文章目錄
- 前言
- 一、概述
- 1 Flink是什么
- 2 架構分層
- 3 基本組件
- 4 其他流式計算框架+
- 二、入門與使用
- 1 Flink基本安裝
- 1.1 Linux
- 1.2 Java
- 1.3 Scala+
- 2 常用API
- 2.1 DataStream 流處理
- DataSource
- Transformation
- Sink
- 示例一:自定義資料源(SourceFunction)
- 示例二:自定義磁區
- 示例三:NettyServer作為資料源
- 示例四:RabbitMQ作為資料源
- 示例五:待定
- 2.2 DataSet 批處理
- 2.3 Table API/SQL
- 2.4 關于序列化
- 3 集群模式
- 三、高階功能使用
- 四、原理決議
- 總結
前言
提示:這里可以添加本文要記錄的大概內容,例如:我是一個帥哥,你懂吧?
| 文獻 |
|---|
| 《Flink入門與實戰》 - 徐葳 |
| / |
一、概述
1 Flink是什么
? Apache Flink,內部是用Java及Scala撰寫的分布式流資料計算引擎,可以支持以批處理或流處理的方式處理資料,在2014年這個專案被Apache范訓器所接受后,Flink迅速成為ASF(ApacheSoftware Foundation)的頂級專案之一,在2019年1月,阿里巴巴集團收購了Flink創始公司(DataArtisans),打造了阿里云商業化的實時計算Flink產品,
它有如下幾個特點
- 低延遲
- 高吞吐
- 支持有界資料/無界資料的處理,資料流式計算
- 支持集群,支持HA,可靠性強
什么是有界資料/無界資料?
- 有界資料:資料是有限的,一條SELECT查詢下的資料不會是源源不斷的
- 無界資料:資料源源不斷,不知道為什么時候結束,例如監控下的告警
2 架構分層
| 名稱 | 描述 |
