信用卡欺詐檢測
- 1. 資料分析與預處理
- 1.1 資料的讀取與分析
- 1.2 解決樣本不均衡
- 1.3 特征標準化
- 2. 下采樣方案
- 2.1 交叉驗證
- 2.2 模型評估方法
- 2.3 正則化懲罰
- 3. 邏輯回歸模型
- 3.1 引數對結果的影響
- 3.2 混淆矩陣
- 3.3 分類閾值對結果的影響
- 4. 過采樣方案
- 4.1 SMOTE演算法資料生成策略
- 4.2 過采樣應用效果
- 總結
假設有一份信用卡交易記錄,遺憾的是資料經過了脫敏處理,只知道其特征,卻不知道每一個欄位代表什么含義,沒關系,就當作是一個個資料特征,
在資料中有兩種類別,分別是正常交易資料和例外 交易資料,欄位中有明確的識別符號,要做的任務就是建立邏輯回歸模型,以對這兩類資料進行分類,看起來似乎很容易,但實際應用時會出現各種問題等待解決,
熟悉任務目標后,第一個想法可能是直接把資料傳到演算法模型中,得到輸出結果就好了,其實并不是這樣,在機器學習建模任務中,要做的事情還是很多的,包括資料預處理、特征提取、模型調參等, 每一步都會對最終的結果產生影響,既然如此,就要處理好每一步,其中會涉及機器學習中很多細節, 這些都是非常重要的,基本上所有實戰任務都會涉及這些問題,所以大家也可以把這份解決方案當作一 個套路,
1. 資料分析與預處理
我們這里有一份信用卡交易記錄資料,是一個.csv檔案:
里面包含28萬多條資料,規模很大,
1.1 資料的讀取與分析
照常匯入數分三大件:
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
先使用Pandas工具包讀取資料,看一下前五條資料樣例:
data = pd.read_csv("creditcard.csv")
data.head()
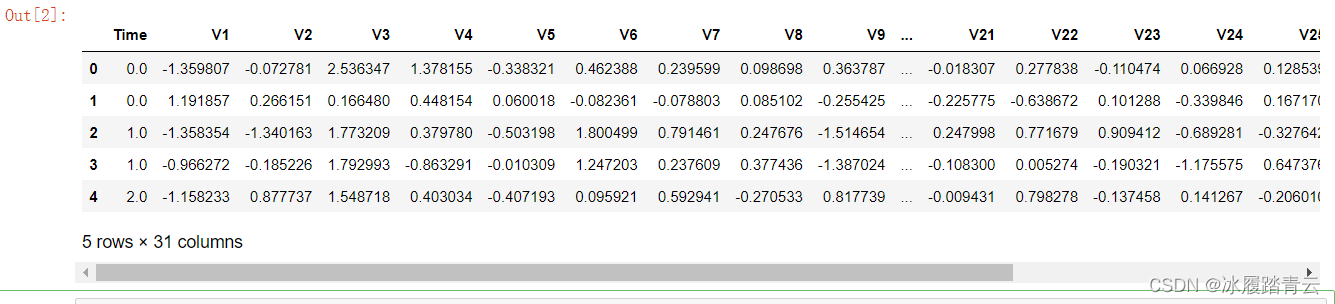
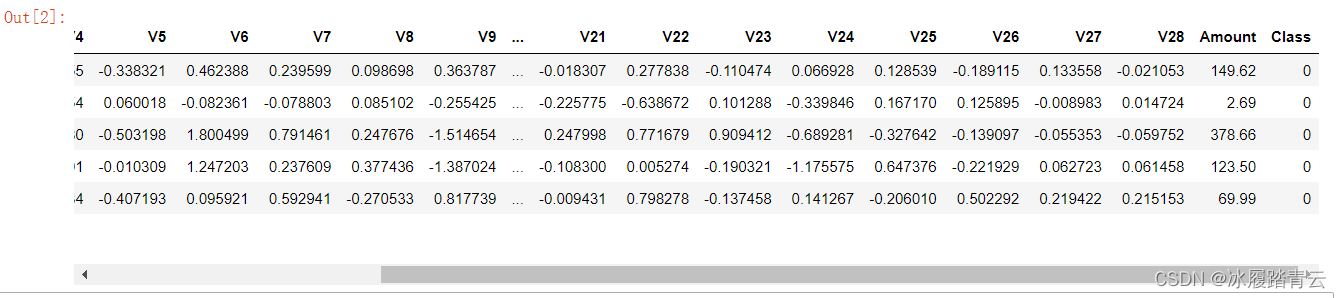
原始資料為個人交易記錄,該資料集總共有31列,其中資料特征有30列,Time列暫時不考慮,Amount串列示貸款的金額,Class串列示分類結果,若Class為0代表該條交易記錄正常,若Class 為1代表交易例外,
拿到這樣一份原始資料之后,直觀感覺可能就是認為資料已經是處理好的特征,只需要對其進行建模任務即可,但是,上述輸出結果只展示了前5條交易記錄并且發現全部是正常交易資料,在實際生活中似乎正常交易也占絕大多數,例外交易僅占一少部分,那么,在整個資料集中,樣本分布是否均衡呢?也就是說,在Class列中,正常資料和例外資料的比例是多少?
我們繪制一份圖表看一下:
count_classes = pd.value_counts(data['Class'], sort = True).sort_index()
count_classes.plot(kind = 'bar')
plt.title("Fraud class histogram")
plt.xlabel("Class")
plt.ylabel("Frequency")
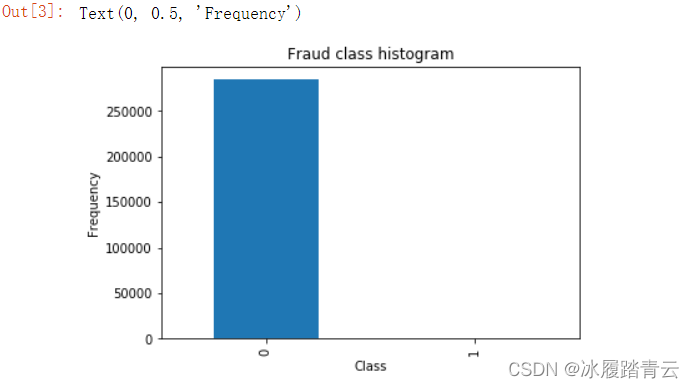
上述代碼首先計算出Class列中各個指標的個數,也就是0和1分別有多少個,為了更直觀地顯示,資料繪制成條形圖,從上圖中可以發現,似乎只有0沒有1,說明資料中絕大多數是正常資料,例外資料極少,
那到底有沒有1這種情況呢?我們查看一下:
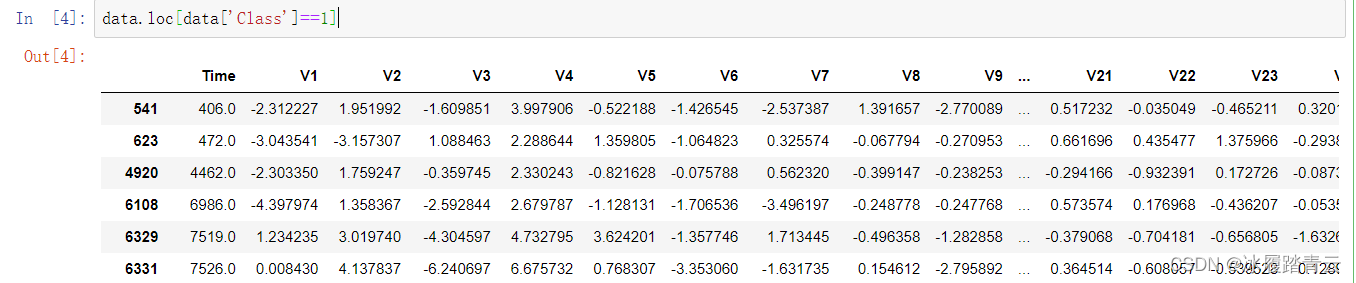
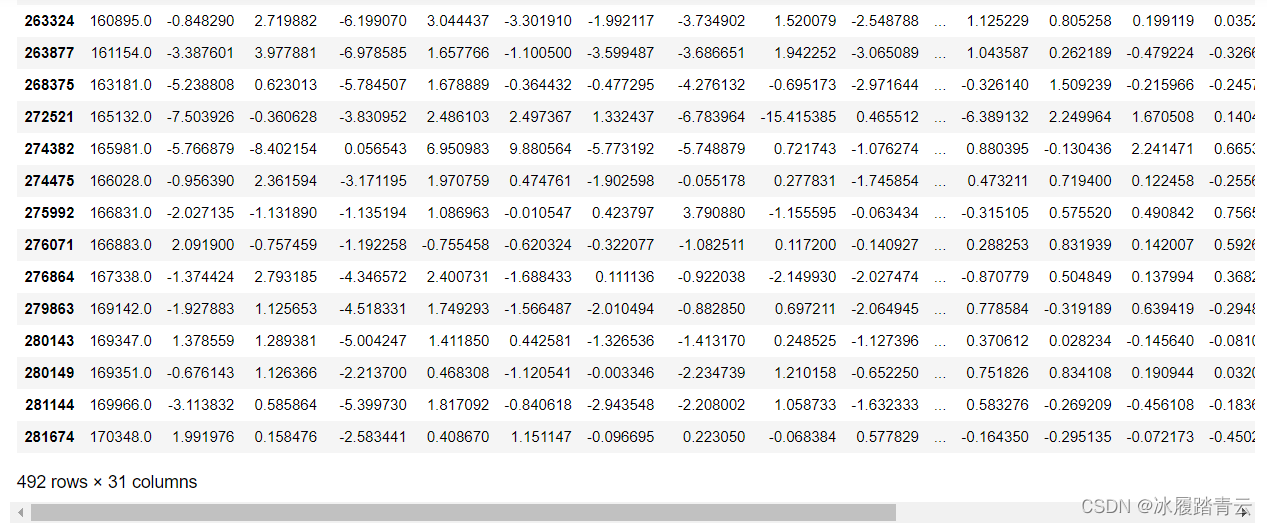
可以看到,實際上是有492條資料是Class為1的情況,492條相對于龐大的28萬條微乎其微,所有我們的柱狀圖幾乎看不到1的柱圖,
這個問題看起來有點嚴峻,資料極度不平衡會對結果造成什么影響呢?模型會不會一邊倒呢?認為所有資料都是正常的,完全不管那些例外的,因為例外資料微乎其微,這種情況出現的可能性很大,
我們的任務目標就是找到例外資料,如果模型不重視例外資料,結果就沒有意義了,所以,首先要做的就是改進不平衡資料,在機器學習任務中,加載資料后,首先應當觀察資料是否存在問題,先把問題處理掉,再考慮特征提取與建模任務,
1.2 解決樣本不均衡
那么,如何解決資料標簽不平衡問題呢?首先,造成資料標簽不平衡的最根本的原因就是它們的個數相差懸殊,如果能讓它們的個數相差不大,或者比例接近,這個問題就解決了,
基于此,提出以下兩種解決方案,
(1)下采樣,
既然例外資料比較少,那就讓正常樣本和例外樣本一樣少,例如正常樣本有30萬個, 例外樣本只有500個,若從正常樣本中隨機選出500個,它們的比例就均衡了,
雖然下采樣的方法看似很簡單,但是也存在瑕疵,即使原始資料很豐富,下采樣過后,只利用了其中一小部分,這樣對結果會不 會有影響呢?
(2)過采樣,
不想放棄任何有價值的資料,只能讓例外樣本和正常樣本一樣多,怎么做到呢?例外樣本若只有500個,此時可以對資料進行變換,假造出來一些例外資料,資料生成也是現階段常見的一種套路,
