉及的完整代碼檔案下載頁?
前言
車牌識別其實是個經典的機器視覺任務了,通過影像處理技術檢測、定位、識別車牌上的字符,實作計算機對車牌的智能管理功能,如今在小區停車場、高速公路出入口、監控場所、自動收費站等地都有車牌識別系統的存在,車牌識別的研究也已逐步成熟,盡管該技術隨處可見了,但其實在精度和識別速度上還需要進一步提升,自己動手實作一個車牌識別系統有利于學習和理解影像處理的先進技術,
車牌識別的演算法經過了多次版本迭代,檢測的效率和準確率有所提升,從最初的基于LBP和Haar特征的車牌檢測,到后來逐步采用深度學習的方式如SSD、YOLO等演算法,車牌的識別部分也由字符匹配到深度神經網路,通過不斷驗證和測驗,其檢測和識別效果和適用性都更加突出,支持的模型也更為豐富,
網上的車牌識別程式代碼很多,大部分都是采用深度學習的目標檢測演算法等識別單張圖片中的車牌,但幾乎沒有人將其開發成一個可以展示的完整軟體,即使有的也是比較簡單的界面,對此這里給出博主設計的界面,不算精美但比較簡約風,功能也可以滿足單張圖片、批量圖片、視頻和攝像頭的識別檢測了,初始界面如下圖:
檢測車牌時的界面截圖(點擊圖片可放大)如下圖,也可開啟攝像頭或視頻檢測:
詳細的功能演示效果參見博主的B站視頻或下一節的動圖演示,覺得不錯的朋友敬請點贊、關注加收藏!系統UI界面的設計作業量較大,界面美化更需仔細雕琢,大家有任何建議或意見和可在下方評論交流,
1. 效果演示
首先還是用動圖先展示一下效果,系統主要實作的功能是對圖片、視頻和攝像頭畫面中的車牌進行檢測和識別,識別的結果可視化顯示在界面和影像中,另外提供車牌識別歷史記錄和回看功能,演示效果如下,
(一)選擇單張 / 批量車牌識別
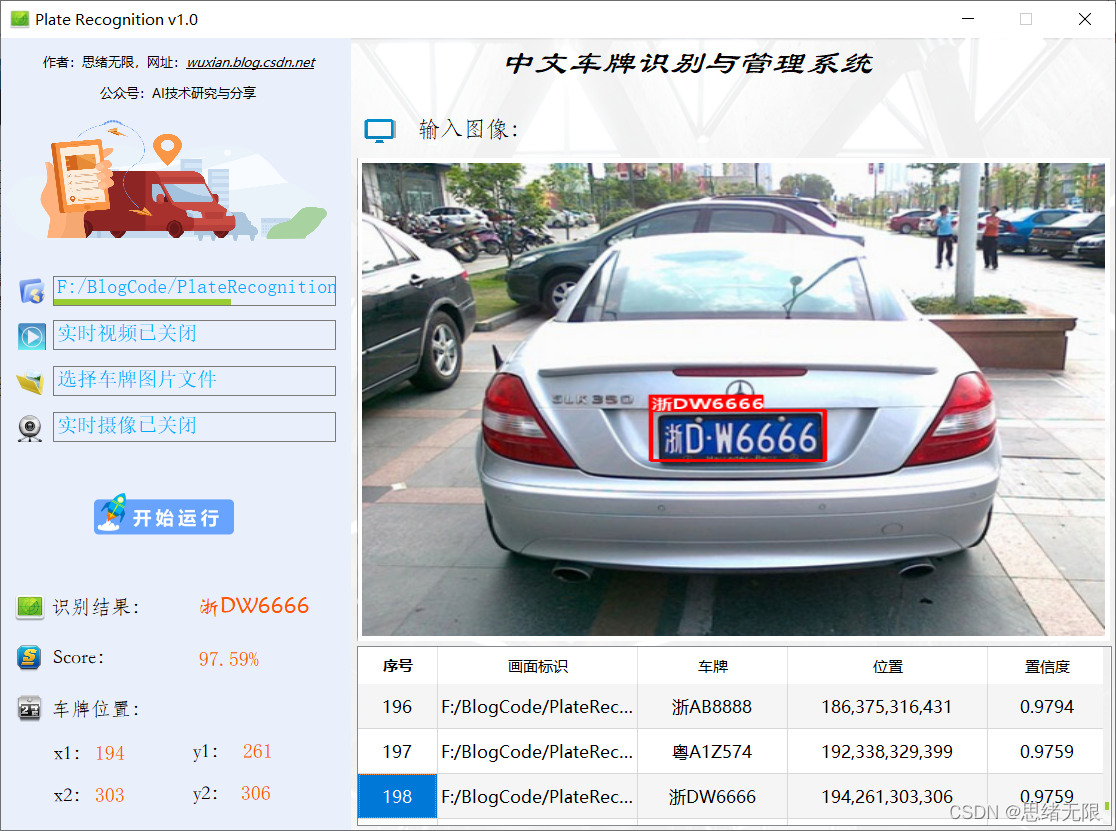