|---|---|
| Deploy 部署方式 | 本地/集群/云服務部署, |
| Core 分布式流處理模型 | 計算核心實作,為API層提供基礎服務, |
| API 呼叫介面 | 提供面向無界資料的流處理API及有界資料的批處理API,其中流處理對應DataStream API,批處理對應DataSet API, |
| Library 應用層 | 提供應用計算框架,面向流處理支持CEP(復雜事件處理)、基于SQL-like的操作(基于Table的關系操作),面向批處理支持FlinkML(機器學習庫)、Gelly(圖處理)、Table 操作, |
3 基本組件
一個Flink任務 = DataSource + Transformation + DataSink
DataSource :資料源
Transformation :資料處理
DataSink:計算結果輸出
而Flink在網路傳輸中通過快取塊承載資料,可以通過設定快取塊的超時時間,變相的決定了資料在網路中的處理方式,
4 其他流式計算框架+
1
1
1
1
1
二、入門與使用
1 Flink基本安裝
1.1 Linux
| 下載鏈接 |
|---|
| Index of /dist/flink/flink-1.14.3 (apache.org) |
首先去apache官網下載部署的軟體包,下載完成之后進行解壓
## 解壓
tar -zxvf flink-1.14.3-bin-scala_2.12.tgz
## 進入bin目錄 啟動
./start-cluster.sh
## Flink提供的WebUI的埠是8081 此時可以去看看是否啟動完成
netstat -anp |grep 8081
接著通過頁面訪問8081埠來個初體驗
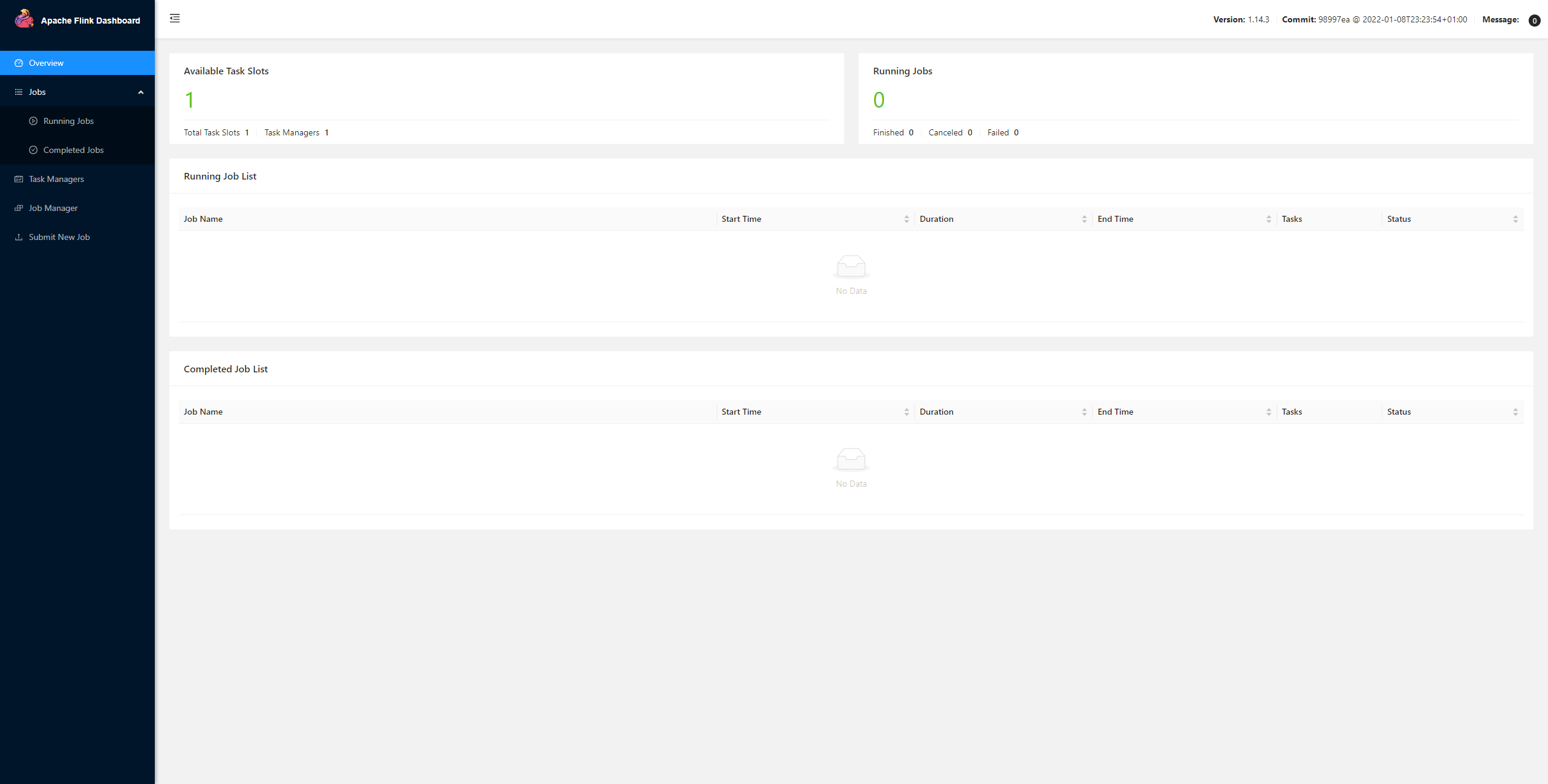
關于Linux下的Flink Shell終端的使用
| 文章目錄 |
