簡介
之前實作了基于FPGA的Winograd CNN加速器(VGG16)和基于FPGA的MobileNet v2加速器,但這兩個演算法在本質上區別不大:一個是VGG16,另一個是輕量級的MobileNet v2,所實作的功能都是影像分類,因此,為了嘗試更多的應用,本文在FPGA上實作了一個目標檢測網路----Yolov4 tiny,yolo4 tiny的結構是YOLOv4的精簡版,屬于輕量化模型,引數只有600萬相當于原來的十分之一,這類網路不僅能實作對影像的分類任務,還可以找出目標的位置,因此,更加貼近實際應用中的需求,如行人檢測、口罩檢測等,
網路結構
對于該部分的內容,已經在博主的另一篇文章中進行了詳細的介紹,此處略去,
FPGA IP核的設計
根據對網路結構的分析,我們發現,yolo4 tiny主要由以下幾個計算組成:
1.3x3標準卷積
2.1x1point-wise卷積
3.上采樣、下采樣(2x2最大池化)
4.concat操作
我們將上述計算分成兩類,第一類是需要重點加速的,如3x3標準卷積和1x1point-wise卷積,它們占網路總體計算量的95%以上,因此是我們需要重點關注的地方,第二類是一些輕量級的運算,如上采樣、下采樣和concat操作,其中concat可以通過設定起始地址偏移的方式實作,因此不予以考慮,而其他兩個運算,計算量相對于整個網路來說,也是微乎其微的,因此簡單的在FPGA上實作即可,
3x3標準卷積設計
關于這部分的設計,我們很大程度上參考了論文,
訪存部分
由于FPGA片上存盤資源(BRAM)十分有限,而卷積神經網路的權重以及中間計算結果特征圖都具有較大的存盤占用,因此,快取整幅特征圖顯然是不現實的,因此,我們采取了回圈分塊策略,
具體如下:
假
設
輸
入
特
征
圖
I
為
N
×
H
i
n
×
W
i
n
,
權
重
為
M
×
N
×
K
×
K
(
K
=
3
)
,
輸
出
特
征
圖
O
為
M
×
H
×
W
,
假設輸入特征圖I為N\times H_{in}\times W_{in},權重為M\times N\times K\times K(K=3),輸出特征圖O為M\times H\times W,
假設輸入特征圖I為N×Hin?×Win?,權重為M×N×K×K(K=3),輸出特征圖O為M×H×W,令輸入通道、輸出通道、輸出特征圖高、寬的分塊因子分別為
T
n
,
T
m
,
T
r
,
T
c
T_n,T_m,T_r,T_c
Tn?,Tm?,Tr?,Tc?,則每次計算的時候,我們加載
T
n
×
(
T
r
+
K
?
1
)
×
(
T
c
+
K
?
1
)
T_n\times (T_r+K-1)\times (T_c+K-1)
Tn?×(Tr?+K?1)×(Tc?+K?1)大小的輸入特征圖塊,
T
m
×
T
n
×
K
×
K
T_m\times T_n \times K \times K
Tm?×Tn?×K×K大小的權重,然后進行卷積計算,得到
T
m
×
T
r
×
T
c
T_m\times T_r\times T_c
Tm?×Tr?×Tc?大小的輸出特征塊(部分和或者最終結果),本次計算完成后,我們再讀取下一塊輸入特征和權重,再進行計算,如下圖所示(下圖中load output feature maps可以省去,部分和一直存盤在片上即可)

計算部分
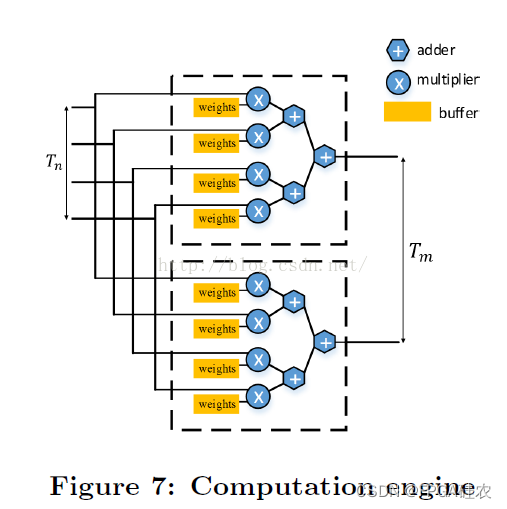
計算部分就是一個標準的3x3卷積,而卷積運算的并行度共有4個維度,分別是
1.輸入通道并行,即同時計算多個輸入通道的特征圖和權重的卷積,
2.輸出通道并行,即同時計算多個輸出特征圖的結果或部分和,
3.卷積視窗內并行,即卷積視窗內
K
×
K
K\times K
K×K個神經元和權重之間乘法的并行,
4.輸出像素之間的并行,即同時計算輸出特征圖上多個神經元,
其中后兩者的實作較為不易,例如3需要使用行緩沖,4的設計則更加復雜,因此,在本加速器的設計中,我們采用1,2這兩種并行方式,假設并行度為
T
n
,
T
m
T_n,T_m
Tn?,Tm?,則有

不難想象,其硬體架構應該是一個并行乘法單元+一個加法樹,如下圖所示
總結
上面已經分別講了計算部分和訪存部分的設計方式,因此可以得到整個加速程序,用偽代碼表示,即
for(r=0;r<H;r+=Tr){
for(c=0;c<W;c+=Tc){
for(m=0;m<M;m+=Tm){
for(n=0;n<N;n+=Tn){
load I[n:n+Tn][r:r+Tr+K-1][c:c+Tc+K-1] to ifm_buff;
load W[m:m+Tm][n:n+Tn][:][:] to wt_buff; //片外訪存
//片上計算
for(ii=0;ii<K;ii++)
for(jj=0;jj<K;jj++)
for(rr=0;rr<Tr;rr++)
for(cc=0;cc<Tc;cc++)
for(mm=0;mm<Tm;mm++)
for(nn=0;nn<Tn;nn++)
ofm_buff[mm][rr][cc]+=
ifm_buff[nn][rr+ii-1][cc+jj-1]*wt_buff[mm][nn][ii][jj];
}