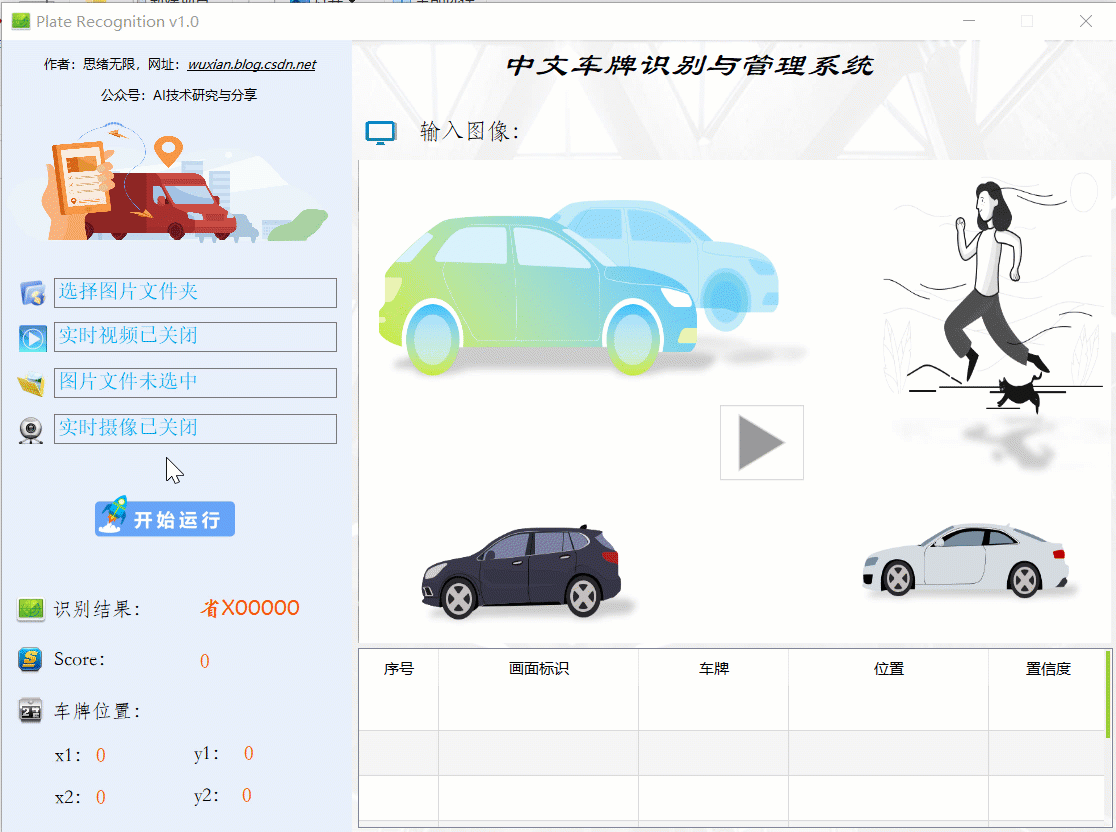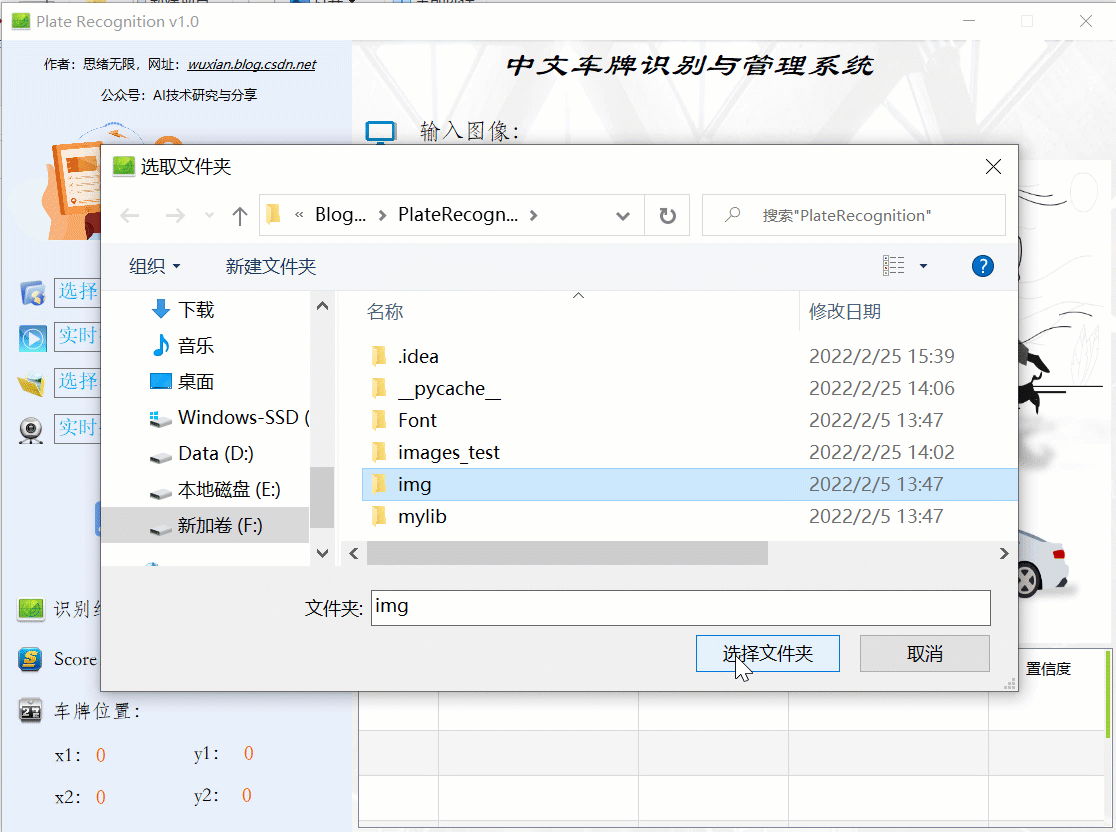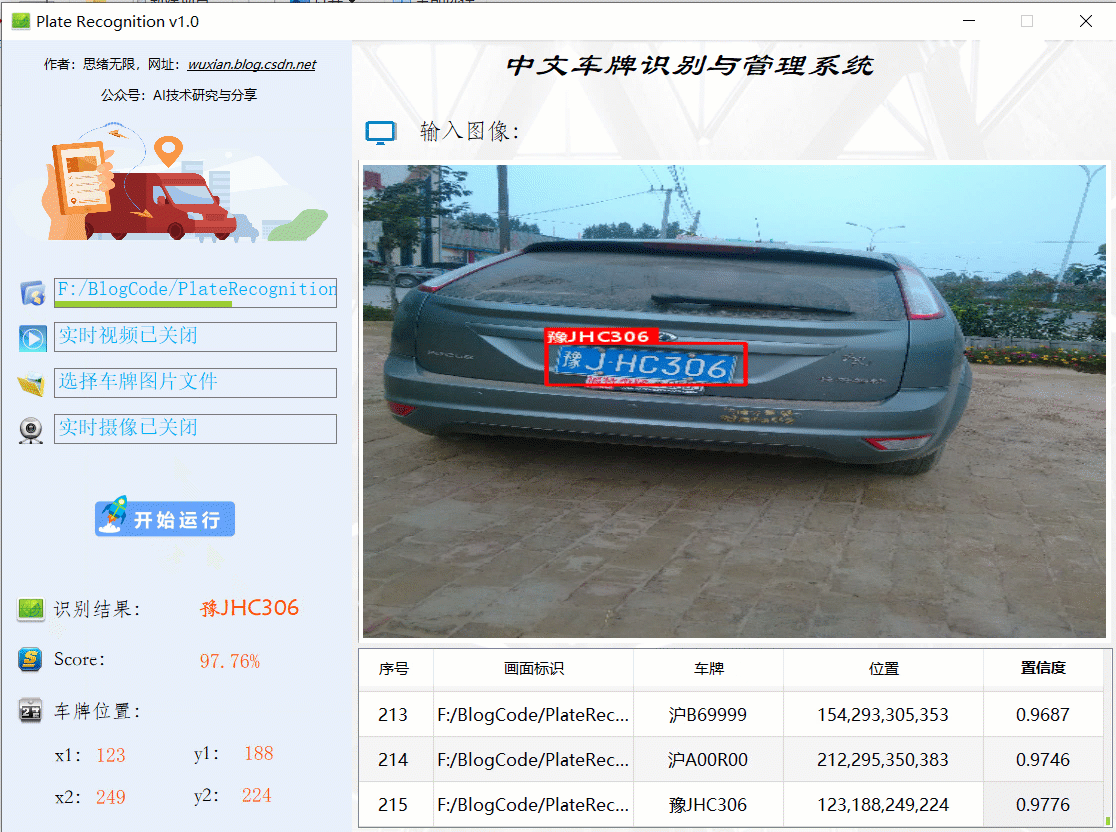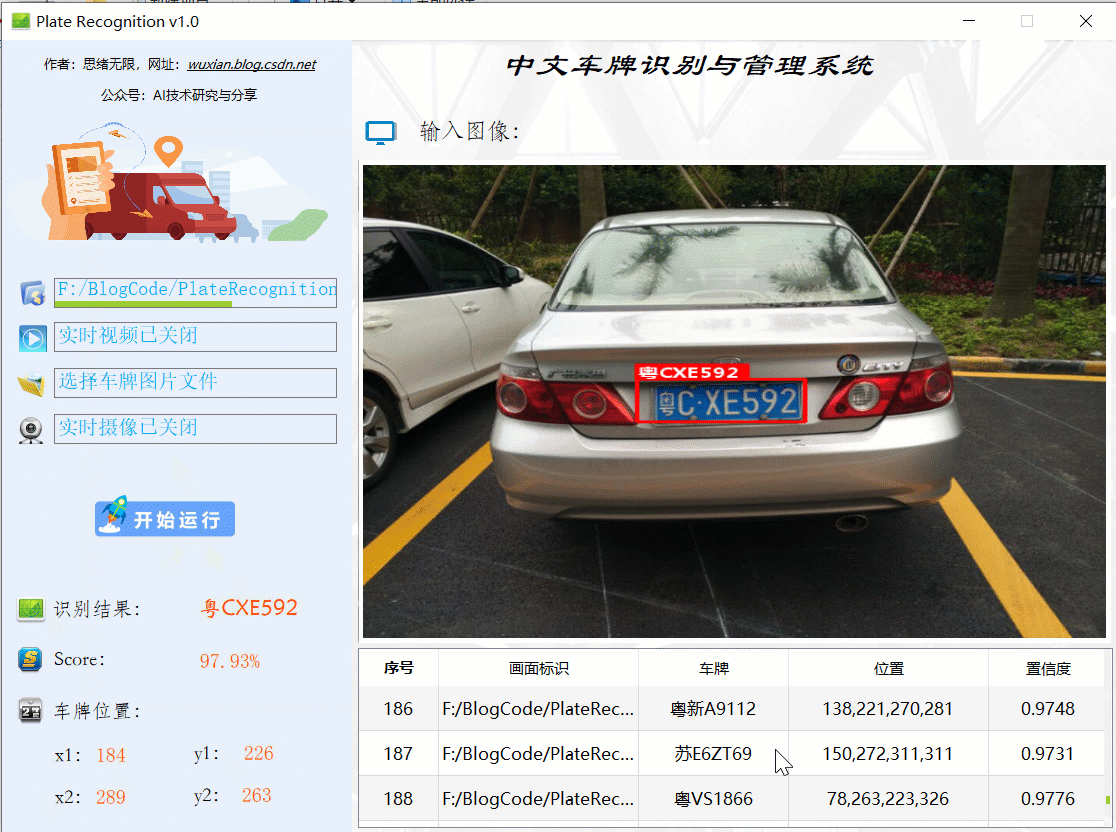
首先還是用動圖先展示一下效果,進入軟體界面后,點擊圖片選擇按鈕選擇一張圖片,點擊“開始運行”即可自動識別車牌并顯示結果在界面上;點擊歷史識別記錄的表格序號可回看識別記錄,本功能的界面展示如下圖所示:
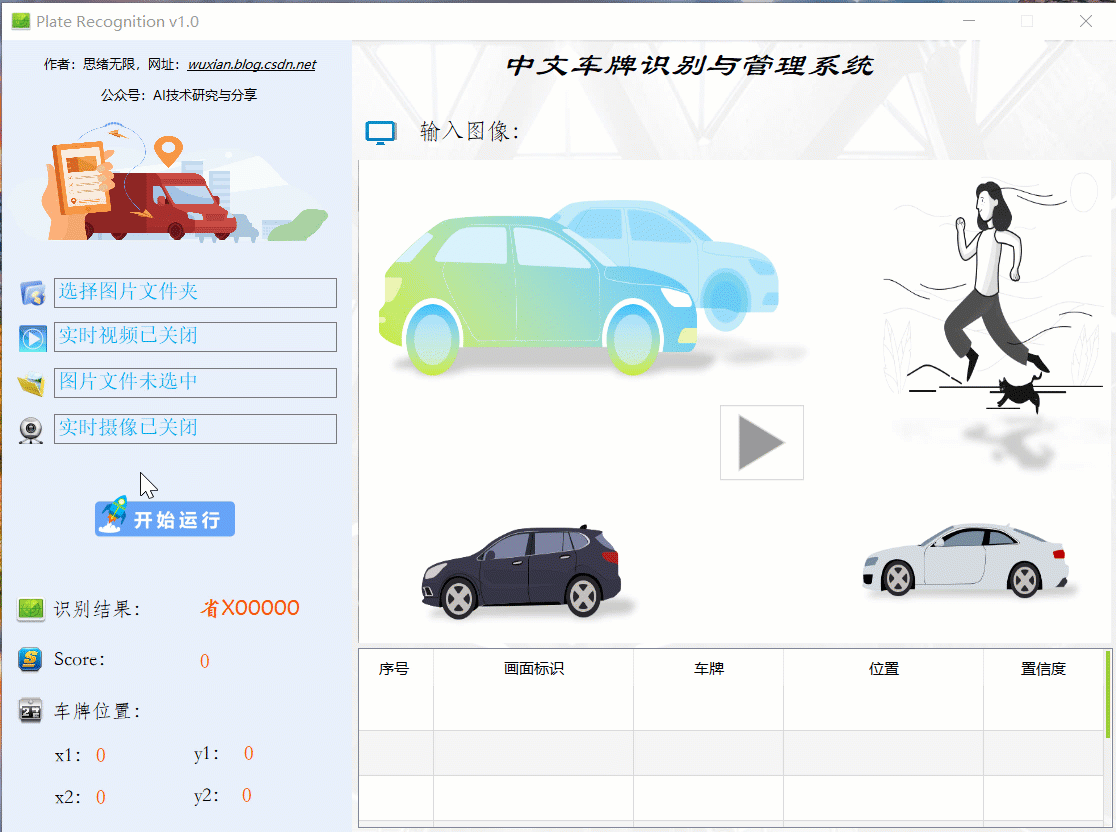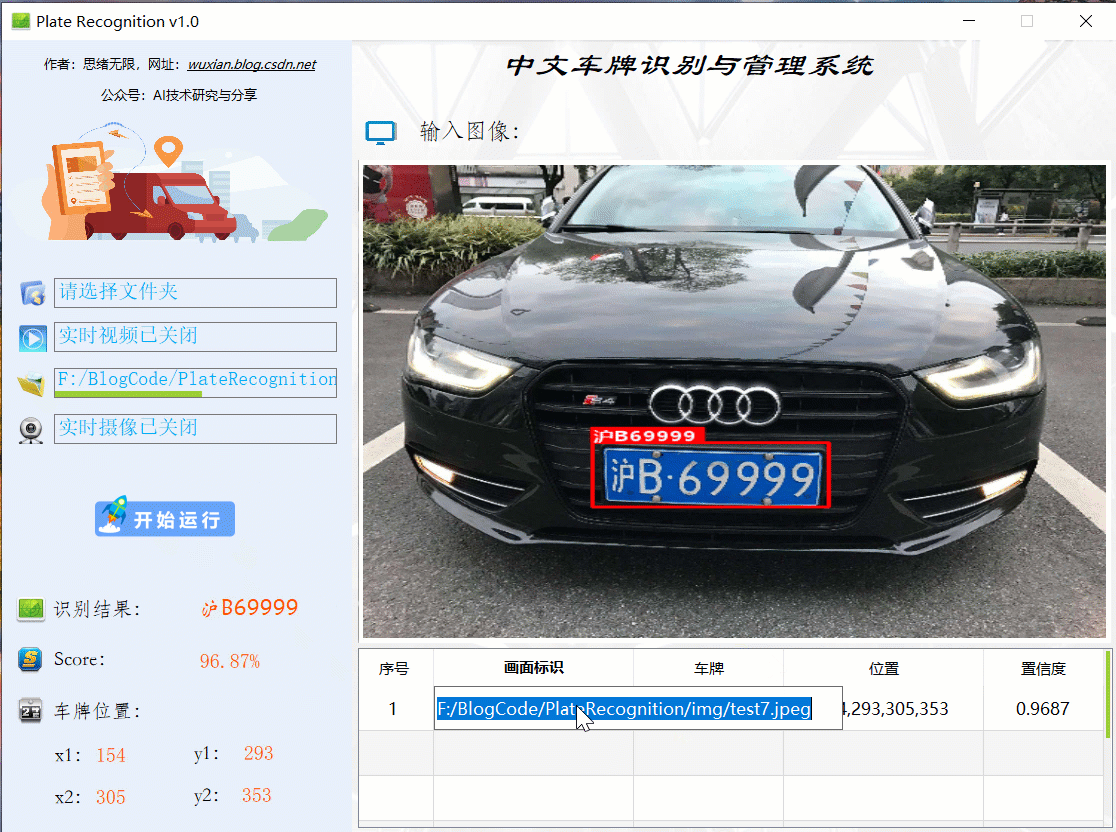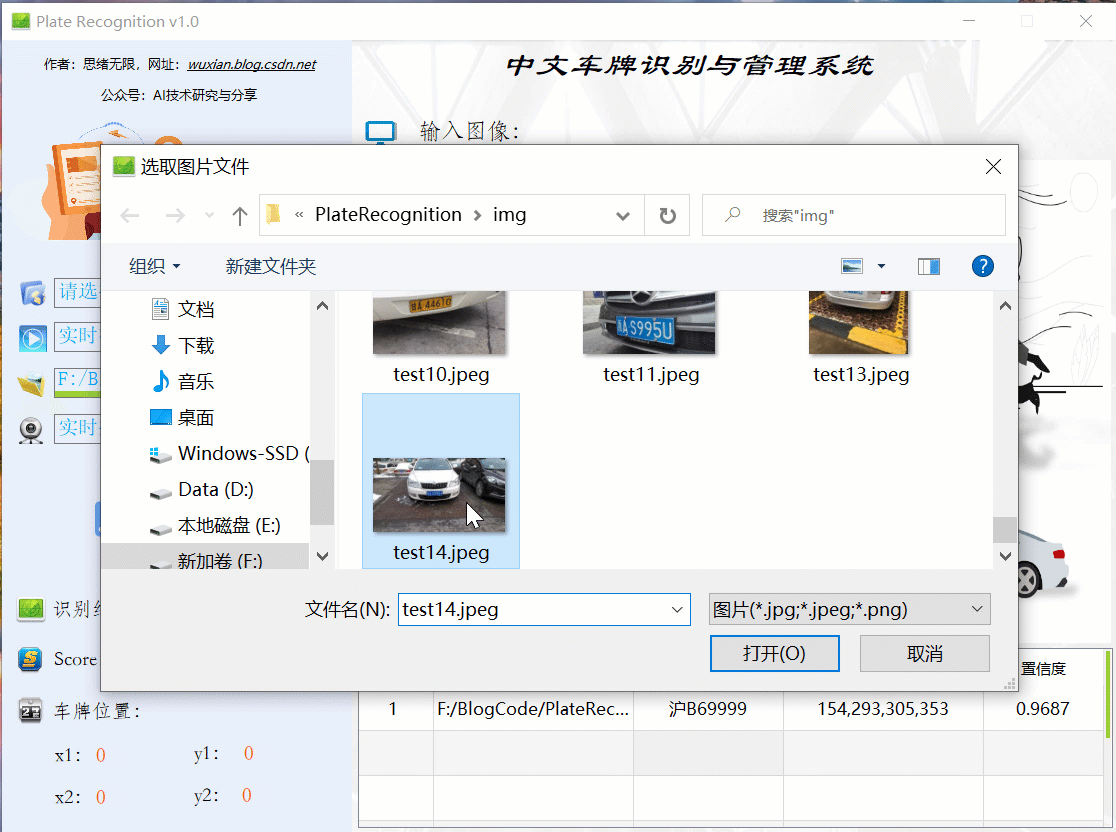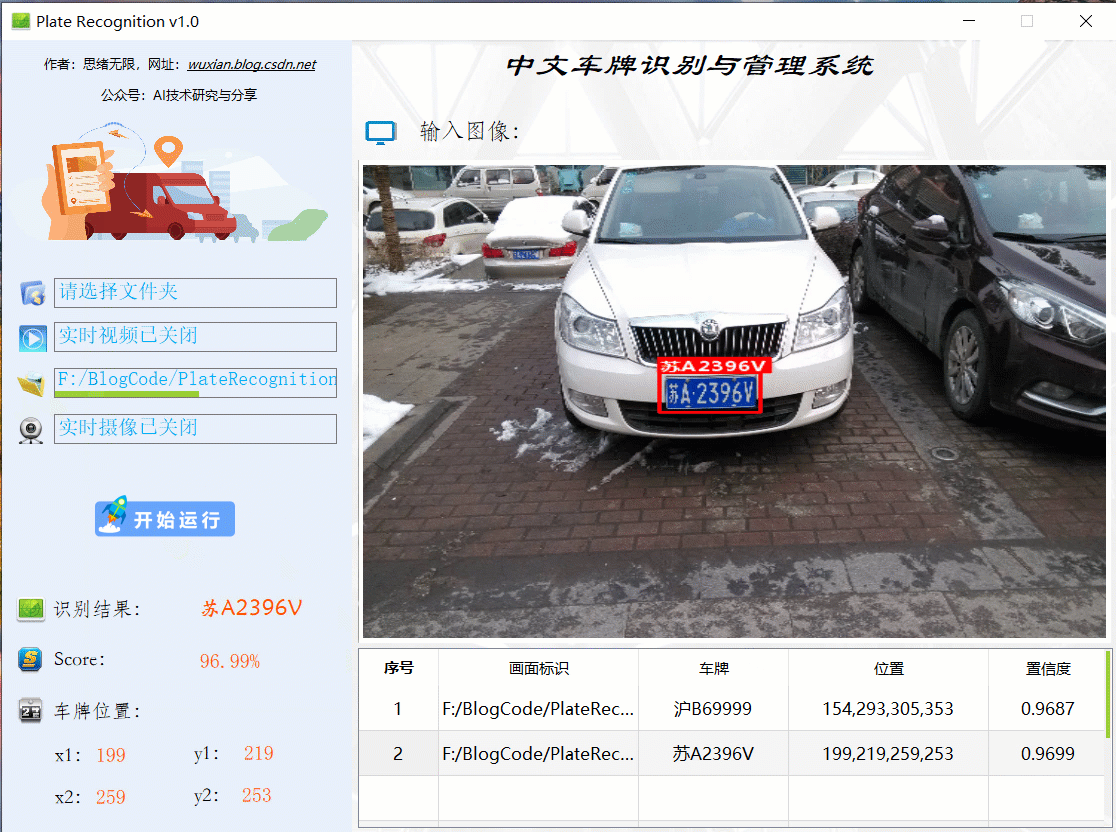
同樣的如果需要識別批量圖片,可以選擇一個包含多張圖片檔案的檔案夾,選擇好后點擊“開始運行”則逐個對每個檔案進行檢測和識別,結果與單張圖片時類似,可通過表格記錄回看識別結果:
(二)車牌視頻識別效果展示
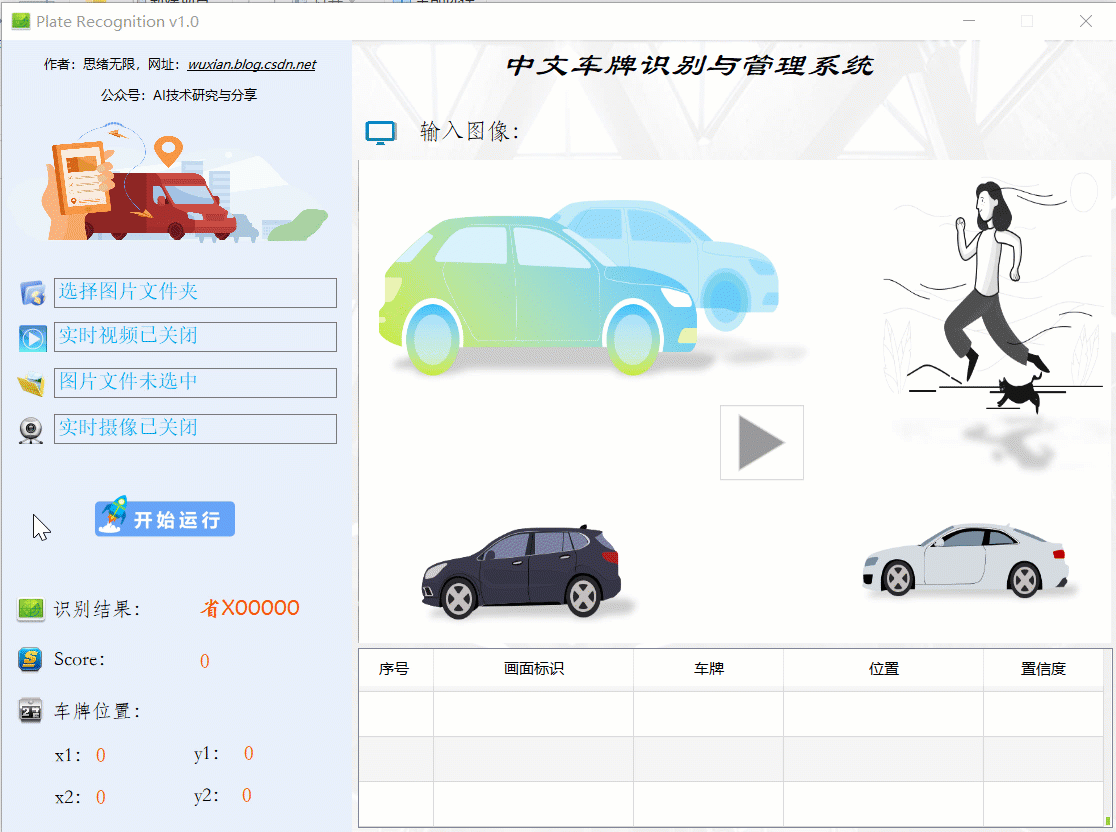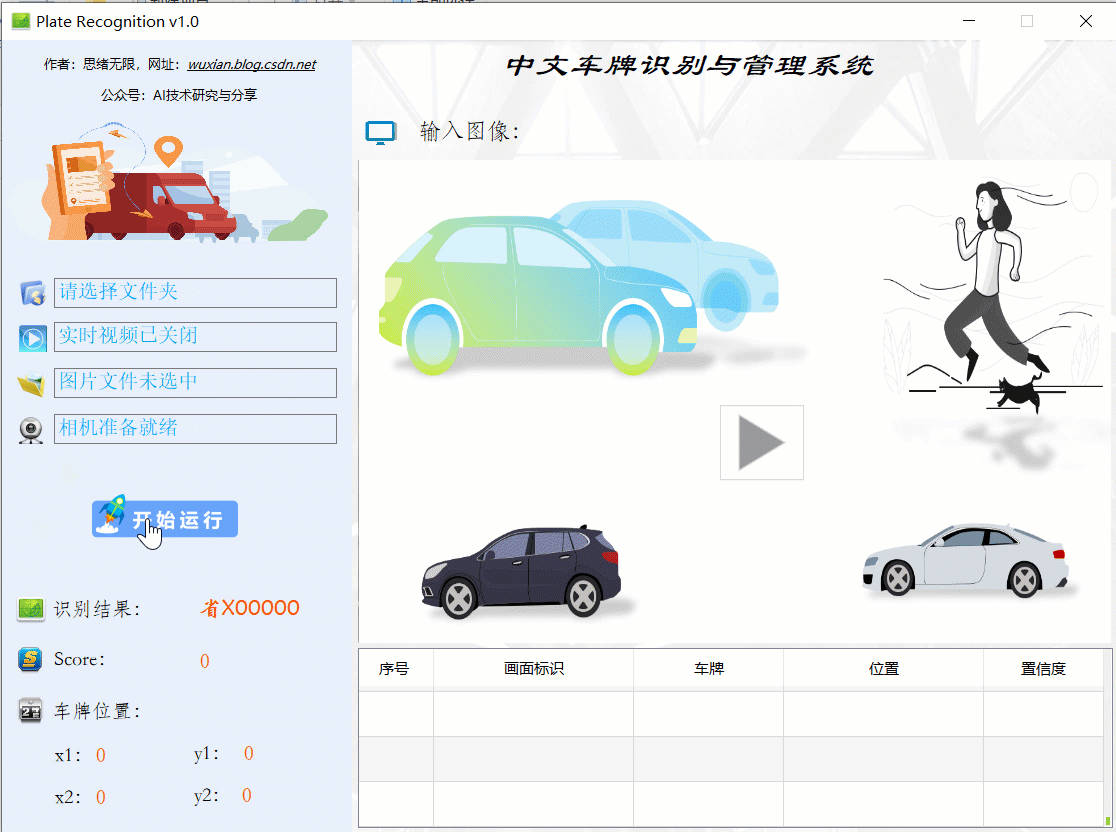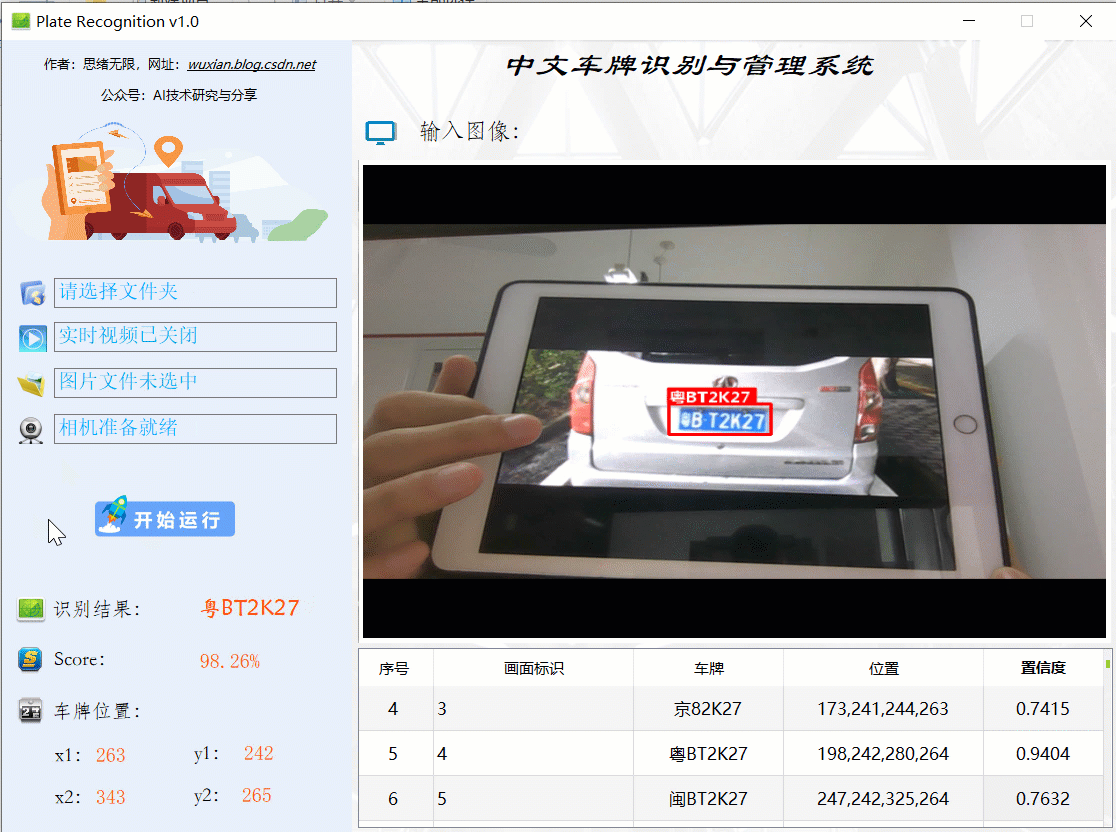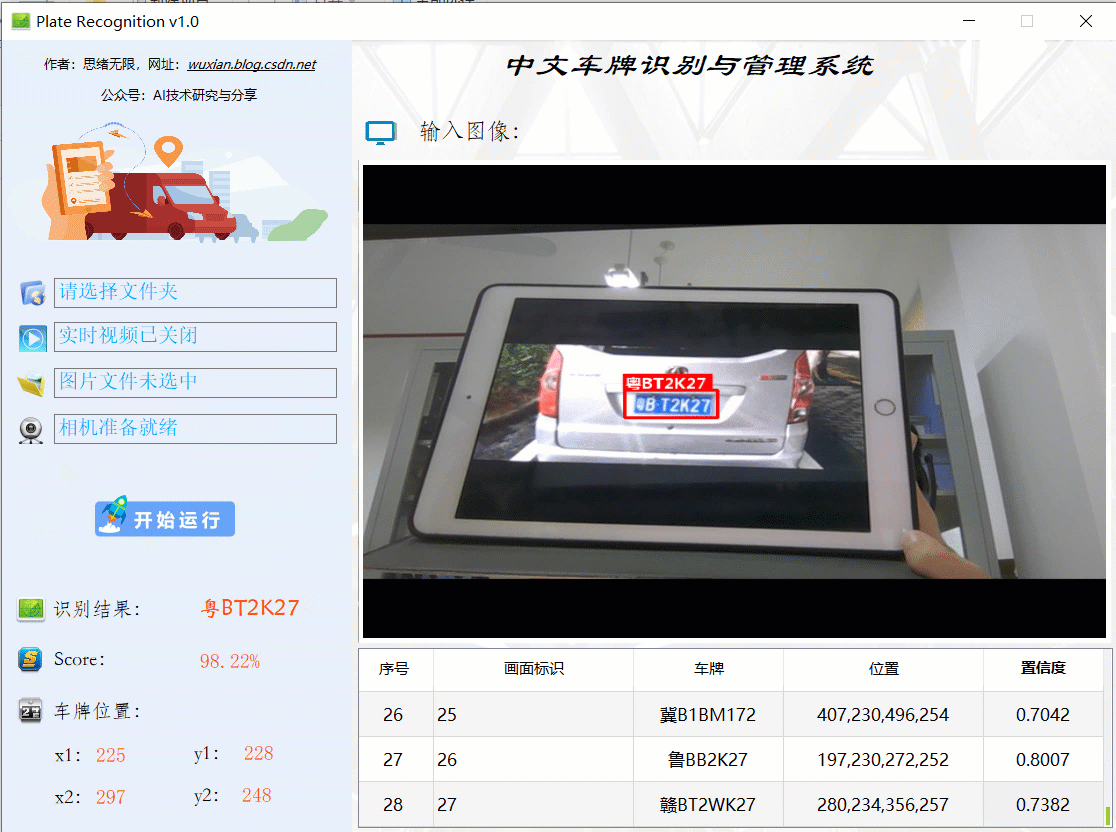
很多時候我們需要識別一段視頻中的車牌,這里設計了視頻選擇功能,點擊視頻按鈕可選擇待檢測的視頻,系統會自動決議視頻逐幀識別車牌,并將結果記錄在右下角表格中,效果如下圖所示:
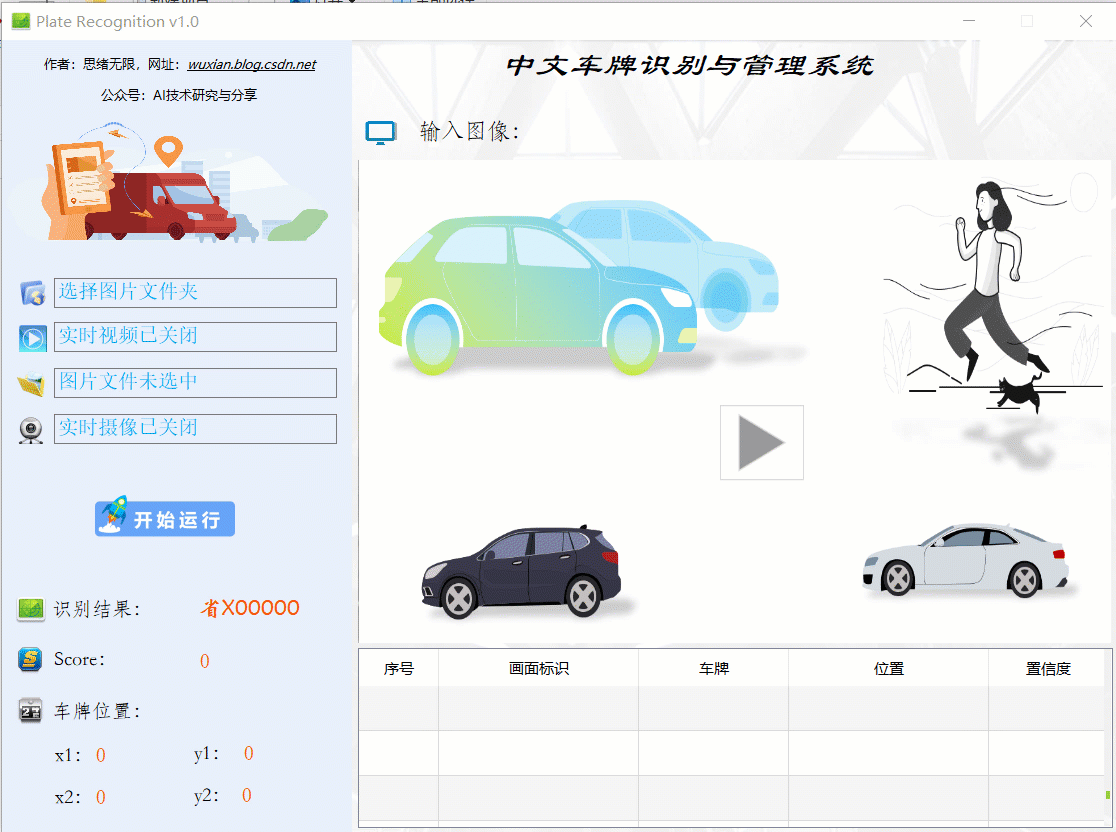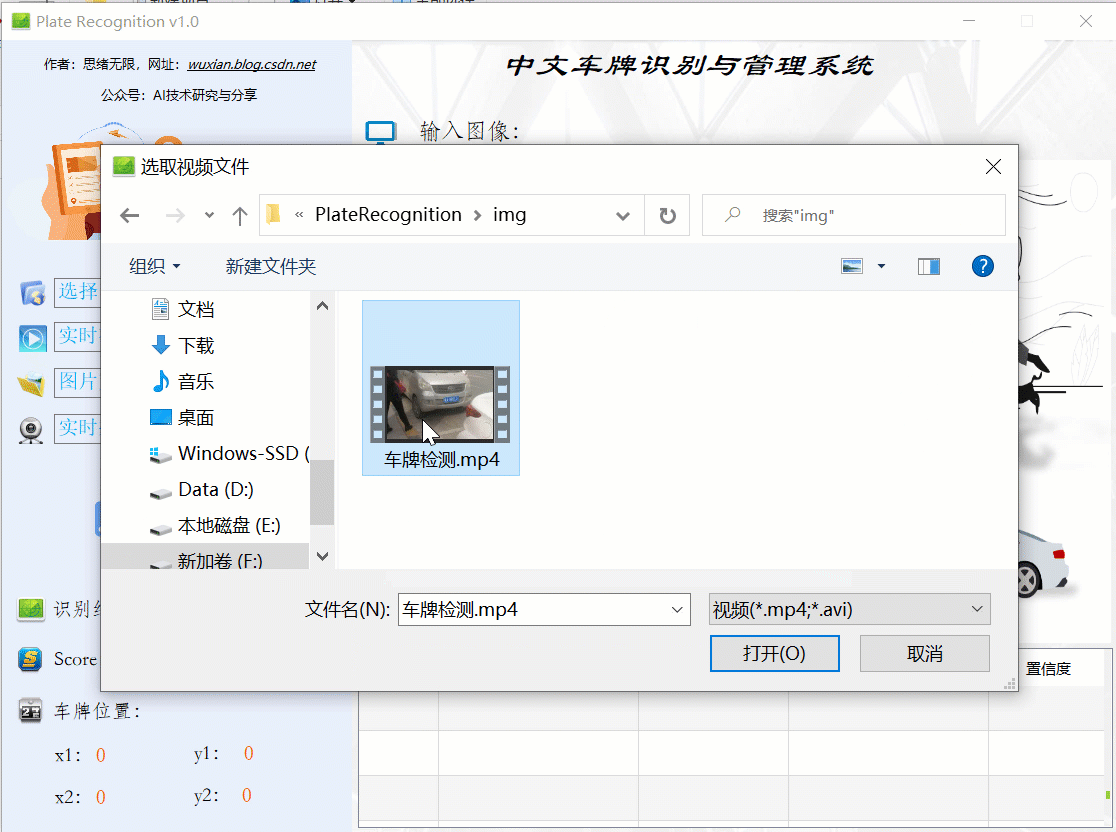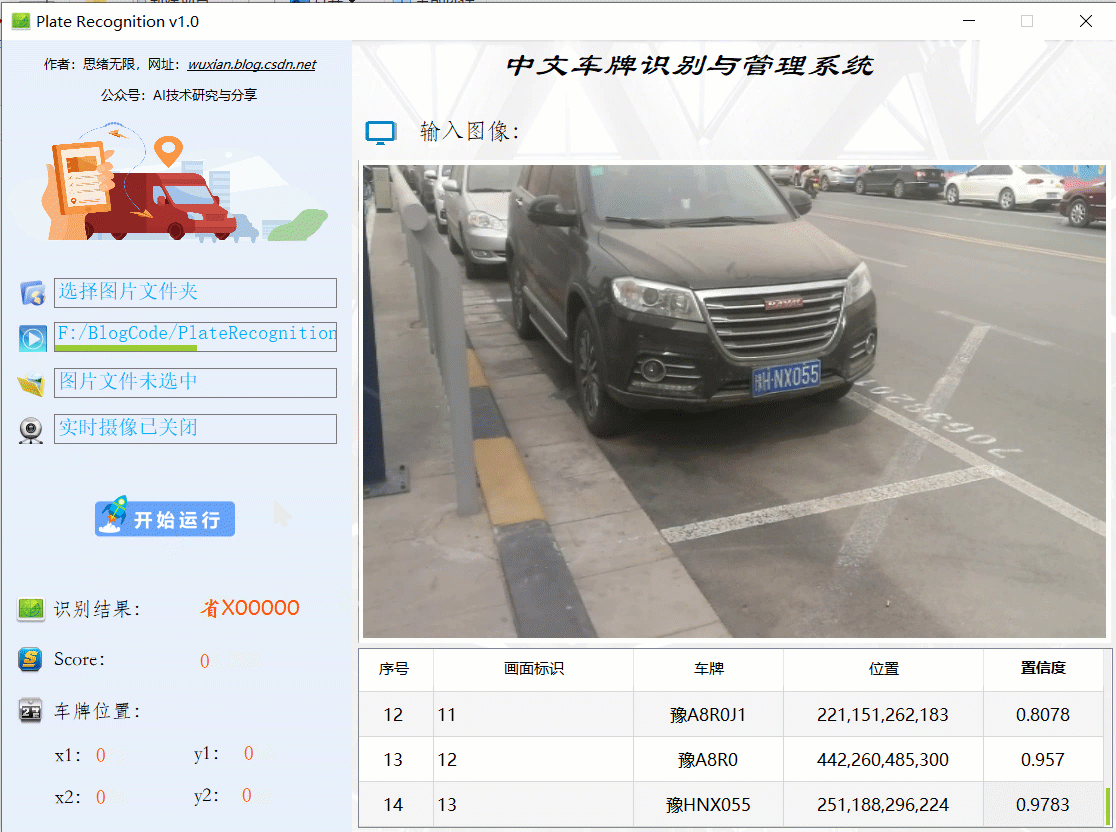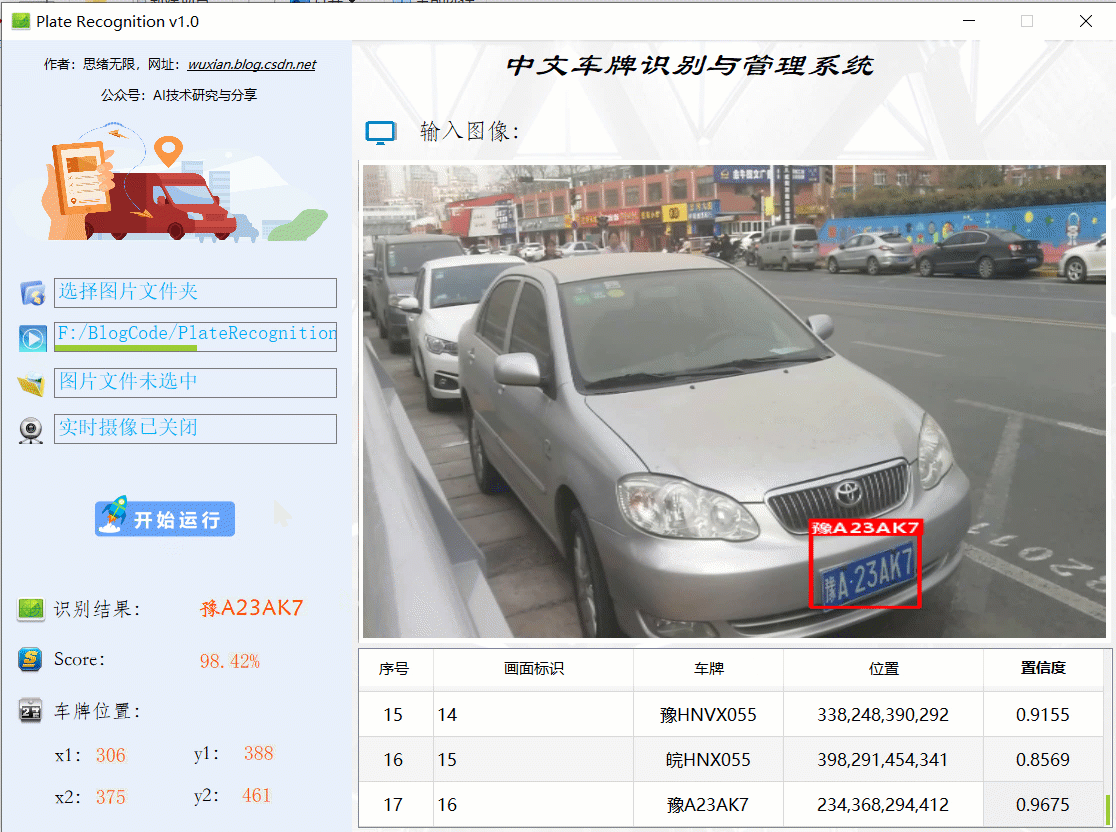
