python大資料可視化分析淘寶商品,開專賣店不行啊
現如今大資料分析例外火爆,如何正確分析資料,并且抓住資料特點,獲得不為人知的秘密?今天沉默帶你用python爬蟲,爬取淘寶網站進行淘寶商品大資料分析的實戰!文章目錄
- python大資料可視化分析淘寶商品,開專賣店不行啊
- 前言
- 一、明確爬取方向
- 1.1 淘寶搜索介面的分析
- 1.1.1 cookie獲取的途徑
- 1.1.2 搜索介面的分析
- 二、爬蟲腳本撰寫
- 1.1引入庫
- 1.3 格式化頁面,查找資料
- 1.4 將資料存盤到csv檔案中
- 1.5 完整代碼
- 三、資料可視化實作
- 1.1 引入依賴
- 1.2 價格分布直方圖實作邏輯
- 1.3 商品銷售地分析實作邏輯
- 1.4 商品店名稱聚集實作邏輯
- 1.5 完整代碼
- 四 、擴展
- 總結
前言
通過這場專案實戰,我將帶你進入大資料分析的世界,并且學習爬蟲技術,pandas,pyecharts,matplotlib等技術,一、明確爬取方向
淘寶的商品數量是特別巨大的,如此海量的資料我們如何去爬取,并且分析?因此我們需要明確爬取方向,怎么才可以爬取自己想分析的資料?我們最有效的方法就是從淘寶主頁的搜索介面找到突破口,1.1 淘寶搜索介面的分析
淘寶web網站
我總結如下步驟:
- 第一步:登錄淘寶網站,獲取我們登錄的淘寶賬號
- 第二步:獲取我們的cookie
- 第三步:獲取搜索介面
- 第四步:分析介面,確定爬取數量
1.1.1 cookie獲取的途徑
我們登錄上淘寶賬戶后,按電腦的F12鍵,進入開發者模式
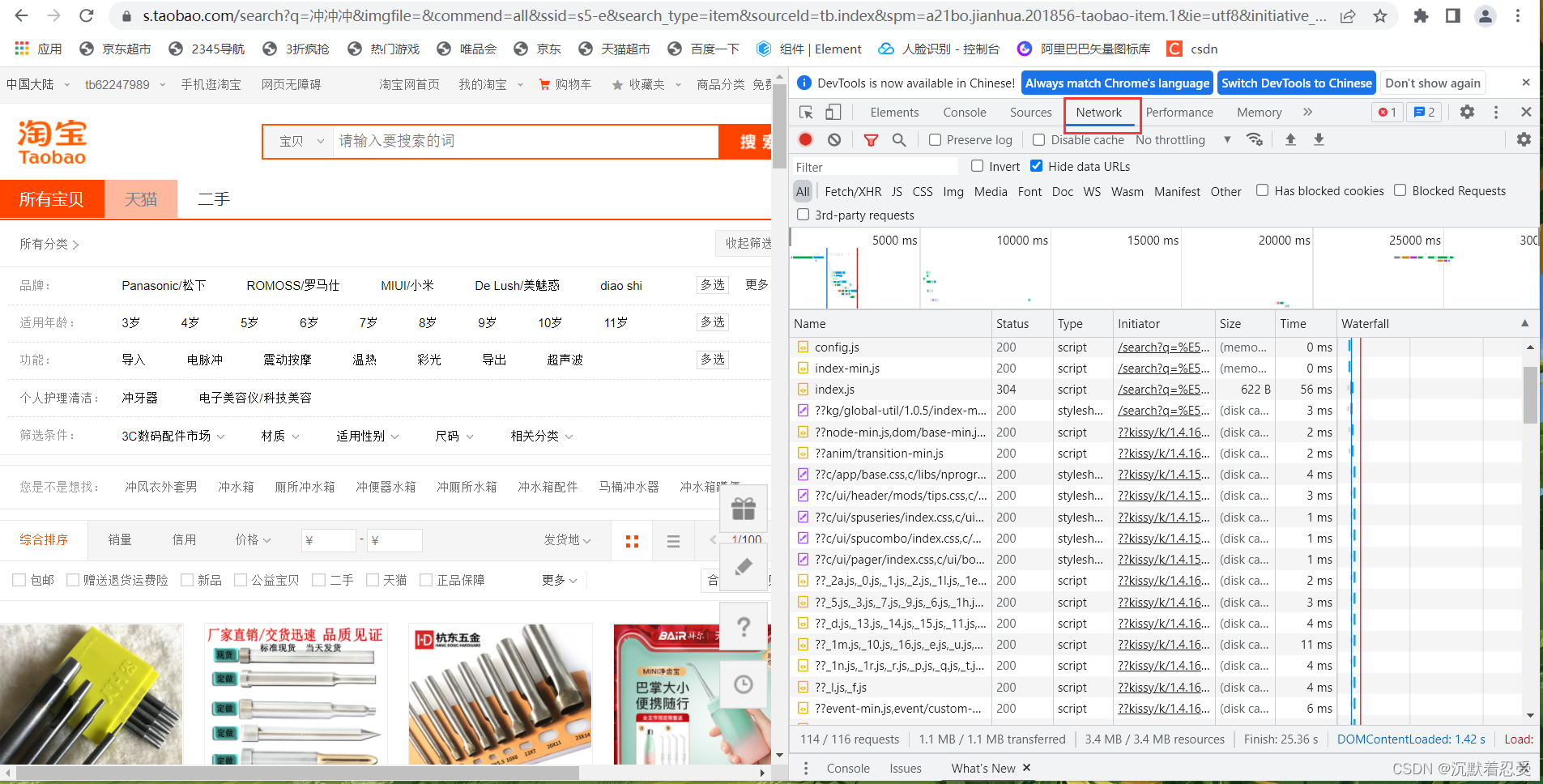
點擊Network,這里就是淘寶前端介面互動的資訊,然后我們隨便在搜索框中搜索資訊,然后在開發者框中找search介面,點擊該介面,你就會找到cookie資訊,復制一份資訊,保存起來,待后續爬蟲使用,
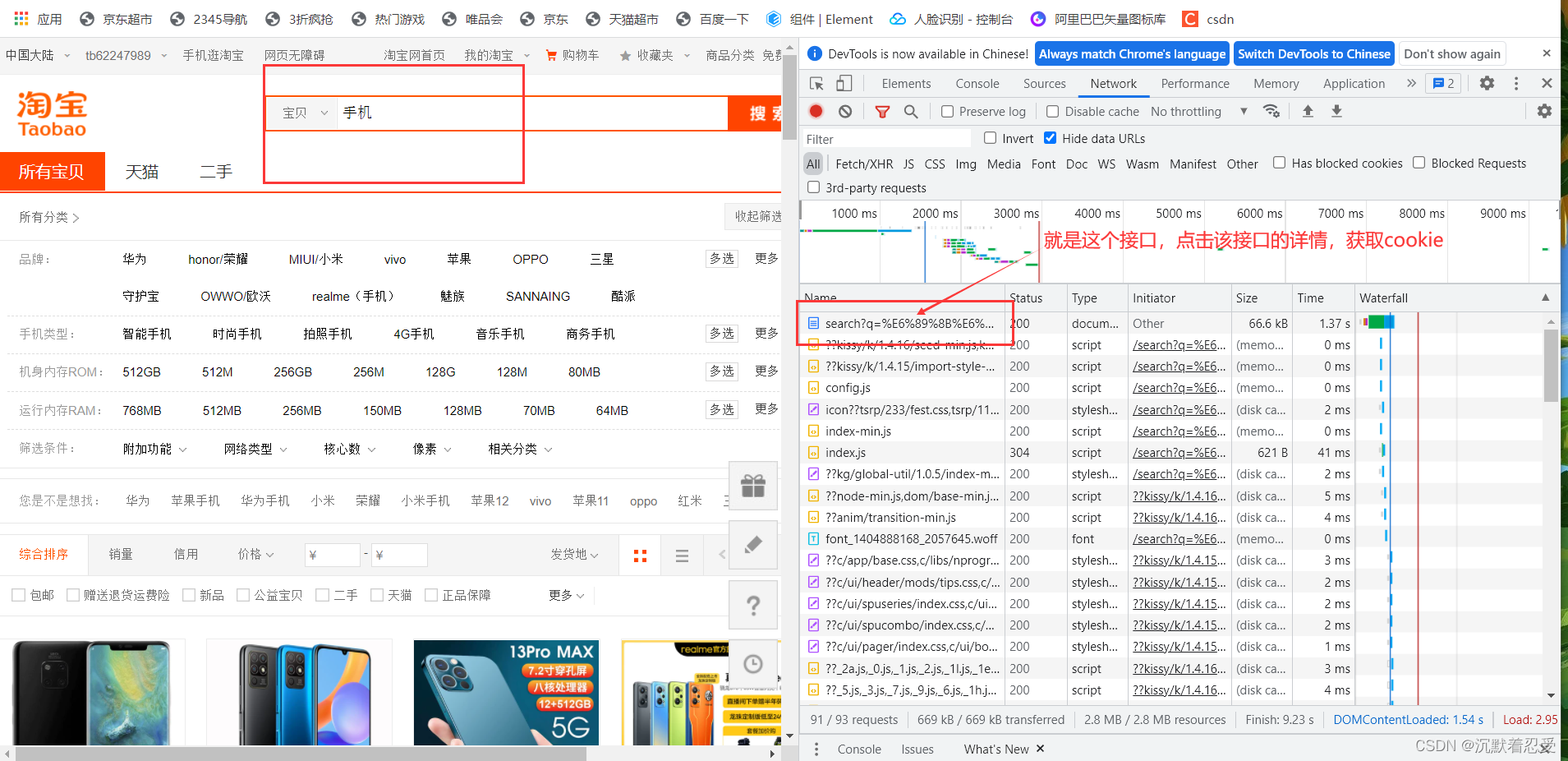
1.1.2 搜索介面的分析
分析搜索介面
https://s.taobao.com/search?q=小米手機&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200415&ie=utf8&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=0
https://s.taobao.com/search?q=小米手機&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200415&ie=utf8&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=44
https://s.taobao.com/search?q=小米手機&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200415&ie=utf8&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=88
分析得知:每個頁面參請求數基本相同,只有最后一個頁碼引數不同,而且是規律的:當前頁面資料(頁數-1)*
所以當我們想要將前端頁面跳轉至下一頁爬取資料只需要將url拼接上面邏輯
運算后的資料即可,
二、爬蟲腳本撰寫
以男士襯衫商品為例子,開展的簡單資料分析,其目的是了解淘寶網站線上銷售男士內褲的方法和模式,通過獲取到的淘寶網站男士襯衫銷售資料情況,進一步分析和判斷出哪個價格區間及品牌等資訊更加受到網購消費者的青睞和偏好,從而給自己買一個性價比較好的襯衫,1.1引入庫
代碼如下(區域):
# -*- coding: utf-8 -*-
import requests
import re