雖然資料生成解決了例外樣本數量的問題,但是例外資料畢竟是造出來的,會不會存在問題呢? 這兩種方案各有優缺點,到底哪種方案效果更好呢?需要進行實驗比較,
在開始階段,應當多提出各種解決和對比方案,盡可能先把全域規劃制定完整,如果只是 想一步做一步,會做大量重復性操作,降低效率,
1.3 特征標準化
既然已經有了解決方案,是不是應當按照制訂的計劃準備開始建模任務呢?千萬別心急,還差好多步呢,首先要對資料進行預處理,可能大家覺得機器學習的核心就是對資料建模,其實建模只是其中一 部分,通常更多的時間和精力都用于資料處理中,例如資料清洗、特征提取等,這些并不是小的細節, 而是十分重要的核心內容,目的都是使得最終的結果更好,大佬們常說:“資料特征決定結果的上限,而模型的調優只決定如何接近這個上限,”

觀察樣表的資料特征可以發現,Amount列的數值變化幅度很大,而V1~V28列的特征資料的數值都比較小,此 時Amount列的數值相對來說比較大,這會產生什么影響呢?模型對數值是十分敏感的,它不像人類能夠 理解每一個指標的物理含義,可能會認為數值大的資料相對更重要(此處僅是假設),但是在資料中, 并沒有強調Amount列更重要,而是應當同等對待它們,因此需要改善一下,
特征標準化就是希望資料經過處理后得到的每一個特征的數值都在較小范圍內浮動,公式如下:
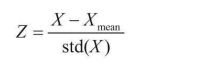
其中,Z為標準化后的資料;X為原始資料;Xmean為原始資料的均值;std(X)為原始資料的標準差,
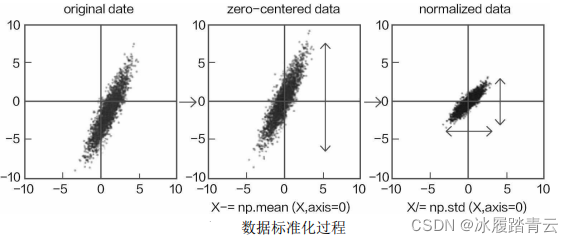
如果把上式的程序進行分解,就會更加清晰明了,首先將資料的各個維度減去其各自的均值, 這樣資料就是以原點為中心對稱,其中數值浮動較大的資料,其標準差也必然更大;數值浮動較小的資料,其標準差也會比較小,再將結果除以各自的標準差,就相當于讓大的資料壓縮到較小的空間中,讓小的資料能夠伸張一些,對于下圖所示的二維資料,就得到其標準化之后的結果,以原點為中心,各個維度的取值范圍基本一致,
接下來,很多資料處理和機器學習建模任務都會用到sklearn工具包,這里先做簡單介紹,該工具包提供了幾乎所有常用的機器學習演算法,僅需一兩行代碼,即可完成建模作業,計算也比較高效,不僅如此,還提供了非常豐富的資料預處理與特征提取模塊,方便大家快速上手處理資料特征,它是Python中非常實用的機器學習建模工具包,在后續的實戰任務中,都會出現它的身影,
sklearn工具包提供了在機器學習中最核心的三大模塊(Classification、Regression、Clustering)的實作方法供大家呼叫,還包括資料降維(Dimensionality reduction)、模型選擇(Model selection)、資料預處理(Preprocessing)等模塊,功能十分豐富,
sklearn工具包還提供了很多實際應用的例子,并且配套相應的代碼與可視化展示方法,簡直就是一 條龍服務,非常適合大家學習與理解,如下圖所示:

sklearn最常用的是其API檔案,如下圖所示,無論執行建模還是預處理任務,都需先熟悉其函式功能再使用,
我接下來使用sklearn工具包來完成特征標準化操作,
StandardScaler API
代碼如下:
from sklearn.preprocessing import StandardScaler
data['normAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1))
data = data.drop(['Time','Amount'],axis=1)
data.head()
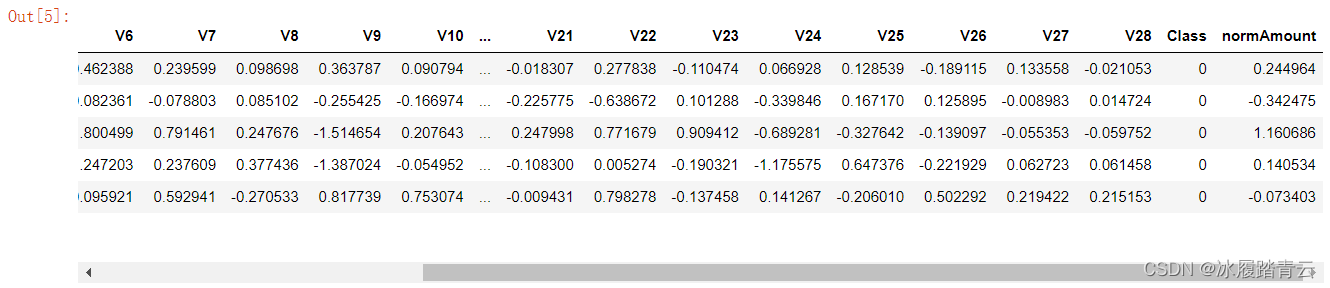
上述代碼使用 StandardScaler方法對資料進行標準化處理,呼叫時需先匯入該模塊,然后進行 fit_transform操作,相當于執行公式
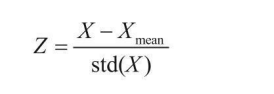
reshape(?1,1)的含義是將傳入資料轉換成一列的形式(需按照函式輸入要求做),最后用drop操作去掉無用特征,上述輸出結果中的normAmount列就是標準化處理后的結果,可見數值都在較小范圍內浮動,
資料預處理程序非常重要,絕大多數任務都需要對特征資料進行標準化操作(或者其他預處理方法,如歸一化等),
2. 下采樣方案
下采樣方案的實作程序比較簡單,只需要對正常樣本進行采樣,得到與例外樣本一樣多的個數即可,代碼如下:
X = data.iloc[:, data.columns != 'Class']
y = data.iloc[:, data.columns == 'Class']
# 得到所有例外樣本的索引
number_records_fraud = len(data[data.Class == 1])
fraud_indices = np.array(data[data.Class == 1].index)
# 得到所有正常樣本的索引
normal_indices = data[data.Class == 0].index