|---|
| flink~使用shell終端_cai_and_luo的博客-CSDN博客 |
1.2 Java
| 文章目錄 |
|---|
| Flink入門之Flink程式開發步驟(java語言)_胖虎兒的博客-CSDN博客 |
匯入依賴
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>1.14.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-core -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.14.3</version>
</dependency>
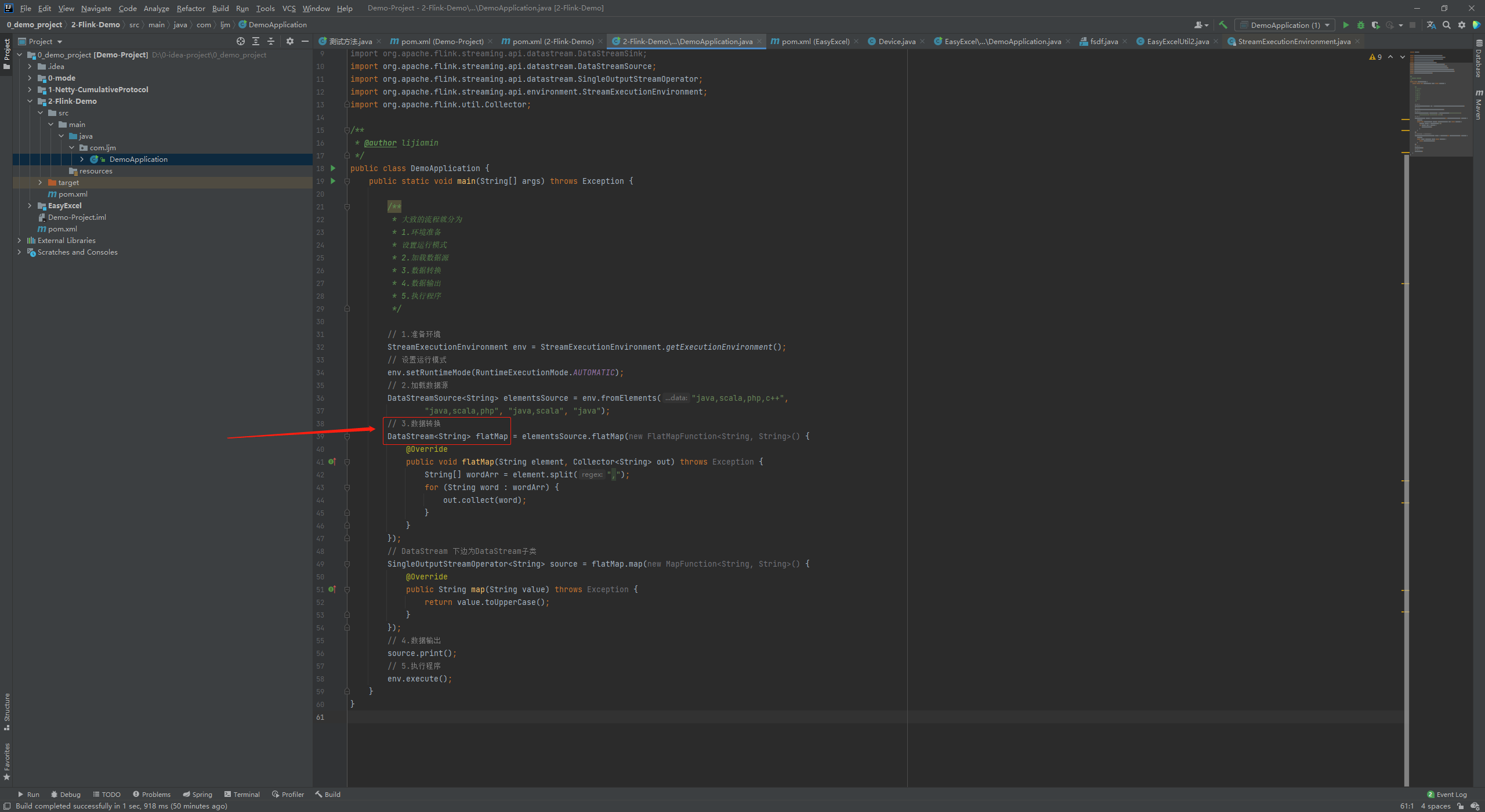
入門Demo
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class DemoApplication {
public static void main(String[] args) throws Exception {
/**
* 大致的流程就分為
* 1.環境準備
* 設定運行模式
* 2.加載資料源
* 3.資料轉換
* 4.資料輸出
* 5.執行程式
*/
// 1.準備環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 設定運行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.加載資料源
DataStreamSource<String> elementsSource = env.fromElements("java,scala,php,c++",
"java,scala,php", "java,scala", "java");
