動手實作深度神經網路1 兩層神經網路
在這個系列中,我們將嘗試使用python手寫一個神經網路,當然實際可用的神經網路模型非非常復雜,涉及諸多實作細節和優化,因此,我們先從一個兩層的神經網路開始,之后不斷完善和改進,
我們使用這個網路進行MNIST資料集手寫數字識別,因為這是第一個網路,所以事先比較簡單,沒有實作批處理等,而是每次輸入一個圖片(MNIST資料集中的一個手寫圖片時28*28的矩陣,為了運算方便,我們一般把它扁平化為有784個元素的一維矩陣),同時,因為在計算梯度時采用數值微分的方法,這樣是非常慢的,因此訓練資料和測驗資料都只能從MNIST資料集中選取一小部分,不過不要灰心,等到下一篇文章時,就會實作一個快速高效的神經網路了,
1.網路的基本結構
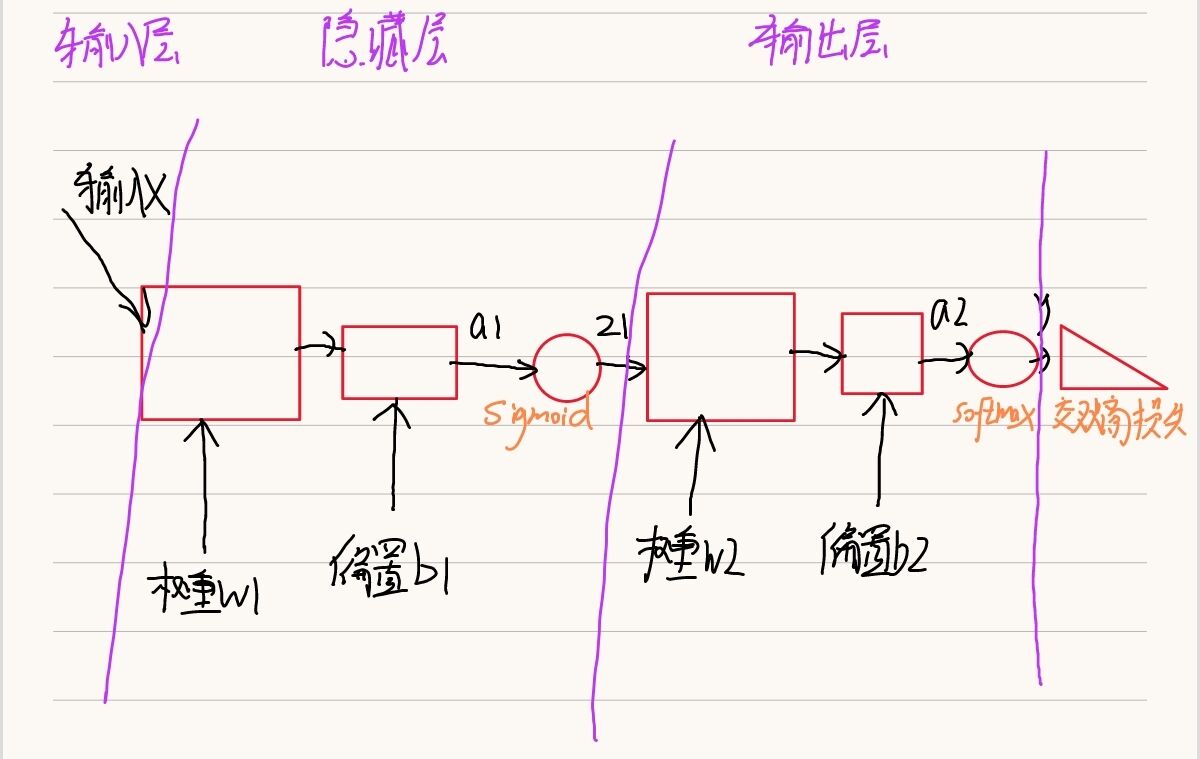
2.兩層神經網路的類
2.1定義類與類初始化函式
class Myself_Two_Layer_Net:
# 一個神經網路在初始化應該接受一些超引數的設定如:各層神經元數量、初始化引數時的高斯分布的規模
def __init__(self,input_size,hidden_size,output_size,weight_init_std):
# 這是神經網路的引數,使用字典存放
# 引數初始化
self.params={}
# w1 b1是第一層(隱藏層)的權重和偏置
# w1的形狀是input_size*hidden_size的矩陣 b1的形狀是有hidden_size格元素的一維矩陣 圖
# 引數一般初始化時選用高斯分布(正態分布)亂數 np.random.randn(a,b)生成a行b列的符合高斯分布的亂數矩陣
self.params['w1']=weight_init_std*np.random.randn(input_size,hidden_size)
self.params['b1']=hidden_size
# w2 b2是第二層(隱藏層)的權重和偏置
self.params['w2'] = weight_init_std * np.random.randn(hidden_size,output_size)
self.params['b2'] = output_size
一個神經網路在初始化應該接受一些超引數的設定如:各層神經元數量、引數初始化規則等,因為“根據梯度調整引數”的作業沒有放在這個類中,所以不需要接受學習率,
引數初始化一般使用高斯分布隨機初始化,關于各層神經元數量的具體值,等到后面使用這個網路時再說明,
2.2兩層神經網路的作業流程
1 接收輸入–>2 經過兩層運算–>3 求損失函式值–>4 求個損失函式值關于各個引數的梯度–>5 (根據梯度更新引數)
步驟1已經在“類初始化方法”中實作了,步驟5由類的使用者實作,因此主要是實作2 3 4三個步驟,
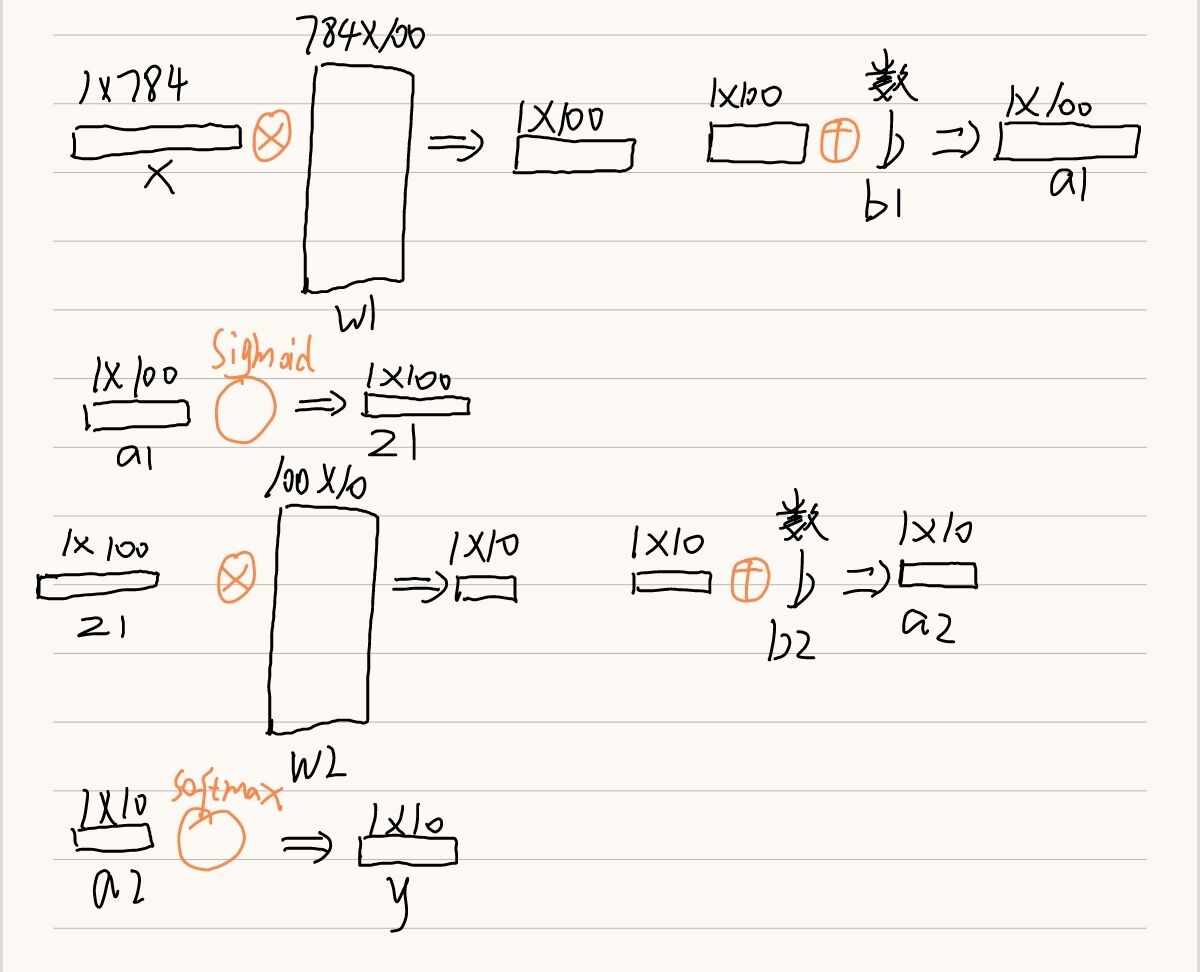
2.2.1經過兩層運算
# 經過兩層運算
def predict(self,x):
# 取出引數
w1,b1=self.params['w1'],self.params['b1']
w2,b2=self.params['w2'],self.params['b2']
a1=np.dot(x,w1)+b1
# 這里需要我們自己實作一下sigmoid激活函式
z1=sigmoid(a1)
a2=np.dot(z1,w2)+b2
