本文基于之前學習的透視變換、和OCR識別,做了個簡單的小票識別,如下:
import cv2
import numpy as np
from PIL import Image
import pytesseract as tess
dsize = (55, 88) # 統一尺度
# 展示影像,封裝成函式
def cv_show_image(name, img):
cv2.imshow(name, img)
cv2.waitKey(0) # 等待時間,單位是毫秒,0代表任意鍵終止
cv2.destroyAllWindows()
# =========================================================
# ================讀取影像進行預處理=========================
# =========================================================
# 讀取原始的彩色影像
ocr_img = cv2.imread('images/ocr_qr_code.PNG')
h_src, w_src, c_src = ocr_img.shape
# 進行灰度值和二值化轉換
ocr_img_gray = cv2.cvtColor(ocr_img, cv2.COLOR_BGR2GRAY)
# cv_show_image('template_gray', template_gray)
# 高斯濾波
ocr_img_gray = cv2.GaussianBlur(ocr_img_gray, (3, 3), 1)
# 二值化
ret, ocr_img_thresh = cv2.threshold(ocr_img_gray, 200, 255, cv2.THRESH_BINARY)
cv_show_image('template_thresh', ocr_img_thresh)
# 找到所有的輪廓,只需要外輪廓
ocr_img_contours, hierarchy = cv2.findContours(ocr_img_thresh,
cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
# =========================================================
# ================找到最大面積的那個輪廓=========================
# =========================================================
# 找到最大面積的那個輪廓
draw_img = ocr_img.copy() # 階段性測驗查看使用
# 最后的引數可以控制找到前幾個最大的,比如哈,0表示最大的,2表示前三大的,
cont_max = sorted(ocr_img_contours, key=cv2.contourArea, reverse=True)[0] # 按照面積來排序,找到最大的,倒序,
# 畫出這個輪廓,紅色線條
x, y, w, h = cv2.boundingRect(cont_max)
draw_img = cv2.drawContours(draw_img, [cont_max], -1, color=(0, 0, 255), thickness=2) # 畫出這個輪廓,會在原圖上畫
arcLength = cv2.arcLength(cont_max, True) # 求最大的輪廓的周長
# 這個原始輪廓可能是很多歌點哈,但是我們只需要四個點的四邊形的輪廓就行了,這里需要進行輪廓近似運算,
# 不斷的嘗試提升閾值,增大近似范圍,減少邊數目,
rate = 0.01
approx_max = None
while len(cont_max) != 4:
# epsilon是原始輪廓到近似輪廓的最大距離,也是近似的判斷閾值, closed 是表示是個封閉的輪廓
approx_max = cv2.approxPolyDP(cont_max, epsilon=rate * arcLength, closed=True)
if len(approx_max) == 4:
print("rate={}, epsilon={}".format(rate, rate * arcLength))
break
rate += 0.01
print("approx: ", approx_max)
# 畫出這個輪廓,綠色線條
draw_img = cv2.drawContours(draw_img, [approx_max], -1, color=(0, 255, 0), thickness=2) # 畫出這個輪廓,會在原圖上畫
cv_show_image('rectangle_contours_img', draw_img)
del draw_img
# =========================================================
# ================得到了四個頂點,進行透視變換=========================
# =========================================================
# 先排序這個四個頂點,按照((左上),(右上),(右下),(坐下))的順序來定義
# 最終這四個點將轉成((0,0), (w,0), (w,h), (h,w)) + 平移(左上)的形式,
def sort_dotCnt(kps):
rect = np.zeros((4, 2), dtype='float32')
s = kps.sum(axis=1)
# 找出左上和右下
rect[0] = kps[np.argmin(s)]
rect[2] = kps[np.argmax(s)]
# 找出右上和左下
diff = np.diff(kps, axis=1)
rect[1] = kps[np.argmin(diff)]
rect[3] = kps[np.argmax(diff)]
return rect
print(approx_max.shape)
print(approx_max.reshape(4, 2))
rect_ordered = sort_dotCnt(approx_max.reshape(4, 2))
(top_left, top_right, bottom_right, bottom_left) = rect_ordered
# 原始影像中物體的四個頂點的資訊
pts_src = np.array([top_left, top_right, bottom_right, bottom_left], dtype="float32")
# 目標物體中的物體的四個頂點資訊
pts_dst = np.array([(0 + top_left[0], 0 + top_left[1]),
(w + top_left[0], 0 + top_left[1]),
(w + top_left[0], h + top_left[1]),
(0 + top_left[0], h + top_left[1])], dtype="float32")
# 是一個3x3的矩陣,根據對應的兩個點,計算出變換矩陣,由此將原始影像進行轉換,
M = cv2.getPerspectiveTransform(pts_src, pts_dst)
# 基于單應性矩陣,將原始影像轉換成目標影像
im_out = cv2.warpPerspective(ocr_img_thresh, M, (w_src, h_src))
cv_show_image('im_out', im_out)
# =========================================================
# ================識別其數字=========================
# =========================================================
textInImage = Image.fromarray(im_out)
text = tess.image_to_string(textInImage)
print("\nocr detect result:%s" % text)
原圖經過預處理后:

經過輪廓檢測后,得到一個四個頂點的輪廓用綠色線畫出

經過透視變換得到:

最后用過OCR識別得到:
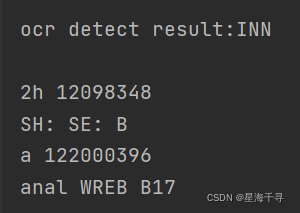
目前智能識別到數字,下一次,我將去看看學習下怎么識別簡體漢字
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/434550.html
標籤:AI