# 在正常樣本中隨機采樣出指定個數的樣本,并取其索引
random_normal_indices = np.random.choice(normal_indices, number_records_fraud, replace = False)
random_normal_indices = np.array(random_normal_indices)
# 有了正常和例外樣本后把它們的索引都拿到手
under_sample_indices = np.concatenate([fraud_indices,random_normal_indices])
# 根據索引得到下采樣所有樣本點
under_sample_data = data.iloc[under_sample_indices,:]
X_undersample = under_sample_data.iloc[:, under_sample_data.columns != 'Class']
y_undersample = under_sample_data.iloc[:, under_sample_data.columns == 'Class']
# 下采樣 樣本比例
print("正常樣本所占整體比例: ", len(under_sample_data[under_sample_data.Class == 0])/len(under_sample_data))
print("例外樣本所占整體比例: ", len(under_sample_data[under_sample_data.Class == 1])/len(under_sample_data))
print("下采樣策略總體樣本數量: ", len(under_sample_data))
輸出結果:

整體流程比較簡單,首先計算例外樣本的個數并取其索引,接下來在正常樣本中隨機選擇指定個數樣本,最后把所有樣本索引拼接在一起即可,上述輸出結果顯示,執行下采樣方案后,一共有984條資料,其中正常樣本和例外樣本各占50%,此時資料滿足平衡標準,
2.1 交叉驗證
得到輸入資料后,接下來劃分資料集,在機器學習中,使用訓練集完成建模后,還需知道這個模型的效果,也就是需要一個測驗集,以幫助完成模型測驗作業,不僅如此,在整個模型訓練程序中,也會涉及一些引數調整,所以,還需要驗證集,幫助模型進行引數的調整與選擇,
突然出現很多種集合,感覺很容易弄混,再來總結一下:

首先把資料分成兩部分,左邊是訓練集,右邊是測驗集,如上圖所示,訓練集用于建立模型,例如以梯度下降來迭代優化,這里需要的資料就是由訓練集提供的,測驗集是當所有建模作業都完成后使用的,需要強調一點,測驗集十分寶貴,在建模的程序中,不能加入任何與測驗集有關的資訊,否則就相當于透題,評估結果就不會準確,可以自己設定訓練集和測驗集的大小和比例,8︰2、9︰1都是常見的切分比例,
接下來需要對資料集再進行處理,如下圖所示,可以發現測驗集沒有任何變化,僅把訓練集劃分成很多份,這樣做的目的在于,建模嘗試程序中,需要調整各種可能影響結果的引數,因此需要知道每一 種引數方案的效果,但是這里不能用測驗集,因為建模任務還沒有全部完成,所以驗證集就是在建模程序中評估引數用的,那么單獨在訓練集中找出來一份做驗證集(例如fold5)不就可以了嗎,為什么要劃分出來這么多小份呢?

在這個實戰任務中,涉及非常多的細節知識點,這些知識點是通用的,任何實戰都能用 上,如果只是單獨找出來一份,恰好這一份資料比較簡單,那么最終的結果可能會偏高;如果選出來的這一份里面有一些錯誤點或者離群點,得到的結果可能就會偏低,無論哪種情況,評估結果都會出現一 定偏差,為了解決這個問題,可以把訓練集切分成多份,例如將訓練集分成10份,如下圖所示: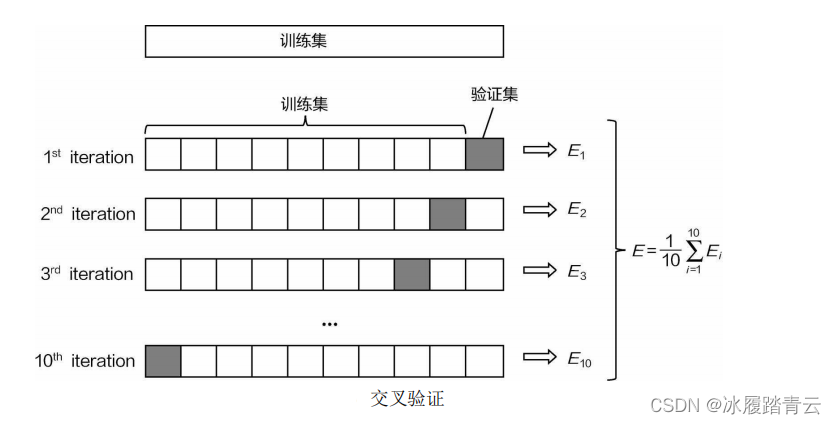
在驗證某一 次結果時,需要把整個程序分成10步,第一步用前9份當作訓練集,最后一份當作驗證集,得到一個結果,以此類推,每次都依次用另外一份當作驗證集,其他部分當作訓練集,這樣經過10步之后,就得到 10個結果,每個結果分別對應其中每一小份,組合在一起恰好包含原始訓練集中所有資料,再對最終得 到的10個結果進行平均,就得到最終模型評估的結果,這個程序就叫作交叉驗證,
交叉驗證看起來有些復雜,但是能對模型進行更好的評估,使得結果更準確,從后續的實驗中,大家會發現,用不同驗證集評估的時候,結果差異很大,所以這個套路是必須要做的,
在sklearn工具包 中,已經實作好資料集切分的功能,這里需先將資料集劃分成訓練集和測驗集,切分驗證集的作業等到建模的時候再做也來得及,代碼如下:
#from sklearn.cross_validation import train_test_split
# 在sklearn 0.18及以上的版本中,cross_validation包已經被廢棄,
from sklearn.model_selection import train_test_split
# 整個資料集進行劃分
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)
