ResNet簡單介紹
ResNet是15年提出的經典網路了,在ResNet提出之前,人們發現當模型層數提升到一定程度后,再增加層數就不再能提升模型效果了——這就導致深度學習網路看似出現了瓶頸,通過增加層數來提升效果的方式似乎已經到頭了,ResNet解決了這一問題,
ResNet的核心思想就是引入了殘差邊,即一條直接從輸入添加到輸出的邊,
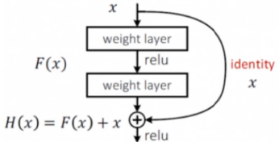
這樣做有什么用處呢?可以這樣理解:假如新加的這些層的學習效果非常差,那我們就可以通過一條殘差邊將這一部分直接“跳過”,實作這一目的很簡單,將這些層的權重引數設定為0就行了,這樣一來,不管網路中有多少層,效果好的層我們保留,效果不好的我們可以跳過,總之,添加的新網路層至少不會使效果比原來差,就可以較為穩定地通過加深層數來提高模型的效果了,
此外,使用殘差邊的另一個好處在于可以避免梯度消失的問題,因為它的這個特點,它可以訓練幾百甚至上千層的網路,
殘差網路為什么可以避免梯度消失其實也很好理解:
在沒有殘差邊的時候,假如網路層數很深的話,要想更新底層的(靠近輸入資料部分)的網路權重,首先對其求梯度,根據鏈式法則需要一直向前累乘,只要其中的任何一個因數過小就會導致求出來的梯度很小很小,這個小梯度就算乘以再大的學習率也是無濟于事;
而當我們有了殘差邊時,求梯度可以直接經過“高速公路”直達我們想要求梯度的物件,此時不管通過鏈式法則走正常路線得到的梯度多么小,兩條路線相加的結果都不會小,就可以很有效地進行梯度更新了,
因為殘差網路的種種優勢,現在很多的主流網路,殘差邊已經成為標配了,可見其深遠的影響力,
ResNet一些具體要點
ResNet根據層數的不同分為很多種,比如下圖中的每一列,也就分別對應著ResNet18,ResNet34,ResNet50等網路結構,其中ResNet152層數最多,也被普遍認為是效果最不錯的(代價也是需要更多的計算量),一般來說ResNet可以作為首選的網路去做分類任務,如果追求最高的精度就用ResNet152,
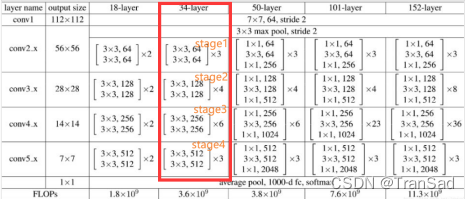
以ResNet34(上圖中框起來的)來舉例子解釋一下它的結構,34其實就代表它有34層,它最上面首先有7*7的卷積層(算1層),再經過(3+4+6+3)=16個殘差塊,每個殘差快有兩層卷積(這里就有16*2=32層),在最后連上一個全連接層(最后1層),所以共34層,
殘差塊是長什么樣子的呢?用殘差邊“包”起來的一部分就可以看作是個殘差快,我在圖中寫了stage1到stage4(補充一下:一般影像的尺寸減半、通道數翻倍時我們就認為算一個stage,不過這些維度在上圖中看不出來,上圖中顯示的都是卷積核的尺寸和通道數,不要搞混了),每個stage其實都用了不同的殘差快,ResNet的重點也就在于殘差塊中的結構,
我們把ResNet34中間結構部分截取出來,從stage1開始往下,其具體結構如下圖:
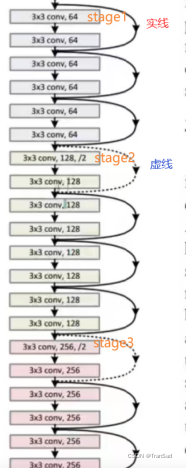
通過各個stage的標記位置可以對比兩張圖,我們對ResNet殘差塊具體是怎么連接的就清楚多了,可以發現除了正常的卷積之外,最顯著的特點就在于每個殘差塊旁邊都帶了要么實線要么虛線的殘差邊,
就通過這些重復的殘差塊結構,我們通過控制層數以及殘差塊中卷積核尺寸和通道數,就得到了各個不同的ResNet了,到此,不管是ResNet幾,其網路結構都可以按同樣邏輯理解了,