# 這里需要我們自己實作一下softmax激活函式
y=softmax(a2)
return y
可以看到,神經網路的計算流程還是很簡單的,我們使用np.dot進行矩陣乘法,
這里需要我們自己實作一下sigmoid和softmax兩個激活函式(如果對于這兩個激活函式還不熟悉,可以看我之前的文章,有詳細的講解)
def sigmoid(x):
# 因為是矩陣運算所以使用np.exp而不是math.exp
return 1/(1+np.exp(-x))
def softmax(x):
max=np.max(x)
x=x-max
return np.exp(x)/np.sum(np.exp(x))
(這里的softmax函式只是用與沒有實作批處理的神經網路,在后續文章中會對它進行過完善)
max=np.max(x)
x=x-max
這兩行代碼是防止計算溢位,這里回答兩個問題:
1.為什么會出現計算溢位?
因為softmax函式的實作中要進行指數函式的運算,但是指數函式的值很容易變得非常大,比如,exp(10)的值 會超過20000,exp(100)會變成一個后面有40多個0的超大值,exp(1000)的結果會回傳 一個表示無窮大的inf,如果在這些超大值之間進行除法運算,結果會出現“不確定”的情況,
2.為什么會可以使用減去最大值這樣簡單粗暴的函式?
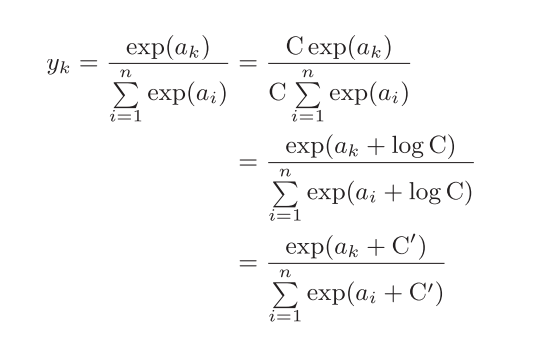
從這個式子中可以看出在進行softmax的指數函式的運算時,加上(或者減去) 某個常數并不會改變運算的結果,
2.2.2求損失函式值
# 求損失函式值
def loss(self,x,t):
y=self.predict(x)
# 這里需要我們自己實作一下交叉熵損失函式
return cross_entropy_error(y,t)
# 無batch學習的交叉熵函式 監督資料是one-hot格式
# 對于監督資料是one-hot格式的情況 實際上只計算對應正確解標簽的輸出的自然對數
def cross_entropy_error(y,t):
# 函式內部在計算np.log時,加上了一個微小值delta 1e-7,
# 這是因為,當出現np.log(0)時,np.log(0)會變為負無限大的 - inf,這樣一來就會導致后續計算無法進行,作為保護性對策,添加一個微小值可以防止負無限大的發生
delta=1e-7
return -np.sum(t*np.log(y+delta))
這里解釋兩個問題:
一個是監督資料,它很容易個測驗資料這個概念混淆起來,后面的代碼會讓你有一個更直觀的認識

一個是one-hot格式(獨熱編碼),它指的是將正確解標簽設為1,其他均設為0
假設監督資料t是[0,0,1,0,0,0,0,0,0,0] 神經網路的輸出y是[0.1,0.05,0.6,0.1…] 正確解標簽的索引是“2”,與之對應的神經網路的輸出是0.6
那么交叉熵就是:就是?log 0.6 = 0.51
我們寫一個例子驗證一下:
t=np.array([0,0,1,0,0,0,0,0,0,0])
# 這里關鍵是索引2上是0.6 其他位置資料都不重要
y=np.array([0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06])
print(np.log(y))
print(t*np.log(y))
