動手實作深度神經網路2 增加批處理
在上一部分中,我們構造了一個簡單的兩層神將網路,上文中那個網路使用數值微分計算梯度,沒有實作批處理,所以可以認為時不可用的,在著一部分中,批處理將會被實作,
得益于numpy的廣播屬性,我們要實作批處理不難,簡單來說,我們原來的網路中,每次輸入都是一個有784個元素的二維矩陣,而加入我們每次輸入一批資料(例如200條),那輸入就是一個200*784的二維矩陣,
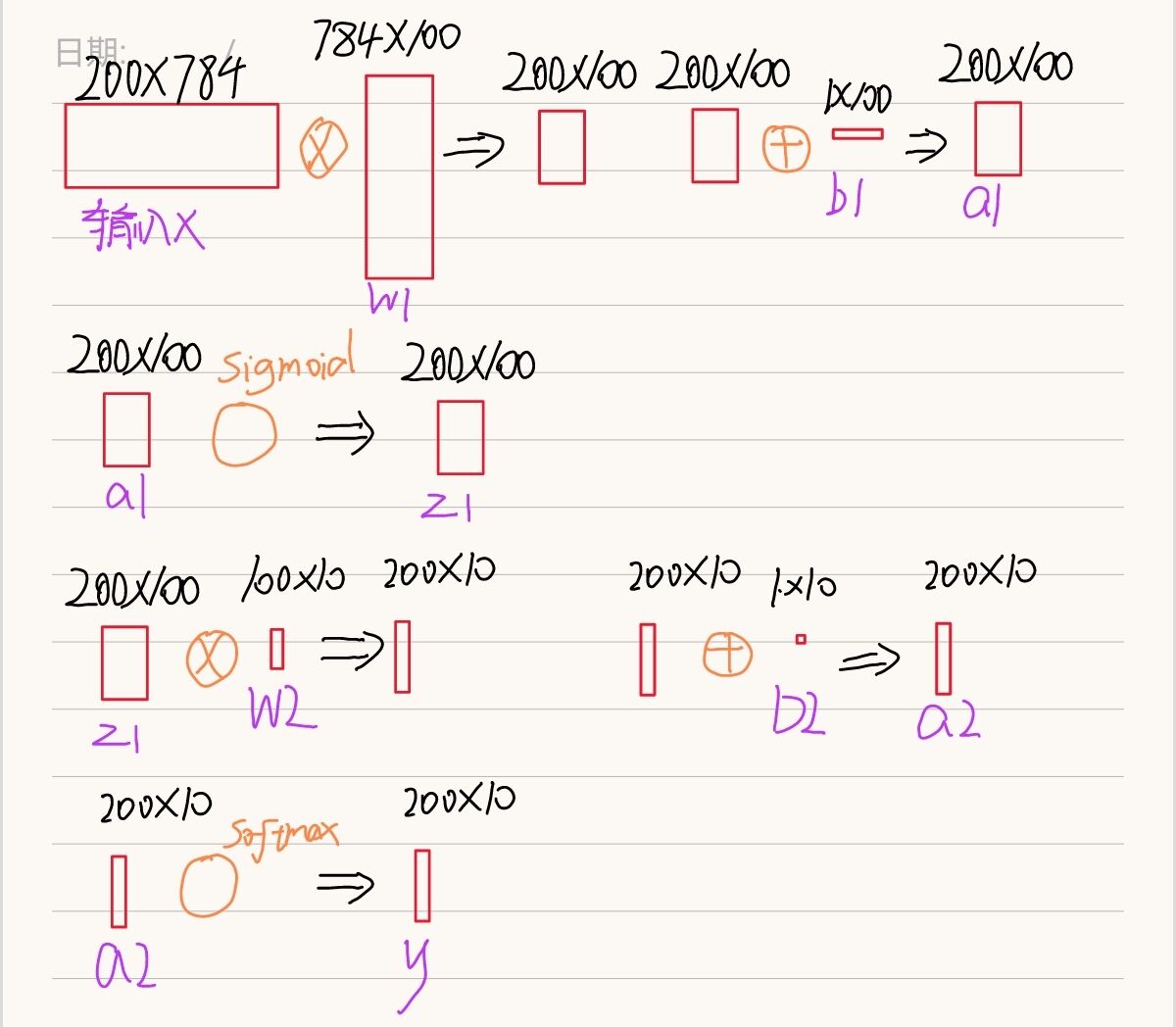
那么我們來看看代碼中有哪些地方需要為批處理的實作做修改
1.對神經網路類的修改
下面是原來實作的神經網路的主要代碼
# 經過兩層運算
def predict(self,x):
# 取出引數
w1,b1=self.params['w1'],self.params['b1']
w2,b2=self.params['w2'],self.params['b2']
a1=np.dot(x,w1)+b1
#一 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
z1=sigmoid(a1)
a2=np.dot(z1,w2)+b2
#一 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
y=softmax(a2)
return y
# 求損失函式值
def loss(self,x,t):
y=self.predict(x)
#二 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
return cross_entropy_error(y,t)
# 求個損失函式值關于各個引數的梯度
def gradient_numerical(self,x,t):
loss_W=lambda w:self.loss(x,t)
grads={}
#三 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
grads['w1'] = numerical_gradient_2d(loss_W, self.params['w1'])
grads['b1'] = numerical_gradient_onenumber(loss_W, self.params['b1'])
grads['w2'] = numerical_gradient_2d(loss_W, self.params['w2'])
grads['b2'] = numerical_gradient_onenumber(loss_W, self.params['b2'])
return grads
# 計算準確率
def accuracy(self, x, t):
y = self.predict(x)
#四 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!
y=np.argmax(y)
t=np.argmax(t)
return y==t
得益于numpy的廣播機制,例如np.dot等操作就不需要修改了,可能需要修改的部分我都已經用感嘆號做了標注,接下來我們一個一個來看看,
1.1 sigmoid和softmax
我們先來看一下之前實作的sigmoid和softmax源代碼
def sigmoid(x):
return 1 / (1 + np.exp(-x))
sigmoid只是簡單的做矩陣運算,不管一維矩陣還是二維矩陣都不影響,所以sigmoid不需要修改,
def softmax(x):
# 這里就需要修改了
max = np.max(x)
x = x - max
return np.exp(x) / np.sum(np.exp(x))
**softmax中涉及到np.max操作這就需要修改了,**因為對二維矩陣做np.max操作只會回傳最大的一個值,而我們需要的是每一條資料中的最大值,
幸好,np.max提供了 axis 引數,具體來說就是對于二維矩陣np.max(x,axis=0)回傳每列的最大值,np.max(x,axis=1)回傳每行的最大值,
