
賽題背景
近年來,隨著陸上風電機組裝機廠址的擴展,在天氣突變較多的地區安裝的風力發電機組受到氣象變化的影響愈發顯著,在風況突變時,由于控制系統的滯后性,容易導致機組出現載荷過大,甚至是倒機的情況,造成重大經濟損失,同時,現有超短期風功率預測的準確性較差,導致風功率預測系統對電網調度的參考價值不大,并且會導致業主產生大量的發電量計劃考核,由于常見的激光雷達等風速測量產品單價高昂、受天氣影響較大,難以實作批量化的應用部署,且在大時間空間尺度下仍難以具有可靠的前瞻性,因此,可靠的超短期風況預測迫在眉睫,
超短期風況預測是一個世界性難題,如果能通過大資料、人工智能技術預測出每臺機組在未來短時間內的風速和風向資料,可以提升風電機組的控制前瞻性、提高風電機組的載荷安全性;同時,現有超短期風功率預測能力的提升,將帶來顯著的安全價值和經濟效益,
本次比賽由深圳保安區人民政府與中國資訊通信研究院聯合主辦,提供了來自工業生產中的真實資料與場景,希望結合工業與AI大資料,解決實際生產任務中面臨的挑戰,
資料分析
訓練集說明
兩個風場各兩年的訓練資料:
1. 每個風場25臺風電機組,提供各臺機組的機艙風速、風向、溫度、功率和對應的小時級氣象資料;
2. 風場1的風機編號為:x26-x50,訓練集資料范圍為2018、2019年;
3. 風場2的風機編號為:x25-x49,訓練集資料范圍為2017、2018年;
4. 各機組的資料檔案按 /訓練集/[風場]/[機組]/[日期].csv的方式存盤;
5. 氣象資料存盤在 /訓練集/[風場] 檔案夾下,
測驗集說明
1. 測驗集分為兩個檔案夾:測驗集初賽、測驗集決賽,初賽和決賽的檔案夾組織形式一致;
2. 初賽和決賽檔案夾各包括80個時段的資料,每個時段1小時資料(30S解析度,時間以秒數表達),春夏秋冬各20個時段,初賽編號1-20,決賽編號21-40;即初賽的時段編號為春_01-冬_20共80個;決賽的時段編號為春_21-冬_40共80個;
3. 各機組的資料檔案按照 /測驗集_**/[風場]/[機組]/[時段].csv 的方式存盤;
4. 氣象資料存盤在 /測驗集_**/[風場]/ 檔案夾下,共80個時段風場所在地的風速風向資料,每個時段提供過去12小時和未來1小時的風速和風向資料,時段編碼同上,時間編碼為-11~2,其中0~1這個小時正好對應的是機艙的1小時資料,

上圖為測驗集合資料劃分方式,-11~1時間段之內積累的資料作為模型的輸入,用于預測未來10分鐘內(1~2之間)的風速和風向,
缺失值
資料中的缺失值主要來自兩個方面,一種是當天的資料記錄存在缺失,另一種是某些時間段的資料存在缺失,多種缺失情況導致在填充資料時存在遺漏問題,僅使用一種方式填充缺失值會導致缺失值的填充出現缺漏,因此比賽中我們同時使用了 forward fill、backward fill與均值填充以保證填充覆寫率,這樣處理可能會引入噪音,但是神經網路對于噪音有一定的容忍度,因而最終的訓練效果影響并不大,考慮到訓練資料、未來的測驗資料中都可能存在缺失資料,而且它們的記錄方式是相同的,因此我們沒有去掉存在缺失值的資料,同時對它們使用了相同的填充方式,避免因為預處理不同導致資料分布不一致問題的出現,
模型思路介紹
模型結構
比賽中,我們采用了Encoder-Decoder 形式的模型,通過序列模型挖掘輸入序列中的資訊,再通過Decoder進行預測,這里的Encoder、Decoder有多種選擇,例如常見的序列模型LSTM,或者近幾年興起的Transformer,比賽中我們在Decoder側堆疊了多層LSTM,Encoder側只使用了一層LSTM,模型中沒有加入dropout進行正則化,這是考慮到資料中本身就存在大量的高頻噪音,再加入dropout會導致模型收斂緩慢,影響模型的訓練效率,我們使用飛槳框架搭建模型結構,后來發現飛槳官方的自然語言處理模型庫PaddleNLP(https://github.com/PaddlePaddle/PaddleNLP)提供了方便的資料處理API、豐富的網路結構和預訓練模型以及分類、生成等各種NLP應用示例,很適合打比賽,后續會考慮用起來,
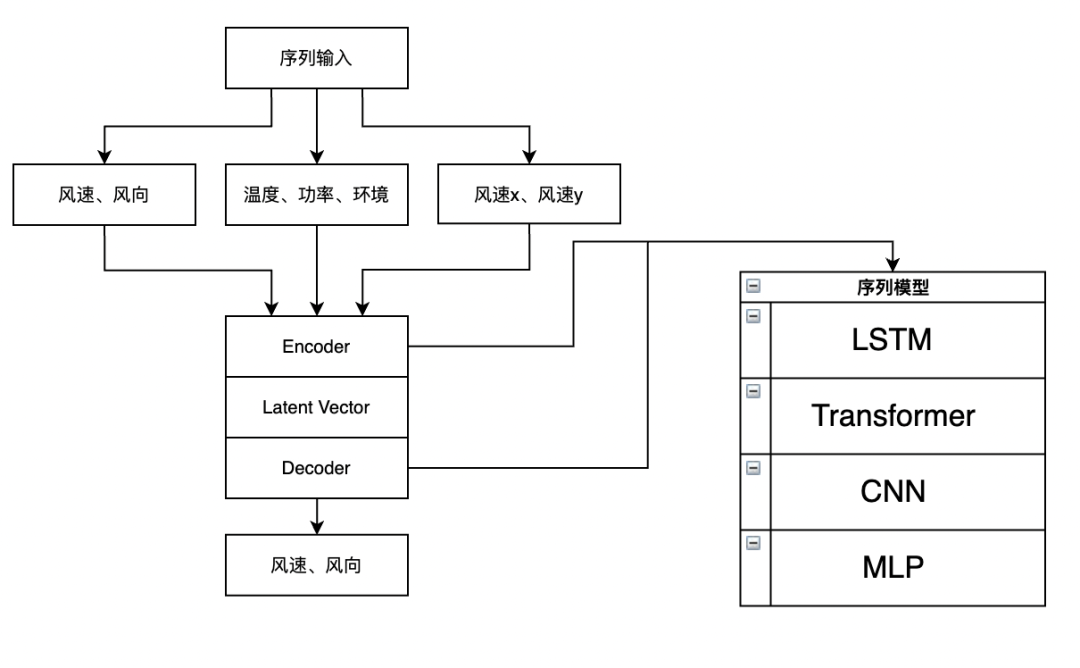
使用飛槳框架構建的最終模型結構的代碼如下:
class network(nn.Layer):
def __init__(self, name_scope='baseline'):
super(network, self).__init__(name_scope)
name_scope = self.full_name()
self.lstm1 = paddle.nn.LSTM(128, 128, direction = 'bidirectional', dropout=0.0)
self.lstm2 = paddle.nn.LSTM(25, 128, direction = 'bidirectional', dropout=0.0)
self.embedding_layer1= paddle.nn.Embedding(100, 4)
self.embedding_layer2 = paddle.nn.Embedding(100, 16)
self.mlp1 = paddle.nn.Linear(29, 128)
self.mlp_bn1 = paddle.nn.BatchNorm(120)
self.bn2 = paddle.nn.BatchNorm(14)
self.mlp2 = paddle.nn.Linear(1536, 256)
self.mlp_bn2 = paddle.nn.BatchNorm(256)
self.lstm_out1 = paddle.nn.LSTM(256, 256, direction = 'bidirectional', dropout=0.0)
self.lstm_out2 = paddle.nn.LSTM(512, 128, direction = 'bidirectional', dropout=0.0)
self.lstm_out3 = paddle.nn.LSTM(256, 64, direction = 'bidirectional', dropout=0.0)
self.lstm_out4 = paddle.nn.LSTM(128, 64, direction = 'bidirectional', dropout=0.0)
self.output = paddle.nn.Linear(128, 2, )
self.sigmoid = paddle.nn.Sigmoid()
# 網路的前向計算函式
def forward(self, input1, input2):
embedded1 = self.embedding_layer1(paddle.cast(input1[:,:,0], dtype='int64'))
embedded2 = self.embedding_layer2(paddle.cast(input1[:,:,1]+input1[:,:,0] # * 30
, dtype='int64'))
x1 = paddle.concat([
embedded1,
embedded2,
input1[:,:,2:],
input1[:,:,-2:-1] * paddle.sin(np.pi * 2 *input1[:,:,-1:]),
input1[:,:,-2:-1] * paddle.cos(np.pi * 2 *input1[:,:,-1:]),
paddle.sin(np.pi * 2 *input1[:,:,-1:]),
paddle.cos(np.pi * 2 *input1[:,:,-1:]),
], axis=-1) # 4+16+5+2+2 = 29
x1 = self.mlp1(x1)
x1 = self.mlp_bn1(x1)
x1 = paddle.nn.ReLU()(x1)
x2 = paddle.concat([
embedded1[:,:14],
embedded2[:,:14],
input2[:,:,:-1],
input2[:,:,-2:-1] * paddle.sin(np.pi * 2 * input2[:,:,-1:]/360.),
input2[:,:,-2:-1] * paddle.cos(np.pi * 2 * input2[:,:,-1:]/360.),
paddle.sin(np.pi * 2 * input2[:,:,-1:]/360.),