print("原始訓練集包含樣本數量: ", len(X_train))
print("原始測驗集包含樣本數量: ", len(X_test))
print("原始樣本總數: ", len(X_train)+len(X_test))
# 下采樣資料集進行劃分
X_train_undersample, X_test_undersample, y_train_undersample, y_test_undersample = train_test_split(X_undersample
,y_undersample
,test_size = 0.3
,random_state = 0)
print("")
print("下采樣訓練集包含樣本數量: ", len(X_train_undersample))
print("下采樣測驗集包含樣本數量: ", len(X_test_undersample))
print("下采樣樣本總數: ", len(X_train_undersample)+len(X_test_undersample))
輸出結果如下:

通過輸出結果可以發現,在切分資料集時做了兩件事:首先對原始資料集進行劃分,然后對下采樣資料集進行劃分,我們最初的目標不是要用下采樣資料集建模嗎,為什么又對原始資料進行切分操作呢?這里先留一個伏筆,后續將慢慢揭曉,
2.2 模型評估方法
接下來還沒到實際建模任務,還需要考慮模型的評估方法,為什么建模之前要考慮整個程序呢?因為建模是一個程序,需要優先考慮如何評估其價值,而不是僅僅提供一堆模型引數值,
準確率是分類問題中最常使用的一個引數,用于說明在整體中做對了多少,下面舉一個與這份資料集相似的例子:醫院中有1000個病人,其中10個患癌,990個沒有患癌,需要建立一個模型來區分他們, 假設模型認為病人都沒有患癌,只有10個人分類有錯,因此得到的準確率高達990/1000,也就是0.99,看起來是十分不錯的結果,但是建模的目的是找出患有癌癥的病人,即使一個都沒找到,準確率也很高, 這說明對于不同的問題,需要指定特定的評估標準,因為不同的評估方法會產生非常大的差異,
選擇合適的評估方法非常重要,因為評估方法是為整個實驗提供決策的服務的,所以一定 要基于實際任務與資料集進行選擇,
在這個問題中,癌癥患者與非癌癥患者人數比例十分不均衡,那么,該如何建模呢?既然已經明確建模的目標是為了檢測到癌癥患者(例外樣本),應當把關注點放在他們身上,可以考慮模型在例外樣本中檢測到多少個,對于上述問題來說,一個癌癥病人都沒檢測到,意味著召回率(Recall)為0,
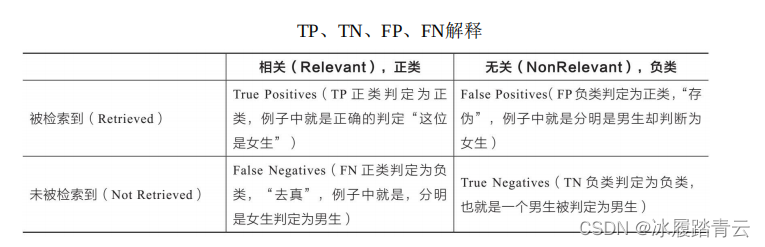
這里提到了召回率,先通俗理解一下:就是觀察給定目標,針對這個目標統計你取得了多大成績,而不是針對整體而言, 如果直接給出計算公式,理解起來可能有點吃力,現在先來解釋一下在機器學習以及資料科學領域中常用的名詞,理解了這些名詞,就很容易理解這些評估方法, 下面還是由一個問題來引入,假如某個班級有男生80人,女生20人,共計100人,目標是找出所有女生,現在某次實驗挑選出50個人,其中20人是女生,另外還錯誤地把30個男生也當作女生挑選出來(這里把女生當作正例,男生當作負例),
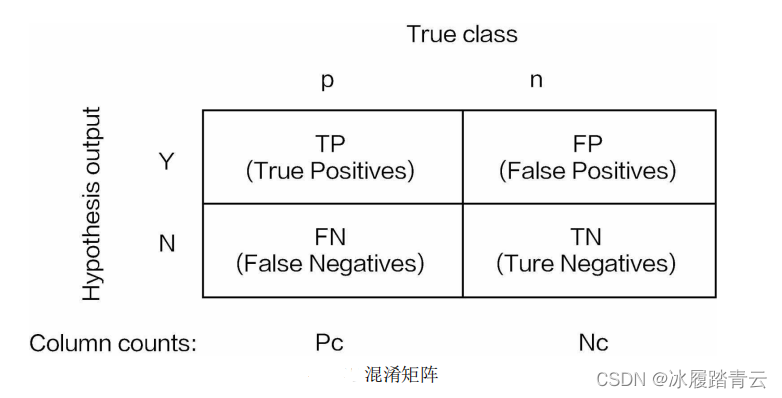
下表列出了TP、TN、FP、FN四個關鍵詞的解釋,這里告訴大家一個竅門,不需要死記硬背,從詞表面的意思上也可以理解它們:
(1)TP
首先,第一個詞是True,這就表明模型預測結果正確,再看Positive,指預測成正例,組 合在一起就是首先模型預測正確,即將正例預測成正例,回傳來看題目,選出來的50人中有20個是女 生,那么TP值就是20,這20個女生被當作女生選出來,
(2)FP
FP表明模型預測結果錯誤,并且被當作Positive(也就是正例),在題目中,就是錯把男 生當作女生選出來,在這里目標是選女生,選出來的50人中有30個卻是男的,因此FP等于30,
(3)FN
同理,首先預測結果錯誤,并且被當作負例,也就是把女生錯當作男生選出來,題中并沒有這個現象,所以FN等于0,
(4)TN
預測結果正確,但把負例當作負例,將男生當作男生選出來,題中有100人,選出認為是女生的50人,剩下的就是男生了,所以TN等于50,
上述評估分析中常見的4個指標只需要掌握其含義即可,下面來看看通過這4個指標能得出什么結 論,
?準確率(Accuracy):表示在分類問題中,做對的占總體的百分比,
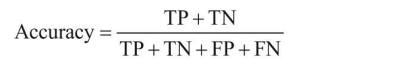
?召回率(Recall):表示在正例中有多少能預測到,覆寫面的大小,
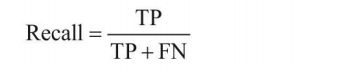
?精確度(Precision):表示被分為正例中實際為正例的比例,

上面介紹了3種比較常見的評估指標,下面回到信用卡分類問題,想一想在這份檢測任務中,應當使用哪一個評估指標呢?由于目的是查看有多少例外樣本能被檢測出來,所以應當使用召回率進行模型評估,
2.3 正則化懲罰
正則化懲罰,這個名字看起來有點別扭,好好的模型為什么要懲罰呢?