(三)攝像頭檢測效果展示
在真實場景中,我們往往利用設備攝像頭獲取實時畫面,同時需要對畫面中的車牌進行識別,因此本文考慮此功能,如下圖所示,點擊攝像頭按鈕后系統進入準備狀態,再點擊“開始運行”后,系統顯示實時畫面并開始檢測畫面中的車牌,識別結果展示并記錄:
2. 車牌檢測與識別
目前,智能交通系統中集成運用計算機視覺、物聯網、人工智能等多種技術成為未來發展方向,其中,車牌識別(License Plate Recognition, LPR)技術作為一項重要技術,從獲取的影像中提取目標車輛的車牌資訊,成為完善智能交通管理運行的基礎,
由于本文介紹的是中文車牌,所以可以簡單了解一下國內汽車拍照的特點:字符數為七個,包括漢字、字母和數字,車牌顏色組合中,其中最常見的組合為普通小型汽車藍底白字和新能源汽車的漸變綠底黑字1,
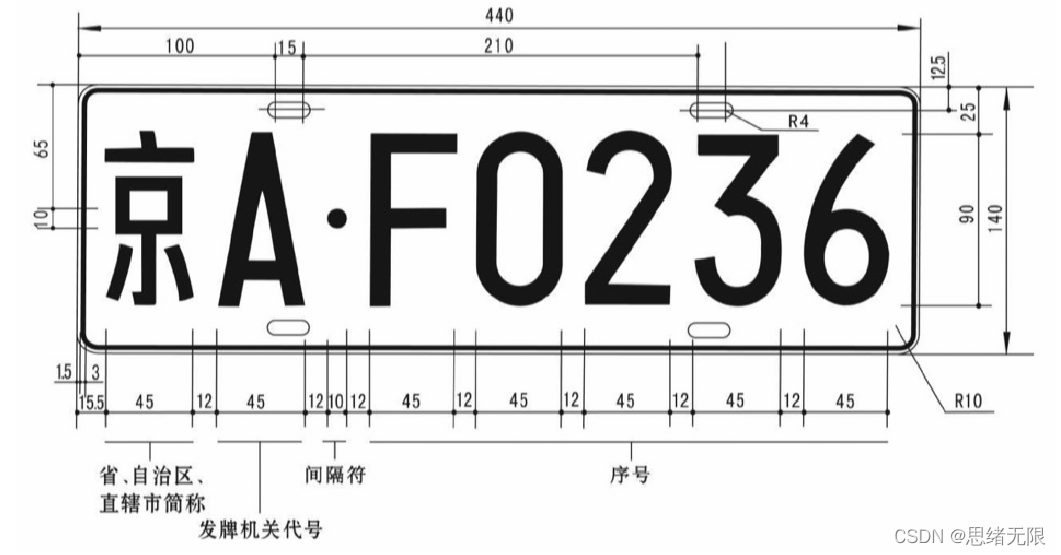
由于本文介紹的是中文車牌,所以可以簡單了解一下國內汽車拍照的特點:字符數為七個,包括漢字、字母和數字,車牌輪廓長寬比例基本固定,車牌顏色組合中,其中最常見的組合為普通小型汽車藍底白字和新能源汽車的漸變綠底黑字,總結來說,車牌是一個有特點的影像區域,幾種特征可以綜合起來確定車牌定位,所以之前就有利用車牌與周圍環境的差異的演算法,目前常見的車牌定位演算法有以下 4 種:基于顏色、紋理、邊緣資訊的車牌定位演算法和基于人工神經網路的車牌定位演算法2,
為了方便演示,博主繪制了一張車牌識別的流程圖,如下圖所示,常規的步驟包括影像采集、預處理、車牌定位、字符分割、字符識別、輸出結果,深度學習技術成熟之后,端到端的網路模型使得這一程序變得簡單起來,從思想上來說,基于深度學習的車牌識別實作思路主要包括兩個部分:(1)車牌檢測定位;(2)車牌字符識別,
