為什么是ppo?
ppo演算法作為強化學習領域out of art的演算法,如果你要學習強化學習的話 ppo會是你最常用的演算法,openai早已把ppo 作為自己的默認演算法,所以我希望你能認真學完ppo演算法并為自己所用,
強化學習是什么?
簡單來說 強化學習是一類通過不斷與環境互動來學習如何達到設定目標的一類演算法,比如走迷宮,傳統的運籌學演算法往往是通過遍歷所有的點來完成路徑規劃,而強化學習則是實作一個anget,讓這個 agent自己去隨機探索路線,在探索的程序中學習如何走的更遠并最終走到終點,這就是強化學習的思想,
R0 ppo玩超級瑪麗1-1關的視頻
R1 先來學習如何用代碼實作隨機動作play超級瑪麗游戲(5 min)
本次學習需要的相關庫如下,
- gym
- gym_super_mario_bros
- opencv-python
- spinup
- joblib
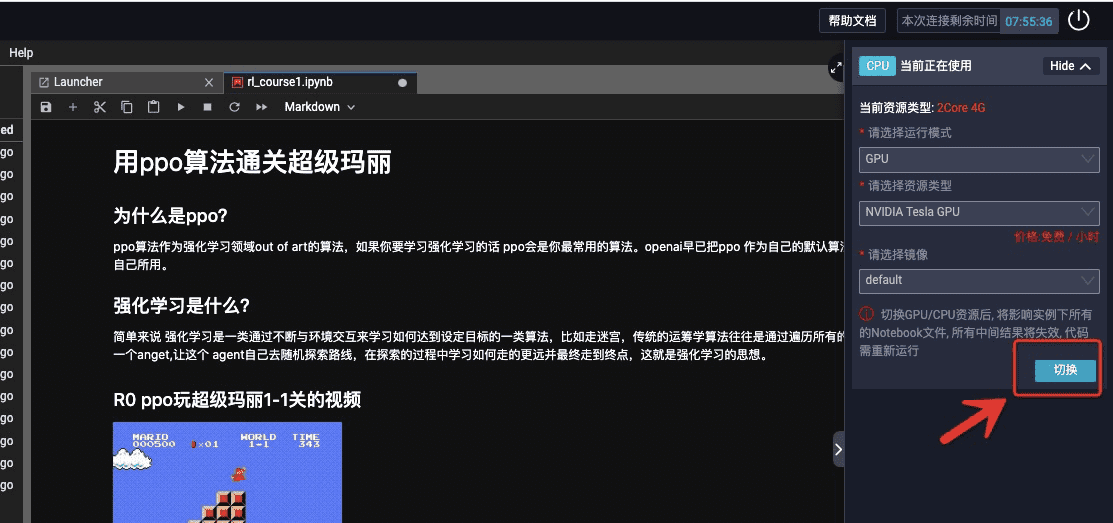
注意本次學習需要在GPU環境中,所以進入DSW后,點擊右側的環境切換按鈕,運行模式選擇GPU,如下圖所示,
# 安裝相關包
# 再次提醒:必須先切換環境為GPU
!pip install gym gym_super_mario_bros opencv-python spinup joblib --user
#匯入實驗需要的包
from nes_py.wrappers import JoypadSpace
import gym_super_mario_bros
from gym_super_mario_bros.actions import SIMPLE_MOVEMENT
#使用gym_super_mario_bros包函式創建游戲環境env
env = gym_super_mario_bros.make('SuperMarioBros-v0')
#指定環境為簡單模式(動作簡化,去除一些左上、左下等復雜動作)
env = JoypadSpace(env, SIMPLE_MOVEMENT)
#使用gym的wrapper函式對游戲視頻進行錄像(由于notebook不支持display,我們錄像后播放觀看)
from gym import wrappers
env = wrappers.Monitor(env,"./gym-results", force=True)
#執行5000個簡單的向右隨機操作
done = True #游戲結束標志
for step in range(5000):
if done:
#如果游戲結束則重置:
state = env.reset()
state, reward, done, info = env.step(env.action_space.sample())
# 關閉創建的游戲env
env.close()
# 通過網頁播放出來剛才的運行實況
import io
import base64
from IPython.display import HTML
video = io.open('./gym-results/openaigym.video.%s.video000000.mp4' % env.file_infix, 'r+b').read()
encoded = base64.b64encode(video)
HTML(data='''
<video width="360" height="auto" alt="test" controls><source src="data:video/mp4;base64,{0}" type="video/mp4" /></video>'''
.format(encoded.decode('ascii')))轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435423.html
標籤:AI
上一篇:動手實作深度神經網路3 增加誤差反向傳播計算梯度&完成MNIST資料集手寫數字識別
下一篇:Opencv 基于C++識別綠燈