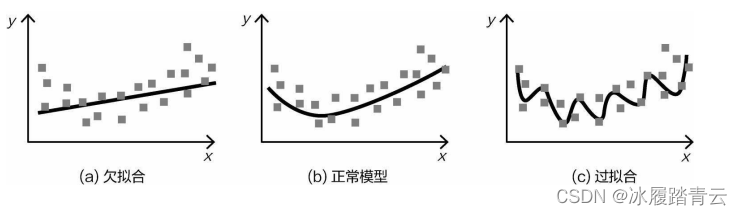
先來解釋一 下過擬合的含義,建模的出發點就是盡可能多地滿足樣本資料,在圖(a)中直線看起來有點簡單,沒有滿足大部分資料樣本點,這種情況就是欠擬合,究其原因,可能由于模型本身過于簡單所導致,再來看圖(b),比圖(a)所示模型稍微復雜些,可以滿足大多數樣本點,這是一個比較不錯的模型,但是通過觀察可以發現,還是沒有抓住所有樣本點,這只是一個大致輪廓,那么如果能把模型做得更復雜,豈不是更好?再來看圖(c),這是一個非常復雜的回歸模型,竟然把所有樣本點都抓到 了,給人的第一感覺是模型十分強大,但是也會存在一個問題—模型是在訓練集上得到的,測驗集與訓 練集卻不完全一樣,一旦進行測驗,效果可能不盡如人意,
在機器學習中,通常都是先用簡單的模型進行嘗試,如果達不到要求,再做復雜一點的,而不是先用最復雜的模型來做,雖然訓練集的準確度可以達到99%甚至更高,但是實際應用的效果卻很差,這就是過擬合,
我們在機器學習任務中經常會遇到過擬合現象,最常見的情況就是隨著模型復雜程度的提升,訓練集效果越來越好,但是測驗集效果反而越來越差,如下圖所示:
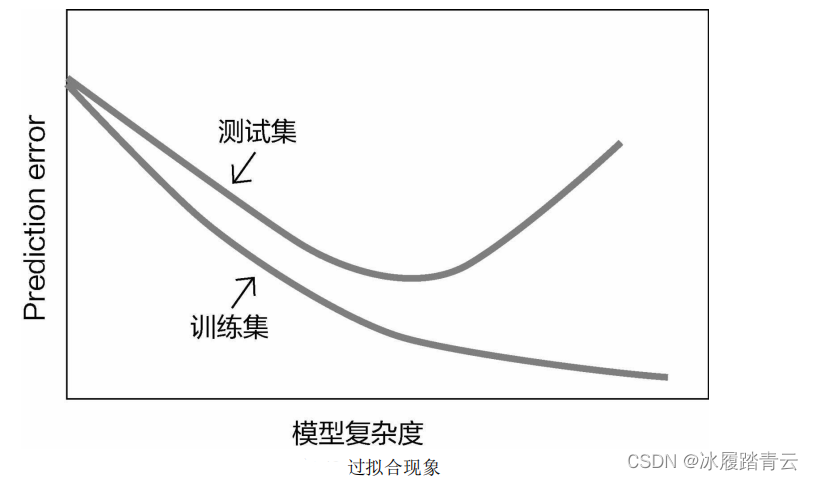
對于同一演算法來說,模型的復雜程度由誰來控制呢?當然就是其中要求解的引數(例如梯度下降中優化的引數),如果在訓練集上得到的引數值忽高忽低,就很可能導致過擬合,所以正則化懲罰就是為解決過擬合準備的,即懲罰數值較大的權重引數,讓它們對結果的影響小一點,
還是舉一個例子來看看其作用,假設有一條樣本資料是x:[1,1,1,1],現在有兩個模型:
?θ1:[1,0,0,0]
?θ2:[0.25,0.25,0.25,0.25]
可以發現,模型引數θ1、θ2與資料x組合之后的結果都為1(也就是對應位置相乘求和的結果),這是不是意味著兩個模型的效果相同呢?再觀察發現,兩個引數本身有著很大的差異,θ1只有第一個位置有值,相當于只注重資料中第一個特征,其他特征完全不考慮;而θ2會同等對待資料中的所有特征,雖然 它們的結果相同,但是,如果讓大家來選擇,大概都會選擇第二個,因為它比較均衡,沒有那么絕對,
在實際建模中,通常要選擇泛化能力更強的也就是都趨于穩定的權重引數,那么如何把控引數呢?此時就需要一個懲罰項,懲罰項會與目標函陣列合在 一起,讓模型在迭代程序中就開始重視這個問題,而不是建模完成后再來調整,常見的有L1和L2正則化懲罰項:
-
L1正則化:
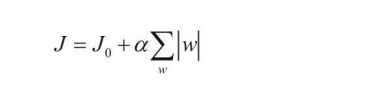
-
L2正則化:
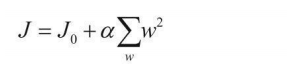
兩種正則化懲罰方法都對權重引數進行了處理,既然加到目標函式中,目的就是不讓個別權重太大,以致對區域產生較大影響,也就是過擬合的結果,在L1正則化中可以對|w|求累加和,但是只直接計算絕對值求累加和的話,例如上述例子中θ1和θ2的結果仍然相同,都等于1,并沒有作出區分,這時候L2 正則化就登場了,它的懲罰力度更大,對權重引數求平方和,目的就是讓大的更大,相對懲罰也更多, θ1的L2懲罰為1,θ2的L2懲罰只有0.25,表明θ1帶來的損失更大,在模型效果一致的前提下,當然選擇整體效果更優的θ2組模型,
在懲罰項的前面還有一個α系數,它表示正則化懲罰的力度,以一種極端情況舉例說明:如果α值比較大,意味著要非常嚴格地對待權重引數,此時正則化懲罰的結果會對整體目標函式產生較大影響,如果α值較小,意味著懲罰的力度較小,不會對結果產生太大影響,
最終結果的定論是由測驗集決定的,訓練集上的效果僅供參考,因為過擬合現象十分常見,
3. 邏輯回歸模型
歷盡千辛萬苦,現在終于到建模的時候了,這里需要把上面考慮的所有內容都結合在一起,再用工具包建立一個基礎模型就非常簡單,難點在于怎樣得到最優的結果,其中每一環節都會對結果產生不同的影響,
3.1 引數對結果的影響
在邏輯回歸演算法中,涉及的引數比較少,這里僅對正則化懲罰力度進行調參實驗,為了對比分析交叉驗證的效果,對不同驗證集分別進行建模與評估分析,代碼如下:
#Recall = TP/(TP+FN)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
from sklearn.model_selection import cross_val_predict
def printing_Kfold_scores(x_train_data,y_train_data):
fold = KFold(5,shuffle=False)
# 定義不同力度的正則化懲罰力度
c_param_range = [0.01,0.1,1,10,100]
# 展示結果用的表格
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
# k-fold 表示K折的交叉驗證,這里會得到兩個索引集合: 訓練集 = indices[0], 驗證集 = indices[1]
j = 0
#回圈遍歷不同的引數
for c_param in c_param_range:
print('-------------------------------------------')
print('正則化懲罰力度: ', c_param)
print('-------------------------------------------')
print('')
recall_accs = []
#一步步分解來執行交叉驗證
for iteration, indices in enumerate(fold.split(y_train_data),start=1):
# 指定演算法模型,并且給定引數
lr = LogisticRegression(C = c_param, penalty = 'l1',solver='liblinear')
# 訓練模型,注意索引不要給錯了,訓練的時候一定傳入的是訓練集,所以X和Y的索引都是0
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
# 建立好模型后,預測模型結果,這里用的就是驗證集,索引為1
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
# 有了預測結果之后就可以來進行評估了,這里recall_score需要傳入預測值和真實值,
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
# 一會還要算平均,所以把每一步的結果都先保存起來,
recall_accs.append(recall_acc)