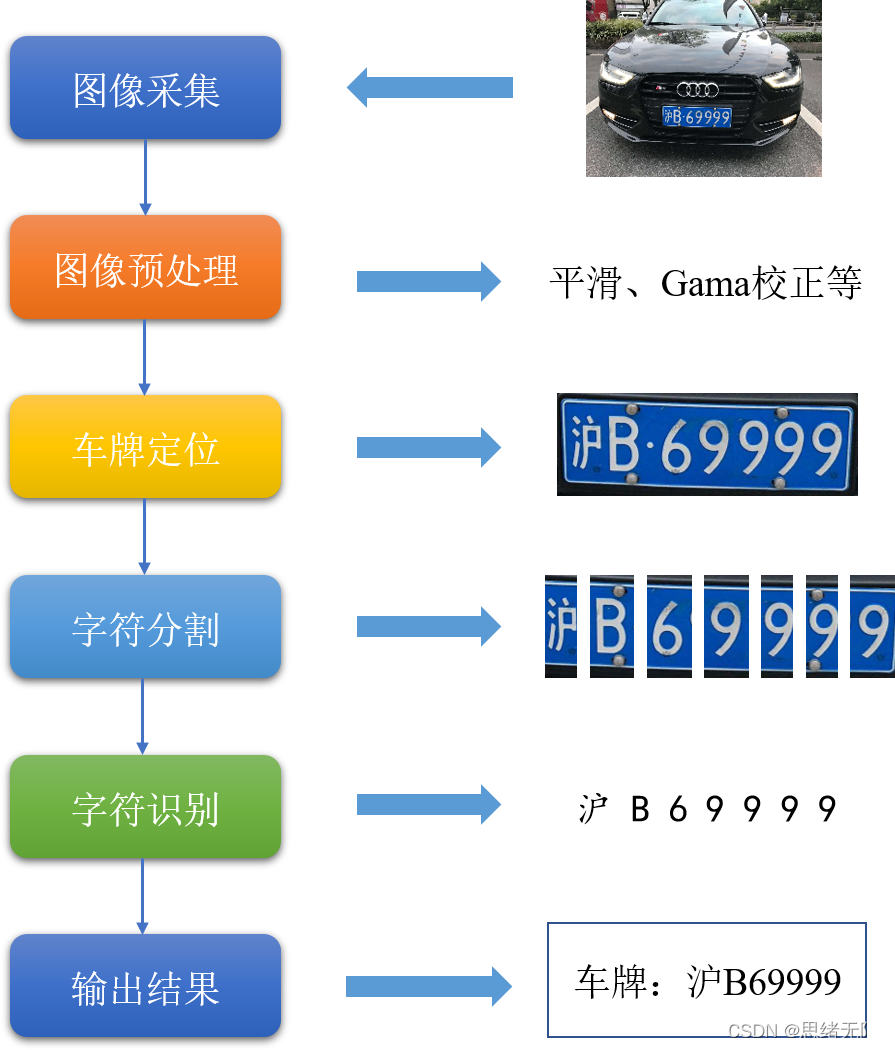
其中,車牌的檢測定位本質是一個特定的目標檢測(Object Detection)任務,即通過演算法框選出屬于車牌的位置坐標,以便將其與背景區分開來,可以認為檢測出的車牌位置才是我們的感興趣區域(Region Of Interest, ROI),好用的方法如Cascade LBP,它是一種機器學習的方法,可以利用OPenCV訓練級聯分類器,依賴CPU進行計算,參考網址:https://gitee.com/zeusees/HyperLPR,級聯分類器的方法對于常用場景效果比較好,檢測速度較快,曾經一度比較流行,但準確率一般,基于深度學習的檢測演算法有Mobilene-SSD、YOLO-v5等,利用大批量的標注資料進行訓練,訓練代碼可以參考開源代碼https://github.com/zeusees/License-Plate-Detector,
當ROI被檢測出來,如何對這一區域中的字符進行識別,這就涉及到采取的處理方式,第一種處理方式,首先利用一系列字符分割的演算法將車牌中的字符逐個分開,然后基于深度學習進行字符分類,得到識別結果,可參考的代碼地址:https://github.com/LCorleone/A-Simple-Chinese-License-Plate-Generator-and-Recognition-Framework;第二種,區別于第一種先分割再分類的兩步走方式,利用端到端的CTC( Connectionist Temporal Classification)網路直接進行識別,代碼地址:https://github.com/armaab/hyperlpr-train,
這里我們使用網上開源的HyperLPR中文車牌識別框架,首先匯入OpenCV和hyperlpr,讀取一張車牌圖片呼叫架構中的車牌識別方法獲得結果,以下代碼來自官方的示例:
#匯入包
