動手實作深度神經網路3 增加誤差反向傳播計算梯度
在這一部分中我們利用誤差反向傳播來計算梯度,誤差反向傳播計算梯度的速度大大超過了之前采用的數值微分發法,經過這次改進,我們的神經網路就能以很快的速度和較高的準確率完成MNIST資料集手寫數字識別啦!
1.理解誤差反向傳播
關于誤差反向傳播的理論和使用計算圖推導理解的程序,我之前的文章:Python深度學習入門筆記 2
理解誤差反向傳播&用python實作自動微分中已經介紹地很詳細了啦,如果你對誤差反向傳播還不了解,就先去看看我這兩篇文章吧,
2.代碼實作
在我們的兩層神將網路類中添加一個方法,如下,
def gradient_BP(self,x,t):
w1, w2 = self.params['w1'], self.params['w2']
b1, b2 = self.params['b1'], self.params['b2']
grads = {}
batch_num = x.shape[0]
# 正向傳播 forward
a1=np.dot(x,w1)+b1
z1=sigmoid(a1)
a2=np.dot(z1,w2)+b2
y=softmax(a2)
# 反向傳播 backward
#一
dy=(y-t)/batch_num
#二
grads['b2']=np.sum(dy,axis=0)
#三
grads['w2']=np.dot(z1.T,dy)
#四
da1=np.dot(dy,w2.T)
#五
dz1=sigmoid_grad(a1) * da1
#六
grads['b1'] = np.sum(dz1, axis=0)
#七
grads['w1'] = np.dot(x.T,dz1)
return grads
代碼中反向傳播的每一步都可以在下面的圖中找到對應,
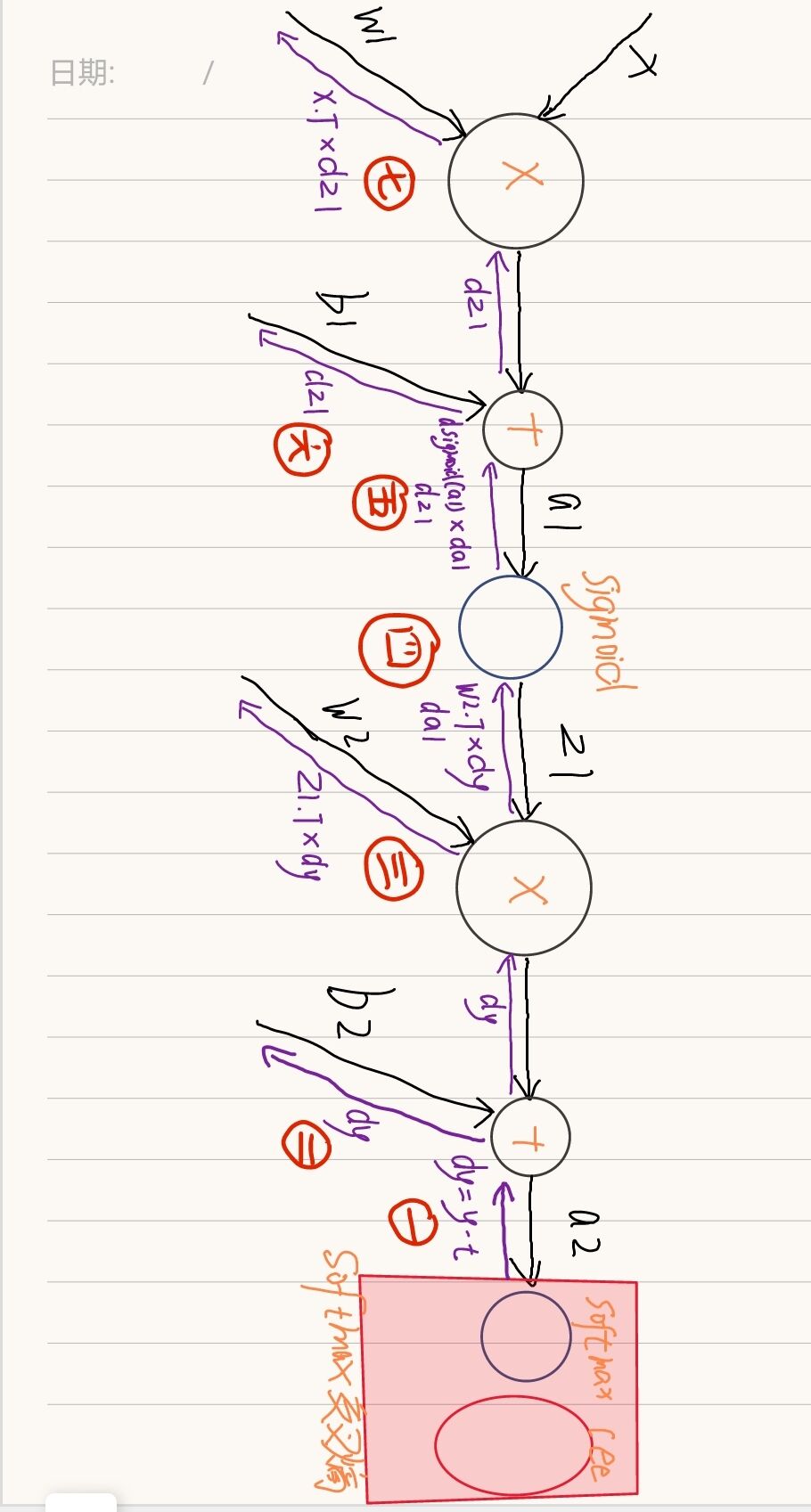
需要說明的有兩點:
- dy=(y-t)/batch_num 在我之前的文章神經網路中的激活函式與損失函式&深入理解推導softmax交叉熵有詳細的解釋和推導程序,這里只說一下結論:
如果神經網路輸出層使用softmax激活函式,并且使用交叉熵誤差,那么反向傳播時,經過交叉熵和softmax后流出的值是(y-t)如下圖
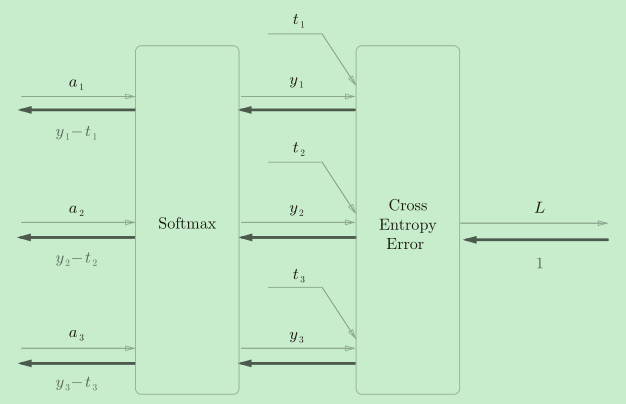
之后除以batch_num是得到平均值,
-
sigmoid_grad
sigmoid函式長這樣:
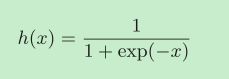
使用計算圖推導它的導函式:
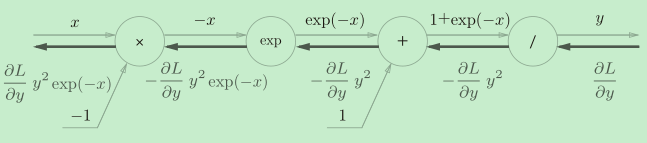
然后,對它的導函式進行化簡:
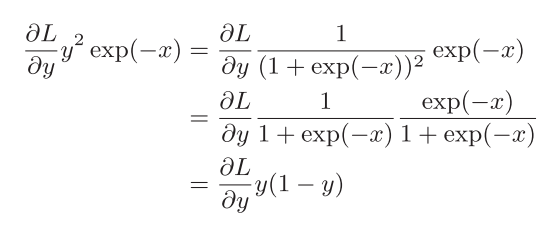
下面是實作的代碼:
def sigmoid_grad(x):
return (1.0 - sigmoid(x)) * sigmoid(x)
3.使用神經網路訓練MNIST資料集手寫數字識別
使用這個神經網路的代碼和上篇文章的幾乎一樣,只有計算梯度的那一行做了替換,
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network=Myself_Two_Layer_Net(input_size=784, hidden_size=100, output_size=10,weight_init_std=0.01)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
learning_rate = 0.1 # 學習率
iters_num = 10000 # 這次終于可以火力全開了
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 計算梯度 這里使用了誤差反向傳播的高效方法!!!!!!!!!!!!!!!!!