import pandas as pd
import time
如果上述的的庫沒有下載,請安裝后在使用;(如果沒有安裝庫,就會爆紅)
## 1.2 獲取頁面資訊
# 此處寫入登錄之后自己的cookies
cookie = ''
# 獲取頁面資訊
def getHTMLText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
user_cookies = cookie
cookies = {}
for a in user_cookies.split(';'): # 因為cookies是字典形式,所以用spilt函式將之改為字典形式
name, value = a.strip().split('=', 1)
cookies[name] = value
try:
r = requests.get(url, cookies=cookies, headers=headers, timeout=60)
print(r.status_code)
print(r.cookies)
return r.text
except:
print('獲取頁面資訊失敗')
return ''
1.3 格式化頁面,查找資料
# 格式化頁面,查找資料
def parsePage(html):
list = []
try:
views_title = re.findall('"raw_title":"(.*?)","pic_url"', html)
print(len(views_title)) # 列印檢索到資料資訊的個數,如果此個數與后面的不一致,則資料資訊不能加入串列
print(views_title)
views_price = re.findall('"view_price":"(.*?)","view_fee"', html)
print(len(views_price))
print(views_price)
item_loc = re.findall('"item_loc":"(.*?)","view_sales"', html)
print(len(item_loc))
print(item_loc)
views_sales = re.findall('"view_sales":"(.*?)","comment_count"', html)
print(len(views_sales))
print(views_sales)
comment_count = re.findall('"comment_count":"(.*?)","user_id"', html)
print(len(comment_count))
print(comment_count)
shop_name = re.findall('"nick":"(.*?)","shopcard"', html)
print(len(shop_name))
for i in range(len(views_price)):
list.append([views_title[i], views_price[i], item_loc[i], comment_count[i], views_sales[i], shop_name[i]])
# print(list)
print('爬取資料成功')
return list
except:
print('有資料資訊不全,如某一頁面中某一商品缺少地區資訊')
1.4 將資料存盤到csv檔案中
# 存盤到csv檔案中,為接下來的資料分析做準備
def save_to_file(list):
data = pd.DataFrame(list)
data.to_csv('F:\\Github\\pythonobject\\taobao\\商品資料.csv', header=False, mode='a+') # 用追加寫入的方式
1.5 完整代碼