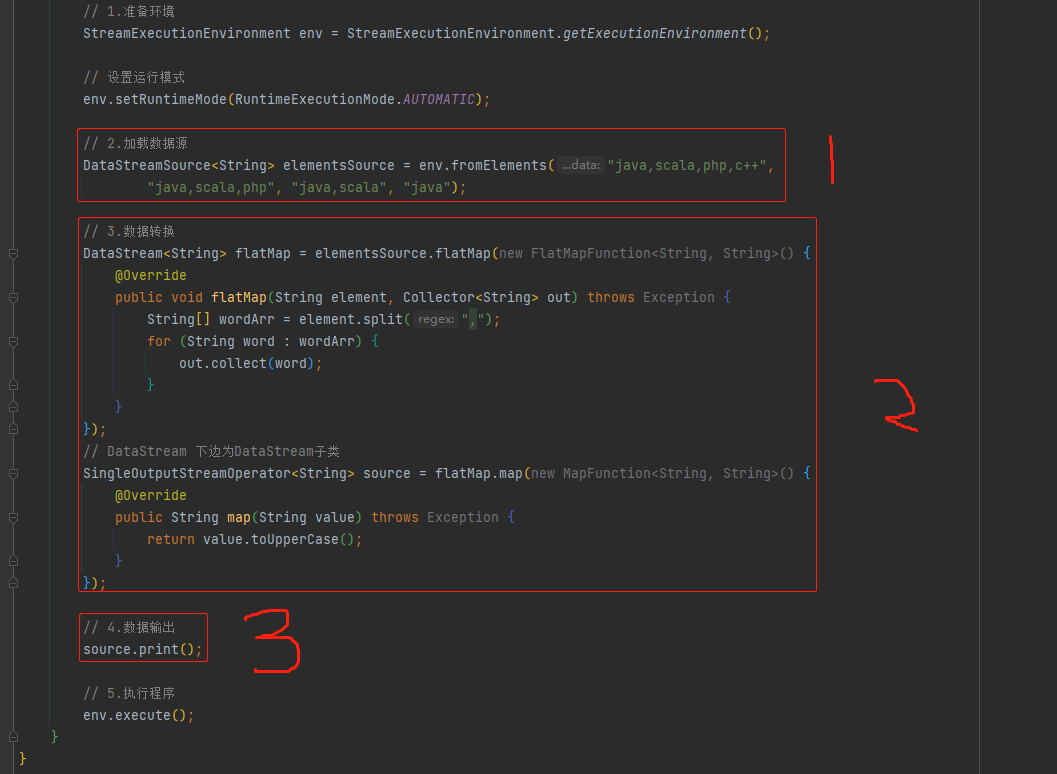
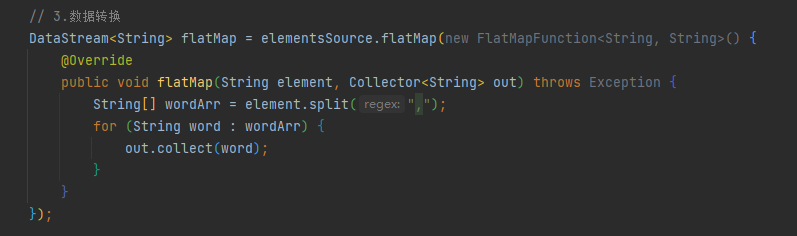
// 3.資料轉換
DataStream<String> flatMap = elementsSource.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String element, Collector<String> out) throws Exception {
String[] wordArr = element.split(",");
for (String word : wordArr) {
out.collect(word);
}
}
});
// DataStream 下邊為DataStream子類
SingleOutputStreamOperator<String> source = flatMap.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value.toUpperCase();
}
});
// 4.資料輸出
source.print();
// 5.執行程式
env.execute();
}
}
關于在設定運行模式的代碼上,有三種選擇
/**
* Runtime execution mode of DataStream programs. Among other things, this controls task scheduling,
* network shuffle behavior, and time semantics. Some operations will also change their record
* emission behaviour based on the configured execution mode.