# grad = network.gradient_numerical(x_batch, t_batch)
grad= network.gradient_BP(x_batch,t_batch)
# 更新引數
for key in ('w1', 'b1', 'w2', 'b2'):
key
network.params[key] -= learning_rate * grad[key]
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# 繪制圖形
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
同時,我們現在可以把回圈次數設定為10000次,然后來訓練MNIST資料集手寫數字識別
執行代碼:
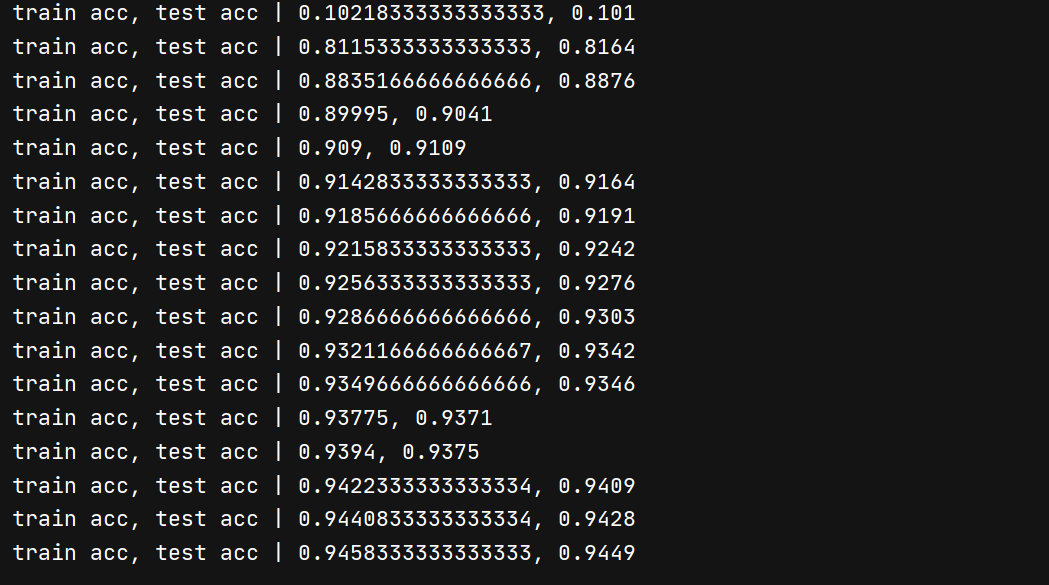
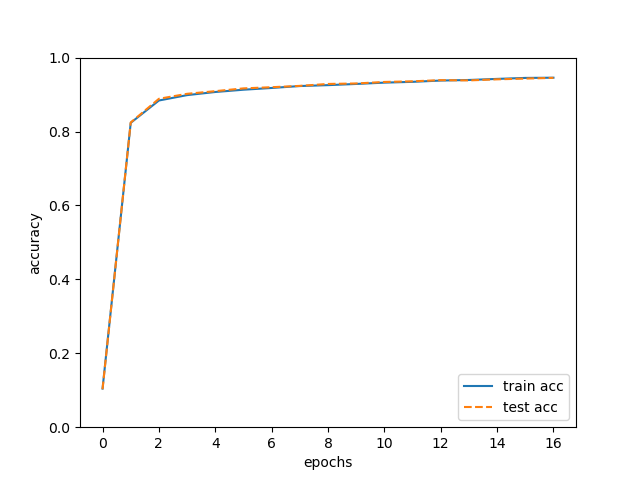
在我的電腦上,只用了不到一分鐘就訓練完成了(在沒有實作誤差反向傳播的代碼,即使把回圈次數設定成5,1分鐘也跑不完)而且可以看到準確率在94%以上!
46124862724)]
[外鏈圖片轉存中…(img-WVB5y6gq-1646124862725)]
在我的電腦上,只用了不到一分鐘就訓練完成了(在沒有實作誤差反向傳播的代碼,即使把回圈次數設定成5,1分鐘也跑不完)而且可以看到準確率在94%以上!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435422.html
標籤:AI
上一篇:目標檢測演算法的分類和優缺點