from hyperlpr import *
#匯入OpenCV庫
import cv2
#讀入圖片
image = cv2.imread("demo.jpg")
#識別結果
print(HyperLPR_plate_recognition(image))
以上代碼運行結果如下,可以看出該方法識別了車牌的車牌字符、置信度值、車牌位置坐標、圖片尺寸等結果,

這樣的結果還不夠直觀,我們寫一個函式將車牌的識別結果標注在圖片上,首先匯入相關依賴包,其代碼如下:
# 匯入包
from hyperlpr import *
# 匯入OpenCV庫
import cv2 as cv
from PIL import Image, ImageDraw, ImageFont
import numpy as np
新建一個函式drawRectBox,將影像資料、識別結果、字體等引數傳入,函式內部利用OpenCV和PIL庫添加標注框和識別結果的字符,其代碼如下:
def drawRectBox(image, rect, addText, fontC):
cv.rectangle(image, (int(round(rect[0])), int(round(rect[1]))),
(int(round(rect[2]) + 8), int(round(rect[3]) + 8)),
(0, 0, 255), 2)
cv.rectangle(image, (int(rect[0] - 1), int(rect[1]) - 16), (int(rect[0] + 75), int(rect[1])), (0, 0, 255), -1, cv.LINE_AA)
img = Image.fromarray(image)
draw = ImageDraw.Draw(img)
draw.text((int(rect[0] + 1), int(rect[1] - 16)), addText, (255, 255, 255), font=fontC)