# -*- coding: utf-8 -*-
import requests
import re
import pandas as pd
import time
# 此處寫入登錄之后自己的cookies
cookie = ''
# 獲取頁面資訊
def getHTMLText(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'}
user_cookies = cookie
cookies = {}
for a in user_cookies.split(';'): # 因為cookies是字典形式,所以用spilt函式將之改為字典形式
name, value = a.strip().split('=', 1)
cookies[name] = value
try:
r = requests.get(url, cookies=cookies, headers=headers, timeout=60)
print(r.status_code)
print(r.cookies)
return r.text
except:
print('獲取頁面資訊失敗')
return ''
# 格式化頁面,查找資料
def parsePage(html):
list = []
try:
views_title = re.findall('"raw_title":"(.*?)","pic_url"', html)
print(len(views_title)) # 列印檢索到資料資訊的個數,如果此個數與后面的不一致,則資料資訊不能加入串列
print(views_title)
views_price = re.findall('"view_price":"(.*?)","view_fee"', html)
print(len(views_price))
print(views_price)
item_loc = re.findall('"item_loc":"(.*?)","view_sales"', html)
print(len(item_loc))
print(item_loc)
views_sales = re.findall('"view_sales":"(.*?)","comment_count"', html)
print(len(views_sales))
print(views_sales)
comment_count = re.findall('"comment_count":"(.*?)","user_id"', html)
print(len(comment_count))
print(comment_count)
shop_name = re.findall('"nick":"(.*?)","shopcard"', html)
print(len(shop_name))
for i in range(len(views_price)):
list.append([views_title[i], views_price[i], item_loc[i], comment_count[i], views_sales[i], shop_name[i]])
# print(list)
print('爬取資料成功')
return list
except:
print('有資料資訊不全,如某一頁面中某一商品缺少地區資訊')
# 存盤到csv檔案中,為接下來的資料分析做準備
def save_to_file(list):
data = pd.DataFrame(list)
data.to_csv('F:\\Github\\pythonobject\\taobao\\商品資料.csv', header=False, mode='a+') # 用追加寫入的方式
def main():