z=-np.sum(t*np.log(y))
print(z)

因此,可以說交叉熵誤差的值是由正確解標簽所對應的輸出結果決定的,
2.2.3求個損失函式值關于各個引數的梯度
# 求個損失函式值關于各個引數的梯度
def gradient_numerical(self,x,t):
# 將前面兩步運算構成lambda運算式(可以理解為數學上的一個函式)傳遞給計算梯度的的方法
loss_W=lambda w:self.loss(x,t)
grads={}
# 這里需要我們自己實作一下numerical_gradient(用數值微分發計算梯度)
grads['w1'] = numerical_gradient_2d(loss_W, self.params['w1'])
grads['b1'] = numerical_gradient_onenumber(loss_W, self.params['b1'])
grads['w2'] = numerical_gradient_2d(loss_W, self.params['w2'])
grads['b2'] = numerical_gradient_onenumber(loss_W, self.params['b2'])
return grads
# 自變數x只能是一個數
def numerical_gradient_onenumber(f, x):
h = 1e-4
# 因為修改了x 也就是params[]所以會計算出f(x+h) 實際上x+h不是作為引數傳遞到f中的,而是直接改變了f原有引數的值
# 所以真正其作用的是“x = x + h”和“x = temp - h”
temp = x
x = x + h
fxh1 = f(x)
x = temp - h
fxh2 = f(x)
grad = (fxh1+fxh2)/2
x=temp
return grad
# 自變數x只能是一維矩陣
def numerical_gradient_1d(f, x):
h = 1e-4
grad = np.zeros_like(x)
# x是[x1,x2,.....] f是f(x1,x2,.....)
for i in range(x.size):
temp=x[i]
x[i]=x[i]+h
fxh1=f(x) # 計算f(x+h) 因為是多元函式,所以只有xi加上h 其他x不加
x[i]=temp
x[i]=x[i]-h
fxh2=f(x)
grad[i]=(fxh1+fxh2)/2
x[i]=temp
return grad
# 自變數可以是二維矩陣 但是處理辦法比較粗暴,就是批次中每一條都進行數值微分
def numerical_gradient_2d(f, x):
if x.ndim == 1:
return numerical_gradient_1d(f, x)
else:
grad = np.zeros_like(x)
for i, x_i in enumerate(x):
grad[i] = numerical_gradient_1d(f, x_i)
return grad
這里需要說明的有:
一,因為偏置b是一個數,而權重w是一個矩陣,所以為它們提供了不同的數值微分方法,但是其本質是一樣的,等到后面實作了批處理或者采用誤差反向傳播求導之后,偏置b和權重w就可以用同一個方法計算梯度啦,
二,lambda運算式,loss_W=lambda w:self.loss(x,t)這一行代碼將前面兩步封裝為一個lambda函式,可以作為引數傳遞給別的方法使用,