imagex = np.array(img)
return imagex
我們首先讀取圖片檔案,利用前面的HyperLPR_plate_recognition方法識別出車牌結果,呼叫以上函式獲得帶標注框的圖片,利用OpenCV的imshow方法顯示結果圖片,其代碼如下:
image = cv.imread('test3.jpeg') # 讀取選擇的圖片
res_all = HyperLPR_plate_recognition(image)
fontC = ImageFont.truetype("./platech.ttf", 14, 0)
res, confi, axes = res_all[0]
image = drawRectBox(image, axes, res, fontC)
cv.imshow('Stream', image)
c = cv.waitKey(0) & 0xff
此時運行以上代碼可以得到如下結果:

同理,識別視頻中的車牌也可以做類似的操作,不過我們需要先對視頻檔案進行逐幀讀取,然后采用以上的方式在圖片中標識出車牌并顯示,這部分代碼如下:
capture = cv.VideoCapture("./車牌檢測.mp4") # 讀取視頻檔案
fontC = ImageFont.truetype("./platech.ttf", 14, 0) # 字體,用于標注圖片
i = 1
while (True):
ref, frame = capture.read()
if ref:
i = i + 1
if i % 5 == 0:
i = 0
res_all = HyperLPR_plate_recognition(frame) # 識別車牌
if len(res_all) > 0:
res, confi, axes = res_all[0] # 獲取結果
