NLP:Transformer的簡介(優缺點)、架構詳解之詳細攻略
目錄
Transformer的簡介(優缺點)、架構詳解之詳細攻略
1、Transformer的簡介
(1)、Transforme的四4個優點和2個缺點
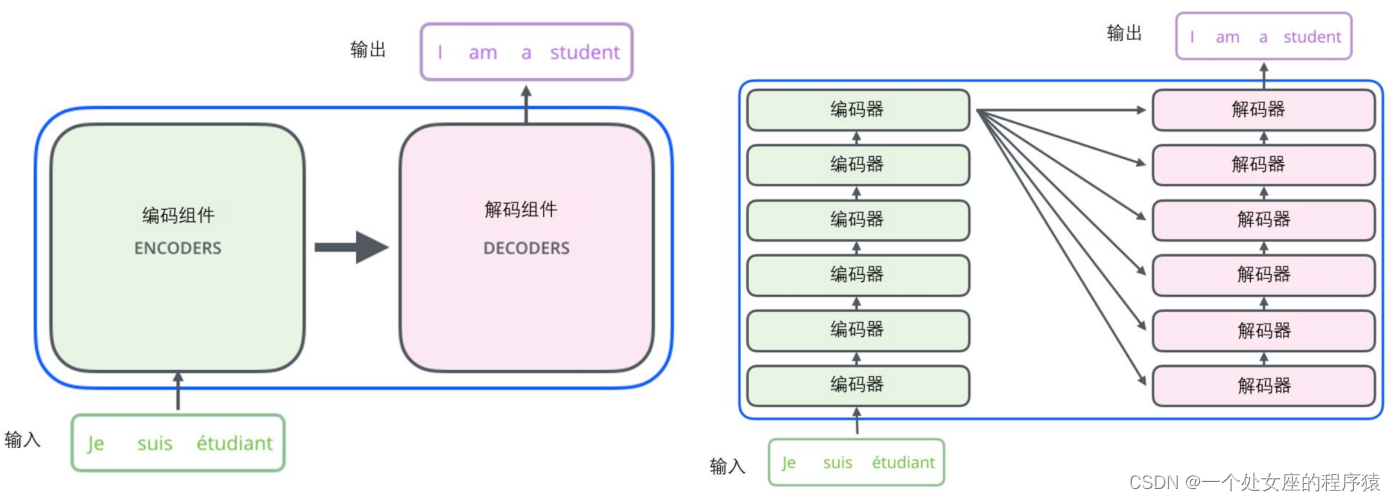
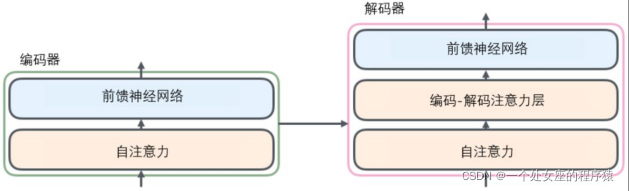
2、Transformer 結構—純用attention搭建的模型→計算速度更快
Transformer的簡介(優缺點)、架構詳解之詳細攻略
1、Transformer的簡介

自 2017 年 Transformer 技術出現以來,便在 NLP、CV、語音、生物、化學等領域引起了諸多進展,
Transformer模型由Google在2017年在 Attention Is All You Need[1] 中提出,該文使用 Attention 替換了原先Seq2Seq模型中的回圈結構,給自然語言處理(NLP)領域帶來極大震動,隨著研究的推進,Transformer 等相關技術也逐漸由 NLP 流向其他領域,例如計算機視覺(CV)、語音、生物、化學等,
因此,我們希望能通過此文盤點 Transformer 的基本架構,分析其優劣,并對近年來其在諸多領域的應用趨勢進行梳理,希望這些作業能夠給其他學科提供有益的借鑒,
本節介紹 Transformer 基本知識,限于篇幅,在這篇推文中,我們先介紹 Transformer 的基本知識,以及其在 NLP 領域的研究進展;后續我們將介紹 Transformer 在其他領域(CV、語音、生物、化學等)中的應用進展,
(1)、Transforme的四4個優點和2個缺點
(1) 每層計算復雜度更優:Total computational complexity per layer,時間復雜度優于R、C等,

(2) 可直接計算點乘結果:作者用最小的序列化運算來測量可以被并行化的計算,也就是說對于某個序列x1,x2……xn ,self-attention可以直接計算xixj的點乘結果,而RNN就必須按照順序從 x1計算到xn,
(3) 一步計算解決長時依賴問題:這里Path length指的是要計算一個序列長度為n的資訊要經過的路徑長度,CNN需要增加卷積層數來擴大視野,RNN需要從1到n逐個進行計算,而self-attention只需要一步矩陣計算就可以,所以也可以看出,self-attention可以比rnn更好地解決長時依賴問題,當然如果計算量太大,比如序列長度n>序列維度d這種情況,也可以用視窗限制self-attention的計算數量,
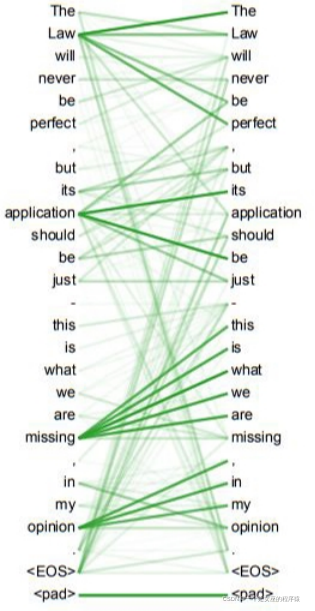
(4) 模型更可解釋:self-attention模型更可解釋,attention結果的分布表明了該模型學習到了一些語法和語意資訊,
實踐上:有些RNN輕易可以解決的問題,transformer沒做到,比如復制string,或者推理時碰到的sequence長度比訓練時更長(因為碰到了沒見過的position embedding),
理論上:transformers非computationally universal(圖靈完備),(我認為)因為無法實作“while”回圈,
2、Transformer 結構—純用attention搭建的模型→計算速度更快
更新……
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/434548.html
標籤:AI
上一篇:超分重建:基礎問答匯總