name = [['views_title', 'views_price', 'item_loc', 'comment_count', 'views_sales', 'shop_name']]
data_name = pd.DataFrame(name)
data_name.to_csv('F:\\Github\\pythonobject\\taobao\\商品資料.csv', header=False, mode='a+') # 提前保存一行列名稱
goods = input('請輸入想查詢的商品名稱:'.strip()) # 輸入想搜索的商品名稱
depth = 5 # 爬取的頁數
start_url = 'https://s.taobao.com/search?q=' + goods # 初始搜索地址
for i in range(depth):
time.sleep(3 + i)
try:
page = i + 1
print('正在爬取第%s頁資料' % page)
url = start_url + 'imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20200408&ie=utf8&sort=sale-desc&bcoffset=0&p4ppushleft=%2C44&s=' + str(
44 * i)
html = getHTMLText(url)
# print(html)
list = parsePage(html)
save_to_file(list)
except:
print('資料沒保存成功')
if __name__ == '__main__':
main()
運行專案,輸入男士襯衫,回車,自動爬取資料
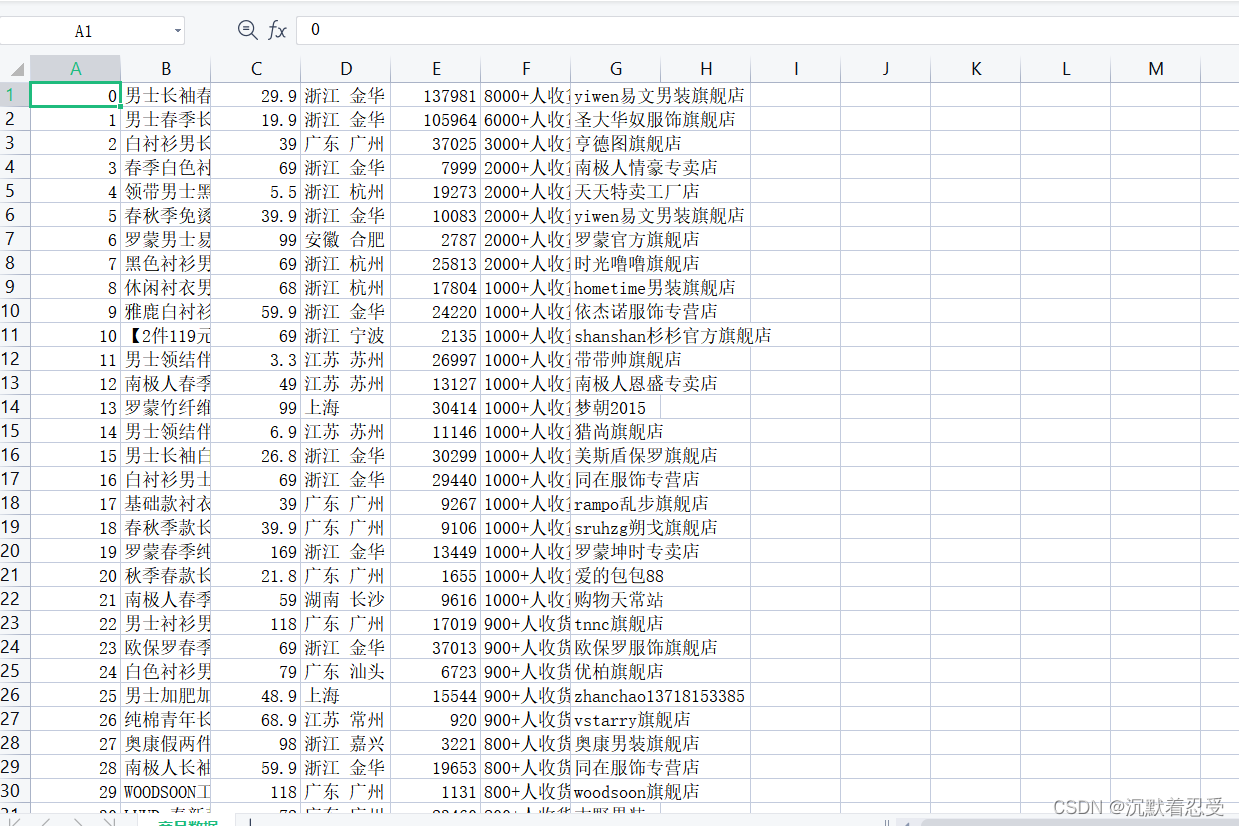
保存的商品資訊csv檔案:
三、資料可視化實作
資料可視化說白了,也就是通過資料分析,將得出的結果用圖表的形式展示出來,圖表的展示無非就是k,v的方式實作,所以我們可以借助pandas,將海量的資料分析出來,并且將分析后的資料處理成可視化表所識別的資料格式就可以實作資料可視化,我們這里可視化依賴于pyecharts和matplotlib,1.1 引入依賴
沒有以下庫的請下載安裝
import pandas as pd
import operator
from matplotlib import pyplot as plt
import matplotlib as mpl
from pyecharts.charts import Bar, Pie
# 用于設值全域配置和系列配置
from pyecharts import options as opts
mpl.rcParams['font.sans-serif'] = ['KaiTi'] # 畫圖時顯示中文
mpl.rcParams['font.serif'] = ['KaiTi']
data = pd.read_csv('F:\\Github\\pythonobject\\taobao\\商品資料.csv', encoding='utf-8')
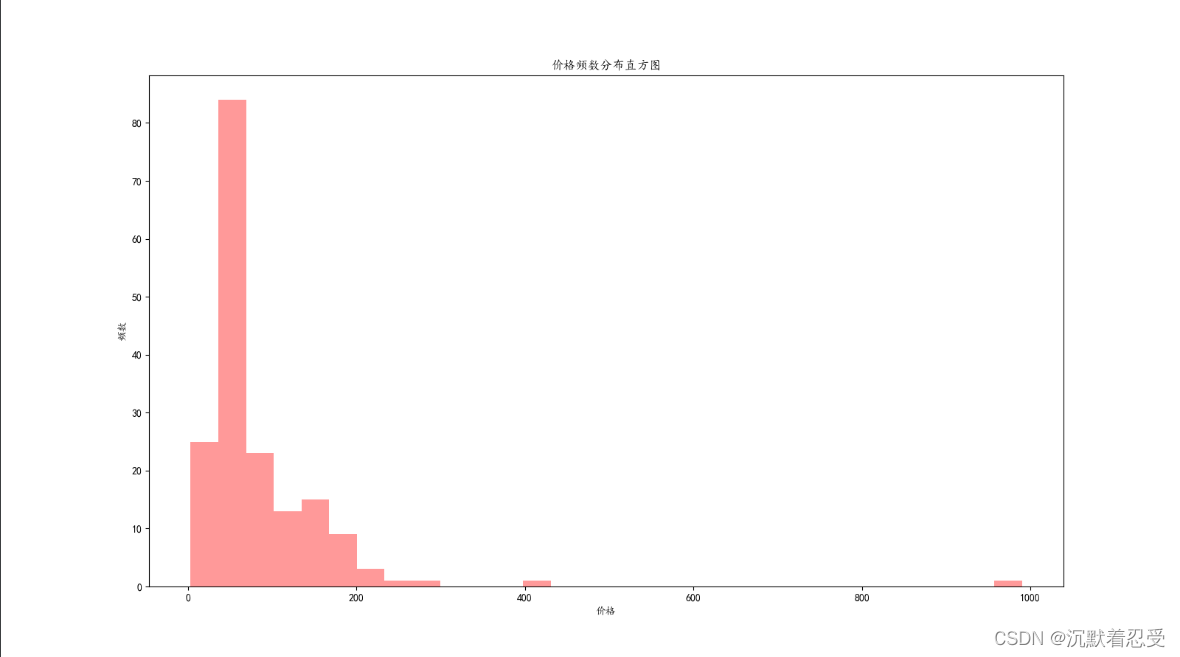
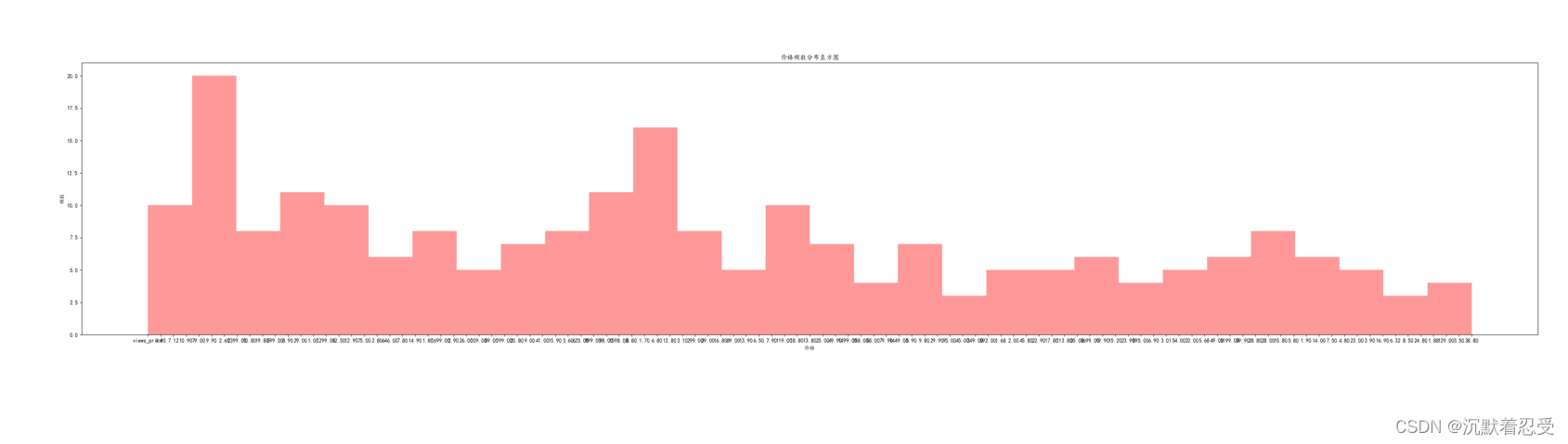
1.2 價格分布直方圖實作邏輯
# 商品價格分析
def priceshow():
print(data['views_price'].describe())
# 價格分布直方圖
plt.figure(figsize=(16, 9)) # 這里是圖片長寬比例
plt.hist(data['views_price'], bins=30, alpha=0.4, color='orange')
plt.title('價格頻數分布直方圖')
plt.xlabel('價格')
plt.ylabel('頻數')