a_2d=np.array([[0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.8,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.1,1.5,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06]])
print(np.max(a_2d))
print(np.max(a_2d,axis=0)) #每列的做大值
print(np.max(a_2d,axis=1)) #每行的最大值

那我們接下來來實作二維矩陣的softmax
def softmax(x):
if x.ndim==2:
max = np.max(x,axis=1)
x = x - max
return np.exp(x) / np.sum(np.exp(x),axis=1)
然后我們來測驗一下,
#測驗一下
x=np.array([[0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.8,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.1,1.5,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06]])
softmax(x)
額,,,,,報錯了

原因是max=np.max(x,axis=1)取到的max是一個3元素的一維矩陣,而x是3*10的二維矩陣,他們二者之間無法相減,一個簡單的解決辦法就是把max轉換成3*1的二維矩陣,代碼如下:
max = np.max(x,axis=1)
print(max) # [0.6 0.8 1.5]
max=max.reshape(max.size,1)
print(max) #[[0.6]
# [0.8]
# [1.5]]
我們再試一次:
def softmax(x):
if x.ndim==2:
max = np.max(x,axis=1)
max=max.reshape(max.size,1)
x = x - max
return np.exp(x) / np.sum(np.exp(x),axis=1)
#測驗一下
x=np.array([[0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.8,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.1,1.5,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06]])
softmax(x)
 h
h
還是出問題了,這次是“np.exp(x) / np.sum(np.exp(x),axis=1)”,其實你很快就會發現,這次的錯誤更上次本質上是一樣的:
np.sum(np.exp(x),axis=1) 的結果是一個3元素的一維矩陣 而讓3*10二維矩陣np.exp(x)去除以一個一維矩陣顯然做不到,怎么辦呢?更上面解決辦法一樣,再講=將一維矩陣裝換為二維矩陣就可以了,
不過這樣總感覺非常的麻煩,有沒有一種便捷的方法呢?看下面的代碼:
def softmax(x):
if x.ndim == 2:
x = x.T # 轉置
x = x - np.max(x, axis=0) # 溢位對策
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
#測驗一下
x=np.array([[0.1,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.8,0.05,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06],
[0.1,1.5,0.6,0.05,0.05,0.05,0.01,0.01,0.02,0.06]])
softmax(x)
執行成功了!!