paddle.cos(np.pi * 2 * input2[:,:,-1:]/360.),
], axis=-1) # 4+16+1+2+2 = 25
x2 = self.bn2(x2)
x1_lstm_out, (hidden, _) = self.lstm1(x1)
x1 = paddle.concat([
hidden[-2, :, :], hidden[-1, :, :],
paddle.max(x1_lstm_out, axis=1),
paddle.mean(x1_lstm_out, axis=1)
], axis=-1)
x2_lstm_out, (hidden, _) = self.lstm2(x2)
x2 = paddle.concat([
hidden[-2, :, :], hidden[-1, :, :],
paddle.max(x2_lstm_out, axis=1),
paddle.mean(x2_lstm_out, axis=1)
], axis=-1)
x = paddle.concat([x1, x2], axis=-1)
x = self.mlp2(x)
x = self.mlp_bn2(x)
x = paddle.nn.ReLU()(x)
# decoder
x = paddle.stack([x]*20, axis=1)
x = self.lstm_out1(x)[0]
x = self.lstm_out2(x)[0]
x = self.lstm_out3(x)[0]
x = self.lstm_out4(x)[0]
x = self.output(x)
output = self.sigmoid(x)*2-1
output = paddle.cast(output, dtype='float32')
return output飛槳框架在訓練模型時有多種方式,可以像其他深度學習框架一樣,通過梯度回傳進行訓練,也可以利用高度封裝后的API進行訓練,在使用高層API訓練時,我們需要準備好資料的generator和模型結構,
飛槳框架中generator的封裝方式如下,使用效率很高:
class TrainDataset(Dataset):
def __init__(self, x_train_array, x_train_array2, y_train_array=None, mode='train'):
# 樣本數量
self.training_data = x_train_array.astype('float32')
self.training_data2 = x_train_array2.astype('float32')
self.mode = mode
if self.mode=='train':
self.training_label = y_train_array.astype('float32')
self.num_samples = self.training_data.shape[0]
def __getitem__(self, idx):
data = self.training_data[idx]
data2 = self.training_data2[idx]
if self.mode=='train':
label = self.training_label[idx]
return [data, data2], label
else:
return [data, data2]
def __len__(self):
# 回傳樣本總數量
return self.num_samples準備好generator后,便可以直接使用fit介面進行訓練:
model = paddle.Model(network(), inputs=inputs)
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.002,
parameters=model.parameters()),
loss=paddle.nn.L1Loss(),
)
model.fit(
train_data=train_loader,
eval_data=valid_loader,
epochs=10,
verbose=1,
)優化pipeline