print('Iteration ', iteration,': 召回率 = ', recall_acc)
# 當執行完所有的交叉驗證后,計算平均結果
results_table.loc[j,'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('平均召回率 ', np.mean(recall_accs))
print('')
#找到最好的引數,哪一個Recall高,自然就是最好的了,
best_c = results_table.loc[results_table['Mean recall score'].astype('float32').idxmax()]['C_parameter']
# 列印最好的結果
print('*********************************************************************************')
print('效果最好的模型所選引數 = ', best_c)
print('*********************************************************************************')
return best_c
上述代碼中,KFold用于選擇交叉驗證的折數,這里選擇5折,即把訓練集平均分成5份,c_param是 正則化懲罰的力度,也就是正則化懲罰公式中的a,為了觀察不同懲罰力度對結果的影響,在建模的時 候,嵌套兩層for回圈,首先選擇不同的懲罰力度引數,然后對于每一個引數都進行5折的交叉驗證,最后得到其驗證集的召回率結果,
在sklearn工具包中,所有演算法的建模呼叫方法都是類似的,首先選擇需要的演算法模型,然后.fit()傳入實際資料進行迭代,最后用.predict()進行預測,
傳入資料看一下效果:
best_c = printing_Kfold_scores(X_train_undersample,y_train_undersample)
輸出結果:


先來單獨看正則化懲罰的力度C為0.01時,通過交叉驗證分別得到5 次實驗結果,可以發現,即便在相同引數的情況下,交叉驗證結果的差異還是很大,其值在0.93~1.0之間浮動,但是千萬別小看這幾個百分點,建模都是圍繞著一步步小的提升逐步優化的,所以交叉驗證非常有必要,
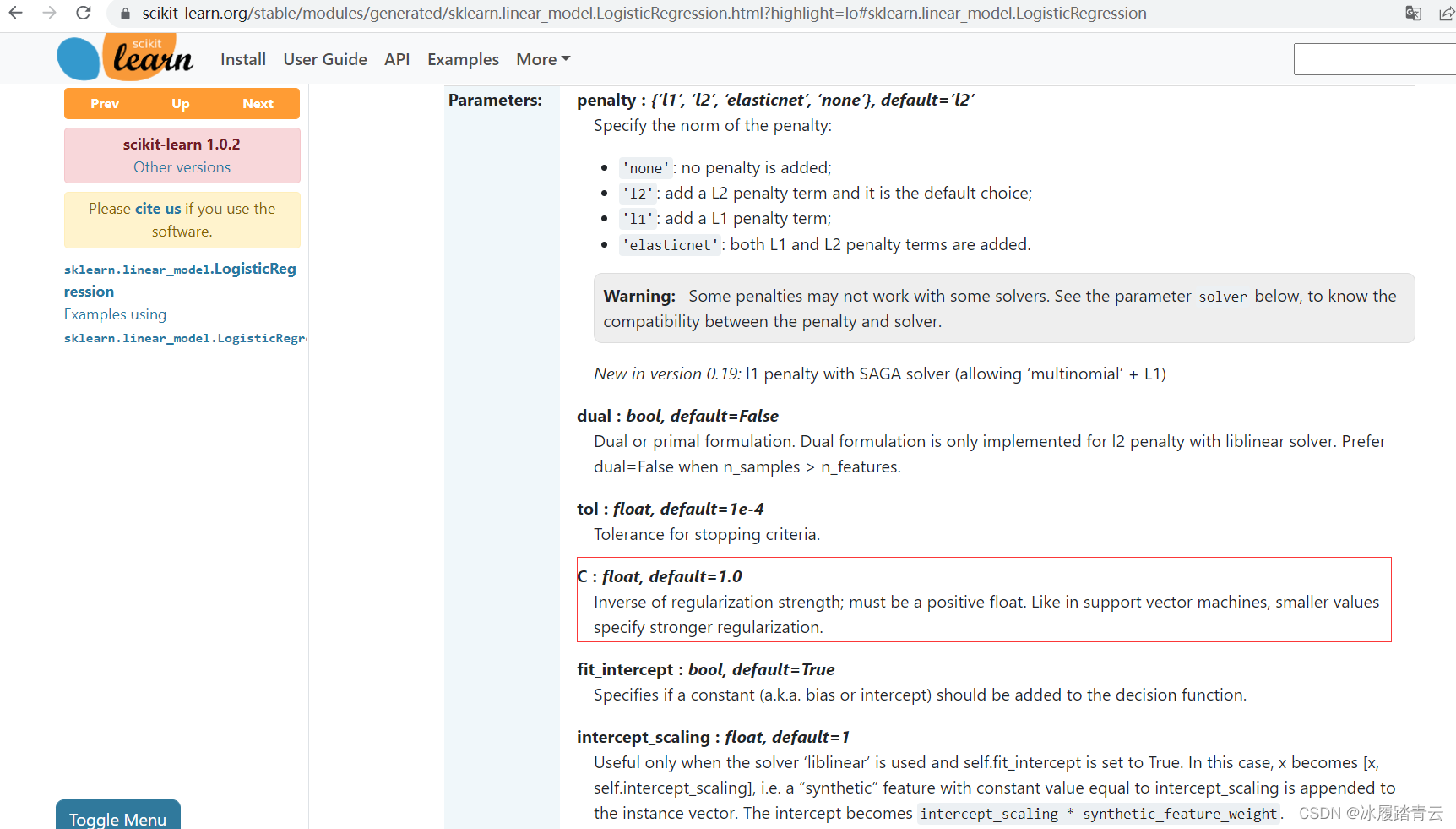
在sklearn工具包中,C引數的意義正好是倒過來的,例如C=0.01表示正則化力度比較大,而C=100則 表示力度比較小,看起來有點像陷阱,但既然工具包這樣定義了,咱們就照做就行了,所以一定要參考其API檔案:
再來對比分析不同引數得到的結果,直接觀察交叉驗證最后的平均召回率值就可以,不同引數的情 況下,得到的結果各不相同,差異還是存在的,所以在建模的時候調參必不可少,可能大家都覺得應該 按照經驗值去做,但更多的時候經驗值只能提供一個大致的方向,具體的探索還是通過大量的實驗進 行分析,
現在已經完成建模和基本的調參任務,只看這個90%左右的結果,感徑訓不錯,但是如果想知道模 型的具體表現,需要再深入分析,
3.2 混淆矩陣
預測結果明確之后,還可以更直觀地進行展示,這時候混淆矩陣就派上用場了,
混淆矩陣中用到的指標值前面已經解釋過,既然已經訓練好模型,就可以展示其結果,這里用到 Matplotlib工具包,大家可以把下面的代碼當成一個混淆矩陣模板,用的時候只需傳入自己的資料即可:
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
繪制混淆矩陣
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
定義好混淆矩陣的畫法之后,需要傳入實際預測結果,呼叫之前的邏輯回歸模型,得到測驗結果, 再把資料的真實標簽值傳進去即可:
import itertools
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample = lr.predict(X_test_undersample.values)
# 計算所需值
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 繪制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
輸出結果:
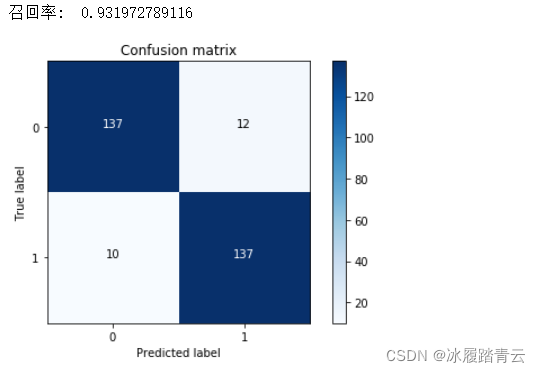
在這份資料集中,目標任務是二分類,所以只有0和1,主對角線上的值就是預測值和真實值一致的情況,深色區域代表模型預測正確(真實值和預測值一致),其余位置代表預測錯誤,數值10代表有10 個樣本資料本來是例外的,模型卻將它預測成為正常,相當于“漏檢”,數值12代表有12個樣本資料本來是正常的,卻把它當成例外的識別出來,相當于“誤殺”,
最終得到的召回率值約為0.9319,看起來是一個還不錯的指標,但是還有沒有問題呢?用下采樣的資料集進行建模,并且測驗集也是下采樣的測驗集,在這份測驗集中,例外樣本和正常樣本的比例基本均衡,因為已經對資料集進行過處理,但是實際的資料集并不是這樣的,相當于在測驗時用理想情況來代替真實情況,這樣的檢測效果可能會偏高,所以值得注意的是,在測驗的時候,需要使用原始資料的測驗集,才能最具代表性,只需要改變傳入的測驗資料即可,代碼如下:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred = lr.predict(X_test.values)
# 計算所需值
cnf_matrix = confusion_matrix(y_test,y_pred)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 繪制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
輸出結果:
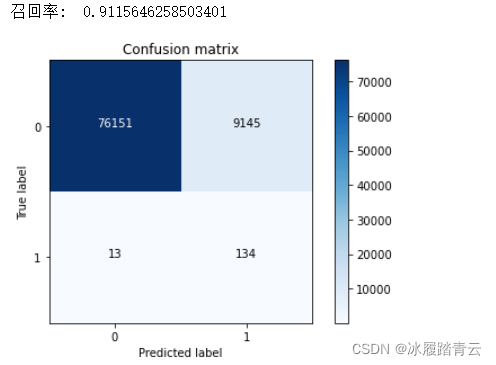
還記得在切分資料集的時候,我們做了兩手準備嗎?不僅對下采樣資料集進行切分,而且對原始資料集也進行了切分,這時候就派上用場了,得到的召回率值為0.925,雖然有所下降,但是整體來說還是可以的,