等等,圖中實線和虛線的殘差邊有啥區別?先說結論:
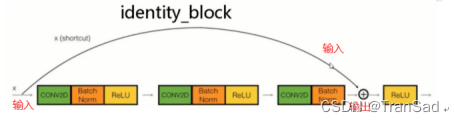
實線的殘差邊,就是直接相連到結果,也就是最簡單最簡單的一條線,對應identity_block;
虛線的殘差邊,其實中間要經過一個1*1的卷積來改變通道數,對應convolution_block,
從stage2開始,每個stage都是先來一個convolution_block,再接若干個identity_block,(如下圖是ResNet網路樣式圖,其中藍色的是convolution_block,紅色的是identity_block)
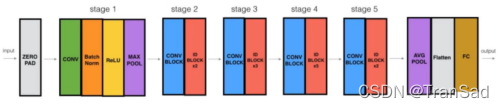
具體來看,為什么在stage的一開始需要一個convolution_block呢?上面說了一個convolution_block的殘差邊是一個1*1的卷積(如下圖),
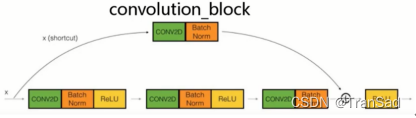
上篇文章整理過1*1卷積的作用,其中一個作用也是在這里的作用就是擴大通道數,為什么要擴大通道數呢?假如說這個convolution_block對應著下圖這里的虛線位置:
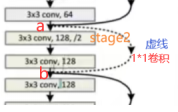
可以發現在a處本來是64個特征圖的,經過了2次3*3、通道數為128的卷積核,到b通道數就變成了128;那么如果從a直接到b的這條殘差邊什么也不做的話,讓64通道直接與128通道相加是不成立的,而如果64通道的特征圖經過了一次1*1卷積,只要卷積核個數為128,就可以實作通道數翻倍從而合理相加了,這就是1*1卷積的作用,在這種通道數翻倍的地方也可以進行殘差邊的應用,而這整體就成為了convolution_block,
而identity_block就很簡單啦(如下圖)就是一條邊,對應著所有實線部分,當輸入輸出的尺寸、通道數前后都沒有變化時,輸入就可以直接加到輸出上,
總之,在整個ResNet網路結構中,從輸入到輸出,就不斷進行著特征圖尺寸縮小以及特征圖數量增加的程序,當特征圖數量增加時,殘差邊就不得不進行1*1的卷積來同樣擴大通道數,從而可以與正常卷積而得到的操作結果的尺寸保持一致,
和NiN網路類似,ResNet最后也使用了全域平均池化,但此時我們不再限制通道數直接等于結果數從而直接經過一個全域平均池化就可以得到結果維數——而是再加上一個全連接層來得到結果,(最后卷積層結果有幾個通道數,比如512,輸入神經元個數就是512;結果有幾維,比如10,輸出層神經元個數就是10)
簡單小結:
這篇文章整理了一下ResNet網路的基本思想和大致結構,提到了一些優勢作用,也區分了一下convolution_block和identity_block的不同之處等,
最后,在ResNet中很多地方都使用了Batch Normal來進行標準化,這個在上面各個程序中一直有意的忽略掉了,Batch Normal主要是用來解決梯度消失和梯度爆炸問題的,可以暫時就當成是一個不會改變尺寸和通道數的處理方式,關于BN展開有點多,以后再作補充,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435426.html
標籤:AI
上一篇:Opencv 基于C++識別綠燈