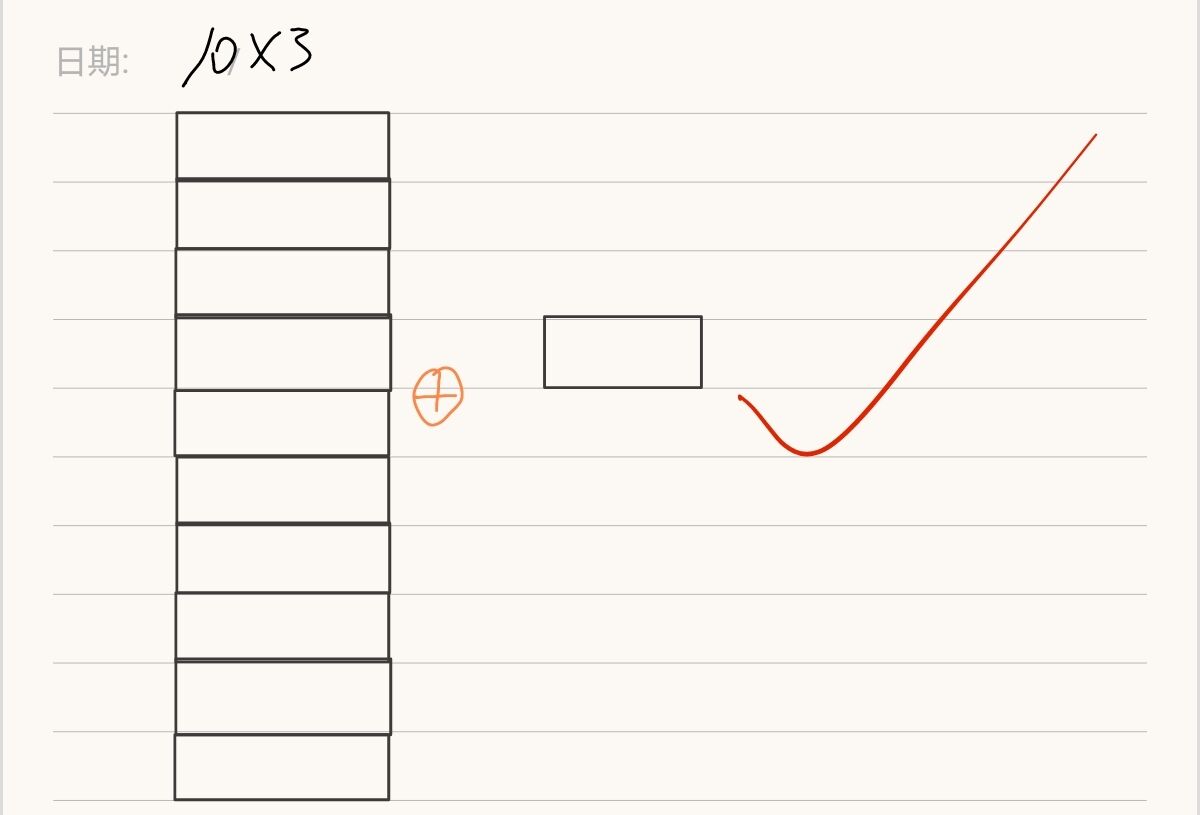
其實,上面的兩個矩陣“不能相減”和“無法相除”都是因為它們的位置對應不上,而將x裝置之后變為10*3的矩陣就可以輕松運算了
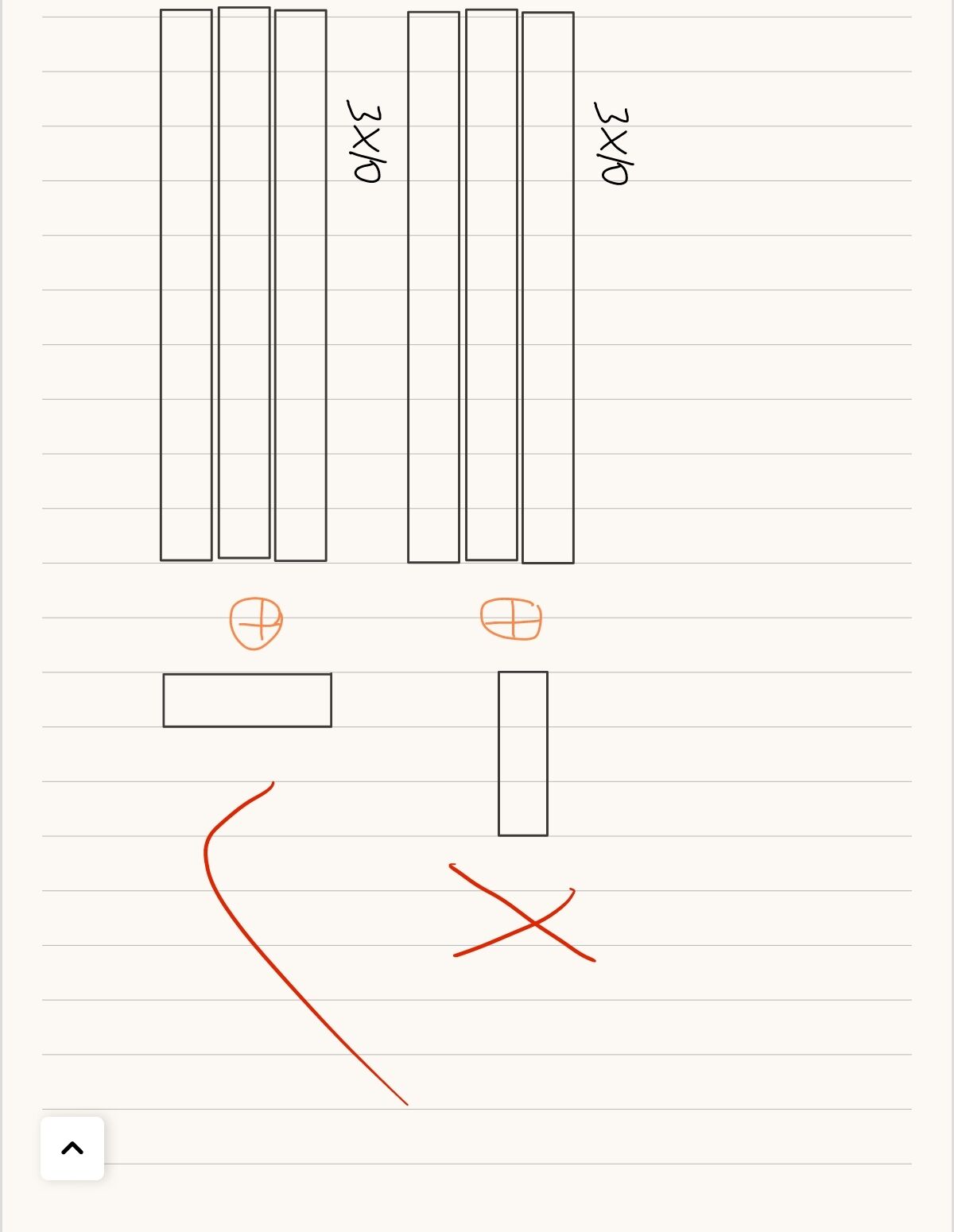
`
好的,二維矩陣softmax解決了,之后我們整理成一個同時支持一維和二維的方法:
def softmax(x):
if x.ndim==1:
x = x - np.max(x) # 溢位對策
return np.exp(x) / np.sum(np.exp(x))
if x.ndim == 2:
x = x.T # 轉置
x = x - np.max(x, axis=0) # 溢位對策
y = np.exp(x) / np.sum(np.exp(x), axis=0)
return y.T
1.2 cross_entropy_error
def cross_entropy_error_batch_1(y, t):
if y.ndim == 1:
# 改變t和y的形狀,使得它們與批處理情況一致 即每批次1條資料
# 一維矩陣變為二維矩陣,統一操作
# t.size-->(1,t.size)
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size
其實還是一維矩陣和二維矩陣的問題,我們這里首先把一維矩陣轉換為二維矩陣,方便之后統一處理,
然后計算一個平均損失函式值,
-np.sum(t * np.log(y + 1e-7)) / batch_size實際上相當于先對每一條資料求損失值,再求平均值,