在實際的測驗中,不僅需要考慮評估方法,還要注重實際應用情況,再深入混淆矩陣中,看看還有 哪些實際問題,上圖中左下角的數值為13,看起來沒有問題,說明有13個漏檢的,但是,右上角有一個數字格外顯眼——9145,意味著有9145個樣本被誤殺,好像之前用下采樣資料集進行測驗的時候沒有注意到這一點,因為只有20個樣本被誤殺,但是,在實際的測驗集中卻出現了這樣的事:整個測驗集一共只有100多個例外樣本,模型卻誤殺掉9145個,有點夸張了,根據實際業務需求,后續肯定要對檢測出來的例外樣本做一些處理,比如凍結賬號、電話詢問等,如果誤殺掉這么多樣本,實際業務也會出現問題,
在測驗中還需綜合考慮,不僅要看模型具體的指標值(例如召回率、精度等),還需要從實際問題角度評估模型到底可不可取, 問題已經很嚴峻,模型現在出現了大問題,該如何改進呢?是對模型調整引數,不斷優化演算法呢? 還是在資料層面做一些處理呢?一般情況下,建議大家先從資料下手,因為對資料做變換要比優化演算法模型更容易,得到的效果也更突出,不要忘了之前提出的兩種方案,而且過采樣方案還沒有嘗試,會不會發生一些變化呢?下面就來揭曉答案,
3.3 分類閾值對結果的影響
回想一下邏輯回歸演算法原理,通過Sigmoid函式將得分值轉換成概率值,那么,怎么得到具體的分類結果呢?默認情況下,模型都是以0.5為界限來劃分類別:
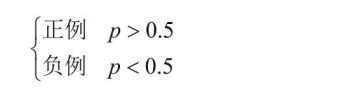
可以說0.5是一個經驗值,但是并不是固定不變的,實踐時可以根據自己的標準來指定該閾值大小, 如果閾值設定得大一些,相當于要求變得嚴格,只有非常例外的樣本才能當作例外;如果閾值設定得比較小,相當于寧肯錯殺也不肯放過,只要有一點例外就通通抓起來,
在sklearn工具包中既可以用.predict()函式得到分類結果,相當于以0.5為默認閾值,也可以 用.predict_proba()函式得到其概率值,而不進行類別判斷,
咱們可以先看一下如果不對資料進行處理,對原始資料直接建模結果:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(X_train,y_train.values.ravel())
y_pred_undersample = lr.predict(X_test.values)
# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test,y_pred_undersample)
np.set_printoptions(precision=2)
print("Recall metric in the testing dataset: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# Plot non-normalized confusion matrix
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
結果:
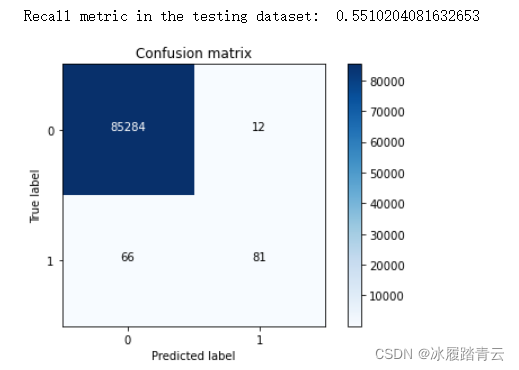
召回率偏低,結果顯然不如我們之前做下采樣資料處理效果好,
再看一下閾值對結果的影響:
# 用之前最好的引數來進行建模
lr = LogisticRegression(C = 0.01, penalty = 'l1',solver='liblinear')
# 訓練模型,還是用下采樣的資料集
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
# 得到預測結果的概率值
y_pred_undersample_proba = lr.predict_proba(X_test_undersample.values)
#指定不同的閾值
thresholds = [0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9]
plt.figure(figsize=(10,10))
j = 1
# 用混淆矩陣來進行展示
for i in thresholds:
y_test_predictions_high_recall = y_pred_undersample_proba[:,1] > i
plt.subplot(3,3,j)
j += 1
cnf_matrix = confusion_matrix(y_test_undersample,y_test_predictions_high_recall)
np.set_printoptions(precision=2)
print("給定閾值為:",i,"時測驗集召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
class_names = [0,1]
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Threshold >= %s'%i)
輸出結果:

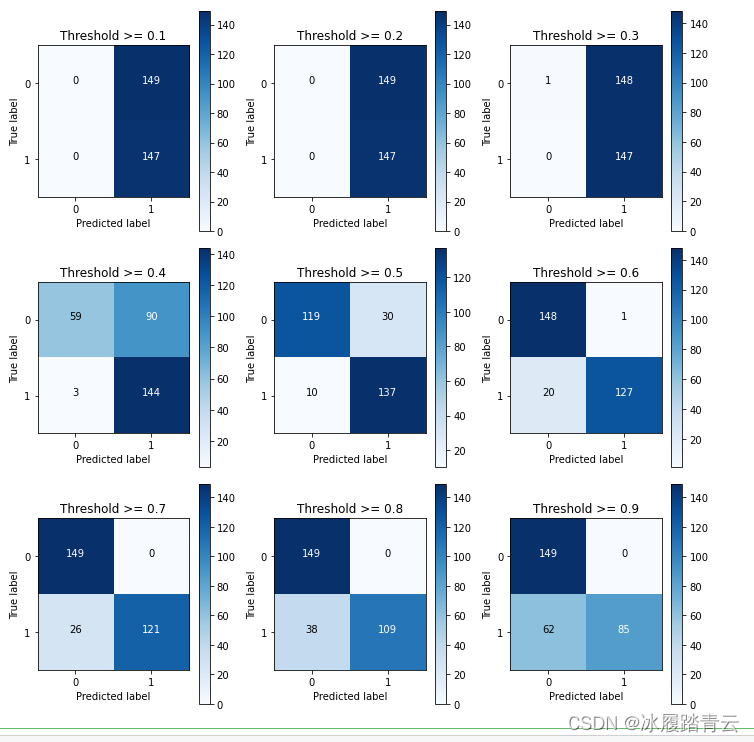
代碼中設定0.1~0.9多個閾值,并且確保每一次建模都使用相同的引數,將得到的概率值與給定閾值進行比較來完成分類任務, 現在觀察一下輸出結果,當閾值比較小的時候,可以發現召回率指標非常高,第一個子圖竟然把所有樣本都當作例外的,但是誤殺率也是很高的,實際意義并不大,隨著閾值的增加,召回率逐漸下降, 也就是漏檢的逐步增多,而誤殺的慢慢減少,這是正常現象,當閾值趨于中間范圍時,看起來各有優缺點,當閾值等于0.5時,召回率偏高,但是誤殺的樣本個數有點多,當閾值等于0.6時,召回率有所下降, 但是誤殺樣本數量明顯減少,那么,究竟選擇哪一個閾值比較合適呢?這就需要從實際業務的角度出發,看一看實際問題中,到底需要模型更符合哪一個標準,
4. 過采樣方案
在下采樣方案中,雖然得到較高的召回率,但是誤殺的樣本數量實在太多了,下面就來看看用過采樣方案能否解決這個問題,
4.1 SMOTE演算法資料生成策略
如何才能讓例外樣本與正常樣本一樣多呢?這里需要對少數樣本進行生成,這可不是復制粘貼,一 模一樣的樣本是沒有用的,需要采用一些策略,最常用的就是SMOTE演算法(見下圖),
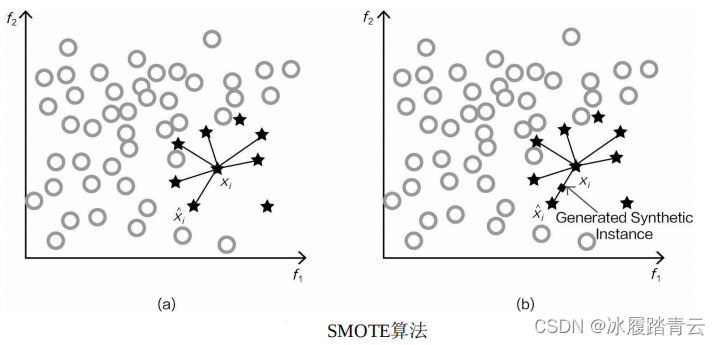
其流程如下:
第①步:對于少數類中每一個樣本x,以歐式距離為標準,計算它到少數類樣本集中所有樣本的距離,經過排序,得到其近鄰樣本,
第②步:根據樣本不平衡比例設定一個采樣倍率N,對于每一個少數樣本x,從其近鄰開始依次選擇N 個樣本,
第③步:對于每一個選出的近鄰樣本,分別與原樣本按照如下的公式構建新的樣本資料,
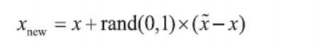
總結一下:對于每一個例外樣本,首先找到離其最近的同類樣本,然后在它們之間的距離上,取0~1中的一個隨機小數作為比例,再加到原始資料點上,就得到新的例外樣本,