可以看到,這個lambda函式式子中的引數’w’并沒有很么作用,根本沒有傳遞到引數里面去,
也就是說“fxh1 = f(x)”這一行代碼寫成“fxh1 = f(1) fxh1 = f(2)“或者給f的引數傳遞任何數都是可以的,因為真正起作用的是“x = x + h”和“x = temp - h”它們改變了params里面的值!!,在呼叫f()之后會執行”y=self.predict(x) return cross_entropy_error(y,t)“這兩行代碼,而self.predict中用到的params被修改了,因此可以出x+h處的函式值,
下面寫一個例子驗證一下:
def add(x,y):
return x+y
def use(f,a):
z1=f(a)
print(z1)
afunction = lambda w: add(1, 2)
use(afunction,5)
use(afunction,6)
use(afunction,100)

3.兩層神經網路的使用
至此,我們簡單的兩層神經網路的類就寫完了,接下來就是使用了,不過再次強調,這個神經網路設計簡單沒有實作批處理,沒有使用誤差反向傳播計算梯度,效率非常非常低,這里只是介紹使用流程,也是因為這個原因,在使用這個類的時候不得不做了很多妥協,比如“從60000條訓練資料中抽取一部分用來訓練”、“迭代次數只有5次”,即使這樣也花費了很長時間,所以對于完整的代碼(我把它放在了最后)你需要關注的只有以下三點:
一、
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
這里的(x_train, t_train)是訓練資料,用于對神經網路的學習,其中的t_train是監督資料,也就是存放手寫數字的結果標簽,可以參考下圖來理解,
(x_test, t_test)是測驗資料,用于驗證神經網路的學習結果,
二、
network=Myself_Two_Layer_Net(input_size=784, hidden_size=50, output_size=10,weight_init_std=0.01)
因為是訓練MNIST手寫數字識別,原影像是28像素 × 28像素的形狀 為了便于訓練,在這里將它扁平化為有784個元素的一維矩陣,所以輸入層有784個神經元,因為最終輸出的結果是0-9十個數字的分類,所以輸出層有10個神經元,
隱藏層的神經元數量是超引數,它的設計屬于神經網路的優化內容,這里暫時設為100,
三、
learning_rate = 0.1 # 學習率
# 以及
# 計算梯度
grad = network.gradient_numerical(x_train_one, t_train_one)
# 根據梯度更新引數
for key in ('w1', 'b1', 'w1', 'b2'):
network.params[key] -= learning_rate * grad[key]
學習率也是一個超引數,它表示每次更新引數的幅度,
更新引數的方法也很簡單啦,因為沿著梯度方向更新即可,
import sys, os
sys.path.append(os.pardir) # 為了匯入父目錄的檔案而進行的設定
import numpy as np
import matplotlib.pyplot as plt