plt.savefig('價格分布直方圖.png')
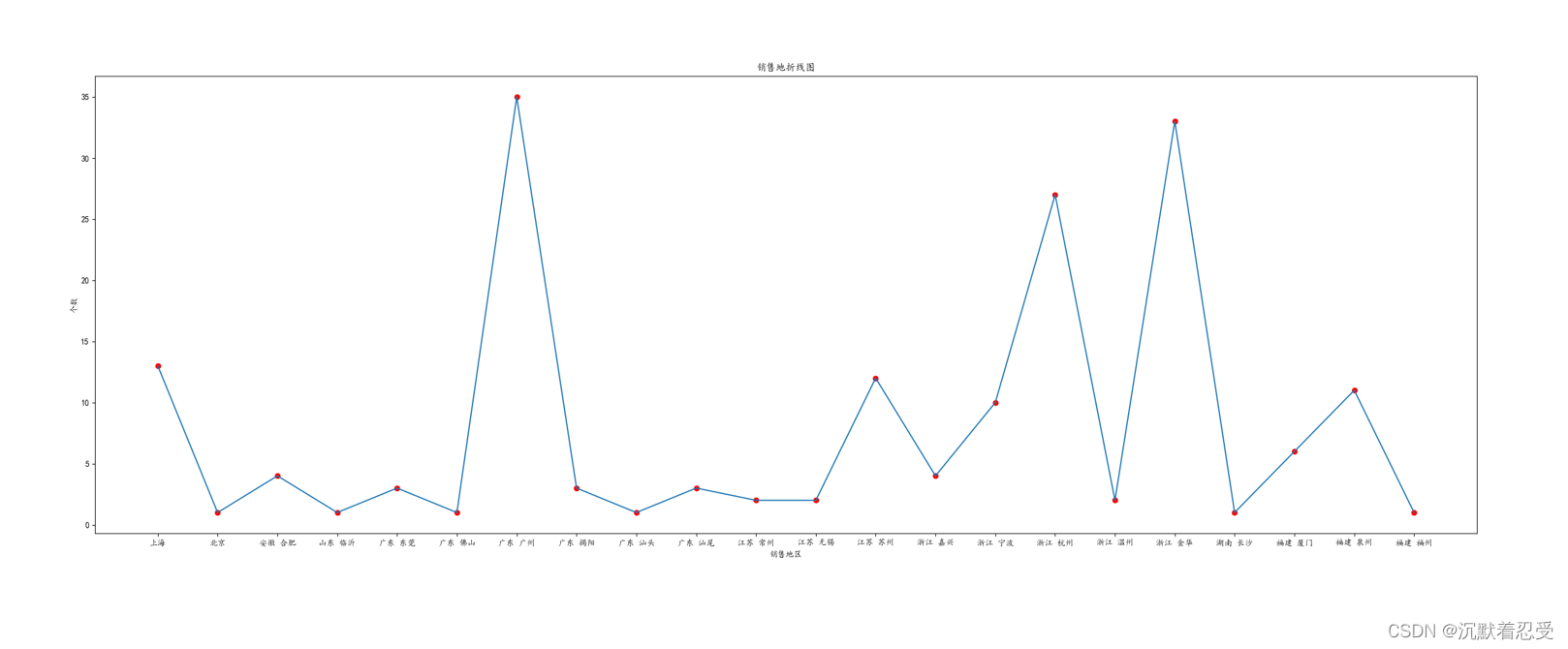
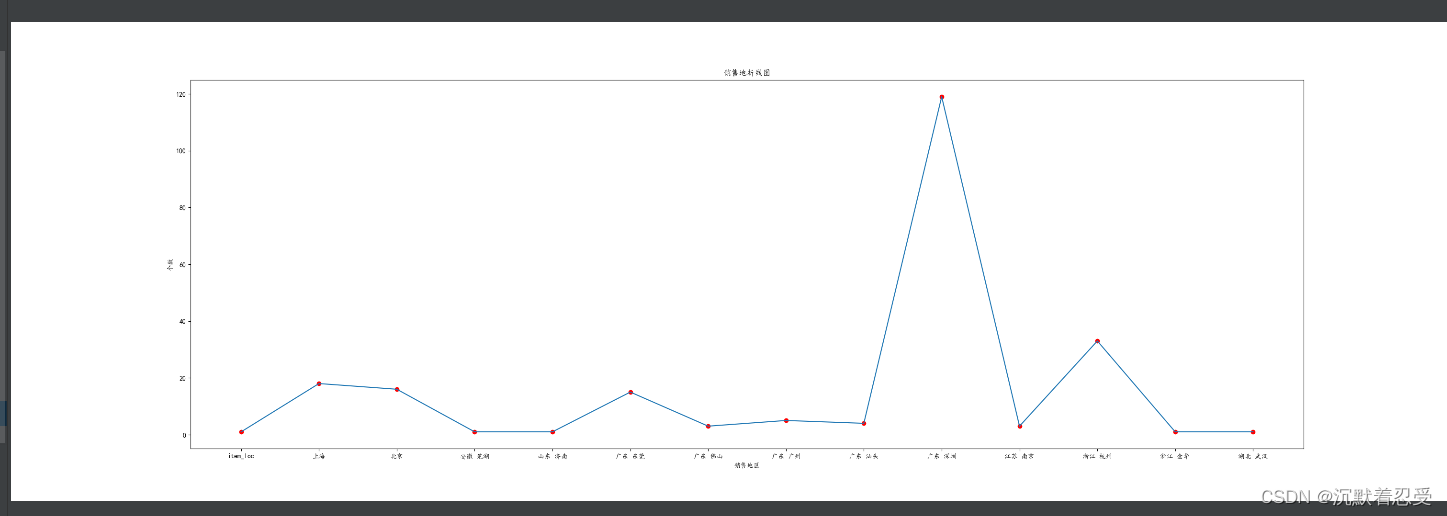
1.3 商品銷售地分析實作邏輯
# 分析商品的資料(商品銷售地分析)
def shop_localdatashow():
# 銷售地分布
group_data = list(data.groupby('item_loc'))
loc_num = {}
for i in range(len(group_data)):
loc_num[group_data[i][0]] = len(group_data[i][1])
print(loc_num)
plt.figure(figsize=(30, 10))
plt.title('銷售地折線圖')
plt.scatter(list(loc_num.keys()), list(loc_num.values()), color='r')
plt.plot(list(loc_num.keys()), list(loc_num.values()))
plt.xlabel('銷售地區')
plt.ylabel('個數')
plt.savefig('銷售地.png')
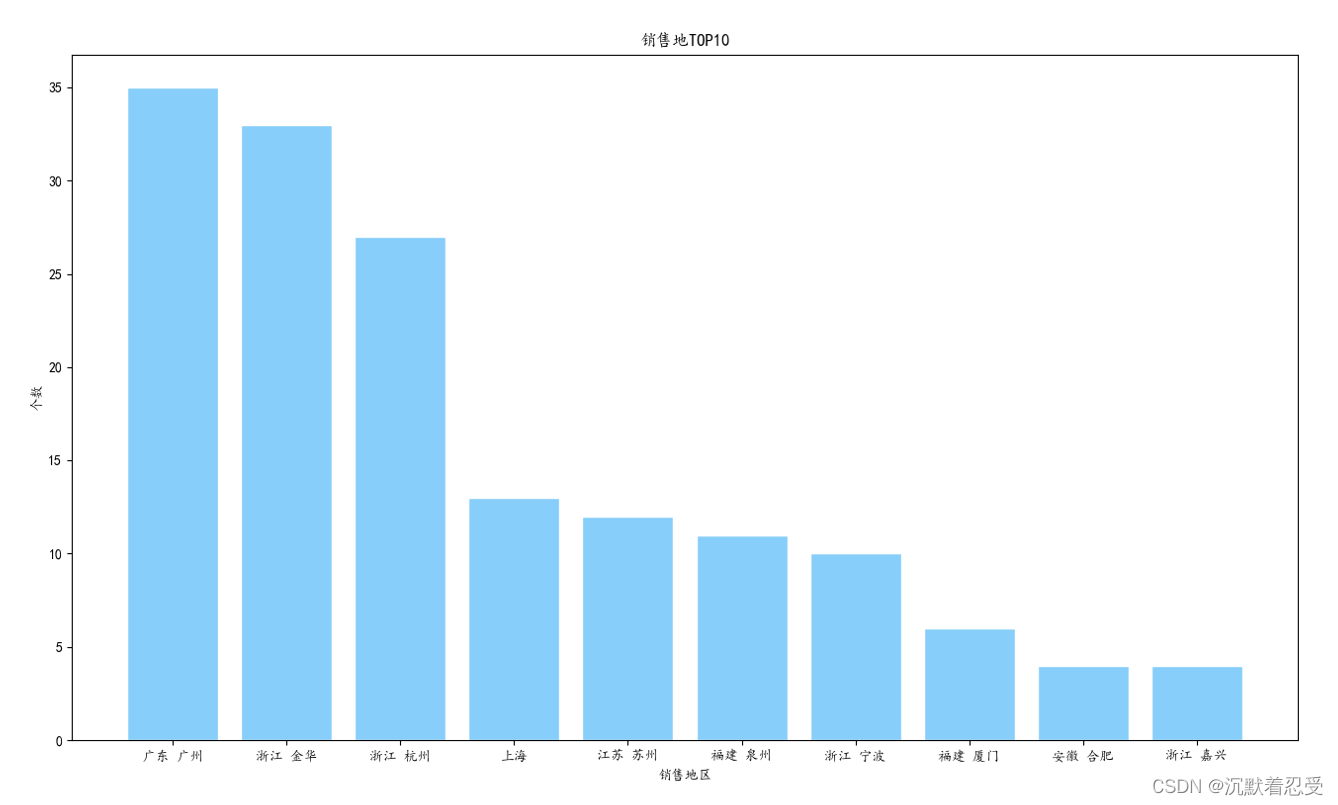
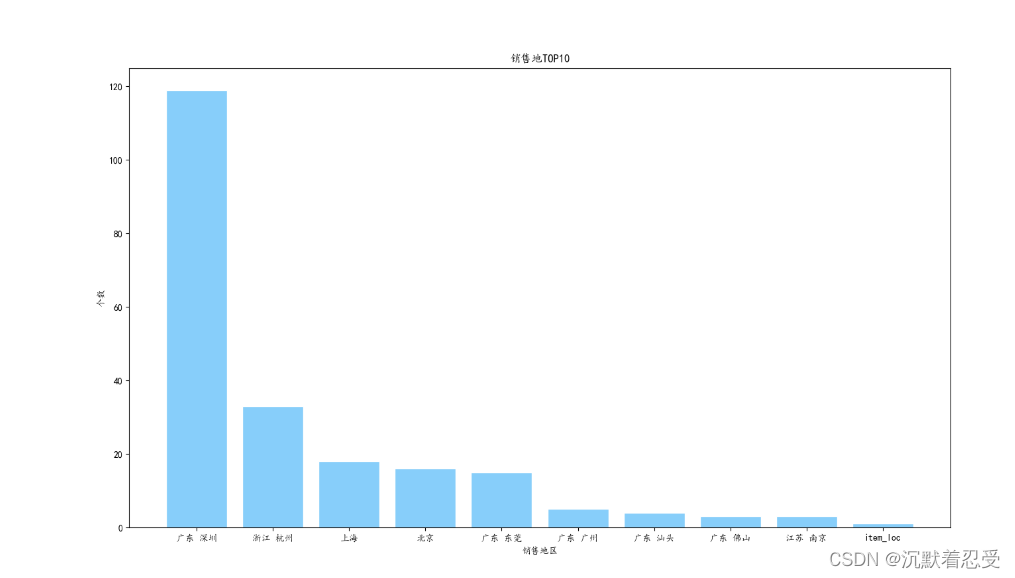
sorted_loc_num = sorted(loc_num.items(), key=operator.itemgetter(1), reverse=True) # 排序
loc_num_10 = sorted_loc_num[:10] # 取前10
loc_10 = []
num_10 = []
for i in range(10):
loc_10.append(loc_num_10[i][0])
num_10.append(loc_num_10[i][1])
plt.figure(figsize=(16, 9))
plt.title('銷售地TOP10')
plt.xlabel('銷售地區')
plt.ylabel('個數')
plt.bar(loc_10, num_10, facecolor='lightskyblue', edgecolor='white')
plt.savefig('銷售地TOP10.png')
top10生產地表
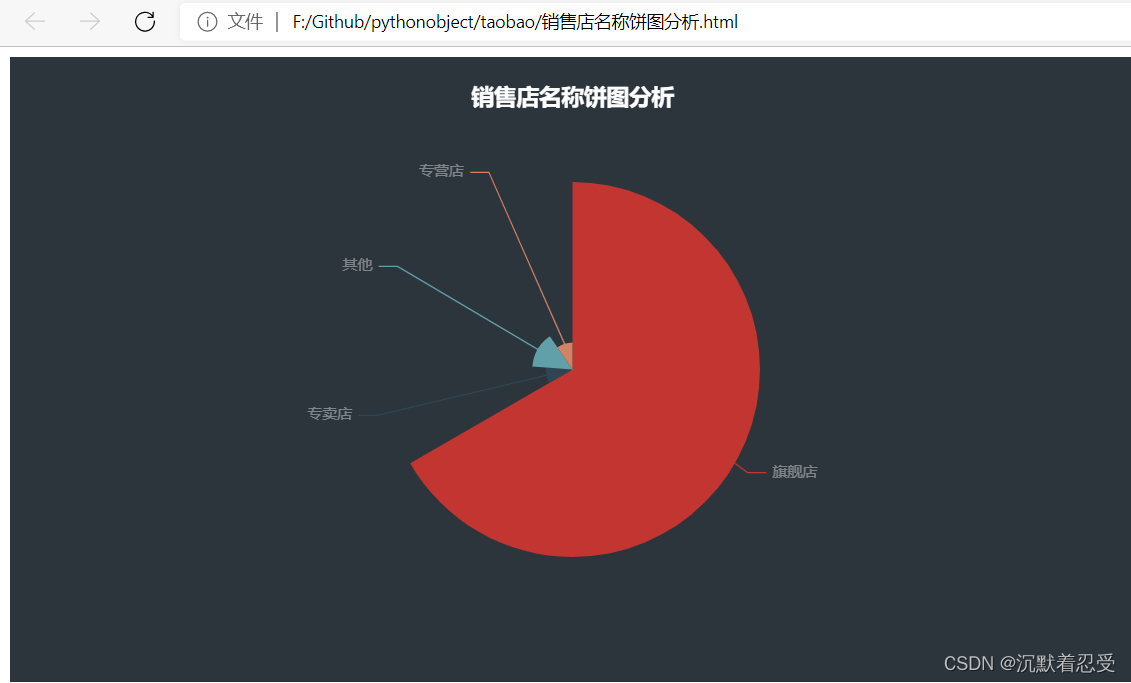
1.4 商品店名稱聚集實作邏輯
資料獲取,通過pyecharts展示資料
# 分析商品店名稱聚集
def shop_name():
# 店名稱分析
df1 = data['shop_name'].str[-3:]
shop = list(df1.groupby(df1))
# print(shop)
shop_num = {}
for i in range(len(shop)):
shop_num[shop[i][0]] = len(shop[i][1])
shop_num['其他'] =176 - shop_num['專賣店'] - shop_num['專營店'] - shop_num['旗艦店']
data1 = sorted(shop_num.values(), reverse=True)[:4]
# print(shop_num)
label = ['旗艦店', '專賣店', '其他', '專營店'] # 定義餅圖的標簽,標簽是串列
# explode = [0.01, 0.01, 0.01, 0.01] # 設定各項距離圓心n個半徑
# attr = ["襯衫", "羊毛衫", "雪紡衫", "褲子", "高跟鞋", "襪子"]
v = [shop_num['旗艦店'], shop_num['專賣店'], shop_num['其他'], shop_num['專賣店']]
arr = [label, v]
return arr
這里注意:
-
shop_num['其他'] =176 - shop_num['專賣店'] - shop_num['專營店'] - shop_num['旗艦店'] - 176是指我爬出了多少條資料資訊,檔案第一行是表頭,不算在內,
銷售店名稱餅圖
def text(x, y):
# 餅圖用的資料格式是[(key1,value1),(key2,value2)],所以先使用 zip函式將二者進行組合
data_pair = [list(z) for z in zip(x, y)]
(
# 初始化配置項,內部可設定顏色
Pie(init_opts=opts.InitOpts(bg_color="#2c343c"))
.add(
# 系列名稱,即該餅圖的名稱
series_name="銷售店名稱餅圖分析",
# 系列資料項,格式為[(key1,value1),(key2,value2)]
data_pair=data_pair,
# 通過半徑區分資料大小 “radius” 和 “area” 兩種
rosetype="radius",
# 餅圖的半徑,設定成默認百分比,相對于容器高寬中較小的一項的一半
radius="60%",
# 餅圖的圓心,第一項是相對于容器的寬度,第二項是相對于容器的高度
center=["50%", "50%"],
# 標簽配置項
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
# 全域設定
.set_global_opts(
# 設定標題
title_opts=opts.TitleOpts(
# 名字
title="銷售店名稱餅圖分析",
# 組件距離容器左側的位置
pos_left="center",
# 組件距離容器上方的像素值
pos_top="20",
# 設定標題顏色
title_textstyle_opts=opts.TextStyleOpts(color="#ffffff"),
),
# 圖例配置項,引數 是否顯示圖里組件
legend_opts=opts.LegendOpts(is_show=False),
)
# 系列設定
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
# 設定標簽顏色
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.4)"),
)
.render("銷售店名稱餅圖分析.html")
)
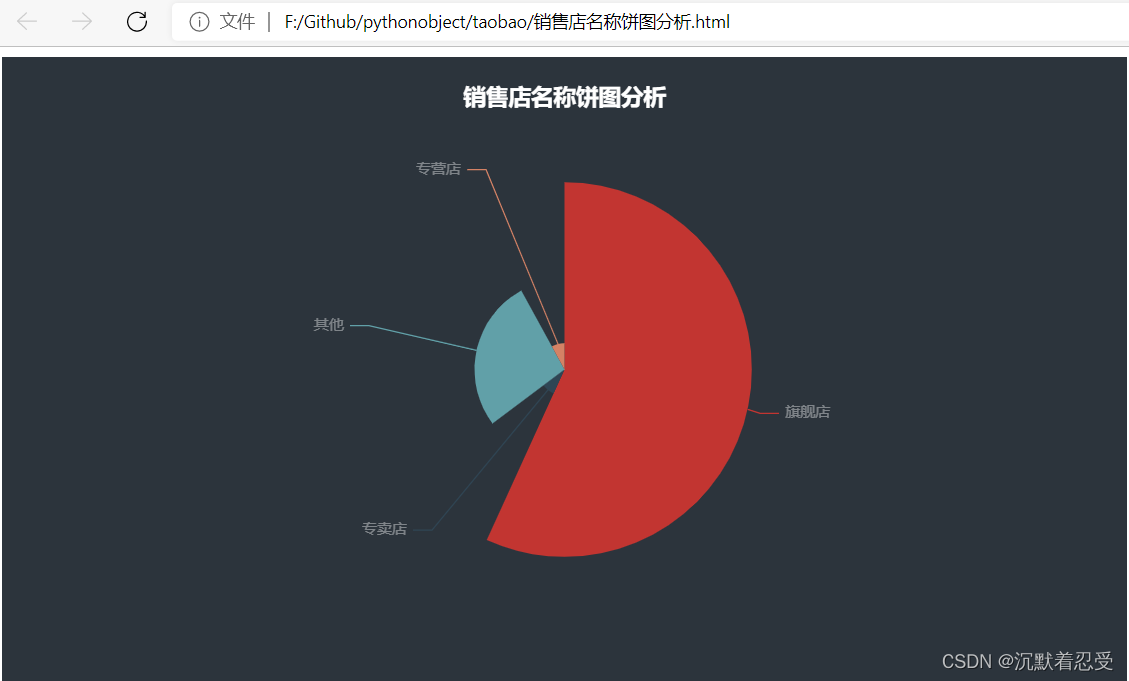
通過分析,旗艦店的商戶占比較大,所以大部分用戶都是在旗艦店購買的衣服,
1.5 完整代碼
import pandas as pd
import operator
from matplotlib import pyplot as plt
import matplotlib as mpl
from pyecharts.charts import Bar, Pie
# 用于設值全域配置和系列配置
from pyecharts import options as opts
mpl.rcParams['font.sans-serif'] = ['KaiTi'] # 畫圖時顯示中文
mpl.rcParams['font.serif'] = ['KaiTi']
data = pd.read_csv('F:\\Github\\pythonobject\\taobao\\商品資料.csv', encoding='utf-8')
# 商品價格分析
def priceshow():
print(data['views_price'].describe())
# 價格分布直方圖
plt.figure(figsize=(16, 9))
plt.hist(data['views_price'], bins=30, alpha=0.4, color='red')
plt.title('價格頻數分布直方圖')
plt.xlabel('價格')
plt.ylabel('頻數')
plt.savefig('價格分布直方圖.png')
# 分析商品的資料(商品銷售地分析)
def shop_localdatashow():
# 銷售地分布
group_data = list(data.groupby('item_loc'))
loc_num = {}
for i in range(len(group_data)):
loc_num[group_data[i][0]] = len(group_data[i][1])
print(loc_num)
plt.figure(figsize=(30, 10))
plt.title('銷售地折線圖')
plt.scatter(list(loc_num.keys()), list(loc_num.values()), color='r')
plt.plot(list(loc_num.keys()), list(loc_num.values()))
plt.xlabel('銷售地區')
plt.ylabel('個數')
plt.savefig('銷售地.png')
sorted_loc_num = sorted(loc_num.items(), key=operator.itemgetter(1), reverse=True) # 排序
loc_num_10 = sorted_loc_num[:10] # 取前10
loc_10 = []
num_10 = []
for i in range(10):
loc_10.append(loc_num_10[i][0])
num_10.append(loc_num_10[i][1])
plt.figure(figsize=(16, 9))
plt.title('銷售地TOP10')
plt.xlabel('銷售地區')
plt.ylabel('個數')
plt.bar(loc_10, num_10, facecolor='lightskyblue', edgecolor='white')
plt.savefig('銷售地TOP10.png')
# 分析商品店名稱聚集
def shop_name():
# 店名稱分析
df1 = data['shop_name'].str[-3:]
shop = list(df1.groupby(df1))
# print(shop)
shop_num = {}
for i in range(len(shop)):
shop_num[shop[i][0]] = len(shop[i][1])
shop_num['其他'] = 176 - shop_num['專賣店'] - shop_num['專營店'] - shop_num['旗艦店']
data1 = sorted(shop_num.values(), reverse=True)[:4]
# print(shop_num)
label = ['旗艦店', '專賣店', '其他', '專營店'] # 定義餅圖的標簽,標簽是串列
# explode = [0.01, 0.01, 0.01, 0.01] # 設定各項距離圓心n個半徑
# attr = ["襯衫", "羊毛衫", "雪紡衫", "褲子", "高跟鞋", "襪子"]
v = [shop_num['旗艦店'], shop_num['專賣店'], shop_num['其他'], shop_num['專賣店']]
arr = [label, v]
return arr
def text(x, y):
# 餅圖用的資料格式是[(key1,value1),(key2,value2)],所以先使用 zip函式將二者進行組合
data_pair = [list(z) for z in zip(x, y)]
(
# 初始化配置項,內部可設定顏色
Pie(init_opts=opts.InitOpts(bg_color="#2c343c"))
.add(
# 系列名稱,即該餅圖的名稱
series_name="銷售店名稱餅圖分析",
# 系列資料項,格式為[(key1,value1),(key2,value2)]
data_pair=data_pair,
# 通過半徑區分資料大小 “radius” 和 “area” 兩種
rosetype="radius",
# 餅圖的半徑,設定成默認百分比,相對于容器高寬中較小的一項的一半
radius="60%",
# 餅圖的圓心,第一項是相對于容器的寬度,第二項是相對于容器的高度
center=["50%", "50%"],
# 標簽配置項
label_opts=opts.LabelOpts(is_show=False, position="center"),
)
# 全域設定
.set_global_opts(
# 設定標題
title_opts=opts.TitleOpts(
# 名字
title="銷售店名稱餅圖分析",
# 組件距離容器左側的位置
pos_left="center",
# 組件距離容器上方的像素值
pos_top="20",
# 設定標題顏色
title_textstyle_opts=opts.TextStyleOpts(color="#ffffff"),
),
# 圖例配置項,引數 是否顯示圖里組件
legend_opts=opts.LegendOpts(is_show=False),
)
# 系列設定
.set_series_opts(
tooltip_opts=opts.TooltipOpts(
trigger="item", formatter="{a} <br/>{b}: {c} ({d}%)"
),
# 設定標簽顏色
label_opts=opts.LabelOpts(color="rgba(255, 255, 255, 0.4)"),
)
.render("銷售店名稱餅圖分析.html")
)
# 通過matplotlib產生的餅圖并不完善
# plt.title('銷售店名稱餅圖分析')
# plt.pie(data1, explode=explode, labels=label, autopct='%1.1f%%') # 繪制餅圖
# plt.savefig('銷售店名稱.png')
if __name__ == '__main__':
priceshow()
shop_localdatashow()
dist = shop_name()
print(dist[0])
print(dist[1])
text(dist[0], dist[1])
四 、擴展
我在腳本設計的時候靈活的將需要爬取的商品通過控制臺輸入,并沒有固定一個商品,所以理論上可以實作所有商品的資料分析,這里我測驗,統計小米手機的資料;
在測驗前,需要洗掉csv檔案,因為在資料爬取之前我是采用追加的方式,如果檔案里有其他商品,資料分析是失敗的
data.to_csv('F:\\Github\\pythonobject\\taobao\\商品資料.csv', header=False, mode='a+') # 用追加寫入的方式
話說,專賣店生意是真不行!
總結
例如:以上就是今天要講的內容,本文僅僅簡單介紹了pandas的使用,而pandas提供了大量能使我們快速便捷地處理資料的函式和方法,轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435472.html
標籤:其他
下一篇:Flink -沒寫完更新中