對于SMOTE演算法,可以使 用imblearn工具包完成這個操作,首先需要安裝該工具包,可以直接在命令列中使用pip install imblearn或者conda install -c glemaitre imbalanced-learn完成安裝操作,(溫馨提示:安裝完成后,最好重啟一下,重啟!重啟!重啟!!!不然可能會有大坑,我經歷了各種各樣的問題卡了幾個小時,最后甚至重裝了anaconda,天殺的,怪我太菜了,,,),再把SMOTE演算法加載進來,只需要將特征資料和標簽傳進去,接下來就得到20W+個例外樣本,完成過采樣方案,
4.2 過采樣應用效果
過采樣方案的效果究竟怎樣呢?同樣使用邏輯回歸演算法來看看,
import pandas as pd
from imblearn.over_sampling import SMOTE
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
credit_cards=pd.read_csv('creditcard.csv')
columns=credit_cards.columns
# 在特征中去除掉標簽
features_columns=columns.delete(len(columns)-1)
features=credit_cards[features_columns]
labels=credit_cards['Class']
features_train, features_test, labels_train, labels_test = train_test_split(features,
labels,
test_size=0.3,
random_state=0)
基于SMOTE演算法來進行樣本生成,這樣正例和負例樣本數量就是一致的了
oversampler=SMOTE(random_state=0)
os_features,os_labels=oversampler.fit_resample(features_train,labels_train)
訓練集樣本數量:

os_features = pd.DataFrame(os_features)
os_labels = pd.DataFrame(os_labels)
best_c = printing_Kfold_scores(os_features,os_labels)


在訓練集上的效果還不錯,再來看看其測驗結果的混淆矩陣:
lr = LogisticRegression(C = best_c, penalty = 'l1',solver='liblinear')
lr.fit(os_features,os_labels.values.ravel())
y_pred = lr.predict(features_test.values)
# 計算混淆矩陣
cnf_matrix = confusion_matrix(labels_test,y_pred)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 繪制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()
輸出結果:
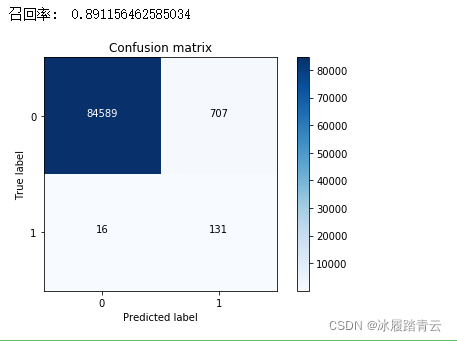
得到的召回率值與之前的下采樣方案相比有所下降,畢竟在例外樣本中很多都是假冒的,不能與真實資料相媲美,值得欣慰的是,這回模型的誤殺比例大大下降,原來誤殺比例占到所有測驗樣本的10%左右,現在只占不到1%,實際應用效果有很大提升,
經過對比可以明顯發現,過采樣的總體效果優于下采樣(還得依據實際應用效果具體分析),因為可利用的資料資訊更多,使得模型更符合實際的任務需求,但是,對于不同的任務與資料源來說,并沒有一成不變的答案,任何結果都需要通過實驗證明,所以當大家遇到問題時,最好的解決方案是通過大量實驗進行分析,
總結
- 在做任務之前一定要檢查資料,看看資料有什么問題,在此專案中,通過對資料進行觀察,發現其中有樣本不均衡的問題,針對這些問題,再來選擇解決方案,
- 針對問題提出兩種方法:下采樣和過采樣,通過兩條路線進行對比實驗,任何實際問題出現后,通常都是先得到一個基礎模型,然后對各種方法進行對比,找到最合適的,所以在任務開始之前,一定要多動腦筋,做多手準備,得到的結果才有可選擇的余地,
- 在建模之前,需要對資料進行各種預處理操作,例如資料標準化、缺失值填充等,這些都是必要的,由于資料本身已經給定特征,此處還沒有涉及特征工程這個概念,后續實戰中會逐步引入,其實資料預處理作業是整個任務中最重、最苦的一個作業階段,資料處理得好壞對結果的影響最大,
- 先選好評估方法,再進行建模實驗,建模的目的就是為了得到結果,但是不可能一次就得到最好的結果,肯定要嘗試很多次,所以一定要有一個合適的評估方法,可以選擇通用的,例如召回率、準確率等,也可以根據實際問題自己指定合適的評估指標,
- 選擇合適的演算法,本例中選擇邏輯回歸演算法,詳細分析其中的細節,之后還會講解其他演算法,并不 一定非要用邏輯回歸完成這個任務,其他演算法效果可能會更好,在機器學習中,并不是越復雜的演算法越實用,反而越簡單的演算法應用越廣泛,邏輯回歸就是其中一個典型的代表,簡單實用,所以任何分類問題都可以把邏輯回歸當作一個待比較的基礎模型,
- 模型的調參也是很重要的,通過實驗發現不同的引數可能會對結果產生較大的影響,這一步也是必須的,使用工具包時,建議最好先查閱其API檔案,知道每一個引數的意義,再來進行實驗,
打打氣吧,可能有時候我們可能會感覺很枯燥,不想堅持了,但親愛的朋友,我想告訴你,你離成功只差一個堅持,前期積累的程序注定是一段沉默的時光,也許你感覺很累,也許你甚至已經猶豫著要不要放棄,但是我可以告訴你,每一個人心中都有一只華麗、睿智、高貴的鳳凰,唯有經歷淬火錘煉,才能涅槃重生,
當我們踩過了眾多的坑,經歷了眾多的艱難,我們會明白暗淡的時光會讓我們逆勢生長,積累到一定的程度你會發現,程式的世界真是一個神奇的世界,為了看看這個世界的風光,你會一直狂熱的一路走下去,成功的路上并不擁擠,因為堅持的人不多,只有堅持了,我們才知道,這一路上有多少事情需要干,有多少東西需要學習,隨著時間的推移,任何一條通往成功的道路上同行者會越來越少,把“勝者為王”改為“剩者為王”也許更能準確地表達成功與堅持的關系,生命需要一種激情,當這種激情能讓別人感到你是不可阻擋的時候,就會為你的成功讓路,所以,親愛的朋友們,用你滿腔的激情繼續堅持吧!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435431.html
標籤:AI