frame = drawRectBox(frame, axes, res, fontC)
cv.imshow("num", frame) # 顯示畫面
if cv.waitKey(1) & 0xFF == ord('q'):
break # 退出
else:
break
以上代碼每5幀識別一次視頻中的車牌,將車牌的結果標注在畫面中進行實時顯示,運行結果的截圖如下所示:

車牌的識別部分代碼演示完畢,對此我們完成了圖片和視頻的識別,然而這些還是簡單的腳本呈現,為了方便更換圖片、視頻以及管理車牌,還需要設計檔案選擇功能以及系統的UI界面,打開QtDesigner軟體,拖動以下控制元件至主視窗中,車牌識別系統的界面設計如下圖所示:
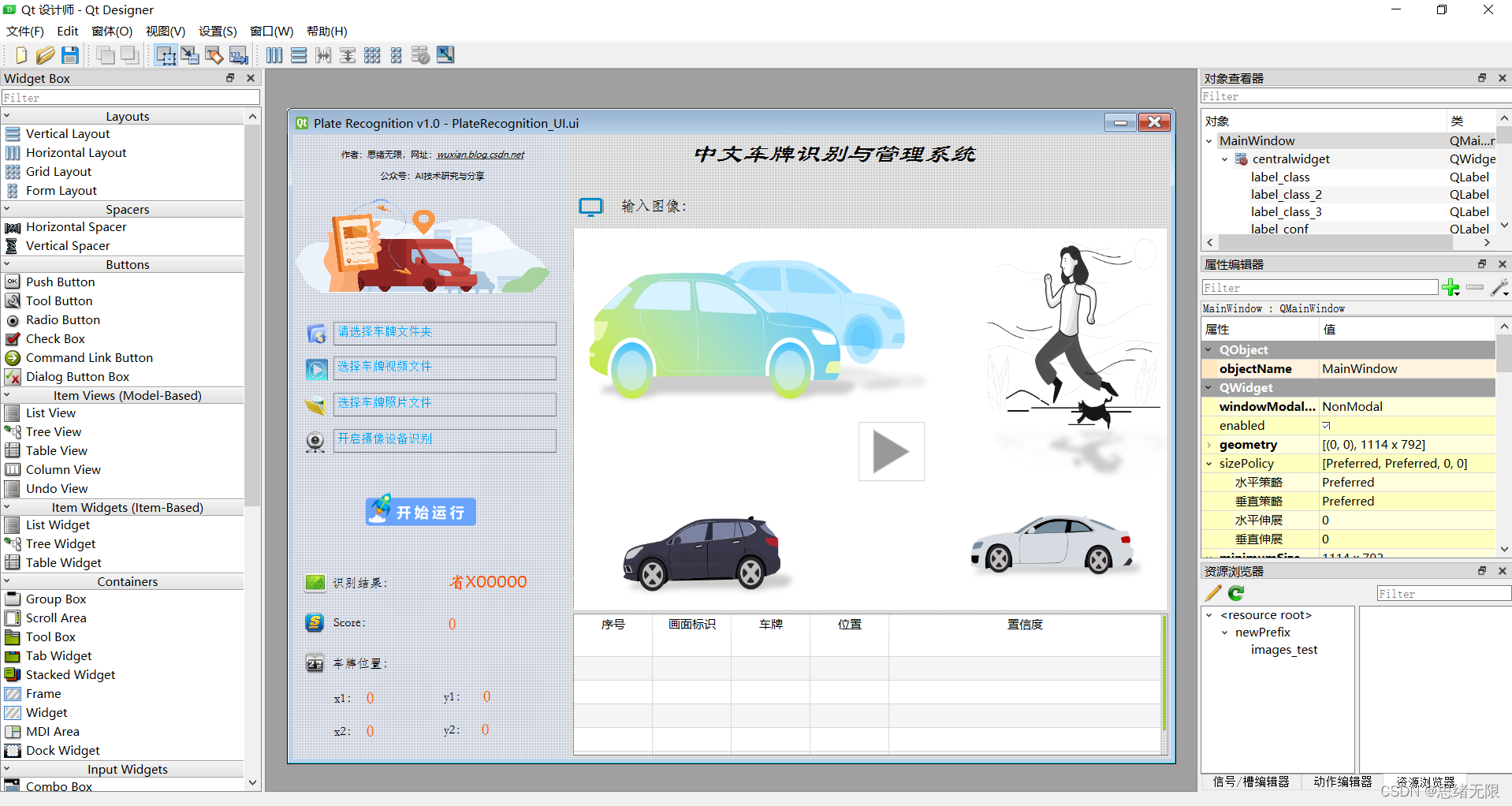
控制元件界面部分設計好,接下來利用PyUIC工具將.ui檔案轉化為.py代碼檔案,通過呼叫界面部分的代碼同時加入對應的邏輯處理代碼,博主對其中的UI功能進行了詳細測驗,最終開發出一版流暢得到清新界面,就是博文演示部分的展示,完整的UI界面、測驗圖片視頻、代碼檔案,以及Python離線依賴包(方便安裝運行,也可自行配置環境),均已打包上傳,感興趣的朋友可以通過下載鏈接獲取,
下載鏈接
若您想獲得博文中涉及的實作完整全部程式檔案(包括測驗圖片、視頻,py, UI檔案等,如下圖),這里已打包上傳至博主的面包多平臺和CSDN下載資源,本資源已上傳至面包多網站和CSDN下載資源頻道,可以點擊以下鏈接獲取,已將所有涉及的檔案同時打包到里面,點擊即可運行,完整檔案截圖如下:
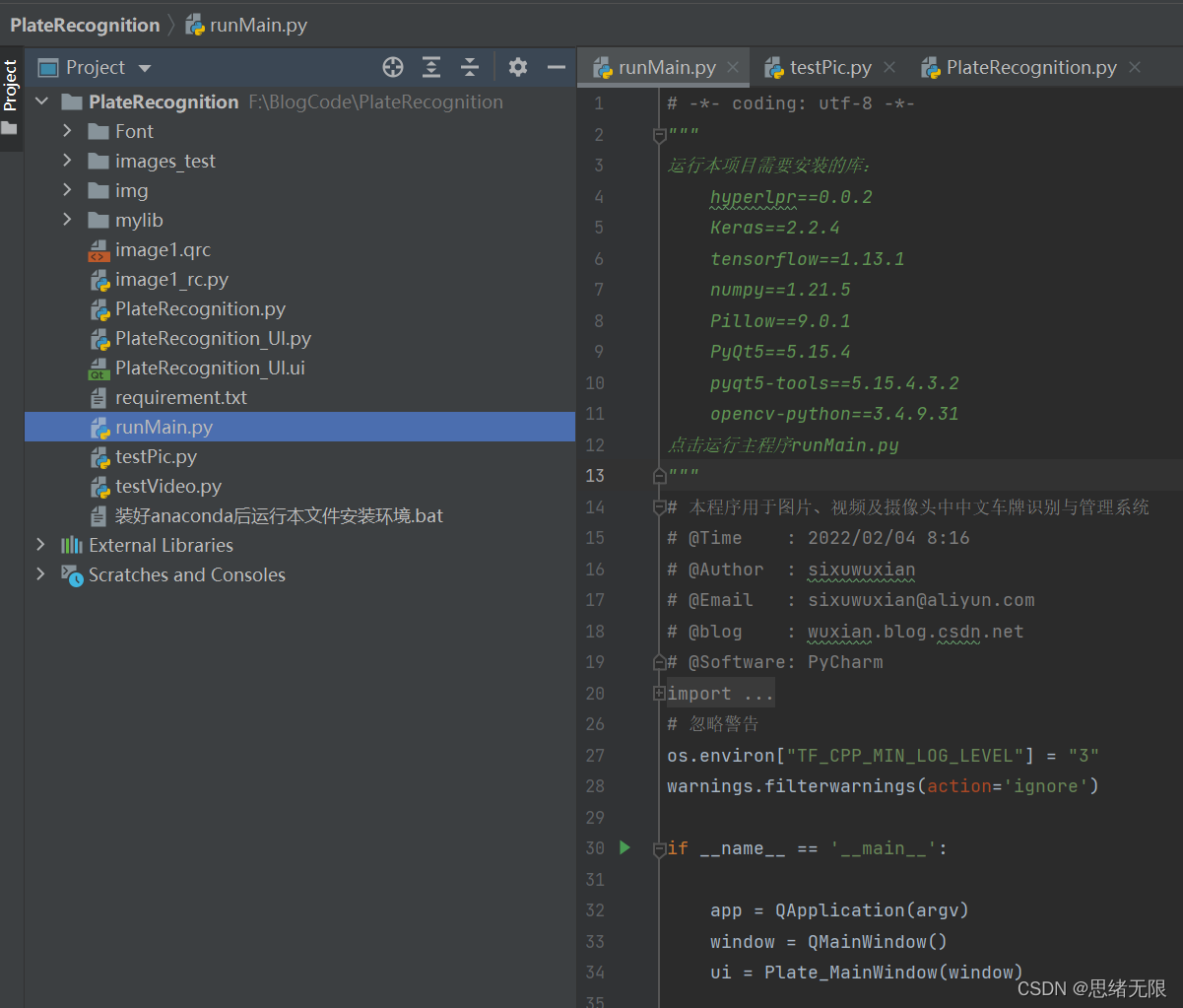
在檔案夾下的資源顯示如下,其中包含了Python的離線依賴包,讀者可在正確安裝Anaconda和Pycharm軟體后,點擊bat檔案進行安裝,詳細演示也可見本人B站視頻,