#-np.sum(t * np.log(y + 1e-7)) / batch_size 相當于
a = -np.sum(t * np.log(y + 1e-7),axis=1)
return np.max(a) / batch_size
交叉熵損失函式現在也完成了批處理的支持啦,我在這里再補充一種情況,那就是“監督資料是標簽形式”,所謂標簽形式就是像“2”“7”這樣的標簽,看下面的表就能輕易理解啦
| 監督資料(表明圖片是幾) | one-hot形式(獨熱編碼) | 標簽形式 |
|---|---|---|
| 1 | [0,1,0,0,0,0,0,0,0,0] | 1 |
| 5 | [0,0,0,0,0,1,0,0,0,0] | 5 |
| (批處理 假設一批3條資料)監督資料 | one-hot形式(獨熱編碼) | 標簽形式 |
|---|---|---|
| [4,2,5] | [ [0,0,0,0,1,0,0,0,0,0] [0,0,1,0,0,0,0,0,0,0] [0,0,0,0,0,1,0,0,0,0] ] | [4,2,5] |
對于“監督資料是標簽形式”我們這樣處理:
# 監督資料是標簽形式(非one-hot表示,而是像“2”“7”這樣的標簽)時
def cross_entropy_error_batch_2(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
假設batch_size=3 假設測驗資料是[4,2,5],那么y[np.arange(batch_size), t]實際上就是 [y[0,4], y[1,2], y[2,5]],也就是y中所有正確解標簽的對應的輸出的自然對數,根據上一篇文章中的推導就知道:交叉熵誤差的值是由正確解標簽所對應的輸出結果決定的,因此可以用這種方法處理“監督資料是標簽形式”的情況,
最后整理成一個包含所有情況的方法:
def cross_entropy_error_batch_all(y, t):
# 把非批處理資料改為批處理資料格式
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
# 如果測驗資料是one-hot格式,將它轉換為標簽形式
if t.size == y.size:
# argmax回傳最大值的索引 例如one-hot下[[0,1,0.....0],[0,0,0.....1]]會轉換為[2,9]
t = t.argmax(axis=1)
batch_size = y.shape[0]
return -np.sum(np.log(y[np.arange(batch_size), t] + 1e-7)) / batch_size
1.3 求梯度
因為在所求的梯度是“損失函式值關于引數的梯度”,所以與輸入的形式無關,所以不需要修改,
1.4 accuracy
計算準確率的方法做一下簡單修改就可以啦
def accuracy(self, x, t):
y = self.predict(x)
y = np.argmax(y, axis=1)
t = np.argmax(t, axis=1)
accuracy = np.sum(y == t) / float(x.shape[0]) # shape回傳形狀 shape[0]行數 shape[1]列數
return accuracy
np.argmax(y, axis=1)回傳每一行中最大值的索引,最后準確率就是 每批次總準確數/每批次總數,2.