# 這里使用別人寫好的資料匯入工具
from dataset.mnist import load_mnist
# 匯入我們剛剛寫好的兩層神經網路類
from * * * import Myself_Two_Layer_Net
# 匯入資料
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network=Myself_Two_Layer_Net(input_size=784, hidden_size=50, output_size=10,weight_init_std=0.01)
learning_rate = 0.1 # 學習率
iters_num = 5 # 適當設定回圈的次數 因為這種實作太慢了所以回圈次數設定的少一些
train_size = x_train.shape[0]
test_size = x_test.shape[0]
# train_size是訓練資料規模 60000 如果不進行批處理就要回圈60000次
# 回圈次數太多 太慢 所以從所有的600000條訓練資料中隨機選取100條
mask1 = np.random.choice(train_size, 100)
x_train_part=x_train[mask1]
t_train_part=t_train[mask1]
for i in range(iters_num):
for j in range(x_train_part.shape[0]):
x_train_one=x_train_part[j]
t_train_one=t_train_part[j]
# 計算梯度
grad = network.gradient_numerical(x_train_one, t_train_one)
# 根據梯度更新引數
for key in ('w1', 'b1', 'w1', 'b2'):
network.params[key] -= learning_rate * grad[key]
print("ok"i,j)
#因為沒有實作批處理且采用數值微分,計算準確率會很慢,所以我們只在最后做一次準確率計算 而且只能抽樣計算,不然會很慢很慢
# 當前網路對于訓練資料的準確率
train_acc=0
for i in range(x_train_part.shape[0]):
train_acc += network.accuracy(x_train_part[i], t_train_part[i])
# 從所有的100000條訓練資料中隨機選取100條
mask2 = np.random.choice(test_size, 10)
x_test_part=x_test[mask2]
t_test_part=t_test[mask2]
# 當前網路對于測驗資料的準確率
test_acc=0
for i in range(x_test_part.shape[0]):
test_acc += network.accuracy(x_test_part[i], t_test_part[i])
print("train acc, test acc | " + str(train_acc/100) + ", " + str(test_acc/100))
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/434538.html
標籤:AI