store ofm_buff to O[m:m+Tm][r:r+Tr][c:c+Tc]; //片外訪存
}
}
}
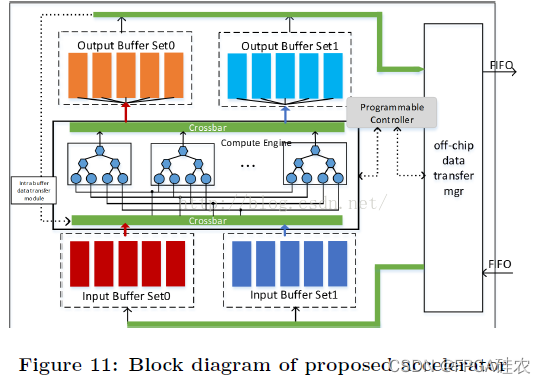
此外,為了進一步增大系統的吞吐率,我們還進行了乒乓操作,以掩蓋資料的傳輸時間,如下圖所示,這是一種以面積換速度的方法,
1x1 Point-Wise卷積設計
1x1卷積,實際上是一個矩陣乘法,因此設計相對比較簡單,按照分塊矩陣乘法進行設計即可,
分析:假設特征圖為
N
×
H
×
W
N\times H \times W
N×H×W,權重為
M
×
N
M\times N
M×N,則1x1卷積相當于矩陣
W
M
×
N
W_{M\times N}
WM×N?和矩陣
I
N
×
(
H
×
W
)
I_{N\times (H\times W)}
IN×(H×W)?的乘積,因此,我們設定分塊系數如下:
輸出通道分塊系數為
T
m
T_m
Tm?,輸入通道分塊系數為
T
n
T_n
Tn?,而二維特征圖我們把它看成一維向量,其分塊系數為
T
p
(
p
i
x
e
l
)
T_p(pixel)
Tp?(pixel),然后進行分塊矩陣乘法IP核的設計,
同3x3標準卷積的設計一樣,我們也進行乒乓操作,
采樣
上采樣
在yolo4-tiny中,上采樣操作是nearest模式的,具體可參見博客
HLS實作在此處略去,因為對最終加速器的吞吐率影響不大,下同,
下采樣
在yolo4-tiny中,就是2x2的最大池化層,
CPU端設計
我們的方法是,在block design中例化卷積和采樣IP核,然后通過在PS端多次呼叫PL端的IP核,來對yolo4 tiny進行加速,
CPU端代碼的撰寫,我們采用的類的方法
class BasicConv{
public:
int h;
int w;
int s;
int k;
int p;
int ch_in;
int ch_out;
data_t* weight;
data_t* bias;
};
class Resblock_body{
public:
int h;
int w;
int ch_in;
int ch_out;
BasicConv* conv1;
BasicConv* conv2;
BasicConv* conv3;
BasicConv* conv4;
};
class CSPDarkNet{
public:
BasicConv* basic_conv1;
BasicConv* basic_conv2;
BasicConv* basic_conv3;
Resblock_body* resblock1;
Resblock_body* resblock2;
Resblock_body* resblock3;
};
如上面的代碼所示,有BasicConv類,Resblock_body類和CSPDarkNet類,其中BasicConv即一個卷積+BN層+leakyrelu層,Resblock_body為yolov4 tiny中的一個重要結構,共4個,最后,BasicConv和Resblock_body組成了yolo4 tiny的backbone:CSPDarkNet,
CSPDarkNet和FPN以及yolo_head,共同組成了yolov4 tiny網路:
class Yolo4_Tiny{
public:
CSPDarkNet* backbone;
//conv_forP5
BasicConv* conv_forP5_conv;
//yolo_headP4
BasicConv* yolo_headP4_basic_conv1;
data_t* yolo_headP4_w2;
data_t* yolo_headP4_b2;
//yolo_headP5
BasicConv* yolo_headP5_basic_conv1;
data_t* yolo_headP5_w2;
data_t* yolo_headP5_b2;
//upsample
BasicConv* upsample_conv;
Yolo4_Tiny(){ //���?��
this->backbone=new CSPDarkNet();
//conv_forP5
this->conv_forP5_conv=new BasicConv(13,13,1,1,0,512,256); //K=1
//yolo_headP4
this->yolo_headP4_basic_conv1=new BasicConv(26,26,3,1,1,384,256);
this->yolo_headP4_w2=new data_t[75*256*1*1]; //K=1
this->yolo_headP4_b2=new data_t[75];
//yolo_headP5
this->yolo_headP5_basic_conv1=new BasicConv(13,13,3,1,1,256,512);
this->yolo_headP5_w2=new data_t[75*512*1*1]; //K=1
this->yolo_headP5_b2=new data_t[75];
//upsample
this->upsample_conv=new BasicConv(13,13,1,1,0,256,128); //K=1