2.對網路的使用代碼的修改
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
network=Myself_Two_Layer_Net(input_size=784, hidden_size=50, output_size=10,weight_init_std=0.01)
train_size = x_train.shape[0]
test_size = x_test.shape[0]
learning_rate = 0.1 # 學習率
iters_num = 100 # 適當設定回圈的次數 因為暫時沒有實作自動微分,所以回圈次數太多會很慢
train_size = x_train.shape[0]
batch_size = 100
learning_rate = 0.1
train_loss_list = []
train_acc_list = []
test_acc_list = []
# 二
# 這里說一下epoch,我們說批處理,在深度學習中往往使用minibatch
# epoch是一個單位,一個 epoch表示學習中所有訓練資料均被使用過一次時的更新次數,
# 比如,對于 10000筆訓練資料,用大小為 100筆資料的mini-batch進行學習時,重復隨機梯度下降法 100次,所
# 有的訓練資料就都被“看過”了A,此時,100次就是一個 epoch,
# 因此iter_per_epoch就是訓練資料大小/每一批大小
iter_per_epoch = max(train_size / batch_size, 1)
for i in range(iters_num):
#、一
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 計算梯度
grad = network.gradient_numerical(x_batch, t_batch)
# 更新引數
for key in ('W1', 'b1', 'W2', 'b2'):
network.params[key] -= learning_rate * grad[key]
if i % iter_per_epoch == 0:
train_acc = network.accuracy(x_train, t_train)
test_acc = network.accuracy(x_test, t_test)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
print("train acc, test acc | " + str(train_acc) + ", " + str(test_acc))
# 繪制圖形
markers = {'train': 'o', 'test': 's'}
x = np.arange(len(train_acc_list))
plt.plot(x, train_acc_list, label='train acc')
plt.plot(x, test_acc_list, label='test acc', linestyle='--')
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
plt.legend(loc='lower right')
plt.show()
源代碼中有兩個點需要注意的:
一是np.random.choice(train_size, batch_size)從60000條訓練資料中挑選100條資料出來,np.random.choice回傳的是選中的下標(位置)
batch_mask=np.random.choice(100, 5)
print(batch_mask) # [31 60 43 54 40]
要注意使用隨機選擇的mini batch資料進行梯度下降的方法就叫做隨機梯度下降法(stochastic gradient descent), 深度學習的很多框架中,隨機梯度下降法一般由一個名為SGD的函式來實作,
二是我們說批處理,在深度學習中往往使用的是mini batch方法:神經網路的學習也是從訓練資料中選出一批資料(稱為mini-batch,小 批量),然后對每個mini-batch進行學習,比如,從60000個訓練資料中隨機 選擇100筆,再用這100筆資料進行學習,這種學習方式稱為mini-batch學習,
而epoch是一個單位,一個 epoch表示學習中所有訓練資料均被使用過一次時的更新次數,比如,對于 10000筆訓練資料,用大小為 100筆資料的mini-batch進行學習時,重復隨機梯度下降法 100次,所有的訓練資料就都被“看過”了A,此時,100次就是一個 epoch,
因此iter_per_epoch就是訓練資料大小/每一批大小,而經過iter_per_epoch訓練,可以認為所有訓練資料均被使用過,這時一般會計算一下精確率,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435428.html
標籤:AI
上一篇:ResNet網路 殘差塊的作用