對于不同風機的資料,我們提取特征的方式是相同的,因此我們可以利用python的Parallel庫進一步優化代碼的性能,提升迭代的效率,核心代碼如下:
# 生成訓練資料
def generate_train_data(station, id):
df = read_data(station, id, 'train').values
return extract_train_data(df)
# 通過并行運算生成訓練集合
train_data = []
for station in [1, 2]:
train_data_tmp = Parallel(n_jobs = -1, verbose = 1)(delayed(lambda x: generate_train_data(station, x))(id) for id in tqdm(range(25)))
train_data = train_data + train_data_tmp這里提升的效率與CPU的核心個數成正比,比賽中我們使用了8核CPU,因此可以在資料生成上提升8倍的效率,
擬合風向的問題
本次比賽的預測標簽包含風速與風向,其中對于風向,由于角度是回圈的,我們有 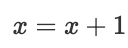 評價函式為 MAE,在訓練階段,直接預測風向會存在問題,因為0與1代表著相同的意義,模型在遇到風向為0/1的情況時預測為它們的均值0.5,導致誤差,這里我們通過將風向、角度轉化為風向在垂直方向上的分量,來避免直接預測風向,同時可以避免擬合風向帶來的問題,
評價函式為 MAE,在訓練階段,直接預測風向會存在問題,因為0與1代表著相同的意義,模型在遇到風向為0/1的情況時預測為它們的均值0.5,導致誤差,這里我們通過將風向、角度轉化為風向在垂直方向上的分量,來避免直接預測風向,同時可以避免擬合風向帶來的問題,
處理噪音
在取得A榜第一名的成績后,我們嘗試對資料中存在的噪音進行處理,由于對輸入側進行處理的風險比較大,容易抹除輸入特征中的有效信號,于是我們選擇對標簽進行平滑處理,我們將模型預測后的值與原標簽做加權平均,接著使用平滑后的新標簽進行訓練,實作了在A榜上0.1分的提升,
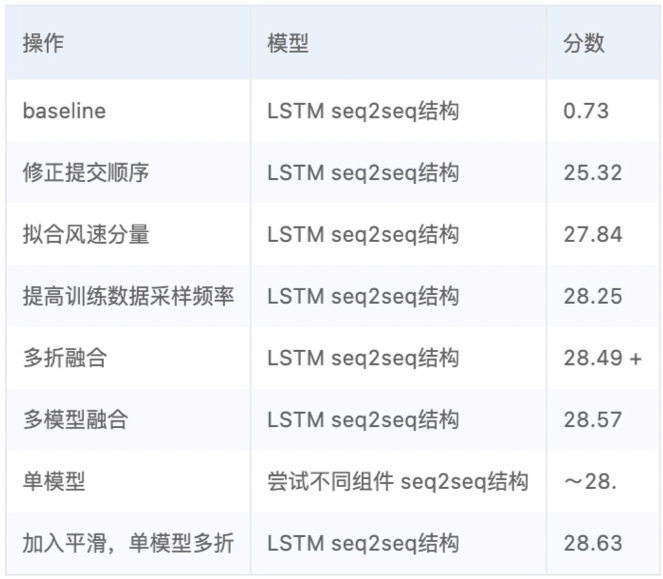
實驗結果
比賽的分數由如下公式計算得出:
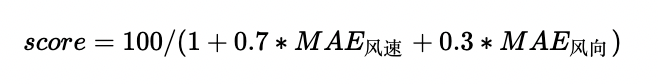
其中,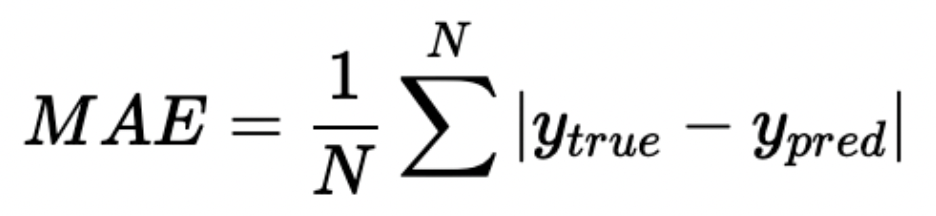 為平均絕對誤差,實驗結果如下表所示,不難發現,比賽成績的提升主要來自于對資料與標簽的處理,這也是我們在建模時最應該重視的兩個要素,
為平均絕對誤差,實驗結果如下表所示,不難發現,比賽成績的提升主要來自于對資料與標簽的處理,這也是我們在建模時最應該重視的兩個要素,
賽后感想
這一次工業大資料比賽中,我們在風況預測賽道與重型配件需求預測賽道中均取得了二等獎的好成績,通過這一次比賽,我們發現工業場景下的資料質量可能并不理想,對缺失值、噪音都需要進行細心處理,在處理時間序列預測任務時,歷史資料的積累中可能并不包括未來遇到的突發情況,僅僅依賴模型可能會存在較大的偏差,這也是我們在建模時需要格外關注的問題,
studio專案鏈接:
https://aistudio.baidu.com/aistudio/projectdetail/3260925
Paddle地址:
https://github.com/PaddlePaddle/Paddle
PaddleNLP地址:
https://github.com/PaddlePaddle/PaddleNLP
參考文獻
[1] 工業大資料產業創新平臺 https://www.industrial-bigdata.com/Competition
相關推薦
這里有一份輕量級文字識別技術創新大賽優勝團隊的修煉秘籍送給你!
輕量級文字識別技術創新大賽亞軍方案分享

關注【飛槳PaddlePaddle】公眾號
獲取更多技術內容~
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/433339.html
標籤:其他
上一篇:mac安裝最新Kafka3.0
下一篇:利用現代技術研發的人工智能