}
void load_weight(string dir){
this->backbone->load_weight(dir);
//conv_forP5
this->conv_forP5_conv->load_weight(dir+"\\conv_forP5");
//yolo_headP4
read_params(dir+"\\yolo_headP4\\w1.bin",this->yolo_headP4_basic_conv1->weight,256*384*3*3);
read_params(dir+"\\yolo_headP4\\b1.bin",this->yolo_headP4_basic_conv1->bias,256);
read_params(dir+"\\yolo_headP4\\w2.bin",this->yolo_headP4_w2,75*256*1*1);
read_params(dir+"\\yolo_headP4\\b2.bin",this->yolo_headP4_b2,75);
//yolo_headP5
read_params(dir+"\\yolo_headP5\\w1.bin",this->yolo_headP5_basic_conv1->weight,512*256*9);
read_params(dir+"\\yolo_headP5\\b1.bin",this->yolo_headP5_basic_conv1->bias,512);
read_params(dir+"\\yolo_headP5\\w2.bin",this->yolo_headP5_w2,75*512*1*1);
read_params(dir+"\\yolo_headP5\\b2.bin",this->yolo_headP5_b2,75);
//upsample
this->upsample_conv->load_weight(dir+"\\upsample");
}
//
void forward(data_t* in,data_t* out0,data_t* out1){
static data_t feat1[256*26*26];
static data_t feat2[512*13*13];
static data_t P5[256*13*13];
static data_t out0_tmp[512*13*13];
static data_t P5_Upsample[128*13*13];
static data_t P4[384*26*26];
static data_t out1_tmp[256*26*26];
//compute
this->backbone->forward(in,P4+128*26*26,feat2); //相當于concat,P4=concat(Upsample_out,feat1)
//cout<<"backbone end\n";
//conv_forP5
this->conv_forP5_conv->forward(feat2,P5);
//out0
this->yolo_headP5_basic_conv1->forward(P5,out0_tmp);
conv_leakyrelu(512,75,0,1,1,13,13,out0_tmp,this->yolo_headP5_w2,this->yolo_headP5_b2,out0,0);
//upsample_conv
this->upsample_conv->forward(P5,P5_Upsample);
//upsample
sampling(P5_Upsample,P4,128,13,0);
//out1
this->yolo_headP4_basic_conv1->forward(P4,out1_tmp);
conv_leakyrelu(256,75,0,1,1,26,26,out1_tmp,this->yolo_headP4_w2,this->yolo_headP4_b2,out1,0);
}
};
模型訓練及匯出
由于算力的限制,模型并沒有訓練,而是直接使用訓練好的權重(資料集為VOC),詳細可參見鏈接
在送入加速器之前,我們進行了卷積-BN融合操作,從而節省了一部分的計算量,經過撰寫的python腳本融合后的權重按如下形式存盤
結果展示
展示:本工程只加速了yolo4 tiny網路本身,并將yolo4 tiny網路的輸出存盤在SD卡上,后續的解碼以及可視化則是在PC上完成的,下圖是結果展示,可以看到,雖然進行了16bit定點數量化,但對最終目標檢測的結果并無很大影響,

模型的性能: 模型部署在zynq7020(xc7z020clg400-2)開發板上,單張圖片的推理時間為383ms
附錄
整個工程檔案夾結構如下
包含HLS原始碼(hls)、CPU端原始碼(sdk)、已經處理好的權重(folded_weights)以及解碼、可視化工具(tools),令附有一個演示視頻,
工程原始碼和更多細節詳情可加qq 1830010557
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/434537.html
標籤:AI