*
* @see <a
* href="https://cwiki.apache.org/confluence/display/FLINK/FLIP-134%3A+Batch+execution+for+the+DataStream+API">
* https://cwiki.apache.org/confluence/display/FLINK/FLIP-134%3A+Batch+execution+for+the+DataStream+API</a>
*/
@PublicEvolving
public enum RuntimeExecutionMode {
/**
* The Pipeline will be executed with Streaming Semantics. All tasks will be deployed before
* execution starts, checkpoints will be enabled, and both processing and event time will be
* fully supported.
*/
/** 流處理模式 */
STREAMING,
/**
* The Pipeline will be executed with Batch Semantics. Tasks will be scheduled gradually based
* on the scheduling region they belong, shuffles between regions will be blocking, watermarks
* are assumed to be "perfect" i.e. no late data, and processing time is assumed to not advance
* during execution.
*/
/** 批處理模式 */
BATCH,
/**
* Flink will set the execution mode to {@link RuntimeExecutionMode#BATCH} if all sources are
* bounded, or {@link RuntimeExecutionMode#STREAMING} if there is at least one source which is
* unbounded.
*/
/** 自動模式 */
AUTOMATIC
}
1.3 Scala+
與Java一樣都在IDEA編譯器上做,此時引入依賴
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-core -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-core</artifactId>
<version>1.14.3</version>
</dependency>
// …
待定 …
// …
2 常用API
第一次學時,光看上面的Demo例子比較難以理解,所以通過書下面的API內容對照上面的Demo來進行理解,先來了解Flink四種層次的API詳情
| 層級 | 描述資訊 | 備注 |
|---|---|---|
| 底層 API | 偏底層,易用性比較差,提供時間/狀態的細粒度控制 | Stateful Stream Processing |
| 核心 API | 對有界/無界資料提供處理方法 | DataStream(流處理) / DataSet(批處理) |
| Table API | / | 宣告式DSL |
| SQL | / | 高級語言 |
2.1 DataStream 流處理
主要分為三個流程
- DataSource 資料輸入:addSource(sourceFunction)為程式添加一個資料源,
- Transformation 資料處理:對一個或多個資料源進行操作,
- Sink 資料輸出:通過Transformation 處理后的資料輸出到指定的位置,
DataSource
看看他們的API
| DataSource API | 描述 |
|---|---|
| readTextFile(檔案路徑) | 逐行讀取文本檔案的資料 |
| socketTextStream(地址資訊) | 從socket中讀取資料 |
| fromCollection(集合資料) | 從集合內獲取資料 |
| 其他第三方輸入資料…或者自定義資料源 | 通過Flink提供的內置連接器去鏈接其它資料源 |
如果是自定義資料源,有兩種實作方式
- 實作SourceFunction介面(并行度為1 = 無并行度)
- 實作ParallelSourceFunction介面 / 繼承RichParallelSourceFunction
什么是并行度?