注意:本資源已經過除錯通過,下載后可通過Pycharm運行;運行界面的主程式為runMain.py,測驗識別圖片腳本可運行testPic.py,視頻測驗腳本可運行testVideo.py檔案,為確保程式順利運行,請配置Python依賴包的版本如下:???
(Python版本:3.7)
hyperlpr 0.0.2
Keras 2.2.4
tensorflow 1.13.1
numpy 1.21.5
Pillow 9.0.1
PyQt5 5.15.4
pyqt5-tools 5.15.4.3.2
opencv-python 3.4.9.31
完整資源下載鏈接1:博主在面包多網站上的完整資源下載頁
完整資源下載鏈接2:https://mianbaoduo.com/o/bread/mbd-YpiUlphp
注:以上兩個鏈接為面包多平臺下載鏈接,CSDN下載資源頻道下載鏈接稍后上傳,
結束語
由于博主能力有限,博文中提及的方法即使經過試驗,也難免會有疏漏之處,希望您能熱心指出其中的錯誤,以便下次修改時能以一個更完美更嚴謹的樣子,呈現在大家面前,同時如果有更好的實作方法也請您不吝賜教,
中華人民共和國公安部.GA36-2014. 中華人民共和國公共安全行業標準–中華人民共和國機動車號牌[S]. 北京:群眾出版社, 2014, 2-4 ??
Du S, Ibrahim M, Shehata M, et al. Automatic license plate recognition (ALPR): A state-of-the-art review[J]. IEEE Transactions on circuits and systems for video technology, 2012, 23(2): 311-325. ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433325.html
標籤:AI