? 一個Flink程式由多個任務(Source、Transformation和Sink)組成,一個任務由多個并行實體(執行緒)來執行,一個任務的并行實體(執行緒)數目被稱為該任務的并行度,
Transformation
接下來是Transformation資料處理,Flink針對DataStream提供了大量的已經實作的算子,
| DataStream API | 描述 |
|---|---|
| Map | 輸入一個元素,然后回傳一個元素,中間可以進行清洗轉換等操作 |
| FlatMap | 輸入一個元素,可以回傳零個、一個或者多個元素 |
| Filter | 過濾函式,對傳入的資料進行判斷,符合條件的資料會被留下 |
| KeyBy | 根據指定的Key進行分組,Key相同的資料會進入同一個磁區,典型用法如下:1、DataStream.keyBy(“someKey”) 指定物件中的someKey段作為分組Key,2、DataStream.keyBy(0) 指定Tuple中的第一個元素作為分組Key, |
| Reduce | 對資料進行聚合操作,結合當前元素和上一次Reduce回傳的值進行聚合操作,然后回傳一個新的值 |
| Aggregations | sum()、min()、max()等 |
| Union | 合并多個流,新的流會包含所有流中的資料,但是Union有一個限制,就是所有合并的流型別必須是一致的 |
| Connect | 和Union類似,但是只能連接兩個流,兩個流的資料型別可以不同,會對兩個流中的資料應用不同的處理方法 |
| coMap和coFlatMap | 在ConnectedStream中需要使用這種函式,類似于Map和flatMap |
| Split | 根據規則把一個資料流切分為多個流 |
| Select | 和Split配合使用,選擇切分后的流 |
關于Flink針對DataStream提供的一些資料磁區規則
| 磁區規則 | 描述 |
|---|---|
| DataStream.shuffle() | 隨機磁區 |
| DataStream.rebalance() | 對資料集進行再平衡、重磁區和消除資料傾斜 |
| DataStream.rescale() | 重新調節 |
| DataStream.partitionCustom(partitioner,0) 或者 DataStream.partitionCustom(partitioner,“smeKey”) | 自定義磁區 |
Sink
資料處理后的輸出
| Sink API | 描述 |
|---|---|
| writeAsText() | 將元素以字串形式逐行寫入,這些字串通過呼叫每個元素的toString()方法來獲取 |
| print() / printToErr() | 列印每個元素的toString()方法的值到標準輸出或者標準錯誤輸出流中 |
| 自定義輸出 | addSink可以實作把資料輸出到第三方存盤介質中,系統提供了一批內置的Connector,它們會提供對應的Sink支持 |
示例一:自定義資料源(SourceFunction)
第一步,繼承SourceFunction介面,實作自定義資料源類
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Random;
/**
* 自定義資料源
* @author 李家民
*/
public class DemoTransactionSource implements SourceFunction<String> {
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (true) {
// 發射元素
ctx.collect(String.valueOf(new Random().nextInt(50)
));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
}
}
第二步,在Flink代碼中引入這個資料源
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
/**
* @author 李家民
*/
@Component
public class FlinkInitialize {
@PostConstruct
public void starter() throws Exception {
// 1.準備環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 設定運行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.設定自定義資料源
DataStreamSource<String> stringDataStreamSource = env.addSource(new DemoTransactionSource(), "測驗用的資料源");
// 3.資料處理
SingleOutputStreamOperator<String> stringSingleOutputStreamOperator = stringDataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value;
}
});
// 4.資料輸出
stringSingleOutputStreamOperator.print();
// 5.執行程式
env.execute();
}
}
此時執行代碼,就可以把引入的資料進行列印
SourceFunction定義了run和cancel兩個方法和SourceContext內部介面,
- run(SourceContex):實作資料獲取邏輯,并可以通過傳入的引數ctx進行向下游節點的資料轉發,
- cancel():用來取消資料源,一般在run方法中,會存在一個回圈來持續產生資料,cancel方法則可以使該回圈終止,
- SourceContext:source函式用于發出元素和可能的watermark的介面,回傳source生成的元素的型別,
示例二:自定義磁區
資料源沿用上述案例的代碼,自定義磁區是通過實作Partitioner介面去做處理
首先看看自定義磁區的實作類
/**
* 自定義磁區
* @author 李家民
*/
public class DemoPartitioner implements Partitioner<String> {
@Override
public int partition(String key, int numPartitions) {
System.out.println("目前磁區總數=" + numPartitions + " 當前值=" + key + " 通過最左邊的值看磁區號");
if (new Integer(key) > 20) {
return 1;
} else {
return 2;
}
}
}
然后在Flink的代碼中體現
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Component
public class FlinkInitialize {
@PostConstruct
public void starter() throws Exception {
// 1.準備環境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 設定運行模式
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 2.設定自定義資料源
DataStreamSource<String> stringDataStreamSource = env.addSource(new DemoTransactionSource(), "測驗用的資料源");
// 3.資料處理
DataStream<String> dataStream = stringDataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value;
}
}).partitionCustom(new DemoPartitioner(), new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
return value;
}
});
// 4.資料輸出
dataStream.print();
// 5.執行程式
env.execute();
}
}
輸出后的結果如下
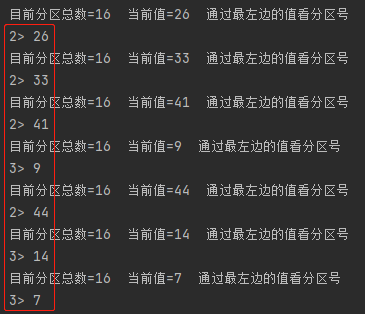
示例三:NettyServer作為資料源
第一步:搭建資料來源,這里選擇了Netty服務端作為本次示例
import com.sun.org.slf4j.internal.Logger;
import com.sun.org.slf4j.internal.LoggerFactory;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.handler.codec.string.StringDecoder;
import io.netty.handler.codec.string.StringEncoder;
import org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
/**
* @author 李家民
*/
@Component
public class NettyServerInitialize {
private static Logger log = LoggerFactory.getLogger(NettyServerInitialize.class);
public static EventLoopGroup bossGroup;
public static EventLoopGroup workerGroup;
public static ServerBootstrap serverBootstrap;
public static ChannelFuture channelFuture;
public static Boolean isRunning = false;
static {
// Server初始化
bossGroup = new NioEventLoopGroup(1);
workerGroup = new NioEventLoopGroup(2);
serverBootstrap =
new ServerBootstrap().group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.SO_BACKLOG, 128)
.childOption(ChannelOption.SO_KEEPALIVE, true)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
System.out.println("客戶端進入:" + ch.remoteAddress().getAddress());
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new StringDecoder());
pipeline.addLast(new NettyServerHandler());
pipeline.addLast(new StringEncoder());
}
});
}
@PostConstruct
public void starter() throws InterruptedException {
try {
if (!isRunning) {
channelFuture = serverBootstrap.bind(16668)
.addListener(new ChannelFutureListener() {
@Override
public void operationComplete(ChannelFuture future) throws Exception {
if (future.isSuccess()) {
System.out.println("監聽埠 16668 成功");
isRunning = true;
} else {
log.error("監聽埠 16668 失敗");
}
}
}).channel().closeFuture().sync();
}
} catch (Exception e) {
e.printStackTrace();
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
第二步:XXXX
示例四:RabbitMQ作為資料源
1
示例五:待定
1
2.2 DataSet 批處理
1
2.3 Table API/SQL
1
1
2.4 關于序列化
1
111111
3 集群模式
1
1
1
三、高階功能使用
1
四、原理決議
1
總結
提示:這里對文章進行總結:
例如:以上就是今天要講的內容,本文僅僅簡單介紹了pandas的使用,而pandas提供了大量能使我們快速便捷地處理資料的函式和方法,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/435540.html
標籤:其他
上一篇:python大資料可視化分析淘寶商品,開專賣店不行啊
下一篇